RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval
by Stanford University
TL;DR
이 연구를 시작하게 된 배경과 동기는 무엇입니까?
대규모 언어 모델(LLMs)은 인상적인 성능을 보이고 있지만, 특정 도메인의 전문 지식 부족과 지식의 시의성 문제라는 한계에 직면해 있습니다. 기존의 검색 증강 접근방식은 텍스트를 짧은 청크로 분할하여 검색하는 방식을 사용하지만, 이는 문서의 전체적인 맥락과 계층적 의미 구조를 효과적으로 포착하지 못한다는 한계가 있습니다. 특히 복잡한 다단계 추론이 필요한 과제에서 이러한 한계가 두드러집니다. 이 연구는 이러한 문제를 해결하기 위해 문서의 계층적 의미 구조를 효과적으로 활용할 수 있는 새로운 검색 증강 방법론을 개발하고자 시작되었습니다.
이 연구에서 제시하는 새로운 해결 방법은 무엇입니까?
RAPTOR(Recursive Abstraction Processing Through Tree-based Organization and Retrieval)는 텍스트의 계층적 의미 구조를 포착하고 활용하는 혁신적인 트리 기반 검색 시스템을 제시합니다. 이 시스템은 텍스트 청크를 재귀적으로 임베딩하고, 클러스터링하며, 요약하는 과정을 통해 다양한 추상화 수준의 정보를 포함하는 트리 구조를 구축합니다. 특히 의미적 유사성을 기반으로 한 클러스터링과 재귀적 요약을 통해, 문서 전체에 걸친 정보를 효과적으로 통합하고 활용할 수 있는 구조를 제공합니다.
제안된 방법은 어떻게 구현되었습니까?
RAPTOR의 구현은 크게 트리 구축과 검색 메커니즘 두 단계로 나뉩니다. 트리 구축 단계에서는 텍스트를 100 토큰 길이의 청크로 분할한 후, SBERT를 사용하여 임베딩합니다. 이후 가우시안 혼합 모델(GMM)을 사용한 클러스터링과 GPT-3.5-turbo를 활용한 요약 생성을 통해 계층적 트리 구조를 구축합니다. 검색 단계에서는 트리 순회와 축소된 트리라는 두 가지 방식을 제공하며, 실험 결과 축소된 트리 방식이 더 우수한 성능을 보였습니다. 시스템의 확장성 분석 결과, 트리 구축 비용과 시간이 문서 길이에 대해 선형적으로 증가하는 것으로 나타났습니다.
이 연구의 결과가 가지는 의미는 무엇입니까?
RAPTOR는 NarrativeQA, QASPER, QuALITY와 같은 복잡한 질의응답 과제에서 기존 최고 성능을 크게 상회하는 결과를 달성했습니다. 특히 GPT-4와 결합했을 때 QuALITY 벤치마크에서 20%의 절대적 정확도 향상을 보여주었습니다. 이러한 성과는 문서의 계층적 의미 구조를 활용하는 RAPTOR의 접근 방식이 복잡한 추론 과제에서 매우 효과적임을 입증합니다. 또한 선형적 확장성과 낮은 환각 발생률(4%)은 RAPTOR가 실제 응용에서도 실용적인 솔루션이 될 수 있음을 보여줍니다. 이는 검색 증강 언어 모델의 새로운 발전 방향을 제시하며, 특히 긴 문서에 대한 심층적 이해가 필요한 과제에서 중요한 의미를 가집니다.
RAPTOR: 재귀적 추상화 처리를 통한 트리 기반 검색
RAPTOR는 기존 검색 증강 언어 모델의 한계를 극복하기 위해 새로운 접근 방식을 제시합니다. 기존 모델들이 검색 코퍼스에서 짧은 연속적인 텍스트 청크만을 검색하는 것과 달리, RAPTOR는 문서의 전체적인 맥락을 더 잘 이해하고 활용할 수 있는 혁신적인 방법론을 도입했습니다.
RAPTOR의 핵심은 텍스트 청크를 재귀적으로 임베딩하고, 클러스터링하며, 요약하는 과정을 통해 상향식으로 다양한 수준의 요약을 포함하는 트리 구조를 구축하는 것입니다. 이렇게 구축된 트리 구조를 통해 추론 단계에서 문서 전체에 걸쳐 서로 다른 추상화 수준의 정보를 통합하여 활용할 수 있습니다.
통제된 실험을 통해 RAPTOR의 재귀적 요약 기반 검색 방식이 기존의 검색 증강 언어 모델들보다 여러 과제에서 상당한 성능 향상을 보여주었습니다. 특히 복잡한 다단계 추론이 필요한 질의응답 과제에서 최신 성능을 달성했습니다. 예를 들어, RAPTOR의 검색 방식을 GPT-4와 결합했을 때 QuALITY 벤치마크에서 기존 최고 성능 대비 절대적 정확도를 20% 향상시켰습니다.
이러한 성과는 RAPTOR가 도입한 재귀적 요약 트리 구조가 문서의 계층적 의미 관계를 효과적으로 포착하고, 복잡한 추론 과정에서 필요한 다양한 수준의 정보를 유연하게 활용할 수 있게 해준다는 것을 보여줍니다. 특히 긴 문서에 대한 전체적인 이해와 세부적인 정보의 통합이 필요한 과제에서 RAPTOR의 장점이 두드러지게 나타납니다.
서론
대규모 언어 모델(Large Language Models, LLMs)은 다양한 과제에서 인상적인 성능을 보이며 혁신적인 도구로 부상했습니다. 모델의 규모가 커짐에 따라 파라미터 내에 사실 정보를 효과적으로 저장할 수 있게 되었고, 이는 Petroni와 연구진의 연구를 통해 입증되었습니다. 또한 Roberts와 연구진이 보여준 것처럼 하위 과제에 대한 미세조정을 통해 모델의 성능을 더욱 향상시킬 수 있습니다.
하지만 대규모 언어 모델에도 한계가 있습니다. 특정 과제에 필요한 도메인별 지식이 충분하지 않을 수 있으며, 세상이 계속 변화함에 따라 모델 내의 사실 정보가 무효화될 수 있습니다. Lewis와 연구진이 지적했듯이, 방대한 텍스트 코퍼스를 통한 추가 미세조정이나 편집을 통해 모델의 지식을 업데이트하는 것은 어려운 과제입니다.
이러한 문제를 해결하기 위한 대안적 접근 방식으로, Chen과 연구진이 개방형 질의응답 시스템에서 선구적으로 도입한 방법이 있습니다. 이는 텍스트를 청크(단락)로 분할한 후 별도의 정보 검색 시스템에 인덱싱하는 방식입니다. 검색된 정보는 질문과 함께 LLM에 문맥으로 제공되며(“검색 증강”), 이를 통해 특정 도메인의 최신 지식을 시스템에 쉽게 제공할 수 있습니다. 또한 Akyurek과 연구진이 언급했듯이, 이는 해석 가능성과 출처 추적을 용이하게 하는 장점이 있습니다.
