DeepSeek-V3 Technical Report
by DeepSeek AI
TL;DR
이 연구를 시작하게 된 배경과 동기는 무엇입니까?
대규모 언어 모델의 성능 향상과 효율적인 학습이 AI 연구의 핵심 과제로 대두되고 있습니다. 특히 모델의 크기가 커질수록 학습 비용과 추론 효율성이 중요한 문제로 부각되었습니다. 기존의 밀집 모델들은 파라미터 수가 증가할수록 학습과 추론에 막대한 컴퓨팅 자원이 필요했으며, 이는 확장성의 한계를 드러냈습니다. 이러한 배경에서 DeepSeek-V3 연구진은 Mixture-of-Experts (MoE) 아키텍처를 활용하여 모델의 성능은 유지하면서도 계산 효율성을 크게 향상시킬 수 있는 방법을 모색하게 되었습니다.
이 연구에서 제시하는 새로운 해결 방법은 무엇입니까?
DeepSeek-V3는 세 가지 주요 혁신을 제시합니다. 첫째, 보조 손실 없는 로드 밸런싱 전략을 도입하여 MoE 모델의 전문가 활용을 최적화했습니다. 이는 전문가들이 자연스럽게 특정 도메인에 특화될 수 있도록 하면서도 계산 부하의 균형을 유지합니다. 둘째, Multi-Token Prediction (MTP) 학습 목표를 도입하여 모델이 여러 미래 토큰을 동시에 예측할 수 있게 했습니다. 셋째, FP8 혼합 정밀도 프레임워크를 구현하여 학습 효율성을 크게 향상시켰습니다.
제안된 방법은 어떻게 구현되었습니까?
DeepSeek-V3는 총 671B 파라미터를 가진 MoE 모델로, 각 토큰 처리 시 37B 파라미터만이 활성화됩니다. 모델은 Multi-head Latent Attention (MLA)과 DeepSeekMoE 아키텍처를 기반으로 하며, 14.8T 토큰으로 사전 학습되었습니다. 구현 과정에서는 2048개의 NVIDIA H800 GPU를 활용했으며, 16-way 파이프라인 병렬화, 64-way 전문가 병렬화, 그리고 ZeRO-1 데이터 병렬화를 적용했습니다. 특히 DualPipe라는 혁신적인 파이프라인 병렬화 알고리즘을 도입하여 계산과 통신의 효율적인 오버랩을 달성했습니다.
이 연구의 결과가 가지는 의미는 무엇입니까?
DeepSeek-V3는 현재 이용 가능한 오픈소스 모델 중 가장 강력한 성능을 보여주며, GPT-4와 Claude-3.5와 같은 주요 비공개 모델들과 대등한 수준의 성능을 달성했습니다. 특히 MMLU, DROP, HumanEval 등 다양한 벤치마크에서 우수한 결과를 보여주었습니다. 더욱 중요한 것은, 이러한 성능을 단 2.788M H800 GPU 시간이라는 매우 효율적인 학습 비용으로 달성했다는 점입니다. 이는 대규모 언어 모델의 개발이 더 경제적이고 접근 가능해질 수 있다는 가능성을 제시합니다. 또한 이 연구는 MoE 아키텍처와 효율적인 학습 전략이 AI 모델의 미래 발전 방향이 될 수 있음을 시사합니다.
DeepSeek-V3 기술 보고서
DeepSeek-V3는 총 671B 파라미터를 가진 강력한 Mixture-of-Experts (MoE) 언어 모델로, 각 토큰 처리 시 37B 파라미터가 활성화됩니다. 이 모델은 효율적인 추론과 비용 효과적인 학습을 위해 DeepSeek-V2에서 검증된 Multi-head Latent Attention (MLA)과 DeepSeekMoE 아키텍처를 채택했습니다. 특히 DeepSeek-V3는 로드 밸런싱을 위한 보조 손실 없는 전략을 최초로 도입하고, 더 강력한 성능을 위한 멀티 토큰 예측 학습 목표를 설정했습니다.
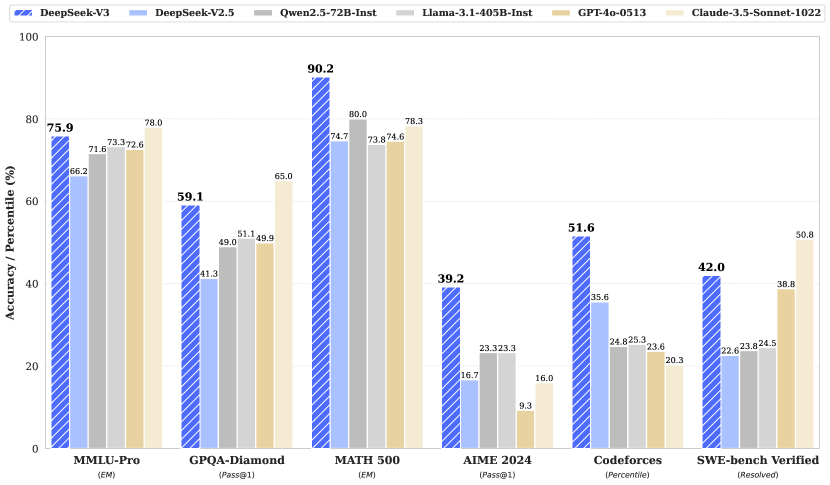
위 그래프는 DeepSeek-V3와 다른 모델들의 벤치마크 성능을 보여줍니다. MMLU-Pro, GPQA-Diamond, MATH 500, AIME 2024, Codeforces, SWE-bench Verified 등 다양한 AI/ML 작업에서 DeepSeek-V3가 대부분의 작업에서 다른 모델들을 능가하는 우수한 성능을 보여주고 있습니다.
DeepSeek-V3는 14.8조 개의 다양하고 고품질 토큰으로 사전 학습을 진행했으며, 이후 지도 학습 미세조정과 강화학습 단계를 거쳐 모델의 능력을 최대한 활용했습니다. 포괄적인 평가 결과, DeepSeek-V3는 다른 오픈소스 모델들을 능가하고 주요 비공개 모델들과 비슷한 수준의 성능을 달성했습니다.
특히 주목할 만한 점은 DeepSeek-V3의 효율적인 학습 과정입니다. 전체 학습에 단 2.788M H800 GPU 시간만이 소요되었으며, 학습 과정이 매우 안정적이었습니다. 전체 학습 과정에서 복구 불가능한 손실 급증이나 롤백이 전혀 발생하지 않았습니다. 모델 체크포인트는 GitHub 저장소에서 공개되어 있습니다.
이 연구의 주요 기여는 크게 세 가지 영역으로 나눌 수 있습니다. 첫째, 아키텍처 측면에서 혁신적인 로드 밸런싱 전략과 학습 목표를 도입했습니다. 둘째, 사전 학습 과정에서 궁극적인 학습 효율성을 달성했습니다. 마지막으로, DeepSeek-R1 시리즈로부터의 지식 증류를 통해 모델의 추론 능력을 향상시켰습니다.
DeepSeek-V3의 아키텍처
DeepSeek-V3는 효율적인 추론과 경제적인 학습을 위해 Multi-head Latent Attention (MLA)과 DeepSeekMoE를 핵심 아키텍처로 채택했습니다. 또한 평가 벤치마크에서 전반적인 성능을 향상시키기 위해 Multi-Token Prediction (MTP) 학습 목표를 도입했습니다.
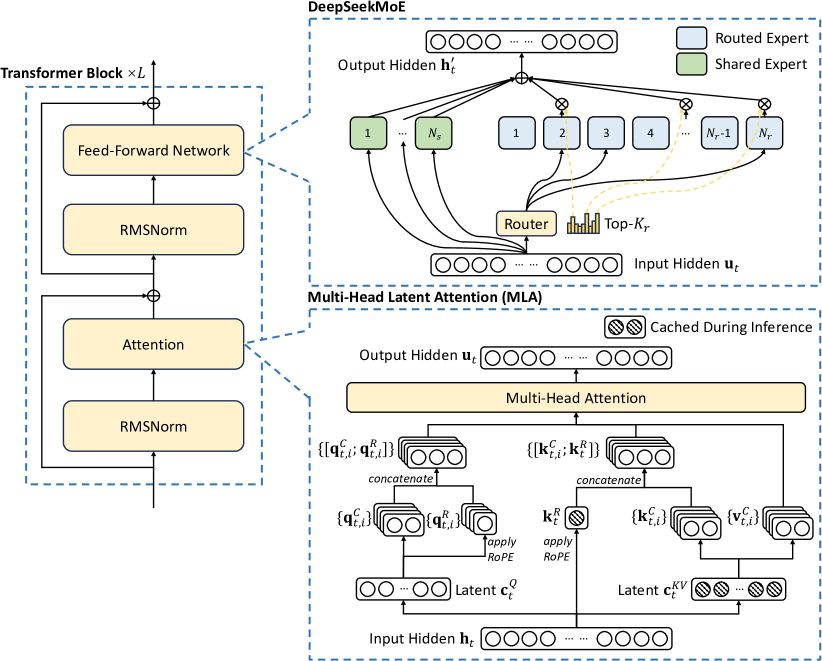
위 그림은 DeepSeek-V3의 기본 아키텍처를 보여줍니다. Feed-Forward Network, RMSNorm, 어텐션, 그리고 라우터가 주요 구성 요소이며, MLA와 DeepSeekMoE를 활용하여 입력 히든 피처를 처리하고 출력 히든 피처를 생성합니다.
Multi-head Latent Attention
DeepSeek-V3는 MLA 아키텍처를 채택했습니다. $d$를 임베딩 차원, $n_h$를 어텐션 헤드 수, $d_h$를 헤드당 차원, 그리고 $\mathbf{h}_t \in \mathbb{R}^d$를 주어진 어텐션 레이어에서 $t$번째 토큰의 어텐션 입력이라고 할 때, MLA의 핵심은 추론 중 Key-Value (KV) 캐시를 줄이기 위한 어텐션 키와 밸류의 저차원 결합 압축입니다.
\[\mathbf{c}_t^{KV} = W^{DKV}\mathbf{h}_t\] \[[\mathbf{k}_{t,1}^{C};\mathbf{k}_{t,2}^{C};...;\mathbf{k}_{t,n_h}^{C}]=\mathbf{k}_{t}^{C} = W^{UK}\mathbf{c}_{t}^{KV}\] \[\mathbf{k}_{t}^{R} = \operatorname{RoPE}(W^{KR}\mathbf{h}_{t})\] \[\mathbf{k}_{t,i} = [\mathbf{k}_{t,i}^{C};\mathbf{k}_{t}^{R}]\]여기서 $\mathbf{c}_t^{KV} \in \mathbb{R}^{d_c}$는 키와 밸류를 위한 압축된 잠재 벡터이고, $d_c(\ll d_hn_h)$는 KV 압축 차원을 나타냅니다. MLA에서는 생성 중에 파란색으로 표시된 벡터들($\mathbf{c}_t^{KV}$와 $\mathbf{k}_t^R$)만 캐시하면 되므로, 표준 Multi-Head Attention (MHA)와 비슷한 성능을 유지하면서도 KV 캐시를 크게 줄일 수 있습니다.
어텐션 쿼리에 대해서도 학습 중 활성화 메모리를 줄이기 위해 저차원 압축을 수행합니다.
\[\mathbf{c}_t^Q = W^{DQ}\mathbf{h}_t\] \[[\mathbf{q}_{t,1}^{C};\mathbf{q}_{t,2}^{C};...;\mathbf{q}_{t,n_h}^{C}]=\mathbf{q}_{t}^{C} = W^{UQ}\mathbf{c}_{t}^{Q}\] \[[\mathbf{q}_{t,1}^{R};\mathbf{q}_{t,2}^{R};...;\mathbf{q}_{t,n_h}^{R}]=\mathbf{q}_{t}^{R} = \operatorname{RoPE}(W^{QR}\mathbf{c}_{t}^{Q})\] \[\mathbf{q}_{t,i} = [\mathbf{q}_{t,i}^{C};\mathbf{q}_{t,i}^{R}]\]최종적으로 어텐션 쿼리($\mathbf{q}_{t,i}$), 키($\mathbf{k}_{j,i}$), 밸류($\mathbf{v}_{j,i}^{C}$)를 결합하여 최종 어텐션 출력 $\mathbf{u}_t$를 생성합니다.
\[\mathbf{o}_{t,i} = \sum_{j=1}^{t}\operatorname{Softmax}_{j}(\frac{\mathbf{q}_{t,i}^{T}\mathbf{k}_{j,i}}{\sqrt{d_h+d_h^{R}}})\mathbf{v}_{j,i}^{C}\] \[\mathbf{u}_{t} = W^{O}[\mathbf{o}_{t,1};\mathbf{o}_{t,2};...;\mathbf{o}_{t,n_h}]\]DeepSeekMoE와 보조 손실이 없는 로드 밸런싱
DeepSeek-V3는 Feed-Forward Networks (FFNs)에 DeepSeekMoE 아키텍처를 채택했습니다. $t$번째 토큰의 FFN 입력을 $\mathbf{u}_t$라고 할 때, FFN 출력 $\mathbf{h}_t^{\prime}$는 다음과 같이 계산됩니다.
\[\mathbf{h}_{t}^{\prime} = \mathbf{u}_{t} + \sum_{i=1}^{N_s}{\operatorname{FFN}^{(s)}_{i}\left(\mathbf{u}_{t}\right)} + \sum_{i=1}^{N_r}{g_{i,t}\operatorname{FFN}^{(r)}_{i}\left(\mathbf{u}_{t}\right)}\] \[g_{i,t} = \frac{g^{\prime}_{i,t}}{\sum_{j=1}^{N_r}g^{\prime}_{j,t}}\] \[g^{\prime}_{i,t} = \begin{cases}s_{i,t}, & s_{i,t}\in\operatorname{Topk}(\{s_{j,t}|1\leqslant j\leqslant N_r\},K_r), \\ 0, & \text{otherwise},\end{cases}\] \[s_{i,t} = \operatorname{Sigmoid}\left({\mathbf{u}_{t}}^{T}\mathbf{e}_{i}\right)\]여기서 $N_s$와 $N_r$은 각각 공유 전문가와 라우팅 전문가의 수를 나타내며, $\operatorname{FFN}^{(s)}_{i}(\cdot)$와 $\operatorname{FFN}^{(r)}_{i}(\cdot)$는 각각 $i$번째 공유 전문가와 라우팅 전문가를 나타냅니다.
DeepSeek-V3는 로드 밸런스와 모델 성능 사이의 더 나은 균형을 위해 보조 손실이 없는 로드 밸런싱 전략을 도입했습니다. 각 전문가에 대한 바이어스 항 $b_i$를 도입하고 이를 해당 친화도 점수 $s_{i,t}$에 추가하여 상위-K 라우팅을 결정합니다.
\[g^{\prime}_{i,t} = \begin{cases}s_{i,t}, & s_{i,t}+b_{i}\in\operatorname{Topk}(\{s_{j,t}+b_{j}|1\leqslant j\leqslant N_r\},K_{r}), \\ 0, & \text{otherwise}.\end{cases}\]바이어스 항은 라우팅에만 사용되며, FFN 출력과 곱해지는 게이팅 값은 여전히 원래의 친화도 점수 $s_{i,t}$로부터 계산됩니다. 학습 중에는 각 학습 단계의 전체 배치에 대한 전문가 로드를 모니터링합니다. 각 단계가 끝날 때, 과부하된 전문가의 바이어스 항은 $γ$만큼 감소시키고, 부족 로드된 전문가의 바이어스 항은 $γ$만큼 증가시킵니다. 여기서 $γ$는 바이어스 업데이트 속도라고 하는 하이퍼파라미터입니다.
