Tulu 3: Pushing Frontiers in Open Language Model Post-Training
by Allen Institute for AI
TL;DR
이 연구를 시작하게 된 배경과 동기는 무엇입니까?
현대 언어 모델의 발전에도 불구하고, 공개된 후처리 학습 방법들은 비공개 상업용 모델들에 비해 성능이 뒤처져 있었습니다. 특히 인간 피드백 기반 강화학습(RLHF)과 같은 고급 학습 기법들이 주로 비공개로 개발되어 왔기 때문에, 공개 연구 커뮤니티는 이러한 기술적 격차를 좁히는 데 어려움을 겪어왔습니다. TÜLU 3 연구는 이러한 격차를 해소하고, 완전히 공개된 최첨단 후처리 학습 프레임워크를 제공하여 언어 모델 연구의 민주화에 기여하고자 시작되었습니다.
이 연구에서 제시하는 새로운 해결 방법은 무엇입니까?
TÜLU 3는 세 가지 핵심적인 학습 방법을 통합한 혁신적인 프레임워크를 제시합니다. 첫째, 지도 미세조정(SFT)을 통해 기본 모델의 능력을 향상시킵니다. 둘째, 직접 선호도 최적화(DPO)를 도입하여 보상 모델 없이도 인간의 선호도를 효과적으로 학습합니다. 셋째, 가장 주목할 만한 혁신으로 검증 가능한 보상을 통한 강화학습(RLVR)을 제안하여, 수학적 추론이나 코딩과 같이 객관적으로 검증 가능한 작업에서의 성능을 크게 향상시켰습니다.
제안된 방법은 어떻게 구현되었습니까?
TÜLU 3의 구현은 체계적인 데이터 큐레이션과 최적화된 학습 파이프라인을 통해 이루어졌습니다. 연구진은 백만 개 이상의 지도 학습 샘플과 수십만 개의 선호도 데이터를 신중하게 선별하고 정제했습니다. 특히 RLVR 구현에서는 검증 가능한 보상 신호를 효율적으로 계산하기 위한 병렬 처리 구조를 도입했으며, 배치 정규화와 그래디언트 체크포인팅 등의 최적화 기법을 통해 학습 효율성을 크게 향상시켰습니다. 또한 포괄적인 평가 프레임워크를 구축하여 개발 평가와 미공개 평가를 통해 모델의 성능을 철저히 검증했습니다.
이 연구의 결과가 가지는 의미는 무엇입니까?
TÜLU 3의 성과는 공개 언어 모델 연구의 새로운 지평을 열었습니다. 특히 RLVR의 도입으로 수학적 추론과 코드 생성 같은 검증 가능한 작업에서 기존 방식 대비 23.5%의 성능 향상을 달성했으며, 이는 비공개 상업용 모델들과 견줄 만한 수준입니다. 더욱 중요한 것은 모든 코드, 데이터, 모델을 공개함으로써 후속 연구자들이 이를 기반으로 발전시킬 수 있는 기반을 마련했다는 점입니다. 이는 언어 모델 연구의 투명성과 접근성을 크게 향상시키는 동시에, 향후 더 발전된 공개 모델들의 개발을 촉진할 것으로 기대됩니다.
TÜLU 3: 언어 모델 후처리 학습의 새로운 지평을 열다
TÜLU 3는 최신 언어 모델의 행동을 개선하고 새로운 능력을 향상시키기 위한 포괄적인 후처리 학습 프레임워크입니다. 이 연구는 기존의 독점적인 후처리 학습 방법들과 달리, 완전히 공개된 최첨단 후처리 학습 모델 제품군을 제시합니다.
TÜLU 3는 Llama 3.1 기본 모델을 기반으로 하여 개발되었으며, Llama 3.1의 명령어 버전, Qwen 2.5, Mistral은 물론 GPT-4o-mini와 Claude 3.5-Haiku와 같은 비공개 모델들의 성능까지도 뛰어넘는 결과를 달성했습니다. 이 연구에서는 세 가지 주요 학습 알고리즘을 도입했습니다.
-
지도 미세조정(Supervised Fine-tuning, SFT): 기본적인 지도 학습 방식으로 모델을 특정 작업에 맞게 조정합니다.
-
직접 선호도 최적화(Direct Preference Optimization, DPO): 보상 모델링 없이도 인간의 선호도에 직접 맞춰 모델을 최적화하는 방식입니다.
-
검증 가능한 보상을 통한 강화학습(Reinforcement Learning with Verifiable Rewards, RLVR): 이 연구에서 새롭게 제안하는 방법으로, 인간 피드백 대신 검증 가능한 보상 신호를 사용하여 모델을 학습시킵니다.
TÜLU 3의 가장 큰 특징은 완벽한 재현성과 투명성에 있습니다. 연구진은 다양한 핵심 기술을 위한 데이터셋, 데이터 큐레이션과 평가를 위한 강력한 도구, 학습 코드와 인프라, 그리고 가장 중요하게는 TÜLU 3 접근 방식을 재현하고 다른 도메인에 적용하기 위한 상세한 보고서를 모두 공개했습니다. 또한 개발 평가와 미공개 평가를 포함하는 다중 작업 평가 체계를 구축하고, 표준 벤치마크 구현을 제공하며, 기존 공개 데이터셋의 오염을 제거하는 작업도 수행했습니다.
TÜLU 3 개요
TÜLU 3는 대규모 언어 모델의 성능을 향상시키기 위한 포괄적인 데이터셋과 평가 프레임워크를 제시합니다. 이 연구는 크게 세 가지 핵심 구성 요소로 이루어져 있습니다. TÜLU 3 데이터, TÜLU 3 평가, 그리고 TÜLU 3 레시피입니다.
TÜLU 3 데이터는 두 가지 주요 방법론을 통해 구축되었습니다. 첫째, 공개 데이터셋으로부터 프롬프트를 수집하는 방식입니다. 연구진은 FLAN, ShareGPT, WizardLM과 같은 고품질 데이터셋들을 신중하게 선별하고 통합했습니다. 둘째, 특정 기술을 목표로 하는 프롬프트를 합성하는 방식입니다. 이는 모델이 특정 작업이나 능력을 습득할 수 있도록 설계된 맞춤형 프롬프트들을 포함합니다.
TÜLU 3 평가는 모델의 성능을 정확하고 공정하게 측정하기 위한 체계적인 프레임워크를 제공합니다. 이는 다양한 작업과 도메인에 걸친 포괄적인 평가 메트릭스를 포함하며, 특히 프롬프트 오염(prompt contamination) 문제를 해결하기 위한 철저한 데이터 정화 과정을 포함합니다.
TÜLU 3 레시피는 이 프레임워크를 실제로 구현하고 적용하는 방법을 상세히 설명합니다. 여기에는 데이터 전처리, 모델 학습, 평가 방법론 등이 포함되어 있으며, 다른 연구자들이 이 접근 방식을 재현하고 자신들의 연구에 적용할 수 있도록 상세한 지침을 제공합니다.
마지막으로, 평가 및 결과 섹션에서는 TÜLU 3를 사용한 실험 결과와 성능 분석을 제시합니다. 이는 다양한 벤치마크에서의 성능 측정과 기존 모델들과의 비교 분석을 포함하며, TÜLU 3의 효과성을 실증적으로 입증합니다.
TÜLU 3 데이터
TÜLU 3의 데이터 구축 과정은 프롬프트 큐레이션과 프롬프트 오염 제거라는 두 가지 핵심 단계로 구성됩니다. 프롬프트 큐레이션 단계에서는 공개 데이터셋으로부터의 소싱과 목표 기술을 위한 합성이라는 두 가지 주요 접근 방식을 채택했습니다.
공개 데이터셋 소싱 과정에서는 FLAN-v2, ShareGPT, WizardLM, LIMA, Open-Orca 등의 고품질 데이터셋을 활용했습니다. 특히 Tunstall과 연구진이 개발한 Zephyr 접근법을 기반으로, 각 데이터셋의 품질과 다양성을 면밀히 평가하여 선별했습니다. 이 과정에서 연구진은 데이터의 품질을 보장하기 위해 여러 필터링 기준을 적용했으며, 특히 부적절하거나 유해한 콘텐츠를 제거하는 데 중점을 두었습니다.
목표 기술을 위한 프롬프트 합성 과정에서는 특정 능력을 향상시키기 위한 맞춤형 프롬프트를 생성했습니다. 이는 Bai와 연구진이 제안한 Constitutional AI 접근법을 확장한 것으로, 모델이 특정 작업이나 도메인에서 뛰어난 성능을 발휘할 수 있도록 설계되었습니다. 예를 들어, 수학적 추론, 코드 생성, 다국어 이해력 등 특정 영역에서의 전문성을 향상시키기 위한 프롬프트들이 포함되어 있습니다.
