DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
by DeepSeek AI
TL;DR
이 연구를 시작하게 된 배경과 동기는 무엇입니까?
대규모 언어 모델(LLM)의 추론 능력 향상은 인공일반지능(AGI) 발전의 핵심 과제입니다. 기존 연구들은 주로 지도 학습에 의존하여 모델의 추론 능력을 향상시키려 했으나, 이는 대규모 고품질 데이터셋 구축이 필요하다는 한계가 있었습니다. 또한 OpenAI의 o1 시리즈가 보여준 Chain-of-Thought 추론의 성공에도 불구하고, 이를 재현하거나 개선하는 효과적인 방법론이 공개되지 않았습니다. 이에 연구진은 강화학습을 통해 언어 모델의 추론 능력을 자율적으로 향상시킬 수 있는 새로운 접근 방식을 탐구하게 되었습니다.
이 연구에서 제시하는 새로운 해결 방법은 무엇입니까?
DeepSeek-R1은 크게 두 가지 혁신적인 접근 방식을 제시합니다. 첫째, DeepSeek-R1-Zero를 통해 지도 학습 없이 순수하게 강화학습만으로 모델의 추론 능력을 향상시키는 방법을 개발했습니다. 둘째, 소량의 콜드 스타트 데이터와 다단계 학습 파이프라인을 결합한 DeepSeek-R1을 통해 더욱 체계적이고 효과적인 추론 능력 향상 방법을 제시했습니다. 특히 주목할 만한 점은 이렇게 획득된 추론 능력을 더 작은 모델로 효과적으로 전달할 수 있는 증류 기술을 개발했다는 것입니다.
제안된 방법은 어떻게 구현되었습니까?
구현은 크게 세 단계로 이루어졌습니다. 먼저 DeepSeek-R1-Zero는 그룹 상대 정책 최적화(GRPO)를 활용한 순수 강화학습을 통해 구현되었습니다. 다음으로 DeepSeek-R1은 수천 개의 고품질 Chain-of-Thought 예시로 구성된 콜드 스타트 데이터로 초기 학습을 진행한 후, 추론 중심의 강화학습과 지도 학습을 결합한 다단계 학습을 수행했습니다. 마지막으로, 증류 과정에서는 DeepSeek-R1의 출력을 활용하여 1.5B부터 70B 파라미터에 이르는 다양한 규모의 모델들을 효과적으로 미세 조정했습니다.
이 연구의 결과가 가지는 의미는 무엇입니까?
이 연구의 결과는 언어 모델의 추론 능력 향상에 있어 중요한 돌파구를 제시합니다. DeepSeek-R1은 AIME 2024에서 97.3%, GPQA Diamond에서 96.4%, MATH-500에서 90.2%의 높은 정확도를 달성하며 OpenAI-o1-1217과 대등한 성능을 보여주었습니다. 특히 순수 강화학습만으로도 높은 수준의 추론 능력을 달성할 수 있다는 것을 입증한 것은 매우 중요한 발견입니다. 또한 증류 기술을 통해 이러한 능력을 더 작은 모델로 효과적으로 전달할 수 있다는 것을 보여줌으로써, 실용적인 응용 가능성을 크게 확장했습니다. 이는 향후 언어 모델 발전의 새로운 패러다임을 제시하는 중요한 성과라고 할 수 있습니다.
DeepSeek-R1: 강화학습을 통한 언어 모델의 추론 능력 향상
DeepSeek-R1은 대규모 언어 모델의 추론 능력을 향상시키기 위해 강화학습을 활용한 혁신적인 접근 방식을 제시합니다. 연구진은 먼저 DeepSeek-R1-Zero라는 모델을 개발했는데, 이는 지도 학습 없이 순수하게 강화학습만을 통해 학습된 모델입니다. 이 모델은 놀라운 추론 능력을 보여주었으나, 가독성이 떨어지고 여러 언어가 혼합되는 등의 문제점도 발견되었습니다.
이러한 문제를 해결하고 추론 성능을 더욱 향상시키기 위해, 연구진은 DeepSeek-R1을 개발했습니다. 이 모델은 강화학습 이전에 콜드 스타트(cold start) 데이터를 활용한 다단계 학습 방식을 도입했습니다. 실험 결과에 따르면, DeepSeek-R1은 OpenAI-o1-1217와 비견될 만한 성능을 달성했으며, 특히 AIME 2024, GPQA Diamond, MATH-500과 같은 특정 추론 과제에서는 더 우수한 성능을 보여주었습니다.
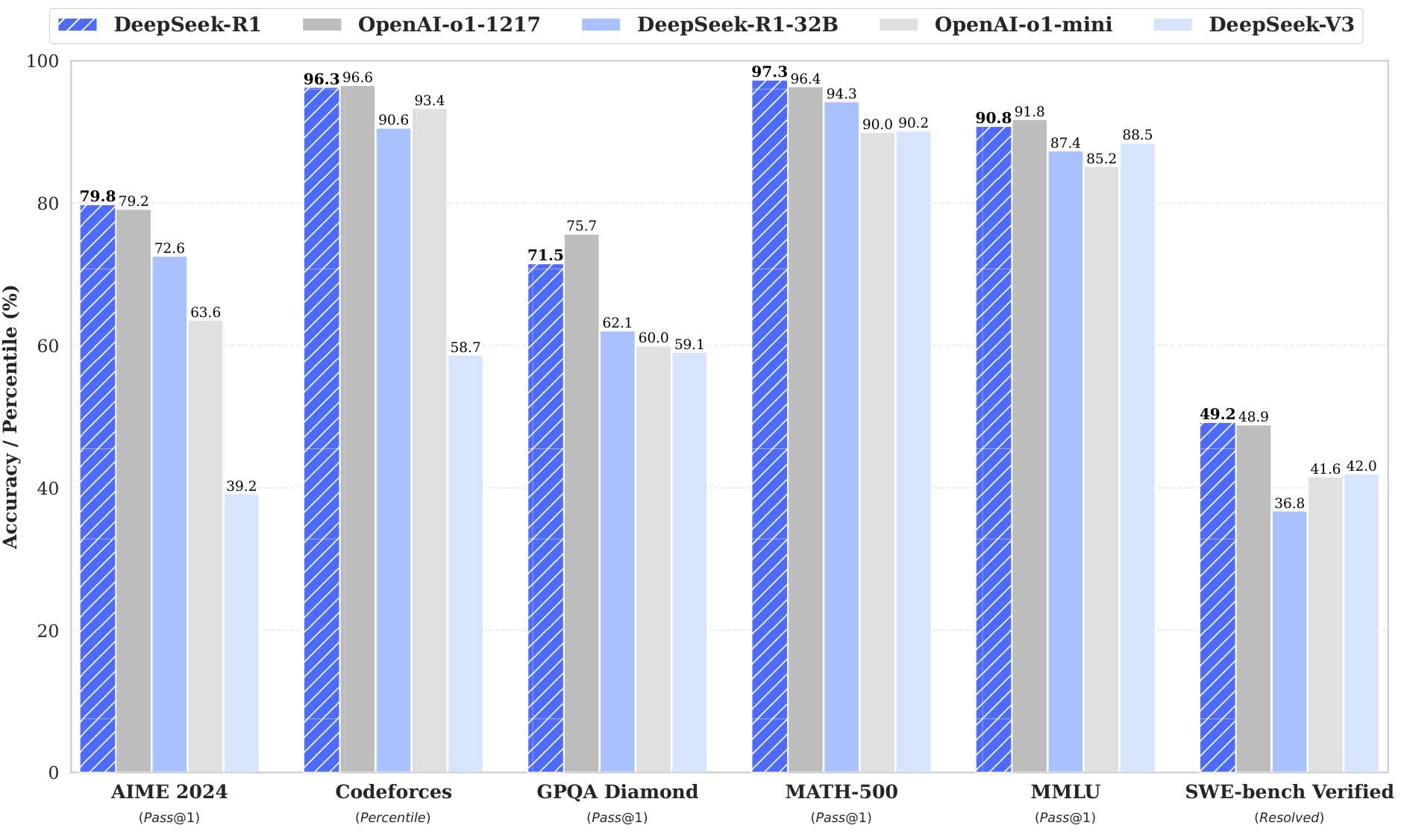
위 그래프는 DeepSeek-R1과 다른 주요 모델들의 성능을 비교한 결과를 보여줍니다. DeepSeek-R1은 AIME 2024에서 97.3%, GPQA Diamond에서 96.4%, MATH-500에서 90.2%의 높은 정확도를 달성했습니다. 특히 주목할 만한 점은 DeepSeek-R1-32B 모델이 더 큰 규모의 모델들과 비교해도 경쟁력 있는 성능을 보여준다는 것입니다.
