Qwen3 Technical Report
by Alibaba Group
Contents
TL;DR
이 연구를 시작하게 된 배경과 동기는 무엇입니까?
인공지능 분야에서 대규모 언어 모델의 발전은 끊임없이 인간의 지능에 근접하려는 도전의 연장선상에 있습니다. GPT-4o, Claude 3.7, Gemini 2.5와 같은 최신 모델들은 인공 일반 지능(AGI)을 향한 중요한 이정표를 제시하고 있지만, 여전히 계산 효율성, 다국어 지원, 추론 능력 등에서 한계를 보여왔습니다. 특히 기존 모델들은 복잡한 추론 작업과 다양한 언어 환경에서 일관된 성능을 유지하는 데 어려움을 겪어왔습니다.
이러한 맥락에서 Qwen3 연구팀은 오픈소스 대규모 언어 모델의 새로운 패러다임을 제시하고자 했습니다. 그들의 주요 목표는 계산 효율성을 높이면서도 다국어 지원과 추론 능력을 획기적으로 개선하는 것이었습니다. 특히 사용자가 모델의 추론 깊이를 동적으로 제어할 수 있는 유연한 프레임워크를 개발함으로써, 기존 모델들의 경직된 작동 방식을 근본적으로 혁신하고자 했습니다.
이 연구에서 제시하는 새로운 해결 방법은 무엇입니까?
Qwen3의 가장 혁신적인 접근법은 사고 모드와 비사고 모드를 단일 모델 내에 통합한 것입니다. 이 접근법은 기존에 서로 다른 모델 간 전환이 필요했던 방식을 완전히 탈피하여, 사용자가 동적으로 모델의 추론 깊이를 조절할 수 있게 합니다. 특히 사고 예산 메커니즘을 도입하여 작업의 복잡성에 따라 계산 자원을 적응적으로 할당할 수 있도록 설계했습니다.
또한 Qwen3는 119개 언어와 방언을 포괄하는 36조 개의 토큰으로 사전 훈련되어 다국어 지원을 획기적으로 확장했습니다. 이를 위해 Qwen2.5-VL 모델을 활용해 PDF 문서에서 텍스트를 추출하고, 도메인별 모델들을 사용해 합성 데이터를 생성하는 혁신적인 데이터 확장 전략을 채택했습니다. 이러한 접근법은 단순한 데이터 수집을 넘어 AI 모델 자체를 데이터 생성에 활용하는 새로운 패러다임을 제시합니다.
제안된 방법은 어떻게 구현되었습니까?
Qwen3의 구현은 3단계 사전 훈련 전략을 중심으로 이루어졌습니다. 첫 번째 단계에서는 30조 개 이상의 토큰으로 일반 언어 능력을 훈련하고, 두 번째 단계에서는 STEM, 코딩, 추론 능력에 중점을 둡니다. 마지막 단계에서는 컨텍스트 길이를 32,768 토큰으로 확장하여 모델의 처리 능력을 높였습니다.
아키텍처 측면에서 Qwen3는 Grouped Query Attention(GQA), SwiGLU 활성화 함수, Rotary Positional Embeddings(RoPE) 등 최신 기술을 통합했습니다. 특히 MoE(Mixture-of-Expert) 모델에서는 128개의 전문가를 활용하고, 토큰당 8개의 전문가를 활성화하는 방식으로 계산 효율성을 극대화했습니다. 후훈련 과정에서는 Long-CoT 콜드 스타트, 추론 강화학습, 사고 모드 융합 등 정교한 단계를 거쳐 모델의 성능을 지속적으로 개선했습니다.
이 연구의 결과가 가지는 의미는 무엇입니까?
Qwen3의 실험 결과는 매우 인상적입니다. Qwen3-235B-A22B 모델은 AIME'24에서 85.7점, LiveCodeBench v5에서 70.7점 등 다양한 벤치마크에서 최첨단 성능을 달성했습니다. 특히 주목할 만한 점은 DeepSeek-V3와 같은 기존 최고 모델들과 비교하여 총 매개변수의 1/3, 활성화 매개변수의 2/3만으로 대부분의 벤치마크에서 우수한 성능을 보였다는 것입니다.
이 연구는 대규모 언어 모델 분야에 여러 중요한 시사점을 제공합니다. 첫째, 모델의 추론 능력을 동적으로 제어할 수 있는 새로운 접근법을 제시했으며, 둘째 오픈소스 모델의 성능과 효율성에 대한 새로운 기준을 제시했습니다. 특히 119개 언어를 지원하며 Apache 2.0 라이선스로 공개됨으로써 AI 연구의 개방성과 접근성을 크게 향상시켰다는 점에서 그 의의가 큽니다.
Qwen3 기술 보고서
초록
Qwen3는 대규모 언어 모델 분야에서 성능, 효율성, 그리고 다국어 지원 능력을 크게 향상시킨 최신 파운데이션 모델 시리즈입니다. 이 모델 시리즈는 0.6억 개부터 2,350억 개까지의 매개변수를 가진 다양한 규모의 모델들로 구성되어 있으며, 밀집형(dense) 아키텍처와 전문가 혼합(Mixture-of-Expert, MoE) 아키텍처를 모두 포함하고 있습니다.
Qwen3의 가장 혁신적인 특징 중 하나는 복잡한 다단계 추론을 위한 사고 모드(thinking mode)와 빠른 맥락 기반 응답을 위한 비사고 모드(non-thinking mode)를 하나의 통합된 프레임워크 안에 결합했다는 점입니다. 이는 기존에 채팅에 최적화된 모델(예: GPT-4o)과 전용 추론 모델(예: QwQ-32B) 사이를 전환해야 했던 필요성을 완전히 제거하며, 사용자 쿼리나 채팅 템플릿에 따라 동적으로 모드를 전환할 수 있게 합니다.
더 나아가 Qwen3는 사고 예산 메커니즘(thinking budget mechanism)을 도입하여 사용자가 추론 과정에서 계산 자원을 적응적으로 할당할 수 있도록 합니다. 이를 통해 작업의 복잡성에 따라 지연 시간과 성능 사이의 균형을 조절할 수 있습니다. 또한 플래그십 모델의 지식을 활용하여 소규모 모델 구축에 필요한 계산 자원을 크게 줄이면서도 높은 경쟁력을 유지할 수 있도록 했습니다.
실험적 평가 결과, Qwen3는 코드 생성, 수학적 추론, 에이전트 작업 등 다양한 벤치마크에서 최첨단 성능을 달성했으며, 더 큰 MoE 모델들과 독점 모델들과 경쟁할 수 있는 수준을 보여줍니다. 특히 AIME'24에서 85.7점, AIME'25에서 81.5점, LiveCodeBench v5에서 70.7점, CodeForces에서 2,056점, BFCL v3에서 70.8점을 달성했습니다.
이전 버전인 Qwen2.5와 비교했을 때, Qwen3는 다국어 지원을 29개 언어에서 119개 언어와 방언으로 확장하여 전 세계적인 접근성을 크게 향상시켰습니다. 모든 Qwen3 모델은 Apache 2.0 라이선스 하에 공개되어 재현 가능성과 커뮤니티 주도의 연구 개발을 촉진합니다.
서론
인공 일반 지능(AGI) 또는 인공 초지능(ASI)의 추구는 오랫동안 인류의 목표였습니다. 최근 GPT-4o, Claude 3.7, Gemini 2.5, DeepSeek-V3, Llama-4, 그리고 Qwen2.5와 같은 대규모 파운데이션 모델들의 발전은 이러한 목표를 향한 상당한 진전을 보여주고 있습니다.