본 연구의 주요 기여는 다양한 규모의 문맥 검색 증강을 가능하게 하는 텍스트 요약 방법을 도입한 것이며, 긴 문서 모음에 대한 실험을 통해 그 효과성을 입증했습니다. UnifiedQA, GPT-3, GPT-4를 사용한 통제된 실험에서 RAPTOR는 기존의 검색 증강 방식보다 우수한 성능을 보였습니다. 특히 GPT-4와 결합된 RAPTOR는 NarrativeQA, QASPER, QuALITY와 같은 세 가지 질의응답 과제에서 새로운 최고 성능을 달성했습니다.
관련 연구
검색의 필요성
최근 하드웨어와 알고리즘의 발전으로 언어 모델이 처리할 수 있는 문맥의 길이가 크게 늘어났습니다. Liu와 연구진은 모델이 긴 문맥에서 관련 정보를 찾아내는 데 어려움을 겪으며, 문맥의 길이가 증가할수록 성능이 저하되는 현상을 관찰했습니다. 또한 긴 문맥을 처리하는 것은 계산 비용이 많이 들고 처리 속도가 느리다는 실용적인 문제도 있습니다. 이러한 이유로 지식 집약적 과제에서는 여전히 가장 관련성 높은 정보를 선별하는 것이 중요합니다.
검색 방법론의 발전
검색 증강 언어 모델(RALMs)은 검색기(retriever), 판독기(reader), 그리고 종단간 시스템 학습 등 다양한 구성 요소에서 발전을 이루었습니다. 검색 방법은 TF-IDF나 BM25와 같은 전통적인 용어 기반 기술에서 딥러닝 기반 전략으로 발전했습니다. 최근에는 Yu와 연구진이 제안한 것처럼 방대한 지식을 기억할 수 있는 대규모 언어 모델을 검색기로 활용하는 연구도 진행되고 있습니다.
판독기 구성 요소에 대한 연구로는 Izacard와 Grave가 제안한 Fusion-in-Decoder(FiD)가 있습니다. FiD는 DPR과 BM25를 모두 활용하여 검색을 수행하고, 인코더에서 각 문단을 독립적으로 처리합니다. 또한 Borgeaud와 연구진이 개발한 RETRO는 교차 청크 어텐션과 청크 단위 검색을 활용하여 검색된 문맥을 기반으로 텍스트를 생성합니다.
종단간 시스템 학습 연구에는 Atlas, REALM, RAG 등이 있습니다. Atlas는 검색기와 함께 인코더-디코더 모델을 미세조정하는 방식을 사용하며, REALM은 개방형 질의응답을 위해 양방향 마스크드 언어 모델을 미세조정합니다. RAG는 사전 학습된 시퀀스-투-시퀀스 모델을 신경망 검색기와 통합하는 방식을 제안했습니다.
Min과 연구진은 다중 답변 검색에서 문단의 다양성과 관련성을 처리하기 위해 트리 디코딩 알고리즘을 사용하는 Joint Passage Retrieval(JPR) 모델을 소개했습니다. Dense Hierarchical Retrieval(DHR)과 Hybrid Hierarchical Retrieval(HHR)은 문서와 문단 수준의 검색을 결합하고 희소 검색과 밀집 검색 방법을 통합하여 검색 정확도를 향상시켰습니다.
검색 방법의 한계와 재귀적 요약의 필요성
현재 대부분의 모델들은 코퍼스를 청크로 나누고 BERT 기반 검색기로 인코딩하는 표준적인 접근 방식을 사용합니다. 하지만 Nair와 연구진이 지적했듯이, 연속적인 세그멘테이션은 텍스트의 완전한 의미적 깊이를 포착하지 못할 수 있습니다. 특히 기술 문서나 과학 문서에서 추출된 스니펫은 중요한 문맥이 누락되어 이해하기 어렵거나 오해의 소지가 있을 수 있습니다.
요약 기술은 문서의 압축된 관점을 제공하여 내용에 더 집중적으로 접근할 수 있게 해줍니다. Gao와 연구진이 제안한 요약/스니펫 모델은 문단의 요약과 스니펫을 활용하여 대부분의 데이터셋에서 정확도를 향상시켰지만, 때로는 정보 손실이 발생할 수 있습니다. Wu와 연구진의 재귀적-추상화 요약 모델은 작은 텍스트 청크를 요약한 후 이를 통합하여 더 큰 섹션의 요약을 생성합니다. 이 방법은 전체적인 주제를 포착하는 데는 효과적이지만 세부적인 내용을 놓칠 수 있습니다.
LlamaIndex는 인접한 텍스트 청크를 요약하면서도 중간 노드를 유지하여 다양한 수준의 세부 정보를 저장함으로써 이러한 문제를 완화합니다. 그러나 이러한 방법들은 인접성에 기반한 그룹화나 요약에 의존하기 때문에 텍스트 내의 원거리 상호 의존성을 놓칠 수 있습니다. RAPTOR는 이러한 상호 의존성을 찾아내고 그룹화할 수 있는 새로운 방법을 제시합니다.
RAPTOR의 방법론 개요
RAPTOR는 긴 텍스트가 일반적으로 하위 주제와 계층적 구조를 가진다는 통찰을 바탕으로, 의미적 깊이와 연결성을 효과적으로 처리하는 재귀적 트리 구조를 구축합니다. 이 트리 구조는 문서의 전체적인 주제 이해와 세부적인 내용을 균형있게 다루며, 텍스트 내의 순서가 아닌 의미적 유사성을 기반으로 노드들을 그룹화합니다.
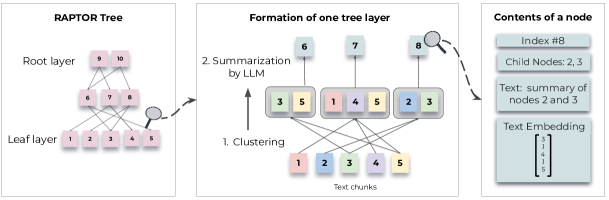
RAPTOR 트리의 구축은 기존의 검색 증강 기법과 유사하게 검색 코퍼스를 100 토큰 길이의 연속적인 텍스트 청크로 분할하는 것으로 시작됩니다. 이때 문장의 문맥적, 의미적 일관성을 유지하기 위해 한 문장이 100 토큰을 초과하는 경우에는 해당 문장을 중간에 자르지 않고 다음 청크로 이동시킵니다.
분할된 텍스트 청크들은 SBERT(multi-qa-mpnet-base-cos-v1)를 사용하여 임베딩됩니다. 이렇게 생성된 텍스트 청크와 해당 SBERT 임베딩은 트리 구조의 리프 노드가 됩니다. 유사한 텍스트 청크들을 그룹화하기 위해 클러스터링 알고리즘이 사용되며, 클러스터링된 텍스트들은 언어 모델을 통해 요약됩니다. 요약된 텍스트는 다시 임베딩되고, 이러한 임베딩-클러스터링-요약의 과정은 더 이상의 클러스터링이 불가능할 때까지 반복되어 원본 문서의 구조화된 다층 트리 표현을 생성합니다.