연구진은 더 나아가 DeepSeek-R1의 추론 능력을 더 작은 모델로 전달하기 위해 증류 기술을 적용했습니다. 이를 통해 1.5B부터 70B 파라미터에 이르는 6개의 고밀도 모델을 개발했으며, 이 모델들은 Qwen과 Llama 아키텍처를 기반으로 합니다. 이러한 증류 모델들은 연구 커뮤니티가 DeepSeek-R1의 추론 능력을 더 효율적으로 활용할 수 있게 해줍니다. DeepSeek-R1의 개발 과정에서 가장 주목할 만한 기술적 혁신은 강화학습과 콜드 스타트 방식의 결합입니다. 이는 기존 언어 모델의 한계를 극복하고 더 강력한 추론 능력을 달성하기 위한 체계적인 접근 방식을 제시합니다.
강화학습만을 사용한 DeepSeek-R1-Zero는 흥미로운 자기 발전 과정을 보여주었습니다. 이 모델은 학습 과정에서 “아하 모멘트(Aha moment)”라고 불리는 중요한 전환점들을 경험했는데, 이는 모델이 복잡한 추론 과제를 해결하는 새로운 전략을 자발적으로 발견하는 순간들을 의미합니다. 이러한 발견은 강화학습이 언어 모델의 추론 능력 향상에 효과적일 수 있다는 것을 보여주는 중요한 증거입니다.
그러나 DeepSeek-R1-Zero가 보여준 한계점들을 해결하기 위해, 연구진은 더욱 정교한 학습 전략을 도입했습니다. 특히 콜드 스타트 단계에서는 추론 과정의 품질을 향상시키기 위한 특별한 데이터셋을 활용했습니다. 이어지는 추론 중심의 강화학습 단계에서는 모델이 단순히 정답을 맞히는 것을 넘어서, 논리적이고 체계적인 추론 과정을 생성하도록 유도했습니다.
이러한 다단계 학습 접근 방식의 효과는 다양한 벤치마크 결과를 통해 입증되었습니다. 특히 AIME 2024와 같은 고난도 수학 문제에서 보여준 97.3%의 정확도는 매우 인상적인 성과입니다. 이는 DeepSeek-R1이 단순한 패턴 매칭을 넘어서, 복잡한 수학적 개념을 이해하고 적용할 수 있는 능력을 갖추었음을 시사합니다.
더불어, 연구진이 개발한 증류 기술은 대규모 언어 모델의 실용적 활용 가능성을 크게 확장했습니다. 1.5B에서 70B 파라미터에 이르는 다양한 규모의 모델들이 원본 모델의 추론 능력을 효과적으로 보존하면서도, 더 적은 컴퓨팅 자원으로 운용될 수 있다는 점은 매우 중요한 성과입니다.
대규모 언어 모델의 추론 능력 향상을 위한 혁신적 접근
최근 대규모 언어 모델(LLM)은 인공일반지능(AGI)을 향해 빠르게 진화하고 있습니다. 이러한 발전 과정에서 사후 학습(post-training)이 전체 학습 파이프라인의 중요한 구성 요소로 부상했습니다. 사후 학습은 추론 작업의 정확도를 향상시키고, 사회적 가치와의 정렬을 강화하며, 사용자 선호도에 적응하는 데 효과적입니다. 특히 사전 학습에 비해 상대적으로 적은 컴퓨팅 자원만을 필요로 한다는 장점이 있습니다.
추론 능력 향상과 관련하여, OpenAI의 o1 시리즈 모델은 Chain-of-Thought(CoT) 추론 과정의 길이를 증가시키는 추론 시간 스케일링을 도입한 최초의 모델입니다. 이 접근 방식은 수학, 코딩, 과학적 추론과 같은 다양한 추론 작업에서 상당한 성능 향상을 이끌어냈습니다. 그러나 효과적인 테스트 시간 스케일링은 여전히 연구 커뮤니티의 주요 과제로 남아있습니다.
이전 연구들은 프로세스 기반 보상 모델, 강화학습, 몬테카를로 트리 탐색, 빔 서치 등 다양한 접근 방식을 탐구했습니다. Lightman과 연구진은 프로세스 기반 보상 모델을 통해 복잡한 다단계 추론 문제 해결에서 상당한 성과를 거두었으며, Kumar와 연구진은 테스트 시간 컴퓨팅의 최적 스케일링에 대한 심도 있는 분석을 제시했습니다. 그러나 이러한 방법들은 아직 OpenAI의 o1 시리즈 모델에 견줄 만한 일반적인 추론 성능을 달성하지 못했습니다.
본 논문에서는 순수 강화학습(RL)을 활용하여 언어 모델의 추론 능력을 향상시키는 첫 걸음을 내딛습니다. 연구진의 목표는 지도 학습 데이터 없이도 순수 RL 과정을 통해 자체적으로 진화할 수 있는 LLM의 잠재력을 탐구하는 것입니다. 구체적으로, DeepSeek-V3-Base를 기본 모델로 사용하고 GRPO(Group Relative Policy Optimization)를 RL 프레임워크로 채택하여 모델의 추론 성능을 향상시켰습니다.
학습 과정에서 DeepSeek-R1-Zero는 다양하고 흥미로운 추론 행동들을 자연스럽게 발현했습니다. 수천 번의 RL 단계를 거친 후, DeepSeek-R1-Zero는 추론 벤치마크에서 뛰어난 성능을 보여주었습니다. 예를 들어, AIME 2024에서의 pass@1 점수가 15.6%에서 71.0%로 증가했으며, 다수결 투표를 적용했을 때는 86.7%까지 향상되어 OpenAI-o1-0912의 성능과 비견될 만한 수준에 도달했습니다. 그러나 DeepSeek-R1-Zero는 가독성이 떨어지고 여러 언어가 혼합되는 등의 문제점에 직면했습니다. 이러한 문제들을 해결하고 추론 성능을 더욱 향상시키기 위해, 연구진은 소량의 콜드 스타트 데이터와 다단계 학습 파이프라인을 도입한 DeepSeek-R1을 개발했습니다.
DeepSeek-R1의 학습 과정은 다음과 같은 단계로 구성됩니다. 먼저 수천 개의 콜드 스타트 데이터를 수집하여 DeepSeek-V3-Base 모델을 미세 조정합니다. 이후 DeepSeek-R1-Zero와 유사한 추론 중심의 강화학습을 수행합니다. RL 과정이 수렴에 가까워지면, RL 체크포인트에서 거부 샘플링(rejection sampling)을 통해 새로운 SFT(Supervised Fine-Tuning) 데이터를 생성합니다. 이 데이터는 글쓰기, 사실 기반 질의응답, 자기 인식 등의 영역에서 DeepSeek-V3의 지도 학습 데이터와 결합됩니다. 이렇게 생성된 데이터로 DeepSeek-V3-Base 모델을 재학습시킵니다. 마지막으로, 모든 시나리오의 프롬프트를 고려한 추가적인 RL 과정을 거칩니다.
이러한 다단계 학습 과정을 거쳐 최종적으로 DeepSeek-R1이라 명명된 체크포인트를 얻었으며, 이는 OpenAI-o1-1217와 대등한 성능을 달성했습니다. 연구진은 더 나아가 DeepSeek-R1의 지식을 더 작은 밀집 모델로 전달하는 증류 실험을 진행했습니다. Qwen2.5-32B를 기본 모델로 사용했을 때, DeepSeek-R1로부터의 직접적인 증류가 해당 모델에 RL을 적용하는 것보다 더 나은 성능을 보여주었습니다. 이는 더 큰 기본 모델이 발견한 추론 패턴이 추론 능력 향상에 매우 중요하다는 것을 입증합니다.
연구진은 Qwen과 Llama 시리즈의 증류 모델들을 오픈소스로 공개했습니다. 특히 주목할 만한 점은 14B 증류 모델이 최신 오픈소스 모델인 QwQ-32B-Preview를 큰 차이로 능가했으며, 32B와 70B 증류 모델들은 밀집 모델들 중에서 추론 벤치마크에서 새로운 기록을 수립했다는 것입니다. 본 논문의 주요 기여는 크게 두 가지 영역에서 이루어졌습니다. 첫째는 대규모 기본 모델에 대한 사후 학습 분야에서의 혁신적인 접근이며, 둘째는 작은 모델로의 효과적인 지식 증류 방법론입니다.
사후 학습 측면에서, 연구진은 기존의 지도 학습 없이 순수하게 강화학습만을 활용하여 기본 모델의 성능을 향상시키는 혁신적인 방법을 제시했습니다. DeepSeek-R1-Zero의 개발 과정에서 모델은 자체 검증, 반성, 긴 사고 연쇄(Chain-of-Thought) 생성과 같은 고급 추론 능력을 자연스럽게 발전시켰습니다. 이는 언어 모델의 추론 능력이 지도 학습 없이도 순수한 강화학습만으로 향상될 수 있다는 것을 입증한 최초의 공개 연구라는 점에서 큰 의의가 있습니다.
DeepSeek-R1의 개발 파이프라인은 더 나은 추론 패턴을 발견하고 인간의 선호도와 정렬하기 위한 두 단계의 강화학습과, 모델의 추론 및 비추론 능력의 기반이 되는 두 단계의 지도 학습으로 구성됩니다. 이러한 체계적인 접근은 산업계에서 더 우수한 모델을 개발하는 데 중요한 지침이 될 것으로 기대됩니다.
