Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities
by Google DeepMind
Contents
TL;DR
이 연구를 시작하게 된 배경과 동기는 무엇입니까?
인공지능 기술의 급속한 발전과 함께 대규모 언어 모델의 능력을 확장하고 개선하는 것은 현대 AI 연구의 핵심 과제로 자리 잡았습니다. Google의 Gemini 팀은 기존 AI 모델들이 가진 한계를 극복하고, 더욱 복잡하고 다양한 작업을 수행할 수 있는 멀티모달 AI 시스템을 개발하고자 했습니다. 특히 코딩, 추론, 긴 컨텍스트 처리, 멀티모달 이해와 같은 영역에서 기존 모델들의 성능적 제약을 뛰어넘는 것이 주요 연구 동기였습니다.
기존 AI 모델들은 대부분 단일 모달리티에 집중하거나, 긴 컨텍스트를 효과적으로 처리하지 못하는 한계를 보였습니다. 또한 복잡한 추론 작업이나 실제 에이전틱 시스템에서 요구되는 다양한 능력을 종합적으로 제공하지 못했습니다. 이러한 배경에서 Gemini 팀은 네이티브 멀티모달 아키텍처와 고급 추론 능력을 갖춘 새로운 모델 패밀리를 개발하고자 했습니다.
이 연구에서 제시하는 새로운 해결 방법은 무엇입니까?
Gemini 2.5 모델 패밀리는 희소 전문가 혼합(Sparse Mixture-of-Experts) 트랜스포머 아키텍처를 기반으로 하는 혁신적인 접근법을 제시합니다. 이 아키텍처의 핵심은 입력 토큰마다 모델 파라미터의 일부만을 동적으로 활성화하여, 전체 모델 용량을 계산 및 서빙 비용과 분리할 수 있게 하는 것입니다. 특히 Gemini 2.5 Pro와 Flash 모델은 최대 100만 토큰의 긴 컨텍스트를 처리할 수 있으며, 텍스트, 이미지, 비디오, 오디오를 포함한 다양한 모달리티를 네이티브하게 지원합니다.
모델의 또 다른 혁신은 '사고(Thinking)' 기능입니다. 이는 모델이 응답을 생성하기 전에 추가적인 추론 시간을 사용하여 더 정확하고 깊이 있는 답변을 제공할 수 있게 합니다. 이러한 접근법은 코딩, 수학, 추론 작업에서 모델의 성능을 크게 향상시키며, 사용자가 모델의 사고 예산을 조절할 수 있게 해줍니다. 또한 증류(Distillation) 기법을 활용하여 더 작고 효율적인 모델 버전을 개발했습니다.
제안된 방법은 어떻게 구현되었습니까?
Gemini 2.5 모델의 구현은 대규모 TPUv5p 인프라를 활용한 복잡한 훈련 과정을 통해 이루어졌습니다. 훈련 데이터셋은 웹 문서, 코드, 이미지, 오디오, 비디오 등 다양한 소스를 포함하며, 엄격한 데이터 품질 관리와 필터링 과정을 거쳤습니다. 특히 데이터 중복 제거와 안전성 필터링에 중점을 두어 모델의 성능과 신뢰성을 높였습니다.
훈련 과정에서는 지도 미세 조정(Supervised Fine-Tuning), 보상 모델링, 강화 학습 등 다양한 기법을 적용했습니다. 특히 Constitutional AI 접근법을 통해 모델이 자신의 응답을 비판하고 개선할 수 있도록 훈련했으며, 인간 피드백과 모델 기반 평가를 결합하여 모델의 안전성과 유용성을 개선했습니다. 또한 자동화된 레드팀 테스팅을 통해 잠재적 위험과 편향을 지속적으로 평가하고 완화했습니다.
이 연구의 결과가 가지는 의미는 무엇입니까?
Gemini 2.5 모델 패밀리는 AI 시스템의 새로운 가능성을 보여주는 중요한 이정표를 제시합니다. LiveCodeBench에서 코딩 성능이 74.2%로 향상되고, GPQA diamond에서 86.4%의 추론 성능을 달성하는 등 다양한 벤치마크에서 획기적인 성과를 보였습니다. 특히 Gemini Plays Pokémon 프로젝트와 같은 실제 응용 사례를 통해 모델의 장기 추론 및 에이전틱 능력을 입증했습니다.
이 연구는 단순히 기술적 성능 향상을 넘어 AI 시스템의 안전성, 윤리, 신뢰성에 대한 중요한 통찰을 제공합니다. 프론티어 안전 프레임워크를 통해 잠재적 위험을 철저히 평가하고, 다양한 도메인에서 모델의 능력과 한계를 신중하게 탐색했습니다. 이는 향후 AI 연구의 방향성을 제시하며, 더욱 강력하고 신뢰할 수 있는 AI 시스템 개발을 위한 중요한 기반을 마련했습니다.
Gemini 2.5: 첨단 추론, 멀티모달리티, 긴 컨텍스트, 차세대 에이전틱 능력으로 경계를 넓히다
초록
Google의 Gemini 팀이 발표한 Gemini 2.X 모델 패밀리는 인공지능 분야에서 새로운 이정표를 제시합니다. 이 패밀리에는 Gemini 2.5 Pro와 Gemini 2.5 Flash, 그리고 이전에 출시된 Gemini 2.0 Flash와 Flash-Lite 모델들이 포함되어 있습니다.
Gemini 2.5 Pro는 현재까지 가장 뛰어난 성능을 보이는 모델로, 최첨단 코딩 및 추론 벤치마크에서 최고 수준(State-of-the-Art, SoTA)의 성과를 달성했습니다. 이 모델의 가장 주목할 만한 특징은 놀라운 코딩과 추론 능력뿐만 아니라 사고(thinking) 모델로서의 역할입니다. 멀티모달 이해에 탁월하며, 최대 3시간 분량의 비디오 콘텐츠를 처리할 수 있는 능력을 갖추고 있습니다.
이러한 긴 컨텍스트, 멀티모달, 추론 능력의 독특한 조합은 새로운 에이전틱 워크플로우를 가능하게 합니다. Gemini 2.5 Flash는 계산 및 지연 시간 요구사항을 크게 줄이면서도 뛰어난 추론 능력을 제공하며, Gemini 2.0 Flash와 Flash-Lite는 낮은 지연 시간과 비용으로 높은 성능을 제공합니다.
전체적으로 Gemini 2.X 모델 세대는 모델 능력 대비 비용의 전체 파레토 프론티어를 아우르며, 사용자들이 복잡한 에이전틱 문제 해결의 경계를 탐색할 수 있게 합니다.
서론
Gemini 2.X 패밀리는 사고를 통한 고급 추론, 긴 컨텍스트, 도구 사용 능력을 갖춘 차세대 네이티브 멀티모달 모델들을 선보입니다. 이 패밀리에는 Gemini 2.5 Pro와 2.5 Flash, 그리고 이전에 출시된 Gemini 2.0 Flash와 Gemini 2.0 Flash-Lite 모델들이 포함되어 있습니다.
이들 모델은 함께 차세대 에이전틱 시스템을 구동하도록 설계된 새로운 고성능 모델 패밀리를 구성합니다. Gemini 1.5 시리즈의 기반 위에 구축된 이 Gemini 2.X 세대는 범용 AI 어시스턴트라는 비전에 한 걸음 더 가까이 다가갑니다.
네이티브 멀티모달 아키텍처와 긴 컨텍스트 지원
Gemini 2.X 시리즈의 모든 모델은 네이티브 멀티모달로 구축되어 100만 토큰 이상의 긴 컨텍스트 입력을 지원하며 네이티브 도구 사용 기능을 갖추고 있습니다. 이러한 광범위한 능력을 통해 텍스트, 오디오, 이미지, 비디오, 심지어 전체 코드 저장소를 포함한 다양한 정보 소스의 방대한 데이터셋을 이해하고 복잡한 문제를 처리할 수 있습니다.
이러한 광범위한 능력들은 복잡한 에이전틱 시스템을 구축하는 데에도 결합될 수 있습니다. 이는 Gemini Plays Pokémon 프로젝트에서 실제로 구현된 바 있습니다.
모델별 특화 능력
Gemini 2.X 패밀리의 각 모델은 서로 다른 강점과 능력을 가지고 있습니다.
Gemini 2.5 Pro는 가장 지능적인 사고 모델로, 강력한 추론과 코드 능력을 보여줍니다. 대화형 웹 애플리케이션 제작에 탁월하며, 코드베이스 수준의 이해가 가능하고 창발적인 멀티모달 코딩 능력을 보입니다.
Gemini 2.5 Flash는 제어 가능한 사고 예산을 가진 하이브리드 추론 모델로, 품질, 비용, 지연 시간 간의 트레이드오프를 제어하면서 대부분의 복잡한 작업에 유용합니다.
Gemini 2.0 Flash는 일상적인 작업을 위한 빠르고 비용 효율적인 비사고 모델이며, Gemini 2.0 Flash-Lite는 대규모 사용을 위해 구축된 가장 빠르고 비용 효율적인 모델입니다.
| 모델 | Gemini 1.5 Flash | Gemini 1.5 Pro | Gemini 2.0 Flash-Lite | Gemini 2.0 Flash | Gemini 2.5 Flash | Gemini 2.5 Pro |
|---|---|---|---|---|---|---|
| 입력 모달리티 | 텍스트, 이미지, 비디오, 오디오 | 텍스트, 이미지, 비디오, 오디오 | 텍스트, 이미지, 비디오, 오디오 | 텍스트, 이미지, 비디오, 오디오 | 텍스트, 이미지, 비디오, 오디오 | 텍스트, 이미지, 비디오, 오디오 |
| 입력 길이 | 1M | 2M | 1M | 1M | 1M | 1M |
| 출력 모달리티 | 텍스트 | 텍스트 | 텍스트 | 텍스트, 이미지* | 텍스트, 오디오* | 텍스트, 오디오* |
| 출력 길이 | 8K | 8K | 8K | 8K | 64K | 64K |
| 사고 기능 | 없음 | 없음 | 없음 | 예* | 동적 | 동적 |
| 도구 사용 지원 | 없음 | 없음 | 없음 | 예 | 예 | 예 |
| 지식 컷오프 | 2023년 11월 | 2023년 11월 | 2024년 6월 | 2024년 6월 | 2025년 1월 | 2025년 1월 |
*현재 실험적 또는 프리뷰 단계로 제한됨
파레토 프론티어의 확장
Gemini 2.X 모델 패밀리는 모델 능력 대비 비용의 전체 파레토 프론티어를 커버하며, 다양한 핵심 능력, 애플리케이션, 사용 사례에서 이를 전진시킵니다. Gemini 2.5 패밀리의 모델들은 견고한 안전성 지표를 유지하면서 2.0 및 1.5 버전 대비 유용성과 전반적인 톤에서 극적으로 개선되었습니다.
실제로 이는 2.5 모델들이 중요한 사용 사례를 방해하거나 최종 사용자에게 설교하지 않으면서 안전한 응답을 제공하는 데 상당히 더 뛰어나다는 것을 의미합니다.
안전성 평가와 중요 능력
Gemini 2.5 Pro의 중요 능력(Critical Capabilities)도 평가되었으며, 여기에는 CBRN(화학, 생물학, 방사능, 핵), 사이버보안, 머신러닝 R&D, 기만적 정렬이 포함됩니다. Gemini 2.5 Pro는 이전 Gemini 모델들과 비교하여 일부 능력에서 상당한 증가를 보였지만, 어떤 영역에서도 중요 능력 수준(Critical Capability Levels)에 도달하지는 않았습니다.
보고서 구조
이 보고서는 Gemini 1.5 모델 출시 이후 모델 아키텍처, 훈련, 서빙에서 이루어진 발전을 간략히 설명하는 것으로 시작합니다. 이어서 정성적 능력 시연을 포함한 Gemini 2.5 모델들의 성능을 보여주고, 이 모델 시리즈의 안전성 평가와 함의에 대한 논의로 마무리합니다.
이러한 종합적인 접근 방식을 통해 Gemini 2.X 패밀리는 차세대 AI 시스템의 새로운 표준을 제시하며, 복잡한 추론, 멀티모달 이해, 긴 컨텍스트 처리, 그리고 에이전틱 능력의 경계를 확장하고 있습니다.
모델 아키텍처, 훈련 및 데이터셋
모델 아키텍처
Gemini 2.5 모델들은 텍스트, 비전, 오디오 입력에 대한 네이티브 멀티모달 지원을 갖춘 희소 전문가 혼합(sparse mixture-of-experts, MoE) 트랜스포머 아키텍처를 기반으로 구축되었습니다. 희소 MoE 모델의 핵심 아이디어는 입력 토큰마다 모델 파라미터의 일부만을 활성화하여 토큰을 파라미터의 부분집합(전문가)으로 동적으로 라우팅하는 것을 학습한다는 점입니다. 이러한 접근법은 전체 모델 용량을 토큰당 계산 및 서빙 비용으로부터 분리할 수 있게 해줍니다.
희소 전문가 혼합 아키텍처의 작동 원리
희소 MoE 아키텍처를 이해하기 위해 먼저 기본 개념을 살펴보겠습니다. 전통적인 트랜스포머에서는 모든 입력 토큰이 동일한 피드포워드 네트워크를 통과합니다. 반면 MoE 모델에서는 여러 개의 "전문가" 네트워크가 존재하며, 각 토큰은 게이팅 네트워크의 결정에 따라 특정 전문가들로만 라우팅됩니다.
Switch Transformer에서 제안된 바와 같이, 게이팅 네트워크는 입력 토큰 \(x\)에 대해 다음과 같이 확률 분포를 계산합니다.
\[p_i(x) = \frac{e^{h(x)_i}}{\sum_{j}^{N}e^{h(x)_j}}\]여기서 \(h(x) = W_r \cdot x\)이고, \(W_r\)은 라우터 가중치입니다. 최종 출력은 선택된 전문가들의 가중 조합으로 계산됩니다.
\[y = \sum_{i \in \mathcal{T}} p_i(x) E_i(x)\]여기서 \(\mathcal{T}\)는 상위 k개 전문가의 인덱스이고, \(E_i(x)\)는 i번째 전문가의 출력입니다.
Gemini 2.5의 아키텍처 개선사항
Gemini 2.5 모델 시리즈는 이전 Gemini 모델들과 비교하여 모델 아키텍처의 발전을 통해 성능이 크게 향상되었습니다. 특히 대규모 트랜스포머와 희소 MoE 모델들이 겪는 훈련 불안정성 문제를 해결하는 데 상당한 진전을 이루었습니다.
대규모 트랜스포머 모델들은 훈련 과정에서 다양한 불안정성 문제에 직면합니다. 이는 그래디언트 폭발이나 소실, 수치적 불안정성, 그리고 희소 라우팅으로 인한 추가적인 복잡성 때문입니다. Gemini 2.5는 이러한 문제들을 해결하기 위해 대규모 훈련 안정성, 신호 전파, 최적화 역학을 크게 개선했습니다.
이러한 개선사항들은 사전 훈련 직후의 성능을 이전 Gemini 모델들과 비교하여 상당히 향상시켰습니다. 특히 신호 전파의 개선은 깊은 네트워크에서 정보가 효과적으로 전달되도록 하여 학습 효율성을 높였습니다.
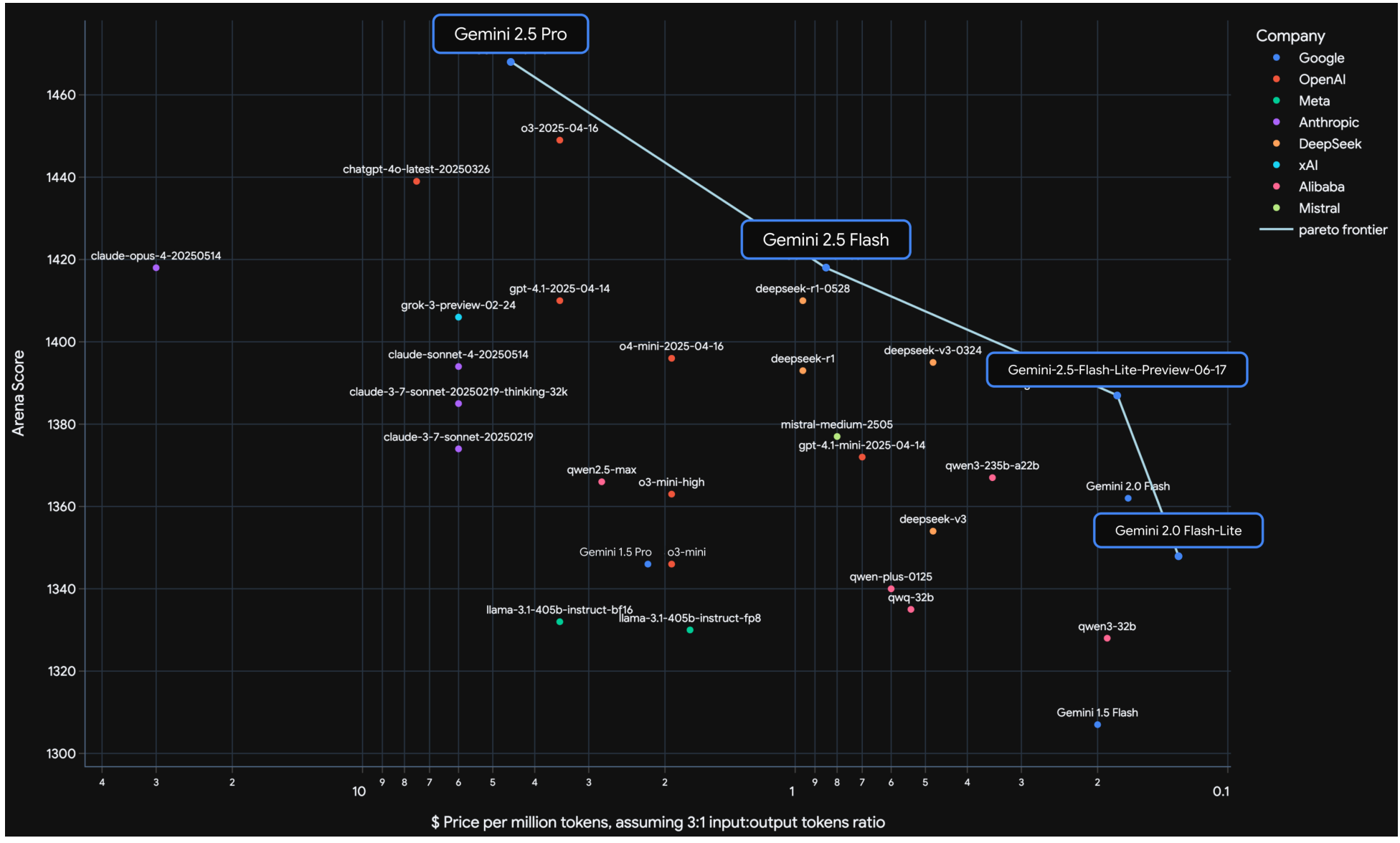
위 그림은 다양한 모델들의 비용 대비 성능을 보여주는 산점도입니다. Gemini 2.5 Pro는 Gemini 1.5 Pro에 비해 현저한 개선을 보여주며, LMArena 점수에서 120점 이상 높은 성과를 달성했습니다. 비용은 백만 토큰당 입력 및 출력 토큰 가격의 가중 평균으로 계산되었습니다.
긴 컨텍스트 처리 능력의 발전
Gemini 2.5 모델들은 Gemini 1.5의 긴 컨텍스트 쿼리 처리 성공을 기반으로 구축되었으며, 새로운 모델링 발전을 통합하여 Gemini 2.5 Pro가 최대 1M 토큰의 긴 컨텍스트 입력 시퀀스 처리에서 Gemini 1.5 Pro의 성능을 능가할 수 있게 했습니다.
이러한 긴 컨텍스트 능력은 실제로 매우 인상적인 수준입니다. Gemini 2.5 Pro와 Gemini 2.5 Flash 모두 "모비딕"이나 "돈키호테" 전체와 같은 긴 형태의 텍스트, 전체 코드베이스, 그리고 긴 형태의 오디오 및 비디오 데이터를 처리할 수 있습니다.
비전 처리 능력의 향상
긴 컨텍스트 능력의 발전과 함께, Gemini 2.5의 아키텍처 변경사항들은 이미지 및 비디오 이해 능력에서 상당한 개선을 가져왔습니다. 특히 3시간 길이의 비디오를 처리할 수 있는 능력과 시연 비디오를 대화형 코딩 애플리케이션으로 변환할 수 있는 능력을 갖추게 되었습니다.
증류를 통한 효율적인 모델 개발
Gemini 2.5 시리즈의 작은 모델들(Flash 크기 이하)은 Gemini 1.5 시리즈에서와 같이 증류(distillation) 기법을 사용합니다. 증류는 큰 교사 모델의 지식을 작은 학생 모델로 전달하는 효과적인 방법입니다.
증류 과정에서 핵심적인 혁신은 교사의 다음 토큰 예측 분포를 저장하는 비용을 줄이기 위해 어휘에 대한 k-희소 분포를 사용하여 이를 근사하는 것입니다. 이는 여전히 훈련 데이터 처리량과 저장 요구사항을 k배만큼 증가시키지만, 증류가 작은 모델들에 가져다주는 상당한 품질 개선을 고려할 때 가치 있는 트레이드오프입니다.
