Gemma 3 Technical Report
by Google DeepMind
TL;DR
이 연구를 시작하게 된 배경과 동기는 무엇입니까?
대규모 언어 모델의 발전은 AI 기술의 핵심 동력으로 자리 잡았지만, 기존 모델들은 여전히 심각한 한계를 가지고 있었습니다. 특히 긴 컨텍스트 처리의 메모리 비효율성, 제한된 멀티모달 능력, 그리고 다국어 성능의 불균형은 AI 시스템의 실용성을 크게 제한하는 주요 문제였습니다. Google DeepMind 연구팀은 이러한 근본적인 기술적 제약을 극복하고, 더욱 접근성 높고 효율적인 AI 모델을 개발하고자 Gemma 3 프로젝트를 시작했습니다.
연구팀은 기존 언어 모델들이 계산 자원과 메모리 사용량 측면에서 비효율적이며, 실제 응용 환경에서 제한적인 성능을 보인다는 점을 깊이 인식하고 있었습니다. 특히 표준 소비자급 하드웨어에서 실행 가능한 고성능 AI 모델의 필요성이 증대되고 있었으며, 이는 AI 기술의 민주화를 위한 핵심 과제였습니다. 이러한 배경에서 Gemma 3는 계산 효율성, 멀티모달 능력, 그리고 광범위한 언어 지원을 동시에 달성할 수 있는 혁신적인 접근법을 모색하게 되었습니다.
이 연구에서 제시하는 새로운 해결 방법은 무엇입니까?
Gemma 3의 가장 혁신적인 기술적 해결책은 로컬-글로벌 어텐션 메커니즘의 도입입니다. 이 접근법은 5개의 로컬 어텐션 레이어마다 1개의 글로벌 어텐션 레이어를 배치하여, 긴 컨텍스트 처리 시 발생하는 메모리 비효율성 문제를 근본적으로 해결합니다. 로컬 어텐션 레이어는 1024 토큰의 제한된 범위만을 처리하는 반면, 글로벌 어텐션 레이어는 전체 128K 토큰 컨텍스트에 접근할 수 있어 메모리 사용량을 획기적으로 줄이면서도 장거리 의존성을 효과적으로 포착할 수 있습니다.
또 다른 핵심 혁신은 멀티모달 능력의 통합입니다. SigLIP 비전 인코더와 Pan & Scan 알고리즘을 결합하여 다양한 해상도와 종횡비의 이미지를 효과적으로 처리할 수 있게 했습니다. 특히 Pan & Scan 방법은 고정 해상도의 한계를 극복하고, 이미지의 중요한 시각적 정보를 놓치지 않고 처리할 수 있게 해줍니다. 이러한 접근법은 DocVQA에서 최대 8.2점, InfoVQA에서 최대 17.0점의 성능 향상을 달성했습니다.
제안된 방법은 어떻게 구현되었습니까?
Gemma 3의 구현은 지식 증류와 혁신적인 후훈련 레시피를 중심으로 이루어졌습니다. 사전 훈련 과정에서는 14조 토큰에 이르는 대규모 데이터셋을 사용하였으며, 다국어 데이터의 비중을 크게 확장했습니다. 특히 Chung et al.의 접근법을 참고하여 저자원 언어들의 성능을 향상시키면서도 주요 언어들의 성능을 유지하는 균형 잡힌 접근을 취했습니다.
후훈련 단계에서는 BOND, WARM, WARP 기법들의 개선된 버전을 활용한 강화학습 파인튜닝을 수행했습니다. 이 과정에서 다양한 보상 함수를 조합하여 모델의 수학, 코딩, 추론 능력을 동시에 향상시켰습니다. 특히 지식 증류 과정에서는 256개의 로짓을 샘플링하고, 교사 모델의 확률 분포를 학습하는 방식으로 계산 효율성을 높이면서도 지식 전달의 정확성을 유지했습니다.
이 연구의 결과가 가지는 의미는 무엇입니까?
Gemma 3의 성과는 AI 기술의 실용성과 접근성 측면에서 매우 중요한 의미를 갖습니다. LMSYS Chatbot Arena에서 1,338점의 Elo 점수를 기록하며 전체 순위 9위에 올랐고, 405B 매개변수를 가진 LLaMA 3.1 모델을 능가하는 성능을 보였습니다. 특히 27B 모델이 Gemini-1.5-Pro와 비교 가능한 수준의 성능을 달성한 것은 매개변수 효율성 측면에서 획기적인 성과입니다.
더욱 주목할 만한 점은 모델의 안전성과 프라이버시 보호 측면입니다. 기존 모델들과 비교하여 현저히 낮은 기억화 비율을 보였으며, 기억화된 출력에서 개인정보가 전혀 관찰되지 않았습니다. 이는 오픈 소스 모델의 안전한 배포 가능성을 크게 높이는 중요한 성과입니다. 또한 ShieldGemma 2와 같은 안전 분류기 개발을 통해 AI 기술의 책임감 있는 활용 가능성을 보여주었습니다.
Gemma 3 Technical Report
서론
Gemma 3는 Google DeepMind에서 개발한 경량 오픈 모델 패밀리인 Gemma의 최신 멀티모달 버전입니다. 이 모델은 1억부터 270억 개의 매개변수 범위에서 제공되며, 기존 Gemma 모델들과 비교하여 세 가지 핵심적인 새로운 능력을 도입했습니다.
주요 혁신 사항
첫 번째 혁신은 비전 이해 능력의 추가입니다. Gemma 3는 텍스트와 이미지를 동시에 처리할 수 있는 멀티모달 아키텍처를 채택했습니다. 이는 맞춤형 SigLIP 비전 인코더를 통해 구현되었으며, 언어 모델이 이미지를 소프트 토큰의 시퀀스로 처리할 수 있게 합니다. 비전 임베딩을 256개의 고정 크기 벡터로 압축하여 이미지 처리의 추론 비용을 크게 줄였습니다.
두 번째 혁신은 긴 컨텍스트 지원입니다. Gemma 3는 최소 128K 토큰까지의 컨텍스트를 처리할 수 있으며, 이는 기존 버전 대비 상당한 확장입니다. 긴 컨텍스트 처리 시 발생하는 KV 캐시 메모리 폭발 문제를 해결하기 위해 혁신적인 아키텍처 설계를 도입했습니다.
세 번째 혁신은 다국어 능력의 확장입니다. 사전 훈련 데이터 혼합을 재검토하여 더 넓은 범위의 언어에 대한 성능을 향상시켰습니다.
아키텍처 혁신: 로컬-글로벌 어텐션 메커니즘
Gemma 3의 가장 중요한 아키텍처 혁신은 로컬 어텐션과 글로벌 어텐션 레이어의 인터리빙 구조입니다. 이 설계는 긴 컨텍스트 처리 시 메모리 효율성을 크게 개선합니다.
구체적으로, 모델은 5개의 로컬 어텐션 레이어마다 1개의 글로벌 어텐션 레이어를 배치합니다. 로컬 어텐션 레이어는 1024 토큰의 제한된 스팬만을 처리하는 반면, 글로벌 어텐션 레이어만이 전체 128K 토큰 컨텍스트에 접근합니다. 이러한 설계를 통해 메모리 사용량을 대폭 줄이면서도 긴 컨텍스트의 정보를 효과적으로 활용할 수 있습니다.
이 접근법은 Longformer에서 제안된 슬라이딩 윈도우 어텐션 개념을 발전시킨 것으로, 로컬 패턴과 글로벌 의존성을 모두 포착할 수 있는 효율적인 메커니즘을 제공합니다.
이미지 처리: Pan and Scan 방법
비전 처리를 위해 Gemma 3는 LLaVA에서 영감을 받은 Pan and Scan (P&S) 방법을 도입했습니다. 이 방법은 고정 해상도에서 작동하는 인코더의 한계를 극복하여 유연한 해상도 처리를 가능하게 합니다.
P&S 방법은 비정사각형 종횡비와 고해상도 이미지를 효과적으로 처리할 수 있도록 적응적 윈도잉을 수행합니다. 이를 통해 다양한 크기와 형태의 이미지에서 중요한 시각적 정보를 놓치지 않고 처리할 수 있습니다.
지식 증류를 통한 성능 향상
모든 Gemma 3 모델은 지식 증류 기법을 사용하여 훈련되었습니다. 이는 더 큰 교사 모델의 지식을 작은 학생 모델로 전달하는 방법으로, 모델 크기 대비 성능을 크게 향상시킵니다.
지식 증류 과정에서 학생 모델은 교사 모델이 생성하는 소프트 타겟을 학습합니다. 이러한 소프트 타겟은 단순한 정답 레이블보다 더 풍부한 정보를 포함하고 있어, 모델이 더 나은 일반화 능력을 획득할 수 있게 합니다.
혁신적인 후훈련 접근법
Gemma 3는 수학, 채팅, 지시 따르기, 다국어 능력을 크게 향상시키는 새로운 후훈련 레시피를 도입했습니다. 이 접근법은 모든 능력 영역에서 일관된 성능 향상을 가져왔으며, 특히 주목할 만한 결과를 달성했습니다.
Gemma3-4B-IT 모델은 Gemma2-27B-IT와 경쟁할 수 있는 성능을 보여주며, Gemma3-27B-IT 모델은 다양한 벤치마크에서 Gemini-1.5-Pro와 비교할 수 있는 수준에 도달했습니다. 이는 모델 크기 대비 놀라운 성능 향상을 의미합니다.
실용적 배포를 위한 설계
Gemma 3 모델들은 스마트폰, 노트북, 고급 GPU와 같은 표준 소비자급 하드웨어에서 실행되도록 설계되었습니다. 이러한 접근성은 AI 기술의 민주화에 중요한 기여를 합니다.

위 그림은 Gemma 3 27B IT 모델과의 시각적 상호작용 예시를 보여줍니다. 모델이 레스토랑 영수증 이미지를 정확히 인식하고 해석할 수 있음을 보여주며, 실제 문서 이해 능력을 입증합니다.
기술적 기여의 의미
Gemma 3의 기술적 혁신들은 여러 측면에서 중요한 의미를 갖습니다. 첫째, 로컬-글로벌 어텐션 메커니즘은 긴 컨텍스트 처리의 메모리 효율성 문제에 대한 실용적 해결책을 제시합니다. 둘째, 멀티모달 능력의 통합은 텍스트와 이미지를 동시에 이해해야 하는 실제 응용 분야에서의 활용 가능성을 크게 확장합니다.
셋째, 지식 증류와 혁신적인 후훈련 방법의 조합은 작은 모델로도 큰 모델에 필적하는 성능을 달성할 수 있음을 보여줍니다. 이는 계산 자원이 제한된 환경에서도 고성능 AI 모델을 활용할 수 있는 길을 열어줍니다.
마지막으로, 모든 모델을 커뮤니티에 공개함으로써 연구와 개발의 투명성을 높이고, AI 기술의 발전에 기여하고자 하는 의지를 보여줍니다. 이러한 오픈 접근법은 AI 연구 생태계 전반에 긍정적인 영향을 미칠 것으로 기대됩니다.
모델 아키텍처
Gemma 3 모델들은 이전 버전들과 마찬가지로 Vaswani et al.에서 제안된 디코더 전용 트랜스포머 아키텍처를 기반으로 합니다. 대부분의 아키텍처 요소들은 첫 번째와 두 번째 Gemma 버전과 유사하지만, 몇 가지 중요한 혁신이 도입되었습니다.
핵심 아키텍처 혁신
Gemma 3의 가장 주목할 만한 특징은 Grouped-Query Attention (GQA)를 사용한다는 점입니다. GQA는 기존의 멀티헤드 어텐션보다 메모리 효율적인 방식으로, 쿼리 헤드들을 그룹으로 나누어 각 그룹이 하나의 키-값 헤드를 공유하도록 합니다. 이는 추론 시 메모리 대역폭을 크게 줄여주면서도 성능 저하를 최소화합니다.
또한 Gemma 3는 post-norm과 pre-norm을 모두 사용하는 RMSNorm을 적용합니다. RMSNorm은 LayerNorm보다 계산 효율적이면서도 안정적인 훈련을 가능하게 하는 정규화 기법입니다. 수식으로 표현하면 다음과 같습니다.
\[\text{RMSNorm}(x) = \frac{x}{\sqrt{\frac{1}{d}\sum_{i=1}^{d}x_i^2 + \epsilon}} \cdot g\]여기서 $x$는 입력 벡터, $d$는 차원 수, $\epsilon$은 수치적 안정성을 위한 작은 상수, $g$는 학습 가능한 스케일 파라미터입니다.