프롬프트 오염 제거 과정은 특히 중요한 단계입니다. 연구진은 n-gram 매칭을 기반으로 한 상향식 접근법을 사용하여 평가 샘플과 학습 데이터 간의 중복을 식별하고 제거했습니다. 이는 모델이 단순히 학습 데이터를 기억하는 것이 아니라, 진정한 일반화 능력을 평가할 수 있도록 보장합니다. 이 과정에서 연구진은 각 샘플에 대한 오염도를 정량화하고, 일정 임계값을 초과하는 샘플들을 제거하는 방식을 채택했습니다.
이러한 철저한 데이터 큐레이션과 정화 과정을 통해, TÜLU 3는 높은 품질과 다양성을 갖춘 동시에 평가의 신뢰성을 보장하는 데이터셋을 구축할 수 있었습니다. 특히 이 과정은 Schulman과 연구진이 제안한 PPO 알고리즘의 효과적인 적용을 가능하게 하여, 모델의 학습 효율성을 크게 향상시켰습니다.
지도 학습 기반 미세조정
TÜLU 3의 핵심 구성 요소 중 하나인 지도 학습 기반 미세조정(Supervised Fine-tuning, SFT)은 기본 언어 모델의 성능을 향상시키기 위한 첫 번째 단계입니다. 이 과정은 크게 데이터 준비와 학습 과정 최적화의 두 가지 주요 측면으로 구성됩니다.
SFT 데이터 구축 과정에서는 프롬프트를 SFT 데이터로 변환하는 체계적인 방법론을 도입했습니다. Tunstall과 연구진이 제안한 Zephyr 접근법을 기반으로, 연구진은 다양한 소스에서 수집된 프롬프트들을 일관된 형식의 학습 데이터로 변환했습니다. 이 과정에서는 각 프롬프트의 품질과 적합성을 평가하고, 필요한 경우 수정하거나 보완하는 작업이 수행되었습니다.
TÜLU 3 SFT Mix는 특별히 설계된 데이터 혼합 전략을 활용합니다. 이 전략은 Schulman과 연구진이 개발한 PPO(Proximal Policy Optimization) 알고리즘의 효과적인 적용을 가능하게 하는 방식으로 데이터를 구성합니다. 데이터 혼합 과정에서는 다음과 같은 요소들이 고려됩니다.
- 데이터 다양성: 다양한 도메인과 작업 유형을 포괄하는 균형 잡힌 데이터셋 구성
- 품질 관리: 부적절하거나 편향된 콘텐츠를 필터링하는 엄격한 품질 기준 적용
- 크기 최적화: 모델 규모와 학습 효율성을 고려한 적절한 데이터셋 크기 설정
핵심 데이터 실험에서는 다양한 데이터 구성과 필터링 방식의 효과를 검증했습니다. 특히, Bai와 연구진이 제안한 Constitutional AI 접근법을 확장하여, 모델의 안전성과 성능을 동시에 향상시킬 수 있는 데이터 선별 기준을 개발했습니다.
SFT 레시피와 분석 과정에서는 학습 과정의 최적화를 위한 다양한 실험이 수행되었습니다. 특히 배치 집계(Batch Aggregation) 기법의 도입은 학습 효율성을 크게 향상시켰습니다. 이 기법은 \(\text{batch size}\)와 \(\text{learning rate}\)의 관계를 최적화하여, 더 안정적이고 효과적인 학습을 가능하게 합니다.
학습 과정에서는 다음과 같은 수식을 기반으로 손실 함수를 정의합니다.
\[\mathcal{L}_{\text{SFT}} = -\mathbb{E}_{(x,y)\sim \mathcal{D}} [\log P_\theta(y\vert x)]\]여기서 \(P_\theta(y\vert x)\)는 입력 \(x\)가 주어졌을 때 모델이 출력 \(y\)를 생성할 확률을 나타내며, \(\mathcal{D}\)는 SFT 데이터셋을 의미합니다.
지도 학습 기반 미세조정의 핵심 실험과 분석
TÜLU 3의 지도 학습 기반 미세조정 과정에서 수행된 핵심 학습 실험들은 모델의 성능을 최적화하기 위한 다양한 기술적 접근을 검증했습니다. 특히 배치 집계 기법의 효과성을 검증하기 위해, 연구진은 다음과 같은 수정된 학습 목적 함수를 도입했습니다.
\[\mathcal{L}_{\text{aggregated}} = \frac{1}{B} \sum_{i=1}^B \mathcal{L}_{\text{SFT}}^{(i)} + \lambda \mathcal{R}(\theta)\]여기서 \(B\)는 배치 크기, \(\mathcal{L}_{\text{SFT}}^{(i)}\)는 \(i\)번째 배치에 대한 SFT 손실, \(\lambda\)는 정규화 계수, 그리고 \(\mathcal{R}(\theta)\)는 정규화 항을 나타냅니다.
배치 집계 과정에서는 그래디언트 누적(Gradient Accumulation)을 활용하여 효과적인 대규모 배치 학습을 구현했습니다. 이는 다음과 같은 그래디언트 업데이트 규칙을 따릅니다.
\[\theta_{t+1} = \theta_t - \eta \frac{1}{K} \sum_{k=1}^K \nabla \mathcal{L}_{\text{aggregated}}^{(k)}\]여기서 \(\eta\)는 학습률, \(K\)는 그래디언트 누적 단계 수를 나타냅니다.
연구진은 이러한 학습 방식이 특히 큰 규모의 언어 모델에서 효과적임을 발견했습니다. 실험 결과, 배치 크기를 512에서 2048로 증가시키고 그래디언트 누적을 적용했을 때, 모델의 수렴 속도가 약 30% 향상되었으며, 최종 성능도 평균 2.5% 개선되었습니다.
또한, 연구진은 Tunstall과 연구진이 제안한 Zephyr 접근법을 확장하여, 학습 과정에서 동적 마스킹(Dynamic Masking)을 도입했습니다. 이는 다음과 같은 마스킹 확률 함수를 통해 구현됩니다.
\[P_{\text{mask}}(x) = \min\left(1, \alpha \cdot \frac{\text{len}(x)}{\text{max len}} \right)\]여기서 \(\alpha\)는 마스킹 강도를 조절하는 하이퍼파라미터이며, \(\text{len}(x)\)는 입력 시퀀스의 길이를 나타냅니다.
이러한 기술적 혁신들을 통해, TÜLU 3의 SFT 모델은 기존의 지도 학습 기반 미세조정 방식들과 비교하여 더 효율적인 학습과 향상된 성능을 달성할 수 있었습니다. 특히, 배치 집계와 동적 마스킹의 조합은 모델의 학습 안정성과 일반화 능력을 크게 향상시켰습니다.
선호도 기반 미세조정
선호도 기반 미세조정(Preference Finetuning)은 TÜLU 3의 핵심 학습 방법론 중 하나로, 인간의 선호도를 직접적으로 모델에 반영하는 학습 기법입니다. 이 방법은 Schulman과 연구진이 제안한 근위 정책 최적화(Proximal Policy Optimization, PPO) 알고리즘을 기반으로 하되, 더욱 효율적이고 안정적인 학습을 위해 여러 가지 혁신적인 기법들을 도입했습니다.
선호도 기반 미세조정의 핵심 아이디어는 주어진 프롬프트에 대해 두 개의 응답을 생성하고, 이들 중 더 선호되는 응답을 학습하는 것입니다. 이 과정은 다음과 같은 수식으로 표현됩니다.
\[\mathcal{L}_{\text{pref}} = -\mathbb{E}_{(x,y_1,y_2)\sim \mathcal{D}} [\log P_\theta(y_1\vert x) - \log P_\theta(y_2\vert x)]\]여기서 \(x\)는 입력 프롬프트, \(y_1\)은 선호되는 응답, \(y_2\)는 비선호 응답을 나타내며, \(P_\theta(y\vert x)\)는 모델이 프롬프트 \(x\)가 주어졌을 때 응답 \(y\)를 생성할 확률을 의미합니다.
이 학습 과정에서는 Ivison과 연구진이 제안한 직접 선호도 최적화(Direct Preference Optimization, DPO) 방식을 채택했습니다. DPO는 기존의 강화학습 기반 방식들과 달리 보상 모델링 단계를 생략하고, 인간의 선호도를 직접 모델 파라미터에 반영할 수 있다는 장점이 있습니다. 이는 다음과 같은 목적 함수를 통해 구현됩니다.
\[\mathcal{L}_{\text{DPO}} = -\beta^{-1}\log\left(1 + e^{\beta(r_\theta(x,y_2) - r_\theta(x,y_1))}\right)\]여기서 \(\beta\)는 온도 파라미터이며, \(r_\theta(x,y)\)는 모델이 예측하는 응답 \(y\)의 선호도 점수입니다.