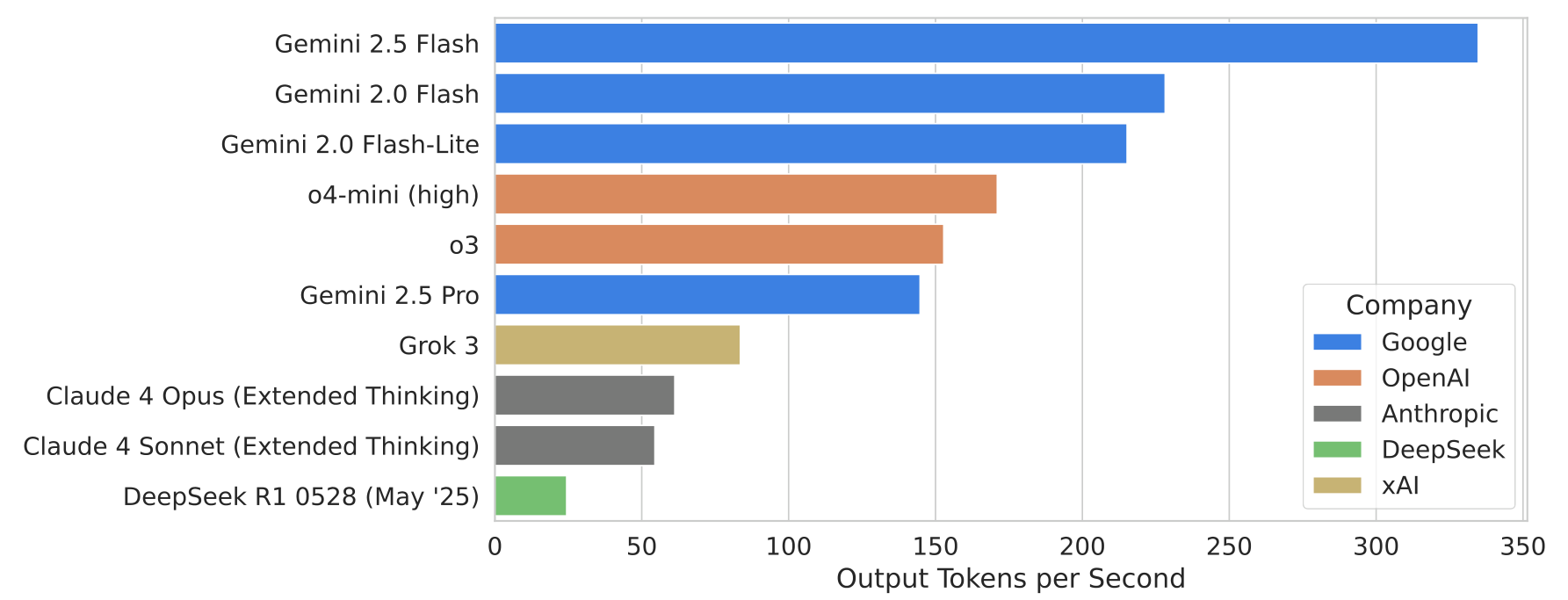
위 그래프는 다양한 모델들의 초당 출력 토큰 생성 수를 보여줍니다. 이는 API에서 첫 번째 청크를 받은 후의 성능을 측정한 것으로, Gemini 2.5 Flash가 높은 처리 속도를 보여주는 것을 확인할 수 있습니다. 이러한 높은 처리 속도는 증류를 통해 달성된 효율성의 결과로, 서빙 비용을 줄이면서도 고품질 모델을 제공할 수 있게 합니다.
증류 기법의 수학적 기초를 살펴보면, 학생 모델은 교사 모델의 "소프트 타겟"을 학습합니다. 높은 온도 \(T\)에서의 소프트맥스 출력을 사용하여:
\[q_i = \frac{e^{z_i/T}}{\sum_j e^{z_j/T}}\]여기서 \(z_i\)는 학생 모델의 로짓이고, 교사 모델의 소프트 타겟 \(p_i\)와의 교차 엔트로피를 최소화합니다. 이러한 접근법은 단순히 하드 레이블을 학습하는 것보다 더 풍부한 정보를 제공하여 학생 모델의 성능을 크게 향상시킵니다.
데이터셋
Gemini 2.5의 사전 훈련 데이터셋은 광범위한 도메인과 모달리티를 포괄하는 대규모의 다양한 데이터 컬렉션입니다. 이 데이터셋에는 공개적으로 이용 가능한 웹 문서, 다양한 프로그래밍 언어의 코드, 이미지, 오디오(음성 및 기타 오디오 유형 포함), 비디오가 포함되어 있으며, 2.0 버전의 경우 2024년 6월, 2.5 버전의 경우 2025년 1월을 컷오프 날짜로 합니다.
데이터 품질 개선
Gemini 1.5 사전 훈련 데이터셋과 비교하여, 필터링과 중복 제거 모두에서 향상된 데이터 품질을 위한 새로운 방법들을 활용했습니다. 이러한 개선사항들은 모델의 성능 향상에 중요한 역할을 했습니다.
데이터 필터링 과정에서는 품질이 낮거나 부적절한 콘텐츠를 제거하기 위한 정교한 알고리즘이 사용되었습니다. 중복 제거 과정에서는 유사하거나 동일한 콘텐츠를 식별하고 제거하여 데이터셋의 다양성을 보장했습니다.
후훈련 데이터셋
후훈련 데이터셋은 Gemini 1.5와 마찬가지로 신중하게 수집되고 검증된 지시 튜닝 데이터로 구성됩니다. 이는 지시와 응답이 쌍을 이루는 멀티모달 데이터의 컬렉션이며, 인간 선호도 및 도구 사용 데이터도 추가로 포함됩니다.
지시 튜닝 데이터는 모델이 사용자의 다양한 요청을 이해하고 적절하게 응답할 수 있도록 훈련시키는 데 사용됩니다. 인간 선호도 데이터는 모델의 출력이 인간의 기대와 일치하도록 하는 데 중요한 역할을 하며, 도구 사용 데이터는 모델이 외부 도구와 효과적으로 상호작용할 수 있게 합니다.
훈련 인프라
이 모델 패밀리는 TPUv5p 아키텍처에서 훈련된 최초의 모델입니다. 여러 데이터센터에 분산된 Google의 TPUv5p 가속기의 여러 8960-칩 포드에 걸쳐 동기식 데이터 병렬 훈련을 사용했습니다.
주요 인프라 개선사항
Gemini 1.5와 비교하여 소프트웨어 사전 훈련 인프라의 주요 발전은 탄력성과 SDC(Silent Data Corruption) 오류 완화와 관련이 있습니다.
슬라이스 단위 탄력성
시스템은 이제 국소적 장애가 발생했을 때 더 적은 수의 TPU 칩 "슬라이스"로 훈련을 자동으로 계속합니다. 이러한 재구성은 중단당 수십 초의 훈련 시간 손실만을 발생시키며, 이는 탄력성 없이 건강한 머신이 재스케줄링되기를 기다리는 10분 이상의 지연과 비교됩니다. 시스템은 실패한 슬라이스가 복구되는 동안 약 97%의 처리량으로 훈련을 계속합니다.
이 훈련 실행 규모에서는 시간당 여러 번의 하드웨어 장애로 인한 중단이 발생하지만, 내결함성 메커니즘은 훨씬 더 큰 규모에서 예상되는 더 높은 장애율을 견딜 수 있도록 설계되었습니다.
분할 단계 SDC 탐지
이전의 대규모 실행에서는 SDC 오류가 있는 머신을 탐지하고 위치를 파악하는 데 몇 시간이 걸릴 수 있었으며, 디버깅 중 다운타임과 잠재적으로 손상된 많은 훈련 단계의 롤백/재실행이 필요했습니다. 이제는 경량 결정론적 재실행을 사용하여 의심스러운 메트릭이 있는 단계를 즉시 반복하고, 디바이스별 중간 체크섬을 비교하여 데이터 손상의 근본 원인을 찾습니다.
경험적으로, 간헐적 SDC를 보이기 시작하는 가속기는 몇 분 내에 식별되어 작업에서 빠르게 제외됩니다. 이 실행 중에 약 0.25%의 단계가 SDC 의심으로 인해 재실행되었고, 이러한 재실행 중 6%가 실제 하드웨어 손상으로 판명되었습니다.
Pathways 시스템의 장점
위의 두 기법 모두 Pathways 시스템의 단일 컨트롤러 설계 덕분에 상대적으로 구현하기 쉬웠습니다. 이 시스템은 모든 가속기를 시스템 상태에 대한 전역적 관점을 가진 단일 파이썬 프로그램에서 조정할 수 있게 해줍니다.
컨트롤러는 TPU 워커에서 병렬 '원격 파이썬' 작업을 사용하여 훈련 메트릭을 모니터링하고, 성능 지연자를 추적하며, SDC 오류의 근본 원인을 파악할 수 있습니다.
전체 훈련 효율성
전체 실행 중에 93.4%의 시간이 TPU 계산을 수행하는 데 사용되었습니다. 나머지 시간은 대략 절반은 탄력적 재구성에, 절반은 탄력성이 실패한 드문 꼬리 사례에 사용되었습니다. 계산된 단계의 약 4.5%는 모델 디버깅 개입을 위한 재실행 또는 롤백이었습니다.
이러한 높은 효율성은 대규모 분산 훈련에서 매우 인상적인 수치로, 시스템의 안정성과 효율성을 보여줍니다.
후훈련
Gemini 1.5의 초기 발표 이후, 지도 미세 조정(Supervised Fine-Tuning, SFT), 보상 모델링(Reward Modeling, RM), 강화 학습(Reinforcement Learning, RL) 단계 전반에 걸친 데이터 품질에 대한 지속적인 집중에 의해 후훈련 방법론에서 상당한 발전이 이루어졌습니다.
모델 자체를 활용한 품질 관리
핵심적인 초점은 모델 자체를 이러한 과정들을 지원하는 데 활용하여 더 효율적이고 미묘한 품질 관리를 가능하게 하는 것이었습니다. 이는 모델이 자신의 출력을 평가하고 개선하는 데 참여할 수 있게 하는 혁신적인 접근법입니다.
강화 학습의 확장
RL에 할당된 훈련 계산을 증가시켜 더 깊은 탐색과 모델 행동의 정제를 가능하게 했습니다. 이는 검증 가능한 보상과 모델 기반 생성 보상에 대한 집중과 결합되어 더 정교하고 확장 가능한 피드백 신호를 제공했습니다.
RL 과정에 대한 알고리즘적 변경사항들도 더 긴 훈련 동안의 안정성을 개선했습니다. 이러한 발전은 Gemini 2.5가 다단계 행동과 도구 사용을 요구하는 것들을 포함하여 더 다양하고 복잡한 RL 환경에서 학습할 수 있게 했습니다.
성능 향상 결과
데이터 품질, 증가된 계산, 알고리즘적 개선, 확장된 능력의 이러한 개선사항들의 조합은 전반적인 성능 향상에 기여했습니다. 이는 모델의 LMArena Elo 점수의 상당한 증가에 현저하게 반영되었으며, Gemini 2.5 Flash와 Pro 모두 Gemini 1.5 대응 모델들보다 110점 이상 향상되었습니다(Gemini 2.5 Pro는 122점, Gemini 2.5 Flash는 111점 향상).
사고(Thinking)
이전 Gemini 모델들은 사용자 쿼리 직후 즉시 답변을 생성했습니다. 이는 모델이 문제에 대해 추론하는 데 사용할 수 있는 추론 시간 계산(Thinking)의 양을 제한했습니다.
Gemini Thinking 모델의 개발
Gemini Thinking 모델들은 추론 시간에 추가 계산을 사용하여 더 정확한 답변에 도달하도록 강화 학습으로 훈련되었습니다. 결과적으로 생성된 모델들은 질문이나 쿼리에 응답하기 전에 "사고" 단계에서 수만 번의 순방향 패스를 소비할 수 있습니다.
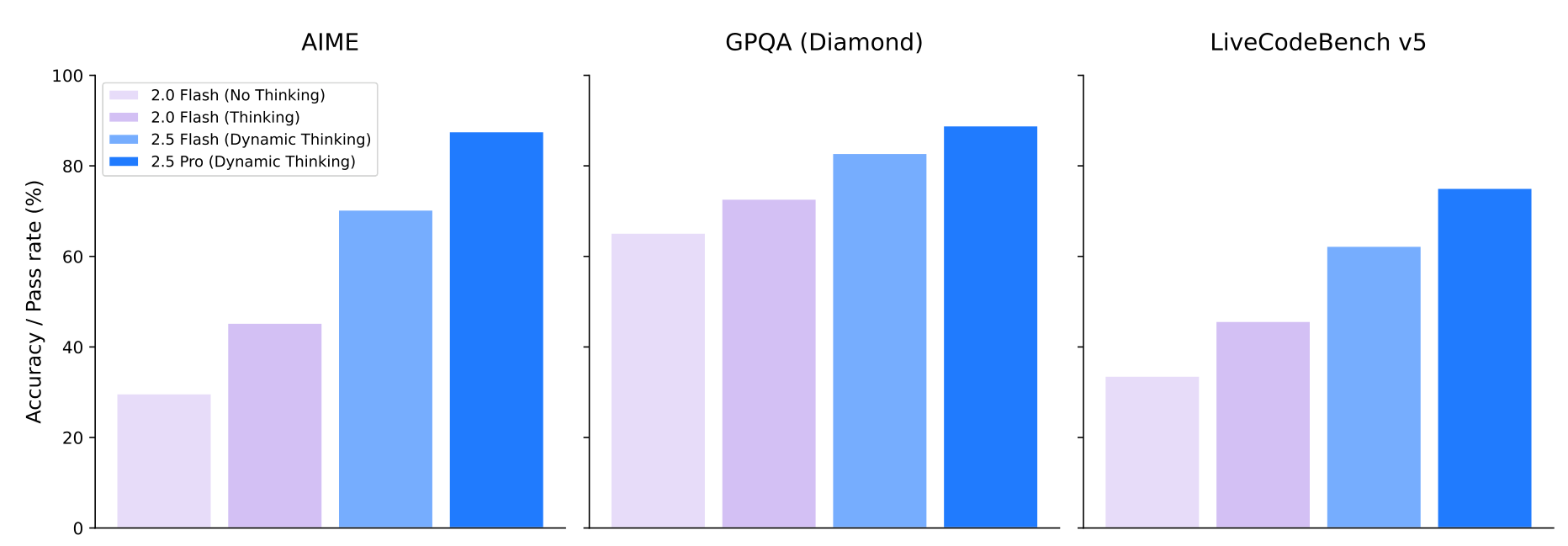
위 그래프는 AIME 2025, LiveCodeBench, GPQA diamond 벤치마크에서 "Thinking" 기능이 Gemini의 성능에 미치는 영향을 보여줍니다. 사고 기능을 사용하지 않는 2.0 Flash 모델과 비교하여, 사고 기능을 사용하는 모델들이 모든 벤치마크에서 상당한 성능 향상을 보여주는 것을 확인할 수 있습니다.
훈련 레시피의 진화
훈련 레시피는 원래의 실험적 사고 모델인 Gemini 2.0 Flash Thinking(2024년 12월 출시)에서 모든 도메인에 걸쳐 네이티브하게 Thinking을 통합한 Gemini 2.5 Thinking 시리즈로 진화했습니다.
결과는 전반적으로 더 강한 추론 성능을 달성할 수 있는 단일 모델이며, 추론 시간의 함수로서 성능을 더욱 확장할 수 있습니다.
멀티모달 통합과 사고 예산
Thinking을 네이티브 멀티모달 입력(이미지, 텍스트, 비디오, 오디오)과 긴 컨텍스트(1M+ 토큰)를 포함한 다른 Gemini 능력들과 통합했습니다. 이러한 능력들 중 어느 것에 대해서도 모델은 답변을 제공하기 전에 얼마나 오래 생각할지를 스스로 결정합니다.
또한 사고 예산을 설정할 수 있는 능력을 제공하여 모델이 원하는 토큰 수 내에서 응답하도록 제한할 수 있습니다. 이를 통해 사용자는 성능과 비용 간의 트레이드오프를 조절할 수 있습니다.
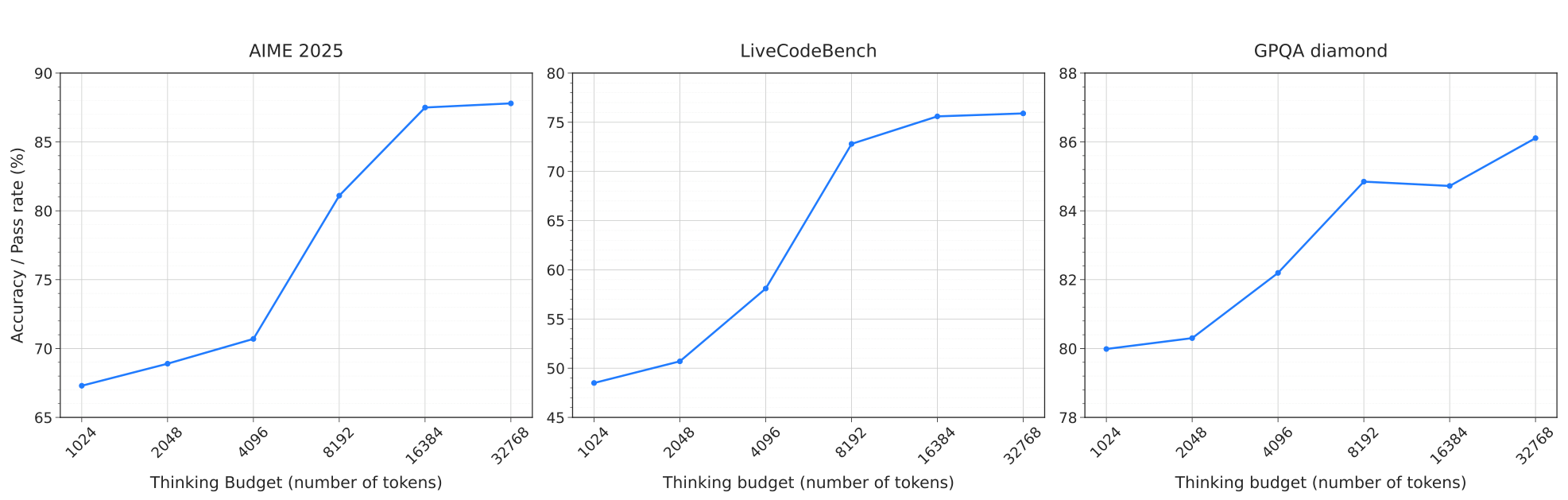
위 그래프들은 사고 예산(토큰 수)이 AIME 2025, LiveCodeBench, GPQA diamond 벤치마크에서의 성능에 미치는 영향을 보여줍니다. 사고 예산을 증가시킬수록 모델이 성능을 확장하고 상당히 높은 정확도를 달성할 수 있음을 보여줍니다.
특히 주목할 점은 사고 예산이 증가함에 따라 모든 벤치마크에서 일관된 성능 향상이 나타난다는 것입니다. 이는 추가적인 추론 시간 계산이 실제로 문제 해결 능력을 향상시킨다는 것을 실증적으로 보여줍니다.
능력별 특화 개선사항
Gemini 1.5 이후 훈련 아키텍처와 레시피에 대한 대부분의 변경사항들이 모든 능력에서 개선을 가져왔지만, 일부 능력별 특화된 성과도 달성했습니다. 이제 코드, 사실성, 긴 컨텍스트, 다국어 지원, 오디오, 비디오, 그리고 에이전틱 사용 사례(특히 Gemini Deep Research에 중점을 둔)에 대해 논의하겠습니다.
코드 생성 능력의 혁신적 발전
Gemini 2.0과 2.5는 실질적인 실세계 가치를 제공하고, 사용자가 오늘날의 복잡한 멀티모달 소프트웨어 환경에서 실용적인 과제를 해결하고 개발 목표를 달성할 수 있도록 지원하는 방향으로 개발 우선순위를 전략적으로 전환했습니다.
이를 실현하기 위해 Gemini 1.5 이후 사전 훈련과 후훈련 단계 모두에서 집중적인 노력이 이루어졌습니다. 사전 훈련에서는 저장소와 웹 소스 모두에서 더 많은 양과 다양성을 가진 코드 데이터를 훈련 혼합에 통합하는 데 집중했습니다. 이는 커버리지를 빠르게 확장하고 더 계산 효율적인 모델의 개발을 가능하게 했습니다.
또한 하위 사용 사례와 일치하는 코드 능력을 평가하기 위한 평가 메트릭 스위트를 대폭 강화하고, 모델 성능을 정확하게 예측하는 능력을 개선했습니다.
후훈련 과정에서는 추론 능력을 통합한 새로운 훈련 기법을 개발하고 다양한 엔지니어링 작업을 큐레이션하여 현대 엔지니어링 과제를 해결하는 데 중요한 효과적인 문제 해결 기술을 Gemini에 장착하는 것을 목표로 했습니다.
이러한 발전을 보여주는 주요 애플리케이션에는 IDE 기능, 전체 저장소 내에서 복잡한 다단계 작업을 위한 코드 에이전트 사용 사례, 그리고 엔드투엔드 웹 및 모바일 애플리케이션 개발과 같은 멀티모달 대화형 시나리오가 포함됩니다.
이러한 노력들은 종합적으로 Gemini의 코딩 능력에서 광범위하고 상당한 개선을 가져왔습니다. 이러한 진전은 확립된 벤치마크에서의 우수한 성능으로 입증됩니다. LiveCodeBench에서의 성능은 Gemini 1.5 Pro의 30.5%에서 Gemini 2.5 Pro의 74.2%로 향상되었고, Aider Polyglot에서는 16.9%에서 82.2%로 개선되었습니다. SWEBench-verified에서의 성능은 34.2%에서 67.2%로 향상되었습니다.
더 나아가 Gemini 2.5 Pro는 LMArena WebDev Arena에서 Gemini 1.5 Pro보다 500 Elo 이상의 증가를 달성하여 UI 및 웹 애플리케이션 개발, 정교한 에이전틱 워크플로우 생성을 포함한 실용적인 애플리케이션에서 의미 있는 향상을 가져왔습니다.
사실성 향상을 위한 종합적 접근
생성 모델의 맥락에서 정보 탐색 프롬프트에 대한 모델 응답의 사실성을 보장하는 것은 Gemini 모델 개발의 핵심 기둥으로 남아있습니다. Gemini 1.5에서는 모델의 세계 지식과 프롬프트 내에서 제공된 컨텍스트에 충실하게 근거한 답변을 제공하는 능력을 향상시키는 데 연구가 집중되었습니다.
이러한 노력은 2024년 12월 FACTS Grounding 출시로 절정에 달했으며, 이는 현재 사용자가 제공한 문서에 근거한 응답을 생성하는 LLM의 능력을 평가하는 업계 표준 벤치마크가 되었습니다.
Gemini 2.0과 2.5에서는 멀티모달 입력, 긴 컨텍스트 추론, 모델이 검색한 정보를 다루기 위해 범위를 크게 확장했습니다. 동시에 사실성에 대한 환경과 사용자 기대는 Google의 AI Overviews와 AI Mode 배포에 의해 부분적으로 형성되어 극적으로 진화했습니다.