QK-Norm의 도입
Dehghani et al.과 Wortsman et al.의 연구에서 영감을 받아, Gemma 3는 Gemma 2에서 사용되던 소프트 캐핑을 QK-norm으로 대체했습니다. QK-norm은 어텐션 계산 전에 쿼리와 키 벡터를 정규화하는 기법으로, 훈련 안정성을 크게 향상시킵니다.
QK-norm의 수학적 표현은 다음과 같습니다.
\[Q' = \text{LayerNorm}(Q), \quad K' = \text{LayerNorm}(K)\] \[\text{Attention}(Q', K', V) = \text{softmax}\left(\frac{Q'K'^T}{\sqrt{d_k}}\right)V\]이 정규화는 어텐션 점수의 분산을 제어하여 그래디언트 폭발이나 소실 문제를 방지합니다.
혁신적인 로컬-글로벌 어텐션 패턴
Gemma 3의 가장 독창적인 아키텍처 혁신은 5:1 로컬-글로벌 레이어 인터리빙입니다. 이는 Longformer에서 제안된 슬라이딩 윈도우 어텐션 개념을 발전시킨 것입니다.
구체적으로, 모델은 5개의 로컬 슬라이딩 윈도우 셀프 어텐션 레이어와 1개의 글로벌 셀프 어텐션 레이어를 번갈아 배치합니다. 첫 번째 레이어는 로컬 레이어로 시작합니다. 이러한 패턴은 다음과 같은 장점을 제공합니다.
로컬 어텐션의 특징:
- 제한된 윈도우 크기(일반적으로 1024 토큰) 내에서만 어텐션을 계산
- 메모리 사용량이 선형적으로 증가 ($O(n \cdot w)$, 여기서 $n$은 시퀀스 길이, $w$는 윈도우 크기)
- 지역적 패턴과 단기 의존성을 효과적으로 포착
글로벌 어텐션의 특징:
- 전체 컨텍스트에 대해 어텐션을 계산
- 장거리 의존성과 전역적 정보 흐름을 담당
- 메모리 사용량이 제곱적으로 증가하지만 전체 레이어 중 일부만 사용
이러한 하이브리드 접근법을 통해 Gemma 3는 긴 컨텍스트를 효율적으로 처리하면서도 전역적 정보 통합 능력을 유지합니다.
긴 컨텍스트 지원
Gemma 3 모델들은 128K 토큰의 컨텍스트 길이를 지원합니다(1B 모델은 32K). 이를 위해 RoPE(Rotary Position Embedding) 기본 주파수를 조정했습니다.
- 로컬 레이어: 기본 주파수 10k 유지
- 글로벌 레이어: 기본 주파수를 10k에서 1M으로 증가
이는 Chen et al.의 위치 보간법과 유사한 과정을 따라 글로벌 셀프 어텐션 레이어의 스팬을 확장합니다. RoPE의 수학적 정의는 다음과 같습니다.
\[f(x, m) = \begin{pmatrix} x_1 \cos(m\theta_1) - x_2 \sin(m\theta_1) \\ x_1 \sin(m\theta_1) + x_2 \cos(m\theta_1) \\ \vdots \\ x_{d-1} \cos(m\theta_{d/2}) - x_d \sin(m\theta_{d/2}) \\ x_{d-1} \sin(m\theta_{d/2}) + x_d \cos(m\theta_{d/2}) \end{pmatrix}\]여기서 $\theta_i = \text{base}^{-2i/d}$이고, base가 더 큰 값일수록 더 긴 시퀀스를 처리할 수 있습니다.
모델 크기별 매개변수 구성
다음 표는 Gemma 3 모델들의 매개변수 구성을 보여줍니다.
| 모델 | 비전 인코더 | 임베딩 매개변수 | 비임베딩 매개변수 |
|---|---|---|---|
| 1B | 0 | 302M | 698M |
| 4B | 417M | 675M | 3,209M |
| 12B | 417M | 1,012M | 10,759M |
| 27B | 417M | 1,416M | 25,600M |
모든 모델은 256k 항목의 어휘를 사용합니다. 4B, 12B, 27B 모델들은 동일한 417M 매개변수의 비전 인코더를 공유하여 효율성을 높입니다.
비전 모달리티 통합
SigLIP 비전 인코더
Gemma 3는 SigLIP 인코더의 400M 변형을 사용합니다. SigLIP은 Vision Transformer 아키텍처를 기반으로 하며, CLIP 손실의 변형으로 훈련됩니다.
비전 인코더는 896 × 896 픽셀로 크기 조정된 정사각형 이미지를 입력으로 받습니다. 이미지는 14 × 14 픽셀 패치로 분할되어 총 64 × 64 = 4,096개의 패치가 생성됩니다. 각 패치는 선형 투영을 통해 임베딩 벡터로 변환됩니다.
\[\text{patch\_embedding} = \text{Linear}(\text{flatten}(\text{patch}))\]비전 인코더는 시각적 어시스턴트 작업 데이터로 파인튜닝되었으며, 단순성을 위해 4B, 12B, 27B 모델 간에 공유되고 훈련 중에는 고정됩니다.
Pan & Scan 알고리즘
고정 해상도 896 × 896에서 작동하는 비전 인코더의 한계를 해결하기 위해, Gemma 3는 Pan & Scan (P&S) 적응형 윈도잉 알고리즘을 도입했습니다. 이 알고리즘은 비정사각형 종횡비와 고해상도 이미지를 처리할 때 발생하는 아티팩트를 해결합니다.
P&S 알고리즘의 작동 원리:
- 이미지 분할: 입력 이미지를 겹치지 않는 동일한 크기의 크롭으로 분할
- 크기 조정: 각 크롭을 896×896 픽셀로 크기 조정
- 인코더 처리: 조정된 크롭들을 비전 인코더에 전달
- 제어 메커니즘: 최대 크롭 수를 제한하여 계산 비용 관리
이 방법은 추론 시에만 적용되는 최적화로, 더 빠른 추론을 위해 비활성화할 수 있습니다. P&S는 특히 텍스트가 포함된 이미지나 작은 객체가 있는 고해상도 이미지에서 성능을 크게 향상시킵니다.
훈련 인프라
Gemma 3 모델들은 다양한 TPU 구성에서 훈련되었습니다.
| 모델 | 타입 | 칩 수 | 데이터 | 시퀀스 | 복제본 |
|---|---|---|---|---|---|
| 1B | TPUv5e | 512 | 16 | 16 | 2 |
| 4B | TPUv5e | 2048 | 16 | 16 | 8 |
| 12B | TPUv4 | 6144 | 16 | 16 | 24 |
| 27B | TPUv5p | 6144 | 24 | 8 | 32 |
이러한 분산 훈련 설정은 데이터, 시퀀스, 복제본 차원에서의 샤딩을 통해 대규모 모델의 효율적인 훈련을 가능하게 합니다.
Gemma 3의 아키텍처 혁신들은 메모리 효율성, 긴 컨텍스트 처리, 멀티모달 능력을 동시에 달성하면서도 표준 하드웨어에서 실행 가능한 실용적인 모델을 만들어냅니다. 특히 로컬-글로벌 어텐션 패턴은 긴 컨텍스트 처리의 메모리 병목 현상을 해결하는 혁신적인 접근법으로 평가됩니다.
사전 훈련
Gemma 3의 사전 훈련은 Gemma 2에서 사용된 지식 증류 방법론을 기반으로 하면서도 멀티모달 능력과 확장된 언어 지원을 위한 중요한 개선사항들을 도입했습니다.
훈련 데이터 확장
Gemma 3는 이전 버전보다 상당히 확장된 토큰 예산으로 훈련되었습니다. 구체적으로 Gemma 3 27B 모델은 14조 토큰, 12B 모델은 12조 토큰, 4B 모델은 4조 토큰, 1B 모델은 2조 토큰으로 훈련되었습니다. 이러한 토큰 수의 증가는 사전 훈련 과정에서 이미지와 텍스트가 혼합된 데이터를 사용하기 때문입니다.
특히 주목할 만한 점은 다국어 데이터의 대폭 확장입니다. 언어 커버리지를 개선하기 위해 단일 언어 데이터와 병렬 데이터를 모두 추가했으며, 언어 표현의 불균형 문제를 해결하기 위해 Chung et al. (2023)에서 영감을 받은 전략을 사용했습니다. 이 접근법은 저자원 언어들에 대한 성능을 향상시키면서도 주요 언어들의 성능을 유지하는 균형잡힌 다국어 모델을 만들어냅니다.
토크나이저 혁신
Gemma 3는 Gemini 2.0과 동일한 토크나이저를 사용합니다. 이는 SentencePiece 토크나이저를 기반으로 하며, 다음과 같은 특징을 갖습니다.
- 분할된 숫자 처리: 숫자를 개별 자릿수로 분할하여 처리
- 공백 보존: 원본 텍스트의 공백 정보를 메타 기호로 보존
- 바이트 레벨 인코딩: 모든 유니코드 문자를 안정적으로 처리
결과적으로 생성된 어휘는 262,144개의 항목을 포함하며, 이는 영어가 아닌 언어들에 대해 더욱 균형잡힌 토큰화를 제공합니다. 이러한 설계는 다국어 성능 향상에 직접적으로 기여합니다.
데이터 필터링과 안전성
Gemma 3의 사전 훈련 데이터는 엄격한 필터링 과정을 거쳤습니다. 이 과정은 여러 단계로 구성됩니다.
안전성 필터링: 원치 않거나 안전하지 않은 발화의 위험을 줄이는 기법들이 적용되었습니다. 특정 개인 정보와 기타 민감한 데이터를 제거하여 모델의 안전성을 보장합니다.
평가 세트 오염 제거: 사전 훈련 데이터 혼합에서 평가 세트를 제거하여 공정한 성능 평가를 보장합니다. 이는 모델이 평가 데이터를 미리 학습하여 성능이 부풀려지는 것을 방지합니다.
암송 위험 감소: 민감한 출력의 확산을 최소화하여 암송 위험을 줄입니다. 이는 모델이 훈련 데이터를 그대로 복사하여 출력하는 것을 방지하는 중요한 안전 장치입니다.
품질 재가중: Sachdeva et al. (2024)에서 영감을 받은 품질 재가중 단계를 적용하여 저품질 데이터의 발생을 줄입니다. 이 방법은 Ask-LLM과 Density 샘플링 기법을 활용하여 고품질 데이터를 선별적으로 활용합니다.
지식 증류 메커니즘
Gemma 3의 지식 증류 과정은 매우 정교하게 설계되었습니다. 각 토큰에 대해 256개의 로짓을 샘플링하며, 이들은 교사 확률에 따라 가중치가 부여됩니다. 학생 모델은 이러한 샘플들 내에서 교사의 분포를 교차 엔트로피 손실을 통해 학습합니다.
수학적으로 이 과정은 다음과 같이 표현됩니다.
\[\mathcal{L}_{\text{distill}} = -\sum_{i=1}^{256} P_T(x_i\left\vert x_c\right.) \log P_S(x_i\left\vert x_c\right.)\]여기서 $P_T(x_i\left\vert x_c\right.)$는 교사 모델의 확률 분포이고, $P_S(x_i\left\vert x_c\right.)$는 학생 모델의 확률 분포입니다. 교사의 목표 분포는 샘플링되지 않은 로짓에 대해 0 확률로 설정되고 재정규화됩니다.
이러한 접근법은 전체 어휘에 대한 소프트맥스 계산의 계산 비용을 크게 줄이면서도 교사 모델의 지식을 효과적으로 전달합니다.
양자화 인식 훈련
원본 체크포인트와 함께 Gemma 3는 다양한 표준 형식으로 양자화된 버전도 제공합니다. 이러한 버전들은 Quantization Aware Training (QAT) 기법을 사용하여 각 모델을 일반적으로 5,000 스텝 동안 파인튜닝하여 얻어집니다.