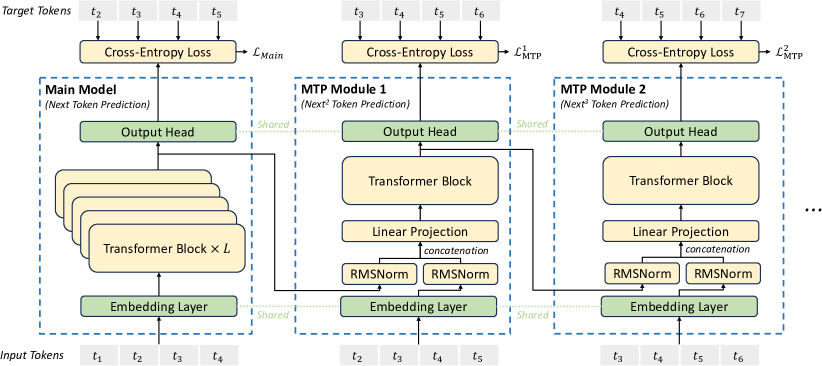
위 그림은 Multi-Token Prediction (MTP) 아키텍처를 보여줍니다. 각 깊이에서 각 토큰을 예측하기 위한 완전한 인과 체인을 유지하며, 트랜스포머 블록, 선형 투영, 임베딩 레이어가 주요 구성 요소입니다.
보완적인 시퀀스 단위 보조 손실
DeepSeek-V3는 보조 손실이 없는 전략을 주로 사용하지만, 단일 시퀀스 내에서 극단적인 불균형을 방지하기 위해 보완적인 시퀀스 단위 밸런스 손실도 함께 사용합니다.
\[\mathcal{L}_{\mathrm{Bal}} = \alpha\sum_{i=1}^{N_{r}}{f_{i}P_{i}}\] \[f_i = \frac{N_r}{K_rT}\sum_{t=1}^{T}\mathbb{1}\left(s_{i,t}\in\operatorname{Topk}(\{s_{j,t}|1\leqslant j\leqslant N_r\},K_r)\right)\] \[s^{\prime}_{i,t} = \frac{s_{i,t}}{\sum_{j=1}^{N_r}s_{j,t}}\] \[P_{i} = \frac{1}{T}\sum_{t=1}^{T}{s^{\prime}_{i,t}}\]여기서 밸런스 계수 $\alpha$는 하이퍼파라미터이며, DeepSeek-V3에서는 매우 작은 값으로 설정됩니다. 시퀀스 단위 밸런스 손실은 각 시퀀스에서의 전문가 로드가 균형을 이루도록 유도합니다.
노드 제한 라우팅
DeepSeek-V2에서 사용된 디바이스 제한 라우팅과 유사하게, DeepSeek-V3도 학습 중 통신 비용을 제한하기 위해 제한된 라우팅 메커니즘을 사용합니다. 각 토큰이 최대 $M$개의 노드로만 전송되도록 보장하며, 이 노드들은 각 노드에 분산된 전문가들의 가장 높은 $\frac{K_r}{M}$개의 친화도 점수 합계에 따라 선택됩니다. 이러한 제약 조건 하에서, MoE 학습 프레임워크는 거의 완전한 계산-통신 오버랩을 달성할 수 있습니다.
토큰 드롭핑 없음
효과적인 로드 밸런싱 전략 덕분에 DeepSeek-V3는 전체 학습 과정에서 좋은 로드 밸런스를 유지합니다. 따라서 학습 중에 어떤 토큰도 드롭하지 않습니다. 또한 추론 시 로드 밸런스를 보장하기 위한 특정 배포 전략도 구현되어 있어, 추론 중에도 토큰을 드롭하지 않습니다.
Multi-Token Prediction
Gloeckle와 연구진의 영감을 받아, DeepSeek-V3는 각 위치에서 여러 미래 토큰을 예측하도록 하는 Multi-Token Prediction (MTP) 목표를 설정했습니다. MTP 목표는 학습 신호를 밀집하게 만들어 데이터 효율성을 향상시킬 수 있으며, 모델이 미래 토큰을 더 잘 예측하기 위해 표현을 사전에 계획할 수 있게 합니다.
Gloeckle와 연구진과는 달리, 독립적인 출력 헤드를 사용하여 $D$개의 추가 토큰을 병렬로 예측하는 대신, 각 예측 깊이에서 완전한 인과 체인을 유지하면서 추가 토큰을 순차적으로 예측합니다.
DeepSeek-V3의 아키텍처
MTP 모듈 구현
MTP 구현은 $D$개의 순차적 모듈을 사용하여 $D$개의 추가 토큰을 예측합니다. $k$번째 MTP 모듈은 공유 임베딩 레이어 $\operatorname{Emb}(\cdot)$, 공유 출력 헤드 $\operatorname{OutHead}(\cdot)$, 트랜스포머 블록 $\operatorname{TRM}_k(\cdot)$, 그리고 투영 행렬 $M_k \in \mathbb{R}^{d \times 2d}$로 구성됩니다.
$i$번째 입력 토큰 $t_i$에 대해, $k$번째 예측 깊이에서는 먼저 $(k-1)$번째 깊이에서의 $i$번째 토큰의 표현 $\mathbf{h}_i^{k-1} \in \mathbb{R}^d$와 $(i+k)$번째 토큰의 임베딩 $\operatorname{Emb}(t_{i+k}) \in \mathbb{R}^d$를 선형 투영을 통해 결합합니다.
\[\mathbf{h}_i^{\prime k} = M_k[\operatorname{RMSNorm}(\mathbf{h}_i^{k-1}); \operatorname{RMSNorm}(\operatorname{Emb}(t_{i+k}))]\]특히 $k=1$일 때, $\mathbf{h}_i^{k-1}$는 메인 모델이 제공한 표현을 참조합니다. 각 MTP 모듈의 임베딩 레이어는 메인 모델과 공유됩니다.
결합된 $\mathbf{h}_i^{\prime k}$는 $k$번째 깊이의 트랜스포머 블록의 입력으로 사용되어 현재 깊이의 출력 표현 $\mathbf{h}_i^k$를 생성합니다.
\[\mathbf{h}_{1:T-k}^{k} = \operatorname{TRM}_{k}(\mathbf{h}_{1:T-k}^{\prime k})\]여기서 $T$는 입력 시퀀스 길이를 나타내며, i:j는 슬라이싱 연산(좌우 경계 모두 포함)을 나타냅니다.
마지막으로, $\mathbf{h}_i^k$를 입력으로 받아 공유 출력 헤드가 $k$번째 추가 예측 토큰에 대한 확률 분포 $P_{i+k+1}^k \in \mathbb{R}^V$를 계산합니다.
\[P_{i+k+1}^k = \operatorname{OutHead}(\mathbf{h}_i^k)\]출력 헤드 $\operatorname{OutHead}(\cdot)$는 표현을 로짓으로 선형 매핑한 후 $\operatorname{Softmax}(\cdot)$ 함수를 적용하여 $k$번째 추가 토큰의 예측 확률을 계산합니다. 각 MTP 모듈의 출력 헤드도 메인 모델과 공유됩니다.
MTP 학습 목표
각 예측 깊이에 대해 크로스 엔트로피 손실 $\mathcal{L}_{\text{MTP}}^k$를 계산합니다.
\[\mathcal{L}_{\text{MTP}}^k = \operatorname{CrossEntropy}(P_{2+k:T+1}^k,t_{2+k:T+1}) = -\frac{1}{T}\sum_{i=2+k}^{T+1}\log P_{i}^k[t_{i}]\]여기서 $T$는 입력 시퀀스 길이, $t_i$는 $i$번째 위치의 실제 토큰, 그리고 $P_i^k[t_i]$는 $k$번째 MTP 모듈이 제공한 $t_i$의 예측 확률입니다.
최종적으로 모든 깊이에 걸친 MTP 손실의 평균을 계산하고 가중치 인자 $\lambda$를 곱하여 전체 MTP 손실 $\mathcal{L}_{\text{MTP}}$를 얻습니다. 이는 DeepSeek-V3의 추가 학습 목표로 사용됩니다.
\[\mathcal{L}_{\text{MTP}} = \frac{\lambda}{D}\sum_{k=1}^{D}\mathcal{L}_{\text{MTP}}^k\]인프라스트럭처
컴퓨트 클러스터
DeepSeek-V3는 2048개의 NVIDIA H800 GPU가 장착된 클러스터에서 학습되었습니다. H800 클러스터의 각 노드는 8개의 GPU로 구성되어 있으며, 노드 내부에서는 NVLink와 NVSwitch를 통해 GPU들이 연결됩니다. 서로 다른 노드 간의 통신은 InfiniBand(IB) 인터커넥트를 통해 이루어집니다.
학습 프레임워크
DeepSeek-V3의 학습은 엔지니어들이 처음부터 직접 개발한 효율적이고 경량화된 학습 프레임워크인 HAI-LLM을 기반으로 합니다. 전체적으로 DeepSeek-V3는 16-way 파이프라인 병렬화(PP), 8개 노드에 걸친 64-way 전문가 병렬화(EP), 그리고 ZeRO-1 데이터 병렬화(DP)를 적용합니다.
DeepSeek-V3의 효율적인 학습을 위해 세밀한 엔지니어링 최적화가 구현되었습니다. 첫째, 효율적인 파이프라인 병렬화를 위해 DualPipe 알고리즘을 설계했습니다. 기존 PP 방식들과 비교했을 때 DualPipe는 파이프라인 버블이 더 적습니다. 더 중요한 점은 순방향과 역방향 프로세스 전반에 걸쳐 계산과 통신 단계를 오버랩하여, 노드 간 전문가 병렬화로 인한 과도한 통신 오버헤드 문제를 해결했다는 것입니다.
둘째, IB와 NVLink 대역폭을 최대한 활용하고 통신에 할당되는 스트리밍 멀티프로세서(SM)를 절약하기 위해 효율적인 노드 간 all-to-all 통신 커널을 개발했습니다. 마지막으로, 학습 중 메모리 사용량을 세밀하게 최적화하여 비용이 많이 드는 텐서 병렬화(TP)를 사용하지 않고도 DeepSeek-V3를 학습할 수 있게 했습니다.

위 그림은 트랜스포머 기반 모델에서 개별 순방향과 역방향 청크 쌍에 대한 오버랩 전략을 보여줍니다. 다이어그램은 순방향, 역방향, 병렬 처리(PP) 단계를 포함한 다양한 계산 및 통신 구성 요소들의 시간적 정렬을 보여줍니다. 주요 발견은 all-to-all과 PP 통신이 모두 완전히 숨겨질 수 있다는 것이며, 이는 대규모 트랜스포머 모델의 효율성과 확장성 향상에 중요한 의미를 가집니다.
DeepSeek-V3의 경우, 노드 간 전문가 병렬화로 인한 통신 오버헤드로 인해 계산 대 통신 비율이 약 1:1로 비효율적입니다. 이 문제를 해결하기 위해 DualPipe라는 혁신적인 파이프라인 병렬화 알고리즘을 설계했습니다. 이 알고리즘은 순방향과 역방향 계산-통신 단계를 효과적으로 오버랩함으로써 모델 학습을 가속화할 뿐만 아니라 파이프라인 버블도 줄입니다.
DualPipe의 핵심 아이디어는 개별 순방향과 역방향 청크 쌍 내에서 계산과 통신을 오버랩하는 것입니다. 구체적으로, 각 청크를 어텐션, all-to-all 디스패치, MLP, all-to-all 결합의 네 가지 구성 요소로 나눕니다. 특히 역방향 청크의 경우, ZeroBubble에서와 같이 어텐션과 MLP 모두 입력에 대한 역전파와 가중치에 대한 역전파의 두 부분으로 더 나뉩니다. 또한 PP 통신 구성 요소도 있습니다.

위 그림은 8개의 처리 파이프라인(PP) 랭크와 순방향 및 역방향 모두에서 20개의 마이크로배치에 대한 DualPipe 스케줄링 방식을 보여줍니다. 주요 구성 요소에는 마이크로배치 ID, 각 디바이스의 계산 및 통신 단계, 그리고 순방향과 역방향 패스 사이의 오버랩 영역이 포함됩니다. 이 그림은 계산과 통신을 오버랩하여 리소스를 효율적으로 활용하는 것을 보여주며, 이는 대규모 분산 ML 모델의 학습 처리량을 향상시키는 데 중요한 발견입니다.
더 일반적인 시나리오에서도 과도한 통신 부담이 없는 경우에도 DualPipe는 여전히 효율성 측면에서 장점을 보입니다. 아래 표는 서로 다른 PP 방식들 간의 파이프라인 버블과 메모리 사용량을 비교합니다.
| 방식 | 버블 | 파라미터 | 활성화 |
|---|---|---|---|
| 1F1B | \((PP-1)(F+B)\) | \(1×\) | \(PP\) |
| ZB1P | \((PP-1)(F+B-2W)\) | \(1×\) | \(PP\) |
| DualPipe (제안) | \((\frac{PP}{2}-1)(F\&B+B-3W)\) | \(2×\) | \(PP+1\) |
표에서 보듯이 ZB1P와 1F1B에 비해 DualPipe는 파이프라인 버블을 크게 줄이면서도 피크 활성화 메모리는 \(\frac{1}{PP}\) 배만큼만 증가시킵니다. DualPipe는 모델 파라미터의 두 복사본을 유지해야 하지만, 학습 중에 큰 EP 크기를 사용하기 때문에 이는 메모리 소비를 크게 증가시키지 않습니다. Chimera와 비교했을 때, DualPipe는 파이프라인 단계와 마이크로배치가 2로 나누어떨어져야 한다는 요구사항만 있을 뿐, 마이크로배치가 파이프라인 단계로 나누어떨어져야 한다는 제약은 없습니다. 또한 DualPipe의 경우 마이크로배치 수가 증가해도 버블이나 활성화 메모리가 증가하지 않습니다.
노드 간 All-to-All 통신의 효율적인 구현
DualPipe의 충분한 계산 성능을 보장하기 위해, 통신에 할당되는 SM 수를 절약하기 위한 효율적인 노드 간 all-to-all 통신 커널(디스패치와 결합 포함)을 커스터마이즈했습니다. 이 커널의 구현은 MoE 게이팅 알고리즘과 클러스터의 네트워크 토폴로지를 고려하여 공동 설계되었습니다.
구체적으로, 클러스터에서 노드 간 GPU들은 IB를 통해 완전히 연결되어 있고, 노드 내부 통신은 NVLink를 통해 처리됩니다. NVLink는 160 GB/s의 대역폭을 제공하며, 이는 IB(50 GB/s)의 약 3.2배입니다. IB와 NVLink의 서로 다른 대역폭을 효과적으로 활용하기 위해, 각 토큰이 최대 4개의 노드로만 디스패치되도록 제한하여 IB 트래픽을 줄입니다. 각 토큰에 대해 라우팅 결정이 이루어지면, 먼저 IB를 통해 대상 노드의 동일한 노드 내 인덱스를 가진 GPU로 전송됩니다. 토큰이 대상 노드에 도달하면, 이후 도착하는 토큰에 의해 차단되지 않고 즉시 NVLink를 통해 대상 전문가를 호스팅하는 특정 GPU로 전달되도록 합니다.
이러한 방식으로 IB와 NVLink를 통한 통신이 완전히 오버랩되며, 각 토큰은 NVLink로 인한 추가 오버헤드 없이 노드당 평균 3.2개의 전문가를 선택할 수 있습니다. 이는 DeepSeek-V3가 실제로는 8개의 라우팅된 전문가만 선택하지만, 동일한 통신 비용으로 최대 13개의 전문가(4개 노드 × 3.2 전문가/노드)까지 확장할 수 있음을 의미합니다.
이러한 통신 전략 하에서는 IB와 NVLink 대역폭을 완전히 활용하는 데 20개의 SM만으로도 충분합니다. 구체적으로, 워프 특수화 기법을 사용하여 20개의 SM을 10개의 통신 채널로 분할합니다. 디스패치 과정에서 (1) IB 송신, (2) IB-to-NVLink 전달, (3) NVLink 수신은 각각의 워프에 의해 처리됩니다. 각 통신 작업에 할당되는 워프의 수는 모든 SM에 걸친 실제 작업량에 따라 동적으로 조정됩니다. 마찬가지로 결합 과정에서도 (1) NVLink 송신, (2) NVLink-to-IB 전달 및 누적, (3) IB 수신 및 누적이 동적으로 조정되는 워프에 의해 처리됩니다.