이러한 모델들은 다양한 도메인과 작업에 걸쳐 수조 개의 토큰으로 구성된 방대한 데이터셋으로 훈련되어, 인간의 지식과 능력을 효과적으로 매개변수에 증류하고 있습니다. 더욱이 강화학습을 통해 최적화된 최근의 추론 모델 개발은 파운데이션 모델이 추론 시간 스케일링을 향상시키고 더 높은 수준의 지능을 달성할 수 있는 잠재력을 보여주고 있습니다. 예를 들어 o3와 DeepSeek-R1 같은 모델들이 이러한 발전을 대표합니다.
대부분의 최첨단 모델들이 여전히 독점적인 상태로 남아있지만, 오픈소스 커뮤니티의 급속한 성장은 오픈 웨이트 모델과 폐쇄형 소스 모델 간의 성능 격차를 상당히 줄였습니다. 특히 주목할 점은 점점 더 많은 최고 수준의 모델들(Llama-4, DeepSeek-V3, DeepSeek-R1, Qwen2.5)이 오픈소스로 공개되고 있어 인공지능 분야의 더 광범위한 연구와 혁신을 촉진하고 있다는 것입니다.
Qwen3의 핵심 혁신
이 연구에서는 파운데이션 모델 패밀리인 Qwen의 최신 시리즈인 Qwen3를 소개합니다. Qwen3는 다양한 작업과 도메인에서 최첨단 성능을 달성하는 오픈 웨이트 대규모 언어 모델들의 집합입니다. 다양한 하위 애플리케이션의 요구사항을 충족하기 위해 0.6억 개부터 2,350억 개까지의 매개변수를 가진 밀집형과 전문가 혼합(MoE) 모델을 모두 공개합니다.
특히 플래그십 모델인 Qwen3-235B-A22B는 총 2,350억 개의 매개변수를 가지고 있으며 토큰당 220억 개의 매개변수가 활성화되는 MoE 모델입니다. 이러한 설계는 높은 성능과 효율적인 추론을 모두 보장합니다.
Qwen3는 기능성과 사용성을 향상시키기 위한 몇 가지 핵심적인 발전을 도입합니다. 첫째, 사고 모드와 비사고 모드라는 두 가지 서로 다른 작동 모드를 단일 모델에 통합했습니다. 이를 통해 사용자는 Qwen2.5에서 QwQ로 전환하는 것과 같이 서로 다른 모델 간을 전환할 필요 없이 이러한 모드들 사이를 전환할 수 있습니다. 이러한 유연성은 개발자와 사용자가 특정 작업에 맞게 모델의 행동을 효율적으로 적응시킬 수 있도록 보장합니다.
또한 Qwen3는 사고 예산(thinking budgets)을 통합하여 사용자가 작업 실행 중 모델이 적용하는 추론 노력의 수준을 세밀하게 제어할 수 있도록 합니다. 이 기능은 계산 자원과 성능의 최적화에 중요하며, 실제 애플리케이션에서 다양한 복잡성에 맞춰 모델의 사고 행동을 조정할 수 있게 합니다.
대규모 다국어 사전 훈련
더 나아가 Qwen3는 최대 119개 언어와 방언을 포괄하는 36조 개의 토큰으로 사전 훈련되어 다국어 능력을 효과적으로 향상시켰습니다. 이러한 확장된 언어 지원은 전 세계적인 사용 사례와 국제적 애플리케이션에서의 배포 잠재력을 증폭시킵니다.
Qwen3의 사전 훈련 과정은 언어적 및 도메인 다양성을 보장하기 위해 큐레이션된 약 36조 개의 토큰으로 구성된 대규모 데이터셋을 활용합니다. 훈련 데이터를 효율적으로 확장하기 위해 다중 모달 접근법을 사용합니다. Qwen2.5-VL을 파인튜닝하여 광범위한 PDF 문서에서 텍스트를 추출하고, 수학적 콘텐츠를 위한 Qwen2.5-Math와 코드 관련 데이터를 위한 Qwen2.5-Coder와 같은 도메인별 모델을 사용하여 합성 데이터를 생성합니다.
3단계 사전 훈련 전략
사전 훈련 과정은 3단계 전략을 따릅니다. 첫 번째 단계에서는 일반적인 지식의 강력한 기반을 구축하기 위해 약 30조 개의 토큰으로 모델을 훈련합니다. 두 번째 단계에서는 과학, 기술, 공학, 수학(STEM) 및 코딩과 같은 영역에서 추론 능력을 향상시키기 위해 지식 집약적 데이터로 추가 훈련을 진행합니다. 마지막으로 세 번째 단계에서는 최대 컨텍스트 길이를 4,096 토큰에서 32,768 토큰으로 늘리기 위해 긴 컨텍스트 데이터로 모델을 훈련합니다.
다단계 후훈련 접근법
파운데이션 모델을 인간의 선호도와 하위 애플리케이션에 더 잘 맞추기 위해, 사고(추론) 모드와 비사고 모드를 모두 강화하는 다단계 후훈련 접근법을 사용합니다. 처음 두 단계에서는 긴 체인 오브 소트(CoT) 콜드 스타트 파인튜닝과 수학 및 코딩 작업에 중점을 둔 강화학습을 통해 강력한 추론 능력 개발에 집중합니다.
마지막 두 단계에서는 추론 경로가 있는 데이터와 없는 데이터를 통합 데이터셋으로 결합하여 추가 파인튜닝을 진행하여 모델이 두 유형의 입력을 효과적으로 처리할 수 있도록 하고, 이후 광범위한 하위 작업에서 성능을 향상시키기 위해 일반 도메인 강화학습을 적용합니다.
소규모 모델의 경우, 강한 모델에서 약한 모델로의 증류를 사용하여 더 큰 모델로부터의 오프 정책 및 온 정책 지식 전달을 활용하여 능력을 향상시킵니다. 고급 교사 모델로부터의 증류는 성능과 훈련 효율성 면에서 강화학습을 크게 능가합니다.
종합적인 성능 평가
사전 훈련된 버전과 후훈련된 버전의 모델을 모두 여러 작업과 도메인에 걸친 포괄적인 벤치마크 세트에서 평가했습니다. 실험 결과는 기본 사전 훈련된 모델들이 최첨단 성능을 달성함을 보여줍니다. 사고 모드든 비사고 모드든 후훈련된 모델들은 o1, o3-mini, DeepSeek-V3와 같은 주요 독점 모델들과 대규모 전문가 혼합(MoE) 모델들과 경쟁적으로 수행됩니다.
특히 모델들은 코딩, 수학, 에이전트 관련 작업에서 뛰어난 성능을 보입니다. 예를 들어, 플래그십 모델 Qwen3-235B-A22B는 AIME'24에서 85.7점, AIME'25에서 81.5점, LiveCodeBench v5에서 70.7점, CodeForces에서 2,056점, BFCL v3에서 70.8점을 달성했습니다. 또한 Qwen3 시리즈의 다른 모델들도 각각의 크기에 비해 강력한 성능을 보여줍니다.
더욱이 사고 토큰에 대한 사고 예산을 늘리면 다양한 작업에서 모델의 성능이 일관되게 향상되는 것을 관찰했습니다. 이는 사용자가 작업의 복잡성에 따라 계산 자원을 동적으로 할당할 수 있는 유연성을 제공하며, 실제 애플리케이션에서 효율성과 성능 사이의 최적의 균형을 찾을 수 있게 합니다.
이어지는 섹션들에서는 모델 아키텍처의 설계를 설명하고, 훈련 절차에 대한 세부사항을 제공하며, 사전 훈련된 모델과 후훈련된 모델의 실험 결과를 제시하고, 마지막으로 주요 발견사항을 요약하고 향후 연구를 위한 잠재적 방향을 제시하며 이 기술 보고서를 마무리합니다.