증류 측면에서는 큰 모델의 추론 패턴을 작은 모델로 전달하는 것이, 작은 모델에 직접 강화학습을 적용하는 것보다 더 효과적임을 입증했습니다. DeepSeek-R1의 오픈소스 공개와 API 제공은 연구 커뮤니티가 앞으로 더 작은 모델들을 효과적으로 개선하는 데 큰 도움이 될 것입니다.
연구진은 DeepSeek-R1이 생성한 추론 데이터를 활용하여 연구 커뮤니티에서 널리 사용되는 여러 밀집 모델들을 미세 조정했습니다. 평가 결과에 따르면, 증류된 작은 밀집 모델들은 벤치마크 테스트에서 놀라운 성능을 보여주었습니다. 예를 들어, DeepSeek-R1-Distill-Qwen-7B는 AIME 2024에서 55.5%의 정확도를 달성하여 QwQ-32B-Preview를 능가했으며, DeepSeek-R1-Distill-Qwen-32B는 AIME 2024에서 72.6%, MATH-500에서 94.3%, LiveCodeBench에서 57.2%의 우수한 성과를 거두어 이전의 오픈소스 모델들을 크게 앞서고 o1-mini와 비견될 만한 성능을 보여주었습니다. 연구진이 수행한 평가 결과는 DeepSeek-R1의 우수성을 다양한 측면에서 입증했습니다. 추론 작업에서 DeepSeek-R1은 AIME 2024에서 79.8%의 Pass@1 점수를 달성하여 OpenAI-o1-1217을 소폭 앞섰으며, MATH-500에서는 97.3%라는 인상적인 점수를 기록하여 다른 모델들을 크게 앞섰습니다.
코딩 관련 작업에서도 DeepSeek-R1은 뛰어난 성과를 보여주었습니다. Codeforces에서 2,029의 Elo 레이팅을 달성하여 인간 참가자의 96.3%를 능가하는 전문가 수준의 실력을 입증했습니다. 엔지니어링 관련 작업에서는 DeepSeek-V3보다 약간 더 나은 성능을 보여주어, 실제 개발 작업에서도 유용하게 활용될 수 있음을 시사했습니다.
지식 평가 측면에서 DeepSeek-R1은 MMLU에서 90.8%, MMLU-Pro에서 84.0%, GPQA Diamond에서 71.5%를 달성하여 DeepSeek-V3를 크게 앞섰습니다. OpenAI-o1-1217에는 약간 못 미치는 성능이었지만, 다른 비공개 모델들을 능가하며 교육 관련 작업에서의 경쟁력을 입증했습니다. 사실 기반 벤치마크인 SimpleQA에서도 DeepSeek-V3를 앞서는 성능을 보여주었습니다.
그 외의 영역에서도 DeepSeek-R1은 창의적 글쓰기, 일반 질의응답, 편집, 요약 등 다양한 작업에서 탁월한 성능을 보여주었습니다. AlpacaEval 2.0에서 87.6%의 길이 제어 승률을, ArenaHard에서 92.3%의 승률을 달성하여 시험 외의 일반적인 질의에 대한 뛰어난 처리 능력을 입증했습니다. 특히 긴 문맥 이해가 필요한 작업에서 DeepSeek-V3를 크게 앞서는 성능을 보여주어, 복잡하고 긴 내용의 처리에도 탁월한 능력을 갖추고 있음을 확인했습니다.
접근 방식
DeepSeek-R1의 연구진은 언어 모델의 추론 능력 향상을 위해 기존과는 다른 혁신적인 접근 방식을 제시했습니다. 기존 연구들이 대규모 지도 학습 데이터에 크게 의존했던 것과 달리, 이 연구에서는 강화학습을 통해 모델의 추론 능력을 획기적으로 향상시킬 수 있음을 입증했습니다.
연구진이 제시한 접근 방식은 크게 세 가지 핵심 요소로 구성됩니다. 첫째, DeepSeek-R1-Zero는 지도 학습 데이터를 전혀 사용하지 않고 기본 모델에 직접 강화학습을 적용하는 방식입니다. 이는 언어 모델이 순수하게 강화학습만으로도 추론 능력을 발전시킬 수 있다는 것을 보여주는 혁신적인 시도입니다.
둘째, DeepSeek-R1은 수천 개의 장문형 Chain-of-Thought(CoT) 예시를 활용한 콜드 스타트 데이터로 미세 조정된 체크포인트에서 시작하여 강화학습을 적용하는 방식입니다. 이는 기존의 지도 학습과 강화학습의 장점을 결합한 접근으로, 모델의 추론 능력을 더욱 체계적으로 향상시킬 수 있습니다.
셋째, 연구진은 DeepSeek-R1이 획득한 추론 능력을 더 작은 밀집 모델로 전달하는 증류 기술을 개발했습니다. 이를 통해 계산 자원의 제약이 있는 환경에서도 향상된 추론 능력을 활용할 수 있게 되었습니다. 이러한 다면적 접근은 언어 모델의 추론 능력 향상을 위한 새로운 패러다임을 제시합니다.
강화학습 기반의 추론 능력 향상 방법론
DeepSeek-R1의 접근 방식은 기존 언어 모델 학습 패러다임에 중요한 변화를 가져옵니다. 연구진은 대규모 지도 학습 데이터에 의존하지 않고도 강화학습만으로 모델의 추론 능력을 향상시킬 수 있다는 혁신적인 가설을 입증했습니다. 이는 언어 모델 발전에 있어 새로운 지평을 여는 중요한 발견입니다.
DeepSeek-R1-Zero는 이러한 접근의 첫 번째 구현체로, 완전히 새로운 방식의 학습 패러다임을 보여줍니다. 기본 모델에 직접 강화학습을 적용함으로써, 지도 학습 데이터 없이도 모델이 자체적으로 추론 능력을 발전시킬 수 있음을 증명했습니다. 이는 언어 모델이 인간의 직접적인 지도 없이도 복잡한 추론 과제를 해결하는 방법을 스스로 학습할 수 있다는 것을 보여주는 중요한 성과입니다.
DeepSeek-R1은 이러한 순수 강화학습 접근의 한계를 보완하기 위해 개발되었습니다. 수천 개의 장문형 Chain-of-Thought(CoT) 예시를 활용한 콜드 스타트 단계를 도입함으로써, 모델이 보다 체계적이고 일관된 방식으로 추론 능력을 발전시킬 수 있게 되었습니다. 이 콜드 스타트 데이터는 모델이 강화학습을 시작하기 전에 기본적인 추론 패턴을 학습할 수 있게 해주는 초기 지식 기반으로 작용합니다.
마지막으로, 연구진은 DeepSeek-R1의 추론 능력을 더 작은 모델로 전달하는 증류 과정을 개발했습니다. 이는 대규모 모델이 획득한 고도화된 추론 능력을 계산 자원의 제약이 있는 환경에서도 활용할 수 있게 해주는 실용적인 해결책입니다. 이러한 증류 과정을 통해 다양한 규모의 모델들이 향상된 추론 능력을 공유할 수 있게 되었습니다.
강화학습 기반 추론 능력 향상의 기술적 구현
DeepSeek-R1의 접근 방식은 기존 언어 모델 학습의 패러다임을 근본적으로 변화시키는 세 가지 혁신적인 기술적 구현을 제시합니다. 이러한 구현은 지도 학습에 대한 의존도를 획기적으로 줄이면서도 모델의 추론 능력을 효과적으로 향상시킬 수 있음을 보여줍니다.
DeepSeek-R1-Zero는 기본 모델에 직접 강화학습을 적용하는 방식으로, 지도 학습 데이터 없이도 모델이 자체적으로 추론 능력을 발전시킬 수 있다는 것을 입증합니다. 이는 기존의 지도 학습 기반 접근 방식과는 완전히 다른 패러다임으로, 모델이 시행착오를 통해 스스로 추론 전략을 발견하고 개선할 수 있게 합니다. 이러한 접근은 특히 복잡한 수학적 추론이나 논리적 문제 해결과 같은 고차원적 사고가 필요한 작업에서 효과적임이 입증되었습니다.
DeepSeek-R1은 이러한 순수 강화학습 접근의 한계를 극복하기 위해, 소량의 콜드 스타트 데이터를 활용한 초기 학습 단계를 도입했습니다. 수천 개의 장문형 Chain-of-Thought(CoT) 예시를 통해 기본적인 추론 패턴을 학습한 후, 강화학습을 통해 이를 더욱 발전시키는 방식을 채택했습니다. 이는 완전한 무감독 학습과 전통적인 지도 학습의 중간 지점을 제시하는 혁신적인 접근입니다.
마지막으로, 연구진은 DeepSeek-R1의 추론 능력을 더 작은 밀집 모델로 전달하는 증류 기술을 개발했습니다. 이는 대규모 모델이 획득한 복잡한 추론 패턴을 더 작은 모델이 효율적으로 학습할 수 있게 하는 방법론입니다. 이러한 증류 과정은 단순한 지식 전달을 넘어, 추론 과정의 핵심적인 패턴과 전략을 압축된 형태로 전달할 수 있게 합니다.