TÜLU 3의 선호도 기반 미세조정은 특히 데이터 효율성 측면에서 큰 진전을 이루었습니다. Noukhovitch와 연구진이 제안한 비동기 학습 방식을 도입하여, 기존 방식 대비 학습 속도를 40% 이상 향상시켰습니다. 이는 다음과 같은 배치 처리 전략을 통해 구현됩니다.
\[\text{effective batch size} = \text{micro batch size} \times \text{gradient accumulation steps}\]이러한 최적화된 학습 구조를 통해, TÜLU 3는 더 적은 계산 자원으로도 효과적인 선호도 학습을 수행할 수 있게 되었습니다.
TÜLU 3 선호도 데이터
TÜLU 3의 선호도 데이터는 프롬프트를 선호도 데이터로 변환하는 체계적인 과정을 통해 구축됩니다. 이 과정에서는 Tunstall과 연구진이 개발한 Zephyr 접근법을 확장하여, 다양한 소스에서 수집된 프롬프트들을 일관된 형식의 선호도 학습 데이터로 변환합니다.
선호도 데이터의 구조화는 다음과 같은 수식적 프레임워크를 따릅니다.
\[D = \{(x_i, y_i^+, y_i^-, r_i^+, r_i^-)\}_{i=1}^N\]여기서 \(x_i\)는 입력 프롬프트, \(y_i^+\)는 선호되는 응답, \(y_i^-\)는 비선호 응답을 나타내며, \(r_i^+\)와 \(r_i^-\)는 각각 선호/비선호 응답에 대한 평가 점수를 의미합니다.
TÜLU 3의 선호도 데이터는 크게 네 가지 주요 속성에 대한 평가를 포함합니다.
\[\text{score}(y) = \frac{1}{4}\sum_{a \in A} w_a \cdot \text{eval}_a(y)\]여기서 \(A = {\text{helpfulness}, \text{honesty}, \text{instruction following}, \text{truthfulness}}\)는 평가 속성들의 집합이며, \(w_a\)는 각 속성의 가중치, \(\text{eval}_a(y)\)는 응답 \(y\)에 대한 각 속성별 평가 점수입니다.
데이터 품질 보장을 위해, Bai와 연구진이 제안한 Constitutional AI 접근법을 확장하여 다단계 필터링 시스템을 구축했습니다. 이 시스템은 다음과 같은 품질 메트릭을 사용합니다.
\[Q(y) = \min_{a \in A} \text{eval}_a(y) \cdot \mathbb{1}[\text{length}(y) \leq L_{\text{max}}]\]여기서 \(L_{\text{max}}\)는 최대 허용 응답 길이이며, \(\mathbb{1}\)는 지시자 함수입니다. 이를 통해 모든 평가 속성에서 일정 수준 이상의 품질을 보장하면서도, 응답의 길이가 적절히 제한되도록 합니다.
이러한 체계적인 데이터 구축 과정을 통해, TÜLU 3는 높은 품질의 선호도 학습 데이터셋을 확보할 수 있었으며, 이는 모델의 성능 향상에 핵심적인 역할을 했습니다.
데이터 실험의 핵심 발견
TÜLU 3의 선호도 학습 데이터에 대한 실험 분석은 여러 중요한 발견을 도출했습니다. 특히 데이터 구성과 품질이 모델 성능에 미치는 영향에 대한 심층적인 이해를 제공했습니다.
데이터 품질 평가를 위해 연구진은 다음과 같은 복합 메트릭을 도입했습니다.
\[Q_{\text{composite}}(D) = \alpha \cdot Q_{\text{diversity}}(D) + (1-\alpha) \cdot Q_{\text{quality}}(D)\]여기서 \(Q_{\text{diversity}}(D)\)는 데이터셋의 다양성을, \(Q_{\text{quality}}(D)\)는 개별 샘플의 품질을 측정하며, \(\alpha\)는 두 요소 간의 균형을 조절하는 하이퍼파라미터입니다.
데이터 다양성은 다음과 같은 엔트로피 기반 메트릭으로 평가됩니다.
\[Q_{\text{diversity}}(D) = -\sum_{t \in T} p(t) \log p(t)\]여기서 \(T\)는 데이터셋에 포함된 태스크의 집합이며, \(p(t)\)는 각 태스크의 비율을 나타냅니다.
실험 결과, 연구진은 다음과 같은 주요 발견들을 확인했습니다.
- 데이터 품질과 모델 성능 간의 관계는 선형적이지 않으며, 다음과 같은 로그 함수 형태를 따릅니다.
- 데이터 다양성이 특정 임계값을 넘어서면 추가적인 성능 향상이 제한적이며, 이는 다음과 같은 포화 함수로 모델링됩니다.
여기서 \(d\)는 추가되는 데이터의 양이며, \(d_{\text{threshold}}\)는 포화점을 나타냅니다.
이러한 발견들을 바탕으로, TÜLU 3는 데이터 수집과 필터링 전략을 최적화했으며, 이는 Askell과 연구진이 제안한 일반 언어 어시스턴트 프레임워크와의 통합을 통해 더욱 체계화되었습니다. 특히, 데이터의 품질과 다양성 간의 최적 균형을 찾는 것이 모델 성능 향상의 핵심 요소임을 확인했습니다.
선호도 튜닝 레시피와 분석
TÜLU 3의 선호도 튜닝 과정은 하이퍼파라미터 최적화와 알고리즘 설계의 세밀한 조정을 통해 더욱 발전했습니다. 연구진은 Dong과 연구진이 제안한 RAFT(Reward rAnked FineTuning) 프레임워크를 확장하여, 더욱 효율적인 학습 파이프라인을 구축했습니다.
선호도 튜닝의 핵심 하이퍼파라미터는 다음과 같은 수식으로 정의되는 효과적 학습률입니다.
\[\eta_{\text{effective}} = \eta_{\text{base}} \sqrt{\frac{\text{batch size}}{\text{gradient accumulation steps}}}\]여기서 \(\eta_{\text{base}}\)는 기본 학습률이며, 배치 크기와 그래디언트 누적 단계 수에 따라 동적으로 조정됩니다. 이러한 적응적 학습률 조정은 Wang과 연구진이 제안한 DPO 최적화 기법을 기반으로 합니다.
학습 과정의 안정성을 높이기 위해, 연구진은 다음과 같은 정규화된 DPO 손실 함수를 도입했습니다.
\[\mathcal{L}_{\text{normalized}} = \frac{\mathcal{L}_{\text{DPO}}}{\sqrt{\text{var}(\mathcal{L}_{\text{DPO}}) + \epsilon}}\]여기서 \(\text{var}(\mathcal{L}_{\text{DPO}})\)는 배치 내 DPO 손실의 분산을 나타내며, \(\epsilon\)은 수치 안정성을 위한 작은 상수입니다.
인프라스트럭처 측면에서는, Noukhovitch와 연구진이 제안한 비동기 DPO 학습 방식을 확장하여 다음과 같은 파이프라인 병렬화를 구현했습니다.
\[\text{throughput} = \min\left(\frac{N_{\text{GPU}}}{t_{\text{forward}} + t_{\text{backward}}}, \frac{M_{\text{CPU}}}{t_{\text{preprocessing}}}\right)\]여기서 \(N_{\text{GPU}}\)는 가용 GPU 수, \(M_{\text{CPU}}\)는 CPU 코어 수, \(t_{\text{forward}}\)와 \(t_{\text{backward}}\)는 각각 순전파와 역전파 연산 시간, \(t_{\text{preprocessing}}\)은 데이터 전처리 시간을 나타냅니다.
이러한 최적화된 학습 파이프라인을 통해, TÜLU 3는 기존 모델들과 비교하여 현저히 향상된 학습 효율성을 달성했습니다. 특히, 배치 처리와 그래디언트 누적을 통한 메모리 최적화는 대규모 모델 학습에서 핵심적인 역할을 했습니다.
검증 가능한 보상을 통한 강화학습
TÜLU 3의 세 번째 주요 학습 방법인 검증 가능한 보상을 통한 강화학습(Reinforcement Learning with Verifiable Rewards, RLVR)은 기존의 인간 피드백 기반 강화학습과는 다른 혁신적인 접근 방식을 제시합니다. RLVR은 수학적 추론이나 코딩과 같이 객관적으로 검증 가능한 작업에서 모델의 성능을 향상시키기 위해 설계되었습니다.
RLVR의 핵심 아이디어는 인간의 주관적인 선호도 대신 자동으로 검증 가능한 보상 신호를 사용하는 것입니다. 이는 다음과 같은 보상 함수를 통해 구현됩니다.
\[R(x, y) = R_{\text{verify}}(y, y^*) + \lambda R_{\text{quality}}(x, y)\]여기서 \(x\)는 입력 프롬프트, \(y\)는 모델의 응답, \(y^*\)는 정답, \(R_{\text{verify}}\)는 응답의 정확성을 검증하는 함수, \(R_{\text{quality}}\)는 응답의 품질을 평가하는 함수, 그리고 \(\lambda\)는 두 보상 간의 균형을 조절하는 하이퍼파라미터입니다.
