Tulu 3: Pushing Frontiers in Open Language Model Post-Training
by Allen Institute for AI
Contents
TL;DR
이 연구를 시작하게 된 배경과 동기는 무엇입니까?
대규모 언어 모델의 발전은 인공지능 분야에서 혁명적인 변화를 가져왔지만, 사후 훈련 방법론에서 오픈소스와 폐쇄형 접근법 사이에는 여전히 큰 격차가 존재했습니다. 기존의 폐쇄형 모델들은 훈련 데이터와 방법론을 투명하게 공개하지 않아 연구자들의 접근을 제한했고, 오픈소스 모델들은 성능과 정교함에서 뒤처져 있었습니다. 특히 지시 따르기, 수학적 추론, 코딩과 같은 핵심 기술 영역에서 오픈소스 모델들의 성능은 상업용 모델에 비해 현저히 낮았습니다.
이러한 배경에서 연구진은 완전히 투명하고 높은 성능을 가진 오픈소스 언어 모델 패밀리를 개발하고자 했습니다. 그들의 목표는 단순히 모델을 공개하는 것을 넘어, 훈련 데이터, 평가 도구, 훈련 코드, 그리고 개발 레시피 전체를 공개함으로써 언어 모델 연구의 민주화를 촉진하는 것이었습니다. 이는 제한된 자원을 가진 연구자들도 최첨단 언어 모델 연구에 참여할 수 있는 기회를 제공하는 중요한 접근이었습니다.
이 연구에서 제시하는 새로운 해결 방법은 무엇입니까?
Tülu 3의 핵심 혁신은 크게 세 가지로 요약됩니다. 첫째, Tülu 3 Data는 페르소나 기반 접근법을 활용하여 고품질의 다양한 합성 데이터를 대규모로 생성했습니다. 25만 개의 서로 다른 페르소나를 활용해 수학, 코딩, 지시 따르기 등 다양한 기술 영역의 데이터를 생성함으로써 모드 붕괴 문제를 해결하고 데이터의 다양성을 확보했습니다.
둘째, Tülu 3 Eval은 혁신적인 평가 프레임워크를 제시했습니다. 개발용과 미공개 평가를 분리하여 모델의 실제 일반화 능력을 엄격하게 평가할 수 있는 체계를 구축했습니다. 특히 8-gram 매칭을 통한 체계적인 데이터 오염 제거 방법론은 평가의 신뢰성을 크게 향상시켰습니다. 또한 IFEval-OOD와 같은 새로운 평가 벤치마크를 개발하여 모델의 지시 따르기 능력을 더욱 정교하게 측정할 수 있게 했습니다.
셋째, 검증 가능한 보상을 통한 강화학습(RLVR)은 언어 모델 훈련의 새로운 패러다임을 제시했습니다. 기존의 보상 모델 대신 실제 답변의 정확성을 직접 검증하는 이진 보상 메커니즘을 도입했습니다. 이 방법은 수학적 문제 해결과 정확한 지시 따르기와 같은 검증 가능한 작업에서 특히 효과적으로, 모델의 추론 능력을 획기적으로 개선할 수 있음을 보여주었습니다.
제안된 방법은 어떻게 구현되었습니까?
Tülu 3의 구현은 매우 체계적이고 엄격한 접근법을 따랐습니다. 데이터 생성 과정에서는 페르소나 기반 방법론을 사용해 GPT-4o와 같은 대규모 언어 모델을 활용하여 다양한 기술 영역의 데이터를 합성했습니다. 이 과정에서 각 페르소나의 고유한 관점을 활용해 데이터의 다양성과 품질을 동시에 확보했습니다.
선호도 조정 단계에서는 길이 정규화된 Direct Preference Optimization(DPO) 방법을 채택했습니다. 온폴리시 데이터와 오프폴리시 데이터를 결합하고, GPT-4o를 판단자로 활용하여 선호도 데이터를 생성했습니다. 특히 실제 모델에서 생성된 응답을 포함하는 온폴리시 데이터의 중요성을 강조하며, 이를 통해 모델의 성능을 크게 향상시켰습니다.
RLVR 단계에서는 PPO 알고리즘을 활용하여 검증 가능한 보상 메커니즘을 구현했습니다. GSM8K, MATH, IFEval과 같은 벤치마크에서 모델의 출력을 직접 검증하고, 정확한 답변에 대해서만 보상을 제공하는 방식으로 모델을 훈련했습니다. 비동기 강화학습 인프라와 분산 훈련 최적화 기법을 통해 405B 규모의 대형 모델까지 성공적으로 훈련할 수 있었습니다.
이 연구의 결과가 가지는 의미는 무엇입니까?
Tülu 3의 연구 결과는 언어 모델 분야에 여러 중요한 의미를 가집니다. 성능 측면에서 Tülu 3 모델은 8B와 70B 규모 모두에서 기존 오픈소스 모델들을 능가했으며, 일부 평가에서는 GPT-4o-mini와 같은 폐쇄형 모델의 성능에 근접했습니다. 특히 수학적 추론(GSM8K에서 87.6%), 코딩(HumanEval에서 83.9%), 지시 따르기(IFEval에서 82.4%) 등 핵심 기술 영역에서 뛰어난 성능을 보였습니다.
방법론적 측면에서 Tülu 3는 오픈소스 언어 모델 연구의 새로운 표준을 제시했습니다. 완전한 투명성을 바탕으로 훈련 데이터, 평가 도구, 훈련 코드를 공개함으로써 연구의 재현성을 크게 향상시켰습니다. RLVR과 같은 혁신적인 훈련 방법론은 언어 모델의 추론 능력을 개선하는 새로운 접근법을 제시했으며, 향후 연구의 중요한 영감이 될 것으로 기대됩니다.
더 나아가 이 연구는 언어 모델 연구의 민주화에 기여했습니다. 대규모 자원 없이도 최첨단 모델의 훈련 과정을 이해하고 재현할 수 있는 기반을 마련했으며, 연구자들이 더욱 쉽게 혁신에 참여할 수 있는 길을 열었습니다. 특히 405B 규모까지의 성공적인 확장은 제안된 방법론의 확장성을 입증했다는 점에서 중요한 의미를 가집니다.
Tülu 3: 오픈 언어 모델 사후 훈련의 새로운 지평
초록
Tülu 3는 완전히 오픈소스로 공개된 최첨단 사후 훈련 언어 모델 패밀리입니다. 이 연구는 기존의 독점적인 사후 훈련 기법들과 오픈소스 방법론 사이의 격차를 해소하기 위해 개발되었습니다. Tülu 3는 Llama 3.1 기반 모델을 바탕으로 구축되어 Llama 3.1 Instruct, Qwen 2.5, Mistral과 같은 기존 모델들을 능가하며, 심지어 GPT-4o-mini와 Claude 3.5-Haiku 같은 폐쇄형 모델들도 뛰어넘는 성능을 보여줍니다.
이 프로젝트의 핵심 혁신은 세 가지 주요 구성 요소로 이루어져 있습니다. 첫째, Tülu 3 Data는 핵심 기술들을 대상으로 하는 새로운 허용 라이선스 훈련 데이터셋들을 제공합니다. 둘째, Tülu 3 Eval은 개발 단계와 최종 평가를 위한 표준화된 평가 프레임워크를 구축합니다. 셋째, Tülu 3 Recipe는 지도 학습 미세조정(SFT), Direct Preference Optimization(DPO), 그리고 새롭게 제안된 Reinforcement Learning with Verifiable Rewards(RLVR)를 포함하는 다단계 훈련 파이프라인을 제시합니다.
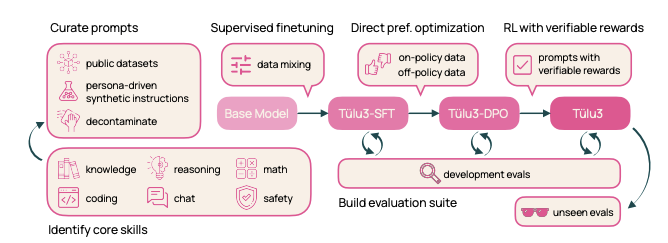
RLVR은 이 연구의 가장 주목할 만한 기술적 기여 중 하나로, 수학이나 정확한 지시 따르기와 같이 검증 가능한 답이 있는 기술들을 향상시키기 위해 특별히 설계된 강화학습 목표 함수를 사용합니다. 이 방법은 모델의 완성이 올바른지 검증되었을 때만 보상을 제공하는 혁신적인 접근법입니다.
연구진은 또한 평가 벤치마크에 대한 광범위한 오염 제거 작업을 수행하여 편향되지 않은 성능 측정을 보장했습니다. 이러한 체계적인 접근법을 통해 Tülu 3는 추론, 수학, 코딩, 안전성 등 다양한 핵심 기술 영역에서 균형 잡힌 성능 향상을 달성했습니다.
서론
현대 언어 모델 개발에서 사후 훈련은 모델의 행동을 개선하고 새로운 기능을 활성화하는 핵심적인 단계가 되었습니다. 그러나 이러한 기법들의 발전은 종종 오픈소스 자원과 레시피의 부족으로 인해 제약을 받고 있습니다. 특히 사후 훈련의 기반이 되는 훈련 데이터와 레시피는 동시에 가장 중요한 퍼즐 조각이면서도 가장 투명성이 부족한 부분입니다.
이러한 문제를 해결하기 위해 연구진은 Tülu 3를 소개합니다. Tülu라는 이름은 박트리아 낙타와 단봉낙타 사이의 하이브리드 낙타에서 따온 것으로, 서로 다른 접근법들을 융합하여 더 강력한 결과를 만들어내는 이 프로젝트의 철학을 잘 보여줍니다.
핵심 기여사항
Tülu 3의 발전은 세 가지 주요 구성 요소의 통합을 통해 이루어졌습니다.
Tülu 3 Data는 핵심 기술들을 대상으로 하는 새로운 허용 라이선스 훈련 데이터셋들을 제공합니다. 이 데이터는 공개적으로 사용 가능한 오픈 데이터를 활용하고, 다양한 훈련 단계에서 기술별 합성 데이터를 생성하며, 평가 스위트에 대한 적극적인 오염 제거를 수행합니다.
Tülu 3 Eval은 명확한 성능 목표를 설정하고 훈련 단계를 통한 모델 개선을 안내하기 위한 평가 프레임워크를 구축합니다. 이는 개발용과 미공개 작업들의 선택을 포함하여 포괄적인 평가 도구를 제공합니다.
Tülu 3 Recipe는 강화학습의 알고리즘적 발전, 최첨단 인프라, 그리고 다양한 훈련 단계에서 데이터 믹스, 방법론, 매개변수를 최적화하기 위한 엄격한 실험을 통합하는 고급 다단계 훈련 파이프라인입니다.
방법론적 접근
Tülu 3를 구축하기 위해 연구진은 먼저 훈련 후 개선할 핵심 기술들의 집합을 식별했습니다. 이에는 추론, 수학, 코딩, 안전성, 정확한 지시 따르기, 지식 회상 등이 포함됩니다. 이러한 기술들을 평가하고 개발 및 미공개 작업들의 선택을 통해 모델 개선을 안내하는 평가 프레임워크를 구축했습니다.
훈련 방법론은 여러 단계로 구성되며, 각 단계는 이전 모델을 기반으로 구축되고 서로 다른 유형의 데이터에 초점을 맞춥니다. 지도 학습 미세조정을 위한 프롬프트-완성 인스턴스, 선호도 조정을 위한 선호도 데이터, 강화학습을 위한 검증 가능한 보상 등이 그 예입니다.
엄격하고 원칙적인 실험을 통해 연구진은 지도 학습 미세조정을 위한 최적의 데이터 믹스를 결정하여 Tülu 3 SFT 체크포인트를 생성했습니다. 선호도 조정의 최근 발전을 활용하여, Tülu 3 SFT 완성과 다른 언어 모델들의 출력을 비교하는 신중하게 큐레이션된 온폴리시 선호도 데이터를 통해 모델을 훈련했습니다.
혁신적인 RLVR 방법론
이 연구의 가장 주목할 만한 기술적 혁신 중 하나는 새로운 최종 미세조정 단계인 Reinforcement Learning with Verifiable Rewards(RLVR)입니다. 이 방법은 수학과 정확한 지시 따르기와 같이 검증 가능한 답이 있는 기술들을 향상시키기 위해 맞춤화된 새로운 강화학습 목표를 사용합니다.
기존의 강화학습 방법들이 인간의 피드백이나 보상 모델에 의존하는 것과 달리, RLVR은 모델의 출력이 실제로 올바른지 자동으로 검증할 수 있는 작업들에 특화되어 있습니다. 예를 들어, 수학 문제의 경우 답이 정확한지 계산을 통해 확인할 수 있고, 지시 따르기의 경우 특정 제약 조건들이 충족되었는지 프로그래밍적으로 검증할 수 있습니다.
성능 결과
최종적으로 개발된 Tülu 3 모델들은 인상적인 성능을 보여줍니다. 동일한 크기의 최첨단 사후 훈련된 오픈 가중치 모델들을 모두 능가하며, 70B 크기에서는 Claude 3.5 Haiku와 GPT-4o mini와 같은 폐쇄형 제공업체들의 제품과 경쟁할 수 있는 수준에 도달했습니다. 더 나아가 405B 크기에서는 DeepSeek v3와 GPT 4o(11-24)와 경쟁적인 성능을 보여줍니다.
| 기술 영역 | 벤치마크 | Tülu 3 8B | Llama 3.1 8B Instruct | Tülu 3 70B | Llama 3.1 70B Instruct | GPT-4o Mini |
|---|---|---|---|---|---|---|
| 지식 | MMLU | 68.2 | 71.2 | 83.1 | 85.3 | 82.2 |
| 추론 | BigBenchHard | 69.0 | 71.9 | 85.0 | 83.0 | 65.9 |
| 수학 | MATH | 43.7 | 42.5 | 63.0 | 56.4 | 67.9 |
| 코딩 | HumanEval | 83.9 | 86.3 | 92.4 | 93.6 | 90.4 |
| 지시 따르기 | IFEval | 82.4 | 80.6 | 83.2 | 88.0 | 83.5 |
| 안전성 | Safety | 85.5 | 75.2 | 88.3 | 76.5 | 84.9 |
완전한 오픈소스 생태계
Tülu 3는 단순히 모델만을 제공하는 것이 아니라 완전한 오픈소스 생태계를 구축합니다. 이에는 다음이 포함됩니다.
- 광범위한 지침과 도구: 평가, 오염 제거, 레시피 설계를 위한 포괄적인 도구
- 확장된 새로운 합성 지시 데이터셋: 대규모로 생성된 고품질 훈련 데이터
- 온폴리시 생성을 통한 선호도 데이터 확장: 실제 모델 출력을 기반으로 한 선호도 학습
- 검증 가능한 보상을 통한 강화학습: 새로운 RLVR 방법론
- 고급 인프라: 대규모 모델의 성공적인 구현을 위한 세부사항과 코드
이러한 완전히 오픈된 파이프라인을 통해 다른 연구자들은 오픈 기반 모델을 가져와서 관심 있는 모든 작업에 대해 고성능으로 미세조정할 수 있습니다. 이는 복잡하고 다목적, 다단계 훈련 체제 내에서 사후 훈련 연구의 기초를 마련합니다.
Tülu 3의 공개는 모델 가중치, 데모, 그리고 완전한 레시피를 포함합니다. 여기에는 다양한 핵심 기술을 위한 데이터셋, 데이터 큐레이션과 평가를 위한 강력한 툴킷, 훈련 코드와 인프라, 그리고 가장 중요하게는 Tülu 3 접근법을 더 많은 도메인으로 재현하고 추가 적응시키기 위한 상세한 보고서가 포함되어 있습니다.
Tülu 3 개요
언어 모델의 사후 훈련 분야는 InstructGPT와 같은 초기 모델들이 개척한 표준적인 레시피를 따라 발전해왔습니다. 이러한 접근법은 지시 조정(instruction-tuning) 후 선호도 미세조정(preference finetuning)을 수행하는 방식으로 구성되었습니다. 그러나 시간이 지나면서 사후 훈련 접근법의 정교함과 복잡성은 지속적으로 증가하여, 다중 라운드 훈련, 인간 데이터와 합성 데이터의 결합, 그리고 다양한 훈련 알고리즘과 목표 함수를 활용하는 방향으로 발전했습니다.
하지만 대부분의 성공적인 사후 훈련 모델들은 훈련 데이터, 코드, 또는 레시피에 대한 제한적인 정보만을 제공합니다. 실제로 LMSYS의 ChatBotArena에서 상위 50위 안에 든 모델 중 어떤 것도 사후 훈련 데이터를 공개하지 않았습니다. Tülu 2나 Zephyr-β와 같은 오픈 사후 훈련 연구들은 일부 벤치마크와 AlpacaEval이나 Arena-Hard 같은 채팅 평가에서 강력한 결과를 보여주지만, MATH, IFEval, GSM8K와 같은 핵심 능력에서는 여전히 뒤처지고 있습니다.
Tülu 3는 사후 훈련 연구의 경계를 확장하고 오픈소스와 폐쇄형 미세조정 레시피 간의 격차를 해소하는 것을 목표로 합니다. 이 프로젝트는 독점적인 방법론의 부분적인 세부사항을 새로운 기법들과 통합하고 이를 확립된 학술 연구와 결합하는 복잡한 훈련 과정입니다. Tülu 3의 성공 요인은 신중한 데이터 큐레이션, 엄격한 실험과 평가, 혁신적인 방법론, 그리고 개선된 훈련 인프라입니다.
연구진은 공개적으로 사용 가능한 데이터셋의 신중한 오염 제거를 수행하고 평가를 위한 개발 및 테스트 세트를 생성하여 이 과정을 과학적으로 평가하는 체계적인 가이드라인을 따랐습니다. Tülu 3는 단순한 결과물이 아니라 오픈 사후 훈련의 최전선을 발전시키기 위해 설계된 포괄적인 데이터와 도구 모음입니다.
Tülu 3 데이터
Tülu 3 노력은 오픈 사후 훈련 레시피가 종종 뒤처지는 핵심 영역들을 식별하고 범용 언어 모델에 바람직한 능력들을 파악하는 것으로 시작되었습니다. 연구진은 지식 회상, 추론, 수학, 코딩, 지시 따르기, 일반 채팅, 안전성과 같은 핵심 기술들을 향상시키는 것에 초점을 맞췄습니다.
이러한 핵심 기술들을 대상으로 하기 위해 공개 데이터에서 소싱하고 합성적으로 데이터를 큐레이션하여 Tülu 3 데이터를 수집했습니다. 훈련의 다양한 단계에서 서로 다른 데이터 형식을 사용하며, 수집된 데이터셋들의 전체 컬렉션은 상세한 표에 정리되어 있습니다.
Tülu 3 평가
사후 훈련 접근법의 성공에서 핵심 요소는 명확한 성능 목표와 개선을 안내하는 평가 도구를 설정하는 것입니다. Tülu 3 Eval을 통해 연구진은 통합되고 표준화된 평가 스위트와 최종 모델의 개발과 평가를 안내하는 툴킷을 공개하면서 훈련 데이터를 평가 벤치마크에 대해 오염 제거했습니다.
이 프레임워크는 재현 가능한 평가를 위한 오픈 평가 툴킷, 별도의 개발 및 보류 평가가 포함된 지시 조정 모델의 핵심 기술 평가 스위트, 그리고 다양한 모델에 대한 실험을 바탕으로 한 평가 스위트에서의 권장 설정으로 구성됩니다. 두 분할 모두 식별된 모든 기술을 다루지만, 보이지 않는 안전성 평가는 포함하지 않습니다.
중요한 점은 모델 개발 시 보이지 않는 세트의 점수를 검토하지 않았다는 것입니다. 이를 통해 데이터 믹스, 알고리즘, 하이퍼파라미터에 대한 결정에서 특정 평가에 얼마나 과적합되었는지 관찰할 수 있었습니다.
Tülu 3 레시피
이 섹션에서는 최첨단 사후 훈련 모델을 얻기 위한 Tülu 3 레시피의 개요를 제공합니다. 연구진은 사전 훈련된 언어 모델 위에 4단계 사후 훈련 레시피를 통해 Tülu 3 모델을 생산합니다.
Tülu 3 레시피는 강화학습의 알고리즘적 발전, 최첨단 인프라, 그리고 다양한 훈련 단계에서 데이터 믹스, 방법론, 매개변수를 최적화하기 위한 엄격한 실험을 통합하는 고급 다단계 훈련 파이프라인입니다. 모든 단계에서 신중하게 선택된 평가 스위트를 사용하여 모델 성능을 측정합니다.
1단계: 데이터 큐레이션 다양한 최적화 단계에 할당될 다양한 프롬프트를 큐레이션합니다. 새로운 합성 프롬프트를 생성하거나 사용 가능한 경우 기존 데이터셋에서 프롬프트를 소싱하여 특정 능력을 대상으로 합니다. 프롬프트가 평가 스위트인 Tülu 3 Eval과 오염되지 않도록 보장합니다.
2단계: 지도 학습 미세조정(SFT) 신중하게 선택된 프롬프트와 완성에 대해 지도 학습 미세조정을 수행합니다. 철저한 실험을 통해 최종 SFT 데이터와 훈련 하이퍼파라미터를 결정하여 다른 능력의 성능에 크게 영향을 주지 않으면서 대상 핵심 기술을 향상시킵니다.
3단계: 선호도 조정 선택된 프롬프트에서 새롭게 큐레이션된 온폴리시 합성 생성 선호도 데이터와 오프폴리시 데이터를 함께 사용하여 선호도 조정, 특히 DPO를 적용합니다. SFT 단계와 마찬가지로 철저한 실험을 통해 최적의 선호도 데이터 믹스를 식별합니다.
4단계: 검증 가능한 보상을 통한 강화학습(RLVR) 전통적인 RLHF 훈련에서 일반적인 보상 모델 대신 검증 가능한 보상에 대해 모델을 훈련하는 새로운 RL 기반 사후 훈련 단계를 도입합니다. 수학적 문제 해결과 같이 검증 가능한 결과가 있는 작업을 선택하고, 모델의 생성이 올바른 것으로 검증될 때만 보상을 제공합니다.
Tülu 3 파이프라인의 핵심 기여는 개선된 데이터, 방법론, 인프라, 그리고 엄격한 평가에 있습니다. 파이프라인의 주요 요소들은 다음과 같습니다.
데이터 품질, 출처, 규모: 사용 가능한 오픈소스 데이터셋을 신중하게 조사하고 출처를 분석하며 오염을 제거하고, 핵심 기술을 대상으로 하는 합성 프롬프트를 큐레이션합니다. 효과를 보장하기 위해 개발 평가 스위트에 대한 영향을 연구하는 철저한 실험을 수행합니다.
다중 기술 SFT 데이터셋 생성: "일반" 및 "기술별" 카테고리의 프롬프트 분포는 다양한 데이터 믹스에 대한 여러 라운드의 지도 학습 미세조정을 통해 개선되었습니다. 예를 들어, 수학적 추론을 개선하기 위해 먼저 평가 스위트에서 수학 전문 모델을 생성하여 상한선을 설정한 다음, 데이터를 믹스하여 일반 모델을 이 상한선에 가깝게 만듭니다.
온폴리시 선호도 데이터셋 큐레이션: 선호도 데이터셋 생성을 확장하기 위한 온폴리시 데이터 큐레이션 파이프라인을 개발했습니다. 구체적으로, 주어진 프롬프트에 대해 Tülu 3-SFT와 다른 모델들로부터 완성을 생성하고, 쌍별 비교를 통해 선호도 라벨을 얻습니다.
선호도 조정 알고리즘 설계: 여러 선호도 조정 알고리즘을 실험하고 길이 정규화된 Direct Preference Optimization을 사용할 때 성능 향상을 관찰했습니다. PPO와 같은 더 비용이 많이 드는 RL 기반 방법에 대한 조사 대신 개발 과정과 최종 모델 훈련에서 단순성과 효율성을 우선시했습니다.