또한 디스패치와 결합 커널은 계산 스트림과 오버랩되므로, 다른 SM 계산 커널에 대한 영향도 고려합니다. 구체적으로, 커스터마이즈된 PTX(Parallel Thread Execution) 명령어를 사용하고 통신 청크 크기를 자동 튜닝하여 L2 캐시 사용과 다른 SM에 대한 간섭을 크게 줄입니다.
극도의 메모리 절약과 최소한의 오버헤드
학습 중 메모리 사용량을 줄이기 위해 다음과 같은 기술들을 적용했습니다.
RMSNorm과 MLA 업-프로젝션의 재계산: 역전파 과정에서 모든 RMSNorm 연산과 MLA 업-프로젝션을 재계산하여 출력 활성화를 지속적으로 저장할 필요가 없게 했습니다. 이 전략은 약간의 오버헤드만으로 활성화 저장에 필요한 메모리를 크게 줄일 수 있습니다.
CPU에서의 지수 이동 평균: 학습 중에는 학습률 감소 후 모델 성능의 조기 추정을 위해 모델 파라미터의 지수 이동 평균(EMA)을 유지합니다. EMA 파라미터는 CPU 메모리에 저장되며 각 학습 단계 후 비동기적으로 업데이트됩니다. 이 방법을 통해 추가적인 메모리나 시간 오버헤드 없이 EMA 파라미터를 유지할 수 있습니다.
멀티 토큰 예측을 위한 공유 임베딩과 출력 헤드: DualPipe 전략을 통해 모델의 가장 얕은 층(임베딩 층 포함)과 가장 깊은 층(출력 헤드 포함)을 동일한 PP 랭크에 배치합니다. 이러한 배치를 통해 MTP 모듈과 메인 모델 사이에서 공유 임베딩과 출력 헤드의 파라미터와 그래디언트를 물리적으로 공유할 수 있습니다. 이러한 물리적 공유 메커니즘은 메모리 효율성을 더욱 향상시킵니다.
FP8 학습
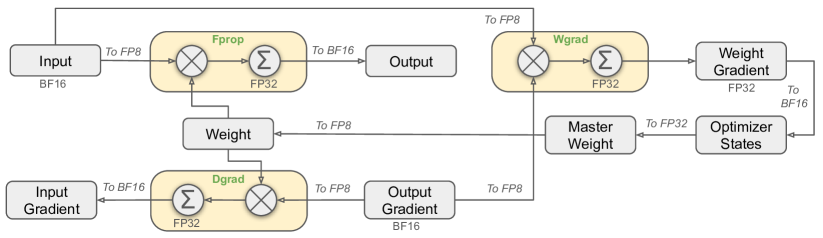
위 그림은 신경망 모델에서 FP8 데이터 포맷을 사용한 전체 혼합 정밀도 프레임워크를 보여줍니다. 주요 구성 요소는 입력, 순방향 전파(Fprop), 가중치 그래디언트(Wgrad), 출력 그래디언트, 가중치, 마스터 가중치, 그리고 옵티마이저 상태입니다. 주요 기술적 관계는 이러한 구성 요소들 간의 데이터와 그래디언트 흐름을 보여주며, 서로 다른 단계에서 FP32와 FP8 데이터 포맷의 사용을 강조합니다. 이 그림은 계산 효율성과 모델 성능을 잠재적으로 향상시킬 수 있는 혼합 정밀도 학습 접근 방식의 구현을 보여줍니다.
최근의 저정밀도 학습 발전에 영감을 받아, DeepSeek-V3의 학습을 위해 FP8 데이터 포맷을 활용하는 세밀한 혼합 정밀도 프레임워크를 제안했습니다. 저정밀도 학습은 큰 잠재력을 가지고 있지만, 활성화, 가중치, 그래디언트에서 발생하는 이상치로 인해 제한되는 경우가 많습니다. 추론 양자화에서 상당한 진전이 있었지만, 대규모 언어 모델 사전 학습에서 저정밀도 기술의 성공적인 적용을 보여주는 연구는 상대적으로 적습니다.
이 문제를 해결하고 FP8 포맷의 동적 범위를 효과적으로 확장하기 위해, $1 \times N_c$ 요소의 타일 단위 그룹화 또는 $N_c \times N_c$ 요소의 블록 단위 그룹화를 사용하는 세밀한 양자화 전략을 도입했습니다. 관련된 역양자화 오버헤드는 정밀도가 향상된 누적 프로세스에서 크게 완화되며, 이는 정확한 FP8 일반 행렬 곱셈(GEMM)을 달성하는 데 중요한 측면입니다. 더욱이 MoE 학습에서 메모리와 통신 오버헤드를 더욱 줄이기 위해 활성화를 FP8로 캐시하고 디스패치하며, 저정밀도 옵티마이저 상태는 BF16으로 저장합니다. 제안된 FP8 혼합 정밀도 프레임워크는 DeepSeek-V2-Lite와 DeepSeek-V2와 유사한 두 가지 모델 규모에서 약 1조 토큰에 대해 검증되었습니다. 특히 BF16 기준선과 비교했을 때, FP8 학습 모델의 상대적 손실 오차는 지속적으로 0.25% 미만을 유지했으며, 이는 학습 무작위성의 허용 범위 내에 있는 수준입니다.
혼합 정밀도 프레임워크
저정밀도 학습에서 널리 채택된 기술들을 기반으로 FP8 학습을 위한 혼합 정밀도 프레임워크를 제안했습니다. 이 프레임워크에서는 대부분의 계산 집약적 연산은 FP8에서 수행되며, 일부 주요 연산은 학습 효율성과 수치적 안정성의 균형을 맞추기 위해 원래의 데이터 포맷을 유지합니다.
먼저, 모델 학습을 가속화하기 위해 대부분의 핵심 계산 커널, 즉 GEMM 연산은 FP8 정밀도로 구현됩니다. 이러한 GEMM 연산은 FP8 텐서를 입력으로 받아 BF16 또는 FP32로 출력을 생성합니다. Linear 연산자와 관련된 세 가지 GEMM, 즉 Fprop(순방향 패스), Dgrad(활성화 역방향 패스), Wgrad(가중치 역방향 패스)는 모두 FP8에서 실행됩니다. 이 설계는 이론적으로 원래의 BF16 방식에 비해 계산 속도를 두 배로 높입니다.
FP8 포맷의 효율성에도 불구하고, 일부 연산자는 저정밀도 계산에 대한 민감성 때문에 더 높은 정밀도가 필요합니다. 또한 일부 저비용 연산자는 전체 학습 비용에 미치는 영향이 미미하므로 더 높은 정밀도를 사용할 수 있습니다. 이러한 이유로 신중한 조사 후 다음 구성 요소들에 대해서는 원래의 정밀도(예: BF16 또는 FP32)를 유지합니다. 임베딩 모듈, 출력 헤드, MoE 게이팅 모듈, 정규화 연산자, 어텐션 연산자. 이러한 높은 정밀도의 선택적 유지는 DeepSeek-V3의 안정적인 학습 동역학을 보장합니다.
수치적 안정성을 더욱 보장하기 위해 마스터 가중치, 가중치 그래디언트, 옵티마이저 상태는 더 높은 정밀도로 저장합니다. 이러한 고정밀도 구성 요소들이 일부 메모리 오버헤드를 발생시키지만, 분산 학습 시스템에서 여러 DP 랭크에 걸쳐 효율적으로 샤딩함으로써 그 영향을 최소화할 수 있습니다.
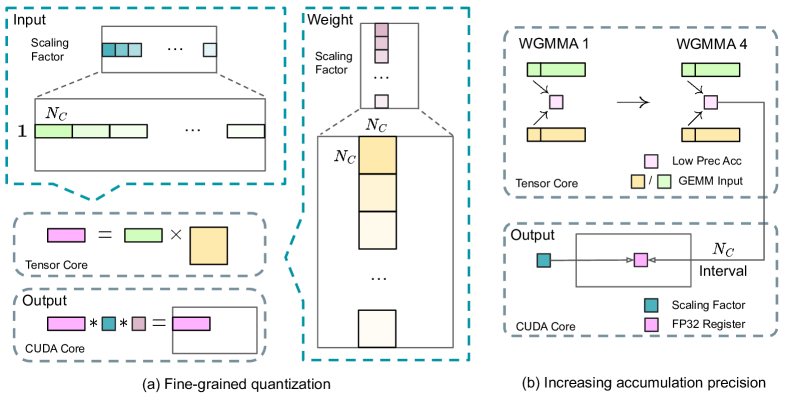
위 그림은 AI/ML 모델에서 저정밀도 행렬 곱셈(GEMM) 연산의 성능을 향상시키기 위해 연구진이 제안한 두 가지 핵심 기술을 보여줍니다. (a) 특성 이상치로 인한 양자화 오류를 완화하기 위한 세밀한 양자화 방법이 도입되었습니다. (b) 연구진은 128개 요소 간격으로 CUDA 코어에 대한 고정밀도 누적을 촉진하여 FP8 GEMM 정밀도를 향상시켰으며, 이는 전체적인 계산 효율성을 향상시킵니다.
양자화와 곱셈의 정밀도 향상
혼합 정밀도 FP8 프레임워크를 기반으로, 양자화 방법과 곱셈 프로세스 모두에 초점을 맞춰 저정밀도 학습 정확도를 향상시키기 위한 여러 전략을 도입했습니다.
세밀한 양자화: 저정밀도 학습 프레임워크에서는 FP8 포맷의 제한된 지수 비트로 인한 동적 범위 제약 때문에 오버플로우와 언더플로우가 일반적인 문제입니다. 표준 관행으로는 입력 텐서의 최대 절대값을 FP8 포맷의 최대 표현 가능한 값에 맞추어 입력 분포를 조정합니다. 이 방법은 저정밀도 학습을 활성화 이상치에 매우 민감하게 만들어 양자화 정확도를 크게 저하시킬 수 있습니다.
이를 해결하기 위해 더 세밀한 수준에서 스케일링을 적용하는 세밀한 양자화 방법을 제안했습니다. (1) 활성화의 경우 1x128 타일 기준으로 요소들을 그룹화하고 스케일링하며(즉, 토큰당 128개 채널), (2) 가중치의 경우 128x128 블록 기준으로 요소들을 그룹화하고 스케일링합니다(즉, 128개 입력 채널당 128개 출력 채널). 이 접근 방식은 더 작은 요소 그룹에 따라 스케일을 조정함으로써 이상치를 더 잘 수용할 수 있도록 합니다.
우리 방법의 한 가지 주요 수정 사항은 GEMM 연산의 내부 차원을 따라 그룹별 스케일링 팩터를 도입한 것입니다. 이 기능은 표준 FP8 GEMM에서 직접 지원되지 않습니다. 하지만 정밀한 FP32 누적 전략과 결합하면 효율적으로 구현될 수 있습니다.
누적 정밀도 향상: 저정밀도 GEMM 연산은 종종 언더플로우 문제를 겪으며, 그 정확도는 주로 고정밀도 누적에 의존합니다. 그러나 NVIDIA H800 GPU에서 FP8 GEMM의 누적 정밀도가 약 14비트로 제한되어 있음을 관찰했습니다. 이는 FP32 누적 정밀도보다 상당히 낮습니다. 이 문제는 내부 차원 K가 클 때 더욱 두드러지며, 이는 배치 크기와 모델 너비가 증가하는 대규모 모델 학습에서 일반적인 시나리오입니다.
이 문제를 해결하기 위해 더 높은 정밀도를 위해 CUDA 코어로의 프로모션 전략을 채택했습니다. 텐서 코어에서 MMA(Matrix Multiply-Accumulate) 실행 중에 중간 결과는 제한된 비트 폭을 사용하여 누적됩니다. $N_C$ 간격에 도달하면 이러한 부분 결과는 CUDA 코어의 FP32 레지스터로 복사되어 전체 정밀도 FP32 누적이 수행됩니다.
지수보다 가수: 이전 작업에서 채택한 하이브리드 FP8 포맷과는 달리, 우리는 모든 텐서에 대해 더 높은 정밀도를 위해 E4M3 포맷을 채택했습니다. 이 접근 방식의 실현 가능성은 우리의 세밀한 양자화 전략, 즉 타일 및 블록 단위 스케일링 덕분입니다. 더 작은 요소 그룹에서 작동함으로써, 우리의 방법론은 이러한 그룹화된 요소들 간에 지수 비트를 효과적으로 공유하여 제한된 동적 범위의 영향을 완화합니다.
온라인 양자화
텐서 단위 양자화 프레임워크에서는 이전 반복에 걸친 최대 절대값의 이력을 유지하여 현재 값을 추론하는 지연된 양자화를 사용합니다. 정확한 스케일을 보장하고 프레임워크를 단순화하기 위해, 각 1x128 활성화 타일 또는 128x128 가중치 블록에 대한 최대 절대값을 온라인으로 계산합니다. 이를 기반으로 스케일링 팩터를 도출한 다음, 활성화나 가중치를 온라인으로 FP8 포맷으로 양자화합니다.
저정밀도 저장과 통신
FP8 학습 프레임워크와 함께, 캐시된 활성화와 옵티마이저 상태를 더 낮은 정밀도 포맷으로 압축하여 메모리 소비와 통신 오버헤드를 더욱 줄였습니다.
저정밀도 옵티마이저 상태: AdamW 옵티마이저에서 첫 번째와 두 번째 모멘트를 추적하기 위해 FP32 대신 BF16 데이터 포맷을 채택했으며, 이는 관찰 가능한 성능 저하를 일으키지 않습니다. 그러나 학습 전반에 걸쳐 수치적 안정성을 보장하기 위해 마스터 가중치(옵티마이저가 저장)와 그래디언트(배치 크기 누적에 사용)는 여전히 FP32로 유지됩니다.
저정밀도 활성화: Linear 연산자의 Wgrad 연산이 FP8에서 수행되므로, 역방향 패스를 위해 활성화를 FP8 포맷으로 캐시하는 것이 자연스러운 선택입니다. 그러나 저비용 고정밀도 학습을 위해 몇 가지 연산자에 대해 특별한 고려사항이 적용됩니다.
-
어텐션 연산자 이후의 Linear 입력: 이러한 활성화는 어텐션 연산자의 역방향 패스에서도 사용되어 정밀도에 민감합니다. 이러한 활성화에 대해서만 커스터마이즈된 E5M6 데이터 포맷을 채택합니다. 또한 이러한 활성화는 역방향 패스에서 1x128 양자화 타일에서 128x1 타일로 변환됩니다. 추가적인 양자화 오차를 도입하지 않기 위해 모든 스케일링 팩터는 라운드 스케일링됩니다(즉, 2의 정수 거듭제곱).
-
MoE의 SwiGLU 연산자 입력: 메모리 비용을 더욱 줄이기 위해 SwiGLU 연산자의 입력을 캐시하고 역방향 패스에서 출력을 재계산합니다. 이러한 활성화도 우리의 세밀한 양자화 방법을 사용하여 FP8로 저장되어 메모리 효율성과 계산 정확도 사이의 균형을 맞춥니다.
저정밀도 통신: 통신 대역폭은 MoE 모델 학습의 중요한 병목점입니다. 이 문제를 완화하기 위해 MoE 업-프로젝션 전의 활성화를 FP8로 양자화한 다음 디스패치 구성 요소를 적용하며, 이는 MoE 업-프로젝션의 FP8 Fprop와 호환됩니다. 어텐션 연산자 이후의 Linear 입력과 마찬가지로, 이 활성화에 대한 스케일링 팩터도 2의 정수 거듭제곱입니다. 유사한 전략이 MoE 다운-프로젝션 전의 활성화 그래디언트에도 적용됩니다. 순방향과 역방향 결합 구성 요소 모두에 대해서는 학습 파이프라인의 중요한 부분에서 학습 정밀도를 보존하기 위해 BF16을 유지합니다.