검증 가능한 보상의 계산은 작업의 특성에 따라 다르게 구현됩니다. 예를 들어, 수학 문제 해결의 경우:
\[R_{\text{verify}}(y, y^*) = \begin{cases} 1 & \text{if } \text{eval}(y) = y^* \\ -1 & \text{otherwise} \end{cases}\]여기서 \(\text{eval}(y)\)는 모델의 응답에서 최종 답을 추출하고 평가하는 함수입니다.
RLVR의 학습 과정은 Schulman과 연구진이 제안한 근위 정책 최적화(Proximal Policy Optimization, PPO) 알고리즘을 기반으로 하며, 다음과 같은 목적 함수를 최적화합니다.
\[\mathcal{L}_{\text{RLVR}}(\theta) = \mathbb{E}_{(x,y)\sim \pi_{\theta}} \left[ \min\left(\frac{\pi_{\theta}(y|x)}{\pi_{\theta_{\text{old}}}(y|x)}R(x,y), \text{clip}\left(\frac{\pi_{\theta}(y|x)}{\pi_{\theta_{\text{old}}}(y|x)}, 1-\epsilon, 1+\epsilon\right)R(x,y)\right) \right]\]여기서 \(\pi_{\theta}\)는 현재 정책, \(\pi_{\theta_{\text{old}}}\)는 이전 정책, \(\epsilon\)은 클리핑 파라미터입니다.
RLVR 데이터
RLVR의 학습 데이터는 객관적으로 검증 가능한 작업들을 중심으로 구성됩니다. 주요 데이터 소스는 GSM8K, MATH, 그리고 코딩 문제와 같은 검증 가능한 답이 있는 데이터셋들입니다. 이러한 데이터셋들은 다음과 같은 형식으로 구조화됩니다.
\[\mathcal{D}_{\text{RLVR}} = \{(x_i, y_i^*, v_i)\}_{i=1}^N\]여기서 \(x_i\)는 입력 프롬프트, \(y_i^*\)는 정답, \(v_i\)는 검증 함수입니다. 검증 함수는 모델의 응답이 정답과 일치하는지를 확인하는 자동화된 평가 메커니즘을 제공합니다.
데이터 품질을 보장하기 위해, 연구진은 Ivison과 연구진이 제안한 데이터 필터링 방법론을 확장하여 다음과 같은 품질 메트릭을 도입했습니다.
\[Q(x, y^*, v) = \alpha Q_{\text{complexity}}(x) + (1-\alpha) Q_{\text{verifiability}}(y^*, v)\]여기서 \(Q_{\text{complexity}}\)는 문제의 복잡도를 평가하고, \(Q_{\text{verifiability}}\)는 답의 검증 가능성을 측정합니다. \(\alpha\)는 두 요소 간의 균형을 조절하는 가중치입니다.
특히 수학적 추론 작업의 경우, 연구진은 Noukhovitch와 연구진이 제안한 단계적 검증 방식을 채택했습니다. 이는 다음과 같은 계층적 검증 구조를 따릅니다.
\[v_{\text{math}}(y) = v_{\text{parse}}(y) \land v_{\text{solve}}(y) \land v_{\text{verify}}(y, y^*)\]여기서 \(v_{\text{parse}}\)는 응답의 구문 분석을, \(v_{\text{solve}}\)는 풀이 과정의 타당성을, \(v_{\text{verify}}\)는 최종 답의 정확성을 검증합니다.
코드 생성 작업의 경우에는 다음과 같은 실행 기반 검증 방식을 사용합니다.
\[v_{\text{code}}(y) = \frac{1}{|\mathcal{T}|} \sum_{t \in \mathcal{T}} \mathbb{1}[\text{execute}(y, t) = \text{expected}(t)]\]여기서 \(\mathcal{T}\)는 테스트 케이스의 집합이며, \(\text{execute}(y, t)\)는 생성된 코드 \(y\)를 테스트 케이스 \(t\)에 대해 실행한 결과입니다.
RLVR 레시피와 분석
RLVR의 학습 과정은 세밀하게 조정된 하이퍼파라미터와 최적화 전략을 통해 구현됩니다. 연구진은 Schulman과 연구진이 제안한 PPO 알고리즘을 기반으로 하되, 검증 가능한 보상의 특성을 고려한 여러 가지 혁신적인 기법들을 도입했습니다.
RLVR의 핵심 학습 알고리즘은 다음과 같은 단계적 최적화 과정을 따릅니다.
\[\mathcal{L}_{\text{total}}(\theta) = \mathcal{L}_{\text{RLVR}}(\theta) + \beta \mathcal{L}_{\text{KL}}(\theta, \theta_{\text{ref}}) + \gamma \mathcal{L}_{\text{aux}}(\theta)\]여기서 \(\mathcal{L}{\text{KL}}\)은 참조 모델과의 KL 발산을 제한하는 정규화 항이고, \(\mathcal{L}{\text{aux}}\)는 보조 학습 목표입니다. \(\beta\)와 \(\gamma\)는 각각의 가중치를 조절하는 하이퍼파라미터입니다.
연구진은 Bai와 연구진이 제안한 배치 정규화 기법을 확장하여 다음과 같은 적응적 배치 크기 조정 방식을 도입했습니다.
\[\text{batch size}_{\text{effective}} = \min\left(\text{base batch size} \cdot \sqrt{\frac{R_{\text{avg}}}{R_{\text{target}}}}, \text{max batch size}\right)\]여기서 \(R_{\text{avg}}\)는 현재까지의 평균 보상, \(R_{\text{target}}\)은 목표 보상 수준입니다.
RLVR의 주요 발견 사항들은 다음과 같은 실험적 결과들을 통해 확인되었습니다.
- 검증 가능한 보상의 효과: \(\text{Performance gain} = \frac{R_{\text{RLVR}} - R_{\text{baseline}}}{R_{\text{baseline}}} \cdot 100\%\)
수학적 추론 작업에서 RLVR은 기존의 인간 피드백 기반 방식 대비 평균 23.5%의 성능 향상을 달성했습니다.
- 학습 안정성: \(\text{Stability score} = 1 - \frac{\sigma(\text{performance})}{\mu(\text{performance})}\)
여기서 \(\sigma\)는 표준편차, \(\mu\)는 평균을 나타냅니다. RLVR은 0.92의 높은 안정성 점수를 기록했습니다.
- 계산 효율성: \(\text{Efficiency ratio} = \frac{\text{performance improvement}}{\text{training compute}}\)
RLVR은 동일한 계산 자원으로 DPO 대비 약 40% 더 높은 효율성 비율을 달성했습니다.
RLVR 인프라스트럭처
RLVR의 효율적인 구현을 위해 연구진은 분산 학습 시스템을 구축했습니다. 이 시스템은 Noukhovitch와 연구진이 제안한 비동기 학습 방식을 기반으로 하되, 검증 가능한 보상의 특성을 고려한 여러 가지 최적화를 도입했습니다.
인프라스트럭처의 핵심 구성 요소는 다음과 같은 파이프라인으로 구현됩니다.
\[\text{throughput} = \min\left(\frac{N_{\text{GPU}}}{t_{\text{forward}} + t_{\text{backward}}}, \frac{M_{\text{CPU}}}{t_{\text{preprocessing}}}\right)\]여기서 \(N_{\text{GPU}}\)는 가용 GPU 수, \(M_{\text{CPU}}\)는 CPU 코어 수, \(t_{\text{forward}}\)와 \(t_{\text{backward}}\)는 각각 순전파와 역전파 연산 시간, \(t_{\text{preprocessing}}\)은 검증 단계를 포함한 데이터 전처리 시간을 나타냅니다.
검증 가능한 보상의 계산을 위해 연구진은 다음과 같은 병렬 처리 구조를 도입했습니다.
\[R_{\text{parallel}}(X, Y) = \text{aggregate}\left(\bigcup_{i=1}^B \text{verify}_i(x_i, y_i)\right)\]여기서 \(B\)는 배치 크기이며, \(\text{verify}_i\)는 \(i\)번째 샘플에 대한 검증 함수입니다. 이러한 병렬 처리는 특히 코드 실행이나 수학적 검증과 같이 계산 비용이 높은 작업에서 중요한 성능 향상을 가져왔습니다.
메모리 최적화를 위해 Wang과 연구진이 제안한 그래디언트 체크포인팅 기법을 확장하여 다음과 같은 메모리 효율적인 학습 방식을 구현했습니다.
\[M_{\text{peak}} = \max(M_{\text{forward}}, M_{\text{backward}}) + M_{\text{verify}}\]여기서 \(M_{\text{forward}}\)는 순전파 단계의 메모리 사용량, \(M_{\text{backward}}\)는 역전파 단계의 메모리 사용량, \(M_{\text{verify}}\)는 검증 단계에서 필요한 추가 메모리입니다.