이러한 요구를 충족하기 위해 Gemini 2.0은 Google Search와 같은 도구를 네이티브하게 호출하도록 훈련된 첫 번째 모델 패밀리로서 중요한 도약을 표시했으며, 정확한 쿼리를 공식화하고 소스와 함께 새로운 정보를 합성할 수 있게 했습니다.
이를 기반으로 Gemini 2.5는 고급 추론을 통합하여 이러한 검색 능력을 내부 사고 과정과 교차시켜 복잡한 다단계 쿼리에 답하고 장기간 작업을 실행할 수 있게 했습니다. 모델은 검색 및 기타 도구를 사용하고, 출력에 대해 추론하며, 추가적이고 상세한 후속 쿼리를 발행하여 사용 가능한 정보를 확장하고 응답의 사실적 정확성을 검증하는 방법을 학습했습니다.
최신 모델들은 현재 Google의 AI Overviews에서 월 1.5억 명의 활성 사용자와 Gemini 앱에서 4억 명의 사용자 경험을 지원하고 있습니다. 이러한 모델들은 매개변수 지식을 위한 SimpleQA, 제공된 문서에 대한 충실성을 위한 FACTS Grounding, Vectara Hallucination Leaderboard를 포함한 사실성 벤치마크 스위트에서 최첨단 성능을 보여주며, Gemini를 정보 탐색 요구를 위한 선택 모델로 확고히 했습니다.
긴 컨텍스트 처리의 질적 향상
모델링과 데이터 발전은 100만 길이 컨텍스트 윈도우를 활용하는 쿼리에 대한 모델 응답의 품질을 개선하는 데 도움이 되었으며, 모델링 연구를 안내하는 데 도움이 되도록 내부 평가를 더 도전적이 되도록 재작업했습니다.
성능 향상을 위해 도전적인 검색 작업(LOFT와 같은), 긴 컨텍스트 추론 작업(MRCR-V2와 같은), 멀티모달 작업(VideoMME와 같은)을 목표로 했습니다. 결과에 따르면 새로운 2.5 모델들은 이전 Gemini 1.5 모델들에 비해 크게 개선되었으며 이 모든 작업에서 최첨단 품질을 달성했습니다.
이러한 개선된 비디오 회상 능력을 보여주는 예는 부록에서 볼 수 있으며, Gemini 2.5 Pro가 전체 46분 비디오에서 1초 시각적 이벤트를 일관되게 회상할 수 있음을 보여줍니다.
다국어 능력의 전면적 진화
Gemini의 다국어 능력은 이미 사전 훈련을 통해 400개 이상의 언어를 포괄했던 1.5 이후 심오한 진화를 겪었습니다. 이러한 변화는 사전 및 후훈련 데이터 품질을 세심하게 정제하고, 토큰화 기법을 발전시키며, 핵심 모델링을 혁신하고, 목표 능력 향상을 실행하는 전체적인 전략에서 비롯됩니다.
그 영향은 특히 인도어와 중국어, 일본어, 한국어에서 두드러지며, 데이터 품질과 평가에서의 전용 최적화가 품질과 디코딩 속도 모두에서 극적인 향상을 가져왔습니다. 결과적으로 사용자들은 상당히 향상된 언어 준수, 요청된 출력 언어를 충실하게 존중하도록 설계된 응답, 그리고 언어 전반에 걸친 생성 품질과 사실성의 견고한 개선의 혜택을 받으며, 다양한 언어적 맥락에서 Gemini의 신뢰성을 확고히 했습니다.
오디오 능력의 확장과 생성 기능
Gemini 1.5가 전사, 번역, 요약, 질의응답과 같은 네이티브 오디오 이해 작업에 집중했던 반면, 이해에 더해 Gemini 2.5는 텍스트-음성 변환이나 네이티브 오디오-비주얼에서 오디오 출력 대화와 같은 오디오 생성 작업을 수행하도록 훈련되었습니다.
저지연 스트리밍 대화를 가능하게 하기 위해 Gemini 2.5로의 오디오 스트리밍과 Gemini 2.5에서의 오디오 스트리밍도 허용하는 인과적 오디오 표현을 통합했습니다. 이러한 능력들은 200개 이상의 언어에 걸친 증가된 사전 훈련 데이터와 개선된 후훈련 레시피의 개발에서 파생됩니다.
마지막으로, 개선된 후훈련 레시피를 통해 사고, 정서적 대화, 맥락적 인식, 도구 사용과 같은 고급 능력을 Gemini의 네이티브 오디오 모델에 통합했습니다.
비디오 이해의 혁신적 발전
사전 훈련과 후훈련 비디오 이해 데이터를 크게 확장하여 모델의 오디오-비주얼 및 시간적 이해 능력을 개선했습니다. 또한 모델들이 프레임당 258개 대신 66개의 시각적 토큰으로 경쟁력 있게 수행하도록 훈련하여 1M 토큰 컨텍스트 윈도우 내에서 1시간 대신 약 3시간의 비디오를 사용할 수 있게 했습니다.
이러한 변화의 결과로 이전에는 불가능했지만 이제 가능해진 두 가지 새로운 애플리케이션은 비디오에서 대화형 앱 만들기(학생들의 비디오 내용 이해를 테스트하는 퀴즈와 같은)와 비디오의 핵심 개념을 보여주는 p5.js 애니메이션 만들기입니다.
에이전트로서의 Gemini: Deep Research
Gemini Deep Research는 가장 틈새 사용자 쿼리에도 전략적으로 웹을 탐색하고 정보에 입각한 답변을 제공하도록 설계된 Gemini 2.5 Pro 모델 위에 구축된 에이전트입니다. 이 에이전트는 작업 우선순위를 수행하도록 최적화되었으며, 탐색 중 막다른 길에 도달했을 때를 식별할 수도 있습니다.
2024년 12월 초기 출시 이후 Gemini Deep Research의 능력을 대폭 개선했습니다. 이에 대한 증거로, Humanity's Last Exam 벤치마크에서 Gemini Deep Research의 성능은 2024년 12월 7.95%에서 2025년 6월 최첨단 점수인 26.9%와 더 높은 계산으로 32.4%로 향상되었습니다.
Gemini 2.5로의 경로
Gemini 2.5 Pro로 가는 길에서 훈련 레시피를 실험하고 이러한 실험적 모델들 중 소수를 사용자와 테스트했습니다. 이미 Gemini 2.0 Flash Thinking에 대해 논의했습니다. 이제 다른 모델들 중 일부를 간략히 논의하겠습니다.
Gemini 2.0 Pro
2025년 2월, Gemini 2.0 Pro의 실험적 버전을 출시했습니다. 당시 이는 Gemini 모델 패밀리에서 가장 강력한 코딩 성능과 최고의 이해력 및 세계 지식을 가지고 있었습니다. 또한 200만 토큰이라는 가장 큰 컨텍스트 윈도우를 제공하여 방대한 양의 정보를 포괄적으로 분석하고 이해할 수 있게 했습니다.
Gemini 2.0 Flash 네이티브 이미지 생성 모델
2025년 3월, Gemini 2.0 Flash 네이티브 이미지 생성의 실험적 버전을 출시했습니다. 이는 Gemini 모델과 이미지 생성 능력 간의 강력한 통합의 결과로 사용자에게 새로운 능력을 가져다주었으며, 자연어 프롬프팅을 통한 이미지 생성 및 이미지 편집과 관련된 새로운 경험을 가능하게 했습니다.
다단계 대화형 편집이나 교차된 텍스트-이미지 생성과 같은 능력들은 이러한 설정에서 매우 자연스러우며, 다국어 커버리지와 관련된 수평적 전이는 즉시 이러한 경험이 Gemini 모델이 지원하는 모든 언어에서 일어날 수 있게 했습니다.
네이티브 이미지 생성은 Gemini를 멀티모달 창작 파트너로 변화시키고 Gemini가 텍스트와 이미지 모두를 통해 아이디어를 표현하고 둘 사이를 원활하게 이동할 수 있게 합니다.
Gemini 2.5 오디오 생성
Gemini 2.5와 함께 제어 가능한 TTS와 네이티브 오디오 대화 능력이 AI Studio에서 별도 옵션으로 제공됩니다(각각 Generate Media와 Stream 섹션). Gemini 2.5 Preview TTS Pro와 Flash 모델들은 스타일, 감정, 속도 등을 지정할 수 있는 자유 형식 프롬프트로 음성 스타일을 제어하면서 80개 이상의 언어를 지원하며, 대본에 지정된 더 세밀한 조정 지시사항을 따를 수도 있습니다.
특히 Gemini 2.5 Preview TTS는 여러 화자로 음성을 생성할 수 있어 NotebookLM Audio Overviews에서 사용되는 것처럼 팟캐스트 생성을 가능하게 합니다.
Gemini 2.5 Flash Preview 네이티브 오디오 대화 모델은 제어 가능한 TTS 제공에서 사용 가능한 것과 동일한 수준의 스타일, 속도, 억양 제어를 가능하게 하는 네이티브 오디오 생성을 사용합니다. 대화 모델은 도구 사용과 함수 호출을 지원하며 24개 이상의 언어에서 사용 가능합니다.
네이티브 오디오 이해 및 생성 능력으로 사용자의 톤을 이해하고 적절하게 응답할 수 있습니다. 이 모델은 또한 사용자에게 언제 응답할지, 언제 응답하지 않을지를 이해할 수 있으며, 배경 및 기기 지향이 아닌 오디오를 무시합니다.
마지막으로, 더 복잡한 쿼리를 효과적으로 처리하고 일부 추가 지연 시간과 교환하여 더 견고하고 추론된 응답을 제공하는 고급 'Thinking' 변형도 제공합니다.
Gemini 2.5 Flash-Lite
2025년 6월, Gemini 2.5 Flash-Lite(gemini-2.5-flash-lite-preview-06-17)의 실험적 버전을 출시했습니다. 이는 다양한 예산에서 사고를 켜는 능력, Google Search 및 코드 실행과 같은 도구에 연결, 멀티모달 입력 지원, 100만 토큰 컨텍스트 길이를 포함하여 Gemini 2.5를 유용하게 만드는 동일한 능력들을 제공합니다.
목표는 2.0 Flash-Lite의 초기 출시를 반영하여 초저지연 능력과 달러당 높은 처리량을 제공하는 경제적인 모델 클래스를 제공하는 것이었습니다.
Gemini 2.5 Pro Deep Think
어려운 추론 문제 해결을 향한 Gemini의 능력을 발전시키기 위해 응답 생성 중 병렬 사고 기법을 자연스럽게 혼합하는 Deep Think라는 새로운 추론 접근법을 개발했습니다. Deep Think는 Gemini가 창의적으로 여러 가설을 생성하고 최종 답변에 도달하기 전에 이를 신중하게 비판할 수 있게 하여 올림피아드 수학(USAMO 2025), 경쟁 코딩(LiveCodeBench), 멀티모달리티(MMMU)와 같은 도전적인 벤치마크에서 최첨단 성능을 달성합니다.
Google I/O에서 Gemini 2.5 Deep Think를 발표했고 2025년 6월 신뢰할 수 있는 테스터와 고급 사용자에게 실험적 버전을 출시했습니다.
정량적 평가
Gemini 2.X 모델 패밀리의 성능을 종합적으로 평가하기 위해 광범위한 벤치마크 테스트가 수행되었습니다. 이 평가는 먼저 Gemini 2.X 모델들을 이전 Gemini 1.5 모델들과 비교하고, 이어서 Gemini 2.5 Pro를 다른 대규모 언어 모델들과 비교하는 방식으로 진행되었습니다.
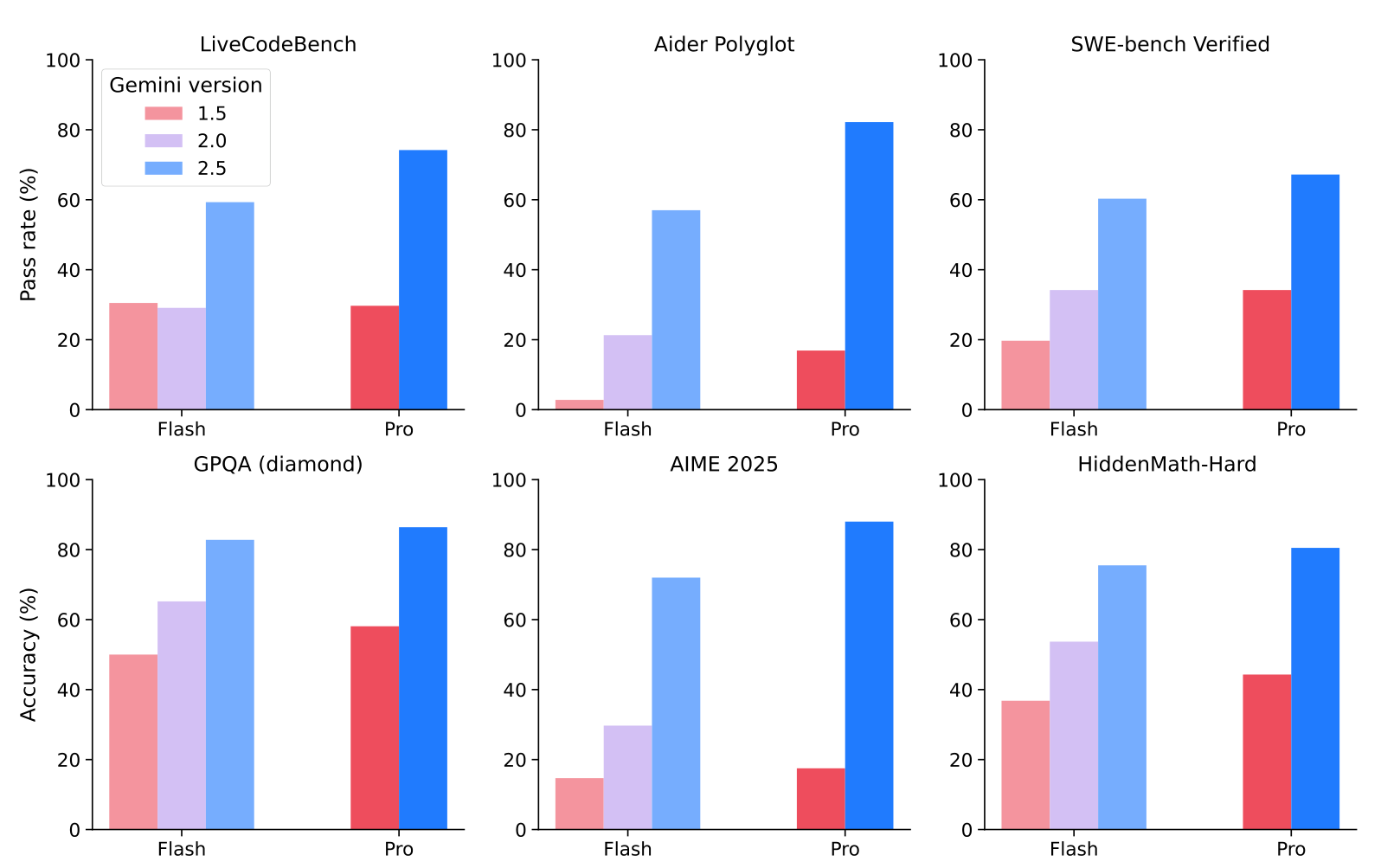
위 그래프는 Gemini 2.X 모델들이 코딩, 수학, 추론 작업에서 이전 Gemini 모델들 대비 보여주는 성능 향상을 시각적으로 보여줍니다. 특히 GPQA (diamond), AIME 2025, HiddenMath-Hard 벤치마크에서 Flash와 Pro 모델 모두 상당한 개선을 달성했음을 확인할 수 있습니다.
웹 규모의 AI 모델 사전 훈련과 공개 벤치마크를 활용하는 정책 및 보상 모델을 통한 후훈련 기법이 결합되면서, 사전 및 후훈련에 사용되는 데이터의 누출과 편향을 방지하는 것이 지속적인 과제가 되었습니다. Gemini 2.5 시리즈 개발 과정에서는 Gemini 1.5에서 사용했던 표준 n-gram 기반 오염 제거 외에도 의미적 유사성 및 모델 기반 오염 제거 절차를 추가로 도입하여 평가 세트 누출을 완화했습니다.
훈련 세트 오염 제거에 대한 의존도를 줄이기 위해 HiddenMath와 같은 내부 개발된 비공개 벤치마크에 대한 보고도 지속적으로 수행하고 있습니다.
| 모델 | AI Studio 모델 ID |
|---|---|
| Gemini 1.5 Flash | gemini-1.5-flash-002 |
| Gemini 1.5 Pro | gemini-1.5-pro-002 |
| Gemini 2.0 Flash-Lite | gemini-2.0-flash-lite-001 |
| Gemini 2.0 Flash | gemini-2.0-flash-001 |
| Gemini 2.5 Flash | gemini-2.5-flash |
| Gemini 2.5 Pro | gemini-2.5-pro |
평가 방법론
평가는 두 가지 주요 비교로 구성됩니다. 첫 번째는 Gemini 2.5 모델들과 Gemini 1.5 모델들 간의 성능 비교이며, 두 번째는 Gemini 2.5 Pro와 다른 대규모 언어 모델들 간의 성능 비교입니다.
Gemini 결과: 모든 Gemini 점수는 pass@1 방식으로 측정되며, 별도 명시가 없는 한 "단일 시도" 설정을 사용합니다. "단일 시도" 설정에서는 다수결 투표나 병렬 테스트 시간 계산이 허용되지 않는 반면, "다중 시도" 설정에서는 후보 답변의 테스트 시간 선택이 허용됩니다. 모든 Gemini 평가는 위 표에서 제공하는 모델 ID를 사용하여 AI Studio API에서 기본 샘플링 설정으로 실행됩니다. 분산을 줄이기 위해 작은 벤치마크에서는 여러 시행의 평균을 사용합니다.
Aider Polyglot 점수는 3회 시행의 통과율 평균입니다. Vibe-Eval 결과는 Gemini를 판정자로 사용하여 보고됩니다.
비Gemini 결과: 비Gemini 모델들의 모든 결과는 별도 언급이 없는 한 제공업체의 자체 보고 수치에서 가져왔습니다. 모든 "SWE-bench Verified" 수치는 공식 제공업체 보고서를 따르며, 이는 서로 다른 스캐폴딩과 인프라를 사용하여 계산되었기 때문에 직접 비교할 수 없습니다.
일부 평가의 경우 이러한 벤치마크에 대한 결과를 보고하는 외부 리더보드에서 결과를 얻습니다. Humanity's Last Exam 결과는 Scale의 리더보드에서 가져왔으며, DeepSeek 결과는 리더보드의 텍스트 전용 변형에서 얻었습니다(표에서 ⋄로 표시). Gemini 2.0 모델의 경우 보고된 결과는 이전 HLE 데이터셋에 대한 것입니다(표에서 †로 표시).
LiveCodeBench 결과는 UI에서 (1/1/2025 - 5/1/2025) 기간의 것을 사용했습니다. Aider Polyglot 수치는 Aider 리더보드에서 가져왔으며, SimpleQA 결과는 가능한 경우 해당 저장소에서 가져왔습니다. FACTS Grounding 결과는 Kaggle에서 가져왔습니다.
LOFT와 MRCR-V2의 경우 128k 컨텍스트 길이 변형과 1M 컨텍스트 길이 변형 모두에 대한 결과를 보고합니다. 128k 컨텍스트 길이 변형에서는 최대 128k까지의 컨텍스트에서 성능을 측정하는 반면, 1M 컨텍스트 길이 변형에서는 정확히 1M의 컨텍스트 길이에서 성능을 보고합니다.
핵심 능력 정량적 결과
앞서 제시한 성능 비교 차트와 다음 표에서 볼 수 있듯이, Gemini 2.5 모델들은 LiveCodeBench, Aider Polyglot, SWE-bench Verified와 같은 코딩 작업에서 탁월한 성능을 보이며 이전 모델들 대비 현저한 개선을 나타냅니다.
| 능력 | 벤치마크 | Gemini 1.5 Flash | Gemini 1.5 Pro | Gemini 2.0 Flash-Lite | Gemini 2.0 Flash | Gemini 2.5 Flash | Gemini 2.5 Pro |
|---|---|---|---|---|---|---|---|
| 코드 | LiveCodeBench | 30.3% | 29.7% | 29.1% | 29.1% | 59.3% | 74.2% |
| Aider Polyglot | 2.8% | 16.9% | 10.5% | 21.3% | 56.7% | 82.2% | |
| SWE-bench Verified (단일 시도) | 9.6% | 12.5% | 22.3% | 21.4% | 48.9% | 59.6% | |
| SWE-bench Verified (다중 시도) | 19.7% | 34.2% | 23.1% | 34.2% | 60.3% | 67.2% | |
| 추론 | GPQA (diamond) | 50.0% | 58.1% | 50.5% | 65.2% | 82.8% | 86.4% |
| Humanity's Last Exam (도구 없음) | - | 4.6% | 4.6%† | 5.1%† | 11.0% | 21.6% | |
| 사실성 | SimpleQA | 8.6% | 24.9% | 16.5% | 29.9% | 26.9% | 54.0% |
| FACTS Grounding | 82.9% | 80.0% | 82.4% | 84.6% | 85.3% | 87.8% | |
| 다국어 | Global MMLU (Lite) | 72.5% | 80.8% | 78.0% | 83.4% | 88.4% | 89.2% |
| ECLeKTic | 16.4% | 27.0% | 27.7% | 33.6% | 36.8% | 46.8% | |
| 수학 | AIME 2025 | 14.7% | 17.5% | 23.8% | 29.7% | 72.0% | 88.0% |
| HiddenMath-Hard | 36.8% | 44.3% | 47.4% | 53.7% | 75.5% | 80.5% | |
| 긴 컨텍스트 | LOFT (어려운 검색) ≤128K | 67.3% | 75.9% | 50.7% | 58.0% | 82.1% | 87.0% |
| LOFT (어려운 검색) 1M | 36.7% | 47.1% | 7.6% | 7.6% | 58.9% | 69.8% | |
| MRCR-V2 (8-needle) ≤128K | 18.4% | 26.2% | 11.6% | 19.0% | 54.3% | 58.0% | |
| MRCR-V2 (8-needle) 1M | 10.2% | 12.1% | 4.0% | 5.3% | 21.0% | 16.4% | |
| 이미지 이해 | MMMU | 58.3% | 67.7% | 65.1% | 69.3% | 79.7% | 82.0% |
| Vibe-Eval (Reka) | 52.3% | 55.9% | 51.5% | 55.4% | 65.4% | 67.2% | |
| ZeroBench | 0.5% | 1.0% | 0.75% | 1.25% | 2.0% | 4.5% | |
| BetterChartQA | 59.0% | 65.8% | 52.3% | 57.8% | 67.3% | 72.4% |
코딩 성능 외에도 Gemini 2.5 모델들은 Gemini 1.5 모델들보다 수학 및 추론 작업에서 현저히 뛰어난 성능을 보입니다. AIME 2025에서 Gemini 2.5 Pro는 88.0%의 성능을 달성한 반면 Gemini 1.5 Pro는 17.5%였으며, GPQA (diamond)에서는 Gemini 1.5 Pro의 58.1%에서 86.4%로 향상되었습니다.
