The Llama 3 Herd of Models
by Meta AI
TL;DR
이 연구를 시작하게 된 배경과 동기는 무엇입니까?
메타(Meta)는 현재 AI 발전의 핵심 과제인 대규모 언어 모델의 성능과 효율성 향상을 목표로 이 연구를 시작했습니다. 특히 기존 모델들이 가진 한계점들, 즉 다국어 처리의 불균형, 긴 컨텍스트 처리의 어려움, 도구 활용 능력의 부족, 그리고 추론 능력의 제한을 극복하고자 했습니다. 또한 모델의 안전성과 신뢰성을 높이면서도 실용적인 활용이 가능한 수준의 계산 효율성을 달성하는 것이 주요 동기였습니다.
이 연구에서 제시하는 새로운 해결 방법은 무엇입니까?
Llama 3는 세 가지 핵심적인 혁신을 제시합니다. 첫째, 데이터 품질과 다양성의 획기적 개선으로, 15조 개의 다국어 토큰을 포함하는 고품질 학습 데이터를 구축했습니다. 둘째, 규모의 효율적 확장으로, 4050억 개의 매개변수를 가진 고밀도 트랜스포머 모델을 이전보다 50배 많은 연산량으로 학습했습니다. 셋째, 복잡성 관리를 위해 표준 트랜스포머 구조를 채택하고 안정적인 학습 절차를 구현했습니다. 특히 주목할 만한 점은 128K 토큰의 컨텍스트 처리 능력과 코드 생성, 수학적 추론, 도구 활용 등 다양한 능력의 통합적 향상입니다.
제안된 방법은 어떻게 구현되었습니까?
구현은 크게 사전 학습과 후속 학습의 두 단계로 진행되었습니다. 사전 학습에서는 엄격한 데이터 정제 과정을 거쳐 고품질 학습 데이터를 구축했으며, 파이프라인 병렬화와 FP8 양자화 등의 최적화 기술을 도입하여 학습 효율성을 높였습니다. 후속 학습에서는 지도 학습 미세조정(SFT)과 직접 선호도 최적화(DPO)를 통해 모델을 인간의 선호도에 맞게 정렬했습니다. 특히 안전성 강화를 위해 Llama Guard 3를 개발하여 입출력 필터링을 구현했으며, 멀티모달 기능 통합을 위한 단계적 접근 방식도 도입했습니다.
이 연구의 결과가 가지는 의미는 무엇입니까?
이 연구의 결과는 대규모 언어 모델 분야에 몇 가지 중요한 의미를 가집니다. 첫째, GPT-4와 같은 최고 수준의 모델들과 견줄 만한 성능을 달성하면서도 공개적으로 접근 가능한 모델을 제공함으로써 AI 연구의 민주화에 기여했습니다. 둘째, 안전성과 성능의 균형을 맞추는 새로운 기준을 제시했으며, 특히 도구 활용과 긴 컨텍스트 처리에서 획기적인 발전을 이루었습니다. 셋째, 효율적인 학습과 추론 최적화 기술을 통해 대규모 모델의 실용적 배포 가능성을 높였습니다. 이는 향후 AI 모델들의 개발 방향에 중요한 지침을 제공할 것으로 기대됩니다.
Llama 3: 메타의 새로운 기초 모델 시리즈
메타(Meta)는 최근 인공지능 발전의 핵심이 되는 새로운 기초 모델 시리즈인 Llama 3를 발표했습니다. Llama 3는 다국어 처리, 코딩, 추론, 도구 활용 능력을 기본적으로 지원하는 언어 모델 시리즈입니다. 이 시리즈의 대표 모델은 4050억 개의 매개변수를 가진 고밀도 트랜스포머 구조를 채택하고 있으며, 최대 128K 토큰의 컨텍스트 윈도우를 처리할 수 있습니다.
메타 연구진은 고품질 기초 모델 개발에 있어 세 가지 핵심 요소에 주목했습니다. 첫째는 데이터로, Llama 2와 비교하여 사전 학습과 후속 학습에 사용되는 데이터의 양과 품질을 대폭 개선했습니다. 구체적으로, 사전 학습 데이터는 약 15조 개의 다국어 토큰을 포함하고 있어, Llama 2의 1.8조 토큰에 비해 크게 증가했습니다.
둘째는 규모의 확장으로, Llama 3의 대표 모델은 이전 Llama 2 모델보다 약 50배 많은 3.8 × 10²⁵ FLOPs를 사용하여 학습되었습니다. 15.6조 개의 텍스트 토큰으로 4050억 개의 학습 가능한 매개변수를 가진 모델을 사전 학습했으며, 기초 모델의 스케일링 법칙에 따라 이 대표 모델은 동일한 학습 절차로 훈련된 더 작은 모델들보다 우수한 성능을 보여주었습니다.
셋째는 복잡성 관리입니다. 연구진은 모델 개발 과정의 확장성을 극대화하기 위해 신중한 설계 선택을 했습니다. Vaswani와 연구진이 제안한 표준 고밀도 트랜스포머 모델 구조를 약간 수정하여 채택했으며, Shazeer와 연구진이 제안한 혼합 전문가 모델(mixture-of-experts) 대신 이 구조를 선택한 것은 학습 안정성을 높이기 위해서였습니다. 또한 후속 학습 과정에서도 지도 학습 미세조정(SFT), 거부 샘플링(RS), 직접 선호도 최적화(DPO)와 같은 비교적 단순한 절차를 채택했습니다. 이는 Ouyang과 연구진이나 Schulman과 연구진이 제안한 것과 같은 더 복잡한 강화학습 알고리즘 대신 선택된 것으로, 안정성과 확장성을 높이기 위한 결정이었습니다. Llama 3 시리즈는 8B, 70B, 405B 매개변수를 가진 세 가지 다국어 언어 모델로 구성되어 있습니다. 연구진은 이 모델들을 다양한 벤치마크 데이터셋에서 평가했으며, 특히 대표 모델인 405B 버전은 GPT-4와 같은 최고 수준의 언어 모델들과 비교했을 때 유사한 수준의 성능을 보여주었습니다.
성능 평가 결과를 살펴보면, Llama 3의 8B 모델은 MMLU 5-shot 평가에서 69.4점을, GSM8K 8-shot CoT 평가에서 84.5점을 기록했습니다. 70B 모델은 더욱 향상된 성능을 보여주어 MMLU에서 83.6점, GSM8K에서 95.1점을 달성했습니다. 대표 모델인 405B 버전은 가장 뛰어난 성능을 보여주어 MMLU에서 87.3점, GSM8K에서 96.8점을 기록했습니다.
메타는 이러한 Llama 3 모델들을 업데이트된 Llama 3 커뮤니티 라이선스 하에 공개적으로 배포하고 있습니다. 여기에는 405B 매개변수 언어 모델의 사전 학습 버전과 후속 학습 버전, 그리고 입출력 안전성을 위한 새로운 Llama Guard 3 모델이 포함됩니다. 특히 Llama Guard 3는 이전 버전을 개선하여 더욱 강화된 안전성 기능을 제공합니다.
연구진은 또한 Llama 3를 기반으로 이미지 인식, 비디오 인식, 음성 이해 기능을 통합하는 실험도 진행했습니다. 이러한 멀티모달 확장 모델들은 이미지, 비디오, 음성 인식 작업에서 최신 기술 수준과 견줄 만한 성능을 보여주었습니다. 다만 이러한 멀티모달 모델들은 아직 개발 중이며, 현재는 공개 배포 단계에 이르지 않았습니다.
Llama 3의 모델 구조와 학습 과정
Llama 3의 모델 구조와 학습 과정은 크게 두 단계로 구성됩니다. 첫 번째는 언어 모델 사전 학습(pre-training) 단계이고, 두 번째는 언어 모델 후속 학습(post-training) 단계입니다.
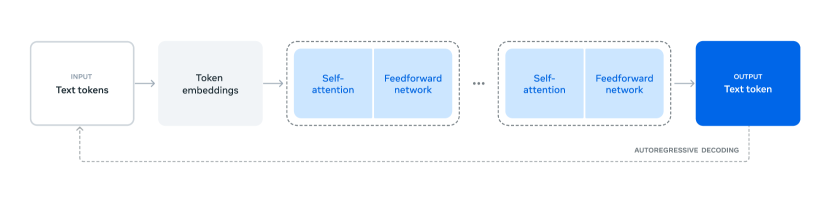
위 구조도는 Llama 3의 전반적인 아키텍처와 학습 과정을 보여줍니다. 모델은 텍스트 토큰을 입력으로 받아 토큰 임베딩 레이어를 통과시킨 후, 셀프 어텐션 네트워크와 피드포워드 네트워크를 통해 처리합니다. 이는 트랜스포머 기반 언어 모델의 핵심 요소들을 포함하고 있으며, 자기회귀적(autoregressive) 방식으로 다음 토큰을 예측하도록 학습됩니다.
사전 학습 단계에서는 대규모 다국어 텍스트 말뭉치를 이산 토큰으로 변환하고, 이를 사용하여 다음 토큰 예측 작업을 수행하도록 대규모 언어 모델을 학습시킵니다. 이 과정에서 모델은 언어의 구조를 학습하고 텍스트로부터 세상에 대한 광범위한 지식을 획득합니다. 구체적으로, 4050억 개의 매개변수를 가진 모델을 15.6조 개의 토큰으로 학습시키며, 초기에는 8K 토큰의 컨텍스트 윈도우를 사용합니다. 이후 지속적인 사전 학습을 통해 컨텍스트 윈도우를 128K 토큰까지 확장합니다.
후속 학습 단계에서는 사전 학습된 언어 모델이 지시사항을 따르고 어시스턴트로서 적절하게 행동하도록 조정됩니다. 이는 지도 학습 미세조정(SFT)과 직접 선호도 최적화(DPO)를 포함하는 여러 라운드의 인간 피드백 기반 정렬 과정을 통해 이루어집니다. 이 단계에서는 도구 사용과 같은 새로운 기능들이 통합되며, 코딩과 추론 능력도 크게 향상됩니다.
멀티모달 기능의 통합을 위해 연구진은 세 가지 추가 단계를 도입했습니다. 첫째, 이미지와 음성을 위한 별도의 인코더를 사전 학습합니다. 이미지 인코더는 대규모 이미지-텍스트 쌍 데이터셋으로 학습되어 시각적 콘텐츠와 자연어 설명 간의 관계를 학습하며, 음성 인코더는 자기지도 학습 방식으로 음성 신호의 구조를 학습합니다.
둘째, 비전 어댑터 학습을 통해 사전 학습된 이미지 인코더를 언어 모델과 통합합니다. 어댑터는 일련의 교차 어텐션 레이어로 구성되어 이미지 인코더의 표현을 언어 모델에 전달합니다. 이 과정에서 이미지 인코더의 매개변수는 업데이트되지만 언어 모델의 매개변수는 의도적으로 고정됩니다. 또한 이미지 어댑터 위에 비디오 어댑터를 학습시켜 프레임 간 정보를 통합하는 능력을 부여합니다.
마지막으로, 음성 어댑터 학습을 통해 음성 인코더를 모델에 통합합니다. 이 어댑터는 음성 인코딩을 미세조정된 언어 모델에 직접 입력할 수 있는 토큰 표현으로 변환합니다. 음성 이해 성능을 높이기 위해 어댑터와 인코더의 매개변수가 지도 학습 미세조정 과정에서 함께 업데이트되며, 이 과정에서도 언어 모델의 매개변수는 변경되지 않습니다.
사전 학습 과정
Llama 3의 사전 학습 과정은 크게 네 가지 핵심 요소로 구성됩니다. 첫째는 대규모 학습 데이터의 수집과 필터링, 둘째는 모델 아키텍처 설계와 스케일링 법칙을 통한 모델 크기 결정, 셋째는 대규모 학습을 위한 효율적인 사전 학습 기술 개발, 마지막으로 사전 학습 레시피의 개발입니다.
사전 학습 데이터
연구진은 2023년 말까지의 지식을 포함하는 다양한 데이터 소스에서 사전 학습 데이터셋을 구축했습니다. 각 데이터 소스에 대해 중복 제거와 데이터 정제 메커니즘을 적용하여 고품질 토큰을 확보했으며, 개인식별정보(PII)가 많이 포함된 도메인과 성인 콘텐츠가 포함된 도메인은 제외했습니다.