RAPTOR의 주목할 만한 특징은 계산 효율성입니다. 시스템은 구축 시간과 토큰 사용량 측면에서 선형적으로 확장되어 대규모의 복잡한 코퍼스를 처리하는 데 적합합니다. 이러한 확장성에 대한 자세한 논의는 논문의 부록 A에서 확인할 수 있습니다.
트리 내에서의 쿼리 처리를 위해 RAPTOR는 두 가지 전략을 제시합니다. 첫 번째는 트리 순회 방식으로, 트리를 계층별로 탐색하면서 각 레벨에서 가장 관련성 높은 노드들을 선택하고 가지치기를 수행합니다. 두 번째는 축소된 트리 방식으로, 모든 계층의 노드들을 통합적으로 평가하여 가장 관련성 높은 노드들을 찾아냅니다.
클러스터링 알고리즘
RAPTOR 트리를 구축하는 데 있어 클러스터링은 핵심적인 역할을 수행합니다. 이 알고리즘은 텍스트 세그먼트를 응집력 있는 그룹으로 조직화하여 후속 검색 프로세스를 지원합니다. 본 연구의 클러스터링 접근 방식의 독특한 특징은 소프트 클러스터링을 사용한다는 점입니다. 소프트 클러스터링에서는 노드가 여러 클러스터에 동시에 속할 수 있으며, 고정된 클러스터 수를 요구하지 않습니다. 이러한 유연성은 개별 텍스트 세그먼트가 다양한 주제와 관련된 정보를 포함할 수 있기 때문에 여러 요약에 포함되어야 하는 경우에 매우 중요합니다.
클러스터링 알고리즘은 가우시안 혼합 모델(Gaussian Mixture Models, GMMs)을 기반으로 합니다. GMMs는 데이터 포인트들이 여러 가우시안 분포의 혼합으로부터 생성된다고 가정합니다. $N$개의 텍스트 세그먼트가 각각 $d$차원의 밀집 벡터 임베딩으로 표현될 때, 텍스트 벡터 $\mathbf{x}$가 $k$번째 가우시안 분포에 속할 때의 우도는 다음과 같이 표현됩니다.
\[P(\mathbf{x}|k)=\mathcal{N}(\mathbf{x};\mathbf{\mu}_{k},\mathbf{\Sigma}_{k})\]전체 확률 분포는 다음과 같은 가중 조합으로 표현됩니다.
\[P(\mathbf{x})=\sum_{k=1}^{K}\pi_{k}\mathcal{N}(\mathbf{x};\mathbf{\mu}_{k},\mathbf{\Sigma}_{k})\]여기서 $\pi_{k}$는 $k$번째 가우시안 분포의 혼합 가중치를 나타냅니다.
벡터 임베딩의 높은 차원성은 전통적인 GMMs에 있어 도전 과제가 됩니다. 고차원 공간에서는 거리 메트릭이 유사성을 측정하는 데 제대로 작동하지 않을 수 있기 때문입니다. 이를 해결하기 위해 균일 매니폴드 근사 및 투영(Uniform Manifold Approximation and Projection, UMAP)이라는 매니폴드 학습 기법을 차원 축소에 활용합니다. UMAP의 최근접 이웃 파라미터인 $n_{neighbors}$는 지역 구조와 전역 구조의 보존 사이의 균형을 결정합니다.
알고리즘은 $n_{neighbors}$를 변화시켜 계층적 클러스터링 구조를 생성합니다. 먼저 전역 클러스터를 식별한 다음, 이러한 전역 클러스터 내에서 지역 클러스터링을 수행합니다. 이러한 2단계 클러스터링 프로세스는 텍스트 데이터 간의 광범위한 관계를 포착합니다. 만약 지역 클러스터의 결합된 문맥이 요약 모델의 토큰 임계값을 초과하는 경우, 알고리즘은 해당 클러스터 내에서 재귀적으로 클러스터링을 적용하여 문맥이 토큰 임계값 내에 유지되도록 합니다.
최적의 클러스터 수를 결정하기 위해 베이지안 정보 기준(Bayesian Information Criterion, BIC)을 사용합니다. BIC는 모델의 복잡성을 페널티로 부과하면서 동시에 적합도를 보상합니다. 주어진 GMM에 대한 BIC는 다음과 같이 계산됩니다.
\[BIC=\ln(N)k-2\ln(\hat{L})\]여기서 $N$은 텍스트 세그먼트(또는 데이터 포인트)의 수, $k$는 모델 파라미터의 수, $\hat{L}$은 모델의 최대화된 우도 함수 값입니다. GMM의 맥락에서 파라미터 수 $k$는 입력 벡터의 차원과 클러스터 수의 함수입니다.
BIC에 의해 최적의 클러스터 수가 결정되면, 기대값 최대화(Expectation-Maximization) 알고리즘을 사용하여 GMM 파라미터, 즉 평균, 공분산, 혼합 가중치를 추정합니다. GMMs의 가우시안 가정이 텍스트 데이터의 희소하고 왜곡된 분포 특성과 완벽하게 일치하지 않을 수 있지만, 경험적 관찰에 따르면 이는 우리의 목적에 효과적인 모델을 제공합니다.
모델 기반 요약
가우시안 혼합 모델(Gaussian Mixture Models)을 사용한 클러스터링 이후, 각 클러스터의 노드들은 요약을 위해 언어 모델로 전송됩니다. 이 단계에서는 대량의 텍스트를 간결하고 일관된 요약으로 변환합니다. 실험에서는 gpt-3.5-turbo를 사용하여 요약을 생성했습니다. 요약 단계는 검색된 정보의 잠재적으로 큰 볼륨을 관리 가능한 크기로 압축합니다.
요약 모델의 성능을 검증하기 위해 상세한 주석 연구를 수행했습니다. 이 연구에서 약 4%의 요약에서 경미한 환각(hallucination) 현상이 발견되었습니다. 그러나 이러한 환각은 상위 노드로 전파되지 않았으며, 질의응답 과제에서 식별 가능한 영향을 미치지 않았습니다. 요약으로 인한 압축 정도에 대한 통계는 부록 C에서, 요약에 사용된 프롬프트는 부록 D에서, 환각 현상에 대한 심층 분석은 부록 E에서 확인할 수 있습니다.
이러한 모델 기반 요약 방식은 트리 구조의 각 계층에서 정보를 효과적으로 압축하면서도 의미적 일관성을 유지할 수 있게 해줍니다. GPT-3.5-Turbo를 사용한 요약 생성은 높은 품질의 요약을 제공하면서도, 환각과 같은 잠재적 문제를 최소화하고 효과적으로 관리할 수 있음을 보여줍니다.
RAPTOR의 쿼리 메커니즘
RAPTOR는 트리 순회(tree traversal)와 축소된 트리(collapsed tree)라는 두 가지 쿼리 메커니즘을 제공합니다. 이 두 방식은 다계층 RAPTOR 트리를 탐색하여 관련 정보를 검색하는 고유한 방법을 제공하며, 각각의 장단점이 있습니다.