기술별 검증 가능한 보상을 통한 RL: 수학과 같이 실제 결과에 대해 평가할 수 있는 기술을 대상으로 하는 새로운 강화학습 목표를 활용하는 새로운 접근법을 적용했습니다. 완성이 성공적일 때 일정한 보상 값을 얻는 RLVR 알고리즘은 GSM8K, MATH, IFEval 성능을 개선할 수 있음을 보여줍니다.
강화학습을 위한 훈련 인프라: 학습자들이 동시에 그래디언트 업데이트를 수행하는 동안 vLLM을 통해 LLM 추론을 효율적으로 실행하는 비동기 RL 설정을 구현했습니다. RL 코드베이스는 또한 높은 확장성을 가지며 70B와 405B RLVR 정책 모델을 훈련할 수 있습니다.
평가 및 결과
이 작업 전반에 걸쳐 점수를 보고할 때는 식별된 메트릭을 사용하며, 높을수록 좋습니다. 전체 성능을 계산할 때는 모든 평가에서 점수를 단순히 평균하여 각 평가를 동등하게 취급합니다. 생성 평가의 경우 출력 길이는 4096입니다.
Llama 3 기본 모델에서 훈련된 Tülu 3는 개발 평가 스위트에서 해당 크기 카테고리의 다른 모든 오픈 가중치 모델을 능가합니다. 폐쇄형 모델과 비교할 때, Tülu 3 70B는 GPT-3.5-Turbo-0125나 GPT-4o-mini-2024-07-18과 같은 폐쇄형 모델을 능가하면서 Claude 3.5 Haiku 20241022의 성능에 접근합니다.
8B와 70B 파라미터에서 Llama 3에서 훈련된 Tülu 3와 해당 크기 클래스의 선도적인 모델들과의 비교 요약이 제시됩니다. 훈련 단계별 성능 분석은 8B 버전과 70B 버전에 대해 각각 표로 정리되어 있습니다.
원시 사전 훈련된 기본 모델에서 훈련된 모델들과 비교하여, 동일한 기본 모델에서 훈련된 지시 모델들(예: Nous Hermes 3), 유사한 크기이지만 다른 기본 버전의 지시 모델들(예: Ministral 8B 또는 Qwen 2.5 Instruct), 그리고 지시 버전에서 훈련된 다른 미세조정 레시피들(예: Nemotron Llama 3.1)과 비교합니다.
70B에서는 Llama 3.1 70B Instruct, Qwen 2.5 72B Instruct, Nous Hermes 3 70B(Llama 3.1 70B에서 훈련), Nemotron Llama 3.1 70B(Llama 3.1 70B Instruct에서 훈련)와 비교하여 이들을 능가합니다. 8B에서는 Llama 3.1 8B Instruct, Gemma 2 9B Instruct, Nous Hermes 3 8B(Llama 3.1 8B에서 훈련), Qwen 2 7B Instruct, Ministral 8B Instruct 2410과 비교하여 이들을 능가합니다.
공개된 결과물: Tülu 3 훈련 레시피와 관련된 모든 결과물을 공개합니다. 여기에는 SFT, DPO, RL 모델 체크포인트와 새로운 SFT 및 DPO 데이터셋이 포함됩니다.
Tülu 3 데이터
프롬프트는 사용자가 모델과 상호작용하는 다양한 방식을 나타내며, 모든 사후 훈련 단계의 필수 구성 요소 역할을 합니다. 연구진은 Tülu 3 사후 훈련 레시피의 출발점으로 수백만 개의 프롬프트로 구성된 광범위한 컬렉션을 큐레이션했습니다. 다음 단계의 훈련을 위한 데이터는 이러한 프롬프트에서 선택됩니다.
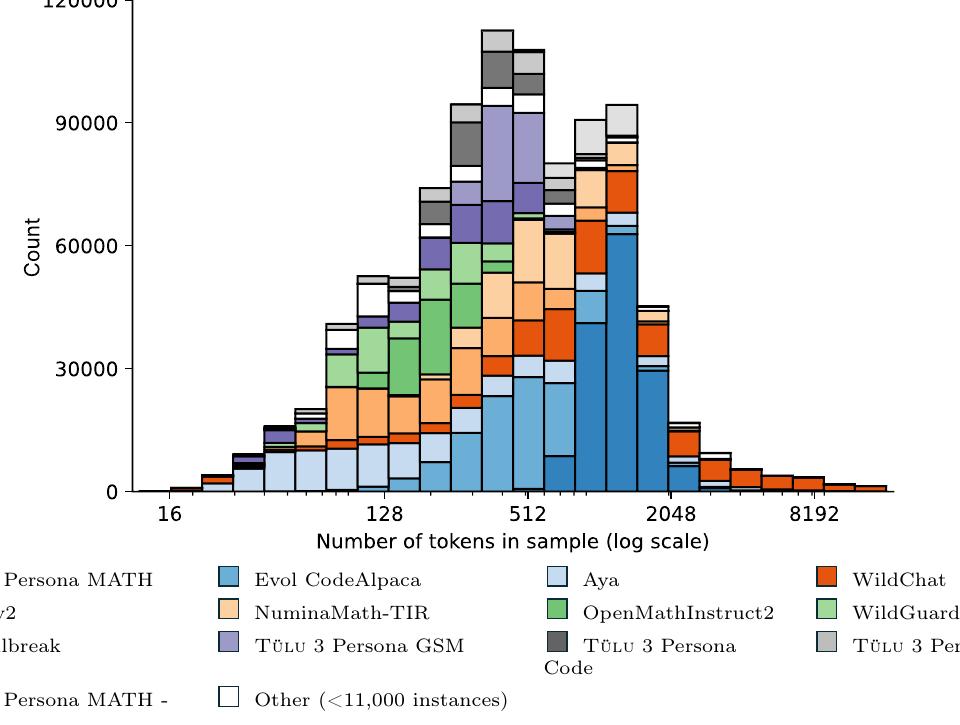
위 그림은 Tülu 3 최종 SFT 믹스를 소스별로 나타내며, 프롬프트와 완성의 토큰 길이 분포를 보여줍니다. 가장 많은 인스턴스를 가진 데이터셋이 히스토그램 하단에 위치하며, 다양한 데이터셋들이 서로 다른 토큰 길이 분포를 가지고 있음을 확인할 수 있습니다.
이 섹션에서는 프롬프트 큐레이션 과정과 평가에서 누출이 발생하지 않도록 보장하는 오염 제거 노력을 설명합니다. 다음 섹션에서는 지도 학습 미세조정과 선호도 조정에서 프롬프트가 어떻게 사용되는지 설명합니다.
프롬프트 큐레이션
목표로 하는 핵심 기술을 대상으로 하기 위해, 연구진은 명확한 출처를 가진 공개적으로 사용 가능한 데이터셋에서 다양하고 고품질의 프롬프트 세트를 큐레이션하고, 부족한 부분을 채우기 위해 합성적으로 프롬프트를 생성했습니다.
공개 데이터셋에서의 소싱
Tülu 2 출시 이후, 커뮤니티는 지도 학습 미세조정과 선호도 조정 모두 측면에서 사후 훈련을 위한 데이터셋을 생성하는 대규모 연구를 목격했습니다. Tülu 3는 이러한 자원들을 통합하고 확장하여 더 강력한 모델을 구축하는 것을 목표로 합니다.
연구진은 전용 작업자가 주석을 단 데이터셋, 실제 사용자로부터 소싱된 데이터셋, 모델로 합성된 데이터셋을 포함하여 공개 데이터셋에 대한 광범위한 조사로 이 과정을 시작했습니다. 그 후 각 개별 데이터셋을 수동으로 검토하고 다음 고려사항에 따라 선택했습니다.
다양성: 훈련 데이터의 다양성은 모델의 일반화를 이끌어내고, 모델 망각을 방지하며, 일반적이지 않은 입력에 대해 모델을 견고하게 만드는 데 중요합니다. 연구진은 다양성을 촉진할 수 있는 데이터셋을 선택했습니다. 여기에는 모델과의 대규모 실제 사용자 상호작용 소스인 WildChat과 일반적인 채팅을 위해 자원봉사 작업자가 생성한 OpenAssistant, 광범위한 개방형 카테고리에 대해 전문 작업자가 주석을 단 No Robots, 그리고 고전적인 NLP 작업의 대규모 컴파일인 FLAN v2가 포함됩니다.
또한 여러 데이터셋의 구성인 UltraFeedback의 오염 제거된 부분집합도 포함했습니다. UltraFeedback은 초기 연구에서 일반적인 선호도 조정에 대해 강력한 성능을 보여주었습니다.
목표 기술: 연구진은 일반적인 사용 사례와 특정 요구사항을 지원할 수 있는 여러 능력을 향상시키는 것을 특별히 고려했습니다. 이전 연구에서 보여준 바와 같이, 복잡한 추론, 코딩, 정확한 지시 따르기와 같은 일부 능력은 추가 데이터를 혼합함으로써 이익을 얻습니다.
따라서 다음 데이터셋들을 포함했습니다. 수학적 추론을 위한 OpenMathInstruct와 NuminaMath, 코딩을 위한 Evol-CodeAlpaca, 정확한 지시 따르기를 위한 Daring-Anteater의 부분집합, 다국어 지원을 위한 Aya, 과학 문헌 이해를 위한 SciRIFF, 그리고 테이블 관련 작업 처리를 위한 TableGPT입니다.
데이터 출처와 라이선스: 프롬프트를 소싱할 때, 연구진은 원본 데이터셋의 라이선스를 신중히 고려하고 명확하고 올바른 라이선스를 가진 것들만 허용했습니다. 많은 공개 출시 데이터셋이 다른 데이터셋의 구성이므로, 부분집합의 출처를 수동으로 추적하여 라이선스를 확인하고 문제가 있는 것들을 제거해야 했습니다.
특히, ShareGPT 데이터셋은 모델 훈련이나 출시에 대한 동의 없이 사용자들이 인터넷에서 공유한 것으로 법적 출처가 의심스러우므로 제외하고 대신 WildChat을 사용했습니다. 또한 UltraFeedback에서 관련 부분집합을 제거했고, 프롬프트에서 ShareGPT를 사용하기 때문에 Helpsteer2를 사용하지 않기로 결정했습니다.
목표 기술을 위한 합성
다양하고 기술별 데이터셋에 대한 증가하는 요구를 해결하기 위해, 연구진은 합성 데이터 생성을 보완적 접근법으로 통합했습니다. 합성 데이터 생성은 더 저렴하게 얻을 수 있고, 다양한 목적에 맞게 맞춤화할 수 있으며, 기본 모델의 방대한 지식을 반영하기 때문에 인간이 작성한 데이터의 유망한 대안으로 주목받고 있습니다.
그러나 대규모로 다양하고 고품질의 데이터를 생성하는 것은 간단하지 않습니다. 언어 모델은 "모드 붕괴"라고 불리는 반복적인 모드나 패턴에 빠지기 쉽기 때문입니다. 생성에서 다양성을 보장하기 위해, 연구진은 Chan et al. (2024)의 최근 페르소나 기반 방법론을 따라 합성 데이터를 생성했습니다.
핵심 아이디어는 서로 다른 페르소나(예: "신경망에 초점을 맞춘 기계학습 연구자")를 데이터 합성 프롬프트(예: "코딩 문제 생성")와 함께 사용하여 LLM이 해당 관점으로 데이터를 합성하도록 유도하는 것입니다. 구체적으로, Persona Hub의 약 25만 개 페르소나를 조건으로 하여 정확한 지시 따르기, 수학, 코딩과 같은 특정 기술을 대상으로 하는 프롬프트를 생성했습니다.
정확한 지시 따르기: 정확한 지시 따르기는 "답변에 정확히 3개의 문단이 포함되어야 합니다"와 같이 자연어로 된 검증 가능한 지시를 따르는 능력으로, 휴리스틱으로 자동 검증할 수 있습니다. 연구진은 페르소나 기반 접근법을 사용하여 IFEval 벤치마크에서 정의된 25가지 다른 제약 유형을 다루는 검증 가능한 지시를 합성적으로 생성했습니다.
구체적으로, 제약당 1-2개의 예시 지시를 수동으로 작성하여 총 33개의 검증 가능한 지시를 시드 프롬프트로 사용했습니다. 그 후 데이터 합성 프롬프트, 페르소나, 그리고 단일 검증 가능한 지시를 예시로 제공하여 GPT-4o를 사용해 새로운 지시를 생성했습니다. 총 29,980개의 검증 가능한 지시-응답 쌍을 수집했으며, 이를 If-Persona-Sft라고 명명했습니다.
마지막으로, Tülu 2 SFT 믹스에서 지시를 무작위로 샘플링하고 Zhou et al. (2023)의 분류법에서 제약을 결합하여 제한된 지시 따르기를 위한 또 다른 유형의 프롬프트를 생성했습니다. 이 세트를 IF-augmented라고 명명했으며, 이러한 프롬프트는 DPO와 RLVR 단계에서만 사용됩니다.
수학과 코딩: 연구진은 유사한 페르소나 기반 접근법을 따라 다양한 수학 문제와 코딩 문제를 합성적으로 생성했습니다. 수학 문제에는 고급 수학 기술이 필요한 문제와 초등학교 수준의 문제가 모두 포함됩니다. 코딩의 경우, 초급에서 중급 수준의 프로그래머가 해결할 수 있는 Python 프로그래밍 질문을 생성했습니다.
정확한 지시 따르기와 달리, 주어진 페르소나 입력에 고유하고 특정한 문제를 생성하기 위해 GPT-4o를 제로샷으로 프롬프트했습니다. 문제를 생성한 후, GPT-4o를 사용해 다단계 수학 해답을 생성하고, claude-3-5-sonnet을 사용해 Python 프로그램을 생성했습니다. 총 약 22만 개의 수학 추론 인스턴스와 3만 5천 개의 코딩 인스턴스를 수집했습니다.
비준수와 안전성: 모델의 능력을 향상시켜 사용자를 효과적으로 도울 수 있도록 하면서, 안전하지 않은 요청을 안정적으로 거부하고 미묘하고 범위를 벗어난 쿼리를 적절히 처리할 수 있도록 보장하는 것이 중요합니다. 이를 지원하기 위해, 모델이 준수해서는 안 되는 비준수 쿼리 세트와 양성 및 악성 시나리오를 모두 다루는 안전 관련 직접 및 적대적 프롬프트를 큐레이션했습니다.
비준수와 안전성 프롬프트는 기존 데이터셋에서 큐레이션되거나 GPT 모델 패밀리에서 합성적으로 생성되었습니다. 구체적으로, 비준수 프롬프트는 불완전, 지원되지 않음, 불확정, 인간화 요청(안전하지 않은 요청 외에도)을 포함하는 여러 카테고리에 걸친 Brahman et al. (2024)의 맥락적 비준수 분류법을 기반으로 얻어졌습니다.
안전 관련 프롬프트는 합성 적대적 프롬프트, 합성 바닐라(직접) 요청, 실제 사용자-LLM 상호작용(In-The-Wild), 그리고 큐레이션된 주석자 작성 예시 중에서 신중하게 선택되어 최대한의 커버리지, 다양성, 균형을 달성했습니다.
프롬프트 오염 제거
훈련 믹스를 큐레이션할 때 중요한 고려사항 중 하나는 훈련 프롬프트와 평가 세트 간의 가능한 중복이었습니다. 연구진은 이러한 중복을 다음과 같이 정량화하고 테스트 세트 오염을 방지하기 위해 필요에 따라 훈련 믹스에서 인스턴스를 제거했습니다.
매칭 방법: 연구진은 전체 문자열, n-gram, 임베딩 기반 매칭을 실험했고, n-gram 매칭이 가장 유용한 결과를 제공한다는 것을 발견했습니다. 임베딩 기반 방법은 원칙적으로 의역으로 인한 비자명한 오염을 식별할 수 있지만, 단순한 분포적 유사성과 실제 의역을 구별하기 어려웠습니다. 더욱이, n-gram 매칭을 사용한 부분적 표면 수준 중복은 숫자만 다른 수학 문제와 같이 사소하게 다른 인스턴스의 오염 사례를 성공적으로 식별했습니다.
매칭 인스턴스 식별: 훈련 데이터셋의 완성은 종종 언어 모델을 사용해 재생성되므로, 프롬프트만으로(또는 더 일반적으로 다중 턴 대화에서 사용자 턴으로) 중복을 계산하기로 선택했습니다. Dubey et al. (2024)와 Singh et al. (2024a)를 따라 오염 검사에 8-gram 매칭을 사용했습니다.
테스트 인스턴스의 각 토큰에 대해, 두 인스턴스가 해당 토큰을 포함하는 8-gram을 공유하는 경우 훈련 인스턴스의 토큰과 매치된다고 간주하고, 테스트 토큰의 50% 이상이 동일한 훈련 인스턴스와 8-gram 매치를 가지는 경우 테스트 인스턴스 자체가 훈련 인스턴스와 상당한 중복을 가진다고 간주했습니다.
오염 제거: 개발 및 미공개 스위트의 평가 중 어느 것에서든 2% 이상의 인스턴스와 중복되는 인스턴스가 있는 경우 훈련 세트가 오염되었다고 간주했습니다. 미공개 평가와 오염된 모든 훈련 세트를 제거했습니다. 개발 평가와 오염된 훈련 세트의 경우, 그렇게 하는 것이 결과 모델의 성능에 크게 영향을 주지 않는다면 전체 데이터셋을 제거했습니다. 그렇지 않으면 테스트 인스턴스와 매치되는 특정 인스턴스를 제거했습니다.
| 데이터셋 | 평가 링크 | 제거 비율(%) |
|---|---|---|
| Evol CodeAlpaca | HumanEval | 3.5 |
| WildChat GPT-4 | Safety | 5.4 |
| WildJailbreak | Safety | 0.7 |
| WildGuardmix | Safety | 1.1 |
| NuminaMath-TIR | MATH | 11.3 |
위 표는 오염 제거된 데이터셋들을 보여주며, 제거 비율은 데이터셋에서 제거된 비율을 나타냅니다. 연구진이 오염 제거하고 중복 샘플이 제거된 버전으로 출시한 데이터셋 목록이 제시되어 있습니다.
지도 학습 미세조정
사전 훈련된 기본 모델을 다양한 작업과 사용자 요청에 적응시키는 과정은 종종 지도 학습 미세조정(SFT), 즉 지시 미세조정에 의존합니다. 이 과정에서 핵심적인 도전 과제는 다양한 기술을 나타내는 혼합 훈련 데이터셋의 비율을 균형 있게 조정하는 것입니다. Tülu 3에서는 우선순위를 둔 핵심 기술들에서 성능을 잘 균형 있게 맞추는 SFT 훈련 절차를 개발하기 위해 데이터 믹스 절제 실험과 모델 병합 기법을 탐구했습니다.
SFT 데이터
프롬프트에서 SFT 데이터로의 변환
SFT 믹스를 생성하기 위해, 연구진은 앞서 설명한 프롬프트들에 대한 응답을 두 가지 방식으로 수집하거나 생성했습니다. 기존 응답 필터링과 새로운 응답 생성입니다. 기존 응답이 있는 프롬프트의 경우, 일반적으로 인간이나 GPT-4o와 같은 최첨단 모델이 작성한 경우 원래 응답을 유지했습니다. 최첨단 모델의 부분집합을 포함하는 대규모 데이터셋(예: WildChat)의 경우, 최고 성능 모델의 부분집합을 사용했습니다.
또한 빈 응답과 모델이나 개발자에 대한 정보를 포함하는 응답을 필터링했습니다. Persona 프롬프트와 같이 응답이 없는 프롬프트 세트나 WildGuardMix와 같이 원래 응답이 더 약한 모델에서 나온 경우, GPT-4o를 사용하여 새로운 응답을 생성했습니다. 또한 하드코딩된 프롬프트에 대해서는 직접 응답을 작성했습니다.
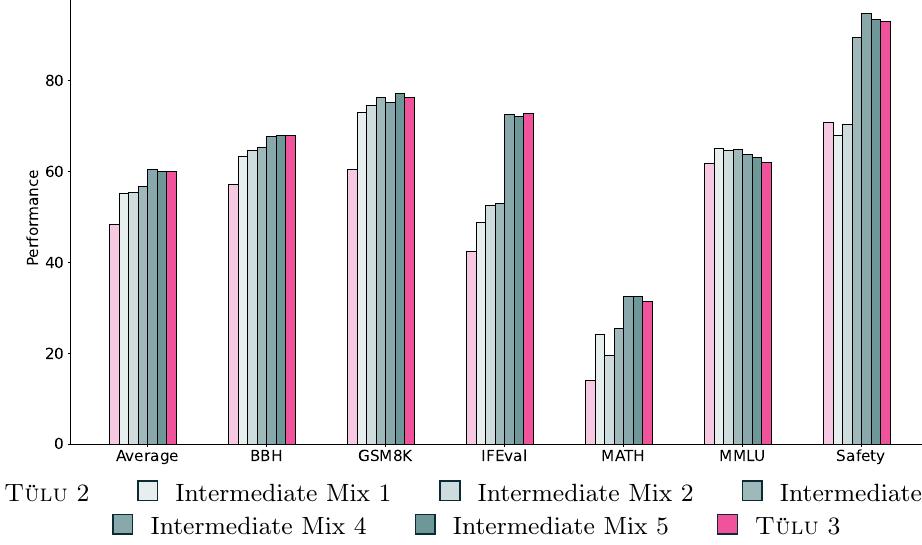
위 그림은 Llama 3.1 8B를 초기 Tülu 2 SFT 믹스와 중간 및 최종 Tülu 3 SFT 믹스로 훈련한 결과의 평균 및 선별된 기술별 성능을 보여줍니다. 중간 믹스 1, 2, 3은 성능 향상을 위해 새로운 데이터셋을 추가한 결과이며, 중간 믹스 4와 5는 여러 라운드의 오염 제거를 실행한 결과로 성능이 소폭 하락했습니다.
Tülu 3 SFT 믹스
SFT 믹스를 개발하기 위해, 연구진은 먼저 Tülu 2로 훈련된 Llama 3.1을 기준선으로 사용하여 최첨단 모델들보다 뒤처지는 기술들을 식별했습니다. 이러한 각 기술을 개별적으로 대상으로 하여, 고품질의 공개적으로 사용 가능한 데이터셋을 수집하고 합성 데이터셋을 생성했으며, 다른 최신 데이터셋에 비해 상대적으로 품질이 낮다고 식별된 일부 데이터셋을 제거했습니다.
최종 SFT 믹스를 설계하기 위해, 연구진은 먼저 기술별 데이터 믹스와 모델을 구축하여 개별 기술에서 최고 성능을 이끌어내는 믹스를 유지했으며, 다른 평가는 무시했습니다. 이는 주어진 설정에서 각 평가의 상한선을 근사하기 위함이었습니다. 그 후 이러한 믹스들을 결합하여 초기 Tülu 3 프리뷰 믹스를 생성했습니다.
이후 뒤처지는 기술을 개선하기 위해 데이터셋을 추가하거나 제거하고, 평가에 대한 오염 제거를 수행하며, 특히 큰 데이터셋을 다운샘플링하여 믹스를 지속적으로 반복 개선했습니다. 개발 과정에서 주요 프리뷰 버전들의 성능은 앞서 보여준 그림에서 확인할 수 있습니다.