웹 데이터 수집 과정에서는 다음과 같은 주요 단계를 거쳤습니다.
-
PII 및 안전성 필터링: 안전하지 않은 콘텐츠나 PII가 포함될 가능성이 높은 웹사이트, Meta의 안전성 기준에 따라 유해하다고 판단된 도메인, 성인 콘텐츠를 포함하는 것으로 알려진 도메인을 필터링했습니다.
-
텍스트 추출 및 정제: 웹 문서의 원본 HTML 콘텐츠에서 고품질의 다양한 텍스트를 추출하기 위해 맞춤형 파서를 개발했습니다. 이 파서는 상용구 제거의 정밀도와 콘텐츠 재현율을 최적화하도록 설계되었으며, 인간 평가를 통해 성능을 검증했습니다. 수학 및 코드 콘텐츠가 포함된 HTML 페이지는 해당 콘텐츠의 구조를 보존하도록 신중하게 처리했습니다.
- 중복 제거: URL 수준, 문서 수준, 라인 수준에서 여러 단계의 중복 제거를 수행했습니다.
- URL 수준에서는 전체 데이터셋에 대해 URL 기반 중복 제거를 수행하고 각 URL에 대해 가장 최신 버전을 유지했습니다.
- 문서 수준에서는 MinHash를 사용하여 전체 데이터셋에서 유사 중복 문서를 제거했습니다.
- 라인 수준에서는 ccNet 방식과 유사한 적극적인 중복 제거를 수행했으며, 각 30M 문서 버킷에서 6회 이상 등장하는 라인을 제거했습니다.
- 휴리스틱 필터링: 추가적인 저품질 문서, 이상치, 과도한 반복을 포함하는 문서를 제거하기 위한 휴리스틱을 개발했습니다. 예를 들어:
- 로깅이나 에러 메시지와 같이 반복된 내용으로 구성된 라인을 제거하기 위해 중복 n-gram 커버리지 비율을 사용했습니다.
- 도메인 차단 목록으로 걸러지지 않은 성인 웹사이트를 필터링하기 위해 “불건전 단어” 카운팅을 활용했습니다.
- 학습 코퍼스 분포와 비교하여 이상치 토큰이 과도하게 많은 문서를 필터링하기 위해 토큰 분포의 Kullback-Leibler 발산을 사용했습니다.
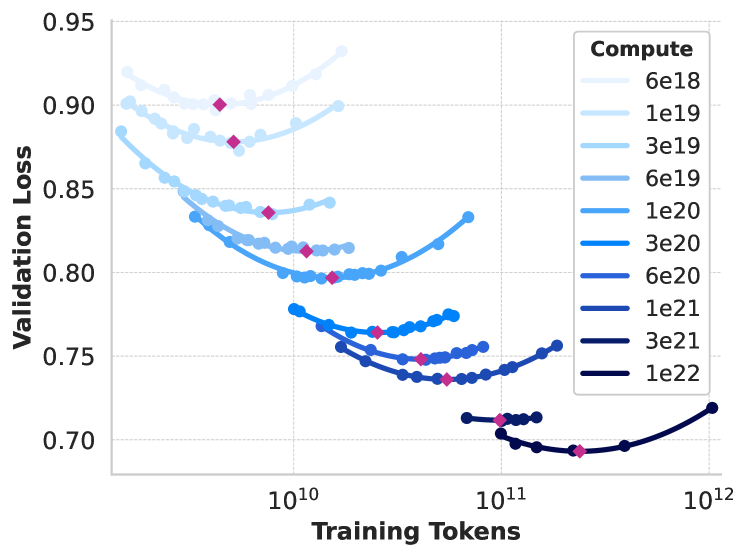
이 그래프는 다양한 컴퓨트 스케일에서의 검증 손실을 보여주는 스케일링 법칙 IsoFLOPs 곡선을 나타냅니다. 6e18에서 1e22 FLOPs 사이의 컴퓨트 규모에서 학습 토큰 수에 따른 손실 변화를 보여주며, 각 컴퓨트 스케일에서의 측정값을 2차 다항식으로 근사화했습니다. 모델 기반 품질 필터링에서는 다양한 모델 기반 품질 분류기를 적용하여 고품질 토큰을 선별했습니다. 여기에는 fasttext와 같은 빠른 분류기를 사용하여 Wikipedia에서 참조될 만한 텍스트를 인식하는 방법과, Llama 2의 예측을 기반으로 학습된 RoBERTa 기반 분류기를 사용하는 더 계산 집약적인 방법이 포함됩니다. Llama 2 기반 품질 분류기를 학습시키기 위해, 정제된 웹 문서의 학습 세트를 만들고 품질 요구사항을 설명한 뒤 Llama 2의 채팅 모델에게 문서가 이러한 요구사항을 충족하는지 판단하도록 지시했습니다. 효율성을 위해 DistilRoBERTa를 사용하여 각 문서의 품질 점수를 생성했습니다.
코드와 추론 데이터를 위해서는 코드와 수학 관련 웹 페이지를 추출하는 도메인별 파이프라인을 구축했습니다. 코드와 추론 분류기는 모두 Llama 2로 주석이 달린 웹 데이터에 대해 학습된 DistilRoBERTa 모델입니다. 앞서 언급한 일반 품질 분류기와 달리, STEM 분야의 수학적 추론과 자연어가 혼합된 코드를 포함하는 웹 페이지를 대상으로 프롬프트 튜닝을 수행했습니다. 코드와 수학의 토큰 분포가 자연어와 상당히 다르기 때문에, 이러한 파이프라인은 도메인별 HTML 추출, 맞춤형 텍스트 특징, 필터링을 위한 휴리스틱을 구현합니다.
다국어 데이터 처리에서도 영어 데이터와 유사한 처리 파이프라인을 구현하여 PII나 안전하지 않은 콘텐츠가 포함된 웹사이트를 필터링했습니다. 다국어 텍스트 처리 파이프라인의 주요 특징은 다음과 같습니다.
- fasttext 기반 언어 식별 모델을 사용하여 문서를 176개 언어로 분류
- 각 언어별 데이터에 대해 문서 수준과 라인 수준의 중복 제거 수행
- 언어별 휴리스틱과 모델 기반 필터를 적용하여 저품질 문서 제거
또한 다국어 Llama 2 기반 분류기를 사용하여 다국어 문서의 품질 순위를 매겨 고품질 콘텐츠가 우선순위를 갖도록 했습니다. 사전 학습에 사용되는 다국어 토큰의 양은 영어와 다국어 벤치마크에서의 모델 성능을 균형있게 고려하여 실험적으로 결정했습니다.
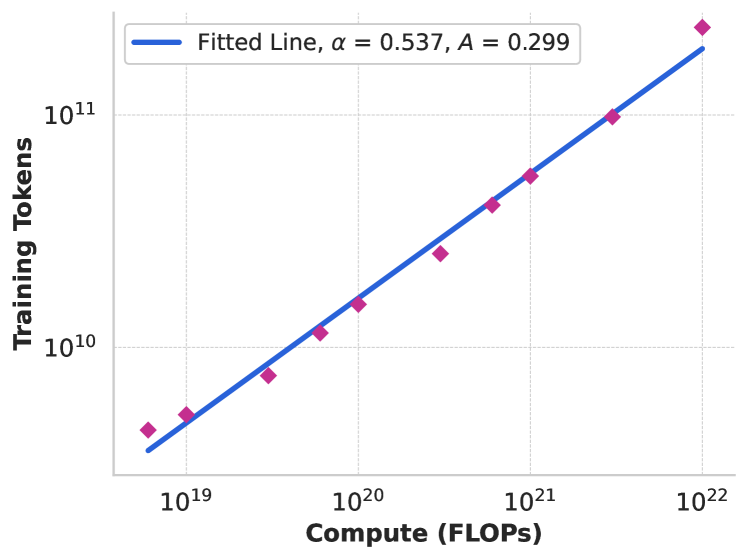
이 그래프는 컴퓨트 최적 모델에서 사전 학습 컴퓨트 예산에 따른 학습 토큰 수의 관계를 보여줍니다. α = 0.537, A = 0.299의 매개변수를 가진 스케일링 법칙에 데이터 포인트를 맞춘 결과를 나타내며, 이는 컴퓨트 예산이 증가할수록 최적의 모델 성능을 위한 학습 토큰 수가 더 느린 비율로 증가함을 시사합니다. 데이터 믹스의 결정을 위해서는 지식 분류와 스케일링 법칙 실험이라는 두 가지 주요 도구를 활용했습니다. 지식 분류를 위해 연구진은 웹 데이터에 포함된 정보의 유형을 분류하는 분류기를 개발했습니다. 이를 통해 예술과 엔터테인먼트와 같이 웹상에서 과다 대표되는 데이터 카테고리의 비중을 적절히 조절할 수 있었습니다.
데이터 믹스를 결정하기 위한 스케일링 법칙 실험에서는, 특정 데이터 믹스로 여러 개의 작은 모델을 학습시키고 이를 통해 해당 믹스로 학습된 대형 모델의 성능을 예측했습니다. 이 과정을 여러 데이터 믹스에 대해 반복하여 새로운 데이터 믹스 후보를 선정했으며, 이후 이 후보 데이터 믹스로 더 큰 모델을 학습시켜 주요 벤치마크에서의 성능을 평가했습니다.
최종적으로 결정된 데이터 믹스는 일반 지식 토큰이 약 50%, 수학 및 추론 토큰이 25%, 코드 토큰이 17%, 다국어 토큰이 8%의 비율로 구성되었습니다.
연구진은 실험을 통해 소량의 고품질 코드와 수학 데이터에 대한 어닐링(annealing)이 사전 학습된 모델의 주요 벤치마크 성능을 향상시킬 수 있다는 것을 발견했습니다. Li와 연구진의 접근 방식과 유사하게, 특정 도메인의 고품질 데이터의 비중을 높인 데이터 믹스로 어닐링을 수행했습니다. 이때 모델의 실제 퓨샷 학습 능력과 도메인 외 일반화 능력을 평가하기 위해 일반적으로 사용되는 벤치마크의 학습 세트는 어닐링 데이터에 포함시키지 않았습니다.
OpenAI의 연구를 따라 GSM8k와 MATH 학습 세트를 어닐링에 사용했을 때의 효과를 평가했습니다. 그 결과 8B 파라미터 Llama 3 모델의 경우 GSM8k와 MATH 검증 세트에서 각각 24.0%와 6.4%의 성능 향상이 있었습니다. 그러나 405B 모델에서는 이러한 향상이 미미했는데, 이는 플래그십 모델이 이미 강력한 문맥 내 학습(in-context learning)과 추론 능력을 갖추고 있어 특정 도메인의 학습 샘플이 없어도 우수한 성능을 보일 수 있음을 시사합니다.
Blakeney와 연구진의 연구와 유사하게, 어닐링을 통해 작은 도메인별 데이터셋의 가치를 판단할 수 있다는 것도 발견했습니다. 50% 학습이 완료된 Llama 3 8B 모델의 학습률을 40B 토큰에 걸쳐 선형적으로 0으로 감소시키는 방식으로 데이터셋의 가치를 측정했습니다. 이러한 실험에서는 새로운 데이터셋에 30%의 가중치를 할당하고 나머지 70%는 기본 데이터 믹스에 할당했습니다. 이러한 어닐링 기반 평가 방식은 모든 작은 데이터셋에 대해 스케일링 법칙 실험을 수행하는 것보다 효율적입니다.
모델 아키텍처
Llama 3는 Vaswani와 연구진이 제안한 표준 고밀도 트랜스포머 아키텍처를 기반으로 합니다. 이 모델은 Llama와 Llama 2의 기본 아키텍처를 크게 변경하지 않았으며, 주요 성능 향상은 데이터 품질과 다양성의 개선, 그리고 학습 규모의 확대를 통해 달성되었습니다.
Llama 2와 비교하여 몇 가지 중요한 수정사항이 있습니다. 첫째, 추론 속도를 개선하고 디코딩 중 키-값 캐시의 크기를 줄이기 위해 8개의 키-값 헤드를 가진 그룹 쿼리 어텐션(GQA)을 도입했습니다. 둘째, 동일한 시퀀스 내의 서로 다른 문서 간 셀프 어텐션을 방지하는 어텐션 마스크를 구현했습니다. 이 변경은 표준 사전 학습 중에는 제한적인 영향을 미쳤지만, 매우 긴 시퀀스에 대한 지속적인 사전 학습에서 중요한 역할을 했습니다.