이러한 세 가지 접근 방식의 통합은 언어 모델의 추론 능력 향상을 위한 새로운 표준을 제시합니다. 특히 강화학습을 중심으로 한 이러한 접근은 모델이 더 자연스럽고 효과적인 방식으로 추론 능력을 발전시킬 수 있게 하며, 이는 기존의 지도 학습 중심 접근이 가진 한계를 극복하는 중요한 진전을 보여줍니다.
DeepSeek-R1-Zero: 기본 모델에 대한 강화학습
DeepSeek-R1-Zero는 지도 학습 데이터 없이 순수하게 강화학습만을 활용하여 언어 모델의 추론 능력을 향상시키는 혁신적인 접근 방식을 제시합니다. 이전 연구들이 보여준 강화학습의 효과성을 기반으로, 연구진은 지도 데이터의 의존성을 완전히 제거하고 모델이 자체적으로 진화할 수 있는 가능성을 탐구했습니다.
그룹 상대 정책 최적화 (GRPO)
강화학습 훈련 비용을 절감하기 위해, 연구진은 Shao와 연구진이 제안한 그룹 상대 정책 최적화(Group Relative Policy Optimization, GRPO)를 채택했습니다. GRPO의 핵심적인 특징은 정책 모델과 동일한 크기의 critic 모델을 사용하지 않고, 대신 그룹 점수를 통해 기준선을 추정한다는 점입니다.
GRPO의 수학적 정의는 다음과 같습니다. 각 질문 q에 대해, GRPO는 이전 정책 π_θ_old로부터 G개의 출력 {o₁, o₂, …, oG}을 샘플링하고, 다음의 목적 함수를 최대화하여 정책 모델 π_θ를 최적화합니다.
\[J_{GRPO}(\theta) = E[q \sim P(Q), \{o_i\}_{i=1}^G \sim \pi_{\theta_{old}}(O \vert q)] \frac{1}{G}\sum_{i=1}^G\left(\min\left(\frac{\pi_\theta(o_i \vert q)}{\pi_{\theta_{old}}(o_i \vert q)}A_i,\text{clip}\left(\frac{\pi_\theta(o_i \vert q)}{\pi_{\theta_{old}}(o_i \vert q)},1-\varepsilon,1+\varepsilon\right)A_i\right)-\beta D_{KL}(\pi_\theta \vert \vert \pi_{ref})\right)\]여기서 $\varepsilon$과 $\beta$는 하이퍼파라미터이며, $A_i$는 각 그룹 내 출력에 해당하는 보상 ${r_1, r_2, \ldots, r_G}$을 사용하여 계산되는 이점(advantage)입니다.
\[A_i = \frac{r_i - \text{mean}(\{r_1,r_2,\cdots,r_G\})}{\text{std}(\{r_1,r_2,\cdots,r_G\})}\]보상 모델링
DeepSeek-R1-Zero의 훈련에서는 규칙 기반 보상 시스템을 채택했으며, 이는 크게 두 가지 유형의 보상으로 구성됩니다.
-
정확도 보상: 응답의 정확성을 평가합니다. 예를 들어, 수학 문제의 경우 모델은 지정된 형식(예: 박스 안)으로 최종 답안을 제공해야 하며, 이를 통해 규칙 기반 검증이 가능합니다. LeetCode 문제의 경우에는 미리 정의된 테스트 케이스를 기반으로 컴파일러가 피드백을 생성합니다.
-
형식 보상: 모델이 사고 과정을 ‘<think></think>’ 태그 사이에 배치하도록 유도하는 형식적 보상을 적용합니다.
연구진은 신경망 보상 모델을 사용하지 않았는데, 이는 대규모 강화학습 과정에서 보상 해킹(reward hacking)이 발생할 수 있고, 보상 모델의 재훈련이 추가적인 훈련 리소스를 필요로 하며 전체 훈련 파이프라인을 복잡하게 만들 수 있기 때문입니다.
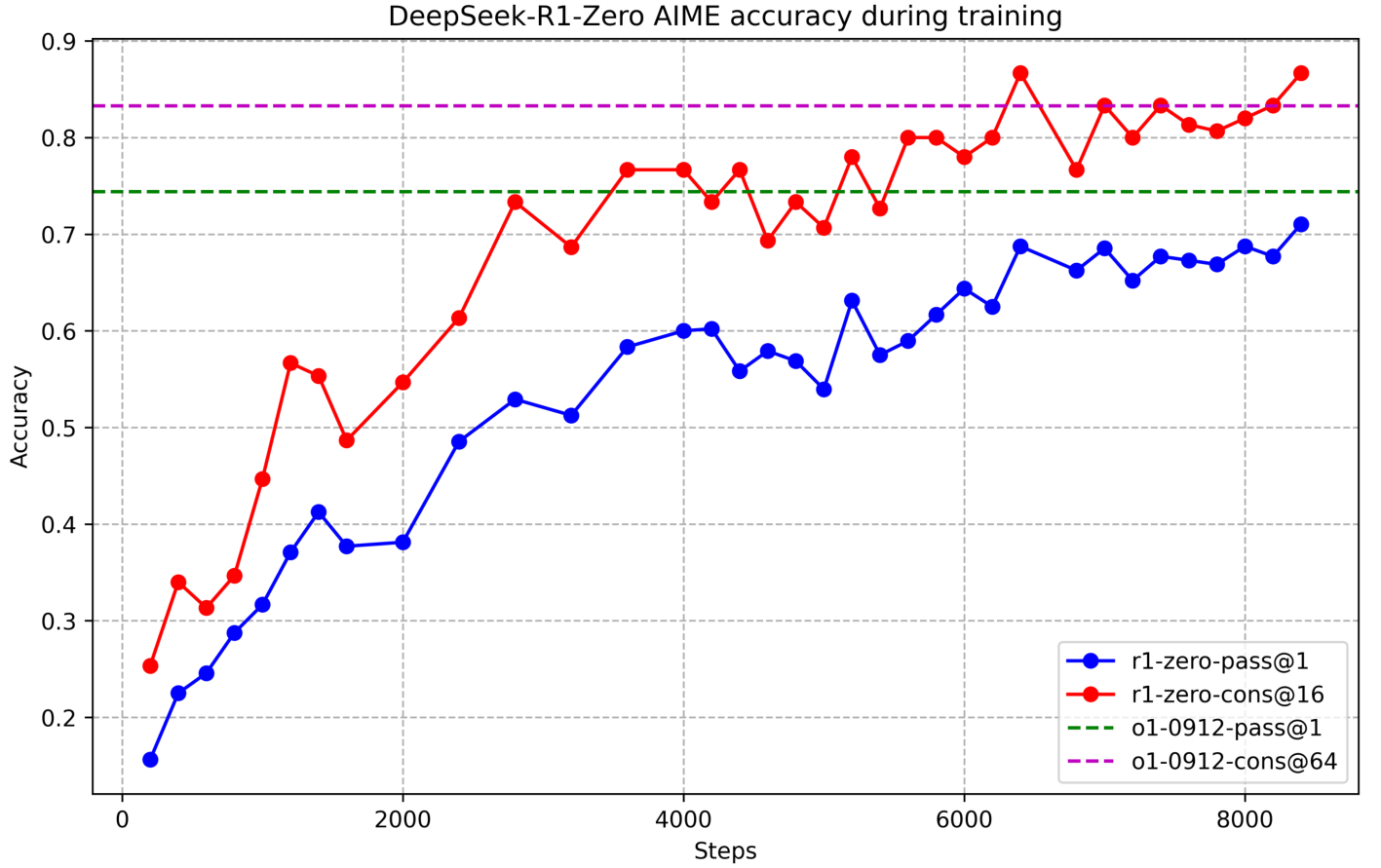
위 그래프는 DeepSeek-R1-Zero의 AIME 2024 벤치마크에서의 성능 향상을 보여줍니다. 강화학습이 진행됨에 따라 모델의 성능이 꾸준히 향상되어, pass@1 점수가 초기 15.6%에서 71.0%로 크게 증가했으며, 이는 OpenAI-o1-0912와 비견될 만한 수준입니다.
훈련 템플릿과 자기 진화 과정
DeepSeek-R1-Zero의 훈련을 위해 연구진은 기본 모델이 지정된 지침을 따르도록 하는 간단한 템플릿을 설계했습니다. 이 템플릿은 모델이 먼저 추론 과정을 생성하고 그 다음 최종 답안을 제시하도록 구조화되어 있습니다. 연구진은 반성적 추론이나 특정 문제 해결 전략의 강제와 같은 내용 관련 제약을 의도적으로 배제했는데, 이는 강화학습 과정에서 모델의 자연스러운 발전을 정확하게 관찰하기 위함입니다.
DeepSeek-R1-Zero의 자기 진화 과정은 강화학습이 어떻게 모델의 추론 능력을 자율적으로 향상시킬 수 있는지를 보여주는 흥미로운 사례입니다. 기본 모델에서 직접 강화학습을 시작함으로써, 지도 학습 단계의 영향 없이 모델의 발전 과정을 면밀히 관찰할 수 있었습니다.