최종 SFT 결과: 다음 표는 Llama 3 8B 또는 70B로 훈련된 다른 SFT 전용 모델들과 최종 Tülu 3 8B SFT 및 Tülu 3 70B SFT 모델을 비교한 결과입니다.
| 모델 | 평균 | MMLU | TQA | PopQA | BBH | CHE | CHE+ | GSM | DROP | MATH | IFEval | AE 2 | Safety |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Tülu 2 8B SFT | 48.3 | 61.8 | 49.4 | 23.3 | 57.1 | 66.9 | 63.1 | 60.4 | 61.7 | 14.0 | 42.3 | 8.9 | 56.0 |
| RLHFlow SFT V2 | 65.8 | 56.0 | 29.7 | 69.3 | 86.2 | 80.9 | 81.6 | 57.2 | 35.7 | 52.7 | 13.6 | - | - |
| MAmmoTH2 8B | 46.4 | 63.6 | 42.7 | 20.8 | 63.4 | 72.8 | 66.4 | 63.7 | 43.8 | 30.5 | 34.9 | 6.5 | - |
| Tülu 3 8B SFT | 60.1 | 62.1 | 46.8 | 29.3 | 67.9 | 86.2 | 81.4 | 76.2 | 61.3 | 31.5 | 72.8 | 12.4 | 93.1 |
| Tülu 2 70B SFT | 63.6 | 76.0 | 57.8 | 44.1 | 79.4 | 86.8 | 83.5 | 83.2 | 75.9 | 33.1 | 57.7 | 17.3 | - |
| Tülu 3 70B SFT | 72.6 | 79.4 | 55.7 | 48.6 | 82.7 | 92.9 | 87.3 | 91.1 | 77.2 | 53.7 | 82.1 | 26.3 | 95.2 |
새로운 SFT 믹스는 두 모델 크기에서 Tülu 2 믹스에 비해 상당한 개선을 보여주며, 다른 경쟁력 있는 8B SFT 모델들보다 평균적으로 더 나은 성능을 보입니다.
핵심 데이터 실험
최종 SFT 믹스를 개발한 후, 연구진은 데이터 믹싱과 훈련 중 내린 다양한 결정의 중요성을 탐구하기 위해 일련의 통제된 실험을 수행했습니다.
다양한 채팅 데이터: 믹스에서 주로 WildChat에서 가져온 다양한 채팅 데이터 추가를 강조했습니다. 다음 표에서 WildChat을 제거한 영향을 보여주며, 대부분의 기술에서 작지만 눈에 띄는 성능 저하가 있었고, 특히 Alpaca Eval에서 가장 두드러져 다양한 실제 데이터의 중요성을 강조합니다.
| 모델 | 평균 | MMLU | TQA | PopQA | BBH | CHE | CHE+ | GSM | DROP | MATH | IFEval | AE 2 | Safety |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Tülu 3 8B SFT | 60.1 | 62.1 | 46.8 | 29.3 | 67.9 | 86.2 | 81.4 | 76.2 | 61.3 | 31.5 | 72.8 | 12.4 | 93.1 |
| → w/o WildChat | 58.9 | 61.0 | 45.2 | 28.9 | 65.6 | 85.3 | 80.7 | 75.8 | 59.3 | 31.8 | 70.1 | 7.5 | 95.2 |
| → w/o Safety | 58.0 | 62.0 | 45.5 | 29.5 | 68.3 | 84.5 | 79.6 | 76.9 | 59.4 | 32.6 | 71.0 | 12.4 | 74.7 |
| → w/o Persona Data | 58.6 | 62.4 | 48.9 | 29.4 | 68.3 | 84.5 | 79.0 | 76.8 | 62.2 | 30.1 | 53.6 | 13.5 | 93.9 |
| → w/o Math Data | 58.2 | 62.2 | 47.1 | 29.5 | 68.9 | 86.0 | 80.5 | 64.1 | 60.9 | 23.5 | 70.6 | 12.0 | 93.5 |
안전성은 직교적: 안전성 SFT 데이터가 일반적으로 다른 데이터셋과 직교적임을 발견했습니다. 위 표에서 안전성 특화 데이터셋을 제거한 효과를 보고하며, 안전성 평균을 제외하고는 대부분의 기술이 거의 동일하게 유지되었습니다. 또한 CoCoNot과 같은 대조적 프롬프트를 추가하는 것이 모델이 안전한 프롬프트를 과도하게 거부하는 것을 방지하는 데 도움이 됨을 발견했습니다.
새로운 Persona 데이터: 새로운 Persona 데이터셋은 수학, 코딩, 지시 따르기와 같은 특정 기술을 대상으로 구축되었습니다. 위 표에서 Persona 데이터셋을 제거한 후 HumanEval(+), GSM8K, MATH, IFEval의 성능이 하락하는 것을 보여주며, 다양하고 기술별 SFT 데이터셋 생성의 가치를 입증합니다.
특정 기술 대상화: 연구의 상당 부분이 특정 능력을 대상으로 하는 데이터셋 수집이나 생성에 집중되었습니다. 수학적 추론을 예시로 사용하여, 위 표에서 수학 특화 데이터가 GSM8K와 MATH 모두에 미치는 영향을 보여줍니다. 수학 특화 SFT 데이터가 GSM8K와 MATH를 상당히 개선시켜 최종 믹스에 포함된 데이터의 가치를 보여줍니다.
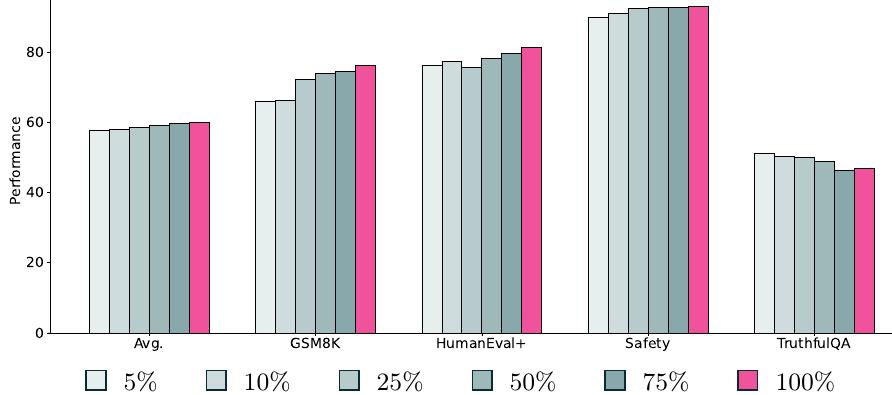
위 그림에서는 SFT 믹스의 계층화된 부분표본을 취한 효과를 보여줍니다. 모델들이 더 많은 SFT 데이터가 포함될수록 평균적으로 계속 개선되며, 전체 믹스까지 데이터 양을 늘릴 때 GSM8K와 같은 메트릭에서 큰 개선을 보입니다. 흥미롭게도 TruthfulQA 성능은 믹스의 데이터 양이 증가할수록 실제로 하락합니다. 선호도 최적화를 위해 다른 프롬프트를 할당했기 때문에 현재 믹스를 넘어서 SFT 데이터 크기를 늘리지 않았습니다.
SFT 레시피와 분석
훈련 설정: Tülu 3 모델을 훈련하기 위해 고속 인터커넥트를 갖춘 4~16개의 8xH100 노드를 사용했습니다. 최종 8B 모델은 32개 GPU에서 6시간 동안 훈련되었고, 70B 모델은 64개 GPU에서 50시간 동안 훈련되었습니다.
| 하이퍼파라미터 | 8B | 70B |
|---|---|---|
| 학습률 | 5 × 10⁻⁶ | 2 × 10⁻⁶ |
| 학습률 스케줄 | Linear | Linear |
| 배치 크기 (유효) | 128 | 128 |
| 최대 토큰 길이 | 4,096 | 4,096 |
| 워밍업 비율 | 0.03 | 0.03 |
| 에포크 수 | 2 | 2 |
유효 배치 크기 128과 최대 시퀀스 길이 4,096 토큰을 사용했습니다. 하이퍼파라미터 탐색을 통해 찾은 학습률을 사용하여 2 에포크 동안 훈련했습니다. 8B 모델의 경우 5e-6, 70B 모델의 경우 2e-6입니다. 병합 실험을 위해서는 선형 가중 평균을 사용하는 mergekit을 사용했습니다.
핵심 훈련 실험
기본 모델 선택: 전체 SFT 믹스를 사용하여 다양한 기본 사전 훈련 모델을 훈련한 수학적 성능에 대한 효과도 테스트했습니다. 다음 표에서 Llama 3.1 8B와 70B 모두에서 훈련하여 모델 크기 변경의 영향과, Qwen 2.5 7B와 Qwen 2.5 Math 7B에서 훈련하여 도메인별 사전 훈련 데이터 추가의 영향을 보여줍니다.
| 기본 모델 | GSM8K | MATH |
|---|---|---|
| Llama 3.1 8B | 76.2 | 31.5 |
| Llama 3.1 70B | 91.1 | 53.7 |
| Qwen 2.5 7B | 79.2 | 49.4 |
| Qwen 2.5 Math 7B | 86.3 | 56.4 |
두 경우 모두 GSM8K와 MATH에서 상당한 개선을 보여 하위 기술에 대한 모델 크기와 사전 훈련 데이터의 중요성을 강조합니다.
채팅 템플릿 변형: Tülu 3를 생성하는 동안 미세조정된 모델의 생성을 안내하는 데 사용되는 채팅 템플릿 변경을 탐구했습니다. 이전 Tülu 버전에서 사용된 채팅 템플릿에 작은 변경을 가했는데, 구체적으로 템플릿 끝(모델 응답 전)의 새 줄을 제거했습니다.
| 채팅 템플릿 | 평균 |
|---|---|
| Tülu (replace \n w/ eos) | 53.0 |
| Zephyr | 52.9 |
| Tülu 3 (no \n) | 52.8 |
| Tülu 2 template | 52.6 |
| Llama 3 template | 51.6 |
어시스턴트 메시지 끝의 새 줄을 eos 토큰으로 교체하는 것이 최고 성능을 보였지만, 사후 훈련 파이프라인의 후속 단계와의 생성 일관성을 피하기 위해 이를 사용하지 않기로 했습니다.
랜덤 시드와 모델 수프: SFT 중 랜덤 시드 변경과 이러한 모델들을 사용한 모델 수프 생성도 탐구했습니다. 다음 표에서 여러 다른 시드로 8B와 70B 모델을 훈련한 결과와 최고 모델 수프를 비교합니다.
| 모델 | 시드 | 평균 |
|---|---|---|
| Tülu 3 8B SFT | 42 (기본) | 59.9 |
| 123 | 60.1 | |
| 456 | 59.8 | |
| 789 | 59.8 | |
| 1011 | 59.8 | |
| 최고 모델 수프 | 123 & 456 | 60.2 |
| Tülu 3 70B SFT | 42 (기본) | 71.8 |
| 123 | 70.0 | |
| 456 | 72.6 | |
| 최고 모델 수프 | 42 & 123 | 72.5 |
SFT 성능이 시드에 따라 눈에 띄게 변하여 여러 훈련 실행의 중요성을 강조하며, 최고 모델 수프가 항상 최고 단일 훈련 실행을 능가하지는 않습니다. 이 때문에 각 모델 크기에 대해 최고 단일 SFT 훈련 실행을 최종 SFT 모델로 사용합니다.
배치 집계
Tülu 3 훈련 초기에 OpenInstruct 프레임워크에서 훈련된 SFT 모델과 TPU와 같은 다른 설정에서 훈련된 모델 간의 성능 격차를 발견했습니다. 이 문제는 주로 Transformers 내의 손실 집계 문제 때문이었습니다. 그래디언트 누적이나 분산 훈련 설정을 고려하지 않고 패딩 토큰에 대해 손실을 평균화하는 것입니다.
예시로 이 문제를 설명하면, 배치에 두 개의 샘플이 있고 각각 \(n_1, n_2\)개의 비패딩 토큰과 \(m_1, m_2\)개의 패딩 토큰이 있다고 가정합니다. 기본 Transformers 순전파에 두 샘플을 동시에 전달하면:
\[L = \frac{ln_1 + ln_2}{n_1 + n_2}\]그러나 그래디언트 누적을 적용하여 두 샘플을 별도로 입력하고 손실을 계산한 후 나누면:
\[L = \frac{\frac{ln_1}{n_1} + \frac{ln_2}{n_2}}{2}\]즉, 두 번째 경우에는 각 예시를 동등하게 가중하는 반면, 첫 번째 경우에는 각 토큰을 동등하게 가중합니다. 따라서 그래디언트 누적을 변경하면 효과적으로 샘플 가중치를 변경하여 성능에 큰 영향을 미칠 수 있습니다.
이 문제를 해결하기 위해 일반적으로 훈련 시 평균 손실 대신 합 손실을 사용하기로 했습니다. 이는 위 방정식에서 분모를 제거하여 문제를 해결하며 학습률 조정이 필요합니다. 이는 효과적으로 모든 토큰을 동등하게 가중하며(초기 믹스에 대해 일반적으로 더 나은 성능을 보임), 다양한 학습률, 에포크, 손실 유형을 사용하여 Tülu 2 SFT 믹스에서 Llama 3.0을 미세조정하여 설정의 성능을 검증했습니다.
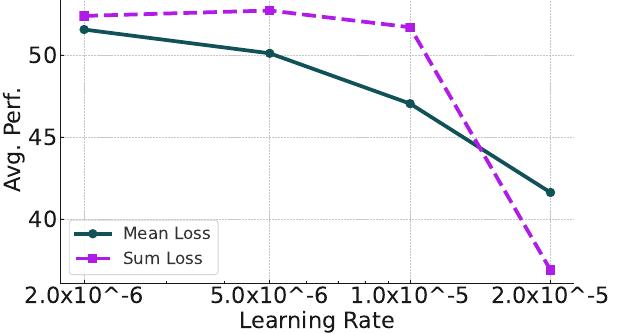
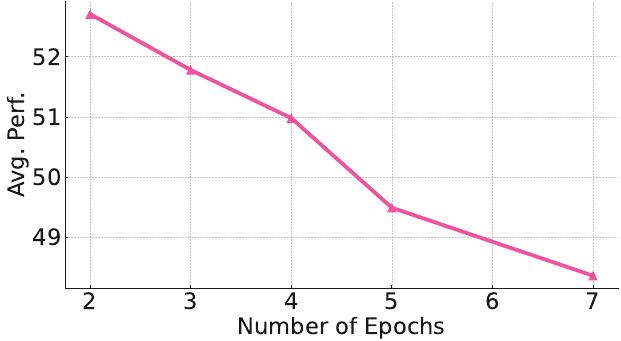
위 그림들에서 보듯이 합 손실과 5.00E-06의 학습률이 최고 성능을 보였습니다. 놀랍게도 더 오래 훈련해도 추가 개선이 없어서 2 에포크를 사용했습니다.
선호도 미세조정
Tülu 3에서는 전체 평가 스위트에서 성능을 향상시키기 위해 다양한 선호도 미세조정 접근법을 탐구했습니다. Direct Preference Optimization(DPO)와 그 파생 방법부터 Proximal Policy Optimization(PPO)과 같은 강화학습 알고리즘까지 여러 훈련 알고리즘을 실험했습니다. 이 섹션에서는 인간 선호도로부터 학습하는 문제 공식화와 옵티마이저들을 자세히 설명합니다. 다음으로 온폴리시(Tülu 3 스위트)와 오프폴리시 모델(다른 지시 모델들) 모두에서 프롬프트를 합성 선호도 데이터로 변환하는 방법을 설명합니다. 특정 관심 기술에 대한 선호도 데이터를 생성하는 방법과 DPO를 통해 모델을 견고하게 개선하는 방법을 보여줍니다.
배경
이전 연구들은 인간 또는 합성 선호도를 시뮬레이션하는 벤치마크에서 모델 성능을 향상시키는 중요한 단계로 선호도 데이터에 대한 훈련을 확립했습니다. 일반적인 절차는 인간 또는 AI 피드백으로부터의 강화학습(RLHF/RLAIF)입니다.
설정
선호도 데이터: 표준 설정에서는 프롬프트 \(x\)와 프롬프트당 두 개의 응답 \(y, y'\)로 구성된 선호도 데이터셋 \(D\)가 있습니다. 일부 판단자(들)가 \(y, y'\) 중 하나를 선호 응답 \(y_c\)로 선택하고, 다른 하나를 거부 응답 \(y_r\)로 라벨링합니다.
보상 모델: 선호도 데이터셋이 주어지면, 보상 모델(RM) \(r_\phi\)가 다음 목표로 훈련됩니다.
\[\max_{r_\phi} \mathbb{E}_{(x,y_c,y_r)\sim D}[\log\sigma(r_\phi(x,y_c) - r_\phi(x,y_r))]\]여기서 \(\sigma\)는 로지스틱 함수입니다. RM 목표는 보상 간의 차이를 최대화하며, 이 차이는 \(y_c\)가 \(y_r\)보다 선호될 로그 우도를 나타냅니다. 이 보상 모델은 RM의 판단에 따라 선호되는 콘텐츠를 출력하도록 정책 모델을 훈련하는 데 도움이 됩니다.
정책 최적화
선호도 데이터에 접근할 수 있는 언어 모델을 최적화하는 옵션은 매우 다양합니다. 오늘날 두 가지 범주로 추상화할 수 있는데, 가치나 보상의 내부 표현으로부터 학습하는 강화학습 알고리즘과 데이터로부터 직접 학습하는 직접 정렬 알고리즘입니다. 이전 연구들은 다음 목표로 정책 \(\pi_\theta\)를 최적화합니다.
\[\max_{\pi_\theta} \mathbb{E}_{y\sim\pi_\theta(x)} [R(x,y)] = [r_\phi(x,y) - \beta KL[\pi_\theta(y|x)\|\pi_{\text{ref}}(y|x)]]\]여기서 \(\pi_{\text{ref}}\)는 초기 참조 정책이고 \(\beta\) 계수는 참조 정책과 훈련 정책 간의 Kullback-Leiber 발산(KL 발산)을 제어하는 데 도움이 됩니다.
Proximal Policy Optimization (PPO): 위 목표를 해결하는 한 가지 접근법은 PPO와 같은 온라인 강화학습을 사용하는 것입니다. PPO의 각 훈련 반복에서 정책은 일부 샘플을 생성하고, 해당 샘플에 대해 RM을 사용하여 보상을 생성하며, PPO 알고리즘을 사용하여 \(R(x,y)\)를 최대화해야 합니다. PPO 훈련 루프는 복잡하므로, 설정과 일반적인 설정에 대한 더 자세한 설명은 관련 연구들을 참조하시기 바랍니다.
Direct Preference Optimization (DPO)와 변형들: 또 다른 접근법은 오프라인 선호도 조정입니다. DPO는 다음과 같은 동등한 목표로 RLHF 목표를 직접 최적화할 수 있습니다.
\[\max_{\pi_\theta} \mathbb{E}_{y_c,y_r\sim D} \left[\log\sigma \left(\beta \log \frac{\pi_\theta(y_c|x)}{\pi_{\text{ref}}(y_c|x)} - \beta \log \frac{\pi_\theta(y_r|x)}{\pi_{\text{ref}}(y_r|x)} \right)\right]\]DPO는 훈련된 보상 모델을 사용하거나, 정책 생성을 수행하거나, RM으로부터 보상을 얻을 필요 없이 암시적 보상 모델과 정책 모델을 동시에 훈련합니다. 중요하게도, 이는 다양한 소스에서 수집된 선호도 쌍에 대해 언어 모델을 직접 훈련하는 오프라인 선호도 미세조정을 가능하게 합니다.
최근 많은 연구들이 DPO 목표를 더욱 개선하는 방법을 검토했으며, 다수의 변형들이 제안되었습니다. 이 연구에서는 두 가지 유망한 변형을 탐구했습니다. SimPO와 길이 정규화된 DPO입니다. 이어지는 섹션에서 길이 정규화된 DPO가 가장 잘 작동한다는 것을 발견했으며, 이는 다음 목표를 사용합니다.
\[\max_{\pi_\theta} \mathbb{E}_{y_c,y_r\sim D} \left[\log\sigma \left(\frac{\beta}{|y_c|} \log \frac{\pi_\theta(y_c|x)}{\pi_{\text{ref}}(y_c|x)} - \frac{\beta}{|y_r|} \log \frac{\pi_\theta(y_r|x)}{\pi_{\text{ref}}(y_r|x)} \right)\right]\]보시다시피, 이는 단순히 DPO 목표이지만 길이에 대해 정규화된 로그 확률을 사용하며, 이는 직관적으로 인간과 모델 선호도에서 흔한 길이 편향을 완화하는 데 도움이 됩니다. Tülu 3를 개발할 때, PPO와 같은 접근법에 비해 상대적인 단순성과 속도 때문에 선호도 데이터 믹스와 생성 방법을 조정하는 데 길이 정규화된 DPO를 사용하기로 했습니다.
Tülu 3 선호도 데이터
프롬프트에서 선호도 데이터로
앞선 섹션의 프롬프트를 사용하여 UltraFeedback 파이프라인을 적응하고 발전시켜 온폴리시 선호도 데이터 \((x,y,y',\text{label})\)을 생성합니다. 초기 실험에서 이 파이프라인이 선호도 데이터 생성에 도움이 된다는 것을 보여주었으며, 이는 고품질의 합성 선호도 데이터셋으로 이어집니다.
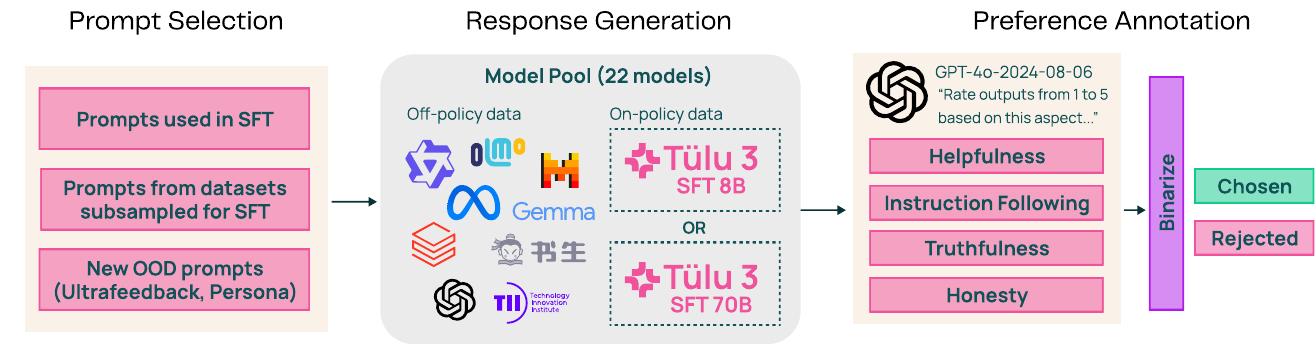
데이터 생성 파이프라인은 세 단계로 구성됩니다. 프롬프트 선택, 모델 풀에서의 응답 생성, 그리고 LLM-as-a-judge를 통한 선호도 주석으로 (선호, 거부) 쌍을 생성합니다.
1단계: 프롬프트 선택 선호도 미세조정을 위한 데이터셋을 준비하는 첫 번째 단계는 응답을 생성하고 선호도를 얻을 프롬프트나 사용자 지시를 선택하는 것입니다. 프롬프트 세트가 주어졌을 때, SFT 중에 사용된 프롬프트와 동일한 소스에서 부분표본화되었지만 SFT에는 사용되지 않은 프롬프트를 포함하도록 선택을 큐레이션했습니다. 또한 TruthfulQA 인스턴스가 없는 UltraFeedback 버전이나 프롬프트에 새로운 IF 제약을 추가하는 등 다른 소스의 프롬프트도 포함했습니다.
2단계: 응답 생성 주어진 프롬프트에 대해 모델 풀에서 네 개의 모델을 무작위로 샘플링하여 응답을 생성합니다. 모델 선택은 매개변수 크기와 모델 패밀리에 걸쳐 다양한 오픈소스 및 독점 모델로 구성된 UltraFeedback 파이프라인에서 영감을 받았습니다. 일부 모델의 최신 버전을 사용하고(Llama 2 → Llama 3.1), 성능이 우수한 모델을 추가하여 풀 크기를 늘리며, WizardLM과 같이 현재 접근할 수 없는 모델을 오픈소스 대안으로 교체하여 UltraFeedback의 모델 풀을 업데이트했습니다. 마지막으로, Tülu SFT 모델에서 완성을 샘플링하여 온폴리시 데이터도 포함했습니다. 한 응답은 온폴리시 모델에서 생성되고 다른 응답은 오프폴리시 모델에서 생성되는 프롬프트 선택을 추가하여 이를 접근했습니다.