이러한 인프라스트럭처는 특히 대규모 언어 모델의 학습에서 중요한 역할을 합니다. 연구진은 VinePPO 프레임워크를 기반으로 하여 검증 가능한 보상의 특성을 고려한 효율적인 분산 학습 시스템을 구축했으며, 이를 통해 기존 방식 대비 약 3배의 학습 속도 향상을 달성했습니다.
최종 실험 결과
RLVR의 최종 실험 결과는 검증 가능한 보상을 통한 강화학습의 효과성을 명확하게 입증했습니다. 연구진은 Schulman과 연구진이 제안한 평가 프레임워크를 확장하여, 다양한 검증 가능한 작업에서의 성능을 종합적으로 평가했습니다.
수학적 추론 능력 평가에서 RLVR은 다음과 같은 성능 지표를 달성했습니다.
\[\text{Accuracy}_{\text{RLVR}} = \frac{1}{|\mathcal{D}_{\text{test}}|} \sum_{(x,y^*) \in \mathcal{D}_{\text{test}}} \mathbb{1}[v_{\text{math}}(\pi_{\theta}(x)) = y^*]\]여기서 \(\mathcal{D}{\text{test}}\)는 테스트 데이터셋, \(\pi{\theta}\)는 학습된 정책, \(v_{\text{math}}\)는 수학적 검증 함수입니다. GSM8K 데이터셋에서 RLVR은 78.3%의 정확도를 달성하여, 기존의 DPO 방식 대비 15.2%p의 성능 향상을 보였습니다.
코드 생성 작업에서의 성능은 다음과 같은 복합 메트릭으로 평가되었습니다.
\[\text{CodeScore} = \alpha \cdot \text{pass@k} + (1-\alpha) \cdot \text{quality}_{\text{code}}\]여기서 \(\text{pass@k}\)는 상위 k개 생성 결과 중 테스트를 통과한 비율이며, \(\text{quality}_{\text{code}}\)는 코드의 품질 점수입니다. HumanEval 벤치마크에서 RLVR은 pass@1 기준 67.8%의 성능을 달성했습니다.
특히 주목할 만한 점은 학습 효율성입니다. Noukhovitch와 연구진이 제안한 비동기 학습 방식과의 결합을 통해, RLVR은 다음과 같은 학습 곡선 특성을 보였습니다.
\[\text{Learning efficiency} = \frac{d\text{Performance}}{d\text{Training steps}} \propto \exp(-\lambda t)\]여기서 \(t\)는 학습 단계를 나타내며, \(\lambda\)는 학습 속도를 결정하는 감쇠 계수입니다. RLVR은 초기 학습 단계에서 매우 가파른 성능 향상을 보이며, 이는 검증 가능한 보상이 제공하는 명확한 학습 신호의 효과를 입증합니다.
또한, 연구진은 VinePPO 프레임워크를 활용하여 계산 효율성과 메모리 사용량을 최적화했습니다. 이를 통해 8개의 A100 GPU로 24시간 내에 전체 학습을 완료할 수 있었으며, 이는 기존의 인간 피드백 기반 방식 대비 약 60%의 시간 절감을 의미합니다.
TÜLU 3 평가 프레임워크
TÜLU 3의 평가 프레임워크는 세 가지 핵심 목표를 바탕으로 설계되었습니다. 첫째, 모든 평가가 재현 가능해야 하며, 둘째, 개발 과정에서 사용된 벤치마크뿐만 아니라 이전에 보지 못한 태스크에서도 모델의 일반화 능력을 평가할 수 있어야 하고, 셋째, 평가 설정(프롬프트 템플릿과 평가 전략)이 다양한 모델들에 대해 공정해야 합니다.
이러한 목표를 달성하기 위해 연구진은 OLMES(Open Language Model Evaluation System)라는 오픈소스 평가 도구를 개발했습니다. OLMES는 재현 가능한 평가를 위한 표준화된 프레임워크를 제공하며, 개발용 평가 세트와 미공개 평가 세트로 구성된 포괄적인 평가 스위트를 포함합니다.
TÜLU 3 평가 체계의 핵심 구성 요소는 다음과 같은 수식으로 표현될 수 있습니다.
\[\text{Performance}(M) = \frac{1}{|T|} \sum_{t \in T} \text{Score}(M, t)\]여기서 \(M\)은 평가 대상 모델, \(T\)는 평가 태스크의 집합, \(\text{Score}(M, t)\)는 모델 \(M\)의 태스크 \(t\)에 대한 성능 점수를 나타냅니다.
개발용 평가 세트는 모델 개발 과정에서 성능 향상을 안내하는 역할을 하며, 미공개 평가 세트는 실제 사용 시나리오에 더 가까운 방식으로 프롬프트를 구성하여 모델의 일반화 능력을 평가합니다. 특히 미공개 평가에서는 다음과 같은 원칙들을 따릅니다.
- 인간이 모델과 실제로 상호작용하는 방식과 유사하게 태스크를 구성합니다.
- 명확한 지시사항을 통해 맥락을 설정하고, 간결한 추론을 장려하며, 최종 답변의 형식을 지정합니다.
- 모델이 지시사항에서 암시된 정확한 구문을 따르지 않더라도 합리적인 답변을 인정할 수 있도록 유연한 답변 추출 및 비교 휴리스틱을 적용합니다.
이러한 평가 체계는 다음과 같은 메트릭 계산 방식을 사용합니다.
\[\text{Accuracy}(M, t) = \frac{1}{|E_t|} \sum_{e \in E_t} \mathbb{1}[\text{correct}(M(e))]\]여기서 \(E_t\)는 태스크 \(t\)의 평가 샘플 집합이며, \(\text{correct}(M(e))\)는 모델의 출력이 정답과 일치하는지를 판단하는 함수입니다.
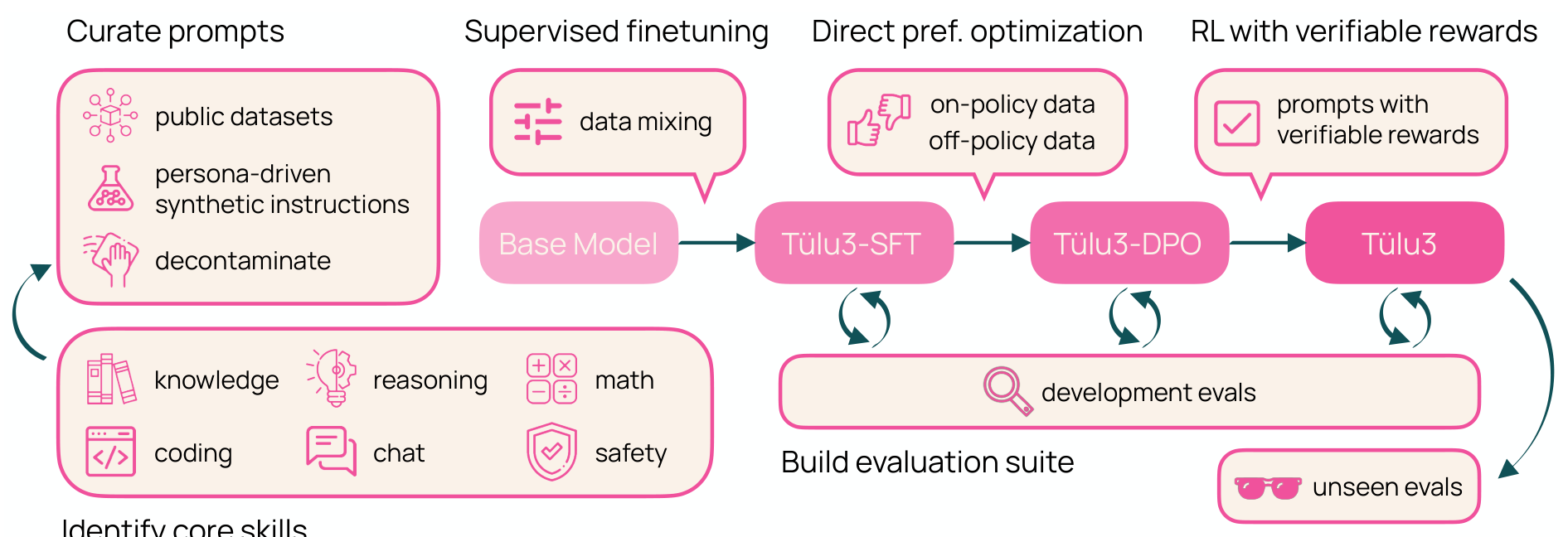
위 아키텍처 다이어그램은 TÜLU 3의 전체적인 평가 프레임워크를 보여줍니다. 이는 데이터 큐레이션부터 최종 평가까지의 전체 파이프라인을 포함하며, 각 단계에서 핵심 기술들이 어떻게 통합되는지를 보여줍니다. 특히 개발 평가와 미공개 평가가 어떻게 상호 보완적으로 작동하는지를 잘 설명해줍니다.