아키텍처
Qwen3 시리즈는 다양한 규모의 애플리케이션 요구사항을 충족하기 위해 설계된 포괄적인 모델 패밀리로 구성되어 있습니다. 이 시리즈는 6개의 밀집형(dense) 모델과 2개의 전문가 혼합(Mixture-of-Expert, MoE) 모델로 구성되어 있으며, 각각 서로 다른 매개변수 규모와 성능 특성을 가지고 있습니다.
밀집형 모델 아키텍처
Qwen3의 밀집형 모델들은 Qwen3-0.6B, Qwen3-1.7B, Qwen3-4B, Qwen3-8B, Qwen3-14B, 그리고 Qwen3-32B로 구성되어 있습니다. 이러한 모델들의 아키텍처는 이전 버전인 Qwen2.5와 유사한 기본 구조를 유지하면서도 중요한 개선사항들을 포함하고 있습니다.
핵심 아키텍처 구성 요소들을 살펴보면, 먼저 Grouped Query Attention (GQA)가 적용되었습니다. GQA는 전통적인 멀티헤드 어텐션의 계산 효율성을 크게 향상시키는 혁신적인 메커니즘입니다. 이 방식은 쿼리(Q) 헤드의 수보다 키(K)와 값(V) 헤드의 수를 줄여서 계산 복잡도를 감소시키면서도 모델 성능을 유지합니다. 예를 들어, Qwen3-32B 모델의 경우 64개의 쿼리 헤드와 8개의 키/값 헤드를 사용하는 64/8 구성을 채택하고 있습니다.
GQA의 핵심 아이디어는 여러 쿼리 헤드가 동일한 키와 값 프로젝션을 공유하도록 하는 것입니다. 이는 다음과 같은 수학적 형태로 표현할 수 있습니다.
\[\text{Attention}(Q_i, K_j, V_j) = \text{softmax}\left(\frac{Q_i K_j^T}{\sqrt{d_k}}\right) V_j\]여기서 여러 개의 \(Q_i\) (쿼리 헤드)가 하나의 \(K_j, V_j\) (키/값 헤드) 쌍을 공유합니다. 이러한 설계는 특히 대규모 모델에서 메모리 사용량과 계산 비용을 크게 줄이면서도 표현력을 유지할 수 있게 해줍니다.
두 번째 핵심 구성 요소는 SwiGLU 활성화 함수입니다. SwiGLU는 기존의 GLU(Gated Linear Unit)를 개선한 고급 활성화 함수로, 더욱 표현력이 풍부한 특징 변환을 제공합니다. SwiGLU의 수학적 정의는 다음과 같습니다.
\[\text{SwiGLU}(x) = \text{Swish}(W_1 x) \odot (W_2 x)\]여기서 \(\text{Swish}(x) = x \cdot \text{sigmoid}(x)\)이고, \(\odot\)는 원소별 곱셈을 나타냅니다. 이 활성화 함수는 적응적이고 맥락 의존적인 비선형성을 도입하여 모델의 표현 능력을 크게 향상시킵니다.
세 번째로, Rotary Positional Embeddings (RoPE)가 위치 정보 인코딩을 위해 사용됩니다. RoPE는 회전 변환을 통해 절대적 및 상대적 위치 정보를 어텐션 메커니즘에 효율적으로 통합하는 혁신적인 방법입니다. 이는 특히 긴 시퀀스 처리에서 뛰어난 성능을 보이며, 모델이 다양한 시퀀스 길이에 대해 더 나은 일반화 능력을 갖도록 합니다.
네 번째 구성 요소는 RMSNorm입니다. RMSNorm은 전통적인 레이어 정규화의 계산 효율적인 대안으로, 평균 제거 과정을 생략하여 계산 복잡도를 줄이면서도 안정적인 훈련 동역학을 제공합니다. 수학적으로는 다음과 같이 표현됩니다.
\[\text{RMSNorm}(x) = \frac{x}{\sqrt{\frac{1}{n}\sum_{i=1}^n x_i^2}} \cdot \gamma\]여기서 \(\gamma\)는 학습 가능한 스케일 매개변수입니다.
Qwen3에서 도입된 중요한 개선사항 중 하나는 QK-Norm의 추가입니다. QK-Norm은 어텐션 메커니즘에서 쿼리(Q)와 키(K) 벡터를 정규화하여 훈련 안정성을 보장하는 기법입니다. 이는 Qwen2에서 사용되던 QKV-bias를 제거하고 대신 도입된 것으로, 더욱 안정적인 훈련 과정을 가능하게 합니다.
| 모델 | 레이어 수 | 헤드 수 (Q / KV) | 임베딩 공유 | 컨텍스트 길이 |
|---|---|---|---|---|
| Qwen3-0.6B | 28 | 16 / 8 | Yes | 32K |
| Qwen3-1.7B | 28 | 16 / 8 | Yes | 32K |
| Qwen3-4B | 36 | 32 / 8 | Yes | 128K |
| Qwen3-8B | 36 | 32 / 8 | No | 128K |
| Qwen3-14B | 40 | 40 / 8 | No | 128K |
| Qwen3-32B | 64 | 64 / 8 | No | 128K |
위 표에서 볼 수 있듯이, 모델 크기가 증가함에 따라 레이어 수와 어텐션 헤드 수가 체계적으로 증가합니다. 특히 주목할 점은 작은 모델들(0.6B, 1.7B, 4B)은 임베딩 가중치를 공유하여 매개변수 효율성을 높이는 반면, 더 큰 모델들은 독립적인 임베딩을 사용하여 표현력을 극대화한다는 것입니다. 또한 4B 이상의 모델들은 128K 토큰의 긴 컨텍스트를 지원하여 더 복잡한 작업을 처리할 수 있습니다.
전문가 혼합(MoE) 모델 아키텍처
Qwen3 시리즈는 또한 두 개의 MoE 모델인 Qwen3-30B-A3B와 Qwen3-235B-A22B를 포함하고 있습니다. 플래그십 모델인 Qwen3-235B-A22B는 총 2,350억 개의 매개변수를 가지고 있으며, 토큰당 220억 개의 매개변수가 활성화됩니다.
MoE 모델들은 밀집형 모델과 동일한 기본 아키텍처를 공유하면서도 전문가 네트워크를 통한 조건부 계산을 활용합니다. 이들은 Qwen2.5-MoE를 따라 세분화된 전문가 분할(fine-grained expert segmentation)을 구현합니다. DeepSeekMoE에서 제안된 이 접근법은 더욱 정교하고 전문화된 토큰 처리를 가능하게 합니다.
Qwen3 MoE 모델의 핵심 특징은 다음과 같습니다.
전문가 구성: 총 128개의 전문가를 보유하며, 토큰당 8개의 전문가가 활성화됩니다. 이는 다음과 같은 수학적 형태로 표현할 수 있습니다.
\[y = \sum_{i \in \text{Top-k}} G(x)_i \cdot E_i(x)\]여기서 \(G(x)\)는 게이팅 함수, \(E_i(x)\)는 \(i\)번째 전문가의 출력, Top-k는 선택된 상위 k개(여기서는 8개)의 전문가를 나타냅니다.
공유 전문가 제거: Qwen2.5-MoE와 달리 Qwen3-MoE는 공유 전문가를 사용하지 않습니다. 이는 각 전문가가 더욱 특화된 역할을 수행할 수 있도록 하여 전체적인 모델 효율성을 향상시킵니다.
글로벌 배치 로드 밸런싱: 글로벌 배치 로드 밸런싱 손실을 채택하여 전문가 특화를 촉진합니다. 이는 모든 전문가가 균등하게 활용되도록 하면서도 각각의 고유한 전문성을 개발할 수 있게 합니다.
| 모델 | 총 매개변수 | 활성화 매개변수 | 전문가 수 | 활성화 전문가 수 |
|---|---|---|---|---|
| Qwen3-30B-A3B | 30B | 3B | 128 | 8 |
| Qwen3-235B-A22B | 235B | 22B | 128 | 8 |
토크나이저 아키텍처
모든 Qwen3 모델은 Qwen의 토크나이저를 활용합니다. 이 토크나이저는 바이트 수준 바이트 쌍 인코딩(Byte-level Byte-Pair Encoding, BBPE)을 구현하며, 151,669개의 어휘 크기를 가지고 있습니다. BBPE는 GPT-3에서 처음 도입된 방식으로, 다양한 언어와 특수 문자를 효율적으로 처리할 수 있는 강력한 토큰화 방법입니다.