토크나이저 측면에서는 128K 토큰의 어휘를 사용하며, 이는 tiktoken 토크나이저의 100K 토큰과 비영어 언어를 더 잘 지원하기 위한 28K개의 추가 토큰으로 구성됩니다. 새로운 토크나이저는 영어 샘플 데이터에서 문자당 토큰 수를 Llama 2의 3.17에서 3.94로 개선했습니다. 이를 통해 동일한 학습 컴퓨팅 리소스로 더 많은 텍스트를 처리할 수 있게 되었습니다. 또한 선별된 비영어 언어에서 28K개의 토큰을 추가한 것이 영어 토큰화에는 영향을 미치지 않으면서 압축률과 다운스트림 성능을 향상시켰습니다.
RoPE 기본 주파수 하이퍼파라미터는 500,000으로 증가시켰습니다. Xiong과 연구진의 연구에 따르면 이 값은 32,768 토큰까지의 컨텍스트 길이에 효과적인 것으로 나타났습니다.
Llama 3의 플래그십 모델인 405B 버전은 126개의 레이어, 16,384 차원의 토큰 표현, 128개의 어텐션 헤드를 가진 아키텍처를 사용합니다. 이는 3.8 × 10²⁵ FLOPs의 학습 예산에 대해 스케일링 법칙에 따른 계산상 최적의 모델 크기입니다.
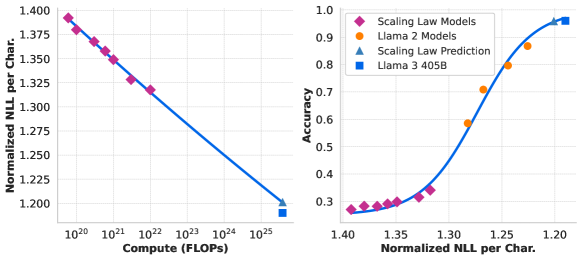
이 그래프는 ARC Challenge 벤치마크에 대한 스케일링 법칙 예측을 보여줍니다. 왼쪽 그래프는 사전 학습 FLOPs에 따른 정답의 정규화된 음의 로그 우도를 나타내며, 오른쪽 그래프는 정규화된 음의 로그 우도에 따른 ARC Challenge 정확도를 보여줍니다. 이러한 분석을 통해 사전 학습을 시작하기 전에 ARC Challenge 벤치마크에서의 모델 성능을 예측할 수 있습니다.
인프라, 스케일링, 효율성
Llama 3의 대규모 사전 학습을 위해 메타는 강력한 하드웨어 인프라와 최적화된 학습 시스템을 구축했습니다. 405B 모델의 학습은 Meta의 프로덕션 클러스터에서 진행되었으며, 이는 이전의 AI Research SuperCluster에서 Llama 1과 2를 학습했던 것과는 다른 접근방식입니다. 프로덕션급 안정성을 최적화한 이 설정은 대규모 학습에 필수적이었습니다.
컴퓨팅 인프라는 최대 16K개의 H100 GPU로 구성되었으며, 각 GPU는 80GB HBM3를 탑재하고 700W TDP로 동작합니다. Meta의 Grand Teton AI 서버 플랫폼을 기반으로 하는 각 서버는 8개의 GPU와 2개의 CPU를 갖추고 있으며, 서버 내의 GPU들은 NVLink를 통해 연결됩니다. 학습 작업은 Meta의 글로벌 스케일 학습 스케줄러인 MAST를 통해 관리됩니다.
스토리지 시스템으로는 Meta의 범용 분산 파일 시스템인 Tectonic을 사용했습니다. 이 시스템은 7,500대의 SSD 서버로 구성되어 240PB의 저장 용량을 제공하며, 지속 가능한 처리량 2TB/s와 최대 처리량 7TB/s를 지원합니다. 특히 중요한 과제는 짧은 시간 동안 스토리지 패브릭을 포화시키는 체크포인트 쓰기 작업을 처리하는 것이었습니다. 체크포인트는 복구와 디버깅을 위해 각 GPU의 모델 상태를 저장하며, GPU당 1MB에서 4GB 범위의 데이터를 저장합니다.
네트워크 인프라는 Arista 7800과 Minipack2 Open Compute Project OCP 랙 스위치를 기반으로 하는 RDMA over Converged Ethernet(RoCE) 패브릭을 사용했습니다. 더 작은 Llama 3 모델들은 Nvidia Quantum2 Infiniband 패브릭에서 학습되었습니다. 두 네트워크 모두 GPU 간 400Gbps 상호 연결을 활용하며, 이러한 기반 네트워크 기술의 차이에도 불구하고 대규모 학습 워크로드에 대해 동등한 성능을 제공하도록 최적화되었습니다.
RoCE 기반 AI 클러스터의 네트워크 토폴로지는 3계층 Clos 네트워크로 구성되어 있습니다. 최하위 계층에서는 각 랙이 16개의 GPU를 호스팅하며, 이는 두 대의 서버로 분할되어 단일 Minipack2 톱오브랙(ToR) 스위치에 연결됩니다. 중간 계층에서는 192개의 이러한 랙이 클러스터 스위치로 연결되어 완전한 양방향 대역폭을 가진 3,072 GPU의 포드를 형성합니다. 최상위 계층에서는 동일한 데이터센터 건물 내의 8개 포드가 집선 스위치를 통해 연결되어 24K GPU 클러스터를 구성합니다. 네트워크 로드 밸런싱에서는 전통적인 Equal-Cost Multi-Path(ECMP) 라우팅으로는 처리하기 어려운 대규모 네트워크 플로우를 효과적으로 관리하기 위해 두 가지 핵심 기술을 도입했습니다. 첫째, 집합 라이브러리는 두 GPU 사이에 단일 플로우 대신 16개의 네트워크 플로우를 생성하여 플로우당 트래픽을 줄이고 로드 밸런싱을 위한 더 많은 플로우를 제공합니다. 둘째, Enhanced-ECMP(E-ECMP) 프로토콜은 RoCE 헤더의 추가 필드를 해싱하여 이 16개의 플로우를 다양한 네트워크 경로에 효과적으로 분산시킵니다.
혼잡 제어를 위해서는 스파인에 딥 버퍼 스위치를 사용하여 집합 통신 패턴으로 인한 일시적인 혼잡과 버퍼링을 수용합니다. 이 설정은 학습 과정에서 흔히 발생하는 느린 서버로 인한 지속적인 혼잡과 네트워크 백프레셔의 영향을 제한하는 데 도움이 됩니다. E-ECMP를 통한 향상된 로드 밸런싱은 혼잡 발생 가능성을 크게 줄여, Data Center Quantized Congestion Notification(DCQCN)과 같은 전통적인 혼잡 제어 방법 없이도 24K GPU 클러스터를 성공적으로 운영할 수 있게 했습니다.
대규모 모델 학습을 위해 연구진은 4D 병렬화 방식을 도입했습니다. 이는 텐서 병렬화(TP), 파이프라인 병렬화(PP), 컨텍스트 병렬화(CP), 데이터 병렬화(DP)를 결합한 것으로, 모델을 여러 GPU에 효율적으로 분산시키고 각 GPU의 HBM에 모델 파라미터, 옵티마이저 상태, 그래디언트, 활성화값을 적절히 맞추는 것을 가능하게 합니다.
텐서 병렬화는 개별 가중치 텐서를 여러 청크로 나누어 다른 디바이스에 분산시킵니다. 파이프라인 병렬화는 모델을 수직으로 레이어별로 나누어 서로 다른 디바이스가 전체 모델 파이프라인의 다른 단계를 병렬로 처리할 수 있게 합니다. 컨텍스트 병렬화는 입력 컨텍스트를 세그먼트로 나누어 매우 긴 시퀀스 길이 입력에 대한 메모리 병목 현상을 줄입니다. 마지막으로 완전 분산 데이터 병렬화(FSDP)를 사용하여 모델, 옵티마이저, 그래디언트를 분산시키면서 데이터 병렬화를 구현합니다.
이러한 병렬화 구성과 하드웨어, 소프트웨어의 세심한 튜닝을 통해 표에 나타난 구성에서 38-43%의 전반적인 BF16 Model FLOPs Utilization(MFU)을 달성했습니다. 16K GPU에서 DP=128로 설정했을 때 MFU가 41%로, 8K GPU에서 DP=64일 때의 43%보다 약간 낮아진 것은 학습 중 전역 배치당 토큰 수를 일정하게 유지하기 위해 DP 그룹당 배치 크기를 줄여야 했기 때문입니다. 파이프라인 병렬화의 개선을 위해 연구진은 기존 구현에서 발견된 여러 문제점들을 해결했습니다. 첫 번째 문제는 배치 크기 제약이었습니다. 기존의 구현에서는 GPU당 배치 크기가 파이프라인 단계 수로 나누어 떨어져야 한다는 제약이 있었습니다. 예를 들어, 깊이 우선 스케줄(DFS)의 경우 N = PP = 4여야 하고, 너비 우선 스케줄(BFS)의 경우 N = M이어야 했습니다. 여기서 M은 총 마이크로배치 수이고 N은 동일한 단계의 순방향 또는 역방향에 대한 연속적인 마이크로배치 수입니다. 하지만 사전 학습에서는 종종 배치 크기를 유연하게 조정할 필요가 있습니다.
두 번째 문제는 메모리 불균형이었습니다. 첫 번째 단계는 임베딩과 웜업 마이크로배치로 인해 더 많은 메모리를 소비했습니다. 세 번째 문제는 계산 불균형으로, 모델의 마지막 레이어 이후에 출력과 손실을 계산해야 하므로 이 단계가 실행 지연의 병목이 되었습니다.
이러한 문제들을 해결하기 위해 연구진은 파이프라인 스케줄을 수정했습니다. 새로운 스케줄에서는 N을 유연하게 설정할 수 있어 이 경우 N = 5로 설정하여 각 배치에서 임의의 수의 마이크로배치를 실행할 수 있게 되었습니다. 이를 통해 대규모에서 배치 크기 제한이 있을 때 단계 수보다 적은 마이크로배치를 실행하거나, 포인트-투-포인트 통신을 숨기기 위해 더 많은 마이크로배치를 실행하여 DFS와 BFS 사이에서 최적의 통신 및 메모리 효율성을 찾을 수 있게 되었습니다.
파이프라인의 균형을 맞추기 위해 첫 번째와 마지막 단계에서 각각 하나의 트랜스포머 레이어를 줄였습니다. 이는 첫 번째 단계의 모델 청크가 임베딩만을 가지고, 마지막 단계의 모델 청크가 출력 투영과 손실 계산만을 수행하도록 한 것입니다. 파이프라인 버블을 줄이기 위해 V개의 파이프라인 단계를 하나의 파이프라인 랭크에서 인터리브된 스케줄로 실행합니다. 전체 파이프라인 버블 비율은 \((PP-1)/(V*M)\)입니다.
또한 PP에서 비동기 포인트-투-포인트 통신을 도입했는데, 이는 특히 문서 마스크가 추가적인 계산 불균형을 도입하는 경우에 학습 속도를 상당히 향상시켰습니다. 비동기 포인트-투-포인트 통신의 메모리 사용량을 줄이기 위해 TORCH_NCCL_AVOID_RECORD_STREAMS를 활성화했습니다. 마지막으로, 상세한 메모리 할당 프로파일링을 기반으로 각 파이프라인 단계의 입력 및 출력 텐서를 포함하여 향후 계산에 사용되지 않을 텐서들을 선제적으로 할당 해제하여 메모리 비용을 줄였습니다. 이러한 최적화를 통해 활성화 체크포인팅 없이도 8K 토큰의 시퀀스에 대해 Llama 3를 사전 학습할 수 있었습니다. 긴 시퀀스 학습을 위한 컨텍스트 병렬화(CP)에서는 시퀀스 차원을 따라 분할하여 메모리 효율성을 개선했습니다. 구체적으로, 입력 시퀀스를 2×CP 청크로 분할하여 각 CP 랭크가 더 나은 부하 균형을 위해 두 개의 청크를 받도록 했습니다. i번째 CP 랭크는 i번째 청크와 (2×CP-1-i)번째 청크를 받게 됩니다.