3단계: 선호도 주석 각 프롬프트에 대해 네 개의 응답을 생성한 후, LLM-as-a-judge, 특히 GPT-4o-2024-0806을 사용하여 유용성, 지시 따르기, 정직성, 진실성의 네 가지 측면에서 각 응답을 1부터 5까지 평가했습니다. 부록 D에서는 오프폴리시 데이터를 샘플링하는 데 사용된 외부 모델과 각 측면에 대한 프롬프트 템플릿을 보여줍니다. DPO를 위한 이진 선호도를 얻기 위해 Argilla의 이진화 방법과 유사하게 선호도 평가의 평균을 구하고 가장 높은 평가를 받은 응답을 선택된 응답으로, 낮은 평균을 가진 응답들 중에서 무작위로 샘플링한 것을 거부된 응답으로 취했습니다.
Tülu 3 선호도 믹스
8B와 70B 모델에 대한 최종 선호도 믹스를 선택했으며, 이는 개발 평가에서 평균 성능을 최대화하면서 목표 기술에서도 뛰어난 성능을 보입니다. 대부분의 선호도 데이터 믹스 절제 실험은 8B 모델에 대해 실행되었습니다. SFT에 사용된 프롬프트로 시작하여 온폴리시와 오프폴리시 선호도 데이터를 생성했으며, 그 결과 96,911개(오프폴리시)와 19,444개(온폴리시) 선호도 인스턴스가 생성되었습니다.
이러한 선호도 기반을 바탕으로 믹스에 추가 프롬프트 소스를 추가하는 절제를 수행하고 이러한 추가가 하위 평가 성능, 특히 정확한 지시 따르기, 수학, AlpacaEval에서의 일반 채팅 성능과 같은 기술을 목표로 하는 데 어떤 영향을 미치는지 연구했습니다. 아래 표는 선호도 데이터셋의 포함 또는 제외가 평균 성능에 미치는 영향을 보여줍니다.
| 데이터셋 | 개수 | 8B | 70B |
|---|---|---|---|
| SFT 재사용 온폴리시 | 19,444 | ✓ | ✓ |
| SFT 재사용 오프폴리시 | 96,911 | ✓ | ✓ |
| IF-증강 | 65,530 | ✓ | ✓ |
| WildChat IF | 10,792 | ✓ | ✓ |
| WildChat 재사용 | 17,207 | ✓ | ✓ |
| WildChat 미사용 | 82,783 | ✓ | |
| Ultrafeedback (정제) | 41,635 | ✓ | ✓ |
| Persona IF | 19,890 | ✓ | |
| 총계 | 354,192 | 271,409 | 334,302 |
Tülu 3 8B DPO와 Tülu 3 70B DPO에 대한 최고의 선호도 데이터셋 믹스는 SFT 데이터, WildChat, Persona IF 등 다양한 프롬프트 소스에서 나옵니다. 여기에는 SFT 훈련 중에 본 프롬프트뿐만 아니라 새로운, 보지 못한 프롬프트도 포함됩니다.
데이터 절제의 주요 발견
합성 선호도 파이프라인의 설계 결정과 Tülu 3 선호도 믹스의 구성을 알리기 위해 여러 절제를 수행했습니다.
고유 프롬프트 수 확장이 하위 DPO 성능을 향상시킵니다. 먼저 프롬프트 수를 늘리는 것이 하위 DPO 성능 향상을 가져올지 조사했습니다. 이를 위해 고유 프롬프트가 있는 고정된 양의 선호도에서 다양한 크기에서 하위 DPO 모델 성능을 측정했습니다.
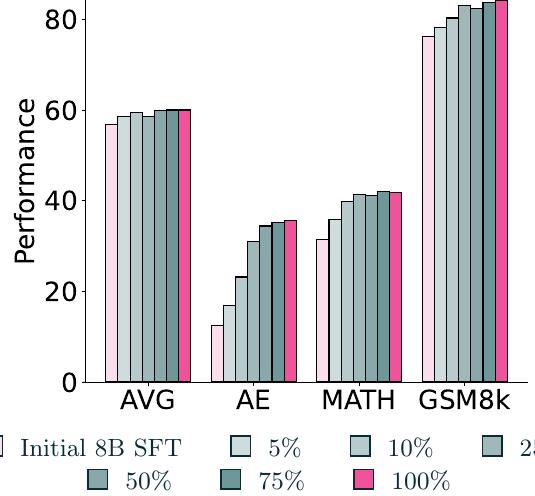
위 그림은 선호도 데이터셋의 크기가 증가함에 따라 여러 메트릭에서 눈에 띄는 성능 향상이 있음을 보여줍니다. 이는 하위 모델 성능에서 개선을 달성하기 위해 데이터셋 확장이 중요함을 시사합니다. 최종 선호도 믹스는 8B 모델에 대해 270k 이상의 데이터 포인트와 70B 모델에 대해 330k 이상의 인스턴스를 포함하며, 이는 많은 사용 가능한 선호도 데이터셋보다 상당히 큽니다.
또한 프롬프트를 복제하는 것, 즉 다른 응답을 가진 동일한 프롬프트가 선호도 데이터셋의 크기를 확장하는 실행 가능한 접근법인지, 그리고 이것이 하위 DPO 성능 향상으로 이어질지 탐구했습니다.
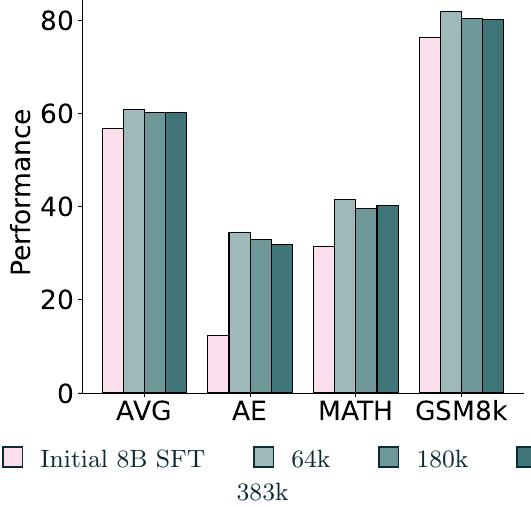
위 그림에서 보듯이, 평균적으로 383k 크기의 선호도 데이터셋은 64k 선호도 데이터셋과 유사하게 수행됩니다. 또한 복제된 프롬프트 수가 증가함에 따라 DROP, GSM8k, AlpacaEval에서 약간의 성능 저하를 관찰했습니다. 이는 프롬프트 복제를 통한 확장이 반드시 하위 DPO 성능에서 상당한 향상을 가져오지 않으며, 고유 프롬프트 수집과 적절한 믹싱에 투자하는 것이 하위 평가에 더 중요함을 시사합니다.
미사용 프롬프트가 SFT 믹스의 프롬프트 재사용보다 높은 성능을 보입니다. 그 다음 새로운 프롬프트를 포함하는 것과 SFT 단계에서 프롬프트를 재사용하는 것이 하위 DPO 성능에 미치는 영향을 비교했습니다.
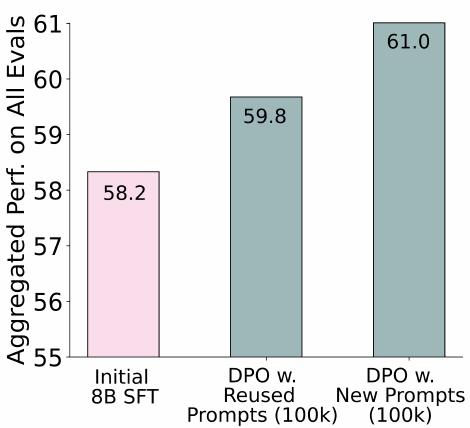
위 그림은 미사용 데이터셋이 프롬프트를 재사용하는 것에 비해 약간 높은 성능을 보임을 보여줍니다. 이는 새로운 프롬프트의 존재가 하위 DPO 성능을 향상시키는 데 도움이 될 수 있음을 시사합니다. 하지만 최고 믹스에서 보듯이, 미사용과 재사용 프롬프트를 결합하는 것이 최고의 결과로 이어지는 것 같습니다.
온폴리시 데이터가 하위 DPO 성능을 향상시킵니다. 온폴리시 데이터, 즉 선호도 미세조정을 위한 기본 모델로 사용될 SFT 모델의 텍스트 생성을 포함하는 것이 하위 모델 성능을 향상시키는지 조사했습니다.
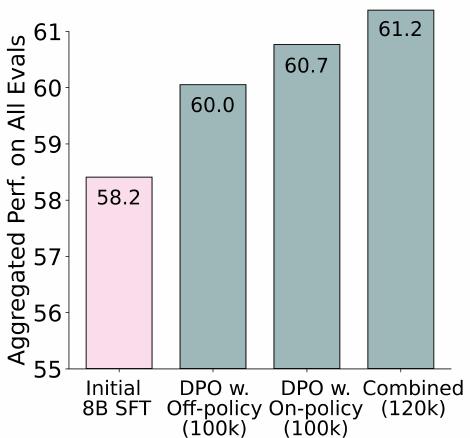
위 그림은 온폴리시 데이터를 포함하는 것이 다른 모델들의 프롬프트 완성이 샘플링된 완전히 오프폴리시 데이터셋에 비해 집계된 하위 DPO 성능을 향상시킴을 보여줍니다.
LLM 판단자들 간의 성능은 유사하며, GPT-4o가 약간 앞섭니다. 선호도 주석을 얻기 위해 사용할 판단자를 결정하기 위해 GPT-4(GPT-4-turbo-2024-04-09, GPT-4o-2024-08-06, gpt-4o-mini-2024-07-18)와 Llama 3.1(70B와 405B)과 같은 여러 상업적 및 오픈소스 LLM 판단자를 동일한 10k 무작위 샘플링된 Ultrafeedback 프롬프트와 응답 세트에서 테스트했습니다.
| LLM 판단자 | 평균 | MMLU | TQA | PopQA | BBH | CHU | CHU+ | GSM8k | Drop | MATH | IFEval | AE | Safety |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| GPT-4o | 57.3 | 64.8 | 56.1 | 30.1 | 66.3 | 87.0 | 80.7 | 75.3 | 62.7 | 20.3 | 60.4 | 20.6 | 62.7 |
| Llama 3.1 405B | 64.8 | 56.0 | 30.3 | 67.4 | 86.2 | 80.8 | 75.1 | 62.0 | 20.1 | 59.0 | 21.5 | 62.8 | |
| GPT-4 Turbo | 57.0 | 64.6 | 55.7 | 30.1 | 66.4 | 86.6 | 79.4 | 75.5 | 62.6 | 20.1 | 59.9 | 20.6 | 62.2 |
| GPT-4o Mini | 56.9 | 64.4 | 55.4 | 30.4 | 66.2 | 86.6 | 79.8 | 74.8 | 60.7 | 20.9 | 60.1 | 21.4 | 61.6 |
| Llama 3.1 70B | 56.6 | 64.3 | 55.5 | 30.2 | 66.6 | 85.3 | 81.4 | 74.8 | 62.1 | 20.1 | 58.2 | 18.6 | 62.2 |
일반적으로 GPT-4o, Llama 3.1 405B, GPT-4 Turbo는 모든 벤치마크에서 유사하게 수행되며, 위 표에서 보듯이 GPT-4o가 집계된 평균 성능에서 약간 앞섭니다. Tülu 3의 합성 선호도 파이프라인에서는 사용 편의성, 요청당 저렴한 비용, OpenAI의 Batch API를 통한 배치 추론 속도 때문에 GPT-4o-2024-08-06을 선택했습니다.
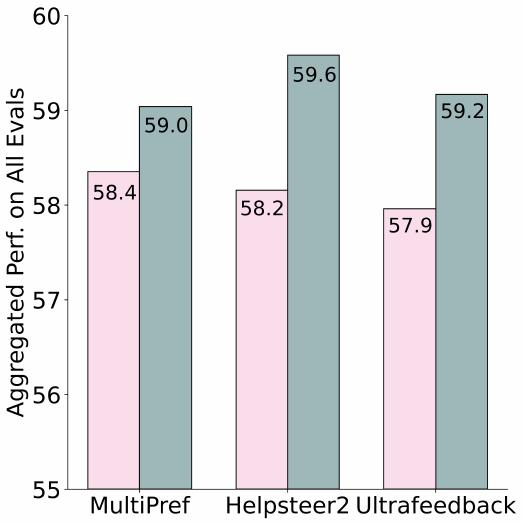
UltraFeedback을 넘어서기. 공개적으로 사용 가능한 데이터셋을 사용한 선호도 학습에 대한 이전 연구는 UltraFeedback 선호도 데이터셋이 일반적으로 다른 선호도 데이터셋보다 우수한 성능을 보인다는 것을 보여주었습니다.
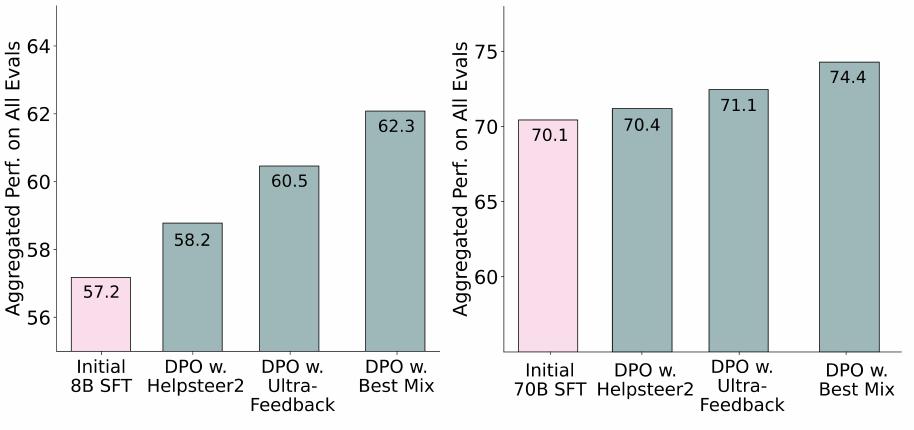
위 그림에서 최고 믹스에서 훈련함으로써 UltraFeedback에서의 DPO 훈련을 상당히 능가할 수 있었음을 보여줍니다. 개선은 70B 모델에서 더 크며(+3.3 vs +1.8), 이는 UltraFeedback의 완성이 주로 시작하는 70B 모델보다 덜 능력 있는 모델들에서 소싱되었기 때문이라고 가설을 세웁니다. 또 다른 고품질 선호도 데이터셋인 Helpsteer2도 8B 모델에서 최고 믹스보다 낮은 성능을 보입니다.
Persona 선호도 데이터. 지시 따르기, 코딩, 수학 기술을 목표로 하는 세 가지 persona 선호도 데이터셋 중에서 Tülu 3 Persona IF만이 평균 평가 점수와 목표 IFEval 점수를 향상시킵니다.
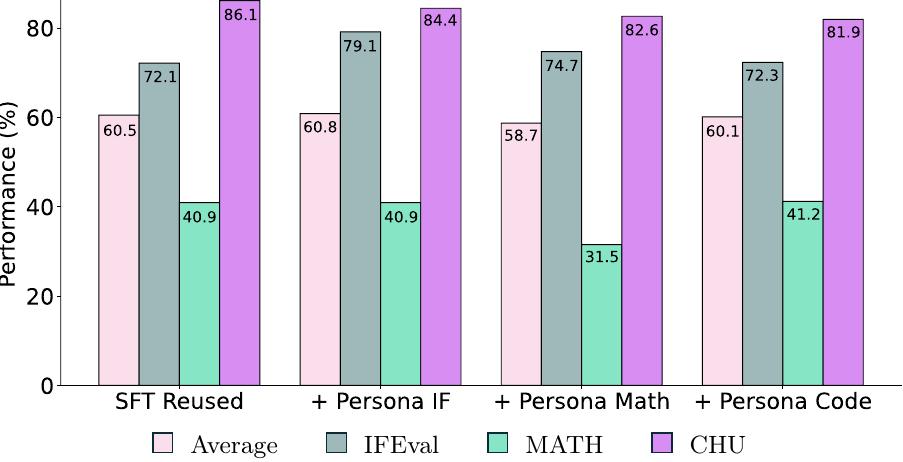
위 그림에서 보듯이 Tülu 3 Persona Math나 Tülu 3 Persona Code는 각각의 목표 평가를 향상시키지 못하고 평균 점수를 약간 해칩니다. 따라서 최종 믹스에는 Tülu 3 Persona IF 선호도만 포함했습니다.
IF 목표화. 모델의 정확한 지시 따르기 기술을 향상시키기 위해 목표화된 선호도 데이터를 생성했습니다.
-
Persona IF: 수집된 지시 따르기 SFT 데이터셋인 If-Persona-Sft의 부분집합을 가져와 선호도 데이터셋으로 변환했습니다. If-Persona-Sft 데이터셋의 각 예시는 (프롬프트, 제약, 응답) 튜플을 포함합니다. 부분집합의 각 프롬프트를 주어진 제약 중 하나를 완화하도록 다시 작성하는 것으로 시작했습니다. 구체적으로, GPT-4o에게 수정된 프롬프트에 대한 새로운 응답이 더 이상 원래 프롬프트에 대한 유효한 응답이 아니도록(모든 제약을 만족하지 않도록) 다시 작성을 생성하도록 프롬프트했습니다. 그 다음 새로운 수정된 프롬프트에 대한 응답을 거부된 응답으로 사용하고, (선택, 거부) 쌍을 생성하여 약 20K 예시를 포함하는 If-Persona-Pref 데이터셋을 형성했습니다.
-
IF-증강: Tülu 2 SFT 믹스에서 지시를 무작위로 샘플링하고 Zhou et al. (2023)의 분류법에서 제약을 결합했습니다. 선택된 완성과 거부된 완성은 §5.2.1의 합성 파이프라인을 통해 얻어졌습니다.
-
WildChat IF: 제약을 포함하는 WildChat의 지시를 샘플링했습니다. 이를 위해 GPT-4에게 프롬프트가 제약을 포함하는지 여부를 추출하도록 요청했습니다.
IF-증강의 경우, 66k 이상의 추가 인스턴스 세트를 생성하고 선택된 완성을 제약 검증자 함수를 통해 실행하여 실제로 제약을 충족한 인스턴스만 최종 세트에 추가했습니다. 이로 인해 약 26k 선호도의 정제된 세트가 남았으며, 이를 IF-증강-검증이라고 명명했습니다.
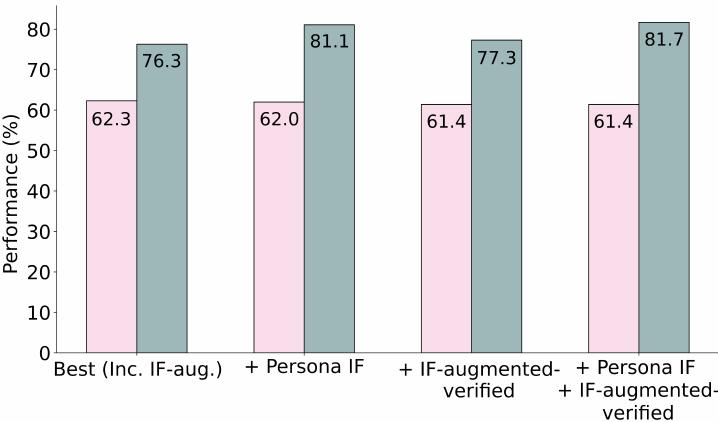
위 그림에서 IF-persona 선호도가 기준 믹스를 넘어 IFEval 점수를 상당히 향상시키면서 평균 성능을 최소한으로 해치는 것을 보여줍니다. IF-증강-검증 데이터셋은 IFEval 성능을 1점만 향상시키면서 평균 성능도 약간 해칩니다. IF-persona와 IF-증강-검증을 결합하면 최고의 IFEval 성능을 보이지만 평균이 약간 낮아집니다. 따라서 최종 8B DPO 믹스에는 IF-증강(검증되지 않음)과 Persona IF를 포함하기로 했으며, 이는 만족스러운 평균과 IFEval 점수 모두로 이어집니다.
WildChat. 절제 실험에서 WildChat 프롬프트와 합성 선호도 데이터 파이프라인을 사용하여 얻은 선택/거부 쌍으로 구성된 선호도 데이터를 추가하는 것이 일반적으로 DPO 성능을 향상시킨다는 것을 보여줍니다. 앞선 섹션의 절제에서 SFT 훈련 중에 본 WildChat 프롬프트를 DPO 믹스에 추가하는 것이 미사용과 재사용 WildChat 프롬프트를 결합하는 것보다 더 나은 평균 성능으로 이어진다는 것을 보여줍니다.
원본 선호도 데이터셋과 재생성된 대응물 비교. 또한 앞선 절의 합성 파이프라인에 의해 생성된 선호도 데이터셋이 기존 데이터셋에서 하위 DPO 성능 향상을 가져올 수 있는지 조사했습니다.
위 그림에서 재생성된 데이터셋의 하위 DPO 성능이 원본 데이터셋보다 더 좋다는 것을 보여주며, 합성 파이프라인 자체가 성능 향상을 가져올 수 있음을 시사합니다.
선호도 조정 레시피와 분석
하이퍼파라미터와 알고리즘 설계
Tülu 2 출시 이후 DPO와 관련 알고리즘을 개선하는 상당한 연구가 이루어진 점을 고려하여, 선호도 데이터셋과 함께 하이퍼파라미터와 알고리즘 선택을 재검토했습니다. 초기 SFT 체크포인트와 UltraFeedback 데이터셋을 사용하여 알고리즘과 하이퍼파라미터 선택을 모두 절제했습니다. DPO, SimPO, 그리고 길이 정규화된 DPO를 탐구했습니다.
| 알고리즘 | 학습률 | γ - β 비율 | β | 에포크 | 배치 크기 | 평균 점수 |
|---|---|---|---|---|---|---|
| SFT 기준 | - | - | - | - | - | 55.7 |
| SimPO | 5.00E-07 | 0.5 | 2 | 1 | 128 | 51.8 |
| SimPO | 5.00E-07 | 0.3 | 10 | 1 | 128 | 52.9 |
| DPO | 5.00E-07 | - | 0.1 | 3 | 32 | 55.2 |
| PPO | 1.00E-06 | - | 0.0325 | 1 | 64 | 54.5 |
| PPO | 1.00E-06 | - | 0.05 | 1 | 64 | 55.5 |
| DPO-norm | 1.00E-07 | - | 5 | 3 | 32 | 56.1 |
| DPO-norm | 5.00E-07 | - | 10 | 3 | 32 | 55.2 |
| DPO-norm | 5.00E-07 | - | 15 | 3 | 32 | 55.7 |
| DPO-norm | 5.00E-07 | - | 2 | 3 | 32 | 46.8 |
| DPO-norm | 5.00E-07 | - | 5 | 1 | 32 | 57.3 |
위 표에서 보듯이 길이 정규화된 DPO만이 전체적으로 기준 체크포인트를 능가했으며, 이를 더욱 조정하여 위 표에 표시된 최종 하이퍼파라미터를 얻었습니다. 더 큰 모델로 SFT를 수행할 때 학습률을 낮추고 배치 크기를 늘리는 것이 일반적이라는 사실을 바탕으로 70B 훈련에서는 학습률을 낮추고 배치 크기를 늘렸습니다.
| 하이퍼파라미터 | 8B | 70B |
|---|---|---|
| 학습률 | 5 × 10⁻⁷ | 2 × 10⁻⁷ |
| 학습률 스케줄 | Linear | Linear |
| 배치 크기 (유효) | 128 | 128 |
| 최대 토큰 길이 | 2,048 | 2,048 |
| KL 페널티 계수 β | 5 | 5 |
| 워밍업 비율 | 0.1 | 0.1 |
| 에포크 수 | 1 | 1 |
8B DPO 모델은 8개의 Nvidia H100 GPU에서 10시간 동안 훈련되었고, 70B DPO 모델은 64개의 상호 연결된 H100에서 19시간 동안 훈련되었습니다. DPO 훈련은 최대 시퀀스 길이 2048을 사용합니다.