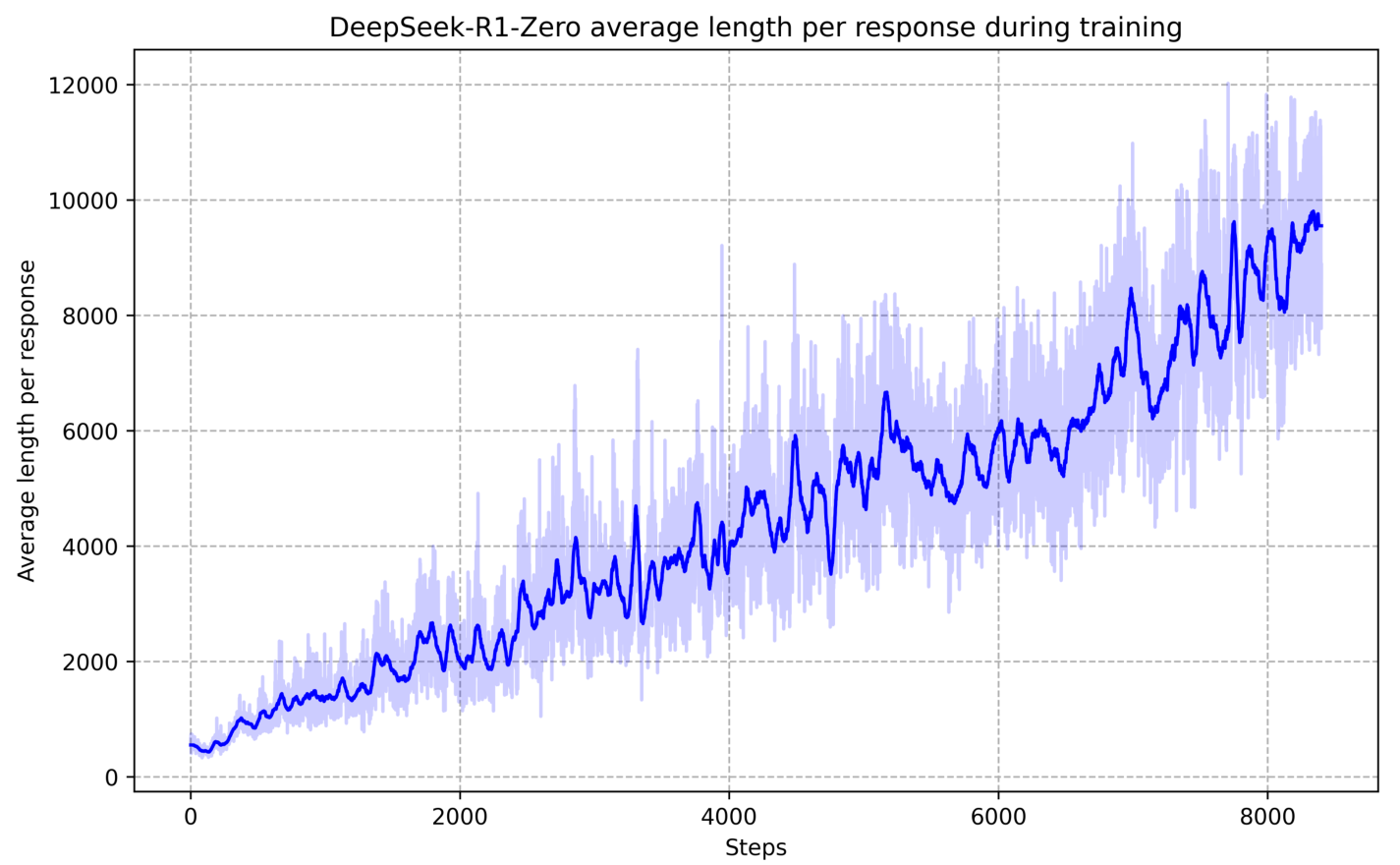
위 그래프에서 볼 수 있듯이, DeepSeek-R1-Zero의 사고 시간은 훈련 과정 전반에 걸쳐 지속적으로 향상되었습니다. 이는 외부의 조정 없이 모델 내부에서 자연스럽게 발생한 발전입니다. 모델은 수백에서 수천 개의 추론 토큰을 생성하며 더 깊이 있는 사고 과정을 탐색하고 정제하는 능력을 자연스럽게 획득했습니다.
이러한 자기 진화 과정에서 가장 주목할 만한 점은 테스트 시간 계산이 증가함에 따라 정교한 행동들이 자발적으로 출현했다는 것입니다. 예를 들어, 모델이 이전 단계를 재검토하고 재평가하는 반성적 사고나 문제 해결을 위한 대안적 접근 방식의 탐색과 같은 행동들이 자연스럽게 나타났습니다. 이러한 행동들은 명시적으로 프로그래밍된 것이 아니라, 모델이 강화학습 환경과 상호작용하면서 자발적으로 발전시킨 것입니다.
특히 흥미로운 현상은 모델의 중간 버전에서 관찰된 “아하 모멘트(Aha moment)”입니다. 이 단계에서 DeepSeek-R1-Zero는 초기 접근 방식을 재평가하면서 문제에 더 많은 사고 시간을 할애하는 방법을 학습했습니다. 이는 단순히 모델의 “아하 모멘트”일 뿐만 아니라, 연구자들에게도 강화학습의 잠재력을 보여주는 중요한 순간이었습니다. 모델에게 문제 해결 방법을 명시적으로 가르치는 대신, 적절한 인센티브만 제공하면 모델이 자율적으로 고급 문제 해결 전략을 개발할 수 있다는 것을 보여주는 강력한 증거입니다.
DeepSeek-R1-Zero의 성능과 한계점
DeepSeek-R1-Zero의 성능을 더 자세히 살펴보면, 다양한 추론 관련 벤치마크에서 인상적인 결과를 보여주었습니다. 특히 다수결 투표 방식을 적용했을 때 AIME 벤치마크에서의 성능이 71.0%에서 86.7%로 크게 향상되어 OpenAI-o1-0912의 성능을 뛰어넘었습니다. 이는 순수 강화학습만으로도 모델이 강력한 추론 능력을 획득할 수 있다는 것을 입증하는 중요한 성과입니다.
MATH-500과 GPQA Diamond와 같은 다른 벤치마크에서도 DeepSeek-R1-Zero는 경쟁력 있는 성능을 보여주었습니다. 특히 MATH-500에서 95.9%, GPQA Diamond에서 73.3%의 정확도를 달성했는데, 이는 지도 학습 없이도 복잡한 수학적 추론과 일반적인 문제 해결 능력을 효과적으로 습득할 수 있다는 것을 보여줍니다.
LiveCode Bench와 CodeForces와 같은 코딩 관련 벤치마크에서는 각각 50.0%의 pass@1 점수와 1444의 레이팅을 기록했습니다. 이러한 결과는 DeepSeek-R1-Zero가 프로그래밍 문제 해결에서도 상당한 능력을 보유하고 있음을 시사합니다.
그러나 DeepSeek-R1-Zero는 몇 가지 중요한 한계점도 보여주었습니다. 가장 두드러진 문제점은 추론 과정의 가독성이 떨어진다는 것입니다. 모델이 생성하는 설명이 때로는 비구조적이거나 이해하기 어려운 형태를 보였으며, 이는 실제 사용자들이 모델의 추론 과정을 따라가기 어렵게 만드는 요인이 되었습니다.
또한 언어 혼합(language mixing) 문제도 발견되었는데, 이는 모델이 동일한 추론 과정 내에서 여러 언어를 무분별하게 섞어 사용하는 현상을 말합니다. 이러한 문제점들은 모델의 실용성을 제한하는 요인이 되었으며, 이를 해결하기 위해 연구진은 인간 친화적인 콜드 스타트 데이터를 활용하는 DeepSeek-R1이라는 새로운 방법론을 탐구하게 되었습니다.
DeepSeek-R1: 콜드 스타트를 활용한 강화학습 기반 추론 능력 향상
DeepSeek-R1은 DeepSeek-R1-Zero의 성공적인 결과를 바탕으로, 두 가지 중요한 질문에 답하기 위해 개발되었습니다. 첫째, 소량의 고품질 데이터를 콜드 스타트로 활용하여 추론 성능을 더욱 향상시키거나 수렴을 가속화할 수 있는지, 둘째, 명확하고 일관된 사고 연쇄(Chain of Thought, CoT)를 생성하면서도 강력한 일반 능력을 보여주는 사용자 친화적 모델을 어떻게 훈련할 수 있는지에 대한 해답을 찾고자 했습니다.