BBPE의 핵심 장점은 다음과 같습니다.
언어 독립성: 바이트 수준에서 작동하므로 어떤 언어나 문자 체계도 처리할 수 있습니다.
효율적인 압축: 자주 나타나는 바이트 시퀀스를 단일 토큰으로 병합하여 시퀀스 길이를 효과적으로 줄입니다.
견고성: 훈련 중에 보지 못한 문자나 기호도 바이트 수준에서 처리할 수 있어 out-of-vocabulary 문제를 해결합니다.
이러한 아키텍처적 혁신과 훈련 기법들의 결합은 다양한 하위 작업에서 모델 성능의 상당한 향상을 가져왔습니다. 특히 GQA와 SwiGLU의 조합은 계산 효율성과 표현력 사이의 최적의 균형을 제공하며, RoPE와 RMSNorm은 긴 시퀀스 처리와 안정적인 훈련을 가능하게 합니다. MoE 아키텍처에서의 세분화된 전문가 분할과 글로벌 로드 밸런싱은 대규모 모델의 효율적인 확장을 실현합니다.
사전 훈련
이 섹션에서는 Qwen3 모델의 사전 훈련 데이터 구축, 훈련 접근법의 세부사항, 그리고 표준 벤치마크에서 기본 모델들을 평가한 실험 결과를 설명합니다.
사전 훈련 데이터
Qwen3는 이전 버전인 Qwen2.5와 비교하여 훈련 데이터의 규모와 다양성을 크게 확장했습니다. 구체적으로, 사전 훈련 토큰 수를 두 배로 늘리고 지원 언어를 세 배로 확장했습니다. 모든 Qwen3 모델은 119개 언어와 방언을 포괄하는 총 36조 개의 토큰으로 구성된 대규모 다양성 데이터셋으로 훈련됩니다.
이 데이터셋은 코딩, STEM(과학, 기술, 공학, 수학), 추론 작업, 도서, 다국어 텍스트, 합성 데이터 등 다양한 도메인의 고품질 콘텐츠를 포함합니다. 이러한 광범위한 도메인 커버리지는 모델이 특정 분야에 편향되지 않고 균형 잡힌 지식을 습득할 수 있도록 보장합니다.
혁신적인 데이터 확장 전략
사전 훈련 데이터 코퍼스를 더욱 확장하기 위해 Qwen3 연구팀은 혁신적인 다단계 접근법을 채택했습니다. 먼저 Qwen2.5-VL 모델을 활용하여 대량의 PDF 형태 문서에서 텍스트 인식을 수행합니다. 이는 기존의 텍스트 기반 데이터 수집 방식을 넘어서 시각적 문서에서도 고품질 텍스트를 추출할 수 있게 해주는 중요한 혁신입니다.
인식된 텍스트는 이후 Qwen2.5 모델을 사용하여 정제됩니다. 이러한 2단계 프로세스를 통해 품질을 향상시키며, 총 수조 개에 달하는 추가적인 고품질 텍스트 토큰을 확보할 수 있었습니다. 이는 단순히 기존 텍스트 데이터를 수집하는 것을 넘어서 멀티모달 접근법을 통해 데이터 소스를 확장한 혁신적인 시도입니다.
더 나아가, Qwen2.5, Qwen2.5-Math, Qwen2.5-Coder 모델들을 활용하여 다양한 형식의 수조 개 텍스트 토큰을 합성합니다. 이러한 합성 데이터는 교과서, 질문-답변, 지시사항, 코드 스니펫 등을 포함하며, 수십 개의 도메인을 아우릅니다. 이는 기존의 수동적인 데이터 수집 방식에서 벗어나 AI 모델 자체를 활용한 능동적인 데이터 생성 전략을 보여줍니다.
다국어 지원의 대폭 확장
마지막으로, 추가적인 다국어 데이터를 통합하고 더 많은 언어를 도입하여 사전 훈련 코퍼스를 더욱 확장했습니다. Qwen2.5에서 사용된 사전 훈련 데이터와 비교했을 때, 지원 언어 수가 29개에서 119개로 대폭 증가하여 모델의 언어적 커버리지와 교차 언어 능력을 크게 향상시켰습니다.
이러한 다국어 확장은 단순히 언어 수를 늘리는 것을 넘어서 전 세계적인 접근성을 고려한 전략적 선택입니다. 119개 언어와 방언을 지원함으로써 Qwen3는 다양한 문화적, 언어적 배경을 가진 사용자들에게 더욱 포용적인 AI 서비스를 제공할 수 있게 되었습니다.
고도화된 데이터 주석 시스템
Qwen3 연구팀은 훈련 데이터의 품질과 다양성을 모두 향상시키기 위해 설계된 다국어 데이터 주석 시스템을 개발했습니다. 이 시스템은 대규모 사전 훈련 데이터셋에 적용되어 30조 개 이상의 토큰을 교육적 가치, 분야, 도메인, 안전성 등 여러 차원에서 주석을 달았습니다.
이러한 세밀한 주석은 더욱 효과적인 데이터 필터링과 조합을 지원합니다. 기존 연구들(doremi, doge, regmix)이 데이터 소스나 도메인 수준에서 데이터 혼합을 최적화했던 것과 달리, Qwen3의 방법은 세분화된 데이터 라벨을 통해 인스턴스 수준에서 데이터 혼합을 최적화합니다.
이는 소규모 프록시 모델에서의 광범위한 절제 실험을 통해 달성됩니다. 인스턴스 수준의 최적화는 각각의 개별 데이터 포인트에 대해 더욱 정교한 제어를 가능하게 하며, 이는 모델 성능의 미세한 조정과 특정 작업에 대한 최적화를 가능하게 합니다.
사전 훈련 단계
Qwen3 모델들은 체계적인 3단계 사전 훈련 프로세스를 통해 훈련됩니다. 각 단계는 서로 다른 목표와 특성을 가지며, 모델의 능력을 점진적으로 구축해 나갑니다.
1단계: 일반 단계 (S1)
첫 번째 사전 훈련 단계에서는 모든 Qwen3 모델이 4,096 토큰의 시퀀스 길이를 사용하여 30조 개 이상의 토큰으로 훈련됩니다. 이 단계에서 모델들은 언어 능력과 일반적인 세계 지식에 대해 완전히 사전 훈련되며, 훈련 데이터는 119개 언어와 방언을 포괄합니다.
이 단계의 핵심 목표는 모델이 다양한 언어에서 기본적인 언어 이해와 생성 능력을 습득하도록 하는 것입니다. 30조 개라는 방대한 토큰 수는 모델이 충분한 언어적 다양성과 지식의 폭을 경험할 수 있도록 보장합니다.
2단계: 추론 단계 (S2)
추론 능력을 더욱 향상시키기 위해, 이 단계의 사전 훈련 코퍼스는 STEM, 코딩, 추론, 합성 데이터의 비율을 증가시켜 최적화됩니다. 모델들은 4,096 토큰의 시퀀스 길이에서 약 5조 개의 더 높은 품질의 토큰으로 추가 사전 훈련됩니다.
이 단계에서는 또한 학습률 감소를 가속화합니다. 이는 모델이 더욱 정교한 추론 패턴을 학습할 수 있도록 하며, 특히 수학적 문제 해결, 논리적 추론, 코드 생성과 같은 복잡한 인지 작업에서의 성능을 향상시킵니다.