QAT 과정에서는 양자화되지 않은 체크포인트의 확률을 목표로 사용하며, 데이터를 사전 훈련과 후훈련 분포에 맞게 조정합니다. 가장 인기 있는 오픈 소스 양자화 추론 엔진(예: llama.cpp)을 기반으로 세 가지 가중치 표현에 중점을 둡니다.
- 채널별 int4: 각 채널마다 독립적인 양자화 매개변수 사용
- 블록별 int4: 블록 단위로 양자화 매개변수 공유
- 스위치드 fp8: 동적으로 전환되는 8비트 부동소수점 표현
다음 표는 원본과 양자화된 모델들의 메모리 사용량을 비교합니다.
| 모델 | Raw (GB) bfloat16 | Quantized (GB) Int4 | Int4 blocks=32 | SFP8 |
|---|---|---|---|---|
| 1B | 2.0 | 0.5 | 0.7 | 1.0 |
| 1B+KV | 2.9 | 1.4 | 1.6 | 1.9 |
| 4B | 8.0 | 2.6 | 2.9 | 4.4 |
| 4B+KV | 12.7 | 7.3 | 7.6 | 9.1 |
| 12B | 24.0 | 6.6 | 7.1 | 12.4 |
| 12B+KV | 38.9 | 21.5 | 22.0 | 27.3 |
| 27B | 54.0 | 14.1 | 15.3 | 27.4 |
| 27B+KV | 72.7 | 32.8 | 34.0 | 46.1 |
이 표에서 "+KV"는 32,768 컨텍스트 크기에서 8비트로 양자화된 KV 캐싱을 포함한 메모리 사용량을 나타냅니다. 양자화를 통해 메모리 사용량을 대폭 줄일 수 있음을 보여주며, 특히 int4 양자화는 원본 대비 약 75%의 메모리 절약을 달성합니다.
계산 인프라
Gemma 3 모델들은 TPUv4, TPUv5e, TPUv5p를 사용하여 훈련되었습니다. 각 모델 구성은 훈련 스텝 시간을 최소화하도록 최적화되었습니다.
| 모델 | TPU 타입 | 칩 수 | 데이터 | 시퀀스 | 복제본 |
|---|---|---|---|---|---|
| 1B | TPUv5e | 512 | 16 | 16 | 2 |
| 4B | TPUv5e | 2048 | 16 | 16 | 8 |
| 12B | TPUv4 | 6144 | 16 | 16 | 24 |
| 27B | TPUv5p | 6144 | 24 | 8 | 32 |
비전 인코더의 경우, 각 이미지에 대한 임베딩을 미리 계산하고 임베딩을 직접 사용하여 훈련함으로써 언어 모델 훈련에 추가 비용을 발생시키지 않습니다.
옵티마이저 상태는 ZeRO-3의 구현을 사용하여 샤딩됩니다. 멀티 포드 훈련의 경우, Pathways 접근법을 사용하여 데이터 센터 네트워크를 통해 데이터 복제본 축소를 수행합니다.
전체 시스템은 JAX와 Pathways의 '단일 컨트롤러' 프로그래밍 패러다임을 사용하며, GSPMD 파티셔너와 MegaScale XLA 컴파일러를 함께 활용합니다.
대화형 모델 포맷팅
Gemma 3 IT(Instruction-Tuned) 모델들은 특별한 대화 포맷을 사용합니다.
| 컨텍스트 | 포맷팅 |
|---|---|
| 사용자 턴 | user |
| 모델 턴 | model |
| 턴 종료 |
대화 예시:
사용자: Who are you?
모델: My name is Gemma!
사용자: What is 2+2?
모델: 2+2=4.
모델 입력 형식:
[BOS]user Who are you? model My name is Gemma! user What is 2+2? model
모델 출력:
2+2=4.
토큰화 후 명시적으로 [BOS] 토큰을 추가하거나 토크나이저에서 add_bos=True 옵션을 사용해야 합니다. "[BOS]" 텍스트 자체를 토큰화해서는 안 됩니다.
이러한 포맷팅은 모델이 대화의 맥락을 정확히 이해하고 적절한 응답을 생성할 수 있도록 도와줍니다. 특히 멀티턴 대화에서 각 발화자의 역할을 명확히 구분하여 일관성 있는 대화를 유지할 수 있게 합니다.
지시 튜닝
Gemma 3의 지시 튜닝은 사전 훈련된 모델을 지시 따르기 능력이 향상된 모델로 변환하는 개선된 후훈련 접근법을 사용합니다. 이 과정은 이전 레시피와 비교하여 상당한 개선사항을 포함하고 있으며, 여러 고급 기법들을 통합하여 모델의 성능을 크게 향상시킵니다.
핵심 기법들
지시 튜닝 과정은 세 가지 주요 구성 요소로 이루어집니다. 첫 번째는 개선된 지식 증류입니다. 이는 대규모 지시 튜닝된 교사 모델로부터 지식을 전달받는 과정으로, Hinton et al.에서 제안된 원리를 발전시킨 것입니다. 지식 증류는 교사 모델이 생성하는 소프트 타겟을 학생 모델이 학습하도록 하여, 단순한 정답 레이블보다 더 풍부한 정보를 전달합니다.
두 번째는 강화학습 파인튜닝 단계입니다. 이 단계에서는 BOND, WARM, WARP 기법들의 개선된 버전을 사용합니다. 이러한 기법들은 모델이 인간의 피드백을 통해 더 나은 응답을 생성하도록 학습시키는 방법들입니다. Tülu 3 연구에서 보여준 바와 같이, 이러한 강화학습 기반 접근법은 모델의 지시 따르기 능력을 크게 향상시킬 수 있습니다.
세 번째는 데이터 필터링과 최적화입니다. 후훈련에 사용되는 데이터를 신중하게 최적화하여 모델 성능을 극대화합니다. 이 과정에서는 개인정보, 안전하지 않거나 독성이 있는 모델 출력, 잘못된 자기 식별 데이터, 중복된 예시들을 제거합니다.
강화학습 목표 함수들
Gemma 3의 지시 튜닝은 다양한 보상 함수를 사용하여 여러 능력을 동시에 향상시킵니다. 이러한 보상 함수들은 유용성, 수학, 코딩, 추론, 지시 따르기, 다국어 능력을 개선하면서 동시에 모델의 유해성을 최소화하도록 설계되었습니다.
가중 평균 보상 모델을 사용한 학습이 핵심적인 역할을 합니다. 이는 인간 피드백 데이터로 훈련된 여러 보상 모델들의 가중 평균을 통해 더 안정적이고 균형잡힌 학습을 가능하게 합니다. RLEF 연구에서 제시된 바와 같이, 코드 실행 피드백을 활용한 강화학습은 특히 코딩 능력 향상에 효과적입니다.
수학 문제 해결을 위한 정답 보상도 중요한 구성 요소입니다. 이는 수학 문제에 대한 정확한 답을 제공했을 때 명확한 보상을 주는 방식으로, 모델의 수학적 추론 능력을 크게 향상시킵니다. 이러한 접근법은 검증 가능한 보상을 통해 모델이 올바른 답을 생성하도록 유도합니다.
데이터 필터링 전략
데이터 필터링 과정은 모델의 안전성과 성능을 동시에 보장하는 중요한 단계입니다. 이 과정에서는 여러 유형의 문제가 있는 데이터를 체계적으로 제거합니다.
개인정보 보호를 위해 특정 개인정보가 포함된 예시들을 필터링합니다. 이는 모델이 훈련 과정에서 민감한 개인정보를 학습하여 나중에 생성하는 것을 방지합니다.
안전성 확보를 위해 안전하지 않거나 독성이 있는 모델 출력을 제거합니다. 이는 모델이 유해한 콘텐츠를 생성할 가능성을 크게 줄입니다.
정확성 향상을 위해 잘못된 자기 식별 데이터와 중복된 예시들을 제거합니다. 이는 모델이 일관되고 정확한 응답을 생성하도록 돕습니다.
특히 주목할 만한 점은 맥락 내 귀속, 헤징, 거부를 장려하는 데이터 하위 집합을 포함한다는 것입니다. 이러한 데이터는 환각을 최소화하는 데 도움이 되며, 사실성 지표에서 성능을 향상시키면서도 다른 지표에서의 성능 저하를 방지합니다.
토큰 포맷팅과 모델 구분
Gemma 3에서는 사전 훈련(PT) 모델과 지시 튜닝(IT) 모델 간에 중요한 포맷팅 차이가 있습니다. 모든 모델은 동일한 토크나이저를 공유하지만, 지시 튜닝을 위한 특별한 제어 토큰들이 추가되었습니다.
[BOS] 토큰 처리는 두 모델 유형 모두에서 중요합니다. 텍스트는 [BOS] 토큰으로 시작해야 하며, 이는 명시적으로 추가되어야 합니다. "[BOS]" 텍스트 자체는 실제 [BOS] 토큰으로 매핑되지 않기 때문입니다. 예를 들어, Flax에서는 add_bos=True 옵션을 사용하여 토큰화 시 이 토큰을 자동으로 추가할 수 있습니다.
생성 종료 토큰에서 가장 중요한 차이가 나타납니다. PT 모델은 생성 끝에 특정 토큰을 출력하는 반면, IT 모델은 생성 끝에 다른 토큰을 출력합니다. 이러한 차이는 각 모델 유형의 파인튜닝 시 해당하는 종료 토큰을 추가해야 함을 의미합니다.
다음 표는 IT 모델의 포맷팅 예시를 보여줍니다.
| 컨텍스트 | 포맷팅 |
|---|---|
| 사용자 입력 | user |
| 모델 응답 | model |
| 턴 종료 | <end_of_turn> |
실제 대화 예시에서 이러한 포맷팅이 어떻게 적용되는지 살펴보면:
[BOS]user
Who are you?
model
My name is Gemma! I'm a helpful AI assistant created by Google.
<end_of_turn>user
What can you help me with?
model
I can help you with a wide variety of tasks including answering questions, writing, coding, math problems, and creative projects.
<end_of_turn>
이러한 구조화된 포맷팅은 모델이 대화의 맥락을 정확히 이해하고 적절한 응답을 생성할 수 있도록 돕습니다. 특히 멀티턴 대화에서 각 발화자의 역할을 명확히 구분하여 일관성 있는 대화를 유지할 수 있게 합니다.
성능 향상 결과
이러한 개선된 후훈련 접근법을 통해 Gemma 3 모델들은 놀라운 성능 향상을 달성했습니다. 특히 Gemma3-4B-IT 모델은 Gemma2-27B-IT와 경쟁할 수 있는 성능을 보여주며, 이는 모델 크기 대비 효율성이 크게 개선되었음을 의미합니다.
더욱 인상적인 것은 Gemma3-27B-IT 모델이 다양한 벤치마크에서 Gemini-1.5-Pro와 비교할 수 있는 수준에 도달했다는 점입니다. 이는 오픈 소스 모델이 상용 모델과 경쟁할 수 있는 수준까지 발전했음을 보여주는 중요한 이정표입니다.
이러한 성능 향상은 단순히 모델 크기를 늘린 결과가 아니라, 정교한 지식 증류, 다양한 보상 함수를 활용한 강화학습, 그리고 체계적인 데이터 필터링의 결합으로 달성된 것입니다. 이는 효율적인 모델 개발을 위한 새로운 패러다임을 제시하며, 제한된 계산 자원으로도 고성능 AI 모델을 개발할 수 있는 가능성을 보여줍니다.
최종 모델 평가
Gemma 3 모델들의 성능을 종합적으로 평가하기 위해 다양한 자동화된 벤치마크와 인간 평가를 통한 검증이 수행되었습니다. 이 평가 과정은 LMSYS Chatbot Arena에서의 인간 평가자들에 의한 블라인드 비교 평가와 MMLU와 같은 표준 벤치마크를 포함한 광범위한 도메인에 걸친 체계적인 성능 측정으로 구성됩니다.
LMSYS Chatbot Arena 성능
Gemma 3 27B IT 모델은 LMSYS Chatbot Arena에서 인상적인 성과를 달성했습니다. Chatbot Arena는 대규모 크라우드소싱 플랫폼으로, 인간 선호도를 기반으로 언어 모델을 평가하는 혁신적인 시스템입니다. 이 플랫폼은 Bradley-Terry 모델을 사용하여 모델 간 쌍별 비교를 통해 Elo 점수를 계산합니다.