70B를 위한 학습률 절제. 일반적으로 잘 수행되는 선호도 데이터 믹스와 최종 최고 믹스를 사용하여 학습률에 대한 소규모 하이퍼파라미터 탐색을 실행했습니다.
| 데이터 | 학습률 | 평균 성능 |
|---|---|---|
| Mix 1 | 5.0 × 10⁻⁷ | 72.74 |
| Mix 1 | 2.0 × 10⁻⁷ | 71.17 |
| Mix 1 | 1.5 × 10⁻⁷ | 71.12 |
| Mix 1 | 1.0 × 10⁻⁷ | 71.06 |
| Mix 2 | 5.0 × 10⁻⁷ | 71.14 |
| Mix 2 | 2.0 × 10⁻⁷ | 74.35 |
위 표에서 데이터 믹스에 따라 2.0 × 10⁻⁷ 또는 5.0 × 10⁻⁷의 학습률이 더 낮은 학습률보다 더 나은 성능을 보임을 보여줍니다. 최종 DPO 모델에서는 2.0 × 10⁻⁷의 학습률을 사용하기로 결정했습니다.
PPO와 DPO 간의 비교. 개발 후반에 PPO와 DPO를 비교하는 더 심층적인 절제 연구도 수행했습니다. 개발 이력에서 DPO 선호도 믹스를 고정하여 RM을 훈련했습니다. 이전 연구들과 동일한 설정을 사용하여, 보상 모델로서 시퀀스 끝(EOS) 토큰에서만 RM의 로짓을 추출했습니다. 또한 보상 스칼라를 출력하는 선형 헤드는 \(N(0,1/\sqrt{d_{\text{model}} + 1})\)에 따라 가중치로 초기화됩니다.
DPO와 PPO 간의 통제된 비교를 위해 DPO 선호도 믹스에서 동일한 프롬프트를 사용했습니다. 보상 모델은 한 번만 훈련되었으며 RM의 성능을 조정하려고 시도하지 않았습니다. 강력한 RM 성능이 RM 특정 벤치마크에서 반드시 PPO의 더 나은 하위 성능으로 이어지지 않기 때문에 RM의 성능을 평가하는 것은 까다로울 수 있습니다.
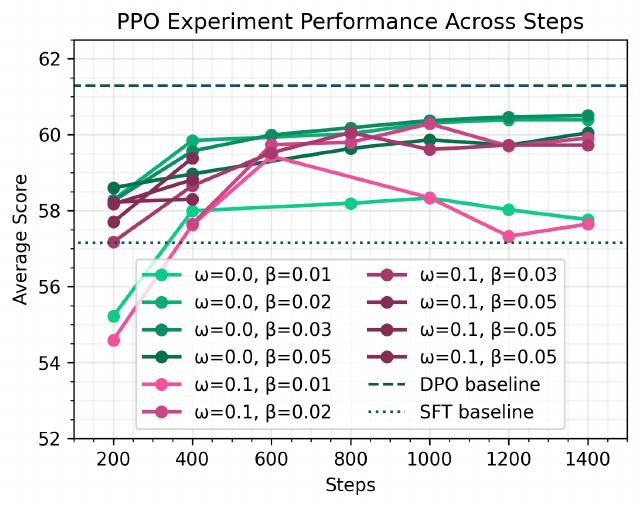
위 그림에서 다양한 학습률 워밍업 비율 ω와 KL 페널티 계수 β를 가진 PPO 실행의 평균 점수를 보여줍니다. PPO는 DPO와 유사한(약간 낮지만) 평균 점수를 얻을 수 있습니다.
주요 발견사항은 다음과 같습니다.
-
PPO는 이 조정되지 않은 설정에서 DPO와 유사한 평균 점수를 얻습니다. 전체적으로 PPO가 이 통제된 설정에서 DPO와 비교 가능한 수준의 성능(약간 낮지만)에 도달할 수 있음을 발견했습니다.
-
PPO는 계산적으로 더 비쌉니다. PPO 런타임은 두 노드를 사용하여 약 28시간인 반면, DPO 런타임은 단일 노드를 사용하여 약 4시간입니다. 더 많은 계산 예산을 사용하거나 더 많은 조정을 수행한다면 PPO의 성능을 더 높일 수 있을 가능성이 충분합니다. 그러나 제한된 자원과 RM 평가의 미묘함을 고려할 때, 선호도 조정에 DPO를 사용하는 것이 더 경제적으로 보입니다. 이어지는 섹션에서 소개될 RLVR에 주로 PPO를 사용하기로 결정했습니다.
DPO 확장을 위한 인프라
70B DPO 훈련을 실행하기 위해 DPO 훈련의 GPU 메모리 사용량을 줄이기 위한 두 가지 핵심 최적화를 구현하는 것이 유용함을 발견했습니다.
-
DPO 로그 확률 캐싱: GPU 메모리 사용량을 줄이기 위해 정규 구현처럼 훈련 중에 참조 DPO 모델을 메모리에 유지하는 대신 초기 모델을 사용하여 데이터셋 전체에서 로그 확률을 미리 계산하고 캐싱합니다. 이 최적화는 참조 모델에 대한 GPU 메모리 할당 필요성을 제거합니다.
-
선택된 시퀀스와 거부된 시퀀스에 대한 별도 순전파: 정규 DPO 구현은 순전파 중에 선택된 시퀀스와 거부된 시퀀스를 연결하여 효과적으로 배치 크기를 두 배로 늘리고 GPU 메모리 요구사항을 증가시킵니다. GPU 메모리를 절약하기 위해 선택된 완성과 거부된 완성에 대해 순전파를 별도로 수행합니다.
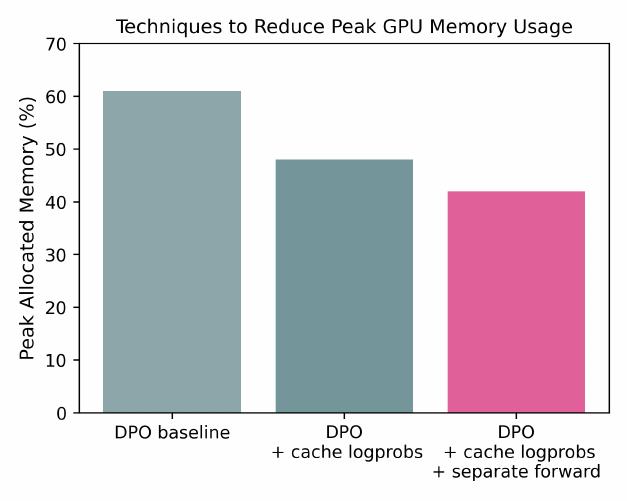
Llama 3.1 모델에서 이 두 기법을 경험적으로 검증했으며 거의 동일한 훈련 손실을 가져온다는 것을 발견했습니다. 예상대로, 위 그림에서 보듯이 8xH100에서 두 기법을 사용할 때 모델이 더 적은 GPU 메모리를 사용합니다.
이러한 최적화 기법들은 대규모 모델의 선호도 조정을 더욱 효율적으로 만들어 줍니다. 참조 모델의 로그 확률을 미리 계산하여 캐싱하는 방식은 메모리 사용량을 크게 줄이면서도 훈련의 정확성을 유지합니다. 또한 선택된 응답과 거부된 응답에 대한 순전파를 분리하는 것은 배치 크기 증가로 인한 메모리 압박을 완화합니다.
이러한 인프라 개선을 통해 70B 규모의 대형 모델에서도 DPO 훈련을 안정적으로 수행할 수 있게 되었으며, 이는 Tülu 3의 성공적인 개발에 중요한 기여를 했습니다. 특히 제한된 GPU 자원 환경에서도 최첨단 성능의 모델을 훈련할 수 있는 실용적인 솔루션을 제공합니다.
검증 가능한 보상을 통한 강화학습
Tülu 3에서는 수학적 문제 해결과 지시 따르기와 같이 검증 가능한 결과를 가진 작업에 대해 언어 모델을 훈련하는 새로운 방법인 Reinforcement Learning with Verifiable Rewards(RLVR)를 소개합니다. RLVR은 기존의 RLHF 목표 함수를 활용하되 보상 모델을 검증 함수로 대체하는 혁신적인 접근법입니다.
위 그림에서 보듯이 RLVR의 핵심 아이디어는 매우 직관적입니다. 정책 모델이 주어진 프롬프트에 대해 완성을 생성하면, 결정론적 검증 함수가 그 답이 올바른지 확인합니다. 답이 검증 가능하게 올바르다면 \(\alpha\)의 보상을, 그렇지 않으면 0의 보상을 제공합니다. 이후 PPO를 사용하여 이 보상에 대해 모델을 훈련합니다.
RLVR은 수학과 검증 가능한 지시 따르기 작업과 같은 검증 가능한 답이 있는 도메인에 적용될 때 GSM8K와 같은 벤치마크에서 목표 지향적인 개선을 보여주면서 다른 작업들에서의 성능을 유지합니다. 이 방법은 기존의 LM 추론 부트스트래핑 접근법의 단순화된 형태로 볼 수 있으며, 실행 피드백을 통한 RL의 더 간단한 형태로도 이해할 수 있습니다. 여기서는 단순히 답 매칭이나 제약 검증을 이진 신호로 사용하여 모델을 훈련합니다.
수학 능력 향상만을 위해 이러한 접근법이 이전 연구에서 사용된 바 있지만, 연구진은 RLVR을 여러 평가로 확장하고 전체 모델 성능을 어떻게 개선할 수 있는지 테스트하여 범용 훈련 파이프라인의 구성 요소로 통합했습니다.
RLVR은 RL 문헌에서 일반적인 간단한 원리를 언어 모델에 적용한 것입니다. 정책은 생성된 응답이 검증 가능하게 올바를 때만 보상을 받습니다. 구체적으로 RLVR은 다음 목표 함수를 최적화합니다.
\[\max_{\pi_\theta} \mathbb{E}_{y \sim \pi_\theta(x)} [R_{\text{RLVR}}(x,y)] = \mathbb{E}_{y \sim \pi_\theta(x)} [v(x,y) - \beta \text{KL}[\pi_\theta(y|x) \| \pi_{\text{ref}}(y|x)]]\]여기서 \(v\)는 검증 가능한 보상 함수입니다. \(v\)는 프롬프트와 완성 쌍 \((x,y)\)를 입력으로 받아 생성된 텍스트 내의 답이 올바른지 확인합니다.
\[v(x,y) = \begin{cases} \alpha & \text{if correct} \\ 0 & \text{otherwise} \end{cases}\]이 목표 함수는 표준 KL 제약 RLHF 목표와 매우 유사하지만, 학습된 보상 모델 대신 보상 함수를 사용한다는 점이 다릅니다. 연구진은 선호도 미세조정 이후에 RLVR로 모델을 훈련하며, PPO 알고리즘을 사용하여 RLVR 목표를 최적화합니다. 파일럿 실험을 바탕으로 \(\alpha = 10\)으로 설정했으며 추가 조정은 하지 않았습니다.
RLVR 데이터
RLVR을 위한 데이터 생성은 이진 검증자를 동반하는 프롬프트를 얻는 것을 포함합니다(즉, 동반하는 검증자 함수 \(v\)와 함께 입력 \(x\)의 집합을 구성하는 것). 연구진은 비교적 직관적인 검증 방법을 가진 두 도메인(수학, 정확한 지시 따르기)과 세 가지 평가(GSM8K, MATH, IFEval)에 초점을 맞췄으며, 더 복잡한 검증자는 향후 연구로 남겨두었습니다.
실제로 답 추출과 검증 방법은 도메인에 따라 달라집니다. 연구진은 세 가지 훈련 프롬프트와 검증자 소스를 사용했습니다.
GSM8K: GSM8K 훈련 세트를 사용했습니다. 각 샘플을 평가 중 사용되는 표준 8-shot 프롬프트로 증강하여 모델이 체인 오브 소트를 사용하도록 장려한 다음, 생성된 최종 숫자를 추출하여 정답 라벨과 비교하여 정확성을 판단했습니다.
MATH: MATH 훈련 세트를 사용했습니다. GSM8K와 유사하게, 각 샘플을 평가 중 사용되는 표준 3-shot CoT 프롬프트로 증강하여 모델이 평가 중 사고 연쇄를 생성하도록 장려한 다음, 답을 추출하고 'flex' MATH 평가 로직에 따라 정확성을 판단했습니다.
IFEval: Tülu 2 SFT 믹스에서 지시를 무작위로 샘플링하고 Zhou et al. (2023)의 분류법에서 제약을 결합했습니다. 완성이 제약을 만족하는지 검증할 수 있는 각 제약 템플릿에 대한 검증 함수를 가지고 있습니다.
이러한 프롬프트와 검증 함수가 주어지면, 연구진은 이러한 검증 가능한 보상에 대해 Proximal Policy Optimization(PPO)을 통해 모델을 훈련했습니다. 모든 프롬프트를 결합하여 약 30,000개의 정답 라벨이 있는 프롬프트 혼합을 만들었습니다.
| 데이터셋 | 프롬프트 수 |
|---|---|
| GSM8K | 7,473 |
| MATH | 7,500 |
| IFEval | 15,000 |
| 총계 | 29,973 |
RLVR 레시피와 분석
구현 세부사항: RL과 RLHF는 훈련 안정성에 상당한 영향을 미칠 수 있는 많은 미묘한 구현 세부사항을 가지고 있습니다. PPO를 사용하여 검증자에 대해 모델을 훈련할 때, 연구진은 Huang et al. (2024a)의 효과적인 구현 세부사항을 적용했습니다.
-
일반 RM에서 Value 모델 초기화: RLVR 설정에서 보상 모델로부터 value 모델을 초기화했습니다(Ziegler et al. (2019); Ouyang et al. (2022)의 표준 설정을 따름).
-
Dropout 비활성화: RM과 RL 훈련 중 dropout 확률을 0으로 설정했습니다(Ziegler et al. (2019)와 유사). 이는 정책 모델과 참조 모델의 순전파 중 토큰 로그 확률을 결정론적으로 계산할 수 있게 하여 KL 페널티의 더 정확한 추정을 가능하게 합니다.
-
SFT 데이터셋으로 훈련하고 에포크 간 셔플: Huang et al. (2024a)에서 지적한 바와 같이, PPO는 총 사용 가능한 프롬프트보다 더 많은 에피소드에 대해 훈련할 수 있어 효과적으로 여러 에포크 동안 훈련합니다. RLVR 절제 실험에서는 약 100,000/7,473 ≈ 13 에포크 동안 훈련했습니다. 에포크 사이에 프롬프트를 셔플했습니다.
-
비EOS 페널티: 훈련 중 PPO는 일반적으로 고정된 양의 최대 토큰을 샘플링합니다. 샘플링된 응답이 EOS 토큰으로 끝나지 않으면 -10 페널티를 주어 모델이 항상 응답을 완료하도록 장려했습니다.
-
Advantage 화이트닝/정규화: 표준 PPO 구현 세부사항 문헌에서 수행되는 것처럼, advantage의 평균을 빼고 표준편차로 나누어 정규화했습니다.
연구진은 개발 이력에서 DPO 모델을 RLVR 실험 수행을 위한 초기 모델로 고정했습니다. 여러 실험 세트를 수행했습니다.
-
개별 작업: GSM8K, MATH, IFEval에 각각 베타 값 [0.1, 0.05, 0.03, 0.01] 스위프와 함께 RLVR 레시피를 적용했습니다.
-
Value 모델 초기화 절제: PPO의 value 모델을 1) 일반 보상 모델 또는 2) 고정된 DPO 모델에서 초기화하는 실험을 수행했습니다.
-
RM 점수 절제: RLVR의 한 가지 가능한 구현은 보상 모델의 점수 위에 검증 가능한 보상을 추가하는 것입니다.
-
더 약한 모델에서 시작: 모델의 기본 능력도 혼재 요인입니다. 더 낮은 평균 점수를 가진 SFT 모델을 사용하여 또 다른 실험 세트를 시작했습니다.
달리 명시되지 않는 한, PPO 훈련에 다음 하이퍼파라미터를 사용했습니다.
| 하이퍼파라미터 | 값 |
|---|---|
| 학습률 | 1e-6 |
| 에피소드 수 | 100,000 |
| 배치 크기 | 128 |
| 베타 (KL 계수) | 0.05 |
| 응답 길이 | 512 |
| 온도 | 0.7 |
위 그림은 DPO 체크포인트에서 시작한 GSM8K, MATH, 제약이 있는 프롬프트에서의 RLVR 검증 가능한 보상, KL 발산, 응답 길이를 보여줍니다. 하단 행은 해당하는 하위 테스트 성능을 보여줍니다. RLVR은 훈련 데이터셋에서 더 높은 검증 가능한 보상으로 이어질 수 있습니다. 중요하게도, RLVR은 해당하는 테스트 데이터셋에서도 더 높은 점수로 이어질 수 있지만, 모든 평가에서 평균 점수의 증가는 보장되지 않습니다.
주요 발견사항
RLVR은 목표 도메인에서 성능을 개선할 수 있습니다: 위 그림에서 보듯이 RLVR로 훈련하면 세 가지 설정 모두에서 테스트 성능이 개선됩니다. 모든 경우에서 해당 평가에서 초기 모델을 능가하는 모델을 달성했습니다. 또한 검증 가능한 보상(즉, 훈련 세트에서의 정확성)이 세 가지 설정 모두에서 일관되게 개선되는 것을 확인했습니다.
흥미롭게도 GSM8K와 MATH에서는 더 많은 KL 예산을 사용하는 것이 반드시 검증 가능한 보상의 개선으로 이어지지 않는다는 것을 발견했습니다.
일반 RM에서 RLVR의 Value 함수 초기화가 가장 잘 작동합니다: 다음 그림에서 일반 RM에서 value를 초기화하는 것이 가장 높은 GSM8K 테스트 점수와 더 높은 평균 점수를 얻는다는 것을 보여줍니다. 이는 value 함수가 RLVR 훈련에서 중요한 역할을 한다는 것을 시사합니다.
RM 점수를 사용하지 마십시오: 검증 가능한 보상만 사용하는 것이 보상 모델의 점수를 사용하는 것보다 성능이 우수합니다. 검증 가능한 보상과 RM 점수로 훈련하는 것은 특히 평균 점수에서 더 많은 노이즈를 도입하는 것으로 보입니다.
더 약한 모델에서 시작해도 동일한 검증 가능한 보상으로 수렴할 수 있습니다: SFT와 DPO 모두에서 시작하는 것이 동일한 수준의 검증 가능한 보상으로 이어질 수 있지만, SFT 모델에서 시작하는 것은 동일한 β를 사용할 때 DPO 모델에서 시작하는 것에 비해 더 큰 KL을 발생시킵니다. 이는 SFT 모델이 DPO 모델보다 GSM8K에서 더 멀리 떨어져 있기 때문에 합리적입니다. 그러나 더 강한 모델에서 시작하는 것이 일반적으로 더 나은 테스트 세트 성능으로 이어진다는 것을 발견했습니다.
과최적화가 발생합니다: KL 페널티 β를 낮추면 훈련된 모델이 초기 모델로부터 더 많은 KL을 발생시킵니다. 더 많은 KL 발산이 일반적으로 더 낮은 평균 점수로 이어진다는 것을 관찰했습니다. 예외는 가장 큰 KL이 가장 높은 평균 점수에 해당하는 경우입니다.
RLVR 인프라
PPO 설정은 구현 세부사항에 대한 모범 사례를 따릅니다. 405B 파라미터까지의 모델로 확장할 수 있도록 구현을 활성화하기 위해, 기존 분산 RLHF 프레임워크의 모델 할당 기법도 적용했습니다. 또한 RL 훈련을 비동기화하여 처리량을 가속화했습니다.
최종 8B 보상 모델은 8개의 H100 GPU에서 9시간 동안 훈련되었고, 최종 8B RL 실행은 8개 GPU에서 65시간, 최종 70B RL 실행은 48개 GPU에서 60시간, 최종 405B RL 실행은 256개 GPU에서 46시간이 소요되었습니다. 모든 모델에 대해 실행에서 최종보다 이른 체크포인트를 사용했습니다.
분산 설정: PPO 인프라는 Zero Stage 3를 활용하여 모델과 적용 가능한 옵티마이저 상태를 메모리에 맞춥니다. RLVR에서는 정책 모델, 참조 정책 모델, value 모델의 3개 모델이 있습니다. 정책과 value 모델은 훈련되어야 하지만 참조 정책 모델은 추론만 수행합니다.
종종 추론 시간이 RLHF 인프라의 병목이므로, OpenRLHF에서 수행되는 것처럼 추론을 수행하기 위해 전용 GPU를 할당했습니다. 특히 Ray를 사용하여 vLLM을 통해 PagedAttention을 실행하기 위해 전용 GPU를 할당했습니다. PagedAttention은 가상 메모리와 페이징 기법을 활용하여 GPU 메모리 단편화와 중복 복제를 줄이는 데 도움이 됩니다. 결과적으로 PPO 인프라가 훨씬 더 큰 배치 크기를 사용하여 LLM 추론을 실행하고 추론을 가속화하는 데 도움이 됩니다.
비동기 RL 훈련: 또한 PPO 설정은 비동기 RL 훈련을 사용하여 훈련 효율성을 개선합니다. 기존 PPO 프레임워크는 일반적으로 동기식입니다. 추론 GPU가 먼저 정책 롤아웃 데이터를 수집한 다음, 학습자 GPU가 해당 롤아웃 데이터에 대해 훈련합니다.
연구진의 설정은 추론과 훈련을 위해 GPU를 구체적으로 할당하여 훈련 GPU에서 추론 엔진을 컴파일하고 정책 파라미터의 사본을 저장할 필요를 완화합니다. 또한 추론 계산을 훈련 계산과 동시에 실행하여 GPU 유휴 시간을 줄입니다.
그러나 비동기 RL 훈련은 추론이 훈련이 소비하는 것보다 훨씬 빠르게 데이터를 생성할 수 있는 경우 오래된 데이터를 도입할 수 있어 재현성 문제를 야기할 수 있습니다. 훈련을 더 재현 가능하게 만들기 위해, 설정은 항상 두 번째로 최신의 추론 데이터를 사용하여 정책을 훈련합니다.
최종 실험 결과
위의 결과를 바탕으로, 연구진은 결합된 검증 가능한 프롬프트 세트를 사용하여 최종 RLVR 실행을 수행했고, 이전 섹션의 최고 DPO 모델을 시작점으로 사용했습니다. 구체적으로, 8B 규모에서는 최고 전체 DPO 모델과 훈련 중 IFEval 페르소나 데이터가 혼합된 최고 모델을 테스트했고, 70B 규모에서는 최고 전체 DPO 모델을 사용했습니다.
하이퍼파라미터의 경우, 8B 모델에서는 이전 8B RL 개발 실행을 바탕으로 더 높은 KL 페널티 계수(최대 0.15)를 테스트했습니다. 70B 모델에서는 이전 70B RL 개발 실행을 바탕으로 1 × 10⁻⁷ 학습률, 0.1 워밍업 비율, 2048 응답 길이, 400,000 에피소드, 640 효과적 배치 크기, β = 0.7을 사용했습니다.
최고 DPO 모델과 동일한 데이터셋(Tülu 3 8B 선호도 혼합)에서 훈련된 보상 모델에서 value 모델을 초기화했습니다. 100 훈련 단계(70B의 경우 40)마다 모델을 평가했고, MATH와 IFEval에서 최고 전체 성능을 가진 체크포인트를 최종 8B 모델로 선택했습니다.
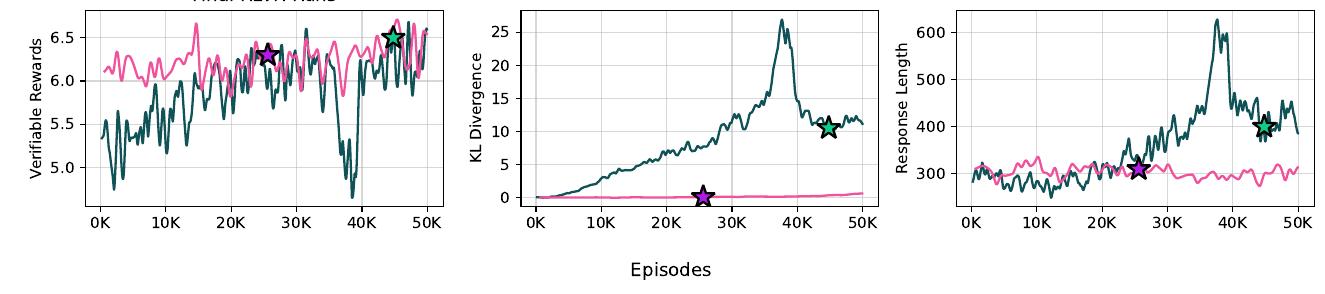
위 그림은 최종 RLVR 실행의 GSM8K 훈련 세트에서 에피소드별 보상, KL 발산, 평균 응답 길이를 보여줍니다. 8B와 70B 체크포인트를 선택한 지점을 각각 녹색과 보라색 별로 표시했습니다.