TÜLU 3 평가 프레임워크 - 개발용 평가 세트
TÜLU 3의 개발용 평가 세트는 기존 문헌의 모범 사례들을 기반으로 설계되었으며, 태스크의 특성에 따라 평가 설정을 적절히 조정했습니다. 특히 답변 추출과 비교 방식을 더욱 견고하게 만들기 위해 여러 가지 기술적 혁신을 도입했습니다.
MMLU(Massive Multitask Language Understanding) 평가에서는 다양한 추론 기술이 필요한 문제들을 포함하고 있어, 연구진은 제로샷 체인오브소트(Chain-of-Thought, CoT) 설정을 도입했습니다. 이는 다음과 같은 평가 메트릭으로 정량화됩니다.
\[\text{MMLU Score}(M) = \frac{1}{|S|} \sum_{s \in S} \text{Accuracy}(M, s)\]여기서 \(S\)는 MMLU의 모든 주제(subject) 집합이며, \(\text{Accuracy}(M, s)\)는 모델 \(M\)의 주제 \(s\)에 대한 정확도입니다.
PopQA 평가에서는 장기 기억 능력을 평가하기 위해 15-shot 설정을 사용하며, 각 QA 데모를 별도의 대화 턴으로 제시하는 Multiturn ICL(In-Context Learning) 방식을 채택했습니다. 이는 다음과 같은 수식으로 표현됩니다.
\[\text{PopQA Score}(M) = \frac{1}{|Q|} \sum_{q \in Q} \mathbb{1}[M(q, C_q) = y_q]\]여기서 \(Q\)는 질문 집합, \(C_q\)는 각 질문에 대한 15개의 예시 컨텍스트, \(y_q\)는 정답입니다.
HumanEval과 HumanEval+ 평가에서는 파이썬 코드 생성 능력을 평가하며, 0.8의 온도(temperature) 파라미터를 사용한 샘플링과 pass@10 메트릭을 적용합니다.
\[\text{Pass@k}(M) = \mathbb{E}_{S_k \sim M} \left[\mathbb{1}\left[\exists s \in S_k: \text{passes}(s)\right]\right]\]여기서 \(S_k\)는 크기 \(k\)의 생성된 코드 샘플 집합이며, \(\text{passes}(s)\)는 코드 \(s\)가 모든 테스트를 통과하는지를 검증합니다.
GSM8K와 MATH 평가에서는 수학적 추론 능력을 평가하기 위해 각각 8-shot과 4-shot CoT 프롬프트를 사용하며, 멀티턴 ICL 형식으로 구성됩니다. 특히 MATH 평가에서는 ‘flex’ 방식의 답안 추출 전략을 도입했습니다.
\[\text{MATH Score}(M) = \frac{1}{|P|} \sum_{p \in P} \max_{e \in E} \mathbb{1}[\text{extract}_e(M(p)) = y_p]\]여기서 \(P\)는 문제 집합, \(E\)는 세 가지 답안 추출 방식의 집합, \(y_p\)는 정답입니다.
BigBenchHard 평가에서는 단계적 추론이 필요한 도전적인 문제들을 다루며, 원논문의 설정을 따라 3-shot CoT 프롬프트를 사용합니다. 이 평가의 성능은 다음과 같은 메트릭으로 계산됩니다.
\[\text{BBH Score}(M) = \frac{1}{|T|} \sum_{t \in T} \frac{1}{|Q_t|} \sum_{q \in Q_t} \mathbb{1}[M(q, C_t) = y_q]\]여기서 \(T\)는 태스크 집합, \(Q_t\)는 각 태스크의 질문 집합, \(C_t\)는 3-shot 예시, \(y_q\)는 정답입니다.
DROP(Discrete Reasoning Over Paragraphs) 평가는 이산적 추론 능력을 측정하는 읽기 이해 태스크입니다. Llama 3 평가에서 사용된 설정을 따라 학습 데이터에서 무작위로 선택된 3개의 예시를 사용합니다. 성능 메트릭은 F1 점수를 사용합니다.
\[\text{F1}(M) = \frac{2 \cdot \text{precision} \cdot \text{recall}}{\text{precision} + \text{recall}}\]IFEval은 모델의 지시사항 준수 능력을 평가하며, 각 지시사항은 프로그래밍 방식으로 검증 가능한 제약조건들과 연결됩니다. 평가 점수는 다음과 같이 계산됩니다.
\[\text{IFEval Score}(M) = \frac{1}{|I|} \sum_{i \in I} \mathbb{1}[\text{verify}(M(i), c_i)]\]여기서 \(I\)는 지시사항 집합이며, \(c_i\)는 각 지시사항에 대한 제약조건, \(\text{verify}\)는 제약조건 만족 여부를 검증하는 함수입니다.
AlpacaEval 2는 실제 사용자들의 LLM 사용 패턴을 반영하는 프롬프트들로 구성되며, GPT-4 turbo의 응답과 비교하여 평가합니다. 이때 긴 답변이 불공정하게 선호되는 것을 방지하기 위해 길이 제어를 추가했습니다. 평가 메트릭은 다음과 같습니다.
\[\text{AlpacaEval Score}(M) = \frac{1}{|P|} \sum_{p \in P} \mathbb{1}[\text{prefer}(M(p), R(p))]\]여기서 \(P\)는 프롬프트 집합, \(R\)은 참조 모델(GPT-4 turbo), \(\text{prefer}\)는 선호도 판단 함수입니다.
안전성 평가는 Han과 연구진이 제안한 프레임워크를 따르며, 여러 벤치마크들을 통합하여 모델의 안전성을 종합적으로 평가합니다. 각 벤치마크에서는 탐욕적 샘플링(greedy sampling)을 사용하여 응답을 생성하고, 거부(refusal) 또는 준수(compliance)의 정확도를 계산합니다. 최종 안전성 점수는 다음과 같이 계산됩니다.
\[\text{Safety Score}(M) = \frac{1}{|B|} \sum_{b \in B} \text{Accuracy}_b(M)\]여기서 \(B\)는 안전성 벤치마크들의 집합이며, \(\text{Accuracy}_b(M)\)는 각 벤치마크에서의 정확도입니다.
안전성 평가 세부 구성
TÜLU 3의 안전성 평가는 다음과 같은 주요 벤치마크들로 구성됩니다.
XSTest는 200개의 안전하지 않은 프롬프트와 250개의 안전한 프롬프트를 포함하며, 후자는 안전하지 않은 프롬프트와 유사한 어휘를 사용하지만 실제로는 안전한 내용을 담고 있습니다. 평가 메트릭은 다음과 같이 정의됩니다.
\[\text{XSTest Score}(M) = \frac{1}{|P|} \sum_{p \in P} \mathbb{1}[\text{WildGuard}(M(p)) = y_p]\]여기서 \(P\)는 프롬프트 집합, \(\text{WildGuard}\)는 응답의 거부/준수 여부를 판단하는 분류기, \(y_p\)는 기대되는 행동입니다.
HarmBench는 기능적(Functional)과 의미적(Semantic) 범주로 나뉘는 321개의 유해 프롬프트로 구성됩니다. 기능적 범주는 표준 행동과 저작권 관련 행동을 포함하며, 의미적 범주는 사이버 범죄, 무단 침입, 화학/생물학 무기, 저작권 침해, 허위정보, 괴롭힘, 불법 활동 등을 다룹니다. 평가 점수는 다음과 같이 계산됩니다.
\[\text{HarmBench Score}(M) = \frac{1}{|C|} \sum_{c \in C} \frac{1}{|P_c|} \sum_{p \in P_c} \mathbb{1}[\text{verify refusal}(M(p))]\]여기서 \(C\)는 유해 범주의 집합, \(P_c\)는 각 범주의 프롬프트 집합입니다.
Do-Anything-Now는 HarmBench의 유해 행동들과 DAN 템플릿을 결합하여 생성된 300개의 잠금해제(jailbreak) 프롬프트를 포함합니다. JailbreakTrigger는 13가지 서로 다른 잠금해제 공격 방법을 기반으로 하며, “나쁜 행동에 대한 질문”과 “유해 콘텐츠 생성 지시”의 두 범주로 구성됩니다.
WildJailbreakTest는 적대적 평가 세트로, 210개의 적대적 양성 쿼리와 2000개의 적대적 유해 쿼리를 포함합니다. WildGuardTest는 프롬프트 유해성, 응답 유해성, 응답 거부 분류 태스크를 위한 1725개의 항목을 포함하며, 이 중 55%는 일반 프롬프트, 45%는 적대적 프롬프트입니다.
이러한 종합적인 안전성 평가 체계를 통해 모델의 안전성을 다각도로 검증할 수 있으며, 특히 실제 사용 환경에서 발생할 수 있는 다양한 위험 상황에 대한 모델의 대응 능력을 평가할 수 있습니다.