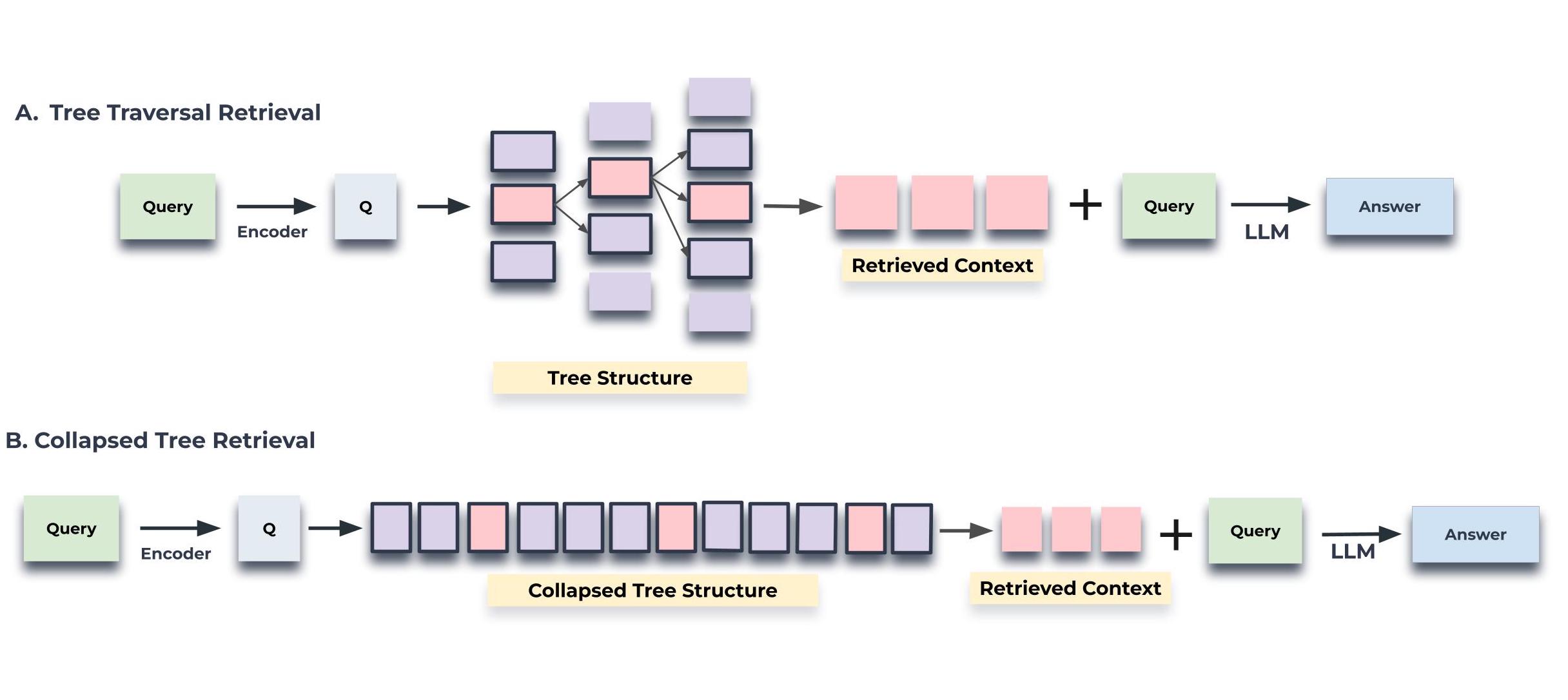
트리 순회 방식은 먼저 루트 노드 계층에서 시작하여 쿼리 임베딩과의 코사인 유사도를 기반으로 상위 \(k\)개의 가장 관련성 높은 루트 노드를 선택합니다. 선택된 노드들의 자식 노드들이 다음 계층에서 고려되며, 이들 중에서 다시 쿼리 벡터와의 코사인 유사도를 기반으로 상위 \(k\)개의 노드를 선택합니다. 이 과정은 리프 노드에 도달할 때까지 반복됩니다. 최종적으로 선택된 모든 노드의 텍스트가 연결되어 검색된 문맥을 형성합니다.
트리 순회 알고리즘의 구체적인 단계는 다음과 같습니다.
- RAPTOR 트리의 루트 계층에서 시작하여 해당 계층의 모든 노드와 쿼리 임베딩 간의 코사인 유사도를 계산합니다.
- 가장 높은 코사인 유사도 점수를 가진 상위 \(k\)개의 노드를 선택하여 집합 $S_1$을 형성합니다.
- 집합 $S_1$의 요소들의 자식 노드들로 이동하여 이들과 쿼리 벡터 간의 코사인 유사도를 계산합니다.
- 쿼리와의 코사인 유사도가 가장 높은 상위 \(k\)개의 자식 노드를 선택하여 집합 $S_2$를 형성합니다.
- 이 과정을 d개의 계층에 대해 재귀적으로 수행하여 집합 $S_1, S_2, …, S_d$를 생성합니다.
- 집합 $S_1$부터 $S_d$까지를 연결하여 쿼리와 관련된 문맥을 구성합니다.
트리 순회 방식에서는 깊이 d와 각 계층에서 선택되는 노드 수 \(k\)를 조정함으로써 검색되는 정보의 구체성과 범위를 제어할 수 있습니다. 이 알고리즘은 트리의 상위 계층에서 넓은 관점으로 시작하여 하위 계층으로 내려가면서 점차 더 세부적인 내용에 초점을 맞추는 방식으로 작동합니다.
반면, 축소된 트리 방식은 모든 노드를 동시에 고려하는 더 단순한 방법을 제공합니다. 이 방식은 다계층 트리를 단일 계층으로 평탄화하여 모든 노드를 동일한 수준에서 비교합니다. 축소된 트리 방식의 단계는 다음과 같습니다.
- 전체 RAPTOR 트리를 단일 계층으로 축소합니다. 새로운 노드 집합 C는 원본 트리의 모든 계층의 노드를 포함합니다.
- 쿼리 임베딩과 축소된 집합 C에 있는 모든 노드의 임베딩 간의 코사인 유사도를 계산합니다.
- 쿼리와의 코사인 유사도가 가장 높은 상위 \(k\)개의 노드를 선택합니다. 모델의 입력 제한을 초과하지 않도록 사전 정의된 최대 토큰 수에 도달할 때까지 노드를 결과 집합에 추가합니다.