기존의 CP 구현과 달리, Liu와 연구진이 제안한 링 구조의 통신과 계산 중첩 방식 대신 올게더(all-gather) 기반 방식을 채택했습니다. 이 방식에서는 먼저 키(K)와 값(V) 텐서를 올게더한 다음, 로컬 쿼리(Q) 텐서 청크에 대한 어텐션 출력을 계산합니다. 올게더 통신 지연이 중요 경로에 노출되지만, 두 가지 주요 이유로 이 접근 방식을 선택했습니다. 첫째, 문서 마스크와 같은 다양한 유형의 어텐션 마스크를 지원하기가 더 쉽고 유연합니다. 둘째, GQA 사용으로 인해 통신되는 K와 V 텐서가 Q 텐서보다 훨씬 작기 때문에 노출된 올게더 지연이 작습니다. 따라서 전체 인과 마스크에서 어텐션 계산의 시간 복잡도(O(S²))가 올게더의 시간 복잡도(O(S))보다 한 차수 더 크기 때문에 올게더 오버헤드는 무시할 만한 수준입니다.
네트워크 인식 병렬화 구성에서는 병렬화 차원의 순서 [TP, CP, PP, DP]를 네트워크 통신을 최적화하도록 구성했습니다. 가장 안쪽의 병렬화는 가장 높은 네트워크 대역폭과 가장 낮은 지연을 필요로 하므로 일반적으로 동일한 서버 내로 제한됩니다. 반면 가장 바깥쪽의 병렬화는 다중 홉 네트워크를 통해 확장될 수 있으며 더 높은 네트워크 지연을 허용할 수 있습니다. 따라서 네트워크 대역폭과 지연 요구사항에 따라 병렬화 차원을 [TP, CP, PP, DP] 순서로 배치했습니다. DP(즉, FSDP)는 가장 바깥쪽 병렬화로 설정되었는데, 이는 분산된 모델 가중치를 비동기적으로 프리페치하고 그래디언트를 리듀스하는 방식으로 더 긴 네트워크 지연을 허용할 수 있기 때문입니다.
GPU 메모리 오버플로를 피하면서 통신 오버헤드를 최소화하는 최적의 병렬화 구성을 찾는 것은 매우 어려운 과제입니다. 이를 위해 연구진은 메모리 소비 추정기와 성능 예측 도구를 개발했습니다. 이 도구들은 다양한 병렬화 구성을 탐색하고 전체 학습 성능을 예측하며 메모리 갭을 효과적으로 식별하는 데 도움을 주었습니다.
수치 안정성 측면에서는 서로 다른 병렬화 설정 간의 학습 손실을 비교하여 여러 수치적 문제를 해결했습니다. 학습 수렴을 보장하기 위해 역전파 계산 중에는 FP32 그래디언트 누적을 사용하고, FSDP에서 데이터 병렬 워커 간의 리듀스-스캐터 그래디언트도 FP32로 처리했습니다. 순방향 계산에서 여러 번 사용되는 비전 인코더 출력과 같은 중간 텐서의 경우, 역전파 그래디언트도 FP32로 누적됩니다.
후속 학습 과정
Llama 3 모델은 사전 학습된 체크포인트를 기반으로 여러 라운드의 후속 학습을 통해 인간의 선호도와 의도에 맞게 정렬됩니다. 각 후속 학습 라운드는 인간 주석이나 합성 데이터를 활용한 지도 학습 미세조정(Supervised Fine-tuning, SFT)과 직접 선호도 최적화(Direct Preference Optimization, DPO)로 구성됩니다.
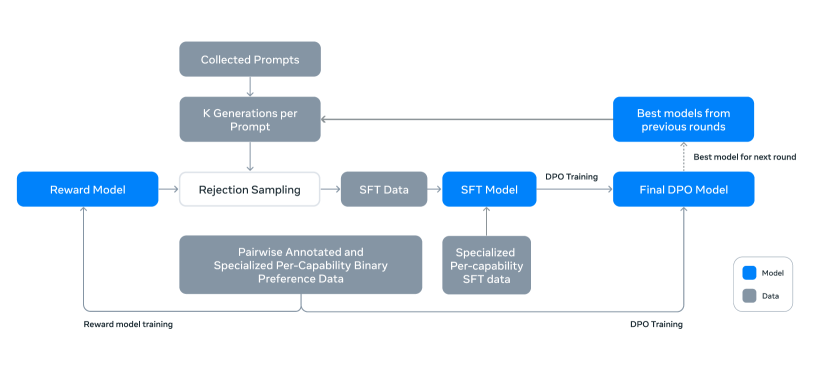
위 도식은 Llama 3의 전반적인 후속 학습 과정을 보여줍니다. 이 과정은 크게 세 가지 핵심 요소로 구성됩니다.
-
보상 모델링: 사전 학습된 체크포인트를 기반으로 인간 주석이 달린 선호도 데이터를 사용하여 보상 모델을 학습합니다. 이 모델은 Llama 2와 동일한 학습 목표를 사용하지만, 데이터 스케일링 후 개선 효과가 감소하는 것이 관찰되어 마진 항을 손실 함수에서 제거했습니다.
-
지도 학습 미세조정: 보상 모델을 사용하여 인간 주석 프롬프트에 대해 거부 샘플링을 수행하고, 이렇게 얻은 데이터와 다른 데이터 소스(합성 데이터 포함)를 사용하여 사전 학습된 언어 모델을 미세조정합니다. 가장 큰 모델의 경우 \(10^{-5}\)의 학습률로 8.5K에서 9K 스텝 동안 미세조정을 수행합니다.
-
직접 선호도 최적화: SFT 모델을 DPO를 통해 추가로 학습시켜 인간의 선호도에 맞게 정렬합니다. 이 과정에서는 이전 정렬 라운드에서 가장 성능이 좋은 모델들로부터 수집된 최신 선호도 데이터를 주로 사용합니다. DPO는 \(\beta = 0.1\)의 하이퍼파라미터와 \(10^{-5}\)의 학습률을 사용하며, 다음과 같은 알고리즘적 수정사항을 포함합니다.
-
DPO 손실에서 포맷팅 토큰 마스킹: 헤더와 종료 토큰과 같은 특수 포맷팅 토큰을 선택된 응답과 거부된 응답 모두에서 손실 계산에서 제외합니다. 이는 DPO 학습을 안정화하는 데 도움이 됩니다.
-
NLL 손실을 통한 정규화: 선택된 시퀀스에 대해 0.2의 스케일링 계수를 가진 음의 로그 우도(Negative Log-Likelihood, NLL) 손실 항을 추가합니다. 이는 생성을 위한 원하는 포맷을 유지하고 선택된 응답의 로그 확률이 감소하는 것을 방지하는 데 도움이 됩니다.
마지막으로, 각 RM, SFT, DPO 단계에서 다양한 데이터 버전이나 하이퍼파라미터를 사용한 실험에서 얻은 모델들을 평균화합니다. 이러한 전체 과정은 총 6라운드에 걸쳐 반복적으로 적용되며, 각 사이클마다 새로운 선호도 주석과 SFT 데이터를 수집하고 최신 모델을 사용하여 합성 데이터를 샘플링합니다.
후속 학습 데이터
Llama 3의 후속 학습 데이터 구성은 모델의 유용성과 행동 특성에 매우 중요한 역할을 합니다. 이 과정은 크게 선호도 데이터 수집과 지도 학습 미세조정(SFT) 데이터 구성으로 나눌 수 있습니다.
선호도 데이터 수집 과정은 Llama 2와 유사한 방식을 따르지만, 몇 가지 중요한 개선사항이 있습니다. 각 라운드 후에 여러 모델을 배포하여 주석을 수집하며, 각 사용자 프롬프트에 대해 두 개의 서로 다른 모델에서 두 개의 응답을 샘플링합니다. 이러한 모델들은 서로 다른 데이터 믹스와 정렬 방식으로 학습되어 있어, 코딩 전문성과 같은 다양한 능력의 강도를 가지며 데이터의 다양성을 높일 수 있습니다.
주석자들은 선택된 응답이 거부된 응답보다 얼마나 더 선호되는지를 네 가지 수준으로 평가합니다.
- 현저히 더 좋음
- 더 좋음
- 약간 더 좋음
- 미세하게 더 좋음
또한 선호도 순위 매기기 후에 편집 단계를 도입하여, 주석자들이 선호하는 응답을 직접 개선하거나 모델에게 피드백을 제공하여 응답을 개선하도록 합니다. 이로 인해 일부 선호도 데이터는 세 가지 응답(편집된 응답 > 선택된 응답 > 거부된 응답)의 순위를 가지게 됩니다.
Llama 3의 선호도 데이터 통계를 살펴보면, 일반 영어가 전체 비교의 81.99%를 차지하며, 코딩이 6.93%, 다국어가 5.19%, 추론 및 도구 사용이 5.89%를 차지합니다. Llama 2와 비교했을 때, 프롬프트와 응답의 평균 길이가 증가한 것이 관찰되었는데, 이는 Llama 3가 더 복잡한 작업에 대해 학습되었음을 시사합니다.
데이터 품질 관리를 위해 연구진은 엄격한 품질 분석과 인간 평가 프로세스를 구현했습니다. 이를 통해 프롬프트를 개선하고 주석자들에게 체계적이고 실행 가능한 피드백을 제공할 수 있었습니다. 예를 들어, Llama 3가 각 라운드 후에 성능이 향상됨에 따라, 모델이 부족한 영역을 타겟팅하기 위해 프롬프트의 복잡성을 적절히 증가시켰습니다.
보상 모델링과 DPO 학습에서는 서로 다른 데이터 선택 전략을 사용합니다. 보상 모델링의 경우 유사한 응답을 가진 샘플을 필터링한 후 해당 시점에서 사용 가능한 모든 선호도 데이터를 사용합니다. 반면 DPO 학습에서는 다양한 능력에 대한 최신 배치의 데이터만을 사용하며, 선택된 응답이 거부된 응답보다 ‘현저히 더 좋음’ 또는 ‘더 좋음’으로 평가된 샘플만을 사용합니다.
지도 학습 미세조정 데이터
Llama 3의 지도 학습 미세조정(SFT) 데이터는 크게 세 가지 주요 소스로 구성됩니다. 첫째는 거부 샘플링된 응답이 포함된 인간 주석 프롬프트, 둘째는 특정 능력을 목표로 하는 합성 데이터, 그리고 셋째는 소량의 인간 큐레이션 데이터입니다. 후속 학습 라운드가 진행됨에 따라 연구진은 더 강력한 Llama 3 변형을 개발했고, 이를 활용하여 복잡한 능력들을 광범위하게 다루는 더 큰 데이터셋을 수집할 수 있었습니다.
거부 샘플링 과정에서는 각 인간 주석 프롬프트에 대해 최신 채팅 모델 정책(일반적으로 이전 후속 학습 반복에서 가장 성능이 좋은 체크포인트나 특정 능력에 대해 가장 성능이 좋은 체크포인트)에서 K개(일반적으로 10에서 30 사이)의 출력을 샘플링하고, 보상 모델을 사용하여 최상의 후보를 선택합니다. 후기 라운드에서는 시스템 프롬프트를 도입하여 거부 샘플링된 응답이 다양한 능력에 따라 원하는 톤, 스타일, 포맷을 따르도록 유도했습니다.
거부 샘플링의 효율성을 높이기 위해 연구진은 PagedAttention을 도입했습니다. PagedAttention은 동적 키-값 캐시 할당을 통해 메모리 효율성을 향상시키며, 현재 캐시 용량에 기반하여 요청을 동적으로 스케줄링함으로써 임의의 출력 길이를 지원합니다. 이는 메모리 부족으로 인한 스왑 오버헤드를 제거하기 위해 최대 출력 길이를 정의하고, 해당 길이의 출력을 수용할 수 있는 충분한 메모리가 있는 경우에만 요청을 수행합니다. 또한 PagedAttention은 프롬프트에 대한 키-값 캐시 페이지를 모든 해당 출력에서 공유할 수 있게 해주어, 거부 샘플링 과정에서 2배 이상의 처리량 향상을 달성했습니다.