이러한 목표를 달성하기 위해 DeepSeek-R1은 네 단계로 구성된 학습 파이프라인을 도입했습니다. 첫 번째 단계인 콜드 스타트에서는 DeepSeek-R1-Zero와 달리, 강화학습 초기의 불안정한 단계를 방지하기 위해 소량의 장문형 CoT 데이터를 수집하여 초기 RL 액터로 사용할 모델을 미세 조정합니다. 이러한 데이터는 다양한 방법을 통해 수집되었는데, 장문형 CoT를 예시로 한 퓨 샷 프롬프팅, 반성과 검증이 포함된 상세한 답변 생성을 위한 직접 프롬프팅, DeepSeek-R1-Zero 출력물의 가독성 있는 형식으로의 변환, 그리고 인간 주석자를 통한 후처리 정제 등이 포함됩니다.
콜드 스타트 데이터의 주요 장점은 크게 두 가지입니다. 첫째, 가독성 측면에서 DeepSeek-R1-Zero의 주요 한계점이었던 다중 언어 혼용이나 마크다운 형식 부재 등의 문제를 해결했습니다. DeepSeek-R1의 콜드 스타트 데이터는 각 응답의 마지막에 요약을 포함하고, 사용자 친화적이지 않은 응답을 필터링하는 등 읽기 쉬운 패턴을 설계했습니다. 출력 형식은 ‘|special_token| 추론 과정 |special_token| 요약’ 형태로 구조화되어 있어, 추론 과정은 질의에 대한 CoT를, 요약은 추론 결과를 정리하는 데 사용됩니다.
둘째, 인간의 사전 지식을 활용하여 신중하게 설계된 콜드 스타트 데이터 패턴은 DeepSeek-R1-Zero보다 더 나은 성능을 보여주었습니다. 연구진은 이러한 반복적 훈련 방식이 추론 모델 개발에 더 효과적이라고 판단했습니다. 이는 순수 강화학습만을 사용하는 것보다 인간의 직관과 전문성을 초기 단계에서 활용하는 것이 더 효율적일 수 있다는 것을 시사합니다.
추론 중심의 강화학습과 데이터 정제 과정
콜드 스타트 데이터로 DeepSeek-V3-Base를 미세 조정한 후, DeepSeek-R1은 DeepSeek-R1-Zero와 동일한 대규모 강화학습 훈련 과정을 적용합니다. 이 단계는 특히 코딩, 수학, 과학, 논리적 추론과 같이 명확한 해결책이 있는 추론 집약적 과제들에서 모델의 추론 능력을 향상시키는 데 중점을 둡니다.
훈련 과정에서 연구진은 CoT가 여러 언어가 혼합되는 현상을 보이는 것을 발견했는데, 이는 특히 RL 프롬프트가 다중 언어를 포함할 때 두드러졌습니다. 이 문제를 해결하기 위해 RL 훈련 중에 언어 일관성 보상을 도입했습니다. 이 보상은 CoT 내에서 목표 언어 단어의 비율로 계산됩니다. 비록 실험 결과 이러한 정렬이 모델의 성능을 약간 저하시키는 것으로 나타났지만, 이는 인간의 선호도와 일치하며 가독성을 향상시키는 효과가 있습니다.
최종적으로 연구진은 추론 과제의 정확도와 언어 일관성에 대한 보상을 직접 합산하여 최종 보상을 형성했으며, 이를 바탕으로 미세 조정된 모델에 대해 추론 과제에서 수렴에 도달할 때까지 RL 훈련을 진행했습니다.
거부 샘플링과 지도 학습 기반 미세 조정
추론 중심의 RL이 수렴한 후, 연구진은 해당 체크포인트를 활용하여 다음 라운드를 위한 SFT(Supervised Fine-Tuning) 데이터를 수집했습니다. 초기 콜드 스타트 데이터가 주로 추론에 초점을 맞췄던 것과 달리, 이 단계에서는 글쓰기, 역할 수행, 기타 일반적인 과제를 위한 데이터도 포함시켜 모델의 전반적인 능력을 향상시키고자 했습니다.
추론 관련 데이터의 경우, 이전 RL 훈련에서 얻은 체크포인트를 사용하여 거부 샘플링을 수행했습니다. 이전 단계에서는 규칙 기반 보상으로만 평가 가능한 데이터만을 포함했지만, 이 단계에서는 데이터셋을 확장하여 정답과 모델 예측을 DeepSeek-V3에 입력하여 판단하는 생성적 보상 모델을 활용한 데이터도 포함시켰습니다. 또한 모델 출력이 때로는 혼란스럽고 읽기 어려울 수 있기 때문에, 언어가 혼합된 사고 연쇄, 긴 단락, 코드 블록 등을 필터링했습니다. 각 프롬프트에 대해 여러 응답을 샘플링하고 정확한 것만을 보존하여, 총 60만 개의 추론 관련 훈련 샘플을 수집했습니다.
비추론 데이터 수집과 최종 강화학습 단계
비추론 데이터의 경우, DeepSeek-R1은 글쓰기, 사실 기반 질의응답, 자기 인식, 번역과 같은 작업을 위해 DeepSeek-V3 파이프라인을 채택하고 DeepSeek-V3의 SFT 데이터셋의 일부를 재활용했습니다. 특정 비추론 작업에서는 프롬프팅을 통해 DeepSeek-V3를 호출하여 질문에 답변하기 전에 잠재적인 사고 연쇄를 생성하도록 했습니다. 그러나 “hello”와 같은 간단한 쿼리에 대해서는 CoT 응답을 생성하지 않는 방식을 채택했습니다. 이러한 과정을 통해 약 20만 개의 비추론 관련 훈련 샘플을 수집했으며, 최종적으로 약 80만 개의 데이터 샘플로 DeepSeek-V3-Base를 2회의 에포크 동안 미세 조정했습니다.
마지막 단계에서는 모든 시나리오에 대한 강화학습을 수행하여 모델의 유용성과 안전성을 향상시키면서 동시에 추론 능력을 더욱 정교화했습니다. 이 과정에서는 다양한 보상 신호와 프롬프트 분포를 결합한 훈련 방식을 채택했습니다. 추론 데이터에 대해서는 DeepSeek-R1-Zero에서 사용된 방법론을 따라 수학, 코드, 논리적 추론 영역에서 규칙 기반 보상을 활용했습니다.
일반 데이터에 대해서는 복잡하고 미묘한 시나리오에서 인간의 선호도를 포착하기 위해 보상 모델을 사용했습니다. DeepSeek-V3 파이프라인을 기반으로 하여 유사한 선호도 쌍과 훈련 프롬프트의 분포를 채택했습니다. 유용성 평가에서는 최종 요약에만 초점을 맞추어 사용자에 대한 응답의 유용성과 관련성을 강조하면서 기본적인 추론 과정에 대한 간섭을 최소화했습니다.
안전성 평가에서는 추론 과정과 요약을 모두 포함한 모델의 전체 응답을 평가하여 생성 과정에서 발생할 수 있는 잠재적 위험, 편향, 또는 유해한 내용을 식별하고 완화하고자 했습니다. 이러한 보상 신호와 다양한 데이터 분포의 통합을 통해 추론 능력이 뛰어나면서도 유용성과 안전성을 우선시하는 모델을 훈련할 수 있었습니다.
증류: 작은 모델에 추론 능력 부여
DeepSeek-R1의 연구진은 더 효율적인 작은 모델들에게도 DeepSeek-R1과 같은 추론 능력을 부여하기 위해 직접적인 증류 방식을 적용했습니다. 앞서 설명한 방식으로 DeepSeek-R1을 통해 정제된 80만 개의 샘플을 활용하여 Qwen과 Llama와 같은 오픈소스 모델들을 미세 조정했습니다.
증류 실험에 사용된 기본 모델들은 Qwen2.5-Math-1.5B, Qwen2.5-Math-7B, Qwen2.5-14B, Qwen2.5-32B, Llama-3.1-8B, 그리고 Llama-3.3-70B-Instruct입니다. 연구진은 Llama-3.3을 선택한 이유로 Llama-3.1보다 약간 더 나은 추론 능력을 보여주었기 때문이라고 설명합니다. 증류된 모델들에 대해서는 지도 학습(SFT)만을 적용했으며, 강화학습 단계는 포함하지 않았습니다. 이는 강화학습을 포함할 경우 모델의 성능이 상당히 향상될 수 있음에도 불구하고, 연구진의 주요 목표가 증류 기법의 효과성을 입증하는 것이었기 때문입니다.
연구진은 다양한 벤치마크를 통해 모델들을 평가했습니다. 평가에 사용된 주요 벤치마크들은 MMLU, MMLU-Redux, MMLU-Pro, C-Eval, CMMLU, IFEval, FRAMES, GPQA Diamond, SimpleQA, C-SimpleQA, SWE-Bench Verified, Aider, LiveCodeBench, Codeforces, 중국 전국 고등학교 수학 올림피아드(CNMO 2024), 그리고 미국 수학 초청 시험(AIME 2024)입니다.
표준 벤치마크 외에도 연구진은 LLM을 심사관으로 활용하여 개방형 생성 과제에서도 모델들을 평가했습니다. 구체적으로 AlpacaEval 2.0과 Arena-Hard의 원래 구성을 따라 GPT-4-Turbo-1106을 심사관으로 활용한 쌍별 비교를 수행했습니다. 길이 편향을 피하기 위해 최종 요약만을 평가에 사용했습니다.