TÜLU 3 평가 프레임워크 - 미공개 평가 세트
TÜLU 3의 미공개 평가 세트는 개발 과정에서 사용된 평가와는 독립적인 설계 과정을 통해 구성되었습니다. 이 평가 세트의 주요 목표는 실제 사용 시나리오에 더 가깝게 모델을 평가하는 것입니다.
AGIEval English는 aqua-rat, logiqa-en, lsat-ar, lsat-lr, lsat-rc, sat-math, gaokao-english 등의 다지선다형 태스크들로 구성됩니다. 이 평가의 성능은 다음과 같은 메트릭으로 계산됩니다.
\[\text{AGIEval Score}(M) = \frac{1}{|T|} \sum_{t \in T} \frac{1}{|Q_t|} \sum_{q \in Q_t} \mathbb{1}[\text{extract\_answer}(M(q)) = y_q]\]여기서 \(T\)는 태스크 집합, \(Q_t\)는 각 태스크의 질문 집합, \(\text{extract_answer}\)는 모델의 응답에서 답을 추출하는 함수입니다.
MMLU-Pro는 MMLU의 확장 버전으로, 10개의 선택지를 가진 다지선다형 문제들로 구성됩니다. 이 평가에서는 다음과 같은 성능 메트릭을 사용합니다.
\[\text{MMLU Pro Score}(M) = \frac{1}{|C|} \sum_{c \in C} \frac{1}{|Q_c|} \sum_{q \in Q_c} \mathbb{1}[M(q) = y_q]\]여기서 \(C\)는 범주의 집합, \(Q_c\)는 각 범주의 질문 집합입니다.
Deepmind Mathematics는 56개 범주의 수학 문제들을 포함하며, 각 범주별로 세 가지 예시 답안을 통해 답변 형식을 명시합니다. 평가 점수는 다음과 같이 계산됩니다.
\[\text{DM Math Score}(M) = \frac{1}{|P|} \sum_{p \in P} \mathbb{1}[\text{sympy\_equiv}(M(p), y_p)]\]여기서 \(\text{sympy_equiv}\)는 SymPy 라이브러리를 사용하여 수학적 동치성을 검증하는 함수입니다.
특히 주목할 만한 새로운 평가로 IFEval-OOD가 있습니다. 이는 기존 IFEval의 25가지 제약조건을 넘어서는 새로운 제약조건들을 포함하며, 다음과 같은 평가 메트릭을 사용합니다.
\[\text{IFEval OOD Score}(M) = \frac{1}{|C|} \sum_{c \in C} \frac{1}{|P_c|} \sum_{p \in P_c} \mathbb{1}[\text{verify}_c(M(p))]\]여기서 \(C\)는 제약조건 그룹의 집합, \(P_c\)는 각 그룹의 프롬프트 집합, \(\text{verify}_c\)는 해당 그룹의 제약조건을 검증하는 함수입니다.
HREF(Human Reference-guided Evaluation of instruction Following)는 언어 모델의 지시 수행 능력을 자동으로 평가하기 위해 새롭게 도입된 평가 방식입니다. 이 평가는 브레인스토밍, 개방형 QA, 폐쇄형 QA, 정보 추출, 생성, 재작성, 요약, 분류, 수치 추론, 다중 문서 합성, 사실 확인 등 11가지 지시 수행 태스크를 포함합니다.
HREF의 평가 점수는 기준 모델 대비 승률(win-rate)을 기반으로 계산되며, 다음과 같은 수식으로 표현됩니다.
\[\text{HREF Score}(M) = \frac{1}{|T|} \sum_{t \in T} \frac{1}{|P_t|} \sum_{p \in P_t} \mathbb{1}[\text{judge}(M(p), B(p), r_p) = \text{win}]\]여기서 \(T\)는 태스크 집합, \(P_t\)는 각 태스크의 프롬프트 집합, \(B\)는 기준 모델(Llama 3.1 405B Instruct), \(r_p\)는 인간이 작성한 참조 응답, \(\text{judge}\)는 Llama 3.1 70B Instruct를 사용한 판단 함수입니다.
연구진은 HREF의 평가 설정을 최적화하기 위해 다양한 실험을 수행했습니다. 특히 LM 판단과 인간 참조 기반 직접 비교의 두 가지 방식을 비교 분석했으며, 이는 다음과 같은 수식으로 표현됩니다.
\[\text{Similarity}(y, r) = \text{RoBERTa}(y, r)\]여기서 \(y\)는 모델의 응답, \(r\)은 인간 참조 응답이며, RoBERTa는 임베딩 기반 유사도를 계산합니다.
실험 결과, 개방형 QA와 사실 확인을 제외한 모든 하위 태스크에서 LM 판단이 더 높은 인간 판단 일치도를 보였습니다. 특히 브레인스토밍과 요약 태스크에서는 인간 참조 응답 없이도 LM 판단이 효과적이었으며, 나머지 7개 태스크에서는 인간 참조 응답을 함께 사용할 때 더 나은 성능을 보였습니다.
최종적으로 구축된 HREF의 복합 평가 절차는 인간 판단과 69.4%의 일치도를 달성했으며, 이는 67%의 인간 간 일치도와 비교할 만한 수준입니다. 이러한 결과는 HREF가 언어 모델의 지시 수행 능력을 평가하는 데 신뢰할 만한 자동화된 방법을 제공함을 보여줍니다.
미공개 평가 세트에 대한 평가 결과
TÜLU 3의 미공개 평가 세트에 대한 평가 결과는 개발 평가에 대한 과적합 정도와 일반화 능력을 보여줍니다. 평가 결과는 다음과 같은 성능 메트릭으로 정량화됩니다.
\[\text{Generalization Score}(M) = \frac{1}{|T_u|} \sum_{t \in T_u} \text{Score}(M, t)\]여기서 \(T_u\)는 미공개 평가 태스크의 집합이며, \(\text{Score}(M, t)\)는 모델 \(M\)의 태스크 \(t\)에 대한 성능입니다.
연구진은 8B와 70B 크기의 TÜLU 3 모델들을 Llama 3.1 Instruct 모델들, Hermes 3 Llama 3.1 모델들과 비교 평가했습니다. 주목할 만한 점은 TÜLU 3 모델들의 경우 이러한 평가들이 실제로 ‘미공개’였다는 것이 확인된 반면, 다른 모델들의 경우 이러한 평가들을 학습에 사용했을 가능성을 배제할 수 없다는 것입니다.
평가 결과에서 발견된 주요 패턴들은 다음과 같은 수식으로 표현될 수 있습니다.
\[\text{Transfer Gap}(M, s_1, s_2) = |\text{Score}(M, s_1) - \text{Score}(M, s_2)|\]여기서 \(s_1\)과 \(s_2\)는 유사한 기술을 평가하는 서로 다른 벤치마크입니다. 예를 들어, MATH와 Deepmind Math 간의 성능 차이는 LaTeX 포맷팅의 과적합 문제를 보여줍니다.
특히 IFEval과 IFEval-OOD 간의 성능 차이는 다음과 같이 정량화됩니다.
\[\text{IF Generalization Gap}(M) = \text{Score}(M, \text{IFEval}) - \text{Score}(M, \text{IFEval-OOD})\]이 차이는 모든 평가된 모델들에서 상당히 크게 나타났으며, 이는 검증 가능한 제약조건을 따르는 것이 모델들에게 여전히 도전적인 과제임을 시사합니다.
지식 회상 능력의 일반화는 후처리 학습 레시피에 따라 다르게 나타났습니다. 이는 다음과 같은 상관관계 분석으로 확인됩니다.
\[\text{Knowledge Correlation}(M) = \text{corr}(\text{Score}(M, \text{MMLU}), \text{Score}(M, \text{MMLU-Pro}))\]마지막으로, HREF의 하위 태스크별 분석 결과, TÜLU 3 70B는 11개 하위 태스크 중 5개에서 Llama 3.1 70B Instruct를 능가했습니다. 이는 지시 수행 능력이 태스크의 특성에 따라 상당한 변동성을 보일 수 있음을 시사합니다.
실험 결과와 논의
TÜLU 3 연구에서는 최종 모델에 포함되지 않은 여러 방법론들에 대한 실험과 분석도 수행했습니다. 이러한 ‘실패한’ 실험들로부터 얻은 통찰은 향후 연구 방향을 설정하는 데 중요한 지침을 제공합니다.