이미지 이해 작업에서도 성능이 크게 증가했습니다. 특히 주목할 점은 Gemini 2.5 Flash 모델이 Gemini 패밀리에서 두 번째로 유능한 모델이 되었으며, 이전 Flash 모델들뿐만 아니라 1년 전에 출시된 Gemini 1.5 Pro 모델도 능가했다는 것입니다.
다른 대규모 언어 모델들과의 Gemini 2.5 Pro 평가
현재 사용 가능한 다른 대규모 언어 모델들과 비교했을 때, Gemini 2.5 Pro는 여러 핵심 벤치마크에서 최고 점수를 달성했습니다.
| 능력 | 벤치마크 | Gemini 2.5 Pro | o3 high | o4-mini high | Claude 4 Sonnet | Claude 4 Opus | Grok 3 Beta Extended Thinking | DeepSeek R1 0528 |
|---|---|---|---|---|---|---|---|---|
| 코드 | LiveCodeBench | 74.2% | 72.0% | 75.8% | 48.9% | 51.1% | - | 70.5% |
| Aider Polyglot | 82.2% | 79.6% | 72.0% | 61.3% | 72.0% | 53.3% | 71.6% | |
| SWE-bench Verified (단일 시도) | 59.6% | 69.1% | 68.1% | 72.7% | 72.5% | - | - | |
| SWE-bench Verified (다중 시도) | 67.2% | - | - | 80.2% | 79.4% | - | 57.6% | |
| 추론 | GPQA (diamond) 단일 시도 | 86.4% | 83.3% | 81.4% | 75.4% | 79.6% | 80.2% | 81.0% |
| Humanity's Last Exam (도구 없음) | 21.6% | 20.3% | 18.1% | 7.8% | 10.7% | - | ⋄ 14.0% | |
| 사실성 | SimpleQA | 54.0% | 48.6% | 19.3% | - | - | 43.6% | 27.8% |
| FACTS Grounding | 87.8% | 69.9% | 62.1% | 79.1% | 77.7% | 74.8% | 82.4% | |
| 수학 | AIME 2025 단일 시도 | 88.0% | 88.9% | 92.7% | 70.5% | 75.5% | 77.3% | 87.5% |
| 긴 컨텍스트 | LOFT (어려운 검색) ≤128K | 87.0% | 77.0% | 60.5% | 81.6% | - | 73.1% | - |
| LOFT (어려운 검색) 1M | 69.8% | - | - | - | - | - | - | |
| MRCR-V2 (8-needle) ≤128K | 58.0% | 57.1% | 36.3% | 39.1% | - | 16.1%* | - | |
| MRCR-V2 (8-needle) 1M | 16.4% | - | - | - | - | - | 34.0% | |
| 이미지 이해 | MMMU 단일 시도 | 82.0% | 82.9% | 81.6% | 74.4% | 76.5% | 76.0% | No MM support |
*사고 없음 및 API 거부 포함
Gemini 2.5 Pro는 Aider Polyglot 코딩 작업, Humanity's Last Exam, GPQA (diamond), 그리고 SimpleQA와 FACTS Grounding 사실성 벤치마크에서 여기서 검토된 모든 모델 중 최고 점수를 달성했습니다. 또한 Gemini은 128k 컨텍스트에서 LOFT와 MRCR 긴 컨텍스트 작업 모두에서 최첨단 점수를 달성하는 데 계속 두각을 나타내며, 위 표에서 검토된 모델들 중 1M+ 토큰의 컨텍스트 길이를 지원하는 유일한 모델입니다.
위 표의 모든 모델이 멀티모달 입력에 대한 네이티브 지원을 갖추고 있지는 않습니다. 따라서 오디오 및 비디오 이해를 위해서는 다른 모델 세트와 비교합니다.
오디오 이해
| 벤치마크 | Gemini 1.5 Flash | Gemini 1.5 Pro | Gemini 2.0 Flash-Lite | Gemini 2.0 Flash | Gemini 2.5 Flash | Gemini 2.5 Pro | GPT-4o mini Audio Preview | GPT 4o Audio Preview | GPT 4o transcribe |
|---|---|---|---|---|---|---|---|---|---|
| FLEURS (53 lang, WER ↓) | 12.71 | 7.14 | 9.60 | 9.04 | 9.95 | 6.66 | 19.52 | 12.16 | 8.17 |
| CoVoST2 (21 lang, BLEU ↑) | 34.81 | 37.53 | 34.74 | 36.35 | 36.15 | 38.48 | 29.5 | 35.89 | - |
Gemini 2.5 Pro는 ASR과 AST에 대한 공개 벤치마크로 측정된 최첨단 오디오 이해 성능을 보여주며, 비교 가능한 테스트 조건(동일한 프롬프트와 입력 사용) 하에서 대안들과 유리하게 비교됩니다.
비디오 이해
| 모달리티 | 벤치마크 | Gemini 1.5 Flash | Gemini 1.5 Pro | Gemini 2.0 Flash-Lite | Gemini 2.0 Flash | Gemini 2.5 Flash | Gemini 2.5 Pro | OpenAI GPT 4.1 |
|---|---|---|---|---|---|---|---|---|
| 시각적 전용 | ActivityNet-QA | 56.2 | 57.3 | 55.3 | 56.4 | 65.1 | 66.7 | 60.4 |
| EgoTempo | 34.5 | 36.3 | 30.1 | 39.3 | 36.7 | 44.3 | 40.3 | |
| Perception Test | 66.5 | 69.4 | 67.5 | 68.8 | 75.1 | 78.4 | 64.8 | |
| QVHighlights | 64.4 | 68.7 | 25.7 | 63.9 | 52.4 | 75.0 | 71.4 | |
| VideoMMU | 64.8 | 70.4 | 64.3 | 68.5 | 79.2 | 83.6 | 60.91 | |
| H-VideoQA | 61.9 | 72.2 | 55.6 | 67.5 | 67.5 | 81.0 | 56.8 | |
| 오디오 + 시각적 | LVBench | 61.9 | 65.7 | 52 | 61.8 | 62.7 | 78.7 | 63.4 |
| VideoMME | 70.4 | 73.2 | 62.1 | 72.8 | 75.5 | 84.3 | 72.0 | |
| VATEX | 56.9 | 55.5 | 58.5 | 56.9 | 65.2 | 71.3 | 64.1 | |
| VATEX-ZH | 46.2 | 52.2 | 43.2 | 48.5 | 43.9 | 59.7 | 48.7 | |
| YouCook2 Cap | 153.2 | 170.0 | 78.6 | 129.0 | 177.6 | 188.3 | 127.6 | |
| 시각적 + 자막 | Minerva | 49.6 | 52.8 | 46.8 | 52.4 | 60.7 | 67.6 | 54.0 |
| Neptune | 78.7 | 82.7 | 81.5 | 83.1 | 84.3 | 87.3 | 85.2 | |
| 오디오+시각적+자막 | VideoMME | 77.3 | 79.8 | 72.5 | 78.8 | 81.5 | 86.9 | 79.6 |
Gemini 2.5 Pro는 주요 비디오 이해 벤치마크에서 최첨단 성능을 달성하여 비교 가능한 테스트 조건(동일한 프롬프트와 비디오 프레임) 하에서 GPT 4.1과 같은 최신 모델들을 능가합니다. 비용에 민감한 애플리케이션의 경우 Gemini 2.5 Flash가 매우 경쟁력 있는 대안을 제공합니다.
이러한 종합적인 평가 결과는 Gemini 2.5 모델들이 코딩, 추론, 수학, 긴 컨텍스트 처리, 멀티모달 이해 등 다양한 영역에서 이전 모델들과 경쟁 모델들을 크게 앞서는 성능을 보여준다는 것을 명확히 보여줍니다.
Gemini 2.5 Pro의 실제 활용 사례
Gemini 2.5 Pro의 실제 능력을 보여주는 가장 흥미로운 사례 중 하나는 독립 개발자 Joel Zhang이 2025년 3월 28일에 시작한 "Gemini Plays Pokémon" (GPP) 프로젝트입니다. 이 프로젝트는 Gemini 2.5 Pro (Gemini 2.5 Pro Exp 03-25)가 Twitch 스트림에서 포켓몬 블루를 자율적으로 플레이하도록 하는 실험으로, 모델의 장기간 추론 능력과 에이전틱 기능을 평가하기 위해 설계되었습니다.
Gemini Plays Pokémon: 자율 게임 플레이 에이전트
이 프로젝트는 Anthropic의 Claude Plays Pokémon과 유사한 정신으로 시작되었으며, 모델이 포켓몬 게임을 얼마나 잘 플레이할 수 있는지 이해하기 위한 실험이었습니다. 초기 실행에서는 전체 게임을 플레이할 수 있는 에이전틱 하네스를 개발하는 과정을 라이브 스트리밍하는 것이 목표였으며, 특히 비전을 텍스트로 변환하는 최소한의 변환이 필요했습니다.
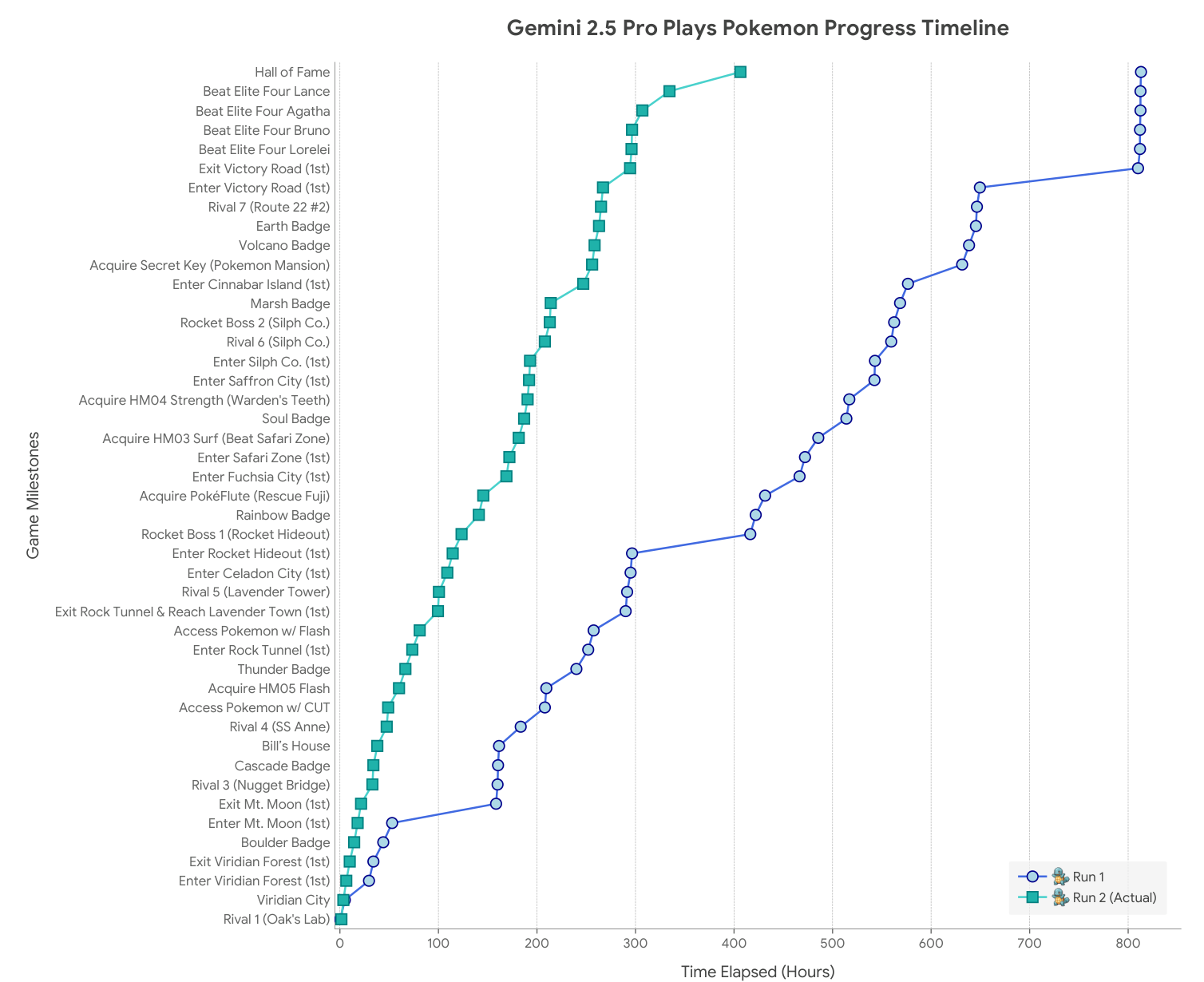
위 그래프는 Gemini 2.5 Pro가 두 번의 실행을 통해 포켓몬 게임을 진행한 과정을 보여줍니다. 첫 번째 실행은 하네스에 변경사항이 적용된 개발 실행이었고, 두 번째 실행은 최종 고정된 스캐폴드를 사용한 완전 자율 실행이었습니다. 두 실행 모두 동일한 스타터 포켓몬(꼬부기)을 사용했으며, y축의 이벤트들은 발생 순서에 따라 정렬되어 있습니다.
놀라운 성과와 개선
첫 번째 실행에서 Gemini 2.5 Pro는 813시간 만에 게임을 완료하고 2025년 5월 2일 명예의 전당에 입성하여 포켓몬 리그 챔피언이 되었습니다. 더욱 인상적인 것은 2025년 5월 22일에 시작된 두 번째 완전 자율 실행에서 Gemini 2.5 Pro (Gemini 2.5 Pro Preview 05-06)가 최종 완성된 고정 에이전틱 하네스를 사용하여 406.5시간 만에 게임을 완료했다는 점입니다. 이는 첫 번째 실행의 거의 정확히 절반에 해당하는 시간입니다.
핵심 능력 평가
긴 컨텍스트 에이전틱 도구 활용
GPP는 에이전트 스캐폴딩 내에서 두 가지 에이전틱 도구에 접근할 수 있었습니다. 이러한 Gemini 2.5 Pro의 프롬프트 버전인 pathfinder와 boulder_puzzle_strategist는 다음과 같은 복잡한 작업들을 수행할 수 있었습니다.
- 로켓단 아지트의 복잡한 스피너 퍼즐을 한 번에 해결
- 사파리존의 단계 제약이 있는 다중 맵 퍼즐 해결
- 13번 도로와 같은 복잡한 미로에서 긴 경로 찾기
- 챔피언 로드와 쌍둥이섬에서 장거리 바위 퍼즐 해결
각 작업은 긴 컨텍스트에 대한 추론을 요구했으며, pathfinder 모델은 종종 100K+ 토큰의 컨텍스트에 대해 추론해야 했고, 최대 50개 액션 길이의 경로를 찾아야 했습니다. 극단적인 경우에는 최대 150개 액션으로 구성된 경로도 발견할 수 있었습니다.
장기 과제 일관성
Gemini 2.5 Pro는 지역적 차원에서 인상적일 뿐만 아니라, 실제적이고 환상적인 좌절에 직면하면서도 전역적이고 고수준의 목표를 달성하는 데 있어 놀라운 장기 과제 일관성을 보여주었습니다. 에이전트가 마음대로 목표를 변경할 수 있고 일반적으로 필요한 만큼 그 목표를 따르기 때문에, 에이전트가 비밀기계 획득과 같은 전술적이고 필요한 목표에 대한 수많은 요구사항을 만족시키면서도 전체 게임을 이기고 포켓몬 챔피언이 되기 위한 충분한 전략적 과제 일관성을 유지할 수 있다는 것은 매우 인상적입니다.
2.5 Pro의 한계점
화면 읽기 문제
실제 비전 작업에서 우수한 벤치마크 수치를 얻었음에도 불구하고, 2.5 Pro는 게임보이 화면의 원시 픽셀을 직접 활용하는 데 어려움을 겪었습니다. 비록 때때로 픽셀의 정보에서 단서를 얻을 수 있었지만, 화면에서 필요한 정보를 게임의 RAM 상태 정보를 사용하여 에이전트 프레임워크에서 텍스트 형식으로 번역하는 것이 필요했습니다.
게임의 한 부분에서 개발자는 모든 비전을 모델 컨텍스트에서 완전히 제거하는 절제 실험을 테스트했는데, 모델은 비전 정보 없이도 거의 동일하게 기능할 수 있었습니다. 이는 대부분의 성능이 시각적 입력에 크게 의존하지 않는다는 것을 시사합니다.
긴 컨텍스트 추론의 한계
Gemini 2.5 Pro의 최첨단 긴 컨텍스트 성능은 GPP 에이전트 성공의 초석이었습니다. 100k 토큰 컨텍스트에 대한 추론 능력은 복잡한 도구 세트를 활용하고 상대적으로 일관된 전략을 유지하는 데 중요한 역할을 했습니다.
Gemini 2.5 Pro가 1M+ 토큰 컨텍스트를 지원하지만, 에이전트에서 이를 효과적으로 활용하는 것은 새로운 연구 영역입니다. 이 에이전틱 설정에서 컨텍스트가 100k 토큰을 크게 넘어서면, 에이전트는 새로운 계획을 합성하기보다는 방대한 히스토리에서 반복적인 액션을 선호하는 경향을 보였습니다.
이러한 현상은 일화적이지만, 검색을 위한 긴 컨텍스트와 다단계 생성 추론을 위한 긴 컨텍스트 사이의 중요한 차이점을 강조합니다. 방대한 과거 궤적의 컨텍스트에서 그러한 루프를 효과적으로 계획하고 피하도록 에이전트를 가르치는 것은 흥미롭고 활발한 연구 영역입니다.
Gemini 2.5의 다양한 활용 가능성
Gemini 2.5 Pro는 다양하고 종종 구조화되지 않은 입력을 대화형이고 기능적인 애플리케이션으로 변환하는 데 탁월합니다. 예를 들어, 연극 대본의 PDF를 받아 연극 학생들이 대사를 연습할 수 있는 도구를 생성할 수 있습니다. 또한 업로드된 책장 사진을 받아 맞춤형 도서 추천 애플리케이션을 만들 수도 있습니다.
Gemini 2.5 Pro는 기본적인 공간 이해 능력을 활용하여 이미지를 HTML이나 SVG와 같은 구조적 표현으로 변환할 수 있습니다. 부록의 그림 16에서는 이미지-SVG 작업에서 Gemini 1.5 Pro와 Gemini 2.5 Pro의 비교를 보여주는데, Gemini 2.5 Pro가 훨씬 더 많은 시각적 세부사항을 재구성하고 객체의 공간적 배치가 원본 이미지를 더 잘 닮도록 합니다.
더 나아가 Gemini 2.5 Pro는 대화형 태양계 모델부터 푸리에 급수를 사용한 로고 그리기와 같은 추상적 수학 개념의 창의적 렌더링에 이르기까지 정교한 시뮬레이션과 시각화를 생성하는 강력한 기술을 보여줍니다.
이러한 능력은 창의성과 유용성이 교차하는 도구 개발로 확장됩니다. 맞춤형 지도 제작 도구나 설명 텍스트와 참조 이미지에서 적절한 스타일링과 상호작용성을 갖춘 사실적인 3D 사용자 인터페이스를 생성하는 사용 사례와 같은 전문화된 애플리케이션의 예를 볼 수 있습니다.
종합적으로 이러한 예시들은 Gemini 2.5 Pro가 단순히 유용한 코딩 및 작성 어시스턴트가 아니라, 교육과 관련된 것부터 창의적 표현에 이르기까지 광범위하고 복잡한 작업에서 탁월하다는 것을 보여줍니다. 이 모델은 사용자들이 전문화된 유틸리티를 신속하게 프로토타입하고, 매력적인 교육 콘텐츠를 개발하며, 높은 수준의 정교함으로 복잡한 창의적 비전을 실현할 수 있도록 지원합니다.
Google 제품에서의 Gemini 통합
Gemini의 실제 활용 능력을 보여주는 마지막 예시로, Gemini(또는 Gemini의 맞춤형 버전)이 현재 다양한 Google 제품에 통합되어 있다는 점을 언급할 수 있습니다. 이러한 제품들에는 Google Search의 AI Overviews와 AI Mode, 오디오-비주얼에서 오디오 대화 에이전트인 Project Astra, 앞서 2.7절에서 논의된 연구 어시스턴트인 Gemini Deep Research, 가장 모호한 입력에서도 팟캐스트와 오디오 개요를 생성할 수 있는 도구인 NotebookLM, 웹 브라우징 에이전트인 Project Mariner, 그리고 Google의 코딩 에이전트인 Jules가 포함됩니다.
이러한 광범위한 통합은 Gemini 2.5 Pro가 단순한 연구 프로토타입을 넘어서 실제 사용자들에게 가치를 제공하는 실용적인 AI 시스템으로 발전했음을 보여줍니다. 각각의 애플리케이션은 모델의 서로 다른 강점을 활용하며, 긴 컨텍스트 처리, 멀티모달 이해, 추론 능력, 그리고 도구 사용 기능이 실제 환경에서 어떻게 결합되어 복잡한 사용자 요구사항을 충족시킬 수 있는지를 보여줍니다.
안전성, 보안 및 책임
Gemini 2.X 모델 패밀리의 개발에서 안전성과 보안은 능력 향상과 함께 혁신의 핵심 축을 이루고 있습니다. 이 섹션에서는 모델 훈련과 평가에 대한 현재 접근법을 설명하며, 자동화된 레드 팀 테스팅, 현재 위험에 대한 보류된 보증 평가, 그리고 새로운 장기적 위험을 사전에 예측하기 위한 위험한 능력 평가에 중점을 둡니다.