Bradley-Terry 모델의 수학적 표현은 다음과 같습니다.
\[P(m \text{ beats } m') = \frac{e^{\xi_m}}{e^{\xi_m} + e^{\xi_{m'}}}\]여기서 $\xi_m$과 $\xi_{m'}$는 각각 모델 $m$과 $m'$의 Bradley-Terry 계수입니다. 이 모델은 인간 평가자들의 선호도 데이터를 바탕으로 최대우도추정을 통해 각 모델의 상대적 성능을 정량화합니다.
Chatbot Arena의 평가 결과를 보면, Gemma 3 27B IT 모델은 1338점의 Elo 점수를 달성하여 전체 순위에서 9위를 기록했습니다. 이는 매우 인상적인 결과로, 다음과 같은 중요한 의미를 갖습니다.
오픈 모델 중 최상위 성능: Gemma 3 27B IT는 DeepSeek-V3 (1318점), Meta-Llama-3.1-405B-Instruct (1269점), Qwen2.5-72B-Instruct (1257점)와 같은 훨씬 큰 규모의 오픈 모델들을 능가했습니다. 특히 405B 매개변수를 가진 LLaMA 3.1 모델보다 높은 점수를 기록한 것은 Gemma 3의 효율성을 보여주는 중요한 지표입니다.
이전 버전 대비 대폭 개선: Gemma 2 27B IT 모델의 1220점과 비교하여 118점이나 향상된 결과를 보여줍니다. 이는 새로운 후훈련 레시피와 아키텍처 개선의 효과를 명확히 입증합니다.
상용 모델과의 경쟁력: 비록 GPT-4.5-Preview (1411점)이나 Gemini-2.0-Flash-Thinking (1384점)과 같은 최상위 상용 모델에는 미치지 못하지만, 오픈 소스 모델로서는 매우 경쟁력 있는 성능을 보여줍니다.
다음 표는 주요 모델들의 Elo 점수 비교를 보여줍니다.
| 순위 | 모델 | Elo 점수 | 95% 신뢰구간 | 오픈 | 타입 | 매개변수 |
|---|---|---|---|---|---|---|
| 1 | Grok-3-Preview | 1412 | +8/-10 | - | - | - |
| 2 | GPT-4.5-Preview | 1411 | +11/-11 | - | - | - |
| 3 | Gemini-2.0-Flash-Thinking | 1384 | +6/-5 | - | - | - |
| 6 | DeepSeek-R1 | 1363 | +8/-6 | 예 | MoE | 671B/37B |
| 9 | Gemma-3-27B-IT | 1338 | +8/-9 | 예 | Dense | 27B |
| 13 | DeepSeek-V3 | 1318 | +8/-6 | 예 | MoE | 671B/37B |
| 28 | Meta-Llama-3.1-405B | 1269 | +4/-3 | 예 | Dense | 405B |
| 39 | Qwen2.5-72B-Instruct | 1257 | +3/-3 | 예 | Dense | 72B |
| 59 | Gemma-2-27B-it | 1220 | +3/-2 | 예 | Dense | 27B |
이 결과에서 주목할 점은 Gemma 3 27B IT가 매개변수 대비 효율성에서 탁월한 성능을 보인다는 것입니다. 27B 매개변수로 405B 모델을 능가하고, 671B MoE 모델과 경쟁할 수 있는 수준에 도달한 것은 지식 증류와 혁신적인 후훈련 기법의 효과를 명확히 보여줍니다.
또한 중요한 점은 이러한 Elo 점수가 시각적 능력을 고려하지 않는다는 것입니다. Gemma 3는 멀티모달 능력을 갖추고 있어 텍스트와 이미지를 동시에 처리할 수 있지만, 이러한 능력은 현재 Arena 평가에 반영되지 않았습니다. 따라서 실제 멀티모달 작업에서는 더욱 뛰어난 성능을 보일 것으로 예상됩니다.
표준 벤치마크 성능
표준 벤치마크 평가에서는 Gemma 3 모델들이 이전 버전인 Gemma 2 및 Gemini 1.5와 비교하여 다양한 영역에서 상당한 성능 향상을 보였습니다. 이 평가는 공정한 비교를 위해 동일한 평가 설정 하에서 수행되었으며, 외부 모델들과의 직접 비교는 평가 설정의 차이로 인한 불공정함을 피하기 위해 제한되었습니다.
수학 및 추론 능력: Gemma 3 모델들은 수학 문제 해결과 논리적 추론 작업에서 특히 두드러진 개선을 보였습니다. 이는 후훈련 과정에서 수학 문제에 대한 정답 보상을 활용한 강화학습의 효과로 해석됩니다.
코딩 능력: 프로그래밍 관련 벤치마크에서도 상당한 성능 향상이 관찰되었습니다. RLEF 연구에서 제시된 코드 실행 피드백을 활용한 강화학습 접근법이 이러한 개선에 기여했을 것으로 분석됩니다.
다국어 능력: 확장된 다국어 데이터 혼합과 개선된 토크나이저의 효과로 다양한 언어에서의 성능이 크게 향상되었습니다. 특히 저자원 언어들에서의 성능 개선이 두드러졌습니다.
일반 지식 및 상식 추론: MMLU와 같은 종합적인 지식 평가에서도 일관된 성능 향상을 보여주었습니다. 이는 지식 증류 과정에서 더 큰 교사 모델로부터 효과적으로 지식을 전달받은 결과로 해석됩니다.
평가 결과는 제3자 정적 리더보드를 통한 공정한 모델 간 비교를 권장하며, 이를 통해 더욱 객관적인 성능 평가가 가능합니다. 부록에는 추가적인 벤치마크 결과들이 포함되어 있어 더욱 상세한 성능 분석을 제공합니다.
이러한 종합적인 평가 결과는 Gemma 3가 단순히 모델 크기를 늘린 것이 아니라, 혁신적인 아키텍처 설계와 정교한 훈련 방법론을 통해 실질적인 성능 향상을 달성했음을 보여줍니다. 특히 매개변수 효율성 측면에서 뛰어난 결과를 보인 것은 제한된 계산 자원 환경에서도 고성능 AI 모델을 활용할 수 있는 가능성을 제시합니다.
절제 연구
이 섹션에서는 아키텍처 변경사항의 영향과 이 모델에 새롭게 추가된 비전 능력들을 중심으로 체계적인 절제 연구를 수행합니다.
사전 훈련 능력 탐지
표준 벤치마크들을 사전 훈련 중 탐지 도구로 활용하여 모델들이 일반적인 능력을 포착하는지 확인했습니다. 다음 그림은 과학, 코드, 사실성, 다국어, 추론, 비전 등 일반적인 능력들에 걸쳐 Gemma 2와 3의 사전 훈련된 모델들의 품질을 비교합니다.
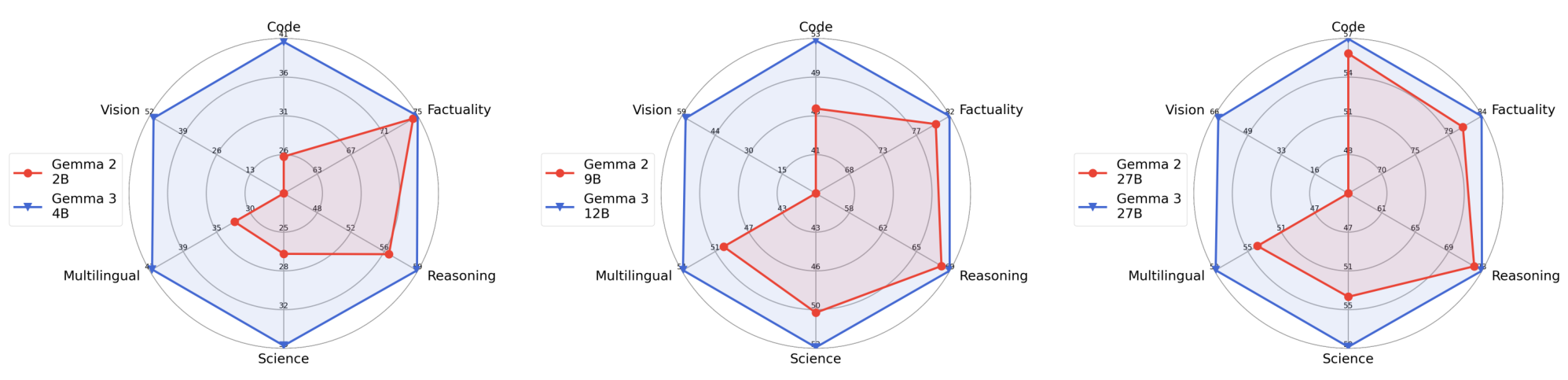
이 레이더 차트는 세 가지 언어 모델(Gemma 2, Gemma 3)의 성능을 다섯 가지 차원에서 비교합니다. 코드, 비전, 사실성, 다국어, 추론 능력에서 각 모델의 상대적 성능을 시각화하여 보여줍니다. 전반적으로 새로운 버전들이 비전 추가에도 불구하고 대부분의 카테고리에서 개선을 보였습니다. 특히 이번 버전에서는 다국어 능력에 중점을 두었으며, 이는 모델의 품질에 직접적인 영향을 미쳤습니다.
그러나 오염 제거 기법을 사용했음에도 불구하고 이러한 탐지에는 항상 오염의 위험이 있어(Mirzadeh et al., 2024), 더 확정적인 결론을 내리기 어렵게 만듭니다. 부록에는 이러한 플롯에 사용된 다양한 공개 벤치마크에서의 성능에 대한 세부 사항이 요약되어 있습니다.
로컬-글로벌 어텐션 레이어
로컬과 글로벌 셀프 어텐션 레이어의 변경이 추론 중 성능과 메모리 소비에 미치는 영향을 측정했습니다.
로컬-글로벌 비율
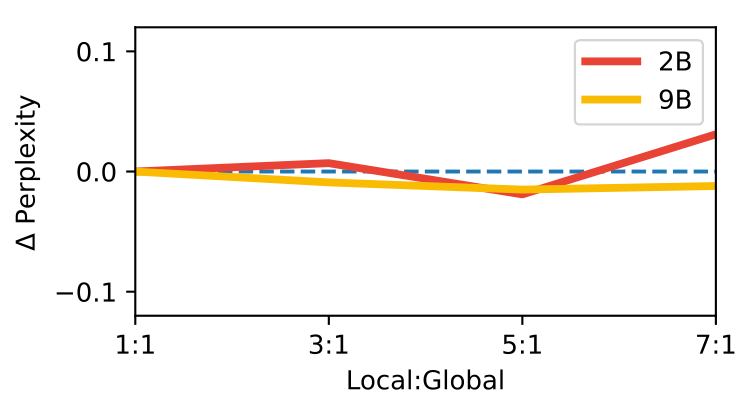
이 막대 그래프는 로컬-글로벌 비율이 검증 세트에서의 퍼플렉시티에 미치는 영향을 보여줍니다. Gemma 2 모델에서는 1:1 비율이 사용되었고, Gemma 3에서는 5:1 비율이 사용되었습니다. 7:1까지의 로컬 대 글로벌 비율에서도 영향이 미미함을 관찰할 수 있습니다. 이 절제 연구는 텍스트 전용 모델로 수행되었습니다.
슬라이딩 윈도우 크기
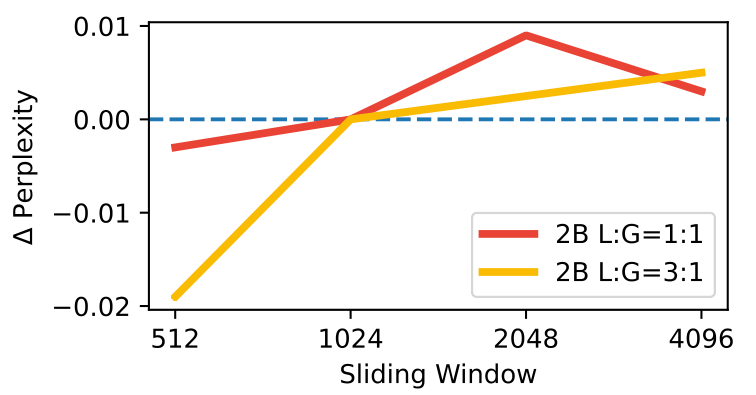
이 선 그래프는 서로 다른 글로벌-로컬 비율 구성에서 로컬 어텐션 레이어의 슬라이딩 윈도우 크기가 퍼플렉시티에 미치는 영향을 보여줍니다. 2B 모델에서 1:1과 3:1 로컬 대 글로벌 레이어 비율을 고려했습니다. 슬라이딩 윈도우는 퍼플렉시티에 영향을 주지 않으면서도 상당히 줄일 수 있음을 보여줍니다. 이 절제 연구 역시 텍스트 전용 모델로 수행되었습니다.