최종 성능을 DPO 시작점과 Llama 3.1과 비교한 결과는 다음과 같습니다.
| 모델 크기 | 8B | 70B |
|---|---|---|
| 벤치마크 | Llama 3.1 Inst. / Tülu 3 DPO / Tülu 3 RLVR | Llama 3.1 Inst. / Tülu 3 DPO / Tülu 3 RLVR |
| MMLU | 62.2 / 64.4 / 64.8 | 73.4 / 75.9 / 76.0 |
| MATH | 42.5 / 42.0 / 43.7 | 56.4 / 62.3 / 63.0 |
| GSM8K | 83.4 / 84.3 / 87.6 | 93.7 / 93.5 / 93.5 |
| IFEval | 80.6 / 81.1 / 82.4 | 88.0 / 82.6 / 83.2 |
RLVR은 8B 규모에서 상당한 개선을 가져와 MATH, GSM8K, IFEval 모두를 개선했습니다. 실제로 일부 8B 실행에서는 GSM8K 점수 89.4%와 IFEval 점수 84.8%까지 달성할 수 있었습니다(비록 이러한 모델들은 다른 메트릭에서 더 나쁜 성능을 보여 전체 평균을 끌어내렸지만).
70B 규모에서는 IFEval과 MATH에서 더 적은 개선을 관찰했고, GSM8K에서는 개선이 없었는데, 이는 이미 포화에 가깝기 때문입니다(93.5%). 놀랍게도 70B 실행은 매우 낮은 KL 발산을 보여 실행 기간 동안 1 미만을 유지했는데, 이는 아마도 더 낮은 학습률 때문일 것입니다.
Tülu 3 평가 프레임워크
Tülu 3 연구진은 모델 평가를 위한 포괄적인 프레임워크를 설계했습니다. 이 프레임워크는 세 가지 핵심 목표를 달성하기 위해 구축되었습니다. 1) 재현 가능한 평가 수행, 2) 개발에 사용된 특정 벤치마크가 아닌 미공개 작업에 대한 모델의 일반화 능력 평가, 3) 다양한 모델에 공정한 평가 설정(예: 템플릿 및 프롬프팅 전략) 제공입니다.
이러한 목표에 따라 프레임워크는 재현 가능한 평가를 위한 오픈 평가 툴킷, 별도의 개발 및 미공개 평가가 포함된 지시 조정 모델의 핵심 기술 평가 스위트, 그리고 다양한 모델에 대한 실험을 바탕으로 한 평가 스위트에서의 권장 설정으로 구성됩니다. 이러한 권장 설정을 Tülu 3 평가 체제라고 부르며, 아래 표에 요약되어 있습니다.
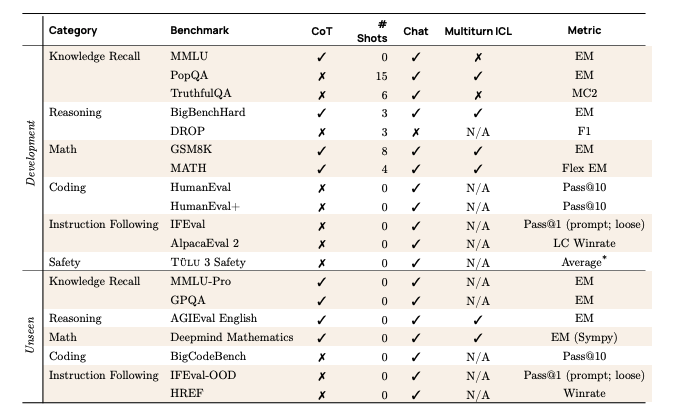
앞선 섹션에서 설명한 바와 같이, 평가 스위트를 개발 세트와 미공개 세트로 분할했습니다. 전자는 모델 개발에 사용되고, 후자는 최종 모델 평가에만 사용됩니다. 이러한 설정은 훈련 데이터 오염 제거 노력과 함께 개발 중 집중한 각 핵심 기술에 대한 모델의 일반화 능력을 더 공정하게 평가할 수 있게 합니다. 그러나 다른 모델들과의 비교에서는 폐쇄형 모델이 평가 스위트에서 훈련하지 않았다고 단정할 수 없으며, 따라서 미세조정 데이터를 공개적으로 공개하지 않은 모델들에 대해서는 명확한 판단을 내릴 수 없습니다.
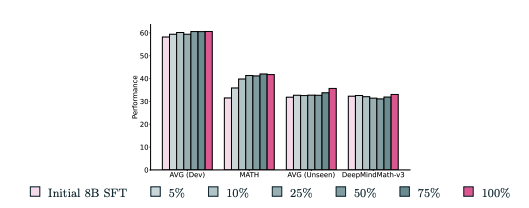
위 그림은 서로 다른 백분위 임계값(5%, 10%, 25%, 50%)에서 다양한 성능 메트릭(예: AVG (Dev), MATH, AVG (Unseen), DeepMindMath-v3)을 보여주는 막대 차트입니다. 이는 선호도 데이터셋 크기 확장, 특히 고유 프롬프트 수가 개발 및 미공개 평가에서 하위 DPO 모델 성능에 미치는 영향을 나타냅니다.
오픈 언어 모델 평가 시스템 (OLMES)
평가를 더욱 표준화되고 재현 가능하게 만들기 위해, 연구진은 이 연구에서 평가를 수행하는 데 사용된 코드베이스를 공유하고 있습니다. OLMES 평가 시스템은 다음을 지원합니다.
- Eleuther AI LM Evaluation Harness의 기존 작업을 활용한 광범위한 모델과 작업 지원
- 각 작업에 대한 유연한 구성 옵션
- 이 연구에서 사용된 특정 작업 공식에 대한 직접 접근(OLMo 및 OLMES 표준과 같은 이전 작업에서도 사용됨)
- 모델 예측, 신뢰도 등의 분석을 위한 상세한 인스턴스 수준 출력 데이터
예를 들어, MMLU-Pro에 대한 Llama-3.1-8B-Instruct 결과를 재현하려면 "olmes –task mmlu_pro::tulu3 –model llama3.1-8b-instruct"와 같이 실행하면 됩니다.
Tülu 3 평가 스위트 - 개발
Tülu 3 Eval의 개발 파티션에 대한 평가 설정은 현재 문헌의 기존 관행과 개발 중 얻은 통찰을 바탕으로 설계되었습니다. 적절한 경우, 작업의 특성에 따라 평가 설정을 조정하고 아래에 설명된 바와 같이 답변 추출 및 비교 접근법을 견고하게 만들기 위해 추가적인 주의를 기울였습니다.
MMLU (Hendrycks et al., 2020)는 질문에 답하는 데 필요한 추론 기술 유형과 관련하여 이질적입니다. 기본적인 사실 회상이 필요한 인스턴스부터 논리적 추론과 문제 해결 기술을 요구하는 인스턴스까지 포함하고 있습니다. 연구진은 모델이 질문에 답하기 전에 추론을 "요약"하도록 요청하는 제로샷 체인 오브 소트 설정을 설계했습니다. 다양한 CoT 설정 중에서 모델에게 "단계별로" 생각하도록 프롬프트하는 것과 CoT를 사용하지 않는 것을 포함하여, 이 프롬프트가 테스트된 모델들에서 표준 5샷 다중 선택 설정에 비해 체계적인 성능 향상을 가져오고 CoT가 도움이 되는 주제(지식 범주) 수를 최대화한다는 것을 발견했습니다. 이는 "요약" 프롬프트가 벤치마크의 이질성을 다루는 효과적인 전략임을 나타냅니다. MMLU의 모든 주제에 대한 매크로 평균을 최종 작업 메트릭으로 계산합니다.
PopQA (Mallen et al., 2022)는 언어 모델이 롱테일 엔티티에 대한 정보를 잊어버리는 경향을 평가하는 엔티티 중심 질문 답변 벤치마크입니다. 데이터셋 논문에서 권장하는 대로 15샷 설정에서 모델을 프롬프트하며, 추가 지시 없이 각 QA 시연을 다른 대화 턴에서 제시하는 설정(이후 Multiturn ICL이라고 함)을 사용하고, 탐욕적 샘플링을 사용하여 모델 예측을 얻습니다.
TruthfulQA (Lin et al., 2021)는 일반적인 오해로 인해 인간이 잘못 답하는 경향이 있는 질문들을 포함합니다. 평가되는 모델에게 여러 정답을 포함하는 질문과 옵션이 제시되는 이 벤치마크의 다중 선택 버전(MC2 설정)을 사용합니다.
HumanEval (Chen et al., 2021)과 HumanEval+ (Liu et al., 2023)는 독스트링이 주어진 상태에서 Python 코드를 완성하는 모델의 능력을 평가합니다. HumanEval+는 추가 테스트를 통해 원래 HumanEval 벤치마크보다 더 엄격한 평가 절차를 사용합니다. 온도 0.8에서 모델로부터 샘플을 사용하고 pass@10을 평가 메트릭으로 사용합니다.
GSM8K (Cobbe et al., 2021)는 초등학교 수학 문장 문제를 포함합니다. Wei et al. (2022b)의 8샷 체인 오브 소트 프롬프트를 멀티턴 ICL 평가용으로 포맷하여 사용합니다. 탐욕적 샘플링을 사용하여 모델 응답을 얻고 모델 응답의 마지막 숫자를 예측 답변으로 추출합니다.
MATH (Hendrycks et al., 2021)는 대수학과 미적분학과 같은 다양한 범주에 걸친 수학 경시대회 문제들을 포함합니다. Lewkowycz et al. (2022)의 4샷 멀티턴 설정과 CoT를 멀티턴 ICL용으로 포맷하여 사용하고, 모델 완성에 탐욕적 샘플링을 사용합니다. 예측의 정확성을 판단하기 위해 세 가지 다른 방식으로 답변을 추출하려고 시도하는 'flex' 체계를 사용합니다. (1) minerva 형식 따르기; (2) ' < ans > '의 마지막 인스턴스 찾기; (3) 마지막 두 '$' 태그 사이의 텍스트 가져오기. 이는 개발 중 발견한 문제 때문인데, 퓨샷 예시에도 불구하고 모델들이 종종 올바른 출력 형식을 따르지 않아 다양한 답변 추출 전략이 필요했습니다. minerva 형식만 사용하는 것에서 'flex' 전략으로 이동하면 때때로 보고된 점수가 최대 10점까지 향상될 수 있어, 이러한 유연한 전략의 필요성을 강조합니다. 하위 섹션들에 대한 매크로 평균을 계산하여 최종 작업 메트릭을 얻습니다.
BigBench-Hard (Suzgun et al., 2022)는 모델이 단계별 추론으로부터 이익을 얻는 도전적인 추론 문제들을 포함합니다. 원래 논문에서 설명된 설정을 따라 3샷 CoT 프롬프트를 멀티턴 ICL용으로 포맷하여 사용합니다. 모델 예측을 얻기 위해 탐욕적 샘플링을 사용합니다.
DROP (Dua et al., 2019)는 이산적 추론이 필요한 독해 작업입니다. Llama 3에서 사용된 설정을 따라 훈련 분할에서 3개의 무작위 퓨샷 예시를 추출하고, 모델 예측을 얻기 위해 탐욕적 샘플링을 사용합니다.
IFEval (Zhou et al., 2023)는 각 지시가 프로그래밍적으로 출력이 해당 제약을 만족하는지 검증할 수 있는 제약에 해당하는 설정에서 모델의 지시 따르기 능력을 평가합니다. 데이터셋의 지시에 대해 탐욕적 디코딩을 사용하여 모델 출력을 생성하고, 느슨한 평가 설정에서 제약 만족의 프롬프트 수준 정확도를 측정합니다.
AlpacaEval 2 (Dubois et al., 2024)는 LM의 실제 인간 사용을 반영하는 소스에서 가져온 프롬프트 세트를 포함하며, 더 긴 답변이 불공정하게 선호되는 것을 피하기 위한 추가 길이 제어와 함께 모델 출력을 GPT-4 turbo 응답과 비교합니다. Ivison et al. (2023)을 따라 최대 8,192 토큰 길이까지 탐욕적 디코딩을 사용하여 응답을 생성합니다.
안전성 평가
Han et al. (2024)과 Jiang et al. (2024)를 따라 다음 벤치마크를 사용하여 안전성 평가 스위트를 정의합니다. 이러한 벤치마크들은 각각 모델이 안전하지 않은 요청에 대해 거부하는지, 그리고 XSTest와 WildJailbreak의 경우 추가적으로 양성 요청에 대해 준수하는지를 평가합니다. 각 벤치마크의 프롬프트에 대해 탐욕적 샘플링을 사용하여 모델 응답을 얻고, 적절한 거부 또는 준수에서의 정확도를 계산합니다. 모든 벤치마크에 대한 점수의 매크로 평균을 최종 안전성 평가 메트릭으로 보고합니다.
XSTest (Röttger et al., 2023)는 200개의 안전하지 않은 프롬프트와 250개의 안전하지만 표면적으로 안전하지 않은 프롬프트와 유사한 프롬프트로 구성됩니다. 이러한 프롬프트들은 안전하지 않은 프롬프트와 유사한 어휘를 사용합니다. 범주에는 동음이의어, 비유적 언어, 안전한 대상, 안전한 맥락, 정의, 실제 차별/무의미한 그룹, 무의미한 차별/실제 그룹, 역사적 사건, 공개 프라이버시, 허구적 프라이버시가 포함됩니다. WildGuard (Han et al., 2024)가 응답을 거부 또는 준수로 분류하는지에 따라 전체 정확도 점수를 보고합니다.
HarmBench (Mazeika et al., 2024)에서는 기능적 및 의미적 범주로 분류된 321개의 유해한 프롬프트 하위 집합을 평가했습니다. 기능적 범주에는 두 가지 유형의 행동이 포함됩니다. AdvBench 및 TDC 2023 Red Teaming Track 데이터셋과 같은 기존 유해 행동 데이터셋을 모델로 한 표준 행동과 저작권 콘텐츠 처리를 테스트하는 저작권 행동입니다. 의미적 범주는 사이버 범죄, 무단 침입, 화학/생물학적 무기 또는 약물, 저작권 위반, 잘못된 정보/허위 정보, 괴롭힘/괴롭힘, 불법 활동, 일반적 피해의 7가지 유형의 유해 행동으로 구성됩니다. WildGuard를 사용하여 유해한 프롬프트에 대한 모델의 거부를 평가합니다.
Do-Anything-Now (Shen et al., 2024b)는 DAN의 탈옥 템플릿을 HarmBench의 유해 행동과 결합하여 생성된 탈옥 프롬프트로 구성되며, 테스트를 위해 300개를 하위 샘플링합니다. WildGuard 분류기를 사용하여 정확도를 보고합니다.
JailbreakTrigger (Huang et al., 2024b)는 13가지 서로 다른 탈옥 공격 방법을 기반으로 한 프롬프트를 포함합니다. 총 400개의 예시로 구성된 데이터셋은 "나쁜 행동에 대한 질문"과 "독성 콘텐츠 생성 지시"의 두 범주로 균등하게 분할됩니다. 이 데이터셋은 LLM의 방어 효과를 평가하고 탈옥 시나리오에서 응답의 독성을 측정하는 역할을 합니다. 보고된 메트릭은 WildGuard로 측정된 RTA입니다.
WildJailbreakTest (Jiang et al., 2024)는 적대적 양성 쿼리(210개 예시)와 적대적 유해 쿼리(2000개 예시)에 대한 하위 집합을 포함하는 적대적 평가 세트입니다. 적대적 양성 쿼리는 모델의 과장된 안전 행동을 측정하는 데 사용되고, 적대적 유해 쿼리는 적대적 공격에 대한 모델의 보호 장치를 측정하는 데 사용됩니다. WildGuard를 사용하여 두 범주 모두에 대해 RTA를 측정합니다. 양성 쿼리의 경우 RTA는 낮을수록 좋고(↓), 유해 쿼리의 경우 RTA는 높을수록 좋습니다(↑).
WildGuardTest (Han et al., 2024)는 프롬프트 피해, 응답 피해, 응답 거부 분류 작업에 대한 1725개 항목을 포함합니다. 55%는 바닐라 프롬프트이고 45%는 적대적입니다. 프롬프트는 적대적 합성 데이터와 실제 사용자-LLM 상호작용을 기반으로 수집되었습니다. WildGuard를 사용하여 RTA를 보고합니다.
다음 표들은 유사한 크기의 오픈 가중치 모델들과 비교한 Tülu 3 8B 및 70B 모델의 벤치마크별 안전성 점수 분석을 보여줍니다.
| 벤치마크 | Llama 3.1 8B Instruct | Ministral 8B Instruct | Qwen 2.5 7B Instruct | Tülu 3 8B SFT | Tülu 3 8B DPO | Tülu 3 8B |
|---|---|---|---|---|---|---|
| HarmBench | 82.8 | 53.4 | 84.1 | 98.4 | 94.4 | 94.7 |
| XSTest | 92.7 | 85.6 | 91.8 | 90.4 | 92.4 | 93.3 |
| WildGuardTest | 86.2 | 68.1 | 85.0 | 99.2 | 98.9 | 98.5 |
| Jailbreaktrigger | 78.8 | 63.3 | 71.0 | 95.8 | 87.0 | 85.5 |
| DoAnythingNow | 45.0 | 16.0 | 61.7 | 88.3 | 69.7 | 62.0 |
| WildjailbreakTest | 65.6 | 50.7 | 56.2 | 86.7 | 81.1 | 78.8 |
| Overall | 75.2 | 56.2 | 75.0 | 93.1 | 87.2 | 85.5 |
| 벤치마크 | Llama 3.1 70B Instruct | Qwen 2.5 72B Instruct | Hermes 3 Llama 3.1 70B | Nemotron Llama 3.1 70B | Tülu 3 70B SFT | Tülu 3 70B DPO | Tülu 3 70B |
|---|---|---|---|---|---|---|---|
| HarmBench | 80.6 | 86.3 | 54.7 | 84.4 | 98.8 | 97.8 | 97.8 |
| XSTest | 87.1 | 93.6 | 89.3 | 92.0 | 91.1 | 94.9 | 92.4 |
| WildGuardTest | 81.3 | 93.1 | 66.6 | 84.9 | 99.1 | 99.2 | 98.9 |
| Jailbreaktrigger | 71.0 | 89.8 | 56.3 | 60.5 | 95.3 | 87.0 | 86.7 |
| DoAnythingNow | 80.0 | 93.3 | 26.7 | 36.3 | 93.7 | 69.0 | 67.7 |
| WildjailbreakTest | 59.2 | 66.0 | 53.8 | 56.1 | 88.6 | 86.3 | 86.2 |
| Overall | 76.5 | 87.0 | 57.9 | 69.0 | 94.4 | 89.0 | 88.3 |
Tülu 3 평가 스위트 - 미공개
미공개 평가 스위트의 경우, 작업 공식은 개발 스위트와는 독립적인 설계 과정을 통해 결정되었습니다. 미공개 스위트의 한 가지 목표는 현실적인 사용과 밀접하게 일치하는 방식으로 지시 조정 모델을 평가하는 것입니다. 구체적으로 다음과 같은 일반적인 원칙을 따릅니다.
- 인간이 모델과 상호작용하는 방식과 유사하게 작업을 공식화합니다. 예를 들어, 대화로 제시된 퓨샷 예시나 모델이 "어떻게" 생각해야 하는지에 대한 정확한 체인 오브 소트 예시를 피합니다.
- 맥락을 설정하고, 간결한 추론을 장려하며, 최종 답변이 어떻게 포맷되어야 하는지 명시하는 명확한 지시로 모델을 프롬프트합니다.
- 지시에 의해 암시된 구문을 정확히 따르지 않는 모델에 대한 페널티를 피하기 위해 답변 추출 및 골드 답변과의 비교에 합리적인 휴리스틱을 적용합니다(광범위한 기존 기준 모델의 출력을 검토한 결과를 바탕으로).
연구진은 먼저 탐색적 모델들(Tülu 3 이전의 지시 조정 모델들)을 사용하여 개발 스위트의 일부 작업에 이러한 원칙들을 적용했습니다. 탐색적 모델들에서 위의 원칙들을 따르는 것, 특히 인간 사용에 더 일치하는 것이 일반적으로 성능을 저하시키지 않으며 종종 대부분의 모델이 더 나은 성능을 발휘할 수 있게 한다는 것을 발견했습니다(예를 들어, 퓨샷 예시를 제거하는 경우에도). 이를 바탕으로 개발 작업의 공식을 업데이트하지는 않았지만, 미공개 작업을 공식화할 때 이러한 원칙들을 적용했습니다.
Tülu 3 미공개 스위트의 작업 공식은 다음과 같습니다. 여러 하위 작업을 포함하는 모든 벤치마크에 대해 일관성을 위해 하위 작업들의 평균(즉, "매크로" 평균)을 계산합니다.
AGIEval English (Zhong et al., 2024)는 AGIEval 벤치마크의 영어 언어 하위 집합을 포함하며, 구체적으로 aqua-rat, logiqa-en, lsat-ar, lsat-lr, lsat-rc, sat-en, sat-math, gaokao-english와 같은 다중 선택 작업들을 포함합니다. 패시지에 대한 접근 없이는 일반적으로 심각하게 명세가 부족한 질문들이므로 sat-en-without-passage 작업은 포함하지 않습니다. 간결한 추론을 장려하고 명확하게 명시된 답변 선택으로 끝나는 간단한 "제로샷 CoT" 프롬프트를 사용하여 작업을 공식화합니다.
모델의 답변 선택은 먼저 요청된 형식에 매칭하고, 형식이 정확히 따라지지 않은 경우 대체 패턴을 사용하여 추출됩니다. 구체적으로, 먼저 프롬프트에 표시된 정확한 구문("Therefore, the answer is [ANSWER]")을 찾고 마지막 매치를 가져옵니다. 실패하면 "answer is [ANSWER]" 또는 "answer: [ANSWER]"와 같은 더 부드러운 변형들의 시퀀스를 찾고, 그것도 실패하면 괄호 안의 마지막 문자를 찾고, 그것도 실패하면 마지막 독립적인 대문자를 찾습니다.
MMLU-Pro (Wang et al., 2024b)는 MMLU 데이터셋의 10-way 다중 선택 확장 버전입니다. AGIEval 설정에서 사용한 것과 본질적으로 동일한 프롬프트와 답변 추출을 사용하되, 답변 선택의 수에 맞게 조정합니다. 연구진의 공식이 훨씬 짧고, 더 현실적이며, 사용자가 만들기 더 쉬움에도 불구하고 전통적인 5샷 CoT 프롬프트(예: Llama 3.1 평가에서 사용됨)만큼 효과적임을 일반적으로 발견했습니다.
다음 표는 탐색적 모델들에서 MMLU-Pro를 평가할 때 연구진의 0샷 CoT 프롬프트와 Llama3.1 평가에서 사용된 5샷 프롬프트를 비교한 결과입니다.
| 모델 | Llama 3.1 프롬프트 | 연구진 프롬프트 |
|---|---|---|
| Gemma 2 9B Inst | 51.6 | 52.6 |
| Gemma 2 9B Inst-SimPO | 52.6 | 51.8 |
| Llama 3.1 8B Inst | 49.2 | 48.7 |
| Llama 3.2 3B Inst | 39.1 | 39.7 |
| Ministral 2410 8B Inst | 43.8 | 44.3 |
| OLMo 0724 7B Inst | 26.1 | 22.9 |
| OLMoE 0924 1B 7B Inst | 20.7 | 20.3 |
| Qwen 2.5 7B Inst | 56.2 | 54.2 |
| Tulu 2 DPO 7B | 25.4 | 22.2 |
GPQA (Rein et al., 2023)는 생물학, 물리학, 화학 분야의 도메인 전문가들이 작성한 매우 도전적인 다중 선택 질문들의 집합입니다. AGIEval과 동일한 제로샷 프롬프트와 답변 추출을 사용합니다.