추론 단계의 도입은 단순한 언어 모델링을 넘어서 고차원적 사고 능력을 개발하려는 Qwen3의 전략적 접근을 보여줍니다. 이는 현대 AI 시스템이 단순한 패턴 매칭을 넘어서 실제 추론과 문제 해결 능력을 갖추어야 한다는 인식을 반영합니다.
3단계: 긴 컨텍스트 단계
마지막 사전 훈련 단계에서는 Qwen3 모델의 컨텍스트 길이를 확장하기 위해 고품질 긴 컨텍스트 코퍼스를 수집합니다. 모든 모델은 32,768 토큰의 시퀀스 길이로 수천억 개의 토큰에 대해 사전 훈련됩니다.
긴 컨텍스트 코퍼스는 신중하게 구성됩니다. 75%는 16,384~32,768 토큰 길이의 텍스트이고, 25%는 4,096~16,384 토큰 길이의 텍스트입니다. 이러한 구성은 모델이 다양한 길이의 컨텍스트를 효과적으로 처리할 수 있도록 균형 잡힌 학습 경험을 제공합니다.
고급 위치 인코딩 기법 적용
Qwen2.5를 따라, ABF 기법을 사용하여 RoPE의 기본 주파수를 10,000에서 1,000,000으로 증가시킵니다. 이는 모델이 더 긴 시퀀스에서도 위치 정보를 정확하게 인코딩할 수 있도록 하는 중요한 기술적 개선입니다.
동시에 YARN과 Dual Chunk Attention (DCA)를 도입하여 추론 시 시퀀스 길이 용량을 4배 증가시킵니다. 이러한 기법들의 조합은 모델이 훈련 시보다 더 긴 컨텍스트도 효과적으로 처리할 수 있게 해주는 혁신적인 접근법입니다.
YARN은 RoPE의 확장 방법 중 하나로, 긴 컨텍스트에서도 위치 임베딩의 품질을 유지할 수 있도록 설계되었습니다. DCA는 청크 기반 어텐션 메커니즘을 통해 메모리 효율성을 높이면서도 긴 시퀀스를 처리할 수 있게 합니다.
체계적인 스케일링 법칙 개발
Qwen2.5와 유사하게, 위에서 언급한 3단계 사전 훈련을 기반으로 최적 하이퍼파라미터(예: 학습률 스케줄러, 배치 크기) 예측을 위한 스케일링 법칙을 개발했습니다.
광범위한 실험을 통해 모델 아키텍처, 훈련 데이터, 훈련 단계, 그리고 최적 훈련 하이퍼파라미터 간의 관계를 체계적으로 연구했습니다. 이러한 연구를 바탕으로 각 밀집형 또는 MoE 모델에 대해 예측된 최적 학습률과 배치 크기 전략을 설정했습니다.
스케일링 법칙의 개발은 단순히 경험적 조정에 의존하는 것이 아니라 과학적이고 체계적인 접근법을 통해 모델 훈련을 최적화하려는 노력을 보여줍니다. 이는 대규모 모델 훈련에서 계산 자원의 효율적 활용과 성능 최적화를 동시에 달성하기 위한 중요한 방법론입니다.
이러한 3단계 사전 훈련 전략은 모델이 기본적인 언어 능력부터 고급 추론 능력, 그리고 긴 컨텍스트 처리 능력까지 점진적으로 발전시킬 수 있도록 설계된 체계적인 접근법입니다. 각 단계는 이전 단계의 성과를 바탕으로 더욱 전문화된 능력을 개발하며, 최종적으로 다양한 복잡한 작업을 수행할 수 있는 강력한 파운데이션 모델을 만들어냅니다.
사전 훈련 평가
Qwen3 시리즈의 기본 언어 모델들에 대한 종합적인 평가를 수행했습니다. 기본 모델 평가는 주로 일반 지식, 추론, 수학, 과학 지식, 코딩, 그리고 다국어 능력에서의 성능에 중점을 두었습니다. 사전 훈련된 기본 모델들의 평가 데이터셋은 15개의 벤치마크로 구성되어 있습니다.
평가 벤치마크 구성
일반 작업에서는 MMLU (5-shot), MMLU-Pro (5-shot, CoT), MMLU-redux (5-shot), BBH (3-shot, CoT), SuperGPQA (5-shot, CoT)가 사용되었습니다. 이러한 벤치마크들은 모델의 광범위한 지식 이해와 추론 능력을 평가하는 데 핵심적인 역할을 합니다.
수학 및 STEM 작업에서는 GPQA (5-shot, CoT), GSM8K (4-shot, CoT), MATH (4-shot, CoT)가 활용되었습니다. 이들은 모델의 수학적 추론과 과학적 문제 해결 능력을 체계적으로 평가합니다.
코딩 작업에서는 EvalPlus (0-shot)가 사용되었으며, 이는 HumanEval, MBPP, Humaneval+, MBPP+의 평균으로 구성됩니다. 또한 MultiPL-E (0-shot)는 Python, C++, JAVA, PHP, TypeScript, C#, Bash, JavaScript 등 다양한 프로그래밍 언어를 포괄하며, MBPP-3shot과 CRUXEval의 CRUX-O (1-shot)도 포함됩니다.
다국어 작업에서는 MGSM (8-shot, CoT), MMMLU (5-shot), INCLUDE (5-shot)가 사용되어 모델의 다국어 이해와 추론 능력을 평가합니다.
기본 모델 베이스라인으로는 Qwen3 시리즈 기본 모델들을 Qwen2.5 기본 모델들과 DeepSeek-V3 Base, Gemma-3, Llama-3, Llama-4 시리즈 기본 모델들과 같은 다른 주요 오픈소스 기본 모델들과 매개변수 규모 측면에서 비교했습니다. 모든 모델은 공정한 비교를 보장하기 위해 동일한 평가 파이프라인과 널리 사용되는 평가 설정을 사용하여 평가되었습니다.
평가 결과 요약
전체 평가 결과를 바탕으로 Qwen3 기본 모델들의 주요 결론들을 강조합니다.
첫째, 이전에 오픈소스로 공개된 최첨단 밀집형 및 MoE 기본 모델들(DeepSeek-V3 Base, Llama-4-Maverick Base, Qwen2.5-72B-Base 등)과 비교했을 때, Qwen3-235B-A22B-Base는 상당히 적은 총 매개변수 또는 활성화 매개변수로 대부분의 작업에서 이들 모델을 능가합니다.
둘째, Qwen3 MoE 기본 모델들에 대한 실험 결과는 다음과 같습니다. (a) 동일한 사전 훈련 데이터를 사용할 때, Qwen3 MoE 기본 모델들은 단지 1/5의 활성화 매개변수로 Qwen3 밀집형 기본 모델들과 유사한 성능을 달성할 수 있습니다. (b) Qwen3 MoE 아키텍처의 개선, 훈련 토큰의 확장, 그리고 더 고급 훈련 전략으로 인해, Qwen3 MoE 기본 모델들은 절반 미만의 활성화 매개변수와 더 적은 총 매개변수로 Qwen2.5 MoE 기본 모델들을 능가할 수 있습니다. (c) Qwen2.5 밀집형 기본 모델의 1/10의 활성화 매개변수만으로도 Qwen3 MoE 기본 모델은 비교 가능한 성능을 달성할 수 있어, 추론 및 훈련 비용에서 상당한 이점을 가져다줍니다.
셋째, Qwen3 밀집형 기본 모델들의 전체 성능은 더 높은 매개변수 규모에서 Qwen2.5 기본 모델들과 비교 가능합니다. 예를 들어, Qwen3-1.7B/4B/8B/14B/32B-Base는 각각 Qwen2.5-3B/7B/14B/32B/72B-Base와 비교 가능한 성능을 달성합니다. 특히 STEM, 코딩, 추론 벤치마크에서 Qwen3 밀집형 기본 모델들의 성능은 더 높은 매개변수 규모의 Qwen2.5 기본 모델들을 능가하기도 합니다.