KV 캐시 메모리에 미치는 영향
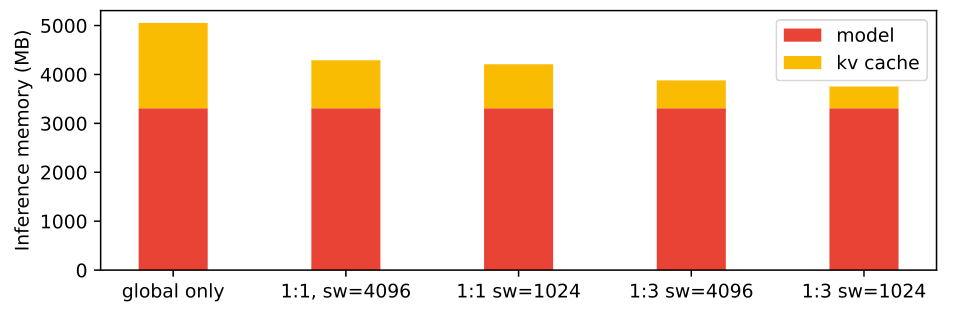
이 막대 차트는 32k 토큰의 컨텍스트로 추론 중 모델과 KV 캐시가 사용하는 메모리를 비교합니다. "글로벌 전용" 구성은 대부분의 밀집 모델에서 사용되는 표준 구성입니다. "1:1, sw=4096"은 Gemma 2에서 사용된 구성입니다. "글로벌 전용" 구성은 60%의 메모리 오버헤드를 발생시키는 반면, 1:3과 1024의 슬라이딩 윈도우("sw=1024")를 사용하면 이것이 15% 미만으로 줄어듭니다.
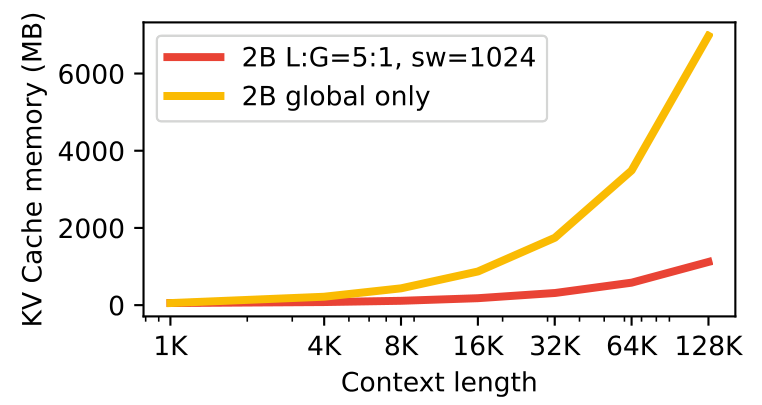
이 선 그래프는 우리의 2B 아키텍처(L:G=5:1, sw=1024)와 "글로벌 전용" 2B 모델에서 컨텍스트 길이에 따른 KV 캐시 메모리 사용량을 계산합니다. 우리의 아키텍처는 컨텍스트 길이가 증가함에 따라 메모리 사용량이 훨씬 더 완만하게 증가함을 보여줍니다. LLaMA나 Gemma 1에서 사용되는 글로벌 어텐션만 사용하는 트랜스포머와 비교하여 메모리 효율성이 크게 개선되었습니다.
긴 컨텍스트 활성화
처음부터 128K 시퀀스로 훈련하는 대신, 32K 시퀀스로 모델을 사전 훈련한 다음 4B, 12B, 27B 모델을 사전 훈련 마지막에 128K 토큰까지 확장하면서 RoPE를 재조정했습니다(Chen et al., 2023). 실제로 8의 스케일링 팩터가 잘 작동함을 발견했습니다.
Gemma 2와 비교하여 글로벌 셀프 어텐션 레이어의 RoPE 기본 주파수를 10k에서 1M으로 증가시켰으며, 로컬 셀프 어텐션 레이어는 10k를 유지했습니다.
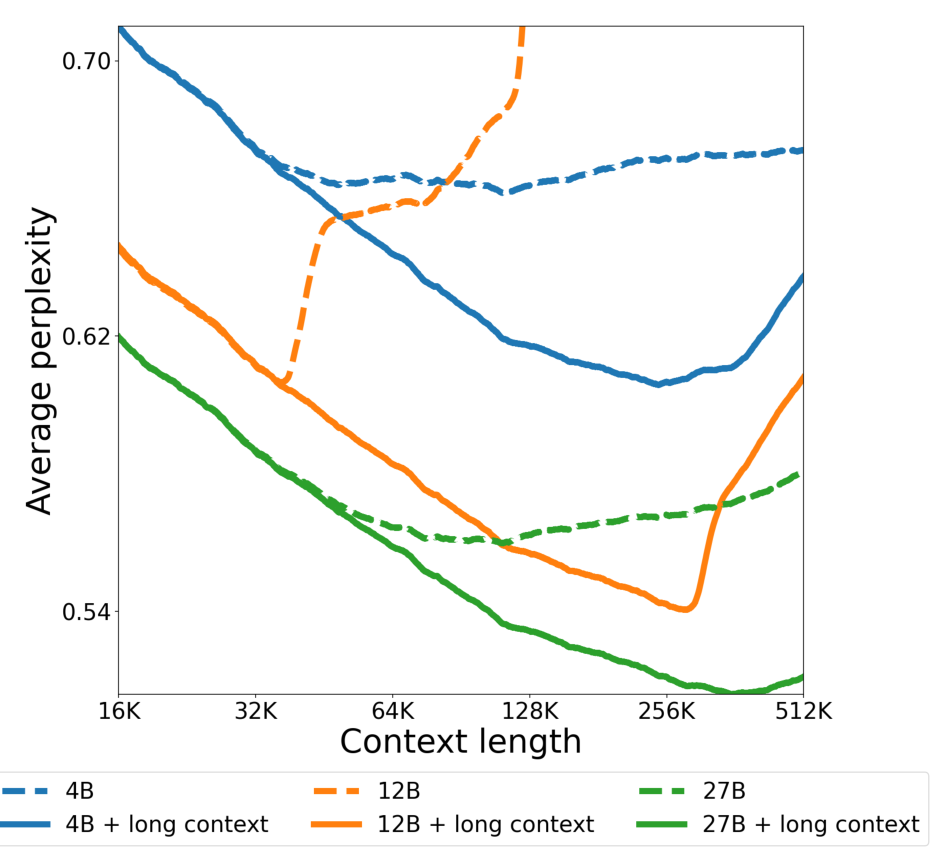
이 선 그래프는 RoPE 재조정 전후의 사전 훈련된 모델들의 긴 컨텍스트 성능을 보여줍니다. 4B, 12B, 27B 모델 크기에 대해 긴 컨텍스트 사용 여부에 따른 평균 퍼플렉시티를 16K에서 512K 토큰까지의 컨텍스트 길이에서 보여줍니다. 모델들이 128K까지 일반화되지만 계속 확장하면서 급속히 성능이 저하됨을 보여줍니다.
작은 교사 대 큰 교사
작은 모델을 훈련하기 위해서는 더 작은 교사로부터 증류하는 것이 바람직하다는 것이 일반적인 발견입니다.
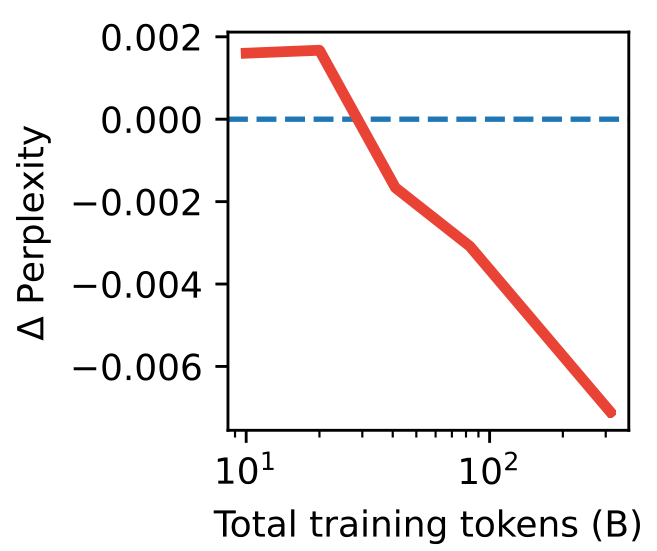
이 선 그래프는 훈련 토큰 크기의 함수로서 작은 교사와 큰 교사를 사용할 때의 퍼플렉시티 상대적 차이를 보여줍니다. 더 작은 숫자는 더 큰 교사로부터 증류하는 것이 더 좋다는 것을 의미합니다. 이러한 연구들이 종종 더 나쁜 교사를 사용하는 정규화 효과가 더 나은 교사를 사용하는 이익을 능가하는 설정에서 수행되기 때문이라고 의심됩니다.
서로 다른 크기의 2명의 교사, 하나는 크고 하나는 작은 교사로 학생을 서로 다른 훈련 기간 동안 훈련시켰습니다. 짧은 훈련 기간에서는 더 작은 교사가 더 좋지만, 더 긴 훈련에서는 추세가 역전됨을 관찰했습니다.
비전 인코더
이미지 해상도의 영향
SigLIP을 기반으로 한 비전 인코더를 사용합니다. 비전 인코더는 고정되어 있으며 언어 모델만 훈련됩니다. 이 멀티모달 데이터의 각 이미지는 해당 비전 인코더에서 256개의 이미지 토큰으로 표현됩니다. 따라서 더 높은 해상도 인코더들은 출력을 256 토큰으로 줄이기 위해 평균 풀링을 사용합니다. 예를 들어, 896 해상도 인코더는 출력에 4x4 평균 풀링을 적용합니다.
| 해상도 | DocVQA | InfoVQA | TextVQA |
|---|---|---|---|
| 256 | 31.9 | 23.1 | 44.1 |
| 448 | 45.4 | 31.6 | 53.5 |
| 896 | 59.8 | 33.7 | 58.0 |
이 표는 이미지 인코더 입력 해상도의 영향을 보여줍니다. 몇 가지 평가 벤치마크에서 짧은 스케줄 2B Gemma 모델을 사용하여 이미지 해상도가 비전 인코더 사전 훈련에 미치는 영향을 관찰하기 위해 성능을 측정했습니다. 더 높은 해상도 인코더가 더 작은 것들보다 더 나은 성능을 보임을 알 수 있습니다.
Pan & Scan
P&S는 원래 종횡비와 이미지 해상도에 가깝게 이미지를 캡처할 수 있게 합니다.
| 모델 | DocVQA | InfoVQA | TextVQA |
|---|---|---|---|
| 4B | 72.8 | 44.1 | 58.9 |
| 4B w/ P&S | 81.0 | 57.0 | 60.8 |
| Δ | (+8.2) | (+12.9) | (+1.9) |
| 27B | 85.6 | 59.4 | 68.6 |
| 27B w/ P&S | 90.4 | 76.4 | 70.2 |
| Δ | (+4.8) | (+17.0) | (+1.6) |
이 표는 P&S의 영향을 보여줍니다. 사전 훈련된 체크포인트에서 P&S 유무에 따른 유효 세트에서의 4-shot 평가 결과입니다. 향상은 다양한 종횡비를 가진 이미지나 이미지의 텍스트 읽기와 관련된 작업에서 나타납니다.
예상대로, 원래 해상도에 가까운 이미지를 처리할 수 있는 능력은 이미지의 텍스트를 읽어야 하는 작업에 크게 도움이 되며, 이는 시각 언어 모델에 특히 중요합니다. P&S를 사용함으로써 DocVQA에서 최대 8.2점, InfoVQA에서 최대 17.0점의 상당한 성능 향상을 달성했습니다.