다음 표는 GPQA에서 연구진의 0샷 CoT 프롬프트와 Llama3.1에서 사용된 프롬프트를 비교한 결과입니다.
| 모델 | Llama 3.1 프롬프트 | 연구진 프롬프트 |
|---|---|---|
| Gemma 2 9B Inst | 35.7 | 35.5 |
| Gemma 2 9B Inst-SimPO | 35.0 | 35.7 |
| Llama 3.1 8B Inst | 29.5 | 29.5 |
| Llama 3.1 70B Inst | 46.2 | 44.0 |
| Llama 3.2 3B Inst | 33.5 | 27.7 |
| Ministral 2410 8B Inst | 31.0 | 31.5 |
| OLMo 0724 7B Inst | 27.2 | 27.9 |
| OLMoE 0924 1B 7B Inst | 24.6 | 24.8 |
| Qwen 2.5 7B Inst | 32.1 | 36.8 |
| Tulu 2 DPO 7B | 28.4 | 27.5 |
Deepmind Mathematics (Saxton et al., 2019)는 수학적 및 대수적 추론 기술을 테스트하는 56개 범주의 수학 질문 데이터셋입니다. 연구진은 작업의 맥락을 설정하고, 답변에 대해 예상되는 형식(예: 거듭제곱에 대한 "x**2")을 설명하며, 각 범주에 대해 답변 형식을 명시하기 위한 세 가지 예시 답변을 포함하는 "제로샷 CoT" 프롬프트를 고안했습니다. 사용된 프롬프트와 답변 추출 휴리스틱은 탐색적 모델들의 예시 출력을 검토하여 개선되었습니다.
다음 표에서 보듯이, 실제 사용에 맞춘 평가 원칙을 적용하는 것("채팅" 버전)이 기본 모델 평가에서 적응된 퓨샷 예시를 사용하는 설정("기본 적응")보다 종종 더 나은 성능을 보입니다.
| 모델 | 기본 적응, 맥락 내 예시 | CoT 프롬프트 |
|---|---|---|
| Gemma 2 9B Inst | 18.0 | 45.9 |
| Gemma 2 9B Inst-SimPO | 19.3 | 45.3 |
| Llama 3.1 8B Inst | 20.0 | 39.4 |
| Llama 3.2 1B Inst | 11.6 | 13.1 |
| Llama 3.2 3B Inst | 19.2 | 32.6 |
| Ministral 2410 8B Inst | 18.8 | 36.7 |
| OLMo 0724 7B Inst | 3.2 | 5.8 |
| OLMoE 0924 1B 7B Inst | 9.0 | 4.2 |
| Qwen 2.5 7B Inst | 21.2 | 54.7 |
| Tulu 2 DPO 7B | 9.6 | 6.0 |
| Llama 3.1 Tulu 2 8B | 21.7 | 13.6 |
| Llama 3.1 Tulu 2 DPO 8B | 18.6 | 14.5 |
BigCodeBench (Zhuo et al., 2024)는 코딩 도전 과제들의 집합입니다. 연구진은 총 1140개 중 148개 인스턴스의 "하드 서브셋"에 초점을 맞추고, 각 작업의 "지시" 공식과 "보정된" 점수를 사용합니다. 원래 리더보드에서 사용된 설정을 구현에 따라 사용합니다.
새로운 평가: IFEval-OOD
LLM의 정확한 지시 따르기 능력을 테스트하고 IFEval에 포함된 25개 제약을 넘어서는 제약을 따를 수 있는지 확인하기 위해, 연구진은 IFEval-OOD(IFEval Out-of-Distribution)를 개발했습니다. IFEval-OOD는 아래 표의 예시와 같이 6개의 광범위한 범주에 걸쳐 52개의 제약으로 구성됩니다.
| 지시 그룹 | 지시 설명 | 개수 |
|---|---|---|
| person_names | 응답에서 최소 {N}개의 서로 다른 인물 이름을 언급하세요. | - |
| format emoji | 모든 문장 끝에 이모지를 사용하세요. | - |
| ratio stop_words | 불용어가 응답의 전체 단어 중 {percentage}% 이하가 되도록 하세요. | - |
| sentence keyword | 응답의 {N}번째 문장에 키워드 {keyword}를 포함해야 합니다. | - |
| words alphabet | 응답의 각 단어는 알파벳의 다음 문자로 시작해야 하며, 'Z' 다음에는 'A'로 돌아갑니다. | - |
| custom csv_special_character | CSV 데이터 생성: 열 이름은 ["ProductID", "Category", "Brand", "Price", "Stock"]이고, 데이터는 쉼표로 구분되어야 합니다. 14행을 생성하세요. 특수 문자를 포함하는 필드 하나를 추가하고 이를 큰따옴표로 묶으세요. | - |
제약의 일부는 연구자 그룹에게 제약 아이디어를 요청하여 소싱되었고, 다른 것들은 이 논문의 저자들이 작성했습니다. 6개 범주 중 하나("custom")는 특정 하위 기술을 다루기 위해 수동으로 작성된 검증 가능한 프롬프트로 구성됩니다. 나머지 5개 범주의 경우, 검증 가능한 제약이 WildChat의 미공개 프롬프트 10개와 결합되었습니다.
최종 프롬프트를 선택하기 위해, 이러한 제약된 프롬프트들은 품질과 제약과의 호환성에 대해 인간 주석을 받았습니다(예를 들어, 이름이 전혀 포함되지 않은 한 문장 참조 텍스트를 의역하라는 프롬프트는 응답에서 최소 23개의 서로 다른 인물 이름을 언급하라는 제약과 호환되지 않을 것입니다). 제약 커버리지를 보장하기 위해, 최소 5개의 선택된 프롬프트가 없는 제약들에는 추가 미공개 WildChat 프롬프트가 수동으로 쌍을 이뤘습니다.
연구진의 평가 데이터셋은 기존 IFEval 제약에 대한 과적합과 제약 따르기 능력을 구별하기 위해 제약 유형의 광범위한 커버리지를 강조합니다.
새로운 평가: HREF
연구진은 언어 모델의 지시 가능성에 대한 자동 평가인 HREF(Human Reference-guided Evaluation of instruction Following)를 구축했습니다. HREF는 언어 모델이 일반적으로 훈련받는 11개의 지시 따르기 작업에 초점을 맞춥니다. 브레인스토밍, 개방형 QA, 폐쇄형 QA, 추출, 생성, 재작성, 요약, 분류, 수치 추론, 다중 문서 합성, 사실 확인입니다.
연구진은 전문 지시 조정 데이터 생성자들로부터 이러한 범주에서 고품질의 인간 작성 프롬프트와 응답을 얻었고, 신뢰할 수 있는 자동 평가 절차를 개발했습니다. AlpacaFarm을 따라 고정된 기준 모델에 대한 승률을 평가 메트릭으로 사용합니다. 그러나 AlpacaFarm보다 벤치마크에 더 많은 작업이 있고, 인간 작성 참조에 접근할 수 있기 때문에, 승률 계산에 사용되는 설정이 새로운 평가에 직접 적용되지 않을 수 있다고 가정했습니다.
따라서 다양한 승률 계산 방법을 실험했고, 여러 차원에 따른 세부사항을 다음과 같이 정리했습니다.
- LM 판단자 선택: GPT-4, GPT-4 turbo, 그리고 7B 및 70B 크기의 Llama 3.1-Instruct 모델을 LM 판단자로 시도했습니다.
- LM-as-a-Judge vs. 인간 참조와의 직접 비교: AlpacaFarm에서 GPT-4 Turbo와 같은 대규모 언어 모델을 사용하는 것이 응답이 짧고 사실적일 것으로 예상되는 작업에는 적절하지 않을 수 있습니다. 이 설정을 더 간단한 임베딩 모델(RoBERTa-Large)에 따라 대상 및 기준 모델의 응답을 인간 작성 참조와 유사성을 직접 비교하는 것과 비교했습니다.
- LM-as-a-Judge로 평가할 때 인간 작성 참조 사용: 인간 작성 참조에 접근할 수 있으므로, LM 판단자를 프롬프트할 때 이를 추가 맥락으로 포함하는 실험을 했습니다.
평가 설정에 대한 결정을 내리기 위해, 평가 데이터셋의 하위 집합에서 가져온 지시를 사용하여 프롬프트될 때 16개 모델의 다양한 세트에서 응답을 비교하는 인간 판단을 수집했습니다. 각 모델 응답 쌍당 4개의 인간 판단을 수집하고, 각 평가 설정의 다수 인간 판단과의 일치를 비교했습니다. 해당 작업 범주에 대한 최적의 설정을 식별하기 위해 각 작업 범주에 대해 이 절차를 반복했습니다.
최종 평가 설정 요약: 고려한 모델 풀 중에서 인간 판단자와의 일치가 가장 높았던 Llama 3.1 70B Instruct를 LM 판단자로 사용했습니다. 사용한 기준 모델은 Llama 3.1 405B Instruct입니다. LM을 판단자로 사용하는 것이 개방형 QA와 사실 확인을 제외한 모든 하위 작업에서 (임베딩 기반 방법과 비교하여) 더 높은 인간 일치를 가져온다는 것을 발견했습니다. 이 두 하위 작업에서는 인간 작성 참조와의 임베딩 유사성을 승률 계산 방법으로 사용합니다. 나머지 9개 하위 작업 중에서 브레인스토밍과 요약에서의 평가는 LM 판단자를 프롬프트할 때 인간 작성 참조를 사용하는 것으로부터 이익을 얻지 못했으므로, 나머지 7개 하위 작업에 대해서만 인간 참조로 LM 판단자를 프롬프트합니다.
인간 판단을 수집한 하위 집합에서 연구진의 복합 평가 절차는 인간과 69.4%의 일치를 가져왔으며, 이는 67%의 인간 간 일치와 비교할 만합니다.
미공개 스위트를 사용한 개발 과정 평가
개발 평가에 얼마나 그리고 어떤 방식으로 과적합되었는지 평가하기 위해, 동일한 핵심 기술 세트에 해당하지만 미공개인 작업에서 모델의 성능을 측정합니다. 개발 과정에서 내린 다양한 설계 결정에 해당하는 체크포인트를 미공개 스위트에서 평가하여 결정들이 개발 평가에 과적합되었는지 확인하고, 다음 섹션에서 발견사항을 요약합니다. 이어지는 섹션에서는 최종 체크포인트와 비교 가능한 공개 모델들 간의 비교를 보여줍니다.
설계 결정 평가
훈련 파이프라인: 다음 표는 8B와 70B 크기의 Tülu 3의 SFT, DPO, 최종 체크포인트가 각 핵심 기술에 대한 하나의 개발 및 하나의 미공개 평가에서의 성능을 보여줍니다.
| 기술 | 8B SFT | 8B DPO | 8B Final | 70B SFT | 70B DPO | 70B Final |
|---|---|---|---|---|---|---|
| Dev. Uns. | Dev. Uns. | Dev. Uns. | Dev. Uns. | Dev. Uns. | Dev. Uns. | |
| 평균 | 64.9 29.9 | 68.3 31.9 | 68.8 32.4 | 78.1 41.0 | 80.5 44.4 | 80.7 44.4 |
| 지식 회상 (MMLU → GPQA) | 65.9 31.9 | 68.7 31.2 | 68.2 35.7 | 78.9 43.3 | 83.3 48.0 | 83.1 48.0 |
| 추론 (BBH → AGIEval) | 67.9 56.2 | 65.8 61.8 | 66.0 59.3 | 82.7 73.2 | 81.8 75.0 | 82.0 75.0 |
| 수학 (MATH → DM Mathematics) | 31.5 32.3 | 42.0 33.0 | 43.7 35.4 | 53.7 49.7 | 62.3 49.4 | 63.0 49.8 |
| 코딩 (HumanEval → BigCodeBench) | 86.2 11.5 | 83.9 9.5 | 83.9 7.4 | 92.9 12.2 | 92.4 23.0 | 92.4 21.6 |
| 지시 따르기 (IFEval → IFEval-OOD) | 72.8 17.6 | 81.1 23.9 | 82.4 24.3 | 82.1 26.8 | 82.6 26.4 | 83.2 27.8 |
파이프라인이 미공개 평가에 잘 일반화되며, 최종 체크포인트가 개발 및 미공개 평가 모두에서 최고의 평균 성능을 얻는다는 것을 확인할 수 있습니다. SFT 체크포인트가 개발 평가에서 최고 성능을 보이는 추론과 코딩의 경우, 후속 훈련 단계들이 여전히 더 어려운 미공개 평가에서 모델 성능을 향상시킵니다.
SFT를 위한 데이터 믹싱: SFT를 위해 내린 데이터 믹싱 선택이 미공개 평가에 일반화되는지 평가하기 위해, 최종 SFT 체크포인트와 함께 다양한 데이터 절제 SFT 모델의 성능을 평가했습니다.
| 모델 | 지식 회상 | 추론 | 수학 | 코딩 | 지시 따르기 | |
|---|---|---|---|---|---|---|
| Dev. Avg Uns. Avg. | MMLU GPQA | BBH AGIE | MATH DMM | CHE BCB | IFE IFEO | |
| Tülu 3 8B SFT | 64.1 29.9 | 62.1 31.9 | 67.9 56.2 | 31.5 32.3 | 86.2 11.5 | 72.8 17.6 |
| w/o WildChat | 62.8 28.8 | 61.0 31.5 | 65.6 53.1 | 31.8 31.2 | 85.3 7.4 | 70.1 20.8 |
| w/o Safety | 63.7 29.7 | 62.0 31.9 | 68.3 55.6 | 32.6 32.6 | 84.5 10.8 | 71.0 17.6 |
| w/o Persona Data | 59.8 29.4 | 62.4 29.5 | 68.3 56.9 | 30.1 31.8 | 84.5 10.8 | 53.6 18.0 |
| w/o Math Data | 62.2 27.4 | 62.2 32.6 | 68.9 54.1 | 23.5 23.3 | 86.0 8.8 | 70.6 18.3 |
각 핵심 기술에 대해 개발 및 미공개 평가에서 모델 성능 추세를 비교합니다. 최종 SFT 체크포인트가 개발 및 미공개 평가 모두에서 최고의 평균 성능을 보여 데이터 선택이 평균적으로 일반화된다는 것을 확인할 수 있습니다. 개별 기술에서는 정확한 지시 따르기에서, 그리고 어느 정도 지식 회상과 추론에서 개발 평가에 과적합된 선택을 보입니다.
선호도 조정을 위한 데이터 확장: 개발 및 미공개 평가에서 DPO 데이터 확장이 미치는 영향을 보여줍니다. 확장 추세가 평균적으로 미공개 평가에 일반화된다는 것을 확인할 수 있습니다. 주목할 점은 개발 및 미공개 수학 평가에서 관찰된 추세로, 개발 과정이 MATH에 어느 정도 과적합되었음을 나타냅니다. 이는 주로 MATH와 Deepmind Math 간의 형식 차이 때문이라고 가설을 세웁니다. 전자는 종종 해답과 답변이 LaTeX 형식으로 출력되어야 하는 반면, 후자는 그렇지 않습니다. 훈련된 모델들이 이것이 필요하지 않은 Deepmind Math 데이터셋의 질문에 대해서도 체인 오브 소트 추론과 최종 답변을 LaTeX로 포맷하는 경향이 있다는 것을 발견했습니다. 이는 종종 중간 추론을 방해하고, 답변 추출 로직을 실패하게 만들었습니다.
공개 모델과의 비교
다음 표는 8B와 70B 크기에서 Tülu 3 모델, Llama 3.1 Instruct 모델, Hermes 3 Llama 3.1 모델 간의 비교를 보여줍니다.
| 벤치마크(평가) | Llama 3.1 8B Instruct | Hermes 3 Llama 3.1 8B | Tülu 3 8B | Llama 3.1 70B Instruct | Hermes 3 Llama 3.1 70B | Tülu 3 70B |
|---|---|---|---|---|---|---|
| 평균 | 36.4 | 30.7 | 34.2 | 51.3 | 43.1 | 47.2 |
| 지식 회상 GPQA(0 shot, CoT) | 28.8 | 32.8 | 35.7 | 43.8 | 42.6 | 48.0 |
| MMLU Pro(0 shot, CoT) | 49.1 | 40.9 | 44.3 | 68.3 | 60.3 | 65.8 |
| 추론 AGIEval English(0 shot, CoT) | 64.2 | 58.1 | 59.3 | 77.8 | 73.3 | 75.0 |
| 수학 DeepMind Math(0 shot, CoT) | 39.3 | 28.3 | 35.4 | 62.4 | 50.0 | 49.8 |
| 코딩 BigCodeBench-Hard(Pass@10) | 15.5 | 9.5 | 7.4 | 26.4 | 14.2 | 21.6 |
| 지시 따르기 IFEval OOD(Prompt loose) | 26.1 | 19.4 | 24.3 | 34.5 | 24.6 | 27.8 |
| HREF(Winrate) | 38.5 | 26.2 | 32.7 | 45.6 | 36.8 | 42.3 |
이러한 모든 평가가 Tülu 3 모델에게는 미공개이지만, GPQA, MMLU-Pro, AGIEval, DeepMind Math, BigCodeBench가 다른 두 모델의 개발에 사용되었는지는 알 수 없다는 점이 중요합니다. 이 비교와 이러한 데이터셋에서 Tülu 3 모델 출력의 정성적 분석에서 얻은 주요 시사점을 아래에 요약합니다.
Tülu 3는 미공개 평가에 잘 일반화됩니다: 거의 모든 평가에서 Tülu 3의 성능은 일반적으로 평가하는 다른 두 모델과 비교할 만하며, 종종 두 모델의 성능 수치 사이에 위치합니다. 이는 각 핵심 기술에 대한 대표적인 평가를 선택하고 해당 평가를 대상으로 하는 훈련 데이터셋을 큐레이션하는 레시피가 동일한 기술을 요구하는 다른 작업에 잘 일반화되는 모델로 이어질 수 있음을 시사합니다.
모델들은 일반적으로 IFEval에 과적합됩니다: 후자를 원래 데이터셋과 매우 유사하게 구조화했지만 분리된 제약 세트만 사용하여 생성했음에도 불구하고, 모든 모델에서 IFEval과 IFEval-OOD 성능 간에 상당한 차이가 있다는 것을 발견했습니다. 검증 가능한 제약을 가진 지시 따르기는 모델이 효과적으로 학습하기 어려운 기술이며, IFEval에서 잘 수행하는 모델들은 데이터셋에 포함된 특정 제약 세트에 과적합되어 새로운 제약에 일반화하기 어렵다고 가설을 세웁니다.
지식 회상에서의 일반화는 사후 훈련 레시피에 의존할 수 있습니다: 예상할 수 있듯이, MMLU와 MMLU-Pro에서 모델의 성능은 상관관계가 있습니다. GPQA에서의 성능은 다른 추세를 보입니다 — 여기서 비교하는 세 모델 모두 동일한 기본 모델에서 사후 훈련되었으므로, 사후 훈련 레시피가 지식 회상에서의 일반화에 영향을 미칠 수 있음을 시사합니다.
지시 따르기 성능은 범주에 따라 다릅니다: HREF에서 Tülu 3 모델의 상대적 성능이 AlpacaEval에서와 다르다는 것을 관찰했습니다. 이는 지시 따르기가 매우 다양한 작업이고, HREF와 AlpacaEval의 분포가 다를 수 있으며, 일부 지시 범주가 다른 범주로 잘 전이되지 않아 상대적 성능의 변화로 이어질 수 있다는 사실로 설명될 수 있습니다. Tülu 3 70B가 11개 하위 작업 중 5개에서 Llama 3.1 70B Instruct를 능가한다는 점을 주목합니다. 향후 연구에서는 서로 다른 지시 따르기 행동이 더 다양한 지시 따르기 평가로 어떻게 측정될 수 있는지 탐구할 것입니다.
논의
Tülu 3 레시피의 Llama 3.1 405B 확장
연구진은 Tülu 3 사후 훈련 레시피를 405B 파라미터 규모로 확장하여 그 확장성과 효과를 입증했습니다. 이러한 대규모 확장은 여러 엔지니어링 노력을 필요로 했으며 다양한 도전 과제를 제기했습니다.
컴퓨팅 요구사항: Tülu 3 405B 훈련은 32개 노드(256개 GPU)가 병렬로 실행되어야 했습니다. 대부분의 코드베이스는 잘 확장되었지만, 때때로 NCCL 타임아웃과 동기화 문제가 발생하여 세심한 모니터링과 개입이 필요했습니다(특히 RL 훈련에서). 더 많은 GPU를 사용할수록 하드웨어 장애를 만날 가능성이 증가하여 반자동적인 실행 재시작이 필요했습니다.
RLVR 훈련: 추론을 위해 16-way 텐서 병렬처리를 사용하여 vLLM으로 모델을 배포하고, 나머지 240개 GPU를 훈련에 활용했습니다. RLVR 업데이트의 각 반복 후에 가중치는 NCCL 브로드캐스트를 사용하여 vLLM 엔진에 동기화됩니다. 추론은 일반적으로 약 550초, 가중치 전송은 약 25초, 훈련은 약 1,500초가 소요됩니다. RLVR 단계에서 계산 비용을 줄이기 위해 8B 가치 모델을 활용했습니다. 향후 연구에서는 더 큰 가치 모델이나 GRPO와 같은 대안적인 가치 모델 없는 RL 알고리즘을 탐구하는 것이 도움이 될 수 있습니다.
하이퍼파라미터 튜닝 도전: 계산 비용을 고려할 때 하이퍼파라미터 튜닝이 제한적이었습니다.
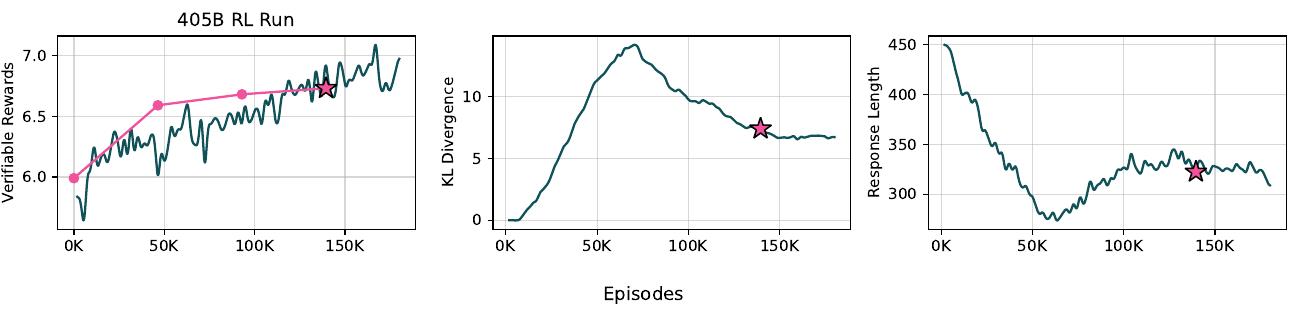
위 그림은 405B RL 실행 과정에서 150,000 에피소드에 걸친 검증 가능한 보상(y축)의 변화를 보여주는 선 그래프입니다. 훈련 과정에서 검증 가능한 보상의 변동을 보여주며, 약 100,000 에피소드 지점에서 보상의 피크를 나타냅니다. 이 그림은 405B RL 실행의 훈련 성능을 시각적으로 보여주는 중요한 의미를 가지며, 연구에서 제시되는 핵심 구성 요소일 가능성이 높습니다.
405B 모델의 훈련 레시피는 8B와 70B 모델과 매우 유사하게 따랐지만, RLVR을 위한 다른 훈련 데이터셋을 사용했습니다. 모델이 SFT와 DPO 훈련만으로도 GSM8K에서 포화 상태에 도달했기 때문에 GSM8K 데이터를 제거했으며, 초기 RLVR 실행에서 IFEval 데이터가 크게 도움이 되지 않는다는 것을 발견했습니다. 따라서 Tülu 3 405B RLVR에서는 MATH 훈련 세트만 사용했습니다.