Qwen3-235B-A22B-Base 상세 분석
| 모델 | 아키텍처 | 총 매개변수 | 활성화 매개변수 | MMLU | MMLU-Redux | MMLU-Pro | SuperGPQA | BBH |
|---|---|---|---|---|---|---|---|---|
| Qwen2.5-72B-Base | Dense | 72B | 72B | 86.06 | 83.91 | 58.07 | 36.20 | 86.30 |
| Qwen2.5-Plus-Base | MoE | 271B | 37B | 85.02 | 82.69 | 63.52 | 37.18 | 85.60 |
| Llama-4-Maverick-Base | MoE | 402B | 17B | 85.16 | 84.05 | 63.91 | 40.85 | 83.62 |
| DeepSeek-V3-Base | MoE | 671B | 37B | 87.19 | 86.14 | 59.84 | 41.53 | 86.22 |
| Qwen3-235B-A22B-Base | MoE | 235B | 22B | 87.81 | 87.40 | 68.18 | 44.06 | 88.87 |
| 모델 | GPQA | GSM8K | MATH | EvalPlus | MultiPL-E | MBPP | CRUX-O |
|---|---|---|---|---|---|---|---|
| Qwen2.5-72B-Base | 45.88 | 91.50 | 62.12 | 65.93 | 58.70 | 76.00 | 66.20 |
| Qwen2.5-Plus-Base | 41.92 | 91.89 | 62.78 | 61.43 | 62.16 | 74.60 | 68.50 |
| Llama-4-Maverick-Base | 43.94 | 87.72 | 63.32 | 68.38 | 57.28 | 75.40 | 77.00 |
| DeepSeek-V3-Base | 41.92 | 87.57 | 62.62 | 63.75 | 62.26 | 74.20 | 76.60 |
| Qwen3-235B-A22B-Base | 47.47 | 94.39 | 71.84 | 77.60 | 65.94 | 81.40 | 79.00 |
| 모델 | MGSM | MMMLU | INCLUDE |
|---|---|---|---|
| Qwen2.5-72B-Base | 82.40 | 84.40 | 69.05 |
| Qwen2.5-Plus-Base | 82.21 | 83.49 | 66.97 |
| Llama-4-Maverick-Base | 79.69 | 83.09 | 73.47 |
| DeepSeek-V3-Base | 82.68 | 85.88 | 75.17 |
| Qwen3-235B-A22B-Base | 83.53 | 86.70 | 73.46 |
Qwen3-235B-A22B-Base 모델은 평가된 벤치마크 대부분에서 최고 성능 점수를 달성했습니다. 다른 베이스라인들과의 세부적인 비교 분석을 통해 다음과 같은 결과를 확인할 수 있습니다.
최근 오픈소스로 공개된 Llama-4-Maverick-Base와 비교했을 때, 이 모델이 약 두 배의 매개변수를 가지고 있음에도 불구하고 Qwen3-235B-A22B-Base는 여전히 대부분의 벤치마크에서 더 나은 성능을 보입니다.
이전 최첨단 오픈소스 모델인 DeepSeek-V3-Base와 비교했을 때, Qwen3-235B-A22B-Base는 총 매개변수 수의 약 1/3과 2/3의 활성화 매개변수만으로 15개 평가 벤치마크 중 14개에서 DeepSeek-V3-Base를 능가하여 모델의 강력함과 비용 효율성을 입증합니다.
유사한 크기의 이전 MoE 모델인 Qwen2.5-Plus와 비교했을 때, Qwen3-235B-A22B-Base는 더 적은 매개변수와 활성화 매개변수로 상당히 뛰어난 성능을 보여주며, 이는 사전 훈련 데이터, 훈련 전략, 모델 아키텍처에서 Qwen3의 현저한 장점을 보여줍니다.
이전 플래그십 오픈소스 밀집형 모델인 Qwen2.5-72B-Base와 비교했을 때, Qwen3-235B-A22B-Base는 모든 벤치마크에서 후자를 능가하며 1/3 미만의 활성화 매개변수를 사용합니다. 동시에 모델 아키텍처의 장점으로 인해 Qwen3-235B-A22B-Base의 추론 비용과 각 조 토큰당 훈련 비용이 Qwen2.5-72B-Base보다 훨씬 저렴합니다.
Qwen3-32B-Base 성능 분석
| 모델 | 아키텍처 | 총 매개변수 | 활성화 매개변수 | MMLU | MMLU-Redux | MMLU-Pro | SuperGPQA | BBH |
|---|---|---|---|---|---|---|---|---|
| Qwen2.5-32B-Base | Dense | 32B | 32B | 83.32 | 81.97 | 55.10 | 33.55 | 84.48 |
| Qwen2.5-72B-Base | Dense | 72B | 72B | 86.06 | 83.91 | 58.07 | 36.20 | 86.30 |
| Gemma-3-27B-Base | Dense | 27B | 27B | 78.69 | 76.53 | 52.88 | 29.87 | 79.95 |
| Llama-4-Scout-Base | MoE | 109B | 17B | 78.27 | 71.09 | 56.13 | 26.51 | 82.40 |
| Qwen3-32B-Base | Dense | 32B | 32B | 83.61 | 83.41 | 65.54 | 39.78 | 87.38 |
Qwen3-32B-Base는 Qwen3 시리즈 중 가장 큰 밀집형 모델입니다. 유사한 크기의 베이스라인들과 비교했으며, 여기에는 Gemma-3-27B와 Qwen2.5-32B가 포함됩니다. 또한 두 개의 강력한 베이스라인을 도입했습니다. 최근 오픈소스로 공개된 MoE 모델 Llama-4-Scout로, Qwen3-32B-Base의 세 배 매개변수를 가지지만 절반의 활성화 매개변수를 가지며, 이전 플래그십 오픈소스 밀집형 모델인 Qwen2.5-72B-Base로, Qwen3-32B-Base와 비교하여 두 배 이상의 매개변수 수를 가집니다.
결과는 세 가지 핵심 결론을 뒷받침합니다. 첫째, 유사한 크기의 모델들과 비교했을 때, Qwen3-32B-Base는 대부분의 벤치마크에서 Qwen2.5-32B-Base와 Gemma-3-27B Base를 능가합니다. 특히 Qwen3-32B-Base는 MMLU-Pro에서 65.54점, SuperGPQA에서 39.78점을 달성하여 이전 버전인 Qwen2.5-32B-Base를 상당히 능가합니다. 또한 Qwen3-32B-Base는 모든 베이스라인 모델들보다 상당히 높은 인코딩 벤치마크 점수를 달성합니다.
놀랍게도 Qwen3-32B-Base는 Qwen2.5-72B-Base와 비교하여 경쟁력 있는 결과를 달성합니다. Qwen3-32B-Base가 Qwen2.5-72B-Base 매개변수 수의 절반 미만임에도 불구하고, 15개 평가 벤치마크 중 10개에서 Qwen2.5-72B-Base를 능가합니다. 코딩, 수학, 추론 벤치마크에서 Qwen3-32B-Base는 현저한 장점을 가집니다.
Llama-4-Scout-Base와 비교했을 때, Qwen3-32B-Base는 Llama-4-Scout-Base 매개변수 수의 1/3에 불과하지만 두 배의 활성화 매개변수를 가지면서 모든 15개 벤치마크에서 상당히 뛰어난 성능을 보입니다.