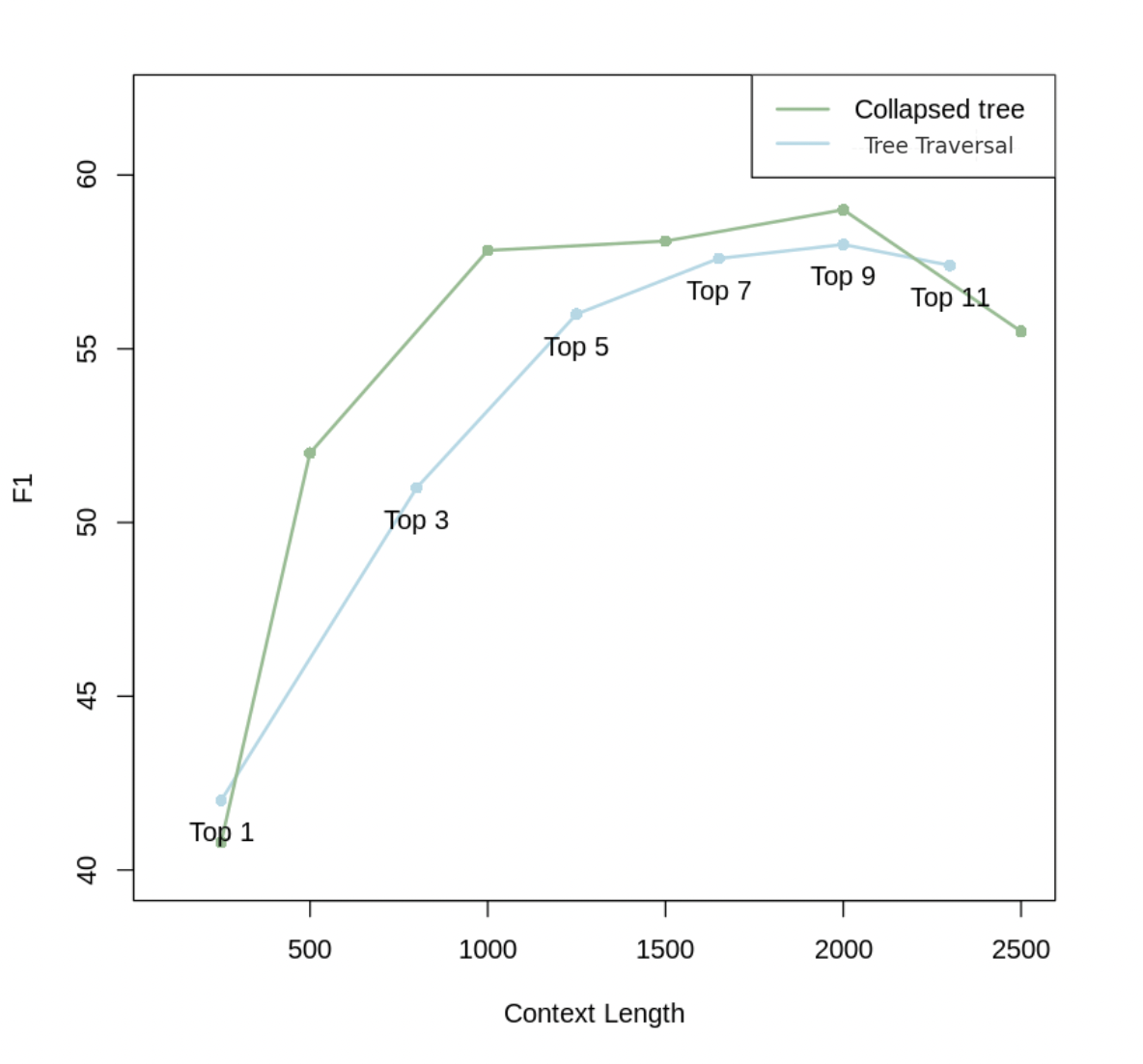
QASPER 데이터셋의 20개 이야기에 대해 두 방식을 테스트한 결과, 축소된 트리 방식이 일관되게 더 나은 성능을 보여주었습니다. 연구진은 축소된 트리 검색이 트리 순회보다 더 나은 성능을 보이는 이유가 주어진 질문에 대해 적절한 수준의 세분성을 가진 정보를 검색할 수 있는 더 큰 유연성을 제공하기 때문이라고 분석했습니다.
예를 들어, 동일한 \(d\)와 \(k\) 값을 사용하는 트리 순회에서는 트리의 각 계층에서 노드의 비율이 일정하게 유지되므로, 상위 수준의 주제 정보와 세부 사항의 비율이 질문과 관계없이 동일하게 유지됩니다. 그러나 축소된 트리 방식의 한 가지 단점은 트리의 모든 노드에 대해 코사인 유사도 검색을 수행해야 한다는 것입니다. 하지만 이는 FAISS와 같은 고속 \(k\)-최근접 이웃 라이브러리를 사용하여 효율적으로 처리할 수 있습니다.
실험 결과를 보여주는 그래프에서 축소된 트리 방식이 2000 토큰의 문맥 길이로 최상의 결과를 보여주었으며, 이는 모든 상위 \(k\) 값에서 트리 순회 방식보다 우수한 성능을 나타냈습니다. 이러한 결과를 바탕으로 연구진은 주요 실험에서 축소된 트리 방식을 채택했으며, 구체적으로는 약 상위 20개 노드에 해당하는 2000 토큰의 최대 토큰 수를 사용했습니다. 토큰 기반 접근 방식을 사용함으로써 노드 간 토큰 수가 다양할 수 있는 상황에서도 문맥이 모델의 제한을 초과하지 않도록 보장할 수 있습니다.
UnifiedQA 모델을 사용한 실험에서는 UnifiedQA가 512 토큰의 최대 문맥 길이를 가지고 있기 때문에 400 토큰의 문맥을 제공했으며, RAPTOR와 베이스라인 모델 모두에 동일한 양의 문맥 토큰을 제공했습니다.
정성적 분석 연구
RAPTOR의 검색 프로세스가 기존의 Dense Passage Retrieval (DPR) 방식과 비교하여 어떤 이점을 제공하는지 이해하기 위해 정성적 분석을 수행했습니다. 이 연구는 주제적이고 다단계적인 질문들을 중심으로 1500단어 분량의 신데렐라 동화를 사용하여 진행되었습니다.
RAPTOR의 트리 기반 검색은 질문의 세부 수준에 맞춰 트리의 서로 다른 계층에서 노드를 선택할 수 있게 해줍니다. 이러한 접근 방식은 DPR보다 더 관련성 높고 포괄적인 정보를 하위 과제에 제공할 수 있습니다. 예를 들어, “신데렐라가 무도회에서 왕자를 만나기 전에 어떤 일이 있었나요?”와 같은 질문에 대해 RAPTOR는 무도회 준비 과정에 대한 상위 수준의 요약과 함께 구체적인 사건들의 세부 사항을 모두 포함하는 문맥을 제공할 수 있습니다.
반면 DPR은 연속적인 텍스트 청크만을 검색하기 때문에, 이야기의 여러 부분에 걸쳐 있는 관련 정보를 모두 포착하지 못할 수 있습니다. 특히 시간적 순서나 인과 관계와 같은 복잡한 관계를 포함하는 질문에서 이러한 한계가 두드러집니다.
RAPTOR의 계층적 검색 방식은 다음과 같은 장점을 제공합니다.
- 문맥적 유연성: 질문의 특성에 따라 다양한 추상화 수준의 정보를 결합할 수 있습니다.
- 포괄적 정보 검색: 문서의 여러 부분에 분산된 관련 정보를 효과적으로 통합할 수 있습니다.
- 의미적 일관성: 검색된 정보들 간의 의미적 관계를 유지하면서 답변에 필요한 문맥을 구성할 수 있습니다.