기억화와 프라이버시
대규모 언어 모델이 훈련 데이터의 거의 완전한 복사본을 생성할 수 있다는 것은 중요한 프라이버시 우려사항입니다. 이러한 현상은 "기억화(memorization)"라고 불리며, 여러 선행 연구들에서 이 위험을 정량화하는 감사 보고서들이 발표되었습니다.
기억화 측정 방법론
Gemma 3의 기억화 평가는 Gemma Team (2024b)에서 설명된 방법론을 따릅니다. 이 접근법은 훈련 데이터의 대규모 부분을 다양한 코퍼스에 걸쳐 균등하게 서브샘플링하고, 길이 50의 접두사와 길이 50의 접미사를 사용하여 발견 가능한 추출(discoverable extraction)을 테스트합니다.
기억화는 두 가지 유형으로 분류됩니다.
정확한 기억화(Exact Memorization): 생성된 연속 텍스트의 모든 토큰이 원본 접미사와 정확히 일치하는 경우입니다. 이는 모델이 훈련 데이터를 문자 그대로 복사하여 출력하는 가장 명확한 형태의 기억화입니다.
근사적 기억화(Approximate Memorization): 생성된 텍스트가 원본과 최대 10%의 편집 거리(edit distance) 내에서 일치하는 경우입니다. 이는 모델이 훈련 데이터를 약간 변형하거나 패러프레이즈하여 출력하는 경우를 포착합니다.
이러한 정의는 Carlini et al. (2021, 2022)의 연구에서 제시된 기억화 개념을 발전시킨 것으로, 모델이 단순히 훈련 데이터를 "포함"하고 있다는 것이 아니라 특정 조건 하에서 통계적으로 훈련 데이터를 생성할 수 있는 능력을 측정합니다.
Gemma 3의 기억화 성능
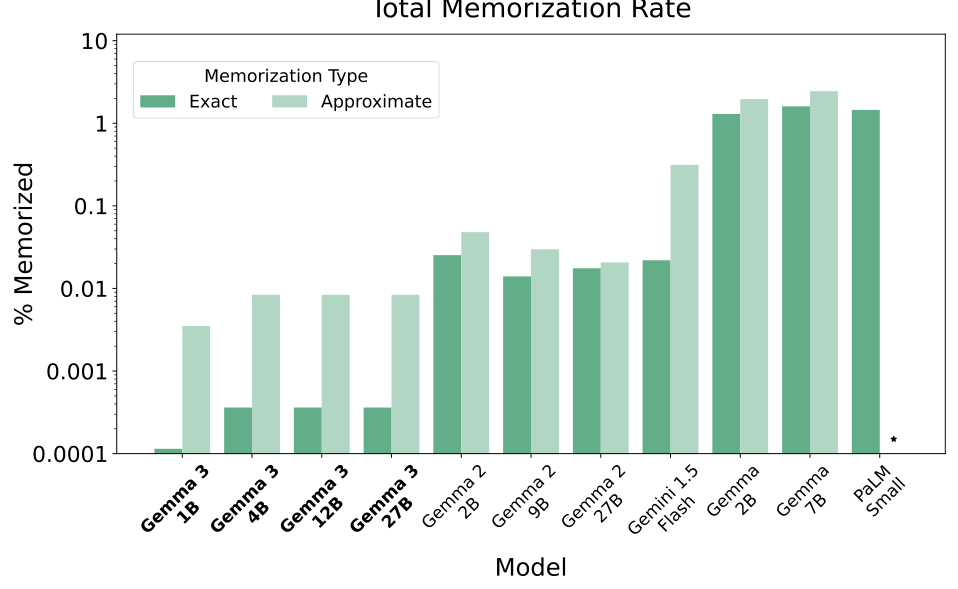
위 그래프는 다양한 모델들의 총 기억화 비율을 보여주며, 정확한 기억화와 근사적 기억화를 서로 다른 색상으로 구분하여 표시합니다. 가장 주목할 만한 결과는 Gemma 3 모델들이 이전의 모든 모델들보다 현저히 낮은 기억화 비율을 보인다는 점입니다.
구체적인 분석 결과는 다음과 같습니다.
모델 크기별 기억화 패턴: Gemma 3의 4B, 12B, 27B 모델들 간에는 기억화 비율에서 미미한 차이만 관찰되었습니다. 흥미롭게도 1B 모델은 더 큰 모델들보다 낮은 기억화 비율을 보였는데, 이는 Carlini et al.의 연구에서 제시된 "모델 크기가 클수록 기억화가 증가한다"는 일반적인 패턴과는 다른 결과입니다.
근사적 기억화의 증가: 특히 중요한 발견은 근사적 기억화의 상대적 증가입니다. Gemma 3에서는 정확한 기억화 대비 근사적 기억화가 평균적으로 약 24배 증가했습니다. 이는 Ippolito et al. (2022)에서 지적한 바와 같이, 단순한 정확한 기억화 방지만으로는 충분하지 않으며 근사적 기억화도 고려해야 한다는 점을 뒷받침합니다.
개인정보 탐지 및 보호
개인정보가 포함될 가능성을 식별하기 위해 Google Cloud Sensitive Data Protection (SDP) 서비스를 활용했습니다. SDP는 개인정보가 포함될 수 있는 텍스트를 식별하기 위한 광범위한 탐지 규칙을 사용합니다.
SDP의 특성과 한계: SDP는 높은 재현율(high recall)을 갖도록 설계되었으며, 정보가 나타나는 맥락을 고려하지 않습니다. 이로 인해 많은 거짓 양성(false positive)이 발생하게 되어, 실제로는 기억화된 출력에 포함된 잠재적 개인정보의 양을 과대평가할 가능성이 높습니다.
SDP는 다음과 같은 심각도 수준을 제공합니다.
- 낮음(Low): 개인정보일 가능성이 낮은 데이터
- 보통(Medium): 개인정보일 가능성이 중간 정도인 데이터
- 높음(High): 개인정보일 가능성이 높은 데이터
연구에서는 어떤 심각도 수준에서든 SDP가 개인정보로 분류한 텍스트를 모두 개인정보로 간주했습니다.
Gemma 3의 개인정보 보호 성과: 가장 중요한 결과는 모든 Gemma 3 모델에서 기억화로 특성화된 출력에서 개인정보가 전혀 관찰되지 않았다는 점입니다. 이는 기억화로 분류된 출력에서 개인 데이터의 비율이 탐지 임계값 이하로 낮다는 것을 의미합니다.
기억화 감소의 기술적 의미
Gemma 3의 낮은 기억화 비율은 여러 기술적 개선사항의 결과로 해석됩니다.
데이터 필터링 개선: 사전 훈련 과정에서 적용된 엄격한 데이터 필터링이 기억화 위험을 크게 줄였습니다. 특히 개인정보와 민감한 데이터의 체계적 제거가 효과적이었습니다.
지식 증류의 효과: 지식 증류 과정에서 교사 모델의 소프트 타겟을 학습함으로써, 단순한 암기보다는 일반화된 패턴 학습이 촉진되었을 것으로 분석됩니다.
아키텍처 혁신의 기여: 로컬-글로벌 어텐션 메커니즘과 같은 아키텍처 혁신이 모델의 일반화 능력을 향상시켜 기억화를 줄이는 데 기여했을 가능성이 있습니다.
이러한 결과는 대규모 언어 모델의 프라이버시 보호 측면에서 중요한 진전을 나타내며, 오픈 소스 모델의 안전한 배포 가능성을 높이는 의미 있는 성과입니다. 특히 Nasr et al. (2023)에서 제시된 확장 가능한 추출 방법론을 통한 평가에서도 우수한 성능을 보인 것은 Gemma 3의 프라이버시 보호 능력이 실질적으로 향상되었음을 시사합니다.
책임, 안전성, 보안
Gemma 3 모델 개발에서 책임, 안전성, 보안은 가장 중요한 고려사항입니다. Gemma 3 사용자들의 위험을 줄이기 위해 최근 Google AI 모델들과 일치하는 향상된 내부 안전 프로세스를 개발 워크플로우 전반에 걸쳐 지속적으로 통합했습니다. 이는 훈련 시점에서의 안전 완화와 새롭게 도입된 이미지-텍스트 능력에 대한 강력하고 투명한 모델 평가에 중점을 둡니다.
거버넌스와 평가
Gemma의 이익과 위험을 평가하는 접근법은 지원되는 모달리티의 변화를 고려하여 Gemma 1에서 설명된 것과 동일한 원칙을 반영합니다. AI의 개방성이 이러한 기술의 이익을 사회 전반에 확산시킬 수 있다고 계속 믿고 있지만, 개인과 기관 차원에서 해를 끼칠 수 있는 악의적 사용의 위험에 대해서도 평가해야 합니다.
Weidinger et al. (2021)의 연구에서 제시된 바와 같이, 대규모 언어 모델은 차별, 독성, 정보 위험, 잘못된 정보 확산, 악의적 사용, 인간-컴퓨터 상호작용 해악 등 다양한 윤리적 및 사회적 위험을 야기할 수 있습니다. 이러한 위험들은 모델이 훈련 데이터에 존재하는 편견과 해악을 반영하는 통계적 특성에서 비롯됩니다.
첫 번째 Gemma 출시 이후, 이러한 모델들이 다양한 사회적으로 유익한 애플리케이션을 구동하는 것을 목격했습니다. 특히 주목할 만한 예시는 ShieldGemma 2입니다. 이는 Gemma 3로 구축된 4B 이미지 안전 분류기로, 위험한 콘텐츠, 성적으로 노골적인 내용, 폭력 카테고리에 걸쳐 안전 레이블을 출력하는 즉시 사용 가능한 이미지 안전 솔루션을 제공합니다.
Gemma 3 모델 출시는 모델 능력의 변화와 기존 멀티모달 LLM의 진화하는 위험에 대한 면밀한 모니터링, 그리고 모델이 실제 환경에서 사용되는 방식에 대한 이해가 필요했습니다. 아직 Gemma에 대한 악의적 사용 보고를 받지 않았지만, 그러한 보고가 있을 경우 조사하고 학술 및 개발자 커뮤니티와 협력하며 자체 모니터링을 수행하여 그러한 사례를 표시하는 데 계속 전념하고 있습니다.
능력의 발전에도 불구하고, 사용 가능한 더 큰 강력한 오픈 모델의 수를 고려할 때 이번 출시가 전체 위험 환경에 미치는 영향은 미미할 것으로 믿습니다. 이는 현재 AI 생태계에서 Gemma 3가 차지하는 상대적 위치를 고려한 현실적인 위험 평가입니다.
안전 정책과 훈련 시점 완화
Gemma의 안전 접근법의 핵심 기둥은 Gemini 모델과 일치하여 파인튜닝된 모델을 Google의 안전 정책에 맞추는 것입니다. 이러한 정책들은 모델이 유해한 콘텐츠를 생성하는 것을 방지하도록 설계되었습니다.
금지되는 콘텐츠 유형들:
아동 성적 학대 및 착취는 가장 엄격하게 금지되는 콘텐츠입니다. 이는 아동을 대상으로 한 모든 형태의 성적 콘텐츠나 착취적 내용을 포함합니다.
개인 식별 정보 노출도 중요한 금지 사항입니다. 특히 해를 끼칠 수 있는 개인정보(예: 주민등록번호, 사회보장번호)의 노출을 방지합니다. 이는 개인의 프라이버시와 보안을 보호하기 위한 필수적인 조치입니다.
혐오 발언과 괴롭힘은 특정 집단이나 개인을 대상으로 한 차별적이거나 공격적인 언어를 포함합니다. 이러한 콘텐츠는 사회적 화합을 해치고 개인에게 심리적 해를 끼칠 수 있습니다.
위험하거나 악의적인 콘텐츠는 자해 촉진이나 유해한 활동에 대한 지시를 포함합니다. 이는 폭탄 제조법, 독성 물질 사용법, 자살 방법 등 실제 물리적 해를 끼칠 수 있는 정보를 포함합니다.
성적으로 노골적인 콘텐츠는 부적절한 성적 내용의 생성을 방지합니다. 이는 특히 미성년자가 접근할 수 있는 환경에서 중요한 보호 조치입니다.
의학적 조언에 대해서는 과학적 또는 의학적 합의에 반하는 조언을 금지합니다. 잘못된 의학 정보는 생명을 위험에 빠뜨릴 수 있기 때문에 특별한 주의가 필요합니다.