중간 규모 모델들의 성능
Qwen3-14B-Base와 Qwen3-30B-A3B-Base의 평가는 유사한 크기의 베이스라인들과 비교되었으며, 여기에는 Gemma-3-12B Base, Qwen2.5-14B Base가 포함됩니다. 마찬가지로 두 개의 강력한 베이스라인도 도입했습니다. 42B 매개변수와 6B 활성화 매개변수를 가진 Qwen2.5-Turbo로, 이는 Qwen3-30B-A3B-Base의 두 배 활성화 매개변수를 가지며, Qwen3-30B-A3B의 11배 활성화 매개변수와 Qwen3-14B의 두 배 이상을 가진 Qwen2.5-32B-Base입니다.
결과에서 다음과 같은 결론을 도출할 수 있습니다. 첫째, 유사한 크기의 모델들과 비교했을 때, Qwen3-14B-Base는 모든 15개 벤치마크에서 Qwen2.5-14B-Base와 Gemma-3-12B-Base보다 상당히 뛰어난 성능을 보입니다.
마찬가지로 Qwen3-14B-Base는 매개변수의 절반 미만으로 Qwen2.5-32B-Base와 비교하여 매우 경쟁력 있는 결과를 달성합니다.
단지 1/5의 활성화 비임베딩 매개변수로 Qwen3-30B-A3B는 모든 작업에서 Qwen2.5-14B-Base를 상당히 능가하며, Qwen3-14B-Base 및 Qwen2.5-32B-Base와 비교 가능한 성능을 달성하여 추론 및 훈련 비용에서 상당한 이점을 가져다줍니다.
소규모 엣지 모델들의 성능
엣지 사이드 모델들의 경우, 유사한 크기의 Qwen2.5, Llama-3, Gemma-3 기본 모델들을 베이스라인으로 사용했습니다. 모든 Qwen3 8B/4B/1.7B/0.6B-Base 모델들은 거의 모든 벤치마크에서 강력한 성능을 지속적으로 유지합니다. 특히 Qwen3-8B/4B/1.7B-Base 모델들은 벤치마크의 절반 이상에서 더 큰 크기의 Qwen2.5-14B/7B/3B Base 모델들을 능가하며, 특히 STEM 관련 및 코딩 벤치마크에서 Qwen3 모델들의 상당한 개선을 반영합니다.
이러한 종합적인 평가 결과는 Qwen3 시리즈가 모든 규모에서 일관되게 이전 버전들과 경쟁 모델들을 능가하는 성능을 보여주며, 특히 추론, 수학, 코딩 영역에서 현저한 개선을 달성했음을 입증합니다.
후훈련
Qwen3 시리즈의 후훈련 파이프라인은 두 가지 핵심 목표를 달성하기 위해 전략적으로 설계되었습니다. 첫 번째는 사고 제어(Thinking Control)로, 이는 "비사고" 모드와 "사고" 모드라는 두 가지 서로 다른 모드를 통합하여 사용자가 모델의 추론 참여 여부를 선택할 수 있는 유연성을 제공하고, 사고 과정에 대한 토큰 예산을 지정하여 사고의 깊이를 제어할 수 있게 합니다. 두 번째는 강한 모델에서 약한 모델로의 증류(Strong-to-Weak Distillation)로, 이는 경량 모델의 후훈련 과정을 간소화하고 최적화하는 것을 목표로 합니다.
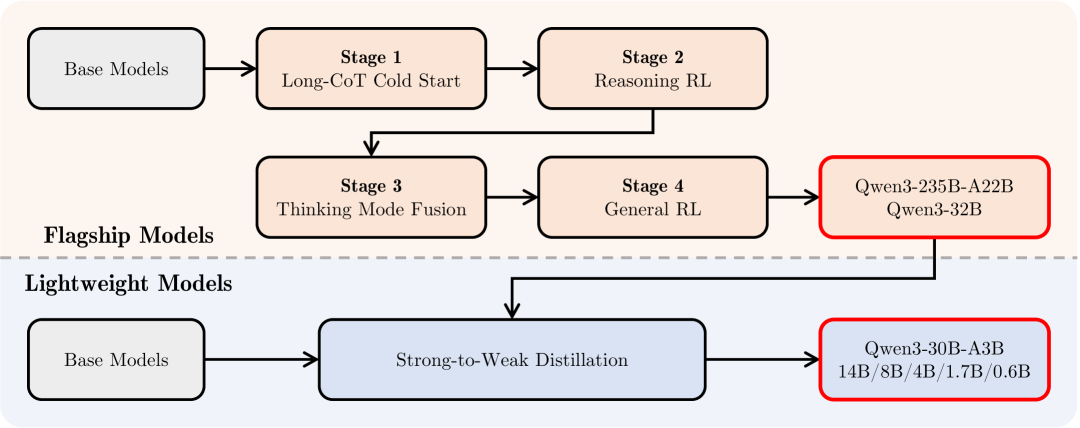
위 그림에서 보듯이, Qwen3 시리즈의 플래그십 모델들은 정교한 4단계 훈련 과정을 따릅니다. 처음 두 단계는 모델의 "사고" 능력 개발에 중점을 두며, 다음 두 단계는 강력한 "비사고" 기능을 모델에 통합하는 것을 목표로 합니다.
대규모 모델의 지식을 활용하여 경량 학생 모델에 교사 모델의 출력 로짓을 직접 증류하는 예비 실험 결과, 이 접근법이 추론 과정에 대한 세밀한 제어를 유지하면서도 성능을 효과적으로 향상시킬 수 있음을 보여줍니다. 이러한 방법은 모든 소규모 모델에 대해 개별적으로 완전한 4단계 훈련 과정을 수행할 필요성을 제거합니다. 이는 더 높은 Pass@1 점수로 나타나는 즉각적인 성능 향상을 가져다주며, Pass@64 결과 개선으로 반영되는 모델의 탐색 능력도 향상시킵니다. 또한 4단계 훈련 방법과 비교하여 단 1/10의 GPU 시간만으로 이러한 성과를 달성하여 훨씬 더 높은 훈련 효율성을 보여줍니다.
Long-CoT 콜드 스타트
첫 번째 단계에서는 수학, 코드, 논리적 추론, 일반 STEM 문제를 포괄하는 광범위한 카테고리에 걸친 포괄적인 데이터셋을 큐레이션합니다. 데이터셋의 각 문제는 검증된 참조 답안이나 코드 기반 테스트 케이스와 쌍을 이룹니다. 이 데이터셋은 긴 체인 오브 소트(long-CoT) 훈련의 "콜드 스타트" 단계의 기초 역할을 합니다.
데이터셋 구축은 엄격한 2단계 필터링 과정을 포함합니다. 쿼리 필터링과 응답 필터링입니다. 쿼리 필터링 단계에서는 Qwen2.5-72B-Instruct를 사용하여 쉽게 검증할 수 없는 쿼리를 식별하고 제거합니다. 여기에는 여러 하위 질문을 포함하거나 일반적인 텍스트 생성을 요구하는 쿼리가 포함됩니다. 또한 Qwen2.5-72B-Instruct가 CoT 추론을 사용하지 않고도 올바르게 답할 수 있는 쿼리는 제외합니다. 이는 모델이 표면적인 추측에 의존하는 것을 방지하고 더 깊은 추론이 필요한 복잡한 문제만 포함되도록 보장합니다.
각 쿼리의 도메인을 Qwen2.5-72B-Instruct를 사용하여 주석을 달아 데이터셋 전반에 걸쳐 균형 잡힌 도메인 표현을 유지합니다. 검증 쿼리 세트를 예약한 후, 나머지 각 쿼리에 대해 QwQ-32B를 사용하여 \(N\)개의 후보 응답을 생성합니다. QwQ-32B가 지속적으로 올바른 솔루션을 생성하지 못할 때는 인간 주석자가 응답의 정확성을 수동으로 평가합니다.