이러한 정성적 분석 결과는 RAPTOR가 단순한 텍스트 청크 검색을 넘어서, 문서의 계층적 구조를 활용하여 더 지능적이고 맥락에 맞는 정보 검색을 가능하게 한다는 것을 보여줍니다. 특히 복잡한 추론이 필요한 질문에서 RAPTOR의 장점이 더욱 분명하게 드러납니다.
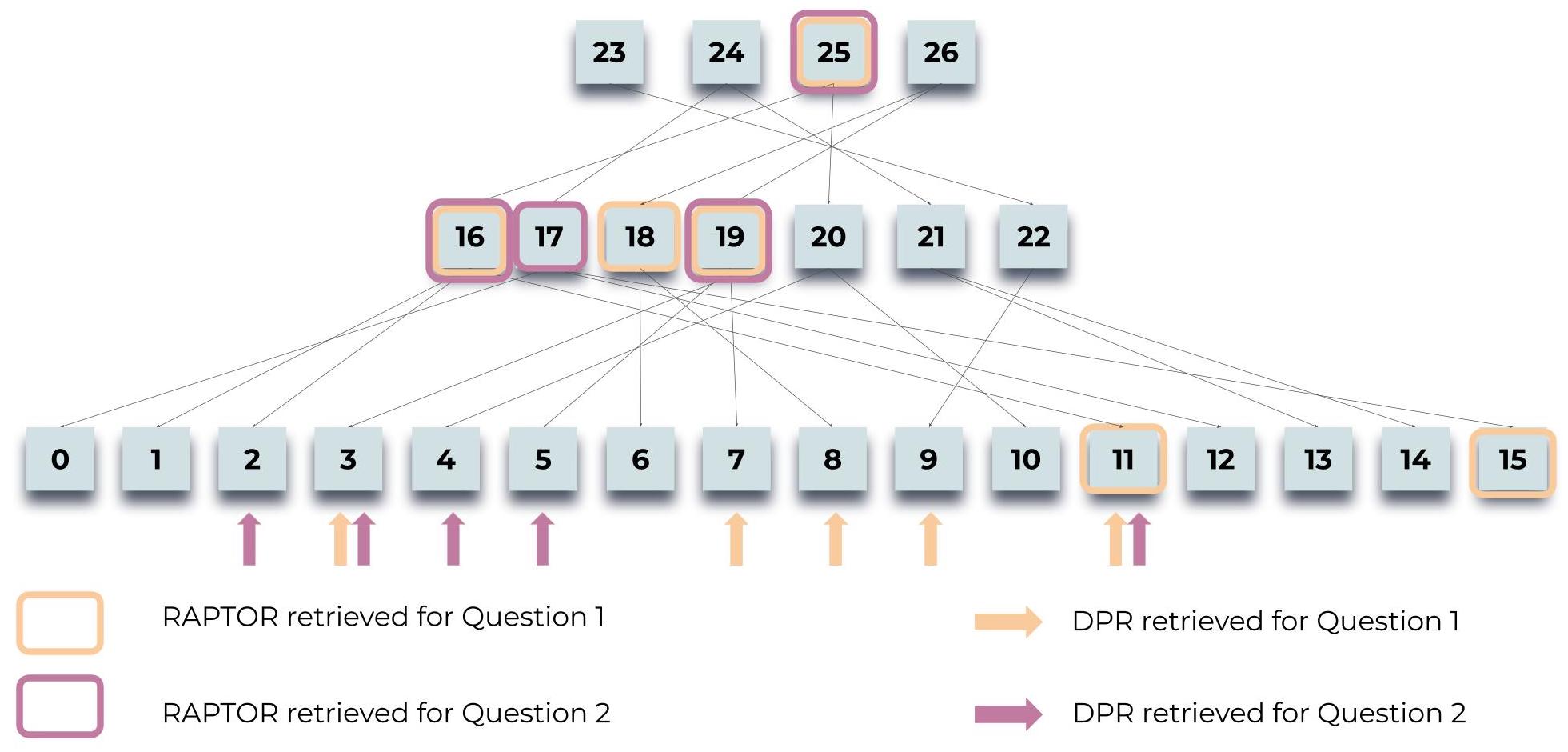
위 그림은 RAPTOR 시스템의 쿼리 프로세스를 보여주며, 신데렐라 이야기에 대한 두 가지 질문(“이야기의 중심 주제는 무엇인가요?”와 “신데렐라는 어떻게 행복한 결말을 맺게 되었나요?”)에 대한 정보를 검색하는 과정을 설명합니다. 강조 표시된 노드는 RAPTOR가 선택한 부분을 나타내고, 화살표는 DPR 모델이 검색한 리프 노드를 가리킵니다. RAPTOR의 문맥은 DPR이 검색한 정보를 직접적으로 또는 상위 계층의 요약을 통해 포함하고 있어, 검색과 추론 능력을 모두 활용하여 더 포괄적인 답변을 제공할 수 있음을 보여줍니다.
실험 데이터셋
RAPTOR의 성능을 평가하기 위해 세 가지 질의응답 데이터셋을 활용했습니다. NarrativeQA는 책과 영화 대본의 전체 텍스트를 기반으로 하는 질문-답변 쌍으로 구성되어 있으며, 총 1,572개의 문서를 포함합니다. NarrativeQA-Story 과제는 이야기 전체에 대한 포괄적인 이해를 바탕으로 질문에 답변해야 하므로, 문학 도메인에서 모델의 긴 텍스트 이해 능력을 평가할 수 있습니다. 이 데이터셋에서는 BLEU(B-1, B-4), ROUGE(R-L), METEOR(M) 지표를 사용하여 성능을 측정했습니다.
QASPER 데이터셋은 1,585개의 NLP 논문에 걸쳐 5,049개의 질문을 포함하고 있으며, 각 질문은 논문 전체 텍스트에 포함된 정보를 탐색하도록 설계되었습니다. QASPER의 답변 유형은 답변 가능/불가능, 예/아니오, 추상적, 추출적으로 분류되며, 표준 F1 점수로 정확도를 측정합니다.
QuALITY 데이터셋은 평균 약 5,000 토큰 길이의 문맥 구절이 포함된 객관식 문제로 구성되어 있습니다. 이 데이터셋은 질의응답 과제를 위해 문서 전체에 대한 추론을 필요로 하므로, 중간 길이 문서에서 RAPTOR의 검색 시스템 성능을 측정할 수 있습니다. 특히 QuALITY-HARD라는 도전적인 하위 집합을 포함하고 있는데, 이는 대다수의 인간 평가자들이 시간 제한 상황에서 잘못 답변한 문제들로 구성되어 있습니다. 전체 테스트 세트와 HARD 하위 집합 모두에 대한 정확도를 보고했습니다.
통제된 기준 비교
먼저 UnifiedQA 3B를 판독기로 사용하고, SBERT, BM25, DPR을 임베딩 모델로 사용하여 RAPTOR 트리 구조의 유무에 따른 통제된 비교를 QASPER, NarrativeQA, QuALITY 세 데이터셋에서 수행했습니다. 실험 결과는 RAPTOR가 어떤 검색기와 결합하더라도 모든 데이터셋에서 해당 검색기의 단독 성능을 일관되게 상회함을 보여줍니다.