전체 데이터 구성을 살펴보면, “유용성” 믹스의 각 범주별 데이터 통계는 다음과 같은 특징을 보입니다. 일반 영어가 52.66%로 가장 큰 비중을 차지하며, 평균 6.3턴의 대화와 974.0 토큰의 평균 길이를 가집니다. 코드 관련 데이터는 14.89%를 차지하며, 평균 2.7턴의 대화와 753.3 토큰의 평균 길이를 보입니다. 추론 및 도구 사용 데이터는 21.19%를 차지하며, 평균 3.1턴의 대화와 661.6 토큰의 평균 길이를 가집니다. 특히 주목할 만한 것은 긴 컨텍스트 데이터로, 전체의 0.11%를 차지하지만 평균 38,135.6 토큰의 매우 긴 컨텍스트를 다룹니다.
데이터 처리와 품질 관리
Llama 3의 학습 데이터는 대부분 모델이 생성한 것이기 때문에 신중한 정제와 품질 관리가 필요합니다. 데이터 정제 과정에서는 초기 라운드에서 관찰된 이모지나 느낌표의 과도한 사용과 같은 바람직하지 않은 패턴들을 제거하기 위해 규칙 기반의 데이터 제거 및 수정 전략을 구현했습니다. 예를 들어, 과도하게 사과하는 톤의 문제를 완화하기 위해 “I’m sorry”나 “I apologize”와 같은 과다 사용되는 문구를 식별하고 데이터셋에서 이러한 샘플의 비율을 신중하게 조절했습니다.
데이터 정제 외에도 저품질 학습 샘플을 제거하고 전반적인 모델 성능을 향상시키기 위해 여러 모델 기반 기술을 적용했습니다. 먼저, Llama 3 8B를 토픽 분류기로 미세조정하여 모든 데이터를 “수학적 추론”과 같은 대분류와 “기하학 및 삼각법”과 같은 소분류로 분류했습니다.
품질 점수 측정을 위해서는 보상 모델과 Llama 기반 신호를 모두 활용했습니다. 보상 모델 기반 점수의 경우, 상위 25% 점수를 받은 데이터를 고품질로 간주했습니다. Llama 기반 점수의 경우, 일반 영어 데이터에 대해서는 정확성, 지시사항 준수, 톤/표현의 3점 척도를, 코딩 데이터에 대해서는 버그 식별과 사용자 의도의 2점 척도를 사용했으며, 최대 점수를 받은 샘플을 고품질로 간주했습니다. 두 점수 체계는 높은 불일치율을 보였지만, 이러한 신호들을 결합하는 것이 내부 테스트 세트에서 가장 좋은 재현율을 보였습니다.
난이도 점수 측정을 위해서는 Instag와 Llama 기반 점수라는 두 가지 측정 방식을 사용했습니다. Instag의 경우, Llama 3 70B를 사용하여 SFT 프롬프트의 의도 태깅을 수행했으며, 더 많은 의도가 있을수록 더 복잡한 것으로 간주했습니다. 또한 Llama 3를 사용하여 대화의 난이도를 3점 척도로 측정했습니다.
마지막으로 의미론적 중복 제거를 수행했습니다. 먼저 RoBERTa를 사용하여 완전한 대화를 클러스터링하고, 각 클러스터 내에서 품질 점수와 난이도 점수의 곱으로 정렬했습니다. 그리고 탐욕적 선택을 통해 모든 정렬된 예시를 반복하면서, 지금까지 본 예시들과의 최대 코사인 유사도가 임계값보다 작은 것들만 유지했습니다.
특수 능력 향상을 위한 접근 방식
Llama 3는 코드 생성, 다국어 처리, 수학 및 추론, 긴 컨텍스트 처리, 도구 활용, 사실성, 그리고 제어 가능성과 같은 특정 능력들을 향상시키기 위한 특별한 노력을 기울였습니다. 각 능력에 대한 개선은 체계적이고 전문화된 접근 방식을 통해 이루어졌습니다.
코드 관련 능력의 경우, Copilot과 Codex 이후 LLM의 코드 생성 능력이 큰 주목을 받아왔습니다. Llama 3는 Python, Java, Javascript, C/C++, Typescript, Rust, PHP, HTML/CSS, SQL, bash/shell과 같은 주요 프로그래밍 언어에 대한 코드 생성, 문서화, 디버깅, 리뷰 능력을 향상시키는 데 중점을 두었습니다.
이를 위해 코드 전문가 모델을 학습시켰는데, 이 모델은 메인 사전 학습 과정에서 분기하여 1조 토큰의 데이터 믹스(85% 이상이 코드 데이터)로 추가 사전 학습을 수행했습니다. 이는 특정 도메인의 성능을 향상시키는 데 효과적인 것으로 알려진 도메인별 지속 사전 학습 방식을 따른 것입니다. 학습의 마지막 수천 스텝에서는 레포지토리 수준의 고품질 코드 데이터로 긴 컨텍스트 미세조정(LCFT)을 수행하여 모델의 컨텍스트 길이를 16K 토큰으로 확장했습니다.
코드 생성 과정에서 발견된 주요 문제점들(지시사항 준수의 어려움, 코드 구문 오류, 잘못된 코드 생성, 버그 수정의 어려움 등)을 해결하기 위해 실행 피드백을 활용한 합성 데이터 생성 방식을 도입했습니다. 이 방식은 다음과 같은 과정으로 진행됩니다.
-
문제 설명 생성: 다양한 소스에서 무작위로 코드 스니펫을 샘플링하고 이를 바탕으로 프로그래밍 문제를 생성하여 긴 꼬리 분포를 포함한 다양한 주제를 다룹니다.
-
해결책 생성: Llama 3에게 각 문제를 주어진 프로그래밍 언어로 해결하도록 요청합니다. 좋은 프로그래밍의 일반적인 규칙을 프롬프트에 추가하고 주석으로 사고 과정을 설명하도록 하는 것이 도움이 되었습니다.
-
정확성 분석: 생성된 해결책의 정확성을 검증하기 위해 정적 분석과 동적 분석을 결합한 기법을 사용합니다. 파서와 린터를 통한 구문 검사, 단위 테스트 생성 및 실행을 통한 런타임 오류 검사 등을 수행합니다.
-
오류 피드백과 반복적 자기 수정: 해결책이 어떤 단계에서든 실패하면 모델에게 수정을 요청합니다. 원래 문제 설명, 오류가 있는 해결책, 파서/린터/테스터의 피드백을 포함한 프롬프트를 제공하여 모델이 스스로 개선할 수 있도록 합니다.
프로그래밍 언어 번역을 통한 합성 데이터 생성도 중요한 접근 방식 중 하나입니다. Python/C++와 같은 주요 프로그래밍 언어와 Typescript/PHP와 같은 덜 일반적인 언어들 사이의 성능 격차가 관찰되었는데, 이는 덜 일반적인 프로그래밍 언어에 대한 학습 데이터가 부족하기 때문입니다. 이를 해결하기 위해 일반적인 프로그래밍 언어의 데이터를 덜 일반적인 언어로 번역하는 방식을 사용했습니다.

위 그림은 Python 코드를 PHP 코드로 번역하는 예시를 보여줍니다. 이러한 번역은 Llama 3를 사용하여 수행되며, 구문 파싱, 컴파일, 실행을 통해 품질을 보장합니다. MultiPL-E 벤치마크에서 측정한 결과, 이 접근 방식은 덜 일반적인 언어들의 성능을 크게 향상시켰습니다.
역번역(backtranslation) 기법도 코드 문서화나 설명과 같이 실행 피드백이 품질 판단에 덜 유용한 능력을 향상시키기 위해 사용되었습니다. 이 방식으로 코드 설명, 생성, 문서화, 디버깅과 관련된 약 120만 개의 합성 대화를 생성했습니다. 사전 학습 데이터의 다양한 언어로 된 코드 스니펫을 시작점으로 하여,
-
생성: Llama 3에게 목표 능력을 나타내는 데이터를 생성하도록 합니다(예: 코드 스니펫에 대한 주석과 문서 문자열 추가, 또는 코드 설명 생성).
-
역번역: 모델에게 합성적으로 생성된 데이터를 원래 코드로 “역번역”하도록 요청합니다(예: 문서화만으로 코드를 생성하거나, 설명만으로 코드를 생성).
-
필터링: 원래 코드를 참조로 사용하여 Llama 3에게 출력의 품질을 판단하도록 합니다(예: 역번역된 코드가 원본에 얼마나 충실한지 평가).

위 그림은 시스템 프롬프트를 사용하여 생성된 코드의 품질을 개선하는 예시를 보여줍니다. 시스템 프롬프트는 필요한 주석 추가, 더 정보가 풍부한 변수명 사용, 메모리 절약 등의 개선을 이끌어냅니다. 이러한 시스템 프롬프트 기반의 품질 향상은 거부 샘플링 과정에서 중요한 역할을 합니다.
실행과 모델 판단 신호를 사용한 학습 데이터 필터링도 중요한 과정입니다. 거부 샘플링된 데이터에서 버그를 포함한 코드 블록과 같은 품질 문제가 발견되는데, 이러한 문제를 감지하는 것은 합성 코드 데이터만큼 간단하지 않습니다. 거부 샘플링된 응답은 일반적으로 자연어와 코드가 혼합되어 있으며, 코드가 항상 실행 가능할 것으로 기대되지는 않기 때문입니다(예: 사용자가 명시적으로 의사코드를 요청하거나 실행 가능한 프로그램의 매우 작은 스니펫만 수정하도록 요청할 수 있음). 이러한 문제를 해결하기 위해 연구진은 “모델 판단자” 접근 방식을 도입했습니다. 이전 버전의 Llama 3를 사용하여 코드 정확성과 코드 스타일이라는 두 가지 기준에 따라 이진(0/1) 점수를 할당합니다. 완벽한 점수인 2점을 받은 샘플만을 유지하는 이 엄격한 필터링은 처음에는 다운스트림 벤치마크 성능의 저하를 초래했는데, 이는 주로 도전적인 프롬프트가 포함된 예시들이 불균형적으로 제거되었기 때문입니다.
이를 해결하기 위해 연구진은 가장 도전적인 것으로 분류된 코딩 데이터의 응답을 Llama 기반 “모델 판단자” 기준을 충족할 때까지 전략적으로 수정했습니다. 이러한 도전적인 문제들을 개선함으로써 코딩 데이터는 품질과 난이도 사이의 균형을 달성할 수 있었고, 이는 최적의 다운스트림 성능으로 이어졌습니다.
다국어 능력 향상을 위해서는 먼저 다국어 전문가를 학습시켰습니다. Llama 3의 사전 학습 데이터 믹스는 영어 토큰이 비영어 토큰보다 상당히 많았기 때문에, 비영어 언어에서 더 높은 품질의 인간 주석을 수집하기 위해 사전 학습 과정에서 분기하여 90%가 다국어 토큰으로 구성된 데이터 믹스로 계속 사전 학습을 수행했습니다. 이후 이 전문가 모델에 대해 앞서 설명한 후속 학습을 수행했으며, 사전 학습이 완전히 완료될 때까지 이 모델을 사용하여 비영어 언어에서 더 높은 품질의 주석을 수집했습니다.
다국어 SFT 데이터는 주로 네 가지 소스에서 파생됩니다. 전체 분포를 보면 인간 주석이 2.4%, 다른 NLP 과제의 데이터가 44.2%, 거부 샘플링된 데이터가 18.8%, 번역된 추론 데이터가 34.6%를 차지합니다. 특히 기계 번역된 데이터는 번역투(translationese)나 이름 편향, 성별 편향, 문화적 편향을 방지하기 위해 가능한 한 사용을 피했습니다. 단, 수학 문제와 같이 언어가 단순한 경우에는 예외적으로 번역을 허용했으며, 이는 MGSM과 같은 다국어 수학 추론 벤치마크에서 강력한 성능 향상을 이끌어냈습니다.
수학 및 추론 능력 향상
Llama 3의 수학 및 추론 능력 향상을 위해 연구진은 여러 가지 핵심적인 도전 과제들을 해결해야 했습니다. 먼저, 문제의 복잡성이 증가할수록 지도 학습 미세조정(SFT)에 사용할 수 있는 유효한 프롬프트나 질문의 수가 감소하는 문제가 있었습니다. 이러한 데이터 부족은 모델이 다양한 수학적 기술을 학습하는 데 필요한 대표성 있는 학습 데이터셋을 만드는 것을 어렵게 만들었습니다.