인프라스트럭처
추론과 배포
DeepSeek-V3는 노드 내 GPU들이 NVLink로 연결되고 클러스터의 모든 GPU가 IB를 통해 완전히 연결된 H800 클러스터에 배포됩니다. 온라인 서비스의 서비스 수준 목표(SLO)와 높은 처리량을 동시에 보장하기 위해, 프리필링과 디코딩 단계를 분리하는 다음과 같은 배포 전략을 사용합니다.
프리필링 단계의 최소 배포 단위는 32개의 GPU가 있는 4개의 노드로 구성됩니다. 어텐션 부분은 시퀀스 병렬화(SP)와 함께 4-way 텐서 병렬화(TP4)를 사용하고 8-way 데이터 병렬화(DP8)와 결합됩니다. 작은 TP 크기인 4는 TP 통신의 오버헤드를 제한합니다. MoE 부분의 경우 32-way 전문가 병렬화(EP32)를 사용하여 각 전문가가 충분히 큰 배치 크기를 처리하도록 보장함으로써 계산 효율성을 향상시킵니다.
MoE all-to-all 통신에는 학습에서와 동일한 방법을 사용합니다. 먼저 IB를 통해 노드 간에 토큰을 전송한 다음, NVLink를 통해 노드 내 GPU들 간에 전달합니다. 특히 얕은 층의 밀집 MLP에는 TP 통신을 절약하기 위해 1-way 텐서 병렬화를 사용합니다.
MoE 부분에서 서로 다른 전문가 간의 로드 밸런싱을 달성하기 위해서는 각 GPU가 대략 동일한 수의 토큰을 처리하도록 보장해야 합니다. 이를 위해 중복 전문가의 배포 전략을 도입하여 높은 부하의 전문가를 복제하고 중복 배포합니다. 높은 부하의 전문가는 온라인 배포 중 수집된 통계를 기반으로 감지되며 주기적으로(예: 10분마다) 조정됩니다.
중복 전문가 세트를 결정한 후, 노드 간 all-to-all 통신 오버헤드를 증가시키지 않으면서 가능한 한 GPU 간의 부하를 균형있게 만들기 위해 관찰된 부하를 기반으로 노드 내 GPU들 간에 전문가들을 신중하게 재배치합니다. DeepSeek-V3의 배포에서는 프리필링 단계에 32개의 중복 전문가를 설정합니다. 각 GPU는 원래 호스팅하는 8개의 전문가 외에도 하나의 추가 중복 전문가를 호스팅합니다.
더욱이 프리필링 단계에서는 처리량을 향상시키고 all-to-all과 TP 통신의 오버헤드를 숨기기 위해 유사한 계산 작업량을 가진 두 개의 마이크로배치를 동시에 처리하여 한 마이크로배치의 어텐션과 MoE를 다른 마이크로배치의 디스패치 및 결합과 오버랩합니다.
마지막으로, 전문가에 대한 동적 중복성 전략을 탐구하고 있습니다. 이 전략에서는 각 GPU가 더 많은 전문가(예: 16개 전문가)를 호스팅하지만 각 추론 단계에서는 9개만 활성화됩니다. 각 층에서 all-to-all 연산이 시작되기 전에 전역적으로 최적의 라우팅 방식을 즉석에서 계산합니다. 프리필링 단계에서 상당한 계산이 포함되어 있기 때문에 이 라우팅 방식을 계산하는 오버헤드는 거의 무시할 만합니다.
디코딩
디코딩 중에는 공유 전문가를 라우팅된 전문가로 취급합니다. 이러한 관점에서 각 토큰은 라우팅 중에 9개의 전문가를 선택하며, 이때 공유 전문가는 항상 선택되는 높은 부하의 전문가로 간주됩니다. 디코딩 단계의 최소 배포 단위는 320개의 GPU가 있는 40개의 노드로 구성됩니다. 어텐션 부분은 SP와 함께 TP4를 사용하고 DP80과 결합되며, MoE 부분은 EP320을 사용합니다.
MoE 부분에서 각 GPU는 하나의 전문가만 호스팅하며, 64개의 GPU가 중복 전문가와 공유 전문가를 호스팅하는 역할을 담당합니다. 디스패치와 결합 부분의 all-to-all 통신은 낮은 지연 시간을 달성하기 위해 IB를 통한 직접적인 지점 간 전송으로 수행됩니다. 또한 IBGDA 기술을 활용하여 지연 시간을 더욱 최소화하고 통신 효율성을 향상시킵니다.
프리필링과 마찬가지로, 일정 간격으로 온라인 서비스의 통계적 전문가 부하를 기반으로 중복 전문가 세트를 주기적으로 결정합니다. 그러나 각 GPU가 하나의 전문가만 호스팅하므로 전문가를 재배치할 필요는 없습니다. 디코딩을 위한 동적 중복성 전략도 탐구하고 있습니다. 하지만 이는 전역적으로 최적의 라우팅 방식을 계산하는 알고리즘과 디스패치 커널과의 융합을 더욱 신중하게 최적화하여 오버헤드를 줄일 필요가 있습니다.
또한 처리량을 향상시키고 all-to-all 통신의 오버헤드를 숨기기 위해 디코딩 단계에서도 유사한 계산 작업량을 가진 두 개의 마이크로배치를 동시에 처리하는 방법을 탐구하고 있습니다. 프리필링과 달리 디코딩 단계에서는 어텐션이 더 많은 시간을 소비합니다. 따라서 한 마이크로배치의 어텐션을 다른 마이크로배치의 디스패치+MoE+결합과 오버랩합니다.
디코딩 단계에서는 전문가당 배치 크기가 상대적으로 작으며(보통 256 토큰 이내), 병목점은 계산이 아닌 메모리 접근입니다. MoE 부분은 하나의 전문가에 대한 파라미터만 로드하면 되므로 메모리 접근 오버헤드가 최소화되어, 더 적은 SM을 사용해도 전체 성능에 큰 영향을 미치지 않습니다. 따라서 어텐션 부분의 계산 속도에 영향을 주지 않기 위해 디스패치+MoE+결합에는 적은 수의 SM만 할당할 수 있습니다.
하드웨어 설계에 대한 제안
AI/ML 모델의 all-to-all 통신과 FP8 학습 방식 구현을 기반으로, AI 하드웨어 벤더들에게 다음과 같은 칩 설계 제안을 합니다.
통신 하드웨어
DeepSeek-V3에서는 계산과 통신을 오버랩하여 통신 지연 시간을 숨기는 방식을 구현했습니다. 이는 순차적 계산과 통신에 비해 통신 대역폭에 대한 의존도를 크게 줄입니다. 그러나 현재의 통신 구현은 비용이 많이 드는 SM(예: H800 GPU에서 사용 가능한 132개의 SM 중 20개를 이 목적으로 할당)에 의존하며, 이는 계산 처리량을 제한하게 됩니다. 더욱이 SM을 통신에 사용하면 텐서 코어가 완전히 활용되지 않아 상당한 비효율성이 발생합니다.
현재 SM은 all-to-all 통신을 위해 주로 다음과 같은 작업을 수행합니다.
- IB와 NVLink 도메인 간의 데이터 전달과 동일한 노드 내의 여러 GPU로 향하는 IB 트래픽을 단일 GPU에서 집계
- RDMA 버퍼(등록된 GPU 메모리 영역)와 입출력 버퍼 간의 데이터 전송
- all-to-all 결합을 위한 리듀스 연산 실행
- IB와 NVLink 도메인에 걸쳐 여러 전문가로의 청크화된 데이터 전송 중 세밀한 메모리 레이아웃 관리
미래의 벤더들이 이러한 통신 작업을 귀중한 계산 유닛 SM에서 오프로드하여 GPU 코프로세서나 NVIDIA SHARP와 같은 네트워크 코프로세서 역할을 하는 하드웨어를 개발하기를 기대합니다. 더 나아가 애플리케이션 프로그래밍 복잡성을 줄이기 위해 이 하드웨어가 계산 유닛의 관점에서 IB(스케일아웃)와 NVLink(스케일업) 네트워크를 통합하기를 바랍니다. 이러한 통합 인터페이스를 통해 계산 유닛은 간단한 프리미티브를 기반으로 한 통신 요청을 제출함으로써 IB-NVLink 통합 도메인 전체에서 읽기, 쓰기, 멀티캐스트, 리듀스와 같은 연산을 쉽게 수행할 수 있습니다.
계산 하드웨어
텐서 코어에서 더 높은 FP8 GEMM 누적 정밀도: 현재 NVIDIA Hopper 아키텍처의 텐서 코어 구현에서 FP8 GEMM은 최대 지수를 기반으로 가수 곱을 오른쪽으로 시프트하여 정렬한 후 더하는 고정 소수점 누적을 사용합니다. 실험 결과 부호-채움 오른쪽 시프트 후 각 가수 곱의 최상위 14비트만 사용하고 이 범위를 초과하는 비트는 절삭하는 것으로 나타났습니다. 그러나 예를 들어 32개의 FP8 × FP8 곱셈의 누적에서 정확한 FP32 결과를 얻으려면 최소 34비트의 정밀도가 필요합니다. 따라서 미래의 칩 설계에서는 텐서 코어의 누적 정밀도를 높여 전체 정밀도 누적을 지원하거나, 학습과 추론 알고리즘의 정확도 요구사항에 따라 적절한 누적 비트 폭을 선택하기를 권장합니다. 이러한 접근 방식은 오차를 허용 가능한 범위 내로 유지하면서 계산 효율성을 유지할 수 있습니다.
하드웨어 설계에 대한 제안
계산 하드웨어
타일 및 블록 단위 양자화 지원: 현재 GPU는 텐서 단위 양자화만 지원하며, 우리의 타일 및 블록 단위 양자화와 같은 세밀한 양자화에 대한 네이티브 지원이 부족합니다. 현재 구현에서는 $N_C$ 간격에 도달하면 부분 결과가 텐서 코어에서 CUDA 코어로 복사되어 스케일링 팩터를 곱한 후 CUDA 코어의 FP32 레지스터에 더해집니다. 정밀한 FP32 누적 전략과 결합하여 역양자화 오버헤드가 크게 완화되지만, 텐서 코어와 CUDA 코어 간의 빈번한 데이터 이동은 여전히 계산 효율성을 제한합니다. 따라서 미래의 칩이 텐서 코어가 스케일링 팩터를 받아 그룹 스케일링과 함께 MMA를 구현할 수 있도록 함으로써 세밀한 양자화를 지원하기를 권장합니다. 이렇게 하면 최종 결과가 생성될 때까지 전체 부분합 누적과 역양자화가 텐서 코어 내부에서 직접 완료될 수 있어 빈번한 데이터 이동을 피할 수 있습니다.
온라인 양자화 지원: 현재 구현은 연구에서 입증된 효과에도 불구하고 온라인 양자화를 효과적으로 지원하는 데 어려움을 겪고 있습니다. 기존 프로세스에서는 양자화를 위해 128개의 BF16 활성화 값(이전 계산의 출력)을 HBM(High Bandwidth Memory)에서 읽어야 하며, 양자화된 FP8 값은 다시 HBM에 쓰여진 후 MMA를 위해 다시 읽혀야 합니다. 이러한 비효율성을 해결하기 위해 미래의 칩이 FP8 캐스트와 TMA(Tensor Memory Accelerator) 접근을 단일 융합 연산으로 통합하여, 활성화가 전역 메모리에서 공유 메모리로 전송되는 동안 양자화가 완료될 수 있도록 하기를 권장합니다. 또한 속도 향상을 위한 워프 수준 캐스트 명령어를 지원하여 레이어 정규화와 FP8 캐스트의 더 나은 융합을 촉진하기를 권장합니다. 대안으로 HBM 근처에 계산 로직을 배치하는 근접 메모리 컴퓨팅 접근 방식을 채택할 수 있습니다. 이 경우 BF16 요소는 GPU로 읽혀지는 과정에서 직접 FP8로 캐스트되어 오프칩 메모리 접근을 약 50% 줄일 수 있습니다.
전치된 GEMM 연산 지원: 현재 아키텍처는 행렬 전치와 GEMM 연산의 융합을 어렵게 만듭니다. 우리의 워크플로우에서는 순방향 패스 중에 활성화가 1x128 FP8 타일로 양자화되어 저장됩니다. 역방향 패스에서는 행렬을 읽어 역양자화하고, 전치한 후, 128x1 타일로 다시 양자화하여 HBM에 저장해야 합니다. 메모리 연산을 줄이기 위해 미래의 칩이 학습과 추론 모두에 필요한 정밀도에 대해 MMA 연산 전에 공유 메모리에서 행렬의 직접 전치 읽기를 가능하게 하기를 권장합니다. FP8 포맷 변환과 TMA 접근의 융합과 결합하면 이러한 개선은 양자화 워크플로우를 크게 간소화할 것입니다.
사전 학습
데이터 구성
DeepSeek-V3는 DeepSeek-V2와 비교하여 수학과 프로그래밍 샘플의 비율을 최적화하고 영어와 중국어를 넘어선 다국어 범위를 확장했습니다. 데이터 처리 파이프라인은 다양성을 유지하면서 중복성을 최소화하도록 개선되었습니다. Ding과 연구진의 연구에서 영감을 받아 데이터 무결성을 위한 문서 패킹 방법을 구현했지만, 학습 중 크로스 샘플 어텐션 마스킹은 적용하지 않았습니다. 최종적으로 DeepSeek-V3의 학습 코퍼스는 토크나이저에서 14.8T의 고품질 다양한 토큰으로 구성되었습니다.
DeepSeekCoder-V2의 학습 과정에서 Fill-in-Middle (FIM) 전략이 다음 토큰 예측 능력을 손상시키지 않으면서도 문맥 단서를 기반으로 중간 텍스트를 정확하게 예측할 수 있게 한다는 것을 관찰했습니다. 이에 따라 DeepSeek-V3의 사전 학습에도 FIM 전략을 도입했습니다. 구체적으로, Prefix-Suffix-Middle (PSM) 프레임워크를 사용하여 다음과 같이 데이터를 구조화했습니다.
\[<|fim\_begin|>f_{\text{pre}}<|fim\_hole|>f_{\text{suf}}<|fim\_end|>f_{\text{middle}}<|eos\_token|>\]이 구조는 문서 수준에서 사전 패킹 프로세스의 일부로 적용되며, FIM 전략은 PSM 프레임워크와 일관되게 0.1의 비율로 적용됩니다.
DeepSeek-V3의 토크나이저는 128K 토큰의 확장된 어휘를 가진 바이트 수준 BPE를 사용합니다. 토크나이저의 사전 토크나이저와 학습 데이터는 다국어 압축 효율성을 최적화하도록 수정되었습니다. 또한 DeepSeek-V2와 비교하여 새로운 사전 토크나이저는 구두점과 줄바꿈을 결합한 토큰을 도입했습니다. 그러나 이 기법은 모델이 터미널 줄바꿈이 없는 여러 줄 프롬프트를 처리할 때, 특히 퓨샷 평가 프롬프트에서 토큰 경계 바이어스를 도입할 수 있습니다. 이 문제를 해결하기 위해 학습 중에 이러한 결합된 토큰의 일정 비율을 무작위로 분할하여 모델이 더 넓은 범위의 특수 케이스에 노출되도록 하고 이 바이어스를 완화했습니다.
하이퍼파라미터
모델 하이퍼파라미터
트랜스포머 레이어 수는 61개로 설정되었으며 은닉 차원은 7168입니다. 모든 학습 가능한 파라미터는 0.006의 표준 편차로 무작위 초기화되었습니다. MLA에서 어텐션 헤드 수 $n_h$는 128로, 헤드당 차원 $d_h$는 128로 설정되었습니다. KV 압축 차원 $d_c$는 512로, 쿼리 압축 차원 $d_c^{\prime}$는 1536으로 설정되었습니다. 디커플된 쿼리와 키의 경우, 헤드당 차원 $d_h^R$은 64로 설정되었습니다.