결론
본 논문에서는 대규모 언어 모델의 파라메트릭 지식을 다양한 추상화 수준의 문맥 정보로 보강하는 혁신적인 트리 기반 검색 시스템인 RAPTOR를 제시했습니다. RAPTOR는 재귀적 클러스터링과 요약 기법을 활용하여 검색 코퍼스의 여러 섹션에 걸친 정보를 통합할 수 있는 계층적 트리 구조를 생성합니다.
RAPTOR의 핵심 기여는 문서의 계층적 의미 구조를 효과적으로 포착하고 활용하는 방식에 있습니다. 기존의 검색 증강 언어 모델들이 단순히 연속적인 텍스트 청크를 검색하는 것과 달리, RAPTOR는 재귀적 요약을 통해 문서의 다양한 수준의 추상화된 정보를 통합하여 제공합니다. 이러한 접근 방식은 특히 복잡한 다단계 추론이 필요한 질의응답 과제에서 그 효과가 두드러집니다.
통제된 실험을 통해 RAPTOR는 기존의 검색 방식들을 크게 상회하는 성능을 보여주었습니다. 특히 NarrativeQA, QASPER, QuALITY와 같은 여러 질의응답 과제에서 새로운 성능 기준을 수립했습니다. 이는 RAPTOR의 계층적 트리 구조가 문서의 전체적인 맥락을 이해하고 필요한 정보를 효과적으로 검색하는 데 매우 효과적임을 입증합니다.
RAPTOR의 성공은 검색 증강 언어 모델의 새로운 가능성을 보여줍니다. 특히 긴 문서에 대한 심층적인 이해가 필요한 과제에서 RAPTOR의 재귀적 요약 기반 접근 방식은 매우 효과적임이 입증되었습니다. 이는 향후 대규모 언어 모델의 지식 증강 연구에 있어 중요한 이정표가 될 것으로 기대됩니다.
재현성 검증
RAPTOR 실험에서는 질의응답과 요약 과제를 위해 네 가지 언어 모델을 활용했습니다. 질의응답 과제에는 GPT-3와 GPT-4를, 요약 과제에는 GPT-3.5-turbo를 사용했습니다. gpt-3, gpt-4, gpt-3.5-turbo 모델들은 OpenAI API를 통해 접근할 수 있으며, 질의응답 과제에 사용된 UnifiedQA는 허깅페이스(Hugging Face)에서 공개적으로 사용할 수 있습니다.
평가에 사용된 세 가지 데이터셋인 QuALITY, QASPER, NarrativeQA는 모두 공개적으로 접근 가능합니다. QuALITY 데이터셋은 NYU-MLL 연구팀이 공개한 것으로, 긴 문서에 대한 질의응답 과제를 위해 설계되었습니다. QASPER는 Allen AI에서 공개한 데이터셋으로 연구 논문에 대한 정보 탐색 질문들로 구성되어 있습니다. NarrativeQA는 Google DeepMind에서 공개한 데이터셋으로 이야기 텍스트에 대한 질의응답을 다룹니다. 이러한 데이터셋들의 공개적 접근성은 본 연구에서 수행된 검색과 질의응답 실험의 재현성을 보장합니다.
RAPTOR의 소스 코드는 GitHub를 통해 공개될 예정이며, 이를 통해 연구 커뮤니티는 제안된 방법론을 직접 구현하고 검증할 수 있습니다. 소스 코드는 트리 구축 프로세스, 검색 메커니즘, 그리고 질의응답 시스템의 전체 구현을 포함할 예정입니다.
부록 A: 트리 구축 프로세스의 확장성과 계산 효율성
RAPTOR의 트리 구축 프로세스의 계산 효율성과 비용 효과성을 평가하기 위해 16GB RAM을 탑재한 Apple M1 Mac 노트북에서 실험을 진행했습니다. 이 실험은 일반적인 하드웨어에서 RAPTOR의 확장성과 실현 가능성을 입증하기 위한 것이었습니다. 문맥 길이를 12,500에서 78,000 토큰까지 다양하게 변화시키면서 트리 구축 프로세스에 필요한 토큰 사용량과 소요 시간을 측정했습니다.
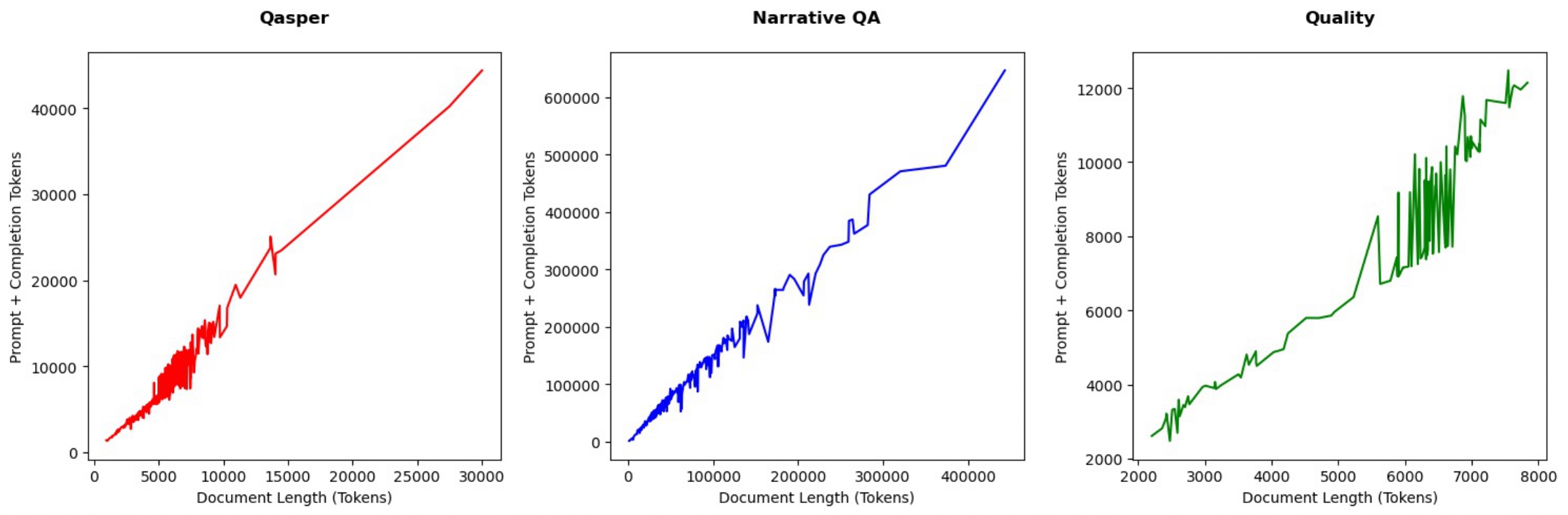
위 그래프는 QASPER, NarrativeQA, QuALITY 세 데이터셋에 대해 문서 길이와 토큰 비용 간의 관계를 보여줍니다. RAPTOR 트리 구축 비용이 모든 데이터셋에서 문서 길이에 대해 선형적으로 증가하는 것을 확인할 수 있습니다. 이는 RAPTOR의 접근 방식이 다양한 길이의 문서를 처리하는 데 있어 계산적으로 효율적임을 보여줍니다.