또한 효과적인 추론을 위해서는 단계별 해결 과정이 필요한데, 이를 위한 실제 사고 과정(chain of thought)의 부족이 큰 문제였습니다. 모델이 문제를 단계별로 분해하고 최종 답에 도달하는 방법을 안내하는 데 필수적인 이러한 사고 과정의 부족은 성능 향상의 큰 장애물이었습니다.
모델이 생성한 사고 과정을 사용할 때는 중간 단계가 항상 정확하지 않을 수 있다는 문제도 있었습니다. 이러한 부정확한 중간 단계는 잘못된 최종 답변으로 이어질 수 있어 해결이 필요했습니다. 또한 코드 인터프리터와 같은 외부 도구를 활용하여 코드와 텍스트를 번갈아 가며 추론하는 능력을 향상시키는 것도 중요한 과제였습니다.
이러한 도전 과제들을 해결하기 위해 연구진은 다음과 같은 방법론을 적용했습니다. 먼저 프롬프트 부족 문제를 해결하기 위해 수학적 맥락의 관련 사전 학습 데이터를 질문-답변 형식으로 변환하여 지도 학습 미세조정에 활용했습니다. 또한 모델이 부족한 수학적 기술을 식별하고 이를 가르치기 위한 프롬프트를 인간으로부터 적극적으로 수집했습니다. 이를 위해 수학적 기술의 분류 체계를 만들고 이에 따라 관련 프롬프트와 질문을 제공하도록 했습니다.
단계별 추론 과정의 부족 문제는 Llama 3를 사용하여 일련의 프롬프트에 대한 단계별 해결책을 생성하는 방식으로 해결했습니다. 각 프롬프트에 대해 모델은 여러 개의 생성을 수행하고, 이를 정답을 기준으로 필터링했습니다. 또한 Llama 3를 사용하여 특정 단계별 해결책이 주어진 질문에 대해 유효한지 검증하는 자체 검증도 수행했습니다. 이 과정은 모델이 유효한 추론 과정을 생성하지 않는 경우를 제거함으로써 미세조정 데이터의 품질을 향상시켰습니다. 잘못된 추론 과정을 필터링하기 위해 연구진은 결과 기반과 단계별 보상 모델을 학습시켜 중간 추론 단계가 잘못된 학습 샘플을 제거했습니다. 더 도전적인 프롬프트의 경우, 몬테 카를로 트리 탐색(MCTS)을 학습된 단계별 보상 모델과 함께 사용하여 유효한 추론 과정을 생성했습니다. 이는 고품질 추론 데이터 수집을 더욱 강화했습니다.
코드와 텍스트 추론의 통합을 위해서는 Llama 3에게 텍스트 추론과 관련 Python 코드의 조합을 통해 추론 문제를 해결하도록 프롬프팅했습니다. 코드 실행은 추론 체인이 유효하지 않은 경우를 제거하기 위한 피드백 신호로 사용되어 추론 과정의 정확성을 보장했습니다.
피드백과 실수로부터의 학습을 위해 연구진은 잘못된 생성(즉, 잘못된 추론 과정으로 이어지는 생성)을 활용하고 Llama 3에게 프롬프팅하여 올바른 생성을 얻는 오류 수정을 수행했습니다. 잘못된 시도로부터의 피드백을 사용하고 이를 수정하는 이러한 반복적인 과정은 모델이 정확하게 추론하고 실수로부터 학습하는 능력을 향상시켰습니다.
긴 컨텍스트 처리 능력의 경우, 최종 사전 학습 단계에서 Llama 3의 컨텍스트 길이를 8K 토큰에서 128K 토큰으로 확장했습니다. 사전 학습과 마찬가지로, 미세조정 과정에서도 짧은 컨텍스트와 긴 컨텍스트 능력 사이의 균형을 맞추기 위해 레시피를 신중하게 조정해야 했습니다. 기존 SFT 레시피를 짧은 컨텍스트 데이터만으로 단순히 적용했을 때는 사전 학습에서 얻은 긴 컨텍스트 능력이 크게 저하되는 것이 관찰되어, 긴 컨텍스트 데이터를 SFT 데이터 믹스에 포함시킬 필요성이 대두되었습니다.
그러나 긴 컨텍스트를 읽는 것이 지루하고 시간이 많이 소요되는 특성 때문에 인간이 이러한 예시에 주석을 다는 것은 현실적으로 어려웠습니다. 따라서 연구진은 주로 합성 데이터에 의존하여 이 격차를 메웠습니다. Llama 3의 이전 버전을 사용하여 주요 긴 컨텍스트 사용 사례에 기반한 합성 데이터를 생성했는데, 여기에는 (가능한 다중 턴) 질의응답, 긴 문서 요약, 코드 저장소에 대한 추론이 포함됩니다.
도구 활용 능력 향상
Llama 3는 검색 엔진이나 코드 인터프리터와 같은 도구를 활용하는 능력을 크게 향상시켰습니다. 이러한 도구 활용은 순수한 채팅 모델을 더 일반적인 어시스턴트로 변환하는 데 매우 중요한 역할을 합니다. 연구진은 Llama 3가 다음과 같은 도구들과 상호작용할 수 있도록 학습시켰습니다.
검색 엔진으로는 Brave Search를 활용하여 모델의 지식 단절 시점을 넘어서는 최신 이벤트나 특정 정보를 웹에서 검색하여 답변할 수 있게 했습니다. Python 인터프리터를 통해서는 복잡한 계산을 수행하고, 사용자가 업로드한 파일을 읽어 질문 답변, 요약, 데이터 분석, 시각화와 같은 작업을 수행할 수 있습니다. 수학적 계산 엔진으로는 Wolfram Alpha API를 활용하여 수학, 과학 문제를 더 정확하게 해결하거나 Wolfram의 데이터베이스에서 정확한 정보를 검색할 수 있습니다.
이렇게 학습된 모델은 채팅 설정에서 이러한 도구들을 사용하여 사용자의 질의를 해결할 수 있으며, 다중 턴 대화에서도 이를 활용할 수 있습니다. 질의가 여러 도구 호출을 필요로 하는 경우, 모델은 단계별 계획을 작성하고, 순차적으로 도구를 호출하며, 각 도구 호출 후 추론을 수행할 수 있습니다. 또한 제로샷 도구 사용 능력도 향상되어, 컨텍스트 내에서 제공된 이전에 보지 못한 도구 정의와 사용자 질의가 주어졌을 때 올바른 도구 호출을 생성할 수 있습니다.
구현 측면에서는 각 핵심 도구를 서로 다른 메서드를 가진 Python 객체로 구현했습니다. 제로샷 도구는 설명과 문서(즉, 사용 예시)가 포함된 Python 함수로 구현되며, 모델은 함수의 시그니처와 독스트링만을 컨텍스트로 하여 적절한 호출을 생성할 수 있습니다. 또한 웹 API 호출을 위해 함수 정의와 호출을 JSON 형식으로 변환할 수 있습니다. 모든 도구 호출은 Python 인터프리터에 의해 실행되며, 이는 Llama 3 시스템 프롬프트에서 활성화되어야 합니다. 핵심 도구들은 시스템 프롬프트에서 개별적으로 활성화하거나 비활성화할 수 있습니다.
도구 활용을 위한 데이터 수집과 처리
Llama 3의 도구 활용 능력을 향상시키기 위한 데이터 수집은 일반적인 후속 학습 파이프라인과는 다소 차이가 있습니다. 도구 사용의 경우 대화에서 종종 하나 이상의 어시스턴트 메시지가 포함됩니다(예: 도구를 호출하고 도구 출력에 대해 추론하는 과정). 따라서 연구진은 메시지 수준에서 주석을 수집하는 방식을 채택했습니다. 주석자들은 동일한 컨텍스트를 가진 두 개의 어시스턴트 메시지 사이에서 선호도를 제공하거나, 둘 다 주요 문제가 있는 경우 하나의 메시지를 편집합니다. 선택되거나 편집된 메시지는 컨텍스트에 추가되고 대화가 계속됩니다. 이를 통해 도구 호출과 도구 출력에 대한 추론 능력 모두에 대해 인간의 피드백을 수집할 수 있습니다. 단, 주석자들은 도구 출력 자체를 순위 매기거나 편집할 수는 없습니다.
주석 과정을 가속화하기 위해 연구진은 먼저 이전 Llama 3 체크포인트에서 합성적으로 생성된 데이터로 기본적인 도구 사용 능력을 부트스트랩했습니다. 이를 통해 주석자들이 수행해야 하는 편집의 수를 줄일 수 있었습니다. 비슷한 맥락에서, Llama 3가 개발 과정에서 점진적으로 개선됨에 따라 인간 주석 프로토콜도 점진적으로 복잡해졌습니다. 단일 턴 도구 사용 주석으로 시작하여, 대화 내 도구 사용으로 이동하고, 최종적으로는 다단계 도구 사용과 데이터 분석에 대한 주석을 수집했습니다.
도구 사용을 위한 데이터셋은 다음과 같은 절차를 통해 생성됩니다. 단일 단계 도구 사용의 경우, 먼저 핵심 도구 중 하나의 호출이 필요한 합성 사용자 프롬프트를 퓨샷 생성 방식으로 생성합니다(예: 지식 단절 날짜를 초과하는 질문들). 그런 다음 이러한 프롬프트에 대한 적절한 도구 호출을 생성하고, 이를 실행한 후 출력을 모델의 컨텍스트에 추가합니다. 마지막으로 도구 출력을 기반으로 사용자의 질의에 대한 최종 답변을 생성하도록 모델에 다시 프롬프팅합니다.
다단계 도구 사용의 경우에도 유사한 프로토콜을 따르되, 먼저 Llama 3에게 최소 두 번의 도구 호출이 필요한 사용자 프롬프트를 생성하도록 요청합니다. 이때 동일하거나 다른 도구를 사용할 수 있습니다. 그런 다음 이러한 프롬프트를 조건으로 하여 Llama 3에게 ReAct와 유사하게 추론 단계와 도구 호출이 번갈아 가며 나타나는 해결책을 생성하도록 퓨샷 프롬프팅을 수행합니다.
파일 업로드 기능을 위해서는 .txt, .docx, .pdf, .pptx, .xlsx, .csv, .tsv, .py, .json, .jsonl, .html, .xml과 같은 파일 형식에 대한 주석을 수집합니다. 프롬프트는 제공된 파일을 기반으로 하며, 파일 내용 요약, 버그 찾기 및 수정, 코드 최적화, 데이터 분석이나 시각화 수행과 같은 작업을 요청합니다.
사실성과 제어 가능성 향상
Llama 3의 중요한 도전 과제 중 하나는 환각(hallucination) 문제였습니다. 대규모 언어 모델들은 지식이 부족한 영역에서도 과도하게 자신감 있는 응답을 하는 경향이 있으며, 이러한 모델들이 지식 베이스로 사용될 때 잘못된 정보의 확산과 같은 위험한 결과를 초래할 수 있습니다. 연구진은 사실성이 환각을 넘어서는 더 넓은 개념이라는 것을 인식하면서도, 환각 문제 해결을 우선순위로 삼았습니다.
연구진의 접근 방식은 후속 학습을 통해 모델이 “자신이 아는 것을 아는” 상태가 되도록 정렬하는 것이었으며, 단순히 지식을 추가하는 것은 지양했습니다. 이를 위한 주요 접근 방식은 모델의 생성을 사전 학습 데이터에 존재하는 사실적 데이터의 부분집합과 정렬하는 데이터를 생성하는 것이었습니다. 이를 위해 Llama 3의 컨텍스트 내 능력을 활용하는 지식 프로빙 기법을 개발했습니다.
이 데이터 생성 과정은 다음과 같이 진행됩니다. 먼저 사전 학습 데이터에서 데이터 스니펫을 추출하고, Llama 3에게 이러한 스니펫(컨텍스트)에 대한 사실적 질문을 생성하도록 프롬프팅합니다. 그런 다음 해당 질문에 대한 응답을 Llama 3에서 샘플링하고, 원본 컨텍스트를 참조로 사용하여 Llama 3를 판단자로 활용해 생성의 정확성을 평가합니다. 또한 Llama 3를 사용하여 생성의 정보성도 평가합니다. 샘플링된 여러 생성에서 일관되게 정보성은 있지만 부정확한 응답에 대해서는 Llama 3를 사용하여 거부 응답을 생성합니다.