놀랍게도 단 25 RLVR 단계만으로도 MATH 성능이 5점 이상 향상되었으며, 더 많은 훈련으로 계속 증가했습니다. 비동기 RL 인프라 확장의 도전으로 인해 더 작은 모델들보다 적은 75단계만 훈련했습니다. RL 보상, KL 발산, 그리고 훈련 배치당 응답 길이는 위 그림에서 확인할 수 있습니다.
SFT와 DPO 단계의 훈련 하이퍼파라미터는 다음과 같습니다.
| 하이퍼파라미터 | 405B SFT | 405B DPO |
|---|---|---|
| 학습률 | 2 × 10⁻⁶ | 2 × 10⁻⁷ |
| 학습률 스케줄 | Linear | Linear |
| 배치 크기 (유효) | 256 | 256 |
| 최대 토큰 길이 | 4,096 | 2,048 |
| KL 페널티 계수 β | - | 5 |
| 워밍업 비율 | 0.03 | 0.1 |
| 에포크 수 | 2 | 1 |
더 많은 GPU 수로 인해 더 큰 배치 크기를 사용하고 SFT 학습률을 낮췄습니다.
이 규모에서 검증 가능한 보상을 통한 RL의 하이퍼파라미터는 다음과 같습니다.
| 하이퍼파라미터 | 405B RLVR |
|---|---|
| 학습률 | 1 × 10⁻⁷ |
| 할인 인수 γ | 1.0 |
| 일반 이점 추정 λ | 0.95 |
| 미니배치 수 Nmb | 1 |
| PPO 클리핑 계수 ε | 0.2 |
| 가치 함수 계수 c1 | 1.0 |
| 그래디언트 노름 임계값 | 0.1 |
| 학습률 스케줄 | Linear |
| 생성 온도 | 1.0 |
| 배치 크기 (유효) | 1,856 |
| 최대 토큰 길이 | 2,048 |
| 최대 프롬프트 토큰 길이 | 2,048 |
| EOS 토큰 없는 응답 페널티 보상 값 | -10.0 |
| PPO 업데이트 반복 K | 1 |
| 응답 길이 | 1,024 |
| 총 에피소드 | 300,000 |
| KL 페널티 계수 (β) | 0.05 |
| 워밍업 비율 (ω) | 0.0 |
이전 Tülu와 Llama 연구를 따라 더 큰 모델에 대해 학습률을 낮추고 "가벼운 터치"로 훈련하기로 했습니다.
Tülu 3 405B를 이전 최첨단 모델들과 비교한 결과, 일반적으로 Tülu 3 405B 결과는 Tülu 3 70B에 비해 개선되었습니다. Tülu 3 405B는 Deepseek v3와 GPT-4o 모두에 대해 경쟁력 있거나 우수한 성능을 달성하면서, 동일한 크기의 이전 오픈 가중치 사후 훈련 모델들인 Llama 3.1 405B Instruct와 Nous Hermes 3 405B를 많은 표준 벤치마크에서 능가했습니다.
연구진은 계산 제약으로 인해 RLVR 훈련을 일찍 종료했으며, 추가 훈련이 성능을 더욱 향상시킬 수 있다고 언급했습니다. 특히 훈련과 테스트 중에 MATH 성능이 포화되지 않았음을 관찰했습니다.
성과를 거두지 못한 접근법들로부터의 통찰
이 섹션에서는 Tülu 3를 위해 고려했지만 다양한 이유로 최종 레시피에 포함되지 않은 여러 방법과 접근법들을 논의합니다.
온라인 DPO: 표준 DPO 방법은 일반적으로 사전에 수집되고 종종 별개의 언어 모델에서 나온 선호도 데이터셋을 사용하므로 오프라인으로 간주됩니다. 즉, DPO에서는 정책이 훈련 중에 자체 생성에 대한 피드백을 얻을 수 없습니다. 이는 훈련되는 정책 \(\pi_\theta\)의 생성에 대해 RM이 온라인 피드백을 제공하는 PPO와 같은 온라인 방법과 대조됩니다.
분포 이동 문제를 완화하기 위해 최근 연구들은 세 단계 과정을 따르는 온라인 DPO를 제안했습니다. (1) 현재 정책에서 프롬프트에 대한 2개의 응답을 샘플링, (2) 응답 쌍에 대한 온라인 피드백을 얻어 쌍별 데이터 생성, (3) 이 쌍별 데이터를 사용하여 표준 DPO 손실을 통해 정책 \(\pi_\theta\) 업데이트.
원래 논문에서는 2단계에 온라인 AI 피드백 사용을 제안했지만, 실험을 더 잘 확장하기 위해 훈련된 보상 모델에서 피드백을 얻었습니다. 일반 능력과 수학적 추론과 같은 목표 능력 모두를 향상시키기 위해 온라인 DPO를 시도했습니다.
일반 능력의 경우 Skywork의 82K 선호도 데이터 포인트를 사용하여 1 에포크 동안 RM을 훈련했습니다. 수학적 추론을 목표로 하기 위해서는 합성 온폴리시 수학 특화 선호도 데이터에서 동일한 RM을 계속 훈련했습니다.
Tülu 3 DPO 체크포인트 중 하나에서 수학 문제에 대해 총 200K 에피소드 동안 온라인 DPO를 훈련한 결과(프롬프트는 동일한 RM 훈련 데이터에서 가져옴), GSM8K에서 개선이 없거나 거의 없었고 MATH 성능에서는 저하가 있었습니다(다양한 샘플링 온도와 KL 페널티 계수를 실험함). 초기 결과가 일반 및 목표 도메인 모두에서 제한적인 이득을 시사했기 때문에 이 접근법을 광범위하게 탐구하지 않았습니다.
향후 연구에서는 다른 샘플링 방법이나 RM 아키텍처 미세조정과 같은 대안적인 훈련 전략을 조사하여 최적화 과정을 원하는 능력과 더 잘 정렬시킬 수 있을 것입니다.
거부 샘플링: 대규모 언어 모델을 위한 거부 샘플링은 최첨단 언어 모델의 사후 훈련 성능을 향상시키는 점점 인기 있는 방법입니다. 초기 SFT와 선호도 데이터 믹스를 사용하여 초기 모델을 훈련한 후, 해당 모델을 사용하여 각 SFT 프롬프트에 대해 n개의 응답을 생성합니다. 이러한 n개의 응답은 원래 응답과 함께 보상 모델이나 판단자로서의 LLM을 사용하여 순위를 매기고, 최고의 응답을 유지합니다. 다른 응답들은 선호도 최적화를 위한 선택/거부 쌍을 만드는 데 사용될 수 있습니다. 전체 사후 훈련 파이프라인이 이러한 데이터셋에서 실행되고, 성능이 수렴할 때까지 과정이 반복됩니다.
거부 샘플링을 시도했지만, 연구진의 설정에서는 필요한 계산량에 비해 성능 향상이 미미하다는 것을 발견했으며, 따라서 더 깊은 탐구는 향후 연구로 남겨두었습니다. 정성적으로 강력한 판단자가 중요하며, 공개적으로 사용 가능한 모델들이 후보 중에서 최고의 응답을 선택하는 데 어려움을 겪을 수 있다는 것을 발견했습니다. 또한 판단자의 선택으로 원래 응답을 포함하는 것(즉, n개의 생성과 원래 응답 중에서 최고의 응답을 선택하는 것)이 새로 생성된 응답들 중에서만 선택하는 것보다 훨씬 더 나은 성능을 보인다는 것을 발견했습니다.
향후 연구
Tülu 3에서 광범위한 기술 세트를 다루는 것을 목표로 했지만, 다양한 제한으로 인해 일부 기술들은 향후 Tülu 반복을 위해 남겨두었습니다. 이러한 기술들 중 일부를 아래에서 논의합니다.
긴 맥락과 멀티턴: 현재 Tülu 3를 위해 수집된 데이터는 상대적으로 짧고 긴 멀티턴 데이터를 포함하지 않습니다(믹스의 평균 턴 수는 2.4턴이고 대부분의 샘플이 2,048 토큰 미만의 길이). 그러나 긴 맥락은 최근 연구에서 인기 있는 초점 영역이 되었으며, LM의 맥락 창을 개선하는 것은 새로운 사용 사례를 가능하게 하고 더 많은 맥락 내 예시를 제공하여 잠재적으로 성능을 향상시킬 수 있습니다.
관련하여, 멀티턴 능력을 개선하는 것은 최종 사용자 경험을 더 잘 향상시킬 수 있으며, 실제 사용자-LM 대화의 상당 부분이 2턴을 넘어갑니다. 향후에는 전용 훈련과 평가를 통해 두 기술을 모두 다루기를 희망합니다.
다국어성: Tülu 3에서는 영어 데이터와 평가에 특별히 초점을 맞췄습니다(고품질로 인해 다국어 Aya 데이터셋을 포함하긴 했지만). 그러나 이는 전 세계에서 사용되는 영어 이외의 수많은 언어들을 무시하며, 이러한 언어의 사용자들은 자신들의 언어를 처리할 수 있는 LM으로부터 이익을 얻거나 원할 수 있습니다.
향후 연구에서는 Tülu 3의 현재 다국어 능력을 검토하고 이를 더욱 향상시키는 방법을 조사할 수 있습니다. 또한 다국어 사후 훈련은 단일 언어 사후 훈련과 다른 기법들을 사용할 수 있다는 점을 주목합니다. 예를 들어, 교차 언어 정렬이나 신중한 데이터 균형 전략 등입니다. 이는 다국어 사후 훈련을 흥미롭고 영향력 있는 향후 연구 영역으로 만듭니다.
도구 사용과 에이전트: Tülu 3를 자체적으로 평가하지만, LM들은 점점 더 큰 시스템의 일부로 배포되고 있으며, 여기서 도구에 접근하거나 더 큰 '에이전트' 프레임워크의 일부가 됩니다. 더 나아가, 도구를 사용하도록 모델을 훈련하는 것은 '가중치에서' 모든 것을 달성하려고 시도하는 것보다 추론과 수학적 기술을 극적으로 향상시키는 자연스러운 방법입니다.
향후 연구에서는 Tülu 3를 자체적으로 또는 더 큰 프레임워크의 일부로서 도구 사용을 위해 훈련하거나 평가하는 것을 포함합니다.
관련 연구
사후 훈련 레시피의 진화
현대적인 "사후 훈련"은 다중 작업 언어 모델 훈련, 특히 지시 조정(instruction tuning)에 그 뿌리를 두고 있습니다. 지시 조정은 작업 지시와 해당 응답을 포함하는 샘플들로 언어 모델을 훈련하여, 모델이 새로운 작업에 대해 '제로샷'으로 일반화할 수 있도록 하는 방법입니다. 초기 지시 조정 데이터셋들은 하위 사용자들이 실제로 수행할 수 있는 일반적인 작업보다는 자연어 추론과 같은 전통적인 자연어처리 작업에 더 초점을 맞추는 경향이 있었습니다.
ChatGPT와 채팅 기반 언어 모델들(Claude, Gemini 등)의 등장과 함께, 사후 훈련 기법들은 지시 조정을 넘어서 선호도 조정 단계를 포함하도록 발전했습니다. 모델들은 지시 조정과 선호도 미세조정(PreFT) 또는 "RLHF"를 모두 거치게 되었습니다. RLHF의 초기 연구는 제어를 위한 심층 강화학습 실험에서 시작되었으며, 일반적으로 먼저 인간 선호도로부터 보상 모델을 학습하고, 그 다음 학습된 보상을 사용하여 강화학습 프레임워크를 통해 언어 모델을 최적화하는 방식을 포함했습니다.
최근에는 이러한 선호도에 대해 언어 모델을 직접 훈련할 수 있는 접근법들이 개발되어, PreFT를 훈련에 통합하는 복잡성을 줄였습니다. 초기 PreFT 접근법들이 수만 또는 수십만 개의 인간이 작성한 지시와 인간 선호도 라벨을 사용하는 극도로 인간 중심적이었던 반면, 최근 연구들은 인간과 합성적으로 생성된 선호도 데이터의 혼합을 사용하며, 다중 라운드 훈련과 다양한 훈련 알고리즘을 활용합니다.
RLHF가 주로 폐쇄된 연구소에서 발전하는 동안, 사후 훈련을 위한 오픈 레시피들은 다소 뒤처져 있었습니다. '오픈 사후 훈련 레시피'를 구축하려는 초기 시도들은 지시 조정 단계에 초점을 맞췄으며, 합성적으로 생성되거나 인간이 만든 데이터셋에서 공개적으로 출시된 언어 모델들을 미세조정했습니다. 이러한 데이터셋들을 결합하면 강력한 성능을 얻을 수 있었지만, 인간 평가를 기반으로 한 폐쇄형 모델들과의 격차를 해소하기 위해서는 PreFT 단계를 통합하는 것이 중요했습니다.
오늘날 PreFT를 위한 오픈 레시피를 가진 대부분의 인기 있는 적응 모델들은 DPO(또는 그 변형들) 중 하나와 AI 피드백 데이터를 사용합니다. 여기에는 Tülu 2, Zephyr-β, Starling 등이 포함됩니다. 그러나 이러한 모델들 중 많은 것들이 데이터와 성능 측면에서 폐쇄형 사후 훈련 레시피에 비해 구식입니다. 2024년 11월 20일 기준으로 LMSYS의 ChatBotArena 상위 50위 안에 든 오픈 레시피 모델 중 어떤 것도 사후 훈련 데이터를 공개하지 않았습니다.
이러한 오픈 레시피들 대부분은 폐쇄형 사후 훈련 설정에 비해 상대적으로 적은 데이터와 적은 훈련 라운드를 사용합니다. 폐쇄형 설정은 다양한 목표를 가진 다중 라운드 훈련과 수백만 개의 데이터 포인트를 포함할 수 있습니다. 예를 들어, Llama 3.1은 이전 모델에서 생성된 출력에 대해 광범위한 인간 피드백 데이터와 함께 여러 라운드에 걸쳐 훈련되었으며, 강력한 모델들을 사용하여 합성 지시를 작성했습니다.
다른 최근 발전사항으로는 합성 데이터를 위한 거부 샘플링과 단계별 어시스턴트 응답을 위한 고급 보상 모델링이 있습니다. 연구진은 이러한 폐쇄형 레시피의 규모에 완전히 도달하지는 못했지만, 이 연구에서는 강력한 폐쇄형 레시피와 일치하거나 이를 능가하는 레시피를 구축하고 추가 과학적 연구와 사용을 위해 모든 관련 결과물(코드, 모델, 데이터 등)을 공개함으로써 오픈 사후 훈련 레시피의 현황을 발전시키기를 희망합니다.
연구진의 파이프라인은 거의 백만 개의 지시 조정 샘플, 수십만 개의 선호도 쌍, 그리고 새로운 온라인 강화학습 훈련 단계를 포함하여 이전 연구보다 훨씬 크고 복잡합니다.
검증 가능한 보상을 통한 훈련
이 연구에서 제안된 RLVR 접근법은 강화학습 관련 기법을 통해 언어 모델 추론을 개선하는 다양한 최근 연구와 관련이 있습니다. 밀접하게 관련된 것은 자기 교육 추론자(STaR) 계열의 연구와 TRICE입니다. 이 두 방법 모두 기존의 정답을 신호로 사용하여 더 나은 모델 근거(또는 사고 연쇄)를 생성하는 것을 검토합니다.
STaR은 정책 그래디언트 알고리즘의 근사로 볼 수 있으며, Quiet-STaR은 모델이 일반적인 언어 모델링을 개선하기 위해 추가 생성을 사용하도록 훈련하는 접근법('말하기 전에 생각하기')을 확장합니다. TRICE 또한 사용자 정의 MCMC 기반 EM 알고리즘을 사용하여 여러 추론 경로에 대해 훈련함으로써 정답의 가능성을 개선하는 것을 목표로 합니다.
더 최근에는 VinePPO가 GSM8k와 MATH 정확성으로부터의 이진 보상을 사용하여 새로운 PPO 기반 알고리즘을 테스트했으며, 다른 최근 연구들은 코드 피드백을 훈련 신호로 사용하는 것을 탐구했습니다. 이와 대조적으로, 연구진이 제안한 RLVR 접근법은 훈련을 위해 기존 강화학습 프레임워크(PPO)를 단순히 사용하며, STaR의 반복적 접근법이나 Quiet-STaR의 로그 가능성 보상과 비교하여 이진 보상으로 완전히 온라인으로 실행됩니다.
또한 연구진은 수학 도메인을 넘어서 확장하여, 이 접근법이 정확한 지시 따르기에서도 개선을 가져올 수 있음을 발견했습니다. 마지막으로, 연구진은 가치 모델 초기화와 일반 보상 모델을 검증 가능한 보상과 함께 사용하는 것을 포함하여 RLVR의 여러 핵심 구성 요소를 신중하게 절제했습니다. 연구진은 향후 연구에서 이 기법을 더욱 발전시키고 확장하기를 희망합니다.
이러한 관련 연구들의 맥락에서 RLVR은 검증 가능한 결과를 가진 작업들에 대해 언어 모델을 훈련하는 새롭고 실용적인 접근법을 제공합니다. 기존 방법들이 복잡한 반복 과정이나 특수한 알고리즘을 요구하는 반면, RLVR은 표준 PPO 프레임워크를 활용하면서도 수학적 추론과 지시 따르기 모두에서 효과적인 개선을 달성할 수 있음을 보여줍니다.
결론
Tülu 3는 완전히 오픈소스로 공개된 최첨단 언어 모델 패밀리로서, 현대적인 사후 훈련 프레임워크와 함께 완전히 공개된 데이터(Tülu 3 Data), 평가 도구(Tülu 3 Eval), 훈련 코드(Tülu 3 Code), 그리고 개발 레시피(Tülu 3 Recipe)를 특징으로 합니다. 연구진은 Llama 3.1 기본 버전에서 훈련된 최종 모델들을 중간 체크포인트, 훈련 데이터, 훈련 코드, 그리고 평가 코드와 함께 공개했습니다.
Tülu 3는 오픈소스와 폐쇄형 사후 훈련 방법론 간의 격차를 해소하여 오픈 사후 훈련 연구에서 새로운 이정표를 세웠습니다. 제공된 자원들을 통해 다른 연구자들은 오픈 기본 모델을 가져와서 다양한 작업에서 고성능을 달성하도록 미세조정할 수 있습니다. 이는 다목적, 다단계 훈련 프레임워크 내에서 사후 훈련 연구를 발전시키는 길을 열어줍니다.
프로젝트의 핵심 성과
Tülu 3 프로젝트는 여러 핵심 영역에서 중요한 기여를 했습니다. 첫째, 완전한 투명성을 달성했습니다. 기존의 최첨단 모델들이 훈련 데이터나 방법론을 공개하지 않는 것과 달리, Tülu 3는 모든 구성 요소를 완전히 공개하여 재현 가능한 연구를 가능하게 했습니다. 이는 학술 연구 커뮤니티에서 매우 중요한 발전입니다.
둘째, 혁신적인 방법론을 도입했습니다. 특히 검증 가능한 보상을 통한 강화학습(RLVR)은 수학적 문제 해결과 정확한 지시 따르기와 같이 검증 가능한 결과를 가진 작업들에 대해 새로운 접근법을 제시했습니다. 이 방법은 기존의 보상 모델 기반 접근법과 달리 실제 정답 여부를 직접 검증하여 보상을 제공하는 혁신적인 방식입니다.
셋째, 체계적인 평가 프레임워크를 구축했습니다. Tülu 3 Eval은 개발용과 미공개 평가를 분리하여 과적합을 방지하고, 모델의 실제 일반화 능력을 평가할 수 있는 체계를 제공했습니다. 이는 향후 언어 모델 평가의 표준이 될 수 있는 중요한 기여입니다.
기술적 혁신의 의미
Tülu 3의 기술적 혁신들은 언어 모델 연구 분야에 여러 중요한 시사점을 제공합니다. 합성 데이터 생성에서 페르소나 기반 접근법의 성공은 다양성과 품질을 동시에 확보할 수 있는 효과적인 방법임을 보여주었습니다. 25만 개의 서로 다른 페르소나를 활용한 데이터 생성은 모드 붕괴 문제를 해결하면서도 대규모 고품질 데이터를 생성할 수 있음을 입증했습니다.
선호도 조정에서 온폴리시 데이터의 중요성도 확인되었습니다. 실제 훈련될 모델에서 생성된 응답을 포함하는 것이 성능 향상에 중요한 역할을 한다는 발견은 향후 선호도 학습 연구에 중요한 지침을 제공합니다. 또한 길이 정규화된 DPO의 효과는 인간과 모델 선호도에서 흔한 길이 편향을 완화하는 실용적인 해결책을 제시했습니다.
오픈소스 생태계에 대한 기여
Tülu 3는 단순히 모델을 공개하는 것을 넘어서 완전한 오픈소스 생태계를 구축했습니다. 이는 언어 모델 연구의 민주화에 중요한 기여를 합니다. 연구자들은 이제 대규모 자원 없이도 최첨단 모델의 훈련 과정을 이해하고 재현할 수 있으며, 자신만의 개선사항을 추가할 수 있습니다.
특히 오염 제거 도구와 평가 프레임워크의 공개는 연구 커뮤니티 전체의 연구 품질 향상에 기여할 것입니다. 8-gram 매칭을 통한 체계적인 오염 제거 방법론과 개발/미공개 평가 분할 전략은 다른 연구자들이 신뢰할 수 있는 평가를 수행하는 데 도움이 될 것입니다.
확장성과 실용성
405B 파라미터 규모까지의 성공적인 확장은 Tülu 3 레시피의 확장성을 입증했습니다. 이는 단순히 작은 모델에서만 작동하는 방법이 아니라, 실제 산업 수준의 대규모 모델에도 적용 가능한 실용적인 접근법임을 보여줍니다. 특히 비동기 강화학습 인프라와 분산 훈련 최적화 기법들은 제한된 자원으로도 대규모 모델 훈련을 가능하게 하는 중요한 기술적 기여입니다.
연구 방법론의 발전
Tülu 3 프로젝트는 언어 모델 연구 방법론 자체에도 중요한 기여를 했습니다. 체계적인 절제 실험을 통한 각 구성 요소의 기여도 분석, 개발 과정에서의 엄격한 평가 프로토콜, 그리고 미공개 평가를 통한 일반화 능력 검증은 향후 언어 모델 연구의 표준이 될 수 있는 방법론적 프레임워크를 제시했습니다.
특히 다양한 기술 영역(수학, 코딩, 추론, 안전성 등)에서의 균형 잡힌 성능 달성을 위한 체계적 접근법은 범용 언어 모델 개발에 중요한 통찰을 제공합니다. 각 기술별로 특화된 데이터를 큐레이션하면서도 전체적인 균형을 유지하는 방법론은 실용적인 가치가 높습니다.
미래 연구에 대한 영향
Tülu 3의 공개는 언어 모델 연구 분야에 장기적인 영향을 미칠 것으로 예상됩니다. 완전히 공개된 레시피와 도구들은 연구자들이 새로운 아이디어를 빠르게 실험하고 검증할 수 있는 기반을 제공합니다. 특히 RLVR과 같은 새로운 방법론은 다른 검증 가능한 도메인으로 확장될 수 있는 잠재력을 가지고 있습니다.
또한 체계적인 평가 프레임워크는 언어 모델 연구에서 더욱 엄격하고 신뢰할 수 있는 평가 문화를 조성하는 데 기여할 것입니다. 개발 과정의 투명성과 재현 가능성은 연구 결과의 신뢰성을 높이고, 학술 커뮤니티 전체의 발전을 가속화할 것입니다.
Tülu 3는 오픈소스 언어 모델 연구의 새로운 표준을 제시하며, 폐쇄형 모델과의 성능 격차를 해소하는 동시에 완전한 투명성을 달성한 중요한 이정표입니다. 이 프로젝트가 제공하는 자원들과 방법론들은 향후 언어 모델 연구의 발전에 지속적으로 기여할 것으로 기대됩니다.
References
Subscribe via RSS