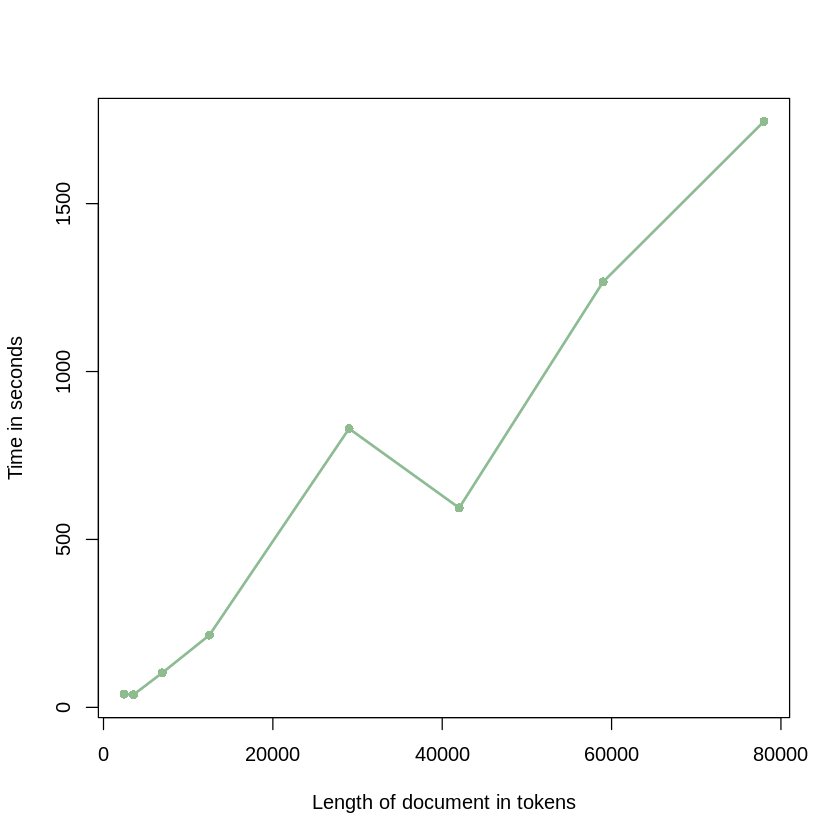
구축 시간 측면에서도 RAPTOR는 문서 길이에 대해 선형적인 확장성을 보여줍니다. 이는 RAPTOR가 대규모 코퍼스를 효율적으로 처리할 수 있는 실용적인 솔루션임을 입증합니다.
부록 B: RAPTOR의 클러스터링 메커니즘 분석
RAPTOR의 클러스터링 메커니즘의 효과성을 평가하기 위해 QuALITY 데이터셋을 사용하여 상세한 분석을 수행했습니다. 이 연구는 RAPTOR의 클러스터링 기반 접근 방식과 균형 트리 스타일의 인코딩 및 요약을 비교했습니다.
분석 방법론에서는 검색의 일관성을 유지하기 위해 두 구성 모두에서 SBERT 임베딩과 UnifiedQA를 사용했습니다. RAPTOR는 일반적인 클러스터링과 요약 프로세스를 적용했으며, 대안적 설정에서는 연속적인 텍스트 청크를 재귀적으로 인코딩하고 요약하여 균형 트리를 생성했습니다. 대안적 설정의 윈도우 크기는 RAPTOR에서 관찰된 평균 클러스터 크기인 약 6.7 노드를 기반으로 7 노드로 설정했습니다. 두 모델 모두에서 축소된 트리 방식을 검색에 적용했습니다.
분석 결과는 RAPTOR의 클러스터링 메커니즘이 시간 기반 트리 접근 방식보다 더 높은 정확도를 달성했음을 보여줍니다. RAPTOR와 SBERT 임베딩, UnifiedQA를 결합한 구성은 56.6%의 정확도를 달성한 반면, 시간 기반 트리 접근 방식은 55.8%의 정확도를 기록했습니다. 이러한 결과는 RAPTOR의 클러스터링 전략이 요약을 위한 동질적 콘텐츠를 포착하는 데 더 효과적이며, 이를 통해 전반적인 검색 성능이 향상된다는 가설을 뒷받침합니다.
부록 C: 데이터셋 통계와 압축 비율
모든 데이터셋에서 자식 노드 길이 합계에 대한 요약 길이의 평균 비율은 0.28로, 72%의 압축률을 나타냅니다. 평균적으로 요약 길이는 131 토큰이며, 평균 자식 노드 길이는 86 토큰입니다. 세 데이터셋의 상세 통계는 다음과 같습니다.
| 데이터셋 | 평균 요약 길이 (토큰) | 평균 자식 노드 텍스트 길이 (토큰) | 부모당 평균 자식 노드 수 | 평균 압축 비율 |
|---|---|---|---|---|
| 전체 데이터셋 | 131 | 85.6 | 6.7 | 0.28 |
| QuALITY | 124.4 | 87.9 | 5.7 | 0.28 |
| NarrativeQA | 129.7 | 85.5 | 6.8 | 0.27 |
| QASPER | 145.9 | 86.2 | 5.7 | 0.35 |
부록 D: 요약 프롬프트
요약 생성을 위해 사용된 프롬프트는 다음과 같은 구조를 가집니다.
시스템 역할: “You are a Summarizing Text Portal” 사용자 지시사항: “Write a summary of the following, including as many key details as possible: {context}:”
부록 E: 환각 현상 분석
RAPTOR 모델 내 요약의 품질과 정확성을 평가하기 위해 생성된 요약에서 발생하는 환각 현상에 대한 분석을 수행했습니다. gpt-3.5-turbo로 생성된 요약을 분석하여 환각의 발생률을 정량화하고, 이러한 부정확성이 상위 노드로 전파되는지 여부를 조사했으며, 질의응답 과제에 미치는 영향을 평가했습니다.
40개의 이야기에서 무작위로 선택된 150개의 노드를 대상으로 환각 현상을 평가했습니다. 각 노드는 수작업으로 주석이 달렸으며, 환각 포함 여부가 판단되었습니다. 분석 결과, 150개의 노드 중 4%(6개 노드)에서 환각이 발견되었습니다. 대부분의 환각은 요약 모델이 요약 중인 텍스트에 없는 정보를 학습 데이터에서 추가하거나, 요약을 생성할 때 정보를 잘못 추론하는 경우에서 발생했습니다.
모든 부모 노드를 검토한 결과, 환각이 상위 계층으로 전파되지 않는다는 것을 확인했습니다. 일반적으로 환각은 경미했으며 텍스트의 주제적 해석에 영향을 미치지 않았습니다. 또한 질의응답 과제의 성능에도 식별 가능한 영향을 미치지 않았습니다. 이는 RAPTOR 아키텍처의 요약 구성 요소에서 환각이 주요한 우려 사항이 아님을 시사합니다.
References
Subscribe via RSS