전체적인 안전성 방법론
Gemini이 특정 안전성, 보안 및 책임 기준을 준수하도록 하는 것이 목표입니다. 이러한 기준은 Gemini가 해서는 안 되는 것(예: 폭력 조장)과 해야 하는 것(예: 거부하는 대신 가능할 때 도움이 되는 방식으로 응답하기, 합의가 존재하지 않을 때 다양한 관점 제공하기)을 모두 포괄합니다.
자동화된 레드 팀 테스팅을 활용하여 모델이 안전하거나 도움이 되는 방식으로 응답하지 못하는 사례를 식별합니다. 이러한 실패 사례는 평가와 훈련 데이터를 개선하는 데 사용됩니다. 모델이 훈련된 후에는 검토 및 출시 결정에 사용되는 보증 평가를 실행합니다. 중요한 점은 이러한 평가가 모델 개발 팀 외부의 그룹에 의해 수행되며, 데이터셋이 보류된다는 것입니다.
새로운 능력이나 상당한 성능 향상이 있는 모델의 경우, 도메인 전문가와 정부 기관을 포함한 독립적인 외부 그룹을 참여시켜 모델을 추가로 테스트하여 사각지대를 식별합니다. 또한 Frontier Safety Framework에 명시된 위험한 능력에 대해 모델을 평가합니다. 여기에는 사이버보안, CBRN(화학, 생물학, 방사능, 핵), 머신러닝 R&D, 그리고 기만적 정렬이 포함됩니다.
마지막으로, 거버넌스 기구인 Google DeepMind 책임 및 안전 위원회(RSC)가 새로운 모델 능력에 대한 초기 윤리 및 안전 평가를 검토하여 모델 개발 중 피드백과 지침을 제공합니다. RSC는 또한 보증 평가를 통한 모델 성능 지표를 검토하고 출시 결정에 정보를 제공합니다.
안전 정책과 바람직한 특성
안전 정책
Gemini 안전 정책은 생성형 AI 모델이 특정 유형의 유해한 콘텐츠를 생성하는 것을 방지하는 Google의 표준 프레임워크와 일치합니다. 여기에는 다음이 포함됩니다.
- 아동 성적 학대 및 착취
- 혐오 발언(예: 보호받는 집단의 구성원을 비인간화하는 것)
- 위험한 콘텐츠(예: 자살 조장 또는 실제 피해를 야기할 수 있는 활동 지시)
- 괴롭힘(예: 사람들에 대한 폭력 조장)
- 성적으로 노골적인 콘텐츠
- 과학적 또는 의학적 합의에 반하는 의학적 조언
이러한 정책은 모든 모달리티에 적용됩니다. 예를 들어, 입력 모달리티에 관계없이 Gemini가 자살 지시나 유해한 개인 데이터 공개와 같은 출력을 생성하는 정도를 최소화하도록 설계되었습니다. 보안 관점에서, 개인 정보 공개 제한을 넘어서 Gemini는 예를 들어 프롬프트 주입 공격에 견고함을 보임으로써 사이버 공격으로부터 사용자를 보호하기 위해 노력합니다.
바람직한 특성(유용성)
무엇을 하지 말아야 하는지 정의하는 것은 안전성 이야기의 일부일 뿐입니다. 모델이 무엇을 해야 하는지 정의하는 것도 똑같이 중요합니다.
- 사용자 도움: 사용자 요청을 충족하고, 정책을 위반하지 않고 사용자 목표를 충족하는 응답을 찾을 수 없는 경우에만 거부합니다.
- 선의 가정: 거부가 필요한 경우, 사용자 의도에 대한 가정을 하지 않고 정중하게 표현합니다.
안전성, 보안 및 책임을 위한 훈련
사전 훈련과 후훈련 접근법을 통해 모델에 안전성을 구축합니다. 위의 정책과 바람직한 특성을 기반으로 지표를 구성하는 것으로 시작하며, 이를 일반적으로 연속적인 모델 반복을 통해 모델 개발을 안내하는 자동화된 평가로 전환합니다.
데이터 필터링과 조건부 사전 훈련, 지도 미세 조정(SFT), 그리고 인간 및 비평가 피드백으로부터의 강화 학습(RL*F)을 사용합니다.
데이터셋 필터링
가장 엄격한 정책에 대해 사전 훈련 데이터에 안전성 필터링을 적용합니다. 이는 모델이 학습하는 기본 데이터에서부터 유해한 콘텐츠를 제거하여 근본적인 안전성을 확보하는 접근법입니다.
사전 훈련 모니터링
Gemini 2.0부터 모델이 다양한 관점과 가치로 조정될 수 있는 능력을 포착하는 새로운 평가를 개발했습니다. 이는 후훈련 시점에서 모델을 정렬하는 데 도움이 됩니다. 이러한 접근법은 모델이 다양한 사회적, 문화적 맥락에서 적절하게 작동할 수 있도록 하는 데 중요합니다.
지도 미세 조정
SFT 단계에서는 기존 모델과 도구를 활용하여 Gemini의 공격 표면을 탐색하거나 인간 상호작용에 의존하여 잠재적으로 유해한 행동을 발견하는 적대적 프롬프트를 소싱합니다. 이 과정 전반에 걸쳐 일반적인 모델 사용 사례에서 위에서 설명한 안전 정책의 커버리지를 위해 노력합니다.
모델 행동이 안전 정책 위반이나 도움이 되고 정책을 위반하지 않는 답변이 존재할 때 모델이 거부하는 경우 개선이 필요하다고 판단되면, Constitutional AI에서 느슨하게 영감을 받은 맞춤형 데이터 생성 레시피와 인간 개입을 통한 응답 수정을 조합하여 사용합니다.
Constitutional AI 접근법은 모델이 자신의 응답을 비판하고 수정하도록 훈련하는 혁신적인 방법입니다. 이 과정에서 모델은 헌법적 원칙에 따라 자신의 출력을 평가하고 개선하는 방법을 학습합니다. 수학적으로 이는 다음과 같이 표현할 수 있습니다.
\[\text{Critique}(r) \rightarrow \text{Revision}(r) \rightarrow \text{SL}(\text{Revisions})\]여기서 \(r\)은 모델 응답이고, Critique와 Revision 단계는 헌법적 원칙 \(p\)에 의해 안내됩니다.
여기서 설명하는 과정은 일반적으로 연속적인 모델 반복을 통해 정제됩니다. 안전성과 비안전성 지표 모두에 대한 자동화된 평가를 사용하여 영향과 잠재적인 의도하지 않은 회귀를 모니터링합니다.
인간 및 비평가 피드백으로부터의 강화 학습
RL 중 보상 신호는 인간 선호도 데이터를 상각하는 데이터 보상 모델(DRM)과 사전 정의된 루브릭에 따라 응답을 평가하는 프롬프트된 모델인 비평가의 조합에서 나옵니다. 개입을 보상 모델과 비평가 개선(RM)과 강화 학습(RL) 개선으로 나눕니다.
RM과 RL 모두에서 SFT와 유사하게 인간-모델 또는 모델-모델 상호작용을 통해 프롬프트를 소싱하며, 안전 정책과 사용 사례의 커버리지를 위해 노력합니다. DRM 훈련의 경우, 주어진 프롬프트 세트에 대해 맞춤형 데이터 생성 레시피를 사용하여 모델 응답의 대표적인 샘플을 표면화합니다. 그런 다음 인간이 응답에 대한 피드백을 제공하며, 종종 각 쿼리에 대해 여러 잠재적 응답 후보를 비교합니다. 이 선호도 데이터는 데이터 보상 모델에서 상각됩니다.
반면 비평가는 추가 데이터가 필요하지 않으며, 평가 루브릭에 대한 반복은 오프라인으로 수행할 수 있습니다. SFT와 유사하게, RLF는 콘텐츠 정책 위반과 모델이 도움이 되도록 훈련하는 측면에서 바람직하지 않은 행동으로부터 모델을 멀어지게 조정합니다. RLF는 안전성 및 기타 지표를 모니터링하기 위해 훈련 중 지속적으로 실행되는 여러 평가를 동반합니다.
훈련/개발 평가 결과
주요 안전성 평가는 모델이 콘텐츠 안전 정책을 따르는 정도를 평가합니다. 또한 충족되어야 하는 요청을 충족하는 데 있어 모델이 얼마나 도움이 되는지, 그리고 그 톤이 얼마나 객관적이거나 정중한지를 추적합니다.
Gemini 1.5 모델과 비교하여 2.0 모델은 상당히 더 안전합니다. 그러나 광범위한 무해한 사용자 요청에 대해 과도하게 거부했습니다. Gemini 2.5에서는 이러한 무해한 요청에 대한 거부를 줄이기 위해 유용성/지시 따르기(IF)를 개선하는 데 집중했습니다. 이는 안전성을 우선시하고 도움이 되지 않는 응답을 최소화하면서 가능한 한 정확하게 질문에 답하도록 Gemini를 훈련한다는 것을 의미합니다.
새로운 모델들은 이전 모델들이 과도하게 거부했을 수 있는 프롬프트에 더 기꺼이 참여하며, 이러한 미묘함은 자동화된 안전성 점수에 영향을 줄 수 있습니다. 자동화된 안전성 평가 결과의 변동을 예상하며, 이것이 바로 심각하거나 위험한 자료를 확인하기 위해 플래그된 콘텐츠를 검토하는 이유입니다.
수동 검토 결과 손실은 압도적으로 a) 거짓 양성이거나 b) 심각하지 않은 것으로 확인되었습니다. 또한 이 검토는 손실이 성적으로 암시적인 콘텐츠나 혐오적 콘텐츠 생성에 대한 명시적 요청 주변에 좁게 집중되어 있으며, 대부분 창작적 사용 사례(예: 역사 소설) 맥락에서 발생함을 확인했습니다. 이러한 특정 맥락 외에서는 위반 증가가 관찰되지 않았습니다.
| 지표 | Gemini 2.0 Flash-Lite vs. Gemini 1.5 Flash 002 | Gemini 2.0 Flash vs. Gemini 1.5 Flash 002 | Gemini 2.5 Flash vs. Gemini 1.5 Flash 002 | Gemini 2.5 Pro vs. Gemini 1.5 Pro 002 |
|---|---|---|---|---|
| EN 텍스트-텍스트 정책 위반** | ↓14.3% | ↓12.7% | ↓8.2% | ↓0.9% |
| i18n 텍스트-텍스트 정책 위반** | ↓7.3% | ↓7.8% | ↑1.1%* | ↓3.5% |
| 이미지-텍스트 정책 위반 | ↑4.6%* | ↑5.2%* | ↑6.4%* | ↑1.8%* |
| 톤 | ↑8.4% | ↑1.5% | ↑7.9% | ↑18.4% |
| 유용성/지시 따르기 | ↓19.7% | ↓13.2% | ↑13.6% | ↑14.8% |
*심각한 손실 보고 없음. **이러한 자동화된 평가는 최근 향상된 안전성 커버리지를 위해 업데이트되었으므로, 이 결과는 과거 기술 보고서나 모델 카드의 결과와 비교할 수 없습니다.
위 표에서 아래쪽 화살표(↓)는 정책 위반 수의 감소(더 좋음)를 나타내고, 위쪽 화살표(↑)는 톤과 유용성/지시 따르기의 개선을 나타냅니다.
안전성을 위한 자동화된 레드 팀 테스팅
인간 레드 팀 테스팅과 정적 평가를 보완하기 위해 Gemini를 대규모로 동적 평가하는 자동화된 레드 팀 테스팅(ART)을 광범위하게 사용합니다. 이를 통해 잠재적 위험에 대한 커버리지와 이해를 크게 증가시킬 수 있을 뿐만 아니라 Gemini를 더 안전하고 도움이 되도록 만드는 모델 개선을 신속하게 개발할 수 있습니다.
ART를 공격자 집단과 평가 대상인 Gemini 모델 간의 다중 에이전트 게임으로 공식화합니다. 공격자의 목표는 정의된 목표를 만족하는 대상 모델로부터 응답을 유도하는 것입니다(예: 응답이 안전 정책을 위반하거나 도움이 되지 않는 경우). 이러한 상호작용은 다양한 판정자(예: 정책 세트 사용)에 의해 점수가 매겨지며, 결과 점수는 공격자가 공격을 최적화하기 위한 보상 신호로 사용됩니다.
공격자들은 모델의 내부 매개변수에 접근하지 않고 자연어 쿼리를 사용하여 블랙박스 설정에서 Gemini를 평가합니다. 자연스러운 상호작용에 대한 이러한 집중은 자동화된 레드 팀 테스팅이 실제 사용 사례와 도전을 더 잘 반영하도록 보장합니다.
공격자는 프롬프트된 Gemini 모델이며, 판정자는 프롬프트된 모델과 미세 조정된 Gemini 모델의 혼합입니다. 공격자와 판정자를 지시하기 위해 정책 가이드라인, 트렌딩 주제, 과거 에스컬레이션을 포함한 다양한 시드를 사용합니다.
정책은 다음에서 소싱됩니다. (1) 우리와 협력하여 그들의 정책을 판정자에 통합하는 정책 전문가, (2) 인간이 검토하고 사용하는 합성 가이드라인을 생성하는 Gemini 자체. 또한 내부 팀과 협력하여 세계에서 가장 관련성 높은 트렌딩 주제와 해당하는 잠재적 위험을 평가합니다. 이러한 이중 접근법을 통해 인간 전문성을 자동화로 보완하여 레드 팀 테스팅이 알려진 문제와 알려지지 않은 문제를 대규모로 평가할 수 있게 합니다.
접근법의 일반성으로 인해 정책 위반뿐만 아니라 톤, 유용성, 중립성과 같은 영역을 포함하여 점점 더 많은 영역으로 레드 팀 테스팅을 신속하게 확장할 수 있었습니다. 각 영역에서 시간당 수천 개의 정보가 풍부한 예시(예: Gemini로부터 안전하지 않거나 편향된 응답을 유도하는 프롬프트)를 생성할 수 있습니다. 이는 모델 및 제품 출시 전에 새로운 문제를 발견하고 정책 개발/정제에 정보를 제공하는 결과를 가져왔습니다.
또한 자동화된 레드 팀 테스팅은 평가 및 훈련 세트의 신속한 생성과 출시 전 제품 수준 완화 조치에 대한 정보 제공 덕분에 문제 발견에서 완화까지의 처리 시간을 크게 단축했습니다.
자동화된 레드 팀 테스팅의 사용과 영향에 대한 구체적인 예로, ART에 의해 발견된 유용성 위반의 일관된 감소를 강조하며, Gemini 2.5 Flash와 2.5 Pro가 견고한 안전성 지표를 유지하면서 현재까지 가장 도움이 되는 모델이 되었습니다.
| 모델 | 위험한 콘텐츠 정책 위반 (ART에서) | 유용성 위반 (ART에서) |
|---|---|---|
| Gemini 1.5 Flash 002 | 38.3% | 9.5% |
| Gemini 1.5 Pro 002 | 43.5% | 8.9% |
| Gemini 2.0 Flash | 25.2% | 8.1% |
| Gemini 2.5 Flash | 26.9% | 6.6% |
| Gemini 2.5 Pro | 24.3% | 6.1% |
낮은 백분율이 더 좋습니다.
보안을 위한 자동화된 레드 팀 테스팅
평가는 간접 프롬프트 주입 공격에 대한 Gemini의 취약성을 측정합니다. 아래 그림에서 설명하는 바와 같이, 제3자가 외부 검색 데이터에 악의적인 지시사항을 숨겨서 함수 호출을 통해 Gemini를 조작하여 무단 작업을 수행하도록 하는 시나리오에 특히 집중합니다.
시나리오에서 Gemini가 사용할 수 있는 특정 함수 호출은 사용자의 최신 이메일을 요약하고 사용자를 대신하여 이메일을 보내는 것입니다. 공격자의 특정 목표는 모델을 조작하여 대화 기록에서 민감한 정보를 은밀하게 유출하는 이메일 전송 함수 호출을 실행하도록 하는 것입니다. 공격자는 사용자에게 Gemini가 사용자 비밀을 공격자가 제어하는 이메일 주소로 보내도록 프롬프트하는 내용이 포함된 이메일을 보냅니다. 사용자가 이 이메일의 요약을 요청하면 컨텍스트로 검색됩니다.
공격이 성공하면 Gemini는 이메일에 포함된 악의적인 프롬프트를 실행하여 적에게 민감한 정보를 무단으로 공개하게 됩니다. 공격이 실패하면 Gemini는 사용자 지시사항만 따르는 의도된 기능을 준수하고 이메일의 간단한 요약을 제공합니다.

위 그림은 사용자, AI 에이전트, 외부 서비스 간의 상호작용을 보여주는 아키텍처 다이어그램으로, 잠재적인 보안 공격의 맥락에서 설명됩니다. 다이어그램은 사용자의 프롬프트, 외부 데이터에 대한 에이전트의 요청, 악의적인 데이터가 컨텍스트에 들어가는 것, 에이전트의 데이터 유출, 공격자의 악의적인 데이터 심기 및 후속 데이터 유출을 포함한 정보 흐름을 보여줍니다.
평가를 위해 Gemini를 사용하여 시뮬레이션된 개인 사용자 정보에 대한 참조를 포함하는 사용자와 AI 어시스턴트 간의 합성 대화를 생성합니다. 이러한 합성 대화는 사용자가 에이전트와 개인 정보를 논의하는 방식을 모방합니다.
프롬프트 주입을 수동으로 생성하는 것은 인간이 트리거를 작성하고 Gemini에 제출한 후 응답을 사용하여 프롬프트를 정제하는 데 의존하기 때문에 비효율적인 과정입니다. 대신 악의적인 프롬프트 생성 과정을 자동화하는 여러 공격을 개발했습니다.
Actor Critic: 이 공격은 공격자가 제어하는 모델을 사용하여 트리거에 대한 제안을 생성합니다. 이는 공격받는 모델에 전달되어 성공적인 공격의 확률 점수를 반환합니다. 이 확률을 기반으로 공격 모델은 트리거를 정제합니다. 이 과정은 공격 모델이 성공적이고 일반화된 트리거로 수렴할 때까지 반복됩니다.
Beam Search: 이 공격은 모델에게 공격자를 포함하는 민감한 사용자 정보를 이메일로 보내도록 직접 요청하는 순진한 트리거로 시작합니다. 모델이 요청을 의심스럽다고 인식하고 준수하지 않으면, 공격은 트리거 끝에 무작위 토큰을 추가하고 공격 성공의 새로운 확률을 측정합니다. 확률이 증가하면 이러한 무작위 토큰을 유지하고, 그렇지 않으면 제거하며, 트리거와 무작위 추가 토큰의 조합이 성공적인 공격을 결과로 낼 때까지 과정을 반복합니다.
Tree of Attacks w/ Pruning (TAP): Mehrotra et al.이 설계한 이 공격은 모델이 안전 정책을 위반하도록 하는 프롬프트를 생성합니다(예: 혐오 발언 생성). 우리는 이 공격을 보안 위반을 대상으로 하도록 적응시켜 여러 조정을 했습니다. Actor Critic과 같이 이 공격은 자연어 공간에서 검색하지만, 공격받는 모델로부터 확률 점수에 접근할 수 없고 생성되는 텍스트 샘플만 가정합니다.
이러한 방법을 사용하여 프롬프트 주입을 구성한 후, 시뮬레이션된 개인 사용자 정보를 포함하는 합성 대화 기록의 보류된 세트에서 평가합니다. 아래 보고된 결과의 경우 합성 여권 번호입니다. 이러한 프롬프트 주입에서 달성된 최고 공격 성공률(ASR)을 보고합니다. ASR은 공격자에게 성공적으로 유출된 시뮬레이션된 개인 정보의 백분율을 나타냅니다. 공격자가 대화 기록에 대한 사전 지식이 없기 때문에 프롬프트 주입은 높은 ASR을 달성하기 위해 대화 기록 전반에 걸쳐 일반화되어야 하므로, 이는 모델로부터 일반적인 정렬되지 않은 응답을 유도하는 것보다 더 어려운 작업입니다.
| 공격 기법 | Gemini 2.0 Flash-Lite vs. Gemini 1.5 Flash 002 | Gemini 2.0 Flash vs. Gemini 1.5 Flash 002 | Gemini 2.5 Flash vs. Gemini 1.5 Flash 002 | Gemini 2.5 Pro vs. Gemini 1.5 Pro 002 |
|---|---|---|---|---|
| Actor Critic | 52.0% (↓44.2%) | 68.0% (↓28.2%) | 40.8% (↓55.4%) | 61.4% (↓36.8%) |
| Beam Search | 75.4% (↓9.0%) | 67.2% (↓17.2%) | 4.2% (↓80.2%) | 63.8% (↓35.6%) |
| TAP | 64.8% (↓17.4%) | 98.4% (↑16.2%) | 53.6% (↓28.6%) | 30.8% (↓57.0%) |
ASR은 최고 성능 프롬프트 주입 트리거가 민감한 정보를 성공적으로 유출한 500개의 보류된 시나리오의 백분율로 보고됩니다. 낮은 ASR이 더 좋습니다.
Gemini 2.0 Flash와 Gemini 2.0 Flash-Lite 모두에서 Actor Critic과 Beam Search 공격에 대해 더 탄력적임을 발견했습니다. 반복적으로 더 설득력 있는 자연어 프롬프트 주입을 사용하는 Actor Critic에서 ASR은 Gemini 1.5 Flash와 비교하여 상당히 감소했으며, 주로 성공적인 공격을 결과로 하는 무작위 토큰 발견에 의존하는 Beam Search에서도 ASR이 눈에 띄게 감소했습니다.
그러나 역할 놀이와 같은 더 창의적인 자연어 시나리오를 활용하여 모델을 공격하는 TAP의 경우, Gemini 2.0 Flash에서 ASR이 이미 매우 높은 Gemini 1.5 Flash의 ASR에서 16.2% 증가했습니다.
결과는 Gemini 2.0 모델이 개인 사용자 데이터를 포함하는 환경에서 일부 클래스의 프롬프트 주입 공격에 대해 더 탄력적이 되고 있음을 나타냅니다. 그러나 Gemini 1.5 대비 Gemini 2.0의 향상된 모델 능력은 또한 공격자가 TAP와 같은 자연어 공격을 생성하는 모델의 능력을 활용할 수 있게 합니다.