양성 Pass@\(N\)을 가진 쿼리의 경우, 다음과 같은 엄격한 필터링 기준을 적용하여 응답을 제거합니다. (1) 잘못된 최종 답안을 산출하는 응답, (2) 상당한 반복을 포함하는 응답, (3) 적절한 추론 없이 추측을 명확히 나타내는 응답, (4) 사고와 요약 내용 간의 불일치를 보이는 응답, (5) 부적절한 언어 혼합이나 문체 변화를 포함하는 응답, (6) 잠재적 검증 세트 항목과 지나치게 유사한 것으로 의심되는 응답입니다.
이후 정제된 데이터셋의 신중하게 선택된 하위 집합을 추론 패턴의 초기 콜드 스타트 훈련에 사용합니다. 이 단계의 목표는 즉각적인 추론 성능을 지나치게 강조하지 않으면서 모델에 기초적인 추론 패턴을 주입하는 것입니다. 이러한 접근법은 모델의 잠재력이 제한되지 않도록 보장하여 후속 강화학습(RL) 단계에서 더 큰 유연성과 개선을 가능하게 합니다. 이 목표를 효과적으로 달성하기 위해서는 이 준비 단계에서 훈련 샘플 수와 훈련 단계를 모두 최소화하는 것이 바람직합니다.
추론 강화학습
추론 RL 단계에서 사용되는 쿼리-검증자 쌍은 다음 네 가지 기준을 만족해야 합니다. (1) 콜드 스타트 단계에서 사용되지 않았을 것, (2) 콜드 스타트 모델에 대해 학습 가능할 것, (3) 가능한 한 도전적일 것, (4) 광범위한 하위 도메인을 포괄할 것입니다.
최종적으로 총 3,995개의 쿼리-검증자 쌍을 수집하고, GRPO를 사용하여 모델 매개변수를 업데이트했습니다. GRPO는 수학적 추론을 위한 일반화된 강화 정책 최적화 방법으로, 샘플 효율성을 개선하기 위한 오프 정책 훈련과 안정적인 훈련을 위한 제어된 엔트로피 관리를 핵심 기법으로 사용합니다.
큰 배치 크기와 쿼리당 높은 롤아웃 수를 사용하고, 샘플 효율성을 개선하기 위한 오프 정책 훈련을 함께 사용하는 것이 훈련 과정에 유익함을 관찰했습니다. 또한 모델의 엔트로피를 꾸준히 증가시키거나 안정적으로 유지하도록 제어하여 탐색과 활용의 균형을 맞추는 방법을 다루었으며, 이는 안정적인 훈련을 유지하는 데 중요합니다.
결과적으로 하이퍼파라미터에 대한 수동 개입 없이 단일 RL 실행 과정에서 훈련 보상과 검증 성능 모두에서 일관된 개선을 달성했습니다. 예를 들어, Qwen3-235B-A22B 모델의 AIME'24 점수는 총 170 RL 훈련 단계에 걸쳐 70.1점에서 85.1점으로 증가했습니다.
사고 모드 융합
사고 모드 융합 단계의 목표는 이전에 개발된 "사고" 모델에 "비사고" 능력을 통합하는 것입니다. 이러한 접근법을 통해 개발자는 추론 행동을 관리하고 제어할 수 있으며, 사고와 비사고 작업을 위해 별도의 모델을 배포하는 비용과 복잡성을 줄일 수 있습니다.
이를 달성하기 위해 추론 RL 모델에 대해 지속적인 지도 파인튜닝(SFT)을 수행하고 두 모드를 융합하기 위한 채팅 템플릿을 설계합니다. 또한 두 모드를 모두 능숙하게 처리할 수 있는 모델이 서로 다른 사고 예산 하에서 일관되게 우수한 성능을 보인다는 것을 발견했습니다.
SFT 데이터 구축
SFT 데이터셋은 "사고"와 "비사고" 데이터를 모두 결합합니다. 2단계 모델의 성능이 추가적인 SFT로 인해 손상되지 않도록 보장하기 위해, "사고" 데이터는 2단계 모델 자체를 사용하여 1단계 쿼리에 대한 거부 샘플링을 통해 생성됩니다. 반면 "비사고" 데이터는 코딩, 수학, 지시 따르기, 다국어 작업, 창의적 글쓰기, 질문 답변, 역할 놀이를 포함한 다양한 작업을 포괄하도록 신중하게 큐레이션됩니다.
또한 "비사고" 데이터의 응답 품질을 평가하기 위해 자동으로 생성된 체크리스트를 사용합니다. 저자원 언어에서의 성능을 향상시키기 위해 특히 번역 작업의 비율을 증가시킵니다.
채팅 템플릿 설계
두 모드를 더 잘 통합하고 사용자가 모델의 사고 과정을 동적으로 전환할 수 있도록 하기 위해 Qwen3용 채팅 템플릿을 설계했습니다. 구체적으로, 사고 모드와 비사고 모드의 샘플에 대해 각각 사용자 쿼리나 시스템 메시지에 /think와 /no_think 플래그를 도입합니다. 이를 통해 모델이 사용자의 입력을 따라 적절한 사고 모드를 선택할 수 있습니다.
비사고 모드 샘플의 경우, 어시스턴트의 응답에 빈 사고 블록을 유지합니다. 이러한 설계는 모델 내에서 내부 형식 일관성을 보장하고 개발자가 채팅 템플릿에 빈 사고 블록을 연결하여 모델이 사고 행동에 참여하는 것을 방지할 수 있게 합니다.
기본적으로 모델은 사고 모드에서 작동하므로, 사용자 쿼리에 /think 플래그가 포함되지 않은 일부 사고 모드 훈련 샘플을 추가합니다. 더 복잡한 다중 턴 대화의 경우, 사용자의 쿼리에 여러 /think와 /no_think 플래그를 무작위로 삽입하며, 모델 응답은 마지막으로 만난 플래그를 따릅니다.
사고 예산
사고 모드 융합의 추가적인 장점은 모델이 비사고와 사고 모드 모두에서 응답하는 방법을 학습하면, 자연스럽게 중간 경우들을 처리하는 능력, 즉 불완전한 사고를 기반으로 응답을 생성하는 능력을 개발한다는 것입니다. 이러한 능력은 모델의 사고 과정에 대한 예산 제어를 구현하는 기초를 마련합니다.
구체적으로, 모델의 사고 길이가 사용자 정의 임계값에 도달하면, 사고 과정을 수동으로 중단하고 사고 중단 지시를 삽입합니다. "사용자의 제한된 시간을 고려하여, 지금 바로 사고를 바탕으로 솔루션을 제공해야 합니다. </think>". 이 지시가 삽입된 후, 모델은 그 시점까지 축적된 추론을 바탕으로 최종 응답을 생성합니다.
주목할 점은 이러한 능력이 명시적으로 훈련되지 않았지만 사고 모드 융합을 적용한 결과로 자연스럽게 나타난다는 것입니다. 이 기능은 Hugging Face의 토크나이저에서 지원하는 채팅 템플릿에 구현되어 있으며, enable_thinking=False 추가 매개변수를 사용하여 사고 모드를 비활성화할 수 있습니다.
| 모드 | 사용자 입력 | 어시스턴트 응답 |
|---|---|---|
| 사고 모드 | 사용자: 2+3은 얼마인가요? | <think>이것은 간단한 덧셈 문제입니다. 2에 3을 더하면 5가 됩니다.</think>2+3은 5입니다. |
| 비사고 모드 | 사용자: /no_think 2+3은 얼마인가요? | <think></think>2+3은 5입니다. |
위 표는 사고 모드 융합 단계에서 사고 모드와 비사고 모드에 대한 SFT 데이터의 예시를 보여줍니다. 사고 모드의 경우 기본 동작을 나타내므로 /think 플래그를 생략할 수 있습니다.
References
Subscribe via RSS