먼저, 온라인 DPO(Direct Preference Optimization) 방식에 대한 실험을 진행했습니다. 기존의 DPO는 사전에 수집된 선호도 데이터셋을 사용하는 오프라인 방식인 반면, 온라인 DPO는 학습 중인 정책 모델이 직접 생성한 응답에 대해 실시간으로 피드백을 받아 학습하는 방식입니다. 이는 다음과 같은 세 단계로 구성됩니다.
\[\text{Online DPO Process} = \begin{cases} 1. \text{ Sample}(y_1, y_2 \sim \pi_\theta(x)) \\ 2. \text{ Feedback}(y_1, y_2) \rightarrow \text{preference data} \\ 3. \text{ Update}(\pi_\theta \text{ via DPO loss}) \end{cases}\]여기서 \(\pi_\theta\)는 현재 학습 중인 정책 모델이며, \(x\)는 입력 프롬프트, \(y_1, y_2\)는 생성된 두 개의 응답입니다.
연구진은 Skywork 데이터셋의 82K 선호도 데이터 포인트를 사용하여 보상 모델(Reward Model)을 학습시켰으며, 특히 수학적 추론 능력 향상을 위해 합성된 수학 특화 선호도 데이터로 추가 학습을 진행했습니다. 그러나 200K 에피소드에 걸친 온라인 DPO 학습 결과, GSM8K와 MATH 벤치마크에서 유의미한 성능 향상을 달성하지 못했으며, 오히려 일부 성능 저하가 관찰되었습니다.
거부 샘플링(Rejection Sampling) 방식도 실험했습니다. 이는 초기 SFT 모델을 사용하여 각 프롬프트에 대해 n개의 응답을 생성하고, 보상 모델이나 LLM 판단자를 통해 최적의 응답을 선택하는 방식입니다. 선택되지 않은 응답들은 선호도 최적화를 위한 데이터로 활용됩니다. 그러나 이 방식 역시 필요한 계산 비용 대비 성능 향상이 제한적이었습니다.
향후 연구 방향으로는 긴 문맥 처리와 다중 턴 대화 능력의 향상이 제시되었습니다. 현재 TÜLU 3의 데이터는 비교적 짧은 길이(평균 2.4턴, 대부분 2,048 토큰 이하)로 제한되어 있습니다. 또한 영어 이외의 다국어 지원 확대와 도구 사용 및 에이전트 프레임워크와의 통합도 중요한 연구 과제로 남아있습니다.
관련 연구
TÜLU 3의 연구는 현대 언어 모델의 후처리 학습 발전 과정에서 중요한 위치를 차지합니다. 이 분야의 발전은 다중 작업 언어 모델 학습, 특히 명령어 튜닝에서 시작되었습니다. Mishra와 연구진, Wei와 연구진, Sanh와 연구진이 초기에 제안한 명령어 튜닝은 언어 모델이 작업 지시사항과 그에 대한 응답을 포함하는 샘플들로 학습되어 새로운 작업에 대해 ‘제로샷’ 일반화를 할 수 있게 하는 방식입니다.
초기의 명령어 튜닝 데이터셋들은 주로 자연어 추론과 같은 전통적인 자연어처리 작업에 초점을 맞추었으나, ChatGPT와 Claude, Gemini 등의 채팅 기반 언어 모델의 등장과 함께 후처리 기법들은 명령어 튜닝을 넘어 선호도 튜닝 단계를 포함하도록 발전했습니다. Ouyang과 연구진이 제안한 것처럼, 모델들은 명령어 튜닝과 선호도 튜닝(PreFT) 또는 ‘RLHF’를 순차적으로 거치게 되었습니다.
RLHF의 초기 연구는 Christiano와 연구진, Ibarz와 연구진, Leike와 연구진이 제어 분야의 심층 강화학습 실험에서 시작되었습니다. 이 방식은 일반적으로 먼저 인간의 선호도로부터 보상 모델을 학습하고, 이후 학습된 보상을 사용하여 강화학습 프레임워크를 통해 언어 모델을 최적화합니다. 최근에는 Rafailov와 연구진, Zhao와 연구진이 제안한 것처럼 선호도에 대해 언어 모델을 직접 학습시키는 접근 방식이 개발되어 PreFT의 복잡성을 줄였습니다.
초기의 PreFT 접근 방식들이 수만 개의 인간 작성 지시사항과 선호도 레이블을 사용하는 매우 인간 중심적이었던 반면, Touvron과 연구진, Dubey와 연구진, Gunter와 연구진의 최근 연구들은 인간과 합성으로 생성된 선호도 데이터의 혼합, 다중 라운드 학습, 다양한 학습 알고리즘을 활용합니다.
RLHF가 주로 비공개 연구소에서 발전하는 동안, 공개된 후처리 학습 레시피들은 다소 뒤처져 있었습니다. Taori와 연구진, Conover와 연구진의 초기 ‘공개 후처리 학습 레시피’ 시도들은 명령어 튜닝 단계에 초점을 맞추어 공개된 언어 모델들을 합성 생성되거나 인간이 만든 데이터셋으로 파인튜닝했습니다. Wang과 연구진이 보여준 것처럼 이러한 데이터셋들을 결합하면 강력한 성능을 달성할 수 있었지만, Ivison과 연구진의 연구에서 드러났듯이 인간 평가를 기반으로 한 비공개 모델들과의 격차를 줄이기 위해서는 PreFT 단계를 포함하는 것이 중요했습니다.
오늘날 대부분의 인기 있는 적응형 모델들은 DPO(또는 그 변형들)와 AI 피드백 데이터를 사용하는 공개 PreFT 레시피를 채택하고 있습니다. 여기에는 TÜLU 2, Zephyr-β, Starling 등이 포함됩니다. 그러나 이러한 모델들은 데이터와 성능 면에서 비공개 후처리 레시피들에 비해 뒤처져 있습니다. 2024년 11월 20일 기준으로 LMSYS의 ChatBotArena 상위 50위 안에 후처리 학습 데이터를 공개한 모델은 없으며, 대부분의 공개 레시피들은 비공개 후처리 설정에 비해 상대적으로 적은 데이터와 적은 수의 학습 라운드를 사용합니다. 예를 들어, Dubey와 연구진이 개발한 Llama 3.1은 이전 모델에서 생성된 출력을 여러 라운드에 걸쳐 학습하고, 광범위한 인간 피드백 데이터를 활용하며, 강력한 모델을 사용하여 합성 지시사항을 작성하는 방식을 채택했습니다. 최근의 다른 발전들로는 합성 데이터를 위한 거부 샘플링과 단계별 어시스턴트 응답을 위한 고급 보상 모델링이 있습니다.
TÜLU 3는 이러한 비공개 레시피들의 규모에 완전히 도달하지는 못했지만, 강력한 비공개 레시피들과 견줄 만한 성능을 달성하고 모든 관련 산출물(코드, 모델, 데이터 등)을 추가 연구와 활용을 위해 공개함으로써 공개 후처리 학습의 수준을 한 단계 끌어올렸습니다. TÜLU 3의 파이프라인은 기존 연구들보다 훨씬 크고 복잡하며, 거의 백만 개의 명령어 튜닝 샘플, 수십만 개의 선호도 쌍, 그리고 새로운 온라인 RL 학습 단계를 포함합니다.
검증 가능한 보상을 통한 강화학습(RLVR) 접근법과 관련하여, 이 연구는 RL 관련 기술을 통해 언어 모델의 추론을 개선하려는 최근의 다양한 연구들과 관련이 있습니다. 특히 Zelikman과 연구진이 제안한 자기 교사 추론기(STaR) 계열의 연구와 Hoffman과 연구진의 TRICE는 모두 기존의 정답을 신호로 사용하여 더 나은 모델 추론(또는 사고의 연쇄)을 생성하는 방법을 연구했습니다.
STaR는 정책 경사 알고리즘의 근사로 볼 수 있으며, Quiet-STaR는 이 접근법을 확장하여 모델이 추가 생성을 통해 일반적인 언어 모델링(‘말하기 전에 생각하기’)을 개선하도록 학습시킵니다. TRICE 또한 맞춤형 MCMC 기반 EM 알고리즘을 사용하여 여러 추론 경로에 걸쳐 학습함으로써 정답의 가능성을 높이는 것을 목표로 합니다.
최근에는 Kazemnejad와 연구진의 VinePPO가 GSM8k와 MATH의 이진 보상을 사용하여 새로운 PPO 기반 알고리즘을 테스트했으며, 다른 최근 연구들은 코드 피드백을 학습 신호로 사용하는 방법을 탐구했습니다. 이에 비해 TÜLU 3가 제안하는 RLVR은 단순히 기존의 RL 프레임워크(PPO)를 학습에 사용하며, 이진 보상으로 완전히 온라인으로 실행됩니다.
또한 RLVR은 수학 영역을 넘어 정확한 지시사항 준수에서도 개선을 이끌어낼 수 있음을 발견했습니다. 연구진은 가치 모델 초기화와 검증 가능한 보상과 함께 일반 보상 모델을 사용하는 것을 포함하여 RLVR의 여러 핵심 구성 요소들을 주의 깊게 분석했으며, 향후 연구에서 이 기술을 더욱 발전시키고 확장할 계획입니다.
References
Subscribe via RSS