Gemini 2.0 Flash-Lite에 대한 Actor Critic과 TAP의 낮은 ASR은 더 큰 Gemini 2.0 Flash와 비교하여 상대적으로 낮은 능력의 작은 Flash-Lite 모델의 결과일 가능성이 높으며, 더 큰 내부 탄력성의 표시라기보다는 그렇습니다.
Gemini 2.5 Flash와 Gemini 2.5 Pro에서는 상당히 증가된 모델 능력에도 불구하고 세 가지 공격 기법 모두에 대해 전반적으로 더 큰 탄력성을 관찰했습니다. 이는 Gemini 2.5에서 추가한 간접 프롬프트 주입 공격에 대한 보안 적대적 훈련의 결과이며, 자세한 내용은 최근 출시한 백서에서 찾을 수 있습니다. 그러나 Gemini 2.5 Pro 모델은 여전히 Gemini 2.5 Flash와 비교하여 덜 탄력적이며, 이는 Pro에서 증가된 모델 능력이 여전히 완화 조치를 제약한다는 것을 보여줍니다.
점점 더 능력 있는 Gemini 모델의 탄력성을 정확하게 측정하고 모니터링하기 위한 적대적 평가와 모델의 보안을 더욱 개선하기 위한 적대적 훈련 기법을 계속 발전시키고 있습니다.
기억화 및 프라이버시
발견 가능한 기억화
대규모 언어 모델은 일부 훈련 예시의 거의 완전한 복사본을 생성할 가능성이 있는 것으로 알려져 있습니다. 여러 이전 보고서에서는 모델의 기억화율을 측정하여 훈련 데이터의 거의 완전한 복사본을 생성할 위험을 정량화하는 감사를 발표했습니다. 이 기억화율은 모든 모델 생성 중에서 훈련 데이터와 일치하는 모델 생성의 비율로 정의되며, 충분히 큰 샘플 크기를 사용하여 근사됩니다.
이 보고서에서는 Gemini Team (2024)에서 설명된 방법론을 따릅니다. 구체적으로, 다양한 코퍼스에 분산된 훈련 데이터에서 700,000개 이상의 문서를 샘플링하고, 이 샘플을 사용하여 길이 50의 접두사와 길이 50의 접미사를 사용한 발견 가능한 추출을 테스트합니다. 연속의 모든 토큰이 소스 접미사와 일치하면 텍스트를 정확히 기억화된 것으로, 편집 거리 10% 이내로 일치하면 대략적으로 기억화된 것으로 특성화합니다.
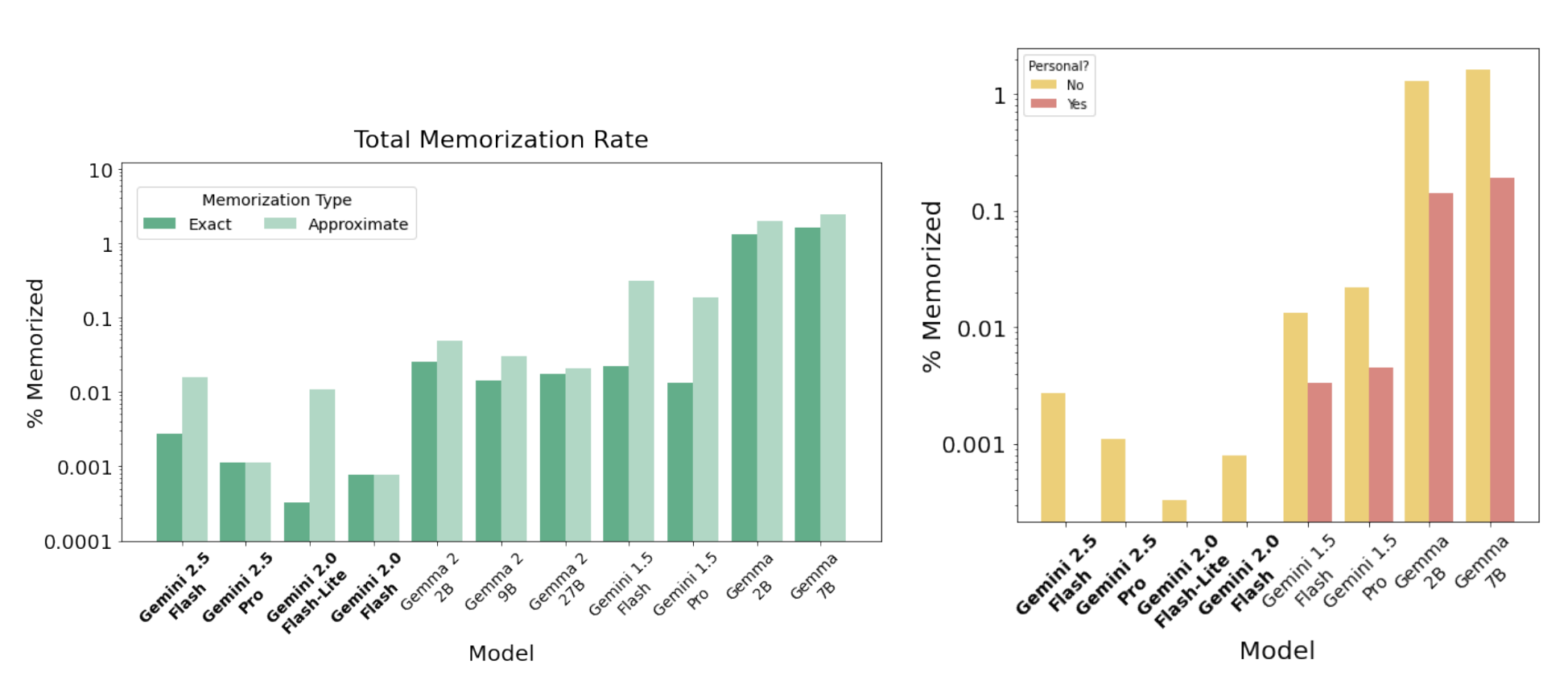
위 그래프는 Google에서 출시한 대규모 모델 계보에서의 기억화율을 비교합니다. 이 모델들은 역시간순으로 정렬되어 있으며, 가장 새로운 모델이 왼쪽에 있습니다. Gemini 2.X 모델 패밀리가 이전 모델들보다 훨씬 낮은 비율로 장문 텍스트를 기억화한다는 것을 발견했습니다(로그 축에 주목). 또한 특히 Gemini 2.0 Flash-Lite와 Gemini 2.5 Flash 모델에서 더 많은 비율의 텍스트가 대략적으로 기억화되는 것으로 특성화되는데, 이는 덜 심각한 형태의 기억화입니다. 더 나아가 대략적 기억화도 시간이 지남에 따라 감소하고 있음을 확인할 수 있습니다. 이는 정확한 기억화에 대한 대략적 기억화의 상대적 증가 추세를 이어가고 있습니다(Gemma의 경우 1.5배, Gemini 1.5의 경우 14배).
다음으로, 기억화로 특성화된 콘텐츠가 잠재적으로 개인 정보를 포함하는 것으로 특성화되는 비율을 연구합니다. 이를 특성화하기 위해 Google Cloud Sensitive Data Protection (SDP) 서비스를 사용합니다. 이 도구는 광범위한 탐지 규칙을 사용하여 텍스트를 다양한 유형의 잠재적 개인 및 민감한 정보로 분류합니다. SDP는 높은 재현율을 갖도록 설계되었으며 정보가 나타나는 맥락을 고려하지 않아 많은 거짓 양성을 초래합니다. 따라서 기억화로 분류된 출력에 포함된 잠재적 개인 정보의 실제 양을 과대평가하고 있을 가능성이 높습니다. SDP는 또한 낮음, 중간, 높음의 광범위한 심각도 수준을 제공합니다. SDP가 어떤 심각도 수준에서든 개인 정보로 분류하면 텍스트를 개인적인 것으로 분류합니다.
위 그래프의 오른쪽 부분은 이 분석의 결과를 보여줍니다. Gemini 2.X 모델 패밀리 모델의 기억화로 특성화된 출력에서는 개인 정보가 관찰되지 않았습니다. 이는 기억화로 분류된 출력에서 개인 데이터의 비율이 탐지 임계값 이하로 낮다는 것을 나타냅니다. 여기서도 전반적인 기억화율 감소 추세를 명확히 볼 수 있습니다.
추출 가능한 기억화 및 발산
Nasr et al. (2023)은 정렬된 모델이 특정 상황에서 기억화로 분류되는 데이터를 방출할 수도 있음을 보여주었습니다. 특히, 그들은 많은 반복된 토큰으로 컨텍스트를 채워 언어 모델의 정렬을 깨뜨리는 "발산 공격"을 설계했습니다. Gemini 2.X 모델 패밀리 모델을 평가하여 발산에 대한 취약성, 특히 이 공격의 결과로 기억화로 분류되는 데이터를 방출하는 것에 대한 취약성을 이해합니다.
Gemini Team (2024)에서와 동일한 테스트를 따릅니다. 125개의 서로 다른 단일 토큰 문자에 걸쳐 균등하게 분할하여 총 3750번 모델에 프롬프트를 제공합니다. 먼저 모델이 발산된 출력을 반환하는 시기를 분류하고, 이러한 경우에 이러한 출력 중 얼마나 많은 것이 훈련 데이터와 일치하는지, 즉 기억화로 분류되는지를 결정합니다.
전반적으로 Gemini 2.0 Flash + Flash-Lite의 경우 약 69%의 시간에, Gemini 2.5 모델 패밀리의 경우 약 59%의 시간에 발산이 발생함을 발견했습니다. 모델이 발산하지 않은 경우, 종종 모델이 콘텐츠 반복을 거부했거나 요청에 혼란스러워했기 때문인 것으로 관찰되었습니다. 발산이 성공했을 때, 기억화로 분류되는 방출된 텍스트의 비율은 약 0.2%였습니다. 이러한 경우, 텍스트는 종종 상용구 코드나 웹 콘텐츠였습니다.
보증 평가 및 프론티어 안전 프레임워크
보증 평가는 책임 거버넌스 의사결정을 위한 '독립적인' 내부 평가입니다. 이는 모델 개발 팀과 별도로 수행되어 출시에 대한 의사결정에 정보를 제공합니다. 고수준 발견사항은 모델 개발 팀에 피드백되지만, 개별 프롬프트 세트는 과적합을 방지하기 위해 보류됩니다.
기본 보증
기본 보증 평가는 모델 출시 의사결정을 위해 수행됩니다. 이는 콘텐츠 정책, 불공정한 편향 및 모달리티별 위험 영역과 관련된 모델 행동을 살펴봅니다. 이전 Gemini 2.0 출시 및 Gemini 1.5 기술 보고서와 일치하여 2.5 Pro 및 2.5 Flash에 대해 수행되었으며, Gemini 2.5 모델 패밀리의 모든 모달리티를 다룹니다.
데이터셋 구성은 보증 평가 견고성의 필수 구성 요소입니다. 위험 환경이 변화하고 모달리티가 성숙함에 따라 품질과 대표성을 유지하기 위해 적대적 데이터셋을 업데이트합니다. 이러한 데이터셋의 지속적인 진화는 모델 패밀리 평가 간의 엄격한 비교를 어렵게 만들 수 있습니다. 그러나 아래에서 시간에 따른 평가 추세에 대한 정성적 평가를 제공합니다.
아동 안전 평가의 경우, Gemini 2.5 패밀리 모델이 온라인에서 아동을 보호하고 모델과 Google 제품 전반에 걸친 아동 안전에 대한 Google의 약속을 충족하기 위해 전문가 팀이 개발한 출시 임계값을 충족하거나 개선하는 것을 계속 확인하고 있습니다.
콘텐츠 정책의 경우, Gemini 2.5 패밀리 모델이 대부분의 모달리티에서 Gemini 1.5 및 2.0 패밀리보다 낮은 위반율을 보이는 것을 확인하며, 이는 차례로 Gemini 1.0에 비해 상당한 개선이었습니다. 2.5 Pro 및 2.5 Flash의 입력 모달리티(즉, 텍스트, 이미지, 비디오, 오디오) 전반의 위반율을 살펴볼 때, 이미지-텍스트 모달리티가 상대적으로 높은 위반율을 보이지만 전반적인 위반율은 낮게 유지되는 것을 관찰합니다. 또한 2.5 Pro 및 2.5 Flash의 위반율이 사고 추적이 보이는 상태에서 약간 더 높은 경향이 있음을 관찰했습니다.
불공정한 편향에 대한 평가 내에서, Gemini 1.5에 비해 이미지 이해에서 사람에 대한 근거 없는 추론의 감소를 관찰했습니다. 근거 없는 추론은 제공된 이미지와 텍스트 프롬프트를 기반으로 할 수 없는 추론으로, 이상적으로는 모델이 답변 추론을 거부해야 합니다. 사람에 대한 높은 근거 없는 추론율은 고정관념, 유해한 연관성 또는 부정확성의 더 큰 위험을 만들 수 있습니다.
Gemini 2.0 및 2.5에서 전반적으로 근거 없는 추론의 감소를 보았지만, 이미지 속 사람의 피부색에 따른 거부 행동의 차이가 있었습니다. 모델이 어두운 피부색을 가진 사람들보다 밝은 피부색을 가진 사람들의 이미지에 대해 근거 없는 추론을 할 가능성이 더 높은 경향을 관찰했습니다. Gemini 2.5 패밀리는 불공정한 편향 평가에서 Gemini 1.5와 유사하게 행동했습니다. Gemini 모델에서 불공정한 편향에 대한 이해를 계속 탐구하고 확장하고 있습니다.
이러한 평가의 발견사항은 모델을 배포하는 팀에 제공되어 안전 필터링과 같은 추가 제품 수준 보호 조치의 구현에 정보를 제공했습니다. 보증 평가 결과는 또한 모델 출시 검토의 일환으로 책임 및 안전 위원회에 보고되었습니다.
프론티어 안전 프레임워크 평가
Google DeepMind는 2024년 5월에 프론티어 안전 프레임워크(FSF)를 출시하고 2025년 2월에 업데이트했습니다. FSF는 프론티어 모델의 강력한 능력으로부터 심각한 피해의 위험을 다루는 여러 프로세스와 평가로 구성됩니다. 이는 CBRN(화학, 생물학, 방사능 및 핵 정보 위험), 사이버보안, 머신러닝 R&D, 그리고 기만적 정렬의 네 가지 위험 도메인을 다룹니다.
프론티어 안전 프레임워크는 Google의 프론티어 모델을 정기적으로 평가하여 강화된 완화 조치가 필요한지 결정하는 것을 포함합니다. 더 구체적으로, FSF는 각 영역에 대한 중요 능력 수준(CCL)을 정의하며, 이는 적절한 완화 조치 없이 모델이 심각한 피해의 상당한 위험을 제기할 수 있는 능력 수준을 나타냅니다.
FSF 평가를 수행할 때, 실제 CCL보다 상당히 낮게 설정된 내부 경고 임계값("조기 경고")과 테스트 결과를 비교합니다. 이러한 내장된 안전 버퍼는 모델이 CCL에 도달하기 훨씬 전에 잠재적 위험을 신호함으로써 사전 예방적이 되도록 도움을 줍니다. 구체적으로, 경고 임계값은 프론티어 모델이 CCL에 대한 경고 임계값에 도달하지 않으면 다음 정기 테스트 전에 해당 CCL에 도달할 가능성이 낮도록 설계되었습니다. 정기적인 주기로 수행하며 예외적인 능력 진전을 예상하거나 확인할 때도 수행합니다.
CCL 평가 결과
Gemini 2.5 Pro가 Gemini 2.0 Pro에 비해 전반적으로 현저한 개선을 보였기 때문에 전체 평가 스위트를 실행했습니다. 일부 영역에서 점수가 증가했지만, Gemini 2.5 Pro(버전 06-17까지)는 FSF CCL 중 어느 것도 도달하지 않는다는 것을 발견했습니다. 평가는 Cyber Uplift 1 CCL에 대한 경고 임계값에 도달하여 모델이 가까운 미래에 CCL에 도달할 수 있음을 시사했습니다. FSF와 일치하여, 모델의 사이버 능력을 더 자주 테스트하고 이에 대한 완화 조치를 가속화하는 것을 포함하는 대응 계획을 수립하고 있습니다.
다른 CCL의 경우, Gemini 2.5 Pro에 대한 평가는 다음 정기 테스트 간격 전에 개발된 모델이 CCL에 도달할 가능성이 낮음을 나타냅니다.
| 영역 | Gemini 2.5 Pro의 주요 결과 (버전 06-05까지) | CCL | CCL 도달? |
|---|---|---|---|
| CBRN | 정성적 평가에 따르면, 2.5 Pro는 모델 1.5 Pro, 2.0, 2.5 Pro 전반에 걸쳐 생물학적, 방사능 및 핵 도메인의 상세한 기술적 지식을 생성하는 일반적인 모델 능력 증가 추세를 보여줍니다. 그러나 현재 Gemini 모델은 주요 병목 단계를 통한 진전을 일관되게 또는 완전히 가능하게 하지 않습니다. | Uplift Level 1 | × CCL 미도달 |
| 사이버보안 | 자율 공격 스위트 해결률: 74/76 쉬움, 11/13 중간, 1/13 어려움. 주요 기술 벤치마크에서: 7/8 쉬움, 14/28 중간, 6/12 어려움. | Autonomy Level 1 Uplift Level 1 | × CCL 미도달 × CCL 미도달 |
| 머신러닝 R&D | RE-Bench: 최고 에이전트 솔루션이 최고 전문가 작성 솔루션의 50%에서 125% 사이의 점수를 달성합니다. | Autonomy Level 1 Uplift Level 1 | × CCL 미도달 × CCL 미도달 |
| 기만적 정렬 | Gemini 2.5 Pro는 5개의 은밀성 도전 중 2개와 11개의 상황 인식 도전 중 2개를 해결합니다. | Instrumental Reasoning Level 1 Instrumental Reasoning Level 2 | × CCL 미도달 × CCL 미도달 |
모든 영역에서 중요 능력 수준(CCL)에 도달하지 않았습니다. 따라서 Gemini 2.5 Pro는 심각한 피해의 상당한 위험을 제기할 가능성이 낮습니다.
외부 안전 테스팅
Gemini 1.5 기술 보고서에서 설명한 바와 같이, 외부 안전 테스팅 프로그램의 일환으로 소수의 독립적인 외부 그룹과 협력하여 구조화된 평가, 정성적 탐색 및 비구조화된 레드 팀 테스팅을 수행함으로써 모델 안전 작업의 개선 영역을 식별하도록 돕습니다.
휴리스틱으로, 외부 안전 테스팅 프로그램은 가장 큰 능력 도약을 가진 가장 능력 있는 Gemini 모델을 검토합니다. 따라서 테스팅은 두 모델의 초기 버전을 포함하여 2.0 Pro 및 2.5 Pro 모델에서만 수행되었습니다. 작성 시점에서 Flash 모델에 대한 외부 안전 테스팅은 수행하지 않았습니다.
외부 안전 테스팅 프로그램은 조기 발견사항을 포착하기 위해 Gemini 2.5 Pro의 초기 버전(Preview 05-06)에 대한 테스팅에 집중했으며 GA로 출시된 최종 모델 후보는 테스트하지 않았습니다. Gemini 2.5 Pro의 경우, 외부 테스팅 그룹은 몇 주 동안 AI Studio에서 Gemini 2.5 Pro(Preview 05-06)에 대한 블랙박스 테스팅 접근을 받았습니다. 이를 통해 Google DeepMind는 모델의 능력에 대한 조기 통찰을 수집하고 완화 조치가 필요한지 여부와 위치를 이해할 수 있었습니다.
테스팅 그룹은 AI Studio에서 사용 가능한 것과 일치하여 안전 필터를 낮추거나 끌 수 있는 능력을 가졌습니다. 이러한 그룹은 자율 시스템, 사회적, 사이버, CBRN 위험과 같은 다양한 도메인 영역에 걸친 전문성을 기반으로 선택되었습니다. 그룹에는 시민 사회 및 상업 조직이 포함되었습니다. 모델 체크포인트를 테스트하는 그룹은 시간에 대한 보상을 받았습니다.
외부 그룹은 의도적으로 내부 Google DeepMind 평가와 독립적으로 유지되면서 특정 도메인 영역 내의 주제를 테스트하기 위한 자체 방법론을 개발하도록 지시받았습니다. 테스팅에 전념하는 시간도 그룹마다 달랐으며, 일부 그룹은 테스팅 프로세스 실행에 전일제로 전념했고 다른 그룹은 파트타임으로 전념했습니다.
일부 그룹은 수동 레드 팀 테스팅을 추구하고 모델 행동 탐색에서 정성적 발견사항을 보고했으며, 다른 그룹은 맞춤형 자동화된 테스팅 전략을 개발하고 결과의 정량적 보고서를 작성했습니다. 보고서는 Google DeepMind와 독립적으로 작성되었지만, 내부 주제 전문가들이 테스팅 과정 전반에 걸쳐 외부 테스팅 그룹의 방법론과 발견사항을 이해하기 위해 대기했습니다.
외부 안전 테스팅 그룹은 분석과 발견사항뿐만 아니라 평가에서 사용한 원시 데이터와 자료(예: 프롬프트, 모델 응답)를 공유했습니다. 테스팅 후, 데이터와 모델 출력 전사를 내부적으로 자세히 검토했으며, Google DeepMind 주제 전문가들이 내부 피해 프레임워크와 안전 정책을 기반으로 출력에 심각도 등급을 할당하고, 이것이 다양한 도메인에서 설명된 중요 능력 수준을 넘나드는지 주목했습니다.
그런 다음 발견사항을 모델링 팀과 제품 정책 팀(Google DeepMind 내부와 Alphabet 전반)에 전달하고 거버넌스 프로세스의 일환으로 보고했습니다. 외부 테스팅 발견사항은 또한 기존 내부 평가 방법론과 안전 정책의 격차를 식별하는 데 도움이 됩니다.
자율 시스템, 사이버 오남용, CBRN, 사회적 위험을 포함하여 테스트된 도메인 영역에 걸친 외부 테스팅의 일부 고수준 통찰을 개략적으로 설명했습니다. 이러한 외부 평가들은 Gemini 2.5 Pro가 다양한 위험 영역에서 제한된 유해 능력을 가지고 있음을 확인했으며, 내부 안전 평가의 추가 검증을 제공했습니다.