처음 세 레이어를 제외한 모든 FFN은 MoE 레이어로 대체되었습니다. 각 MoE 레이어는 1개의 공유 전문가와 256개의 라우팅된 전문가로 구성되며, 각 전문가의 중간 은닉 차원은 2048입니다. 라우팅된 전문가 중 각 토큰에 대해 8개의 전문가가 활성화되며, 각 토큰은 최대 4개의 노드로만 전송됩니다. 멀티 토큰 예측 깊이 $D$는 1로 설정되어, 정확한 다음 토큰 외에도 각 토큰이 하나의 추가 토큰을 예측합니다.
DeepSeek-V2와 마찬가지로 DeepSeek-V3도 압축된 잠재 벡터 이후에 추가 RMSNorm 레이어를 사용하고, 너비 병목 지점에서 추가 스케일링 팩터를 곱합니다. 이 구성에서 DeepSeek-V3는 총 671B 파라미터를 포함하며, 이 중 37B가 각 토큰에 대해 활성화됩니다.
사전 학습
학습 하이퍼파라미터
DeepSeek-V3는 AdamW 옵티마이저를 사용하며, 하이퍼파라미터는 $\beta_1=0.9$, $\beta_2=0.95$, 그리고 $\text{weight_decay}=0.1$로 설정되었습니다. 사전 학습 과정에서 최대 시퀀스 길이는 4K로 설정되었으며, 14.8T 토큰으로 사전 학습을 진행했습니다.
학습률 스케줄링의 경우, 처음 2K 스텝 동안 0에서 $2.2 \times 10^{-4}$까지 선형적으로 증가시킵니다. 이후 모델이 10T 학습 토큰을 소비할 때까지 $2.2 \times 10^{-4}$의 일정한 학습률을 유지합니다. 그 다음 4.3T 토큰 동안 코사인 감소 곡선을 따라 학습률을 $2.2 \times 10^{-5}$로 점진적으로 감소시킵니다. 마지막 500B 토큰의 학습에서는 처음 333B 토큰 동안 $2.2 \times 10^{-5}$의 일정한 학습률을 유지하고, 나머지 167B 토큰에서는 $7.3 \times 10^{-6}$의 다른 일정한 학습률로 전환합니다. 그래디언트 클리핑 노름은 1.0으로 설정되었습니다.
배치 크기 스케줄링 전략을 채택하여, 첫 469B 토큰의 학습에서 배치 크기를 3072에서 15360으로 점진적으로 증가시키고, 이후 남은 학습 과정에서는 15360을 유지합니다. 파이프라인 병렬화를 활용하여 모델의 서로 다른 레이어를 서로 다른 GPU에 배포하며, 각 레이어에서 라우팅된 전문가들은 8개 노드에 속한 64개의 GPU에 균일하게 배포됩니다.
노드 제한 라우팅의 경우, 각 토큰은 최대 4개의 노드로만 전송됩니다(즉, $M=4$). 보조 손실이 없는 로드 밸런싱을 위해 첫 14.3T 토큰 동안 바이어스 업데이트 속도 $\gamma$를 0.001로 설정하고, 남은 500B 토큰에 대해서는 0.0으로 설정합니다. 밸런스 손실의 경우 $\alpha$를 0.0001로 설정하여 단일 시퀀스 내에서 극단적인 불균형을 방지합니다. MTP 손실 가중치 $\lambda$는 첫 10T 토큰에 대해 0.3으로, 남은 4.8T 토큰에 대해서는 0.1로 설정됩니다.
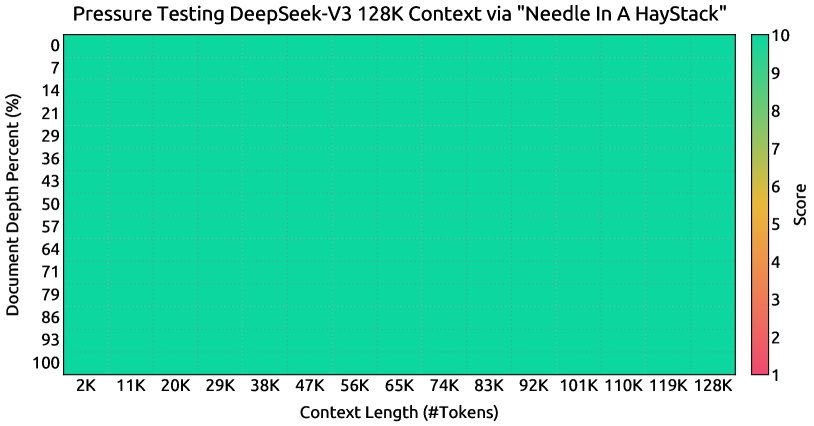
위 그래프는 DeepSeek-V3 모델의 “Needle In A Haystack” (NIAH) 테스트에 대한 평가 결과를 보여줍니다. 문서 깊이 퍼센트를 128K 토큰까지의 컨텍스트 윈도우 길이에 따라 나타냅니다. 주요 발견은 DeepSeek-V3가 모든 컨텍스트 윈도우 길이에서 우수한 성능을 보이며, 128K 토큰의 가장 큰 컨텍스트 크기에서도 높은 문서 깊이 퍼센트를 유지한다는 것입니다. 이는 많은 실제 NLP 작업에서 중요한 능력인 장거리 의존성 처리에서 모델의 견고성과 효과성을 보여줍니다.
사전 학습
긴 컨텍스트 확장
DeepSeek-V3는 DeepSeek-V2와 유사한 접근 방식을 채택하여 긴 컨텍스트 처리 능력을 구현했습니다. 사전 학습 단계 이후, YaRN을 적용하여 컨텍스트 확장을 수행하고 두 번의 추가 학습 단계를 진행했습니다. 각 단계는 1000 스텝으로 구성되어 컨텍스트 윈도우를 4K에서 32K로, 그리고 다시 128K로 점진적으로 확장했습니다.
YaRN 구성은 DeepSeek-V2에서 사용된 것과 동일하며, 디커플된 공유 키 $\mathbf{k}^{R}_{t}$에만 배타적으로 적용됩니다. 두 단계 모두에서 하이퍼파라미터는 동일하게 유지되었으며, 스케일 $s=40$, $\alpha=1$, $\beta=32$, 그리고 스케일링 팩터 $\sqrt{t}=0.1\ln{s}+1$로 설정되었습니다.
첫 번째 단계에서는 시퀀스 길이를 32K로 설정하고 배치 크기는 1920으로 설정했습니다. 두 번째 단계에서는 시퀀스 길이를 128K로 증가시키고 배치 크기는 480으로 감소시켰습니다. 두 단계 모두에서 학습률은 $7.3 \times 10^{-6}$로 설정되어 사전 학습 단계의 최종 학습률과 일치시켰습니다.
이러한 두 단계의 확장 학습을 통해 DeepSeek-V3는 128K 길이까지의 입력을 처리할 수 있게 되었으며, 강력한 성능을 유지할 수 있게 되었습니다. 앞서 보여진 그래프에서 확인할 수 있듯이, 지도 학습 미세조정 이후 DeepSeek-V3는 “Needle In A Haystack” (NIAH) 테스트에서 주목할 만한 성능을 달성했으며, 128K까지의 컨텍스트 윈도우 길이에 걸쳐 일관된 견고성을 보여주었습니다.
사전 학습
평가
평가 벤치마크
DeepSeek-V3의 기본 모델은 영어와 중국어가 대부분을 차지하는 다국어 코퍼스로 사전 학습되었기 때문에, 주로 영어와 중국어 벤치마크, 그리고 다국어 벤치마크에서 성능을 평가했습니다. 평가는 HAI-LLM 프레임워크에 통합된 내부 평가 프레임워크를 기반으로 수행되었습니다. 고려된 벤치마크는 다음과 같이 분류됩니다.
다중 주제 객관식 데이터셋에는 MMLU, MMLU-Redux, MMLU-Pro, MMMLU, C-Eval, CMMLU가 포함됩니다. 언어 이해 및 추론 데이터셋에는 HellaSwag, PIQA, ARC, BigBench Hard (BBH)가 포함됩니다. 클로즈드북 질의응답 데이터셋에는 TriviaQA와 NaturalQuestions가 포함됩니다. 독해 데이터셋에는 RACE, DROP, C3, CMRC가 포함됩니다. 참조 모호성 해소 데이터셋에는 CLUEWSC와 WinoGrande가 포함됩니다. 언어 모델링 데이터셋에는 Pile이 포함됩니다. 중국어 이해 및 문화 데이터셋에는 CCPM이 포함됩니다. 수학 데이터셋에는 GSM8K, MATH, MGSM, CMath가 포함됩니다. 코드 데이터셋에는 HumanEval, LiveCodeBench-Base (0801-1101), MBPP, CRUXEval이 포함됩니다. 표준화된 시험에는 AGIEval이 포함되며, AGIEval은 영어와 중국어 하위 집합을 모두 포함합니다.
이전 연구에서와 같이, HellaSwag, PIQA, WinoGrande, RACE-Middle, RACE-High, MMLU, MMLU-Redux, MMLU-Pro, MMMLU, ARC-Easy, ARC-Challenge, C-Eval, CMMLU, C3, CCPM 데이터셋에 대해서는 퍼플렉시티 기반 평가를 채택했습니다. TriviaQA, NaturalQuestions, DROP, MATH, GSM8K, MGSM, HumanEval, MBPP, LiveCodeBench-Base, CRUXEval, BBH, AGIEval, CLUEWSC, CMRC, CMath에 대해서는 생성 기반 평가를 채택했습니다. 또한 Pile-test에 대해서는 언어 모델링 기반 평가를 수행하고, 서로 다른 토크나이저를 사용하는 모델 간의 공정한 비교를 보장하기 위해 Bits-Per-Byte (BPB)를 메트릭으로 사용했습니다.
사전 학습
평가
평가 결과
DeepSeek-V3-Base를 DeepSeek-V2-Base, Qwen2.5 72B Base, LLaMA-3.1 405B Base와 같은 최신 오픈소스 기본 모델들과 비교했습니다. 모든 모델은 동일한 평가 설정을 공유하는 내부 평가 프레임워크에서 평가되었습니다. 평가 프레임워크의 변경으로 인해 DeepSeek-V2-Base의 성능이 이전에 보고된 결과와 약간의 차이를 보입니다.
전반적으로 DeepSeek-V3-Base는 DeepSeek-V2-Base와 Qwen2.5 72B Base를 포괄적으로 능가하며, 대부분의 벤치마크에서 LLaMA-3.1 405B Base를 뛰어넘어 가장 강력한 오픈소스 모델이 되었습니다.
각 오픈소스 기본 모델과의 세부적인 비교 결과는 다음과 같습니다.
DeepSeek-V2-Base와 비교했을 때, 모델 아키텍처의 개선, 모델 크기와 학습 토큰의 확장, 데이터 품질 향상으로 인해 DeepSeek-V3-Base는 예상대로 크게 향상된 성능을 달성했습니다.
중국의 최신 오픈소스 모델인 Qwen2.5 72B Base와 비교했을 때, 활성화된 파라미터가 절반에 불과함에도 DeepSeek-V3-Base는 특히 영어, 다국어, 코드, 수학 벤치마크에서 주목할 만한 우위를 보여줍니다. 중국어 벤치마크의 경우, 중국어 다중 주제 객관식 과제인 CMMLU를 제외하고 DeepSeek-V3-Base가 Qwen2.5 72B보다 더 나은 성능을 보여줍니다.
활성화된 파라미터가 11배 많은 가장 큰 오픈소스 모델인 LLaMA-3.1 405B Base와 비교했을 때도, DeepSeek-V3-Base는 다국어, 코드, 수학 벤치마크에서 더 나은 성능을 보여줍니다. 영어와 중국어 언어 벤치마크에서는 경쟁력 있거나 더 나은 성능을 보이며, 특히 BBH, MMLU 시리즈, DROP, C-Eval, CMMLU, CCPM에서 우수한 성능을 보입니다.
효율적인 아키텍처와 포괄적인 엔지니어링 최적화 덕분에 DeepSeek-V3는 매우 높은 학습 효율성을 달성했습니다. 학습 프레임워크와 인프라에서 DeepSeek-V3의 각 1조 토큰 학습에는 180K H800 GPU 시간만이 필요하며, 이는 72B나 405B 밀집 모델을 학습하는 것보다 훨씬 저렴합니다.
사전 학습
평가
멀티 토큰 예측에 대한 분석
멀티 토큰 예측(MTP) 전략의 효과를 검증하기 위해 서로 다른 규모에서 두 개의 기준 모델을 대상으로 분석을 수행했습니다. 작은 규모에서는 15.7B 총 파라미터를 가진 기준 MoE 모델을 1.33T 토큰으로 학습했습니다. 큰 규모에서는 228.7B 총 파라미터를 가진 기준 MoE 모델을 540B 토큰으로 학습했습니다. 이들 모델을 기반으로, 학습 데이터와 다른 아키텍처는 동일하게 유지한 채 1-깊이 MTP 모듈을 추가하여 MTP 전략으로 두 모델을 학습했습니다. 추론 시에는 MTP 모듈을 제거하므로 비교 모델들의 추론 비용은 정확히 동일합니다.
실험 결과는 MTP 전략이 대부분의 평가 벤치마크에서 모델 성능을 일관되게 향상시킨다는 것을 보여줍니다. 특히 BBH, MMLU, DROP과 같은 복잡한 추론이 필요한 작업에서 더 큰 성능 향상이 관찰되었습니다.
보조 손실이 없는 밸런싱 전략 분석
보조 손실이 없는 밸런싱 전략의 효과를 검증하기 위해 역시 서로 다른 규모에서 두 개의 기준 모델을 대상으로 분석을 수행했습니다. 작은 규모에서는 15.7B 총 파라미터를 가진 기준 MoE 모델을 1.33T 토큰으로, 큰 규모에서는 228.7B 총 파라미터를 가진 기준 MoE 모델을 578B 토큰으로 학습했습니다. 두 기준 모델 모두 순수하게 보조 손실을 사용하여 로드 밸런스를 장려했으며, 시그모이드 게이팅 함수와 상위-K 친화도 정규화를 사용했습니다.
실험 결과는 보조 손실이 없는 전략이 대부분의 평가 벤치마크에서 더 나은 모델 성능을 일관되게 달성한다는 것을 보여줍니다. 특히 HumanEval, MBPP, GSM8K, MATH와 같은 코딩과 수학 작업에서 더 큰 성능 향상이 관찰되었습니다.
배치 단위 로드 밸런스와 시퀀스 단위 로드 밸런스 비교
보조 손실이 없는 밸런싱과 시퀀스 단위 보조 손실의 핵심적인 차이는 밸런싱 범위에 있습니다. 배치 단위 대 시퀀스 단위입니다. 시퀀스 단위 보조 손실과 비교했을 때, 배치 단위 밸런싱은 각 시퀀스에 대해 도메인 내 밸런스를 강제하지 않는 더 유연한 제약을 부과합니다. 이러한 유연성은 전문가들이 서로 다른 도메인에 더 잘 특화될 수 있게 합니다.
사전 학습
평가
배치 단위 로드 밸런스와 시퀀스 단위 로드 밸런스 비교
이러한 특화 패턴을 검증하기 위해 Pile 테스트 세트의 서로 다른 도메인에서 16B 보조 손실 기반 기준 모델과 16B 보조 손실이 없는 모델의 전문가 로드를 기록하고 분석했습니다.