이러한 안전 정책을 구현하기 위해 사전 훈련 데이터에 대한 상당한 안전 필터링을 수행하여 사전 훈련된 체크포인트와 파인튜닝된 체크포인트가 유해한 콘텐츠를 생성할 가능성을 줄였습니다. 파인튜닝된 모델의 경우, SFT(Supervised Fine-Tuning)와 RLHF(Reinforcement Learning from Human Feedback)를 모두 사용하여 모델을 바람직하지 않은 행동에서 멀어지도록 유도합니다.
보증 평가
IT 모델들을 일련의 기준선 보증 평가를 통해 실행하여 모델이 야기할 수 있는 잠재적 해악을 이해합니다. 오픈 모델을 지지하는 만큼, 가중치 출시의 되돌릴 수 없는 특성이 엄격한 위험 평가를 요구한다는 것도 인식하고 있습니다.
내부 안전 프로세스는 이에 따라 설계되었으며, 이전 Gemma 모델들에 대해서도 극단적 위험과 관련된 능력 평가를 수행했습니다. Phuong et al. (2024)와 Shevlane et al. (2023)의 연구에서 제시된 바와 같이, 극단적 위험 평가는 AI 시스템이 개발하는 위험한 새로운 능력들을 식별하고 완화하는 데 중요합니다.
더 능력 있는 모델을 철저히 평가하는 것이 종종 덜 능력 있는 모델들에 대한 충분한 보증을 제공한다는 휴리스틱을 따라 계속 오픈 모델을 개발하고 공유할 것입니다. 따라서 Gemma 3에 대해서는 간소화된 평가 세트를 우선시하고, 특정 모델이 잠재적으로 높은 위험을 제시할 수 있는 경우(아래 CBRN 평가에서 설명하는 바와 같이)에 대해서는 심층적인 위험한 능력 평가를 예약했습니다.
개발 속도와 표적화된 안전 테스트 사이의 균형을 맞추어 평가가 잘 집중되고 효율적이면서도 Frontier Safety Framework에서 제시된 약속을 지키도록 보장합니다.
기준선 평가는 대량의 합성 적대적 사용자 쿼리와 인간 평가자를 사용하여 답변을 정책 위반 여부로 라벨링함으로써 안전 정책에 대한 모델 위반률을 포착합니다. 전반적으로 Gemma 3의 이러한 안전 정책에 대한 위반률은 전체적으로 상당히 낮습니다.
화학, 생물학, 방사선 및 핵(CBRN) 지식 평가는 STEM 관련 작업에서의 향상된 성능으로 인해 생물학적, 방사선적, 핵 위험과 관련된 지식을 내부 데이터셋의 폐쇄형, 지식 기반 객관식 질문을 사용하여 평가했습니다. 화학 지식 평가의 경우, Macknight et al.이 개발한 화학 위험에 대한 폐쇄형 지식 기반 접근법을 사용했습니다. 평가 결과 Gemma 3 모델들의 이러한 영역에서의 지식은 낮은 수준임을 시사합니다.
책임감 있는 오픈 모델에 대한 접근법
안전하고 보안이 강화된 책임감 있는 애플리케이션을 설계하려면 각 특정 사용 사례와 환경과 관련된 위험을 완화하기 위해 노력하는 시스템 수준의 접근법이 필요합니다. 모델의 잠재적 위험에 비례하는 평가와 안전 완화를 계속 채택할 것이며, 이익이 예측 가능한 위험을 상당히 능가한다고 확신할 때만 커뮤니티와 공유할 것입니다.
이러한 접근법은 AI 개발에서 개방성과 안전성 사이의 균형을 추구하는 것입니다. 오픈 소스 모델의 이익을 최대화하면서도 잠재적 위험을 최소화하기 위한 체계적이고 지속적인 노력을 반영합니다. 특히 멀티모달 능력이 추가된 Gemma 3의 경우, 새로운 위험 벡터에 대한 신중한 평가와 적절한 완화 조치가 필수적입니다.
논의 및 결론
Gemma 3는 텍스트, 이미지, 코드를 처리할 수 있는 오픈 언어 모델 패밀리인 Gemma의 최신 버전으로, 이미지 이해 능력과 긴 컨텍스트 처리 능력을 추가하면서 다국어 및 STEM 관련 능력을 향상시키는 데 중점을 두었습니다. 이 연구는 표준 하드웨어와의 호환성을 고려하여 모델 크기와 아키텍처를 설계했으며, 대부분의 아키텍처 개선사항들은 성능을 유지하면서도 이러한 하드웨어 제약에 맞도록 조정되었습니다.
주요 기술적 성과
Gemma 3의 가장 중요한 기술적 혁신은 로컬-글로벌 어텐션 메커니즘의 5:1 인터리빙 구조입니다. 이 접근법은 긴 컨텍스트 처리 시 발생하는 메모리 효율성 문제를 해결하는 실용적인 솔루션을 제공합니다. 앞서 절제 연구에서 확인했듯이, 이 구조는 128K 토큰의 긴 컨텍스트를 처리하면서도 KV 캐시 메모리 오버헤드를 15% 미만으로 유지할 수 있게 합니다. 이는 기존의 글로벌 어텐션만 사용하는 모델들이 60%의 메모리 오버헤드를 발생시키는 것과 비교하여 현저한 개선입니다.
멀티모달 능력의 통합은 또 다른 중요한 성과입니다. SigLIP 비전 인코더를 기반으로 한 비전 처리 시스템과 Pan & Scan 알고리즘의 조합은 다양한 해상도와 종횡비의 이미지를 효과적으로 처리할 수 있게 합니다. 특히 DocVQA에서 최대 8.2점, InfoVQA에서 최대 17.0점의 성능 향상을 달성한 것은 실제 문서 이해 작업에서의 실용적 가치를 입증합니다.
지식 증류와 후훈련의 혁신
Gemma 3에서 도입된 개선된 지식 증류 방법론은 작은 모델로도 큰 모델에 필적하는 성능을 달성할 수 있음을 보여줍니다. Hinton et al.에서 제안된 기본 원리를 발전시켜, 교사 모델의 소프트 타겟을 256개의 로짓 샘플링을 통해 학습하는 방식은 계산 효율성과 성능 향상을 동시에 달성했습니다.
특히 주목할 만한 것은 혁신적인 후훈련 레시피의 효과입니다. BOND, WARM, WARP 기법들의 개선된 버전을 활용한 강화학습 파인튜닝과 다양한 보상 함수의 조합은 놀라운 결과를 가져왔습니다. Gemma3-4B-IT 모델이 Gemma2-27B-IT와 경쟁할 수 있는 성능을 보이고, Gemma3-27B-IT 모델이 Gemini-1.5-Pro와 비교할 수 있는 수준에 도달한 것은 효율적인 모델 개발의 새로운 패러다임을 제시합니다.
안전성과 책임감 있는 개발
Gemma 3는 기술적 성능 향상과 함께 안전성과 책임감 있는 AI 개발에도 중점을 두었습니다. 기억화 평가에서 이전 모든 모델들보다 현저히 낮은 기억화 비율을 보인 것은 특히 의미가 큽니다. 모든 Gemma 3 모델에서 기억화로 특성화된 출력에서 개인정보가 전혀 관찰되지 않았다는 결과는 오픈 소스 모델의 안전한 배포 가능성을 높이는 중요한 성과입니다.
또한 ShieldGemma 2와 같은 안전 분류기의 개발은 Gemma 3의 멀티모달 능력이 단순히 성능 향상에만 그치지 않고 실용적인 안전 솔루션으로도 활용될 수 있음을 보여줍니다. 이는 AI 기술의 발전과 안전성 확보가 동시에 이루어질 수 있다는 가능성을 제시합니다.
실용적 배포와 접근성
Gemma 3 모델들이 표준 소비자급 하드웨어에서 실행되도록 설계된 것은 AI 기술의 민주화에 중요한 기여를 합니다. 양자화 인식 훈련을 통해 제공되는 다양한 양자화 버전들은 메모리 사용량을 원본 대비 약 75%까지 절약할 수 있게 하여, 제한된 자원 환경에서도 고성능 AI 모델을 활용할 수 있는 길을 열어줍니다.
특히 int4 양자화를 통해 27B 모델을 약 14GB의 메모리로 실행할 수 있게 한 것은 개인용 컴퓨터나 소규모 서버에서도 최신 AI 기술을 활용할 수 있는 가능성을 제공합니다. 이는 연구와 개발의 진입 장벽을 낮추고, 더 많은 개발자와 연구자들이 최신 AI 기술에 접근할 수 있게 합니다.
성능 평가와 벤치마크 결과
LMSYS Chatbot Arena에서의 성과는 Gemma 3의 실질적 성능을 입증하는 중요한 지표입니다. Gemma 3 27B IT 모델의 1338점 Elo 점수는 전체 순위 9위에 해당하며, 405B 매개변수를 가진 LLaMA 3.1 모델(1257점)을 능가하는 결과입니다. 이는 매개변수 효율성 측면에서 탁월한 성능을 보여주는 것으로, 모델 크기 대비 성능 최적화의 새로운 기준을 제시합니다.
또한 다양한 표준 벤치마크에서의 일관된 성능 향상은 Gemma 3가 특정 작업에 특화된 것이 아니라 범용적인 능력 향상을 달성했음을 보여줍니다. 수학, 코딩, 추론, 다국어 능력 등 모든 영역에서의 개선은 종합적인 AI 시스템으로서의 가치를 입증합니다.
연구 생태계에 대한 기여
Gemma 3의 완전한 오픈 소스 공개는 AI 연구 생태계 전반에 긍정적인 영향을 미칠 것으로 기대됩니다. 모든 모델 가중치, 훈련 코드, 평가 프로토콜의 공개는 연구의 투명성을 높이고, 다른 연구자들이 이 연구를 기반으로 더 나은 모델을 개발할 수 있는 기반을 제공합니다.
특히 로컬-글로벌 어텐션 메커니즘과 같은 아키텍처 혁신, 개선된 지식 증류 방법론, 그리고 효과적인 후훈련 레시피는 다른 연구자들이 활용할 수 있는 중요한 기술적 자산이 됩니다. 이러한 기여는 AI 연구 커뮤니티 전체의 발전을 가속화할 것입니다.
미래 전망과 발전 방향
Gemma 3가 제시한 기술적 혁신들은 향후 언어 모델 개발의 중요한 방향성을 제시합니다. 메모리 효율적인 긴 컨텍스트 처리, 효과적인 멀티모달 통합, 그리고 매개변수 효율적인 성능 향상은 모두 실용적인 AI 시스템 개발에 필수적인 요소들입니다.
특히 표준 하드웨어에서의 실행 가능성을 고려한 설계 철학은 AI 기술의 실제 배포와 활용에 중요한 시사점을 제공합니다. 이는 클라우드 기반의 대규모 모델뿐만 아니라 엣지 디바이스에서도 활용 가능한 AI 시스템 개발의 가능성을 보여줍니다.
Gemma 3는 오픈 언어 모델 패밀리의 최신 버전으로서, 이미지 이해, 긴 컨텍스트 처리, 향상된 다국어 및 STEM 능력을 통해 AI 기술의 실용적 활용 가능성을 크게 확장했습니다. 표준 하드웨어와의 호환성을 유지하면서도 최첨단 성능을 달성한 이 연구는 효율적이고 접근 가능한 AI 시스템 개발의 새로운 방향을 제시하며, AI 기술의 민주화에 중요한 기여를 하고 있습니다.
부록
부록에서는 Gemma 3 모델들의 상세한 성능 결과를 다양한 벤치마크에 걸쳐 종합적으로 제시합니다. 이 섹션은 사전 훈련된 모델과 지시 튜닝된 모델 모두의 성능을 포괄하며, 사실성, STEM, 코딩, 멀티모달, 다국어 능력 등 광범위한 평가 영역을 다룹니다.