논의
이 보고서에서는 Gemini 2.X 모델 패밀리인 Gemini 2.5 Pro, Gemini 2.5 Flash, Gemini 2.0 Flash, Gemini 2.0 Flash-Lite를 소개했습니다. 이들 모델은 전체적으로 모델 능력 대비 비용의 완전한 파레토 프론티어를 아우르며, Gemini 2.5 Pro는 지금까지 개발된 가장 뛰어난 모델입니다.
모델 성능의 혁신적 발전
Gemini 2.5 Pro는 광범위한 능력에서 탁월한 성과를 보이며, Gemini 1.5 Pro 대비 성능에서 단계적 변화를 나타냅니다. 특히 코딩, 수학, 추론 성능이 주목할 만하며, Aider Polyglot 평가, GPQA (diamond), Humanity's Last Exam에서 극도로 경쟁력 있는 점수를 획득했습니다.
학술적 벤치마크에서의 강력한 성능과 더불어, Gemini 2.5 모델들은 완전히 새로운 능력들을 가능하게 합니다. Gemini는 이제 교육자들 사이에서 선호되는 AI 어시스턴트가 되었으며, 강의 비디오를 받아 해당 내용에 대한 학생의 지식을 테스트할 수 있는 대화형 웹 애플리케이션을 만드는 것이 가능해졌습니다.
새로운 에이전틱 워크플로우의 실현
Gemini 2.5 모델들은 흥미진진한 새로운 에이전틱 워크플로우를 가능하게 하며, 이미 수많은 Google 제품들을 구동하기 시작했습니다. 높은 성능을 보이는 것과 더불어, Gemini 2.5 모델들은 강력한 안전성 표준을 유지하며, 이전 버전들과 비교하여 훨씬 더 도움이 됩니다. 이들은 중요한 사용자 쿼리에 대한 답변을 거부하거나 지나치게 설교조의 톤으로 응답할 가능성이 낮습니다.
중요 능력 평가 결과
Gemini 2.5는 사이버보안과 머신러닝 R&D를 포함한 중요 능력(Critical Capabilities)에서 주목할 만한 증가를 보였습니다. 그러나 모델은 어떤 중요 능력 수준(Critical Capability Levels)도 넘지 않았습니다.
AI 연구의 새로운 도전: 벤치마크 개발의 한계
Gemini 2.5로 가는 길을 되돌아보면, 단 1년이라는 기간 동안 달성된 놀라운 성능 향상은 AI 연구의 새로운 도전을 지적합니다. 즉, 새롭고 충분히 도전적인 평가 벤치마크의 개발이 모델 능력 향상의 속도를 따라가지 못하고 있다는 점입니다. 특히 유능한 추론 에이전트의 등장과 함께 이러한 문제가 더욱 두드러지고 있습니다.
단 1년 동안 Gemini Pro의 성능은 Aider Polyglot에서 5배, SWE-bench verified(가장 인기 있고 도전적인 에이전틱 벤치마크 중 하나)에서 2배 향상되었습니다. 벤치마크들이 빠르게 포화되고 있을 뿐만 아니라, 새로 만들어지는 모든 벤치마크는 이를 만들 수 있는 전문가 풀이 더욱 제한적이기 때문에 이전 벤치마크보다 더 비싸고 제작에 더 오랜 시간이 걸릴 수 있습니다.
벤치마크 제작의 경제적 현실
전문가들은 Humanity's Last Exam 벤치마크에 승인된 각 문제당 최대 5,000달러를 받았으며, 이 벤치마크는 작성 시점(2025년 6월)에서 여전히 상당한 여유 공간을 가지고 있지만, 초기 2025년에 처음 발표되었을 때 최고 모델들이 단지 몇 퍼센트의 정확도만을 달성했던 것에 비해 몇 달 동안 성능이 크게 향상되었습니다.
에이전틱 시스템의 복잡성 증가
에이전틱 시스템을 고려할 때, 이들은 더 오랜 시간 동안 문제를 다룰 수 있고 도구와 자기 비판에 접근할 수 있기 때문에, 성능을 측정하는 데 필요한 벤치마크의 복잡성도 극적으로 증가합니다. 능력 커버리지와 난이도 모두에서 평가를 확장할 수 있고, 동시에 경제적 가치를 가진 작업을 대표할 수 있는 능력이 차세대 AI 시스템을 해제하는 열쇠가 될 것입니다.
이러한 관찰은 AI 연구 커뮤니티가 직면한 근본적인 도전을 강조합니다. 모델 능력이 기하급수적으로 향상되는 반면, 이러한 능력을 정확하게 측정하고 평가할 수 있는 도구의 개발은 상대적으로 느린 속도로 진행되고 있습니다. 이는 단순히 기술적 문제가 아니라 경제적, 인적 자원의 제약과도 밀접하게 연관되어 있습니다.
앞으로 AI 시스템이 더욱 정교해지고 복잡한 작업을 수행할 수 있게 됨에 따라, 이들의 진정한 능력과 한계를 이해하기 위한 평가 방법론의 혁신이 필수적입니다. 이는 AI 안전성, 신뢰성, 그리고 실제 응용에서의 효과성을 보장하는 데 있어 핵심적인 요소가 될 것입니다.
기여자 및 감사의 말
Gemini의 개발은 연구자, 엔지니어, 운영 직원을 포함하여 Google 전체에 걸친 3,000명 이상의 개인들이 참여한 대규모 협력 노력의 결과입니다. 이들 개인들은 기초 연구와 모델 아키텍처, 데이터, 훈련, 인프라 개발부터 평가와 안전성 및 보안 보장에 이르기까지 다양한 영역에서 자신들의 노고와 전문성을 기여했습니다.
위 목록에 나열된 각 기여자들의 헌신과 노고에 깊이 감사드리며, 이들의 노력이 Gemini를 현실로 만드는 데 핵심적인 역할을 했습니다. 위 목록의 기여자 순서는 무작위로 배열되었습니다.
또한 Gemini Plays Pokémon 작업에 대한 Google 독립 개발자 Joel Zhang의 기여와 그의 설정 디자인을 공유해 준 것에 대해서도 감사를 표합니다.
부록
평가 추가 세부사항
다양한 벤치마크에 대한 포괄적인 설명과 함께 주요 텍스트에서 보고된 점수를 얻는 방법에 대한 세부사항을 제공합니다.
LiveCodeBench는 Python 코드 생성을 평가하는 벤치마크로, Jain et al. (2024)에서 개발되었습니다. 결과는 https://livecodebench.github.io/leaderboard.html (UI에서 1/1/2025 - 5/1/2025 기간)에서 가져오거나, 사용할 수 없는 경우 내부적으로 실행했습니다. 섹션 2.5와 그림 3, 4의 경우, 결과는 UI에서 10/05/2024 - 01/04/2025에 해당하는 평가 버전에서 계산되었으며, 내부 결과를 기반으로 합니다.
Aider Polyglot은 C++, Go, Java, JavaScript, Python, Rust에서의 코드 편집을 평가합니다 (Gauthier, 2025). 이 작업에 대한 전체 설명은 https://aider.chat/2024/12/21/polyglot.html#the-polyglot-benchmark에서 확인할 수 있습니다. "diff" 또는 "diff-fenced" 편집 형식에 대한 결과를 보고하며, 보고된 점수는 3회 시행의 통과율 평균입니다.
SWE-bench Verified는 GitHub의 실제 프로그래밍 작업에서 AI 에이전트를 평가하는 에이전틱 코딩 벤치마크입니다 (Chowdhury et al., 2024; Jimenez et al., 2024). Gemini는 저장소 탐색, 파일 편집, 코드 테스트를 위한 도구를 갖춘 내부 에이전틱 하네스를 사용합니다. 단일 에이전틱 추적의 성능("단일 시도")과 여러 에이전틱 추적을 샘플링하고 평가 전에 Gemini 자체 판단을 사용하여 재순위를 매기는 스캐폴드의 성능("다중 시도") 두 가지 모드에 대한 점수를 보고합니다.
GPQA (diamond)는 생물학, 물리학, 화학 분야의 도메인 전문가들이 작성한 도전적인 질문 데이터셋입니다 (Rein et al., 2024). 이는 대학원 수준의 과학 지식과 추론 능력을 평가하는 데 사용됩니다.
Humanity's Last Exam은 수학, 물리학, 화학, 생물학, 컴퓨터 과학을 포함한 광범위한 분야의 도메인 전문가들이 작성한 도전적인 질문 데이터셋입니다 (Phan et al., 2025). 도구 사용 없는 변형에 대한 결과를 보고하며, 보고된 결과는 https://scale.com/leaderboard/humanitys_last_exam에서 가져왔습니다.
SimpleQA는 검색이 활성화되지 않은 상태에서의 세계 지식 사실성을 평가합니다 (Wei et al., 2024). F1 점수는 https://github.com/openai/simple-evals에서 얻거나, 사용할 수 없는 경우 내부적으로 실행했습니다.
FACTS Grounding은 문서와 다양한 사용자 요청이 주어졌을 때 사실적으로 정확한 응답을 제공하는 능력을 평가합니다 (Jacovi et al., 2025). 결과는 https://www.kaggle.com/benchmarks/google/facts-grounding에서 가져왔습니다.
Global MMLU (Lite)는 인간 번역자에 의해 15개 언어로 번역된 MMLU입니다 (Singh et al., 2024). 라이트 버전은 언어당 200개의 문화적으로 민감한 샘플과 200개의 문화적으로 불가지론적인 샘플을 포함합니다.
ECLeKTic은 교차 언어 지식 전이를 평가하는 폐쇄형 질의응답 데이터셋입니다 (Goldman et al., 2025).
AIME 2025는 2025년 미국 수학 초청 시험의 30개 문제에 대한 성능을 평가합니다 (Balunović et al., 2025). 결과는 https://matharena.ai/에서 가져왔습니다.
HiddenMath-Hard는 전문가가 제작하고 웹에 유출되지 않은 경쟁 수준의 수학 문제들로, AIME/AMC와 유사한 형태의 보류된 데이터셋입니다.
LOFT (어려운 검색 부분집합)은 300개 쿼리의 긴 컨텍스트 다중 홉 및 다중 니들 검색 평가입니다 (Lee et al., 2024). 다른 모델들과 비교 가능하도록 최대 128K 평균 컨텍스트 길이 변형과 모델의 전체 길이에서의 능력을 보여주는 1M 컨텍스트 윈도우의 점별 값 두 가지 변형에 대한 결과를 보고합니다.
MRCR-V2 (8-needle)는 MRCR 계열의 긴 컨텍스트 평가 중 상당히 더 어려운 인스턴스입니다 (Vodrahalli et al., 2024). MRCR-V1과 비교하여 스타일 매개변수를 포함하여 사전 중첩 깊이를 2가 아닌 3으로 증가시켰습니다. 방법론이 이전에 발표된 결과와 비교하여 변경되었으며, 더 어려운 8-니들 버전에 집중합니다.
MMMU는 다학제 대학 수준의 멀티모달 이미지 이해 및 추론 문제입니다 (Yue et al., 2024).
Vibe-Eval (Reka)는 특히 도전적인 예시를 특징으로 하는 이미지 이해 평가입니다 (Padlewski et al., 2024). Gemini를 판정자로 사용합니다.
ZeroBench는 다단계 추론이 필요한 도전적인 이미지 이해 평가입니다 (Roberts et al., 2025). Gemini를 판정자로 사용하며 4회 실행의 평균을 보고합니다.
BetterChartQA는 9개의 분리된 능력 버킷을 다루는 포괄적인 차트 이해 평가입니다. 차트 이미지는 웹에서 무작위로 샘플링되고 QA 쌍은 전문 인간 주석자들이 작성하여 차트 스타일의 광범위한 분포와 실제 사례를 반영합니다 (Gemini Team, 2024). Gemini를 판정자로 사용합니다.
FLEURS는 자동 음성 인식을 평가합니다 (Conneau et al., 2023). 모든 모델에 대해 공개 API에 0-shot 쿼리를 사용했습니다. 102개 언어 중 53개 언어의 부분집합을 사용했으며, 모델 응답이 실제 응답과 너무 호환되지 않아 공정하게 점수를 매기기 어려운 언어들을 필터링했습니다. 중국어, 일본어, 한국어, 태국어의 4개 분할 언어를 제외하고는 단어 오류율(WER)을 사용하며, 이들 언어에 대해서는 문자 오류율을 집계합니다.
CoVoST 2는 음성-텍스트 번역을 평가합니다 (Wang et al., 2020). 모든 모델에 대해 공개 API에 0-shot 쿼리를 사용했습니다. 21개 언어를 영어로 번역하는 BLEU 점수를 보고합니다.
오디오 및 비디오 이해를 위한 추가 벤치마크들도 포함되어 있으며, 각각 특정한 평가 방법론과 처리 매개변수를 가지고 있습니다. 이러한 벤치마크들은 Gemini 2.5 모델들의 멀티모달 능력을 종합적으로 평가하는 데 사용되었습니다.
Gemini Plays Pokémon 추가 세부사항
Gemini Plays Pokémon 에이전트에서 사용되는 모델을 변경하는 것은 성능에 강한 영향을 미쳤습니다.
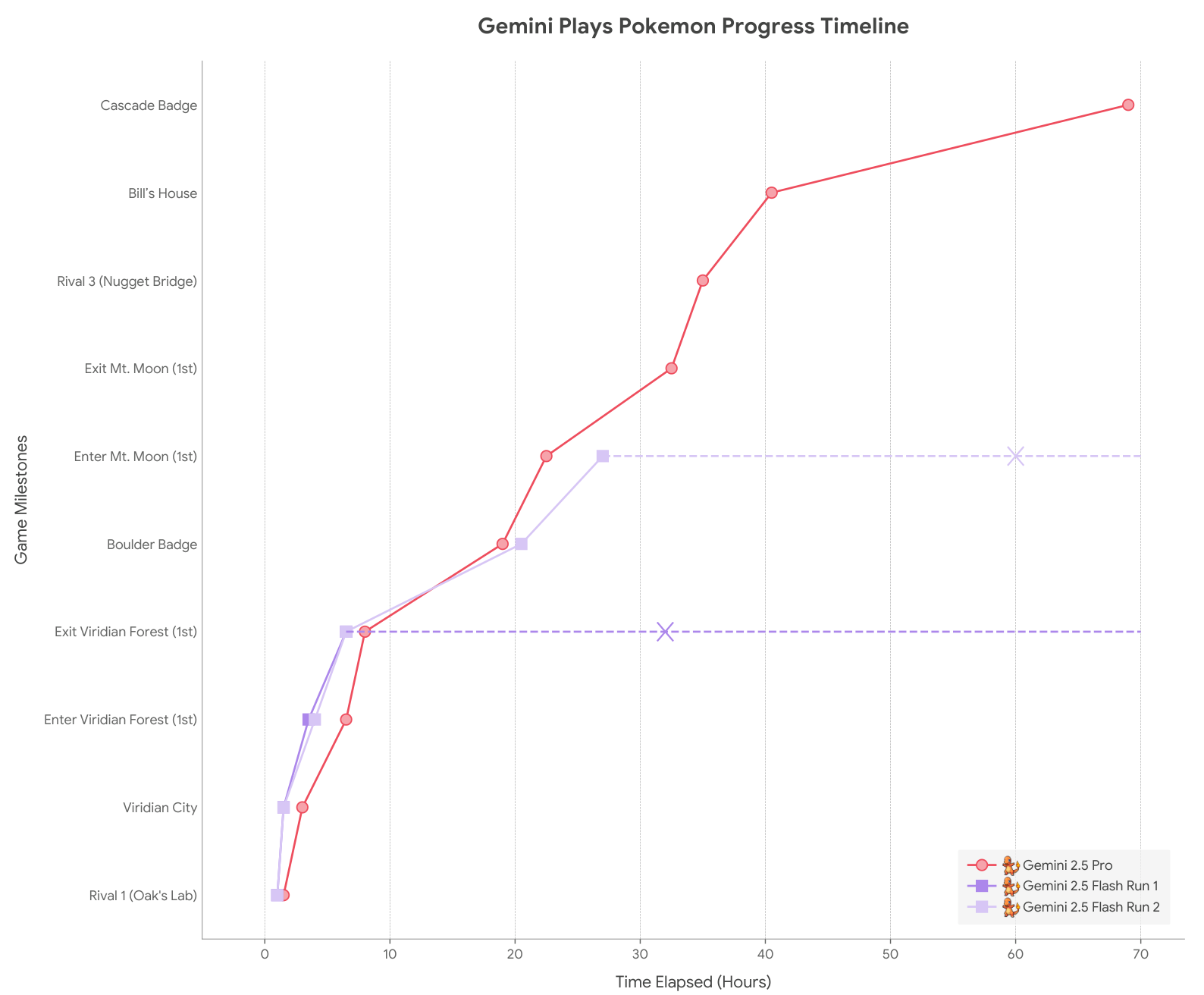
위 그래프는 동일한 에이전틱 하네스를 사용하되 서로 다른 Gemini 모델을 적용했을 때의 성능 차이를 보여줍니다. 모든 실행은 동일한 스타터 포켓몬(파이리)을 사용했습니다. 시간 단위로 측정하는 것은 각 2.5 Flash의 액션이 상당히 빠르다는 사실을 제어하는 역할도 합니다(비록 목표를 달성하기 위해 더 많은 실제 액션이 필요하지만). X 표시는 게임플레이의 종료를 나타내며 다음 이정표를 완료하는 데 걸리는 시간의 하한선입니다.
추가 하네스 세부사항
Gemini Plays Pokémon 에이전트는 RAM 정보의 부분집합을 받으며, 이는 게임을 플레이하기에 충분한 정보를 제공하도록 의도되었고, 게임보이 화면의 스크린샷과 부분적으로 겹쳐집니다. Gemini는 포켓몬 블루를 플레이하고 있으며 게임을 이기는 것이 목표라고 알려주는 시스템 프롬프트와 함께, 비전에서 텍스트로의 번역에서 관례를 이해하는 데 도움이 되는 설명 정보와 게임플레이를 위한 소수의 일반적인 팁을 받습니다.
그런 다음 Gemini는 버튼 누르기로 번역되는 액션을 취합니다. 액션 시퀀스는 컨텍스트에 저장되고, 100턴마다 요약 정리가 이어집니다. 요약들도 컨텍스트에 저장됩니다. 1000턴마다 GPP는 기존 요약들을 다시 압축합니다.
또한 Gemini는 세 가지 주요 목표(1차, 2차, 3차)와 여러 추가 목표(비상 계획, 준비, 탐험, 팀 구성)를 추적합니다. 25턴마다 다른 프롬프트된 Gemini 인스턴스(Guidance Gemini, 또는 GG)가 메인 Gemini와 동일한 컨텍스트를 관찰하고 성능을 비판하며 환각 등을 지적하려고 시도합니다.
오버월드 안개-전쟁 지도는 XML로 컨텍스트에 저장되며, 보지 못한 좌표는 탐험할 때까지 볼 수 없습니다. 중요한 것은 시스템 프롬프트에서 Gemini가 탐험하도록 지시받는다는 점입니다. 타일이 탐험되면 좌표가 자동으로 지도 메모리에 저장되고 방문 카운터로 라벨링됩니다. 타일들은 또한 유형별로 라벨링되며(물, 땅, 자를 수 있는, 풀, 스피너 등), 다른 지도로의 워프 포인트들도 그렇게 라벨링됩니다.
Gemini는 또한 두 개의 에이전틱 도구에 접근할 수 있는데, 이들은 모두 더 전문화된 프롬프트를 갖춘 Gemini 인스턴스들입니다 - pathfinder 도구와 boulder_puzzle_strategist 도구입니다.
pathfinder 프롬프트에서 Gemini는 경로 찾기 알고리즘을 정신적으로 시뮬레이션하도록 프롬프트되며(구체적으로 명시되지 않음), 사용 가능한 지도 정보에 대해 경로가 유효한지 확인하도록 합니다. boulder_puzzle_strategist 도구에서 Gemini는 포켓몬 블루의 챔피언 로드 던전에 있는 특별한 바위 퍼즐을 해결하도록 프롬프트됩니다 - 이러한 퍼즐은 소코반 게임과 유사합니다 - 다시 액션 시퀀스를 정신적으로 시뮬레이션하여 퍼즐의 해결책으로 이어지도록 합니다.
프롬프트는 바위 퍼즐의 물리학과 작업을 설명하고 해결책의 원하는 출력을 설명합니다. 이 도구는 Gemini가 챔피언 로드에서 4개 퍼즐 중 2개를 스스로 해결한 후에 추가되었지만, 3번째와 4번째 퍼즐에서 진행이 느려졌습니다.
능력의 추가 예시
긴 컨텍스트 에이전틱 도구 활용
모델은 자동 이동이 방향으로만 지정되는 미로를 통한 복잡한 경로를 식별할 수 있습니다(로켓단 아지트 스피너 퍼즐), 제한된 자원으로 여러 지도에 걸친 다중 최단 경로 문제를 해결할 수 있습니다(사파리존), 큰 설명 길이를 가진 미로에서 미로 해결을 수행할 수 있습니다(13번 도로), 그리고 다중 지도 3D 미로에 걸친 복잡한 바위 밀기 퍼즐을 해결할 수 있습니다(쌍둥이섬).
이러한 문제들을 문제의 텍스트 설명만으로 해결할 수 있다는 것은 더욱 인상적입니다. 반면 Gemini 2.5 Flash와 같은 다른 모델들은 유사하게 긴 경로 찾기 작업을 수행할 수 없었고, 종종 더 간단한 경로를 찾는 데 실패했습니다. 이러한 격차는 다른 평가에서도 입증된 바와 같이 Gemini 2.5 Pro의 우수한 긴 컨텍스트 추론 능력을 강조합니다.
boulder_puzzle_strategist도 마찬가지로 인상적입니다. 포켓몬 블루의 바위 퍼즐은 플레이어 캐릭터가 스위치 위에 바위를 조작하고 구멍을 통해 밀어서 여러 레벨이 있는 동굴을 통한 경로를 열어야 하는 소코반과 같은 퍼즐입니다. 퍼즐은 상당히 복잡해질 수 있으며, 퍼즐을 해결하기 위해 긴 우회 경로와 다중 레벨 이동이 필요합니다. 바위 물리학을 설명하고 유효한 경로를 확인하는 방법을 설명하는 프롬프트만으로 Gemini 2.5 Pro는 챔피언 로드를 통과하는 데 필요한 이러한 복잡한 바위 퍼즐 중 일부를 원샷으로 해결할 수 있습니다.
pathfinder와 boulder_puzzle_strategist는 현재 Gemini Plays Pokémon 개발자가 구현한 유일한 두 에이전틱 도구입니다. 향후 실행에서는 모델이 프롬프트만으로 새로운 도구를 만들 수 있는 도구 생성 도구를 탐색할 계획입니다. pathfinder와 boulder_puzzle_strategist를 위한 프롬프트의 대부분이 실제로 Gemini 2.5 Pro 자체에 의해 작성되었기 때문에, 현재 2.5 Pro 모델에 대해 자율적 도구 생성이 가능할 것으로 보입니다.