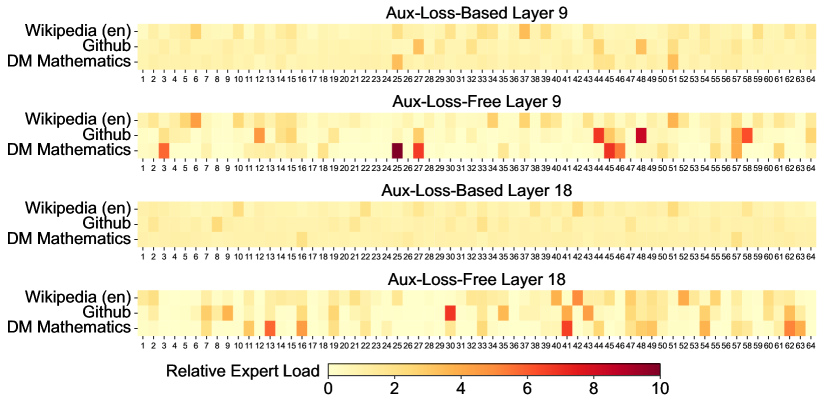
위 그래프는 Pile 테스트 세트의 세 가지 도메인에서 보조 손실이 없는 모델과 보조 손실 기반 모델의 전문가 로드를 시각화한 것입니다. 상대적 전문가 로드는 실제 전문가 로드와 이론적으로 균형 잡힌 전문가 로드 간의 비율을 나타냅니다. 공간 제약으로 인해 두 개 레이어의 결과만을 예시로 제시했으며, 모든 레이어의 결과는 부록 C에서 확인할 수 있습니다. 분석 결과는 예상대로 보조 손실이 없는 모델이 보조 손실 기반 모델보다 더 큰 전문가 특화 패턴을 보여줍니다.
이러한 유연성과 모델 성능 향상 간의 상관관계를 더 자세히 조사하기 위해, 각 학습 배치에서 로드 밸런스를 장려하는 배치 단위 보조 손실을 추가로 설계하고 검증했습니다. 실험 결과는 유사한 수준의 배치 단위 로드 밸런스를 달성할 때, 배치 단위 보조 손실도 보조 손실이 없는 방법과 유사한 모델 성능을 달성할 수 있음을 보여줍니다.
구체적으로, 1B MoE 모델을 사용한 실험에서 검증 손실은 시퀀스 단위 보조 손실을 사용할 때 2.258, 보조 손실이 없는 방법을 사용할 때 2.253, 배치 단위 보조 손실을 사용할 때 2.253으로 나타났습니다. 3B MoE 모델에서도 유사한 결과가 관찰되었습니다. 시퀀스 단위 보조 손실을 사용하는 모델은 2.085의 검증 손실을 달성했고, 보조 손실이 없는 방법이나 배치 단위 보조 손실을 사용하는 모델들은 동일하게 2.080의 검증 손실을 달성했습니다.
그러나 배치 단위 로드 밸런싱 방법들은 일관된 성능 향상을 보여주지만, 효율성 측면에서 두 가지 잠재적 과제에 직면합니다. (1) 특정 시퀀스나 작은 배치 내에서의 로드 불균형, (2) 추론 중 도메인 시프트로 인한 로드 불균형입니다. 첫 번째 과제는 대규모 전문가 병렬화와 데이터 병렬화를 사용하는 학습 프레임워크에 의해 자연스럽게 해결되며, 이는 각 마이크로배치의 큰 크기를 보장합니다. 두 번째 과제의 경우, 중복 전문가 배포를 통한 효율적인 추론 프레임워크를 설계하고 구현하여 극복했습니다.
학습 후 처리 과정
DeepSeek-V3는 다양한 도메인에 걸친 150만 개의 인스턴스로 구성된 지도 학습 데이터셋을 세심하게 큐레이팅하여 학습을 진행했습니다. 각 도메인별로 특화된 데이터 생성 방법을 적용했으며, 특히 추론 관련 데이터셋에 대해서는 DeepSeek-R1 모델을 활용한 고도화된 접근 방식을 채택했습니다.
추론 데이터의 경우, DeepSeek-R1이 생성한 데이터는 높은 정확도를 보이지만 과도한 사고 과정, 부적절한 포맷팅, 그리고 지나치게 긴 응답 길이와 같은 문제점들이 있었습니다. 연구진은 R1이 생성한 추론 데이터의 높은 정확도와 일반적인 포맷의 추론 데이터가 가진 명확성과 간결성 사이의 균형을 맞추고자 했습니다.
이를 위해 코드, 수학, 일반 추론과 같은 특정 도메인에 특화된 전문가 모델을 개발했습니다. 이 과정은 지도 학습 미세조정(SFT)과 강화학습(RL)을 결합한 파이프라인을 통해 이루어졌습니다. 각 인스턴스에 대해 두 가지 유형의 SFT 샘플이 생성되었습니다.
- <문제, 원본 응답> 형식의 기본 쌍
- <시스템 프롬프트, 문제, R1 응답> 형식의 확장 쌍
여기서 시스템 프롬프트는 모델이 반성과 검증 메커니즘이 포함된 응답을 생성하도록 세심하게 설계되었습니다.
RL 단계에서는 높은 온도 값을 사용한 샘플링을 통해 명시적인 시스템 프롬프트 없이도 R1이 생성한 데이터와 원본 데이터의 패턴을 모두 통합할 수 있는 응답을 생성하도록 했습니다. 수백 번의 RL 스텝을 거치면서 중간 RL 모델은 R1의 패턴을 학습하여 전반적인 성능을 전략적으로 향상시켰습니다.
RL 학습이 완료된 후에는 최종 모델을 위한 고품질 SFT 데이터를 선별하기 위해 리젝션 샘플링을 적용했습니다. 이때 전문가 모델들이 데이터 생성 소스로 활용되었습니다. 이러한 방법을 통해 최종 학습 데이터는 DeepSeek-R1의 장점을 유지하면서도 간결하고 효과적인 응답을 생성할 수 있게 되었습니다.
비추론 데이터의 경우, 창의적 글쓰기, 역할극, 단순 질의응답과 같은 작업에 대해서는 DeepSeek-V2.5를 활용하여 응답을 생성하고, 인간 평가자들이 데이터의 정확성과 적절성을 검증했습니다.
SFT 설정에서는 DeepSeek-V3-Base를 2 에폭 동안 미세조정했으며, 학습률은 코사인 감소 스케줄링을 통해 $5 \times 10^{-6}$에서 시작하여 점진적으로 $1 \times 10^{-6}$까지 감소시켰습니다. 학습 중에는 여러 샘플이 하나의 시퀀스로 패킹되었지만, 샘플 마스킹 전략을 통해 이들이 서로 독립적으로 유지되도록 했습니다.
강화학습 과정
DeepSeek-V3의 강화학습 과정에서는 규칙 기반 보상 모델(Rule-based Reward Model)과 모델 기반 보상 모델(Model-based Reward Model)을 함께 활용했습니다.
규칙 기반 보상 모델은 특정 규칙으로 검증이 가능한 문제들에 대해 피드백을 결정하는 데 사용됩니다. 예를 들어, 수학 문제의 경우 결정적인 답이 있으며, 모델이 지정된 형식(예: 박스 안)에 최종 답을 제공하도록 요구함으로써 규칙을 적용하여 정확성을 검증할 수 있습니다. 마찬가지로 LeetCode 문제의 경우에도 컴파일러를 통해 테스트 케이스를 기반으로 피드백을 생성할 수 있습니다. 이러한 규칙 기반 검증은 조작이나 악용에 강한 신뢰성을 제공합니다.
모델 기반 보상 모델은 자유 형식의 정답이 있는 문제들에 대해 응답이 기대하는 정답과 일치하는지 판단하는 데 사용됩니다. 반면 창의적 글쓰기와 같이 명확한 정답이 없는 문제들의 경우, 보상 모델은 질문과 해당 답변을 입력으로 받아 피드백을 제공합니다. 보상 모델은 DeepSeek-V3 SFT 체크포인트로부터 학습되었으며, 신뢰성을 높이기 위해 최종 보상뿐만 아니라 보상에 이르는 체인 오브 소트도 포함하는 선호도 데이터를 구축했습니다. 이러한 접근 방식은 특정 작업에서 보상 해킹의 위험을 완화하는 데 도움이 됩니다.
DeepSeek-V3는 DeepSeek-V2와 마찬가지로 정책 모델과 동일한 크기의 크리틱 모델을 사용하지 않고 그룹 점수로부터 기준선을 추정하는 Group Relative Policy Optimization (GRPO)를 채택했습니다. 구체적으로, 각 질문 $q$에 대해 GRPO는 이전 정책 모델 $\pi_{\theta_{old}}$로부터 출력 그룹 ${o_1, o_2, \cdots, o_G}$를 샘플링하고, 다음과 같은 목적 함수를 최대화하여 정책 모델 $\pi_{\theta}$를 최적화합니다.
\[\mathcal{J}_{GRPO}(\theta) = \mathbb{E}_{[q\sim P(Q),\{o_i\}_{i=1}^{G}\sim\pi_{\theta_{old}}(O|q)]}\frac{1}{G}\sum_{i=1}^{G}\left(\min\left(\frac{\pi_{\theta}(o_i|q)}{\pi_{\theta_{old}}(o_i|q)}A_i,\text{clip}\left(\frac{\pi_{\theta}(o_i|q)}{\pi_{\theta_{old}}(o_i|q)},1-\varepsilon,1+\varepsilon\right)A_i\right)-\beta\mathbb{D}_{KL}\left(\pi_{\theta}||\pi_{ref}\right)\right)\]여기서 $\varepsilon$과 $\beta$는 하이퍼파라미터이고, $\pi_{ref}$는 참조 모델입니다. $A_i$는 각 그룹 내 출력에 해당하는 보상 ${r_1, r_2, \ldots, r_G}$로부터 도출된 어드밴티지로, 다음과 같이 계산됩니다.
\[A_i = \frac{r_i - \text{mean}(\{r_1, r_2, \cdots, r_G\})}{\text{std}(\{r_1, r_2, \cdots, r_G\})}\]RL 과정에서는 코딩, 수학, 글쓰기, 역할극, 질의응답 등 다양한 도메인의 프롬프트를 포함시켰습니다. 이러한 접근 방식은 모델을 인간의 선호도에 더 잘 부합하도록 만들었을 뿐만 아니라, 특히 SFT 데이터가 제한된 시나리오에서 벤치마크 성능을 향상시켰습니다.
평가 과정
DeepSeek-V3의 평가는 기본 모델 테스트에 사용된 벤치마크 외에도 다양한 추가 벤치마크를 통해 이루어졌습니다. IFEval, FRAMES, LongBench v2, GPQA, SimpleQA, C-SimpleQA, SWE-Bench Verified, Aider, LiveCodeBench, Codeforces, 중국 전국 고등학교 수학 올림피아드(CNMO 2024), 그리고 미국 수학 초청 시험(AIME 2024) 등이 평가에 활용되었습니다.
비교 대상으로는 DeepSeek-V2-0506, DeepSeek-V2.5-0905, Qwen2.5 72B Instruct, LLaMA-3.1 405B Instruct, Claude-Sonnet-3.5-1022, GPT-4o-0513 등의 강력한 기준 모델들이 선정되었습니다. DeepSeek-V2 모델 시리즈에서는 가장 대표적인 변형들을 비교 대상으로 선택했으며, 비공개 모델들의 경우 각각의 API를 통해 평가가 수행되었습니다.
평가 구성의 경우, MMLU, DROP, GPQA, SimpleQA와 같은 표준 벤치마크에 대해서는 simple-evals 프레임워크의 평가 프롬프트를 채택했습니다. MMLU-Redux의 경우 제로샷 설정에서 Zero-Eval 프롬프트 형식을 활용했습니다. 다른 데이터셋들에 대해서는 데이터셋 제작자들이 제공한 원래의 평가 프로토콜과 기본 프롬프트를 따랐습니다.
코드와 수학 벤치마크의 경우, HumanEval-Mul 데이터셋은 Python, Java, Cpp, C#, JavaScript, TypeScript, PHP, Bash 등 총 8개의 주요 프로그래밍 언어를 포함합니다. LiveCodeBench는 2024년 8월부터 11월까지 수집된 데이터에 대해 체인 오브 소트(CoT) 방식과 비CoT 방식을 모두 사용하여 평가했습니다. Codeforces 데이터셋은 경쟁자 대비 백분위 점수로 측정되었으며, SWE-Bench verified는 에이전트리스 프레임워크를 사용하여 평가되었습니다. Aider 관련 벤치마크는 “diff” 형식을 사용하여 평가했습니다.
수학적 평가의 경우, AIME와 CNMO 2024는 0.7의 온도 값을 사용하여 평가되었으며, 결과는 16회 실행의 평균을 취했습니다. MATH-500은 그리디 디코딩을 사용했습니다. 모든 벤치마크에서 각 모델은 최대 8192 토큰까지 출력할 수 있도록 허용되었습니다.
평가 결과, DeepSeek-V3는 오픈소스 모델들 중 최고의 성능을 보여주었으며, GPT-4o와 Claude-3.5-Sonnet과 같은 최신 비공개 모델들과도 경쟁력 있는 성능을 달성했습니다. 영어 벤치마크에서 MMLU는 88.5점, MMLU-Redux는 89.1점, MMLU-Pro는 75.9점을 기록했으며, 특히 DROP에서는 91점의 F1 점수를 달성했습니다. 코드 관련 벤치마크에서는 HumanEval-Mul에서 82.6%, LiveCodeBench에서 40.5%의 정확도를 보였으며, 수학 관련 벤치마크에서는 AIME 2024에서 39.2%, MATH-500에서 90.2%의 정확도를 달성했습니다.
오픈 엔드 평가
DeepSeek-V3는 표준 벤치마크 외에도 LLM을 심사관으로 활용한 오픈 엔드 생성 작업에 대한 평가를 수행했습니다. AlpacaEval 2.0과 Arena-Hard에서 GPT-4-Turbo-1106을 심사관으로 활용하여 쌍별 비교를 진행했습니다.
Arena-Hard에서 DeepSeek-V3는 기준 모델인 GPT-4-0314 대비 85.5%의 인상적인 승률을 달성했으며, 이는 Claude-Sonnet-3.5-1022와 비슷한 수준의 성능입니다. 특히 코딩과 디버깅 작업을 포함한 복잡한 프롬프트 처리에서 강력한 능력을 보여주었습니다. DeepSeek-V3는 Arena-Hard 벤치마크에서 85% 이상의 성능을 달성한 최초의 오픈소스 모델이 되었으며, 이는 오픈소스와 비공개 모델 간의 성능 격차를 크게 줄였다는 점에서 의미가 있습니다.
AlpacaEval 2.0에서도 DeepSeek-V3는 비공개 모델과 오픈소스 모델 모두를 능가하는 뛰어난 성능을 보여주었습니다. 이는 글쓰기 작업과 단순 질의응답 시나리오에서의 탁월한 숙련도를 입증합니다. 특히 DeepSeek-V2.5-0905와 비교했을 때 20%의 큰 성능 향상을 보여주어, 단순 작업 처리 능력이 크게 개선되었음을 확인할 수 있습니다.
생성적 보상 모델로서의 DeepSeek-V3
DeepSeek-V3의 판단 능력을 GPT-4o와 Claude-3.5와 같은 최신 모델들과 비교하기 위해 RewardBench에서 평가를 진행했습니다. DeepSeek-V3는 GPT-4o-0806과 Claude-3.5-Sonnet-1022의 최신 버전들과 대등한 성능을 달성했으며, 다른 버전들을 능가했습니다.
더욱이 투표 기법을 통해 DeepSeek-V3의 판단 능력을 향상시킬 수 있음을 확인했습니다. 이를 바탕으로 DeepSeek-V3를 오픈 엔드 질문에 대한 자체 피드백 제공에 활용하여 정렬 과정의 효과성을 높였습니다.
DeepSeek-R1으로부터의 증류 효과
DeepSeek-V2.5를 기반으로 DeepSeek-R1으로부터의 증류 효과를 분석했습니다. 기준 모델은 짧은 체인 오브 소트 데이터로 학습되었으며, 비교 모델은 앞서 설명한 전문가 체크포인트가 생성한 데이터를 사용했습니다. 실험 결과는 증류 데이터의 효과성을 명확하게 보여주었으며, LiveCodeBench와 MATH-500 벤치마크 모두에서 상당한 성능 향상이 관찰되었습니다.
실험을 통해 흥미로운 트레이드오프가 발견되었습니다. 증류는 더 나은 성능을 가져왔지만 평균 응답 길이도 크게 증가시켰습니다. DeepSeek-V3에서는 모델의 정확도와 계산 효율성 사이의 균형을 맞추기 위해 최적의 설정을 신중하게 선택했습니다.