사전 훈련 모델 성능 상세 분석
사전 훈련 단계에서의 성능 평가는 모델의 기본적인 언어 이해 능력과 추론 능력을 측정하는 중요한 지표입니다. 다음 표는 사실성과 상식 추론 능력에 대한 상세한 결과를 보여줍니다.
| 벤치마크 | Gemma 2 2B | Gemma 2 9B | Gemma 2 27B | Gemma 3 1B | Gemma 3 4B | Gemma 3 12B | Gemma 3 27B |
|---|---|---|---|---|---|---|---|
| HellaSwag | 72.9 | 81.9 | 86.4 | 62.3 | 77.2 | 84.2 | 85.6 |
| BoolQ | 75.6 | 77.5 | 76.2 | 63.2 | 72.3 | 78.8 | 82.4 |
| PIQA | 78.1 | 81.9 | 83.5 | 73.8 | 79.6 | 81.8 | 83.3 |
| SIQA | 51.8 | 53.3 | 53.8 | 48.9 | 51.9 | 53.4 | 54.9 |
| TriviaQA | 60.2 | 76.5 | 83.8 | 39.8 | 65.8 | 78.2 | 85.5 |
| Natural Questions | 17.2 | 29.2 | 34.7 | 9.48 | 20.0 | 31.4 | 36.1 |
| ARC-C | 55.8 | 69.1 | 71.4 | 38.4 | 56.2 | 68.9 | 70.6 |
| ARC-E | 80.6 | 88.3 | 88.6 | 73.0 | 82.4 | 88.3 | 89.0 |
| WinoGrande | 65.4 | 73.9 | 79.4 | 58.2 | 64.7 | 74.3 | 78.8 |
| BBH | 42.4 | 69.4 | 74.8 | 28.4 | 50.9 | 72.6 | 77.7 |
| DROP | 53.2 | 71.5 | 75.2 | 42.4 | 60.1 | 72.2 | 77.2 |
이 결과들은 Gemma 3 모델들이 이전 버전과 비교하여 전반적으로 유사하거나 향상된 성능을 보임을 나타냅니다. 특히 주목할 점은 이러한 능력들이 이번 버전의 주요 개선 목표가 아니었음에도 불구하고 성능이 유지되거나 개선되었다는 것입니다.
HellaSwag는 상식적 추론 능력을 평가하는 벤치마크로, Zellers et al. (2019)에서 제안되었습니다. 이 벤치마크는 일상적인 상황에서의 다음 행동을 예측하는 능력을 측정합니다.
BoolQ는 Clark et al. (2019)에서 개발된 예/아니오 질문 답변 벤치마크로, 자연어 추론 능력을 평가합니다.
PIQA는 Bisk et al. (2019)에서 제안된 물리적 상식 추론 벤치마크로, 일상적인 물리적 상황에 대한 이해를 측정합니다.
STEM 및 코딩 성능 분석
STEM 관련 작업과 코딩 능력에서 Gemma 3 모델들은 상당한 개선을 보였습니다.
| 벤치마크 | Gemma 2 2B | Gemma 2 9B | Gemma 2 27B | Gemma 3 4B | Gemma 3 12B | Gemma 3 27B |
|---|---|---|---|---|---|---|
| MMLU | 52.2 | 71.2 | 75.2 | 59.6 | 74.5 | 78.6 |
| MMLU-Pro | 22.2 | 43.7 | 49.4 | 29.2 | 45.3 | 52.2 |
| AGIEval | 31.6 | 53.1 | 55.1 | 42.1 | 57.4 | 66.2 |
| MATH | 16.4 | 36.4 | 42.1 | 24.2 | 43.3 | 50.0 |
| GSM8K | 25.0 | 70.2 | 74.6 | 38.4 | 71.0 | 82.6 |
| GPQA Diamond | 12.5 | 24.8 | 26.3 | 15.0 | 25.4 | 24.3 |
| MBPP | 31.0 | 51.2 | 60.8 | 46.0 | 60.4 | 65.6 |
| HumanEval | 19.5 | 40.2 | 51.2 | 36.0 | 45.7 | 48.8 |
MMLU (Massive Multitask Language Understanding)는 Hendrycks et al. (2020)에서 제안된 종합적인 지식 평가 벤치마크로, 57개의 다양한 학문 분야에 걸친 객관식 문제를 포함합니다.
MATH는 Hendrycks et al. (2021)에서 개발된 수학 문제 해결 벤치마크로, 고등학교 수준의 수학 경시대회 문제들을 포함합니다.
GSM8K는 Cobbe et al. (2021)에서 제안된 초등학교 수준의 수학 단어 문제 벤치마크입니다.
이러한 결과들은 Gemma 3 모델들이 수학적 추론과 코딩 능력에서 일관된 개선을 보임을 나타냅니다. 특히 4B와 12B 모델에서 코딩 성능의 향상이 두드러지지만, 27B 모델에서는 상대적으로 미미한 개선을 보였습니다.
멀티모달 성능 평가
비전 인코더가 포함된 모델들의 이미지 이해 능력을 평가한 결과는 다음과 같습니다.
| 벤치마크 | Gemma 3 4B | Gemma 3 12B | Gemma 3 27B |
|---|---|---|---|
| COCO Caption | 102 | 111 | 116 |
| DocVQA | 72.8 | 82.3 | 85.6 |
| InfoVQA | 44.1 | 54.8 | 59.4 |
| MMMU | 39.2 | 50.3 | 56.1 |
| TextVQA | 58.9 | 66.5 | 68.6 |
| RealWorldQA | 45.5 | 52.2 | 53.9 |
| ReMI | 27.3 | 38.5 | 44.8 |
| AI2D | 63.2 | 75.2 | 79.0 |
| ChartQA | 63.6 | 74.7 | 76.3 |
| VQAv2 | 63.9 | 71.2 | 72.9 |
DocVQA는 Mathew et al. (2020)에서 제안된 문서 시각적 질문 답변 벤치마크로, 문서 이미지에서 정보를 추출하고 이해하는 능력을 평가합니다.
TextVQA는 Singh et al. (2019)에서 개발된 텍스트 기반 시각적 질문 답변 벤치마크로, 이미지 내의 텍스트를 읽고 이해하는 능력을 측정합니다.
MMMU는 Yue et al. (2023)에서 제안된 대학 수준의 멀티모달 이해 벤치마크로, 다양한 학문 분야의 시각적 자료를 포함한 문제들을 다룹니다.
다국어 성능 분석
Gemma 3 모델들의 다국어 능력 평가 결과는 다음과 같습니다.
| 벤치마크 | Gemma 2 2B | Gemma 2 9B | Gemma 2 27B | Gemma 3 1B | Gemma 3 4B | Gemma 3 12B | Gemma 3 27B |
|---|---|---|---|---|---|---|---|
| MGSM | 18.7 | 57.3 | 68.0 | 2.04 | 34.7 | 64.3 | 74.3 |
| Global-MMLU-Lite | 43.3 | 64.0 | 69.4 | 24.9 | 57.0 | 69.4 | 75.7 |
| WMT24++ | 38.8 | 50.3 | 53.0 | 36.7 | 48.4 | 53.9 | 55.7 |
| FLoRes | 30.2 | 41.3 | 44.3 | 29.5 | 39.2 | 46.0 | 48.8 |
| XQuAD | 53.7 | 72.2 | 73.9 | 43.9 | 68.0 | 74.5 | 76.8 |
| ECLeKTic | 8.29 | 14.0 | 17.1 | 4.69 | 11.0 | 17.2 | 24.4 |
| IndicGenBench | 47.4 | 59.3 | 62.1 | 41.4 | 57.2 | 61.7 | 63.4 |
MGSM은 Shi et al. (2023)에서 제안된 다국어 수학 문제 해결 벤치마크로, 10개 언어에서의 수학적 추론 능력을 평가합니다.
FLoRes는 Goyal et al. (2022)에서 개발된 다국어 기계 번역 벤치마크로, 200개 이상의 언어를 지원합니다.
긴 컨텍스트 성능
긴 컨텍스트 처리 능력을 평가한 결과는 다음과 같습니다.
| 모델 | RULER 32K | RULER 128K | MRCR 32K | MRCR 128K |
|---|---|---|---|---|
| Gemma 3 PT 4B | 67.1 | 51.7 | 44.7 | 40.6 |
| Gemma 3 PT 12B | 90.6 | 80.7 | 59.8 | 56.9 |
| Gemma 3 PT 27B | 85.9 | 72.9 | 63.2 | 60.0 |
| Gemma 3 IT 4B | 61.4 | 46.8 | 49.8 | 44.6 |
| Gemma 3 IT 12B | 80.3 | 57.1 | 53.7 | 49.8 |
| Gemma 3 IT 27B | 91.1 | 66.0 | 63.2 | 59.3 |
RULER은 Hsieh et al. (2024)에서 제안된 긴 컨텍스트 언어 모델 평가 벤치마크로, 다양한 작업 카테고리를 통해 단순한 검색을 넘어선 긴 컨텍스트 이해 능력을 측정합니다.
MRCR (Multi-Round Co-reference Resolution)은 Vodrahalli et al. (2024)에서 개발된 Michelangelo 벤치마크의 일부로, 긴 대화 맥락에서 유사한 텍스트 조각들을 구별하는 능력을 평가합니다.
지시 튜닝 모델 추가 성능
지시 튜닝된 모델들의 추가적인 벤치마크 결과는 다음과 같습니다.
| 벤치마크 | Gemma 2 2B | Gemma 2 9B | Gemma 2 27B | Gemma 3 1B | Gemma 3 4B | Gemma 3 12B | Gemma 3 27B |
|---|---|---|---|---|---|---|---|
| MMLU | 56.1 | 71.3 | 76.2 | 38.8 | 58.1 | 71.9 | 76.9 |
| MBPP | 36.6 | 59.2 | 67.4 | 35.2 | 63.2 | 73.0 | 74.4 |
| HumanEval | 20.1 | 40.2 | 51.8 | 41.5 | 71.3 | 85.4 | 87.8 |
| N2C | 46.8 | 68.3 | 77.3 | 56.0 | 70.3 | 80.7 | 84.5 |
| LiveCodeBench | 7.0 | 20.0 | 29.0 | 5.0 | 23.0 | 32.0 | 39.0 |
| GSM8K | 62.6 | 88.1 | 91.1 | 62.8 | 89.2 | 94.4 | 95.9 |
| MATH | 27.2 | 49.4 | 55.6 | 48.0 | 75.6 | 83.8 | 89.0 |
| HiddenMath | 2.0 | 8.0 | 12.0 | 15.0 | 42.0 | 51.0 | 56.0 |
| BBH | 41.4 | 69.0 | 74.9 | 39.1 | 72.2 | 85.7 | 87.6 |
| BBEH | 5.9 | 9.8 | 14.8 | 7.2 | 11.0 | 16.3 | 19.3 |
| IFEval | 80.4 | 88.4 | 91.1 | 80.2 | 90.2 | 88.9 | 90.4 |
N2C (Natural2Code)는 Gemini 1.0의 내부 보류 데이터셋으로, 웹 기반 정보 대신 저자가 생성한 소스를 사용합니다.
BBEH (BIG-Bench Extra Hard)는 Kazemi et al. (2025)에서 제안된 도전적인 LLM 추론 벤치마크로, 여러 추론 작업을 집계합니다.
LiveCodeBench는 실시간 코딩 능력을 평가하는 벤치마크로, 8개 샘플의 평균을 사용합니다.
평가 프로토콜 상세 정보
모든 벤치마크 평가는 일관된 프로토콜을 따라 수행되었습니다. 텍스트 벤치마크의 경우 다음과 같은 설정이 사용되었습니다.
- MBPP: pass@1 샘플링, 3-shot
- HumanEval: pass@1 샘플링, 0-shot
- HellaSwag: 정확도 스코어링, 10-shot, 문자 길이 정규화
- BoolQ: 정확도 스코어링, 0-shot, 문자 길이 정규화
- MATH: 정확도 샘플링, 4-shot, Chain-of-Thought 프롬프팅
- GSM8K: 정확도 샘플링, 8-shot 또는 5-shot, Chain-of-Thought 프롬프팅
비전 벤치마크의 경우:
- COCO Caption: CIDEr 점수 샘플링, 4-shot
- DocVQA: ANLS 점수 샘플링, 4-shot
- TextVQA: 정확도 샘플링, 4-shot
- MMMU: 정확도 샘플링, 3-shot (텍스트만)
이러한 상세한 평가 결과들은 Gemma 3 모델들이 다양한 영역에서 일관된 성능 향상을 달성했음을 보여주며, 특히 수학, 코딩, 다국어 능력에서 두드러진 개선을 나타냅니다.
References
Subscribe via RSS