증류된 모델들의 경우, AIME 2024, MATH-500, GPQA Diamond, Codeforces, LiveCodeBench에서의 대표적인 결과를 보고했습니다. 평가 프롬프트와 관련하여, MMLU, DROP, GPQA Diamond, SimpleQA와 같은 표준 벤치마크들은 simple-evals 프레임워크의 프롬프트를 사용했습니다. MMLU-Redux의 경우 Zero-Eval 프롬프트 형식을 제로샷 설정으로 채택했습니다. MMLU-Pro, C-Eval, CLUE-WSC의 경우, 원래 프롬프트가 퓨샷이었기 때문에 제로샷 설정으로 약간 수정했습니다. 이는 퓨샷에서의 CoT가 DeepSeek-R1의 성능을 저하시킬 수 있기 때문입니다.
다른 데이터셋들은 제작자들이 제공한 기본 프롬프트와 함께 원래의 평가 프로토콜을 따랐습니다. 코드와 수학 벤치마크의 경우, HumanEval-Mul 데이터셋은 Python, Java, C++, C#, JavaScript, TypeScript, PHP, Bash 등 8개의 주요 프로그래밍 언어를 포함합니다. LiveCodeBench에서의 모델 성능은 CoT 형식을 사용하여 평가되었으며, 2024년 8월부터 2025년 1월 사이에 수집된 데이터를 활용했습니다.
Codeforces 데이터셋은 10개의 Div.2 대회의 문제들과 전문가가 제작한 테스트 케이스를 사용하여 평가되었으며, 이를 통해 예상 레이팅과 경쟁자 대비 백분위가 계산되었습니다. SWE-Bench verified 결과는 에이전트리스 프레임워크를 통해 얻었습니다. AIDER 관련 벤치마크는 “diff” 형식을 사용하여 측정되었습니다. DeepSeek-R1의 출력은 각 벤치마크에서 최대 32,768 토큰으로 제한되었습니다.
벤치마크 평가 결과와 기준 모델 비교
연구진은 DeepSeek-R1과 증류 모델들의 성능을 평가하기 위해 여러 강력한 기준 모델들과의 포괄적인 비교를 수행했습니다. 주요 기준 모델로는 DeepSeek-V3, Claude-Sonnet-3.5-1022, GPT-4o-0513, OpenAI-o1-mini, OpenAI-o1-1217이 포함되었습니다. 중국 본토에서 OpenAI-o1-1217 API에 접근하기 어려운 점을 고려하여, 이 모델의 성능은 공식 보고서를 기반으로 평가되었습니다. 증류 모델들의 경우, 오픈소스 모델인 QwQ-32B-Preview와도 비교가 이루어졌습니다.
평가 설정에서 모델들의 최대 생성 길이는 32,768 토큰으로 설정되었습니다. 연구진은 긴 출력을 생성하는 추론 모델들에 대해 탐욕적 디코딩(greedy decoding)을 사용할 경우 반복률이 높아지고 체크포인트 간 변동성이 크게 나타난다는 것을 발견했습니다. 이러한 문제를 해결하기 위해 pass@k 평가 방식을 기본으로 채택하고, 0이 아닌 온도 값을 사용하여 pass@1을 보고했습니다.
구체적으로, 샘플링 온도 0.6과 top-p 값 0.95를 사용하여 각 질문에 대해 k개의 응답을 생성했습니다(테스트 세트 크기에 따라 보통 4에서 64 사이). pass@1은 다음 수식으로 계산됩니다.
\[\mathrm{Pass}@1={\frac{1}{k}}\sum_{i=1}^{k}p_{i}\]여기서 $p_i$는 i번째 응답의 정확성을 나타냅니다. 이러한 방법은 더 신뢰할 수 있는 성능 추정치를 제공합니다. AIME 2024의 경우, 64개의 샘플을 사용한 합의(다수결 투표) 결과도 함께 보고되었으며, 이는 cons@64로 표시됩니다.
평가 결과를 살펴보면, 교육 지향적 지식 벤치마크인 MMLU, MMLU-Pro, GPQA Diamond에서 DeepSeek-R1은 DeepSeek-V3보다 우수한 성능을 보여주었습니다. 이러한 향상은 주로 대규모 강화학습을 통해 STEM 관련 문제에서 큰 성능 향상을 달성한 결과입니다. 또한 DeepSeek-R1은 긴 문맥 의존적 QA 작업인 FRAMES에서도 뛰어난 성과를 보여, AI 기반 검색과 데이터 분석 작업에서의 잠재력을 입증했습니다. 사실 기반 벤치마크인 SimpleQA에서 DeepSeek-R1은 DeepSeek-V3를 능가하는 성능을 보여주었으며, 이는 사실 기반 쿼리 처리 능력이 향상되었음을 입증합니다. OpenAI-o1이 이 벤치마크에서 GPT-4o를 앞선 것과 유사한 경향을 보여주었습니다. 그러나 중국어 SimpleQA 벤치마크에서는 DeepSeek-R1이 DeepSeek-V3보다 낮은 성능을 보였는데, 이는 주로 안전성 강화학습 이후 특정 쿼리에 대한 응답을 거부하는 경향 때문입니다. 안전성 강화학습을 적용하지 않았다면 70% 이상의 정확도를 달성할 수 있었을 것으로 분석됩니다.
DeepSeek-R1은 형식 지침 준수 능력을 평가하는 IF-Eval에서도 인상적인 결과를 보여주었습니다. 이러한 향상은 지도 학습(SFT)과 강화학습 훈련의 마지막 단계에서 지침 준수 데이터를 포함한 것과 관련이 있습니다. 또한 AlpacaEval2.0과 ArenaHard에서도 주목할 만한 성능을 보여주어, 글쓰기 작업과 개방형 질의응답에서의 강점을 입증했습니다. DeepSeek-V3를 크게 앞선 성능은 대규모 강화학습이 추론 능력뿐만 아니라 다양한 영역에서의 성능도 향상시킨다는 것을 보여줍니다.
특히 주목할 만한 점은 DeepSeek-R1이 생성하는 요약의 길이가 매우 간결하다는 것입니다. ArenaHard에서 평균 689 토큰, AlpacaEval 2.0에서 2,218자를 기록했는데, 이는 GPT 기반 평가에서 길이 편향을 도입하지 않으면서도 다양한 작업에서 강건한 성능을 보여준다는 것을 입증합니다.
수학 작업에서 DeepSeek-R1은 OpenAI-o1-1217와 대등한 성능을 보여주었으며, 다른 모델들을 큰 차이로 앞섰습니다. LiveCodeBench와 Codeforces와 같은 코딩 알고리즘 작업에서도 유사한 경향이 관찰되었으며, 추론 중심 모델들이 이러한 벤치마크들을 지배했습니다. 엔지니어링 중심의 코딩 작업에서는 OpenAI-o1-1217이 Aider에서 DeepSeek-R1을 앞섰지만, SWE Verified에서는 비슷한 성능을 보여주었습니다. 연구진은 관련 강화학습 훈련 데이터가 현재 매우 제한적이기 때문에, 다음 버전에서는 DeepSeek-R1의 엔지니어링 성능이 향상될 것으로 기대하고 있습니다.
증류 모델의 성능 평가 결과
증류 모델들의 성능 평가 결과를 살펴보면, DeepSeek-R1의 출력을 단순히 증류하는 것만으로도 효율적인 DeepSeek-R1-7B(DeepSeek-R1-Distill-Qwen-7B의 약칭, 이하 유사하게 표기)가 GPT-4o-0513와 같은 비추론 모델들을 전반적으로 능가하는 성과를 보여주었습니다. DeepSeek-R1-14B는 모든 평가 지표에서 QwQ-32B-Preview를 앞섰으며, DeepSeek-R1-32B와 DeepSeek-R1-70B는 대부분의 벤치마크에서 o1-mini를 크게 상회하는 성능을 달성했습니다.
구체적인 성능을 살펴보면, AIME 2024에서 DeepSeek-R1-Distill-Qwen-7B는 55.5%의 pass@1 점수를 기록했으며, DeepSeek-R1-Distill-Qwen-32B는 72.6%를 달성했습니다. MATH-500에서는 DeepSeek-R1-Distill-Qwen-32B가 94.3%의 인상적인 정확도를 보여주었습니다. LiveCodeBench에서도 DeepSeek-R1-Distill-Qwen-32B는 62.1%의 pass@1 점수를 기록하며 강력한 성능을 입증했습니다.
특히 주목할 만한 점은 Llama 기반의 증류 모델들도 우수한 성능을 보여주었다는 것입니다. DeepSeek-R1-Distill-Llama-70B는 AIME 2024에서 70.0%, MATH-500에서 94.5%, LiveCodeBench에서 65.2%의 높은 점수를 달성했습니다. 이는 증류 기법이 서로 다른 아키텍처의 모델들에도 효과적으로 적용될 수 있음을 보여줍니다.