제어 가능성 측면에서는 시스템 프롬프트를 통해 모델의 행동과 결과를 개발자와 사용자의 명세에 맞게 조정하는 능력에 중점을 두었습니다. Llama 3는 기초 모델로서 다양한 다운스트림 사용 사례에 쉽게 적용될 수 있도록 최대한의 제어 가능성을 갖추는 것을 목표로 했습니다.
제어 가능성 향상을 위한 선호도 샘플 수집은 일반 영어 카테고리 내에서 주석자들에게 Llama 3를 위한 다양한 시스템 프롬프트를 설계하도록 요청하는 방식으로 이루어졌습니다. 주석자들은 이후 모델과 대화를 나누면서 대화 과정 전반에 걸쳐 시스템 프롬프트에 정의된 지시사항을 일관되게 따르는지 평가했습니다. 이렇게 수집된 선호도 데이터는 보상 모델링, 거부 샘플링, SFT, DPO 과정에서 활용되어 Llama 3의 제어 가능성을 향상시켰습니다.
Llama 3의 성능 평가 결과
메타 연구진은 Llama 3의 성능을 세 가지 주요 측면에서 광범위하게 평가했습니다. (1) 사전 학습된 언어 모델의 성능, (2) 후속 학습된 언어 모델의 성능, 그리고 (3) 안전성 특성입니다. 이 중 사전 학습된 언어 모델의 평가 결과를 살펴보면, 연구진은 비슷한 규모의 다른 모델들과 비교 평가를 수행했습니다. 경쟁 모델들의 경우 공개적으로 보고된 결과나 직접 재현한 결과 중 더 좋은 점수를 사용했습니다.
평가 구성과 관련된 세부 사항들(샷 수, 메트릭, 하이퍼파라미터 등)은 메타의 GitHub 저장소에서 확인할 수 있으며, 공개 벤치마크에서 생성된 평가 데이터는 Hugging Face에 공개되어 있습니다. 평가는 표준 벤치마크, 다중 선택 문제 설정 변화에 대한 견고성, 적대적 평가를 포함하며, 학습 데이터 오염이 평가 결과에 미치는 영향도 분석했습니다.
표준 벤치마크는 크게 8가지 상위 범주로 구성됩니다. (1) 상식 추론, (2) 지식, (3) 독해력, (4) 수학/추론/문제 해결, (5) 긴 컨텍스트, (6) 코드, (7) 적대적 평가, (8) 종합 평가입니다. 각 범주별 세부 벤치마크는 다음과 같습니다.
독해력 평가에는 SQuAD V2, QuaC, RACE가 포함됩니다. 코딩 능력은 HumanEval과 MBPP를 통해 평가됩니다. 상식 추론과 이해력은 CommonSenseQA, PiQA, SiQA, OpenBookQA, WinoGrande로 측정됩니다. 수학, 추론, 문제 해결 능력은 GSM8K, MATH, ARC Challenge, DROP, WorldSense를 통해 평가됩니다.
적대적 평가에는 Adv SQuAD, Dynabench SQuAD, GSM-Plus, PAWS가 사용되었고, 긴 컨텍스트 처리 능력은 QuALITY와 many-shot GSM8K로 평가했습니다. 종합적인 능력 평가를 위해서는 MMLU, MMLU-Pro, AGIEval, BIG-Bench Hard가 활용되었습니다.
벤치마크 점수의 신뢰도를 평가하기 위해 연구진은 Madaan과 연구진이 제안한 방법론을 따라 95% 신뢰 구간을 계산했습니다. 벤치마크 점수가 가우시안 분포를 따른다고 가정할 때, 신뢰 구간은 다음 공식으로 계산됩니다.
\[CI(S) = 1.96 \times \sqrt{\frac{S \times (1-S)}{N}}\]여기서 \(S\)는 관찰된 벤치마크 점수(정확도 또는 EM)이고 \(N\)은 벤치마크의 샘플 크기입니다. 단순 평균이 아닌 벤치마크 점수에 대해서는 신뢰 구간을 생략했습니다. 연구진은 하위 샘플링이 능력 추정의 변동성에 영향을 미치는 유일한 요인이 아니므로, 계산된 신뢰 구간 값이 실제 변동성의 하한을 나타낸다는 점을 강조했습니다.
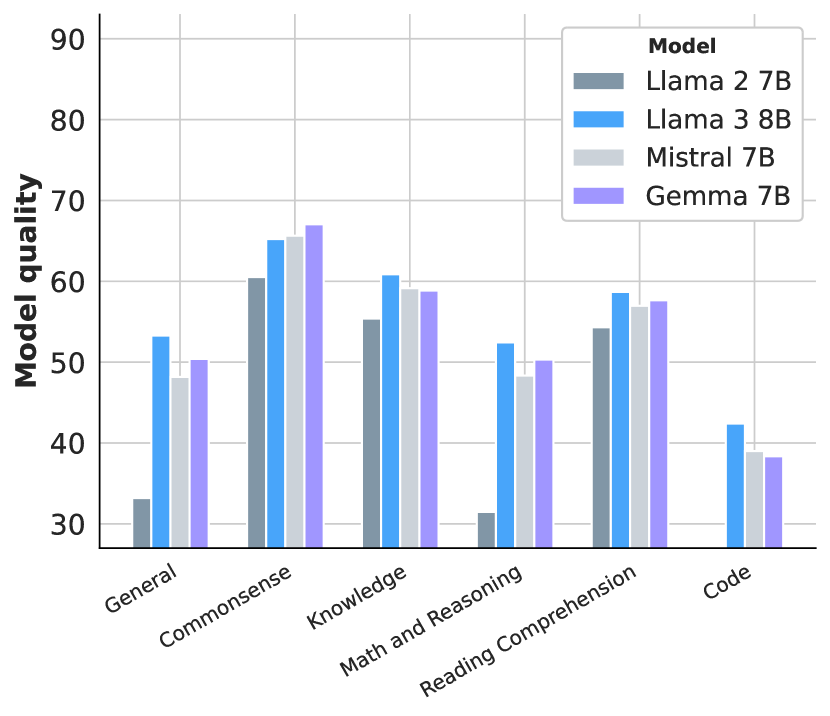
위 그래프는 Llama 3의 8B와 70B 모델, 그리고 Mistral 7B와 Gemma 7B 모델들의 사전 학습 벤치마크 성능을 보여줍니다. 각 능력 범주별로 벤치마크들의 평균 정확도를 표시하고 있으며, 더 큰 Llama 3 8B 모델이 작은 Llama 2 7B 모델보다 우수한 성능을 보이는 것을 확인할 수 있습니다. Llama 3의 8B와 70B 모델의 세부 성능 결과를 살펴보면, 거의 모든 범주에서 경쟁 모델들을 능가하는 것으로 나타났습니다. 특히 범주별 승률과 평균 성능 모두에서 우수한 결과를 보여주었습니다. Llama 3 70B는 이전 버전인 Llama 2 70B와 비교했을 때 대부분의 벤치마크에서 큰 폭의 성능 향상을 보였습니다. 다만 이미 성능이 포화 상태에 도달한 것으로 보이는 상식 벤치마크에서는 예외적으로 큰 차이를 보이지 않았습니다. 또한 Llama 3 70B는 Mixtral 8x22B보다도 전반적으로 더 나은 성능을 달성했습니다.
독해력 평가에서 Llama 3 8B는 SQuAD에서 77.0% (±0.8), QuaC에서 44.9% (±1.1), RACE에서 54.3% (±1.4)의 성능을 보였습니다. 70B 모델은 각각 81.8% (±0.7), 51.1% (±1.1), 59.0% (±1.4)로 성능이 향상되었으며, 405B 모델은 81.8% (±0.7), 53.6% (±1.1), 58.1% (±1.4)를 기록했습니다.
코딩 능력 평가에서는 더욱 두드러진 성능 향상이 관찰되었습니다. HumanEval에서 Llama 3 8B는 37.2% (±7.4), MBPP에서는 47.6% (±4.4)를 달성했습니다. 70B 모델은 각각 58.5% (±7.5)와 66.2% (±4.1)로 크게 향상되었고, 405B 모델은 61.0% (±7.5)와 73.4% (±3.9)를 기록하며 최고 수준의 성능을 보여주었습니다.
상식 이해력 평가에서도 모델 크기에 따른 일관된 성능 향상이 관찰되었습니다. CommonSenseQA의 경우 8B에서 75.0% (±2.5), 70B에서 84.1% (±2.1), 405B에서 85.8% (±2.0)를 기록했습니다. WinoGrande에서는 각각 75.7% (±2.0), 83.5% (±1.7), 82.2% (±1.8)의 성능을 보였습니다.
수학과 추론 능력에서는 특히 큰 모델들이 뛰어난 성과를 보였습니다. GSM8K에서 Llama 3 405B는 89.0% (±1.7)를 달성하며 GPT-4의 92.0% (±1.5)에 근접한 성능을 보여주었습니다. MATH 벤치마크에서도 405B 모델은 53.8% (±1.4)로 Gemini Ultra의 53.2% (±1.4)를 약간 상회하는 결과를 기록했습니다. 종합적인 평가 벤치마크에서도 Llama 3는 인상적인 성능을 보여주었습니다. MMLU에서 Llama 3 8B는 66.7%, 70B는 79.3%, 405B는 85.2%를 달성했습니다. 이는 GPT-4의 86.4%에 매우 근접한 수준입니다. MMLU-Pro에서도 비슷한 경향이 나타났는데, 8B에서 37.1%, 70B에서 53.8%, 405B에서 61.6%로 모델 크기에 따른 일관된 성능 향상을 보여주었습니다.
모델의 견고성(robustness) 평가도 중요한 부분을 차지했습니다. 연구진은 다중 선택형 문제(MCQ) 설정의 변화에 대한 모델의 민감도를 조사했습니다. 이전 연구들에 따르면, 모델의 성능과 순위가 인컨텍스트 예시의 순서와 레이블, 프롬프트의 정확한 형식, 답변 선택지의 형식과 순서와 같은 임의적인 설계 선택에 민감할 수 있다는 것이 알려져 있었습니다.
이러한 견고성을 평가하기 위해 연구진은 MMLU 벤치마크를 사용하여 네 가지 측면에서 모델을 테스트했습니다. (1) 퓨샷 레이블 편향, (2) 레이블 변형, (3) 답변 순서, (4) 프롬프트 형식입니다. 퓨샷 레이블 편향 실험에서는 네 개의 예시가 모두 같은 레이블을 가지는 경우(A A A A), 모두 다른 레이블을 가지는 경우(A B C D), 두 개의 레이블만 있는 경우(A A B B와 C C D D)를 비교했습니다.
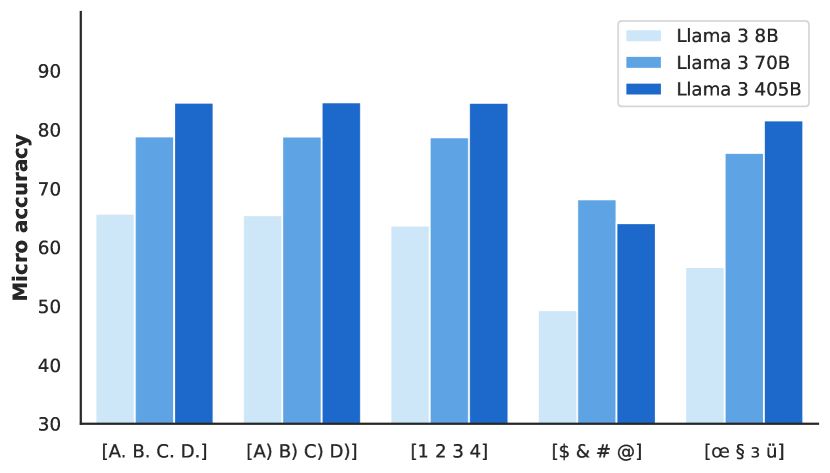
위 그래프는 MMLU 벤치마크에서 다양한 설계 선택에 대한 Llama 3의 견고성을 보여줍니다. 왼쪽 그래프는 레이블 변형에 대한 성능을, 오른쪽 그래프는 퓨샷 예시에 있는 레이블에 대한 성능을 나타냅니다. 특히 405B 모델은 이러한 변화에 매우 안정적인 성능을 보여주었습니다.