연구진은 추론 모델로부터의 지식 증류가 학습 후 최적화를 위한 유망한 방향을 제시한다고 판단했습니다. 현재 연구는 수학과 코딩 도메인의 데이터 증류에 초점을 맞추었지만, 이 접근 방식이 다른 인지 작업에서도 모델 성능을 향상시킬 수 있는 가능성을 보여줍니다. 다양한 도메인에서의 이 접근 방식의 추가 탐구는 향후 연구의 중요한 방향이 될 것입니다.
자체 보상 메커니즘
DeepSeek-V3는 보상이 강화학습에서 최적화 과정을 이끄는 핵심 요소라는 점에 주목했습니다. 코딩이나 수학과 같이 외부 도구를 통한 검증이 간단한 도메인에서는 RL이 뛰어난 효과를 보여주었습니다. 하지만 더 일반적인 시나리오에서는 하드 코딩을 통한 피드백 메커니즘을 구축하는 것이 현실적으로 어렵습니다.
DeepSeek-V3의 개발 과정에서는 이러한 광범위한 시나리오를 위해 constitutional AI 접근 방식을 채택했으며, DeepSeek-V3 자체의 투표 평가 결과를 피드백 소스로 활용했습니다. 이 자체 보상 메커니즘은 주목할 만한 정렬 효과를 보여주었으며, 주관적 평가에서 모델의 성능을 크게 향상시켰습니다. 추가적인 constitutional 입력을 통합함으로써 DeepSeek-V3는 constitutional 방향으로 최적화될 수 있었습니다.
연구진은 이러한 보완적 정보와 LLM을 피드백 소스로 결합하는 패러다임이 매우 중요하다고 판단했습니다. LLM은 다양한 시나리오의 비구조화된 정보를 보상으로 변환할 수 있는 다재다능한 프로세서 역할을 하며, 궁극적으로 LLM의 자체 개선을 촉진합니다. 자체 보상을 넘어서, 연구진은 일반적인 시나리오에서 모델 능력을 지속적으로 향상시킬 수 있는 다른 일반적이고 확장 가능한 보상 방법도 발견하기 위해 노력하고 있습니다.
멀티 토큰 예측
DeepSeek-V3는 다음 단일 토큰만을 예측하는 대신 MTP(Multi-Token Prediction) 기법을 통해 다음 2개의 토큰을 예측합니다. 이는 추측적 디코딩(speculative decoding) 프레임워크와 결합되어 모델의 디코딩 속도를 크게 향상시킬 수 있습니다. 추가로 예측된 토큰의 수용률에 대한 자연스러운 의문이 제기될 수 있는데, 평가 결과 다양한 생성 주제에 걸쳐 두 번째 토큰 예측의 수용률이 85%에서 90% 사이를 유지하는 것으로 나타났습니다. 이러한 높은 수용률 덕분에 DeepSeek-V3는 초당 토큰 생성량(TPS)을 1.8배 향상시킬 수 있었습니다.
배치 단위 로드 밸런스와 시퀀스 단위 로드 밸런스
보조 손실이 없는 밸런싱과 시퀀스 단위 보조 손실의 핵심적인 차이는 밸런싱의 범위에 있습니다. 시퀀스 단위 보조 손실과 비교했을 때, 배치 단위 밸런싱은 각 시퀀스에 대해 도메인 내 밸런스를 강제하지 않는 더 유연한 제약을 부과합니다. 이러한 유연성은 전문가들이 서로 다른 도메인에 더 잘 특화될 수 있게 합니다.
이러한 특화 패턴을 검증하기 위해 Pile 테스트 세트의 서로 다른 도메인에서 16B 보조 손실 기반 기준 모델과 16B 보조 손실이 없는 모델의 전문가 로드를 기록하고 분석했습니다. 분석 결과는 예상대로 보조 손실이 없는 모델이 보조 손실 기반 모델보다 더 큰 전문가 특화 패턴을 보여주었습니다.
하드웨어 설계에 대한 제안
DeepSeek-V3의 all-to-all 통신과 FP8 학습 방식 구현을 기반으로, AI 하드웨어 벤더들에게 다음과 같은 칩 설계 제안을 합니다.
통신 하드웨어의 경우, DeepSeek-V3는 계산과 통신을 오버랩하여 통신 지연 시간을 숨기는 방식을 구현했습니다. 이는 순차적 계산과 통신에 비해 통신 대역폭에 대한 의존도를 크게 줄입니다. 그러나 현재의 통신 구현은 비용이 많이 드는 SM(예: H800 GPU에서 사용 가능한 132개의 SM 중 20개를 이 목적으로 할당)에 의존하며, 이는 계산 처리량을 제한하게 됩니다. 더욱이 SM을 통신에 사용하면 텐서 코어가 완전히 활용되지 않아 상당한 비효율성이 발생합니다.
현재 SM은 all-to-all 통신을 위해 주로 다음과 같은 작업을 수행합니다.
- IB와 NVLink 도메인 간의 데이터 전달과 동일한 노드 내의 여러 GPU로 향하는 IB 트래픽을 단일 GPU에서 집계
- RDMA 버퍼(등록된 GPU 메모리 영역)와 입출력 버퍼 간의 데이터 전송
- all-to-all 결합을 위한 리듀스 연산 실행
- IB와 NVLink 도메인에 걸쳐 여러 전문가로의 청크화된 데이터 전송 중 세밀한 메모리 레이아웃 관리
미래의 벤더들이 이러한 통신 작업을 귀중한 계산 유닛 SM에서 오프로드하여 GPU 코프로세서나 NVIDIA SHARP와 같은 네트워크 코프로세서 역할을 하는 하드웨어를 개발하기를 기대합니다. 더 나아가 애플리케이션 프로그래밍 복잡성을 줄이기 위해 이 하드웨어가 계산 유닛의 관점에서 IB(스케일아웃)와 NVLink(스케일업) 네트워크를 통합하기를 바랍니다. 이러한 통합 인터페이스를 통해 계산 유닛은 간단한 프리미티브를 기반으로 한 통신 요청을 제출함으로써 IB-NVLink 통합 도메인 전체에서 읽기, 쓰기, 멀티캐스트, 리듀스와 같은 연산을 쉽게 수행할 수 있습니다.
계산 하드웨어의 경우, 텐서 코어에서 더 높은 FP8 GEMM 누적 정밀도가 필요합니다. 현재 NVIDIA Hopper 아키텍처의 텐서 코어 구현에서 FP8 GEMM은 최대 지수를 기반으로 가수 곱을 오른쪽으로 시프트하여 정렬한 후 더하는 고정 소수점 누적을 사용합니다. 실험 결과 부호-채움 오른쪽 시프트 후 각 가수 곱의 최상위 14비트만 사용하고 이 범위를 초과하는 비트는 절삭하는 것으로 나타났습니다. 그러나 예를 들어 32개의 FP8 × FP8 곱셈의 누적에서 정확한 FP32 결과를 얻으려면 최소 34비트의 정밀도가 필요합니다. 따라서 미래의 칩 설계에서는 텐서 코어의 누적 정밀도를 높여 전체 정밀도 누적을 지원하거나, 학습과 추론 알고리즘의 정확도 요구사항에 따라 적절한 누적 비트 폭을 선택하기를 권장합니다. 이러한 접근 방식은 오차를 허용 가능한 범위 내로 유지하면서 계산 효율성을 유지할 수 있습니다.
타일 및 블록 단위 양자화 지원
현재 GPU는 텐서 단위 양자화만 지원하며, DeepSeek-V3에서 구현한 타일 및 블록 단위 양자화와 같은 세밀한 양자화에 대한 네이티브 지원이 부족합니다. 현재 구현에서는 $N_C$ 간격에 도달하면 부분 결과가 텐서 코어에서 CUDA 코어로 복사되어 스케일링 팩터를 곱한 후 CUDA 코어의 FP32 레지스터에 더해집니다. 정밀한 FP32 누적 전략과 결합하여 역양자화 오버헤드가 크게 완화되지만, 텐서 코어와 CUDA 코어 간의 빈번한 데이터 이동은 여전히 계산 효율성을 제한합니다.
따라서 미래의 칩이 텐서 코어가 스케일링 팩터를 받아 그룹 스케일링과 함께 MMA를 구현할 수 있도록 함으로써 세밀한 양자화를 지원하기를 권장합니다. 이렇게 하면 최종 결과가 생성될 때까지 전체 부분합 누적과 역양자화가 텐서 코어 내부에서 직접 완료될 수 있어 빈번한 데이터 이동을 피할 수 있습니다.
온라인 양자화 지원
현재 구현은 연구에서 입증된 효과에도 불구하고 온라인 양자화를 효과적으로 지원하는 데 어려움을 겪고 있습니다. 기존 프로세스에서는 양자화를 위해 128개의 BF16 활성화 값(이전 계산의 출력)을 HBM(High Bandwidth Memory)에서 읽어야 하며, 양자화된 FP8 값은 다시 HBM에 쓰여진 후 MMA를 위해 다시 읽혀야 합니다.
이러한 비효율성을 해결하기 위해 미래의 칩이 FP8 캐스트와 TMA(Tensor Memory Accelerator) 접근을 단일 융합 연산으로 통합하여, 활성화가 전역 메모리에서 공유 메모리로 전송되는 동안 양자화가 완료될 수 있도록 하기를 권장합니다. 또한 속도 향상을 위한 워프 수준 캐스트 명령어를 지원하여 레이어 정규화와 FP8 캐스트의 더 나은 융합을 촉진하기를 권장합니다. 대안으로 HBM 근처에 계산 로직을 배치하는 근접 메모리 컴퓨팅 접근 방식을 채택할 수 있습니다. 이 경우 BF16 요소는 GPU로 읽혀지는 과정에서 직접 FP8로 캐스트되어 오프칩 메모리 접근을 약 50% 줄일 수 있습니다.
전치된 GEMM 연산 지원
현재 아키텍처는 행렬 전치와 GEMM 연산의 융합을 어렵게 만듭니다. DeepSeek-V3의 워크플로우에서는 순방향 패스 중에 활성화가 1x128 FP8 타일로 양자화되어 저장됩니다. 역방향 패스에서는 행렬을 읽어 역양자화하고, 전치한 후, 128x1 타일로 다시 양자화하여 HBM에 저장해야 합니다. 메모리 연산을 줄이기 위해 미래의 칩이 학습과 추론 모두에 필요한 정밀도에 대해 MMA 연산 전에 공유 메모리에서 행렬의 직접 전치 읽기를 가능하게 하기를 권장합니다. FP8 포맷 변환과 TMA 접근의 융합과 결합하면 이러한 개선은 양자화 워크플로우를 크게 간소화할 것입니다.
결론과 한계점, 그리고 향후 연구 방향
DeepSeek-V3는 총 671B 파라미터와 활성화되는 37B 파라미터를 가진 대규모 MoE 언어 모델로, 14.8T 토큰으로 학습되었습니다. MLA와 DeepSeekMoE 아키텍처를 기반으로 하며, 로드 밸런싱을 위한 보조 손실이 없는 전략과 더 강력한 성능을 위한 멀티 토큰 예측 학습 목표를 도입했습니다. FP8 학습 지원과 세밀한 엔지니어링 최적화를 통해 비용 효율적인 학습이 가능했으며, DeepSeek-R1 시리즈 모델로부터의 추론 능력 증류도 성공적으로 이루어졌습니다.
포괄적인 평가 결과, DeepSeek-V3는 현재 이용 가능한 오픈소스 모델 중 가장 강력한 성능을 보여주었으며, GPT-4o와 Claude-3.5-Sonnet과 같은 주요 비공개 모델들과 비슷한 수준의 성능을 달성했습니다. 또한 사전 학습, 컨텍스트 길이 확장, 학습 후 처리를 포함한 전체 학습에 단 2.788M H800 GPU 시간만이 소요되어 경제적인 학습 비용을 유지했습니다.
그러나 DeepSeek-V3는 몇 가지 한계점도 가지고 있습니다. 첫째, 효율적인 추론을 위해 권장되는 배포 단위가 상대적으로 크기 때문에 소규모 팀에게는 부담이 될 수 있습니다. 둘째, DeepSeek-V2보다 두 배 이상 빠른 생성 속도를 달성했음에도 불구하고 여전히 개선의 여지가 있습니다. 다행히도 이러한 한계점들은 더 발전된 하드웨어의 개발과 함께 자연스럽게 해결될 것으로 예상됩니다.
DeepSeek는 AGI(인공 일반 지능)라는 궁극적인 목표를 향해 꾸준히 나아가기 위해 장기주의적 관점에서 오픈소스 모델 개발을 지속할 것입니다. 향후 연구는 다음과 같은 방향에 전략적으로 투자할 계획입니다.
첫째, 모델 아키텍처를 지속적으로 연구하고 개선하여 학습과 추론 효율성을 더욱 향상시키고 무한한 컨텍스트 길이를 효율적으로 지원하는 것을 목표로 합니다. 또한 트랜스포머의 아키텍처적 한계를 극복하여 모델링 능력의 경계를 넓히고자 합니다.
둘째, 학습 데이터의 양과 질을 지속적으로 개선하고, 추가적인 학습 신호 소스를 탐구하여 더 포괄적인 차원에서 데이터 스케일링을 추진할 것입니다.
셋째, 모델의 깊은 사고 능력을 지속적으로 탐구하고 개선하여 추론의 길이와 깊이를 확장함으로써 지능과 문제 해결 능력을 향상시킬 것입니다.
마지막으로, 고정된 벤치마크 세트에 대한 최적화가 모델 능력에 대한 잘못된 인상을 줄 수 있다는 점을 고려하여, 더 포괄적이고 다차원적인 모델 평가 방법을 탐구할 것입니다.
저정밀도 학습에 대한 실험 연구
DeepSeek-V3의 저정밀도 학습 성능을 검증하기 위해 BF16과 FP8 데이터 타입을 사용한 학습 실험을 진행했습니다.
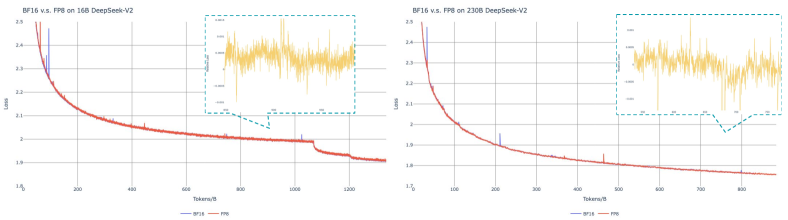
위 그래프는 BF16과 FP8 데이터 타입을 사용한 학습 과정에서의 손실 곡선을 보여줍니다. 손실 값은 0.9의 계수를 가진 지수 이동 평균(EMA)을 통해 스무딩되었습니다. 두 데이터 타입의 학습 곡선이 매우 유사한 패턴을 보이는 것을 확인할 수 있으며, 이는 FP8이 BF16과 비슷한 수준의 학습 성능을 달성할 수 있음을 시사합니다.
연구진은 서로 다른 규모의 두 가지 기준 모델을 대상으로 FP8 혼합 정밀도 프레임워크를 검증했습니다. 작은 규모에서는 약 16B의 총 파라미터를 가진 MoE 모델을 1.33T 토큰으로 학습했으며, 큰 규모에서는 약 230B의 총 파라미터를 가진 MoE 모델을 0.9T 토큰으로 학습했습니다. 실험 결과, 고정밀도 누적과 세밀한 양자화 전략을 통해 상대 오차를 0.25% 미만으로 유지할 수 있었습니다.
블록 단위 양자화의 경우, 연구진의 타일 단위 세밀한 양자화가 특성 이상치로 인한 오차를 효과적으로 완화하지만, 활성화 양자화에 대해 서로 다른 그룹화가 필요하다는 점을 발견했습니다. 순방향 패스에서는 1x128 그룹화를, 역방향 패스에서는 128x1 그룹화를 사용해야 합니다. 이러한 과정은 활성화 그래디언트에도 동일하게 적용됩니다.