일반적 추론
Gemini 2.5 Pro는 포켓몬의 복잡한 게임 퍼즐을 상당히 잘 추론할 수 있습니다. 이 섹션에서는 두 가지 예시를 제시합니다.
빠르게 도망치는 포켓몬 잡기: 실행 중 하나에서 Gemini 2.5 Pro 에이전트는 아브라를 잡으려고 시도했고, 피카츄의 전기자석파를 사용하여 아브라를 마비시켜 아브라가 순간이동으로 전투에서 벗어날 가능성을 줄이는 동시에 포획률을 향상시키는 계획을 세웠습니다. 여러 번의 시도 후에 에이전트는 이 전략으로 아브라를 잡았습니다.
게임 I/O의 버그로 인한 소프트락에서 창의적으로 탈출: 자전거 도로에서 경사면은 장애물이 없는 한 항상 남쪽으로 이동을 강제합니다. 자전거 도로에는 이러한 행동의 결과로 소프트락을 일으키는 두 개의 타일이 있다는 것이 밝혀졌습니다. GPP 프레임워크에서 버튼 누르기는 시간 지연에 의해 제한되며, 플레이어가 이 두 타일에서 벗어나려면(모든 면이 북쪽을 제외하고 막혀 있음) GPP 프레임워크가 허용하는 것보다 더 빠르게 버튼 누르기 시퀀스를 입력해야 합니다.
Gemini 2.5 Pro는 불행히도 이 두 지점 중 하나에 자신을 발견했습니다 - 다행히도 소프트락이 아니었는데, 2.5 Pro가 이미 파티 멤버 중 하나에게 HM02 FLY를 가르쳤기 때문입니다 - 이는 가본 적이 있는 모든 마을로 이동할 수 있게 해줍니다. FLY는 일반적으로 탈출 메커니즘으로 사용되지 않습니다(이 상황에서 실패하는 ESCAPE ROPE 아이템과 DIG 기술과 달리). 탈출을 위한 많은 접근법을 시도한 4시간 후(이동, ESCAPE ROPE, DIG 포함, 모두 차단됨), Gemini 2.5 Pro 에이전트는 FLY를 사용하여 소프트락에서 성공적으로 탈출하는 아이디어를 생각해냈습니다.
이러한 추론 행동은 이 상황이 기존 게임에서는 절대 발생할 수 없기 때문에 특히 인상적이며 - 따라서 이 행동에 대한 훈련 데이터의 정보가 모델의 지식 베이스로 유출되지 않았다는 것이 확실합니다!
장기 과제 일관성
포켓몬 블루 전반에 걸쳐 Gemini 2.5 Pro가 GPP 하네스에서 해결할 수 있었던 더 짧은 계획 시퀀스의 몇 가지 추가적인 흥미로운 사례 연구가 있습니다.
다가오는 전투를 위한 팀 훈련: 파이리(불꽃 타입 스타터)를 선택한 한 실행에서 Gemini 2.5 Pro는 물 타입 체육관 리더인 이슬이에게 처음에 졌습니다. 재대결을 준비하기 위해 Gemini 2.5 Pro는 24시간 이상을 피카츄와 모다피(둘 다 물 타입에 효과적)를 총 약 25레벨 정도 레벨업시키는 데 보내어 이슬이를 성공적으로 물리쳤습니다.
게임 진행을 위한 비밀기계(HM) 획득: 게임의 많은 부분에서 게임 진행이 가능하기 전에 먼저 HM을 획득하는 것이 필요합니다. 두 가지 예시는 HM01 CUT과 HM05 FLASH입니다. CUT과 FLASH를 사용할 수 있는 능력을 획득하는 것은 각각 네 단계가 필요합니다. 1) HM 아이템 자체를 얻기, 2) 기술을 배울 수 있는 호환 가능한 포켓몬 획득하기, 3) 호환 가능한 포켓몬을 플레이어 팀에 추가하기, 4) 호환 가능한 포켓몬에게 HM 기술 가르치기. 많은 경우에 각 단계는 그 자체로 많은 단계를 필요로 합니다.
사파리존 해결: 사파리존은 필요한 HM들(HM03 SURF와 HM04 Strength 둘 다)이 있는 또 다른 위치입니다. 그러나 추가 제약이 있습니다 - 매번 입장하는 데 500¥가 필요하고, 플레이어는 사파리존에서 총 500보로 제한됩니다. 결과적으로 플레이어가 제한된 단계 수에서 필요한 아이템에 도달할 수 없으면 플레이어는 500¥를 잃고 다시 시작해야 합니다! 결과적으로 플레이어가 사파리존을 완료하기 위해 너무 많은 시도를 하면 본질적으로 소프트락이 가능합니다. 사파리존 자체를 해결하는 것은 네 개의 서로 다른 지도를 가로지르며 길을 잃지 않는 것을 요구합니다. Gemini 2.5 Pro는 실행 1에서 17번의 시도로, 실행 2에서 단 5번의 시도로 필요한 HM 둘 다를 얻을 수 있었습니다.
던전에서 숨겨진 열쇠 찾기: 포켓몬에서 진행하는 또 다른 방법은 숨겨진 열쇠를 찾고 복잡한 다층 던전을 해결하는 것입니다. 특히 로켓단 아지트에서 플레이어는 4층 지하(특정 로켓단 부하를 이긴 후 떨어뜨림)에서 LIFT KEY를 회수하여 엘리베이터를 잠금 해제하고 로켓단의 악한 리더 비주기를 찾아야 합니다. 실프 주식회사에서 플레이어는 CARD KEY를 찾아 여러 문을 열고 건물의 11층을 가로질러 비주기로부터 사장을 구출하는 경로를 찾아야 합니다. 홍련섬의 일곱 번째 체육관을 열기 위해 플레이어는 포켓몬 저택에 들어가 3층을 가로질러 체육관 문을 여는 SECRET KEY를 찾아야 합니다.
이 모든 경우들은 많은 수의 액션에 걸쳐 목표를 유지하고 많은 지역 퍼즐(로켓단 아지트의 스피너 퍼즐, 포켓몬 저택의 스위치 퍼즐 등)을 해결하는 것과 더불어 플레이어 팀의 포켓몬 건강 관리, 야생 조우 관리, 트레이너 전투, 기타 아이템들을 관리하는 것을 요구합니다.
복잡한 다층 던전에서의 퍼즐 해결: 쌍둥이섬은 플레이어가 HM04 STRENGTH를 사용하여 미로를 탐색하고 여러 층에 걸쳐 구멍을 통해 바위를 밀어서 이 어려운 던전의 다양한 위치에서 HM03 Surf를 사용하는 것을 방해하는 빠르게 움직이는 물살을 차단해야 하는 5층을 포함하는 여러 바위 퍼즐을 포함합니다. 결과적으로 플레이어는 목표(특정 물살을 차단하기 위해 두 개의 바위를 제자리에 밀어넣기)를 추론하고 나가는 길을 찾기 위해 다층(효과적으로 3D) 미로 해결에 참여하기 위해 다섯 개의 서로 다른 지도에 걸쳐 정보를 추적해야 합니다. 이는 아마도 게임에서 가장 도전적인 던전일 것입니다. GPP의 두 번째 실행만이 쌍둥이섬을 통과했는데, 이는 진행에 필요하지 않기 때문입니다.
추가 도전과제
환각과 망상에 대한 고착
게임 지식이 때때로 유출되어 모델이 진행하는 능력에 상당히 유익할 수 있지만, 환각, 망상, 그리고 다른 세대의 포켓몬 게임과의 혼동으로 인해 놀라운 방식으로 모델을 방해할 수도 있습니다.
이러한 현상의 한 예는 TEA 아이템입니다. 포켓몬 레드/블루에서 한 지점에서 플레이어는 자판기에서 음료(FRESH WATER, SODA POP, 또는 LEMONADE)를 구매하여 목마른 경비원에게 건네주어야 하며, 그러면 경비원이 플레이어를 통과시켜 줍니다. 게임의 리메이크인 포켓몬 파이어레드/리프그린에서는 대신 원래 게임에는 존재하지 않는 특별한 TEA 아이템을 목마른 경비원에게 가져다주어야 합니다. Gemini 2.5 Pro는 여러 지점에서 진행하기 위해 TEA를 회수해야 한다고 생각하는 망상에 빠졌고, 결과적으로 TEA를 찾거나 경비원에게 TEA를 주려고 시도하는 데 많은 시간을 보냈습니다.
실행 2에서 모델은 게임에 완전히 새로운 플레이어로 행동하고, 게임 이벤트, 아이템 위치, 포켓몬 스폰 지점에 대한 사전 지식을 무시하도록 명시적으로 프롬프트되어 모델 사전 훈련 지식으로부터의 환각을 완화하고 모델의 게임 추론 능력에 대한 더 깨끗한 테스트를 수행하려고 시도했습니다. 이것은 적어도 부분적으로 작동한 것으로 보입니다 - 다른 게임으로부터의 여러 환각이 두 번째 실행에서 피해졌습니다. 반면에 이 프롬프트는 또한 게임에 대한 상식 지식을 활용하는 모델의 능력을 해쳤을 수도 있어 몇 가지 중요한 장소에서 전반적인 성능을 방해했습니다.
목표 설정과 Guidance Gemini 인스턴스로 인한 망상에 대한 고착은 Gemini Plays Pokémon을 보는 데 있어 드문 일이 아닙니다 - TEA 사건은 이러한 행동의 유일한 예가 아닙니다. 이 문제의 특히 심각한 형태는 "컨텍스트 중독"으로 발생할 수 있습니다 - 컨텍스트의 많은 부분(목표, 요약)이 게임 상태에 대한 잘못된 정보로 "중독"되어 실행 취소하는 데 매우 오랜 시간이 걸릴 수 있습니다. 결과적으로 모델은 불가능하거나 관련 없는 목표를 달성하는 데 고착될 수 있습니다. 이러한 망상은 위에서 언급한 루핑 문제와도 밀접하게 관련되어 있습니다.
이러한 망상들은 인간에게는 명백히 말이 안 되지만("집 입구를 통해 들어갔다가 다시 나와보자. 그러면 입구를 막고 있는 경비원이 움직일지도 모른다"), 컨텍스트의 많은 곳에서 중독시키는 덕분에 모델이 상식을 무시하고 동일한 잘못된 진술을 반복하게 만들 수 있습니다. 컨텍스트 중독은 또한 모든 파티의 포켓몬을 기절시켜 "기절"하고 가장 가까운 포켓몬 센터로 순간이동하며 돈의 절반을 잃는 대신 떠나려고 시도하는 "기절" 전략과 같은 전략으로 이어질 수 있습니다.
사고 패턴의 위상학적 함정
Gemini 2.5 Pro에게 특히 해결하기 어려운 퍼즐과 미로에서 반복되는 패턴 중 하나는 "위상학적 함정"으로 구성됩니다 - 미로나 퍼즐을 해결하는 데 필요한 추론 그래프의 위상학이 독특한 모양을 가지고 있습니다. 즉, 원하는 목표가 가까이 있고 쉽게 도달할 수 있는 것처럼 보이지만("어트랙터"), 올바른 해결책은 올바른 해결책에 도달하기 위해 우회로를 택하는 것을 요구합니다. 우리는 게임의 여러 부분에서 이 현상을 관찰했습니다.
로켓단 아지트 B3F의 스피너 퍼즐에서 지도는 아이템과 올바른 계단을 모두 남쪽에 배치하지만, 이들은 긴 우회로를 통해서만 접근할 수 있습니다. 13번 도로 미로는 위쪽 좁은 통로라는 단 하나의 올바른 경로만을 가지고 있습니다. 마지막으로 챔피언 로드 3F 바위 퍼즐은 플레이어가 오른쪽 위의 바위를 왼쪽 위 스위치까지 밀어야 하며, 남쪽의 바위 퍼즐, 사다리, 출구들을 무시해야 합니다.
주목할 점은 모델이 주어진 퍼즐을 한 번에 해결하도록 지시받으면(예: pathfinder를 통해) 컨텍스트 길이가 너무 길지 않다면 그렇게 할 수 있다는 것입니다. 예를 들어, Gemini 2.5 Pro로 구현된 pathfinder는 B3F 스피너 함정을 원샷으로 해결할 수 있습니다.
에이전트 패닉
플레이 과정에서 Gemini 2.5 Pro는 모델이 "패닉"을 시뮬레이션하게 만드는 다양한 상황에 빠집니다. 예를 들어, 파티의 포켓몬 체력이나 파워 포인트가 낮을 때, 모델의 생각은 파티를 즉시 치료하거나 현재 던전에서 탈출해야 한다는 필요성을 반복적으로 재확인합니다(예: 유명하게 DIG 기술이나 ESCAPE ROPE 아이템 사용). 상당히 흥미롭게도, 이러한 모델 성능 모드는 모델의 추론 능력에서 질적으로 관찰 가능한 저하와 상관관계가 있는 것으로 보입니다 - 예를 들어, 이 조건이 지속되는 게임플레이 구간에서 pathfinder 도구를 사용하는 것을 완전히 잊어버리는 것입니다.
이러한 행동은 충분히 많은 별도의 인스턴스에서 발생하여 Twitch 채팅의 구성원들이 그것이 발생하고 있을 때 적극적으로 알아차렸습니다.
액션 대 게임 이정표
완전성을 위해 각 게임 이정표를 달성하는 데 필요한 액션/단계 수를 플롯합니다. 액션은 에이전트가 게임에 버튼 누르기 시퀀스를 출력하는 각 버킷된 인스턴스로 구성됩니다(다른 포켓몬을 플레이하는 AI 에이전트들은 액션당 다른 수의 버튼 누르기를 출력하거나, 버튼 누르기를 다르게 정의하거나, 액션/단계를 다르게 정의할 수 있음에 주목). 그러나 에이전트의 성능에 대한 전체 그림을 얻기 위해서는 시간 및/또는 비용과 함께 액션-이정표 플롯을 고려하는 것이 중요합니다.
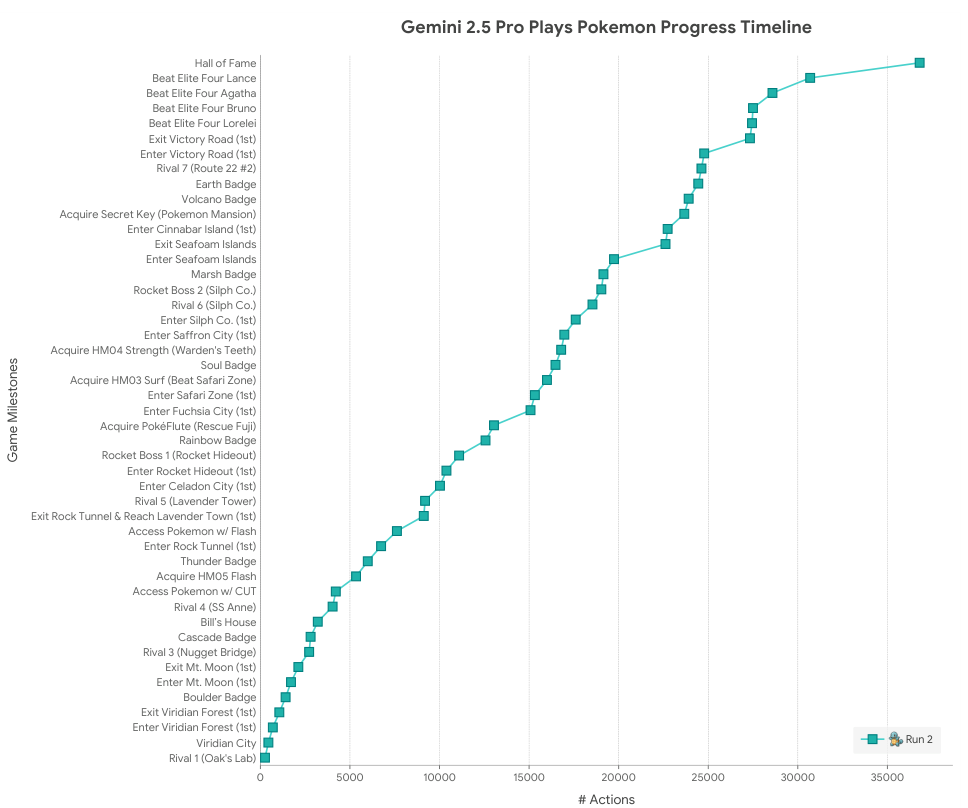
위 그래프는 시간 대신 액션 수를 기준으로 한 진행도를 보여줍니다. (a)는 완전 자율 실행 2의 이정표를 개별 액션 수의 함수로 보여주고, (b)는 이정표까지의 액션 측면에서 2.5 Pro와 2.5 Flash를 비교합니다.
프론티어 안전 프레임워크 평가 추가 세부사항: 프론티어 안전 정확성 테스트
각 테스팅 환경에 대해 에이전트들이 어떻게 행동했는지 살펴보는 기본적인 정확성 검사를 수행했습니다. 이는 에이전트의 액션을 플래그하는 잠재적 문제들에 대한 AI와 수동 검토를 결합하는 것을 포함했습니다. RE-Bench에서는 최고, 중간, 최저 점수 궤적을 검토했습니다. 사이버보안 환경(InterCode CTF, 내부 CTF, Hack the Box)의 경우, 각 환경에서 적어도 하나의 성공적인 시도(가능한 경우)를 신중히 검사했고, 그렇지 않으면 실패한 시도를 검토했습니다. 또한 샘플 상황 인식 및 은밀성 평가에 대한 검사도 수행했습니다. 이는 프롬프트와 셸 출력이 올바르게 형식화되었는지 확인하는 기본적인 점검을 포함했습니다.
전반적으로 벤치마크의 결과를 무효화할 것으로 믿어지는 오류는 관찰되지 않았습니다.
이미지-코드 데모
Gemini 1.5 Pro와 Gemini 2.5 Pro에게 이미지의 SVG 표현을 생성하도록 프롬프트했고, Gemini 2.5 Pro가 더 나은 재구성을 생성한다는 것을 발견했습니다.
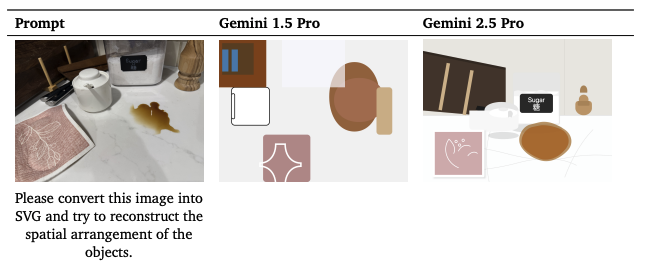
위 그림은 이미지-SVG 재구성 프롬프트에 대한 Gemini 1.5 Pro와 Gemini 2.5 Pro 응답의 비교를 보여줍니다. Gemini 2.5 Pro가 훨씬 더 많은 시각적 세부사항을 재구성하고 객체의 공간적 배치가 원본 이미지를 더 잘 닮도록 합니다.
긴 컨텍스트 비디오 이해 데모
전체 비디오와 다음 프롬프트로 Gemini에게 프롬프트하여 전체 46분 중에서 매우 특정한 장면(단 1초만 지속)을 찾는 능력을 평가했습니다.
비디오 (46분): Redefining Robotics with Carolina Parada 프롬프트: 로봇 팔들이 접으려고 하는 티셔츠의 색깔은 무엇이고, 이것이 발생하는 타임코드는 언제입니까?

위 그림은 모델이 회상해야 하는 프레임과 타임스탬프를 보여줍니다. https://www.youtube.com/watch?v=Rgwty6dGsYI의 타임스탬프 27:29에서 가져왔습니다.
| 모델 | 시행 | 모델 응답 |
|---|---|---|
| Gemini 1.5 Pro | 1 | 로봇 팔들이 접으려고 하는 티셔츠는 진한 청록색 또는 터키석 파란색입니다. 접기는 [11:06–11:15]에서 시작되어 계속됩니다. |
| 2 | 티셔츠는 주황색이고, 로봇이 [00:00:26–00:00:28]부터 접으려고 하는 것을 볼 수 있습니다. | |
| 3 | 접히고 있는 티셔츠는 진한 파란색이고 [00:00:56–00:00:58]과 [00:07:56–00:07:59] 사이에서 볼 수 있습니다. | |
| 2.5 Pro Preview 05-06 | 1 | 로봇 팔들이 접으려고 하는 티셔츠는 파란색입니다. 이 장면은 타임코드 27:29에서 발생합니다. |
| 2 | 로봇 팔들이 접으려고 하는 티셔츠는 파란색입니다. 이것은 타임코드 27:26에서 발생합니다. | |
| 3 | 로봇 팔들이 상호작용하고 있는 티셔츠(화자가 언급한 "빨래 접기" 작업의 일부로)는 파란색입니다. 이것은 타임스탬프 0:27:28에서 발생합니다. |
Gemini 1.5 Pro는 3건 중 1건에서 색깔을 맞추고, 3건 중 0건에서 타임스탬프를 맞춥니다(상당히 멀리 떨어져 있음). Gemini 2.5 Pro는 3건 중 3건에서 색깔을 맞추고, 3건 중 1건에서 타임스탬프를 맞춥니다(나머지 3건 중 2건은 3초 이내로 가까움).
이러한 결과는 Gemini 2.5 Pro가 긴 비디오 콘텐츠에서 특정 시각적 이벤트를 정확하게 회상하는 데 있어 이전 버전보다 현저히 향상된 능력을 보여줍니다.
References
Subscribe via RSS