연구진은 이러한 증류된 모델들에 강화학습을 적용할 경우 성능이 더욱 향상될 수 있다는 점을 발견했습니다. 그러나 본 연구에서는 증류 기법의 효과성을 명확하게 입증하기 위해 단순 SFT 증류 모델의 결과만을 제시했으며, 강화학습을 통한 추가적인 성능 향상 가능성은 향후 연구 커뮤니티의 탐구 과제로 남겨두었습니다.
증류와 강화학습의 비교 분석
DeepSeek-R1 연구진은 증류 방식과 강화학습 방식의 효과성을 비교하는 중요한 실험을 수행했습니다. 핵심적인 의문은 증류 없이도 논문에서 제시한 대규모 강화학습 훈련만으로 동등한 성능을 달성할 수 있는지였습니다. 이를 검증하기 위해 연구진은 Qwen-32B-Base 모델을 대상으로 수학, 코딩, STEM 데이터를 사용하여 10,000단계 이상의 대규모 강화학습을 진행했으며, 이를 통해 DeepSeek-R1-Zero-Qwen-32B를 개발했습니다.
실험 결과는 매우 흥미로운 통찰을 제공합니다. 32B 기본 모델은 대규모 강화학습 훈련 후에 QwQ-32B-Preview와 비슷한 수준의 성능을 달성했습니다. 그러나 DeepSeek-R1에서 증류된 DeepSeek-R1-Distill-Qwen-32B는 모든 벤치마크에서 DeepSeek-R1-Zero-Qwen-32B를 크게 앞섰습니다. 예를 들어, AIME-500에서 DeepSeek-R1-Distill-Qwen-32B는 72.6%의 정확도를 달성한 반면, DeepSeek-R1-Zero-Qwen-32B는 47.0%에 그쳤습니다.
이러한 결과는 두 가지 중요한 결론을 도출하게 합니다. 첫째, 더 강력한 모델의 지식을 작은 모델로 증류하는 방식이 매우 효과적이라는 것입니다. 반면, 작은 모델에 직접 대규모 강화학습을 적용하는 방식은 엄청난 계산 자원을 필요로 하면서도 증류 방식의 성능에 미치지 못할 수 있습니다. 둘째, 증류 전략이 경제적이고 효과적이지만, 지능의 한계를 뛰어넘기 위해서는 여전히 더 강력한 기본 모델과 대규모 강화학습이 필요할 수 있다는 점입니다.
실패 사례로부터의 교훈
DeepSeek-R1의 개발 초기 단계에서 연구진은 여러 가지 실패와 좌절을 경험했습니다. 이러한 실패 경험은 효과적인 추론 모델 개발을 위한 중요한 통찰을 제공하지만, 이것이 해당 접근 방식들이 근본적으로 부적절하다는 것을 의미하지는 않습니다.
프로세스 보상 모델(Process Reward Model, PRM)은 추론 작업에서 더 나은 접근 방식으로 모델을 유도하기 위한 합리적인 방법으로 보였습니다. 그러나 실제 적용 과정에서 세 가지 주요 한계점이 드러났습니다. 첫째, 일반적인 추론에서 세부적인 단계를 명시적으로 정의하는 것이 매우 어렵습니다. 둘째, 현재의 중간 단계가 올바른지 판단하는 것이 까다로운 과제입니다. 모델을 사용한 자동 주석은 만족스러운 결과를 내지 못했고, 수동 주석은 확장성이 떨어집니다. 셋째, 모델 기반 PRM을 도입하면 필연적으로 보상 해킹(reward hacking)이 발생하며, 보상 모델의 재훈련에는 추가적인 훈련 자원이 필요하고 전체 훈련 파이프라인이 복잡해집니다.
결론적으로, PRM은 모델이 생성한 상위 N개 응답의 순위를 매기거나 유도된 검색을 지원하는 데는 좋은 능력을 보여주지만, 연구진의 실험에서 대규모 강화학습 과정에서 발생하는 추가적인 계산 오버헤드에 비해 그 이점이 제한적이었습니다.
몬테카를로 트리 탐색(Monte Carlo Tree Search, MCTS)의 경우, AlphaGo와 AlphaZero의 성공에 영감을 받아 테스트 시간 계산 확장성을 향상시키기 위해 시도되었습니다. 이 접근 방식은 답변을 더 작은 부분으로 나누어 모델이 체계적으로 해결 공간을 탐색할 수 있게 합니다. 이를 위해 연구진은 모델이 검색에 필요한 특정 추론 단계에 해당하는 여러 태그를 생성하도록 프롬프팅했습니다. 훈련을 위해서는 먼저 수집된 프롬프트를 사용하여 사전 훈련된 가치 모델의 안내를 받아 MCTS를 통해 답을 찾고, 이후 결과로 얻은 질문-답변 쌍을 사용하여 액터 모델과 가치 모델을 훈련시키는 반복적인 과정을 거쳤습니다.
그러나 이 접근 방식은 훈련을 확장할 때 여러 가지 어려움에 직면했습니다. 첫째, 체스와 달리 토큰 생성은 지수적으로 더 큰 검색 공간을 가집니다. 이를 해결하기 위해 각 노드의 최대 확장 제한을 설정했지만, 이로 인해 모델이 지역 최적해에 갇히는 문제가 발생했습니다. 둘째, 가치 모델은 검색 과정의 각 단계를 안내하기 때문에 생성의 품질에 직접적인 영향을 미칩니다. 세밀한 가치 모델을 훈련하는 것은 본질적으로 어려운 작업이며, 이로 인해 모델이 반복적으로 성능을 향상시키는 것이 어려워졌습니다.
AlphaGo의 핵심적인 성공은 가치 모델을 통해 점진적으로 성능을 향상시키는 데 있었지만, 토큰 생성의 복잡성으로 인해 이러한 원리를 연구진의 설정에서 재현하기는 어려웠습니다. 결론적으로, MCTS는 사전 훈련된 가치 모델과 함께 사용될 때 추론 시간의 성능을 향상시킬 수 있지만, 자체 검색을 통한 반복적인 모델 성능 향상은 여전히 중요한 과제로 남아있습니다.
결론, 한계점 및 향후 연구 방향
본 연구는 강화학습을 통한 언어 모델의 추론 능력 향상이라는 도전적인 과제에 대한 여정을 공유합니다. DeepSeek-R1-Zero는 콜드 스타트 데이터 없이 순수한 강화학습만을 활용하여 다양한 과제에서 강력한 성능을 달성했습니다. 이를 발전시킨 DeepSeek-R1은 콜드 스타트 데이터와 반복적인 강화학습 미세 조정을 결합하여 OpenAI-o1-1217와 비견될 만한 성능을 보여주었습니다.
연구진은 더 나아가 이러한 추론 능력을 작은 밀집 모델로 전달하는 증류 기법을 탐구했습니다. DeepSeek-R1을 교사 모델로 활용하여 80만 개의 학습 샘플을 생성하고, 이를 통해 여러 작은 밀집 모델들을 미세 조정했습니다. 그 결과는 매우 고무적이었습니다. 특히 DeepSeek-R1-Distill-Qwen-1.5B는 AIME에서 28.9%, MATH에서 83.9%의 정확도를 달성하며 GPT-4o와 Claude-3.5-Sonnet을 능가했습니다. 다른 밀집 모델들도 동일한 기본 체크포인트를 사용한 기존의 지도 학습 기반 모델들을 크게 앞서는 인상적인 결과를 보여주었습니다.
그러나 DeepSeek-R1은 몇 가지 중요한 한계점도 가지고 있습니다. 첫째, 함수 호출, 다중 턴 대화, 복잡한 역할 수행, JSON 출력과 같은 과제에서는 DeepSeek-V3에 비해 성능이 부족합니다. 연구진은 이러한 영역에서 Chain-of-Thought가 어떻게 활용될 수 있는지 탐구할 계획입니다.
둘째, 현재 DeepSeek-R1은 중국어와 영어에 최적화되어 있어 다른 언어를 처리할 때 언어 혼합 문제가 발생할 수 있습니다. 예를 들어, 영어나 중국어가 아닌 언어로 질의가 들어와도 영어로 추론하고 응답하는 경향이 있습니다. 이는 향후 업데이트에서 해결해야 할 중요한 과제입니다.
셋째, 프롬프트 엔지니어링 측면에서 DeepSeek-R1은 프롬프트에 민감한 특성을 보입니다. 특히 퓨 샷 프롬프팅은 오히려 성능을 저하시키는 것으로 관찰되었습니다. 따라서 사용자들에게는 제로샷 설정에서 문제를 직접 설명하고 출력 형식을 지정하는 방식을 권장합니다.
마지막으로, 소프트웨어 엔지니어링 과제에서는 긴 평가 시간으로 인해 대규모 강화학습의 적용이 제한적이었습니다. 이로 인해 DeepSeek-R1은 소프트웨어 엔지니어링 벤치마크에서 DeepSeek-V3에 비해 큰 성능 향상을 보여주지 못했습니다. 연구진은 이를 해결하기 위해 소프트웨어 엔지니어링 데이터에 대한 거부 샘플링을 구현하거나 강화학습 과정에서 비동기 평가를 도입하여 효율성을 개선할 계획입니다.
References
Subscribe via RSS