단순한 접근 방식으로는 모델 가중치를 양자화하는 것과 같이 128x128 요소 단위로 블록 단위 양자화를 적용하는 것입니다. 이 방식을 사용하면 역방향 패스에서는 전치 연산만 필요합니다. 하지만 실험 결과, 활성화 그래디언트를 계산하고 얕은 층으로 체인처럼 역전파하는 Dgrad 연산이 정밀도에 매우 민감하다는 것이 밝혀졌습니다. 구체적으로, 약 16B의 총 파라미터를 가진 MoE 모델을 300B 토큰으로 학습했을 때 활성화 그래디언트의 블록 단위 양자화는 모델의 발산을 초래했습니다.
연구진은 이러한 민감성이 토큰 간에 상관관계가 있는 이상치로 인해 발생한다고 추정했습니다. Xi와 연구진이 지적한 것처럼, 이러한 이상치는 블록 단위 양자화 방식으로는 효과적으로 관리할 수 없습니다.
전문가 특화 패턴 분석
DeepSeek-V3의 16B 보조 손실 기반 모델과 보조 손실이 없는 모델의 전문가 로드를 Pile 테스트 세트에서 분석했습니다. 이 분석은 각 모델의 전문가 특화 패턴을 이해하고 비교하기 위해 수행되었습니다.
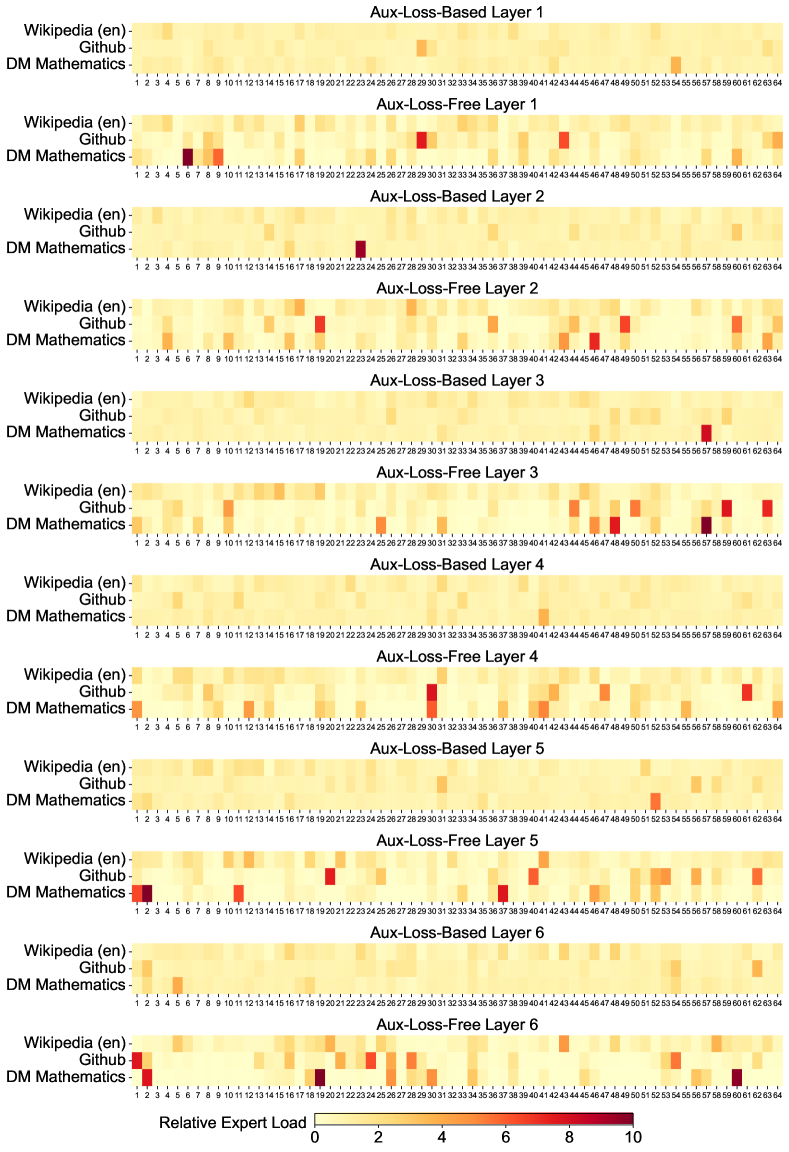
위 그래프는 모델의 첫 번째부터 일곱 번째 레이어까지의 전문가 로드 패턴을 보여줍니다. 각 행은 서로 다른 레이어를 나타내며, 노란색과 빨간색 픽셀의 강도는 각 전문가의 활성화 강도를 나타냅니다. 보조 손실이 없는 모델이 보조 손실 기반 모델보다 더 뚜렷한 전문가 특화 패턴을 보여주는 것을 확인할 수 있습니다.
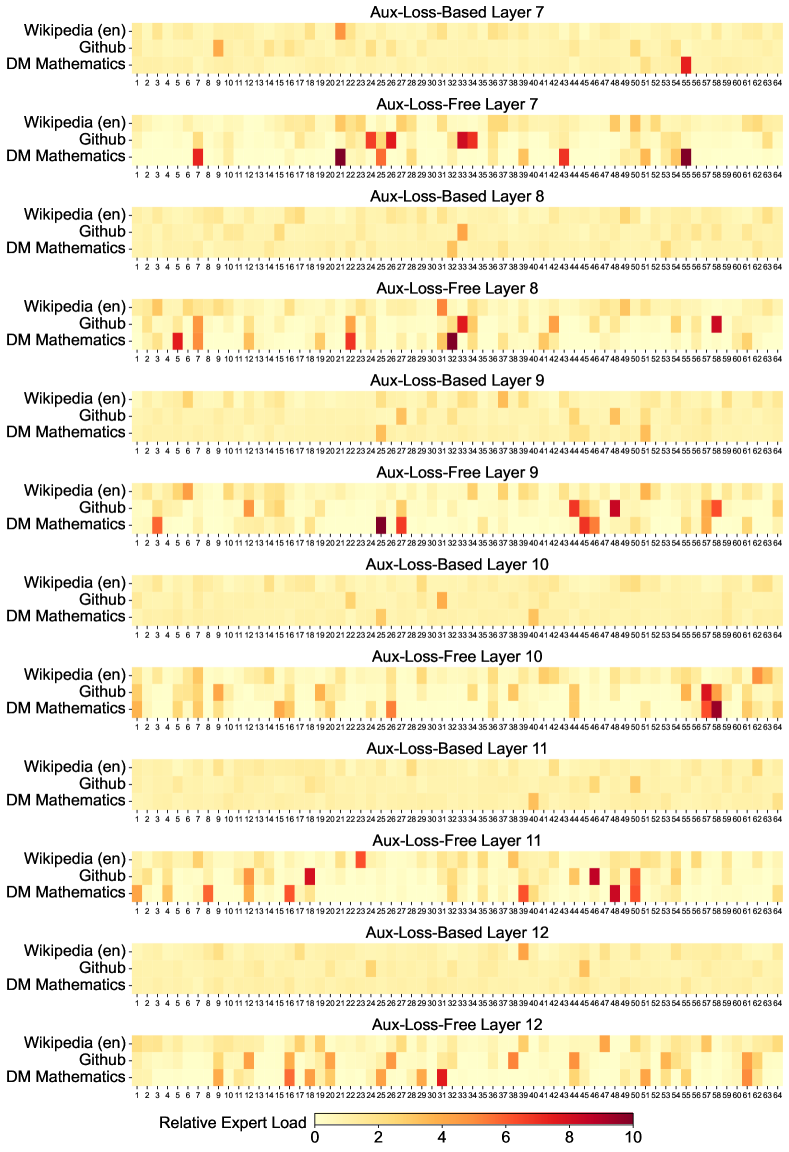
중간 레이어(7-13)에서도 유사한 패턴이 관찰됩니다. 보조 손실이 없는 모델의 전문가들은 더 명확한 특화 영역을 가지고 있으며, 이는 각 전문가가 특정 도메인이나 작업에 더 집중적으로 특화되어 있음을 시사합니다.
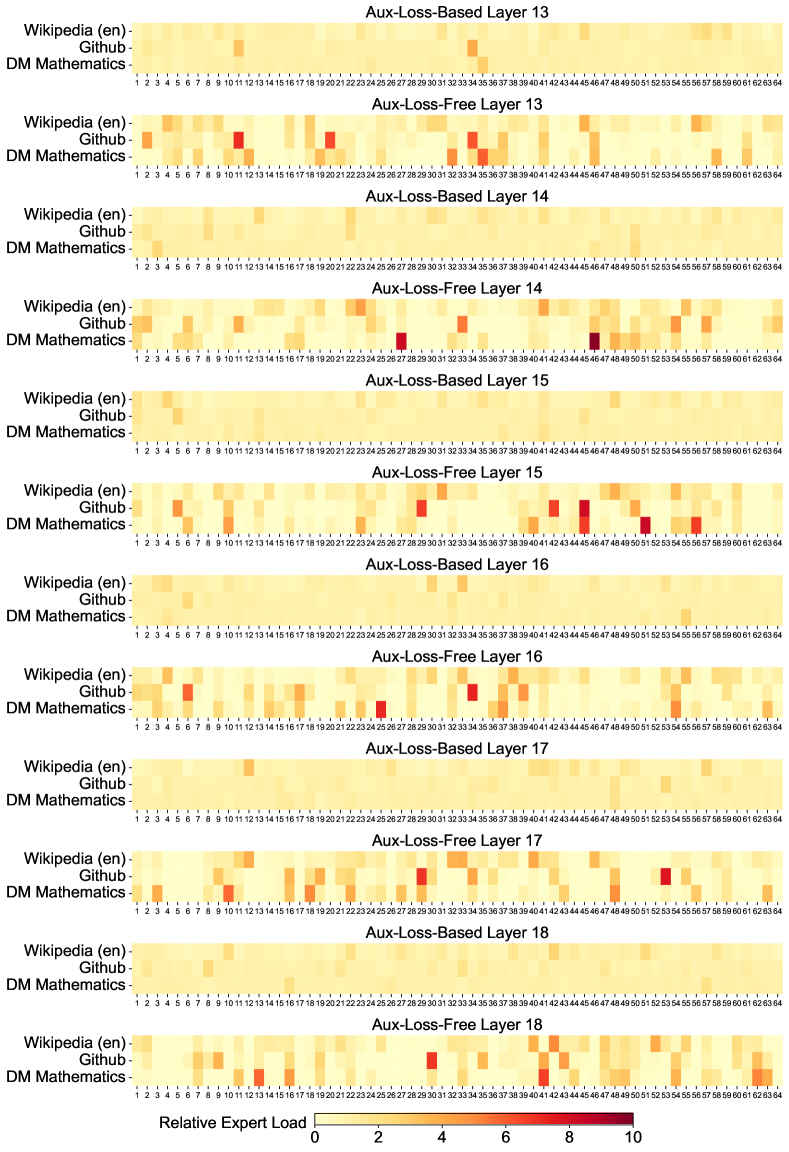
13-19 레이어 구간에서도 보조 손실이 없는 모델의 전문가들은 더 강한 특화 패턴을 보여줍니다. 이는 보조 손실이 없는 접근 방식이 전문가들의 자연스러운 특화를 촉진한다는 것을 입증합니다.
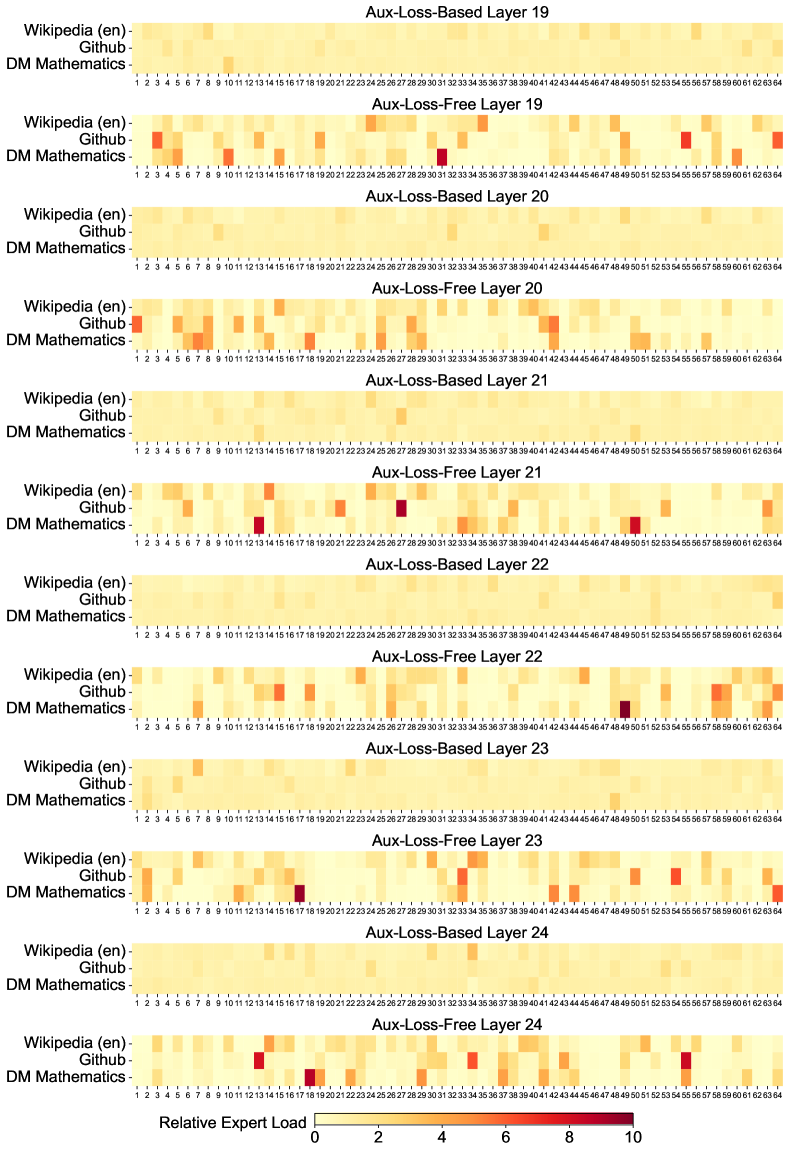
상위 레이어(19-25)에서도 이러한 경향이 지속됩니다. 보조 손실이 없는 모델의 전문가들은 더 선명한 활성화 패턴을 보여주며, 이는 각 전문가가 자신의 고유한 전문 영역을 더 효과적으로 개발했음을 나타냅니다.
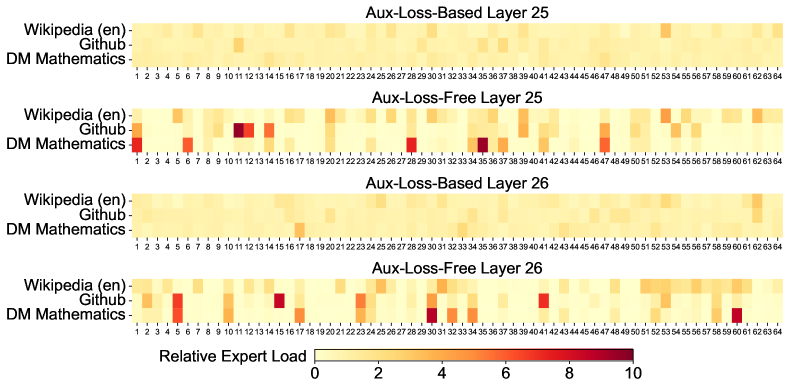
마지막 레이어들(25-27)에서도 보조 손실이 없는 모델의 전문가들은 더 뚜렷한 특화 패턴을 유지합니다. 상대적 전문가 로드는 실제 전문가 로드와 이론적으로 균형 잡힌 전문가 로드 간의 비율을 나타내며, 이 분석을 통해 보조 손실이 없는 전략이 전문가들의 자연스러운 특화를 더 잘 지원한다는 것을 확인할 수 있습니다.
References
Subscribe via RSS