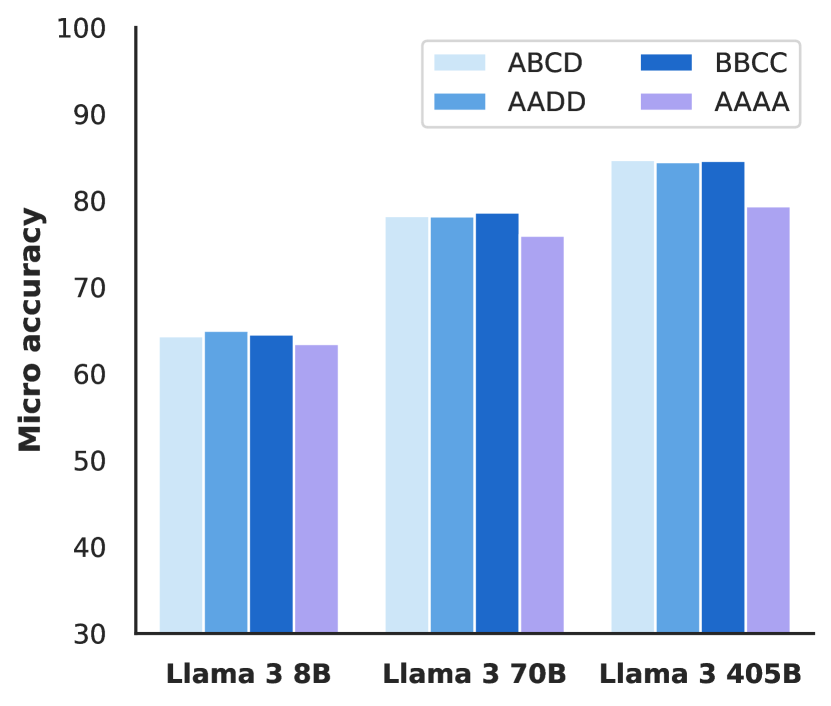
이 그래프는 답변 순서와 프롬프트 형식의 변화에 대한 Llama 3의 견고성을 보여줍니다. 405B 모델은 이러한 변화에도 일관된 성능을 유지했으며, 이는 모델이 표면적인 형식보다 실제 과제의 본질에 집중하고 있음을 시사합니다. 적대적 벤치마크에서의 Llama 3의 성능도 주목할 만한 결과를 보여주었습니다. 연구진은 질문 답변, 수학적 추론, 그리고 패러프레이즈 감지라는 세 가지 영역에서 적대적 벤치마크를 평가했습니다. 질문 답변 영역에서는 Adversarial SQuAD와 Dynabench SQuAD를, 수학적 추론에서는 GSM-Plus를, 패러프레이즈 감지에서는 PAWS를 사용했습니다.
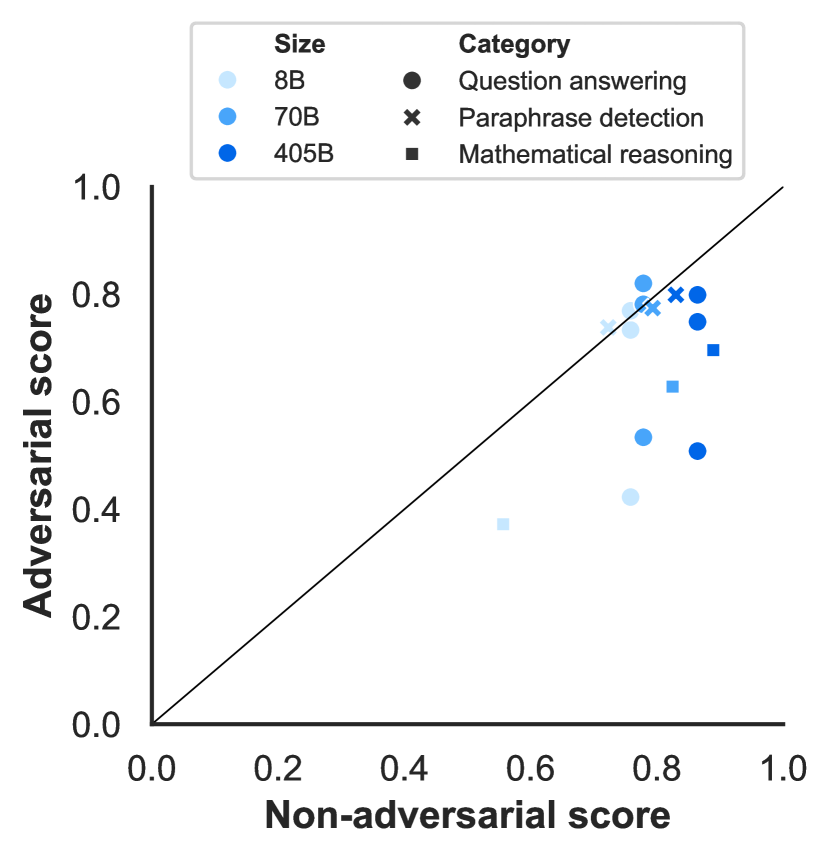
위 그래프는 질문 답변, 수학적 추론, 패러프레이즈 감지 벤치마크에서의 적대적 성능과 비적대적 성능을 비교하여 보여줍니다. 왼쪽은 사전 학습 모델의 결과를, 오른쪽은 후속 학습 모델의 결과를 나타냅니다. 비적대적 벤치마크로는 각각 SQuAD, GSM8K, QQP가 사용되었습니다.
패러프레이즈 감지 작업에서는 사전 학습 모델과 후속 학습 모델 모두 PAWS에서 구성된 적대성에 크게 영향을 받지 않는 것으로 나타났습니다. 이는 Weber와 연구진의 발견과 일치하는 결과로, 최신 대규모 언어 모델들이 여러 적대적 데이터셋에서 발견되는 피상적 상관관계에 덜 취약하다는 것을 보여줍니다.
그러나 수학적 추론과 질문 답변 영역에서는 적대적 성능이 비적대적 성능보다 상당히 낮게 나타났습니다. 이러한 패턴은 사전 학습 모델과 후속 학습 모델 모두에서 유사하게 관찰되었습니다. 이는 이들 영역에서 모델의 견고성을 더욱 향상시킬 필요가 있음을 시사합니다.
오염 분석(contamination analysis)에서는 평가 데이터가 사전 학습 코퍼스에 포함되어 있을 가능성이 벤치마크 점수에 미치는 영향을 추정했습니다. Singh과 연구진이 제안한 방법론을 따라, 연구진은 8-gram 중복을 기반으로 평가 예시의 점수를 매겼습니다. 데이터셋 \(D\)의 예시는 토큰의 비율 \(\mathcal{T}_{D}\)가 사전 학습 코퍼스에서 최소 한 번 발생하는 8-gram의 일부인 경우 오염된 것으로 간주되었습니다.
연구진은 각 데이터셋에 대해 세 가지 모델 크기에서 최대 유의미한 성능 향상 추정치를 보이는 값을 기준으로 \(\mathcal{T}_{D}\)를 선택했습니다. 이러한 분석을 통해 일부 데이터셋에서는 오염이 큰 영향을 미치는 반면, 다른 데이터셋에서는 그렇지 않다는 것을 발견했습니다. 예를 들어, PiQA와 HellaSwag의 경우 오염 추정치와 성능 향상 추정치가 모두 높게 나타났습니다. 반면 Natural Questions는 52%의 오염이 추정되었지만 성능에는 거의 영향을 미치지 않았습니다. Llama 3의 긴 컨텍스트 처리 능력에 대한 평가 결과도 주목할 만합니다. 연구진은 다양한 도메인과 텍스트 유형을 포괄하는 벤치마크를 사용했으며, 특히 편향되지 않은 평가 프로토콜(정확도 기반 메트릭)을 사용하는 하위 작업에 초점을 맞추었습니다.
Needle-in-a-Haystack 평가에서 Llama 3 모델들은 완벽한 성능을 보여주었습니다. 모든 문서 깊이와 컨텍스트 길이에서 100%의 바늘 검색 성능을 달성했습니다. Multi-needle 변형에서도 뛰어난 성능을 보였는데, 이는 컨텍스트에 네 개의 바늘을 삽입하고 그 중 두 개를 검색하는 능력을 테스트하는 것입니다. Llama 3 모델들은 이 작업에서도 거의 완벽에 가까운 검색 결과를 보여주었습니다.
ZeroSCROLLS 벤치마크는 긴 텍스트에 대한 제로샷 자연어 이해 능력을 평가합니다. 검증 세트에서의 평가 결과, Llama 3의 405B와 70B 모델은 다른 모델들과 비교하여 동등하거나 더 우수한 성능을 보여주었습니다. 특히 QuALITY에서 405B 모델은 95.2% (±9.1)의 높은 정확도를 달성했습니다.
InfiniteBench는 컨텍스트 윈도우 내의 긴 의존성을 이해하는 능력을 평가합니다. En.QA(소설에 대한 질의응답)와 En.MC(소설에 대한 객관식 질의응답)에서 405B 모델은 다른 모든 모델들을 능가했습니다. 특히 En.QA에서의 성능 향상이 두드러졌는데, 30.5% (±4.8)의 정확도를 기록했습니다.
긴 컨텍스트 벤치마크에서 특히 주목할 만한 점은 Llama 3 405B가 GPT-4나 Claude 3.5 Sonnet과 같은 최신 모델들과 비교했을 때도 경쟁력 있는 성능을 보여주었다는 것입니다. 예를 들어, SQuALITY에서 Llama 3 405B는 83.4% (±4.8)를 달성하여 GPT-4의 72.0% (±5.8)와 Claude 3.5 Sonnet을 크게 앞섰습니다.
이러한 평가 결과들은 Llama 3가 긴 컨텍스트 처리에서 상당한 진전을 이루었음을 보여줍니다. 특히 정보 검색, 문서 이해, 그리고 긴 시퀀스에서의 의존성 파악과 같은 핵심적인 능력들에서 강점을 보여주었습니다. 이는 128K 토큰이라는 긴 컨텍스트 윈도우를 효과적으로 활용할 수 있는 모델의 능력을 입증하는 것입니다. 도구 활용 능력에 대한 평가에서도 Llama 3는 주목할 만한 성과를 보여주었습니다. 연구진은 제로샷 도구 활용 능력을 Nexus, API-Bank, Gorilla API-Bench, 그리고 Berkeley Function Calling Leaderboard(BFCL)와 같은 다양한 벤치마크를 통해 평가했습니다.
Nexus 벤치마크에서 Llama 3의 모든 변형은 동급의 다른 모델들보다 우수한 성능을 보였습니다. 특히 405B 모델은 58.7% (±4.1)의 정확도를 달성했으며, 이는 GPT-4의 50.3% (±4.2)와 Claude 3.5 Sonnet의 45.7% (±4.2)를 크게 상회하는 결과입니다. API-Bank에서는 8B와 70B 모델이 각각 82.6% (±3.8)와 90.0% (±3.0)를 기록하며 같은 규모의 다른 모델들을 큰 차이로 앞섰습니다. 405B 모델은 92.3% (±2.6)를 달성하여 Claude 3.5 Sonnet의 92.6% (±2.6)에 근접한 성능을 보여주었습니다.
BFCL에서는 405B와 70B 모델이 각각 88.5% (±1.5)와 84.8% (±1.7)를 기록하며 경쟁력 있는 성능을 보였습니다. 특히 8B 모델은 76.1% (±2.0)로 같은 규모의 모델들 중 가장 우수한 성능을 달성했습니다.
연구진은 또한 코드 실행 작업에 초점을 맞춘 인간 평가도 수행했습니다. LMSys 데이터셋, GAIA 벤치마크, 인간 주석자, 그리고 합성 생성을 통해 수집된 2,000개의 사용자 프롬프트를 사용했으며, 이는 코드 실행(플롯팅이나 파일 업로드 제외), 플롯 생성, 파일 업로드와 관련된 작업들을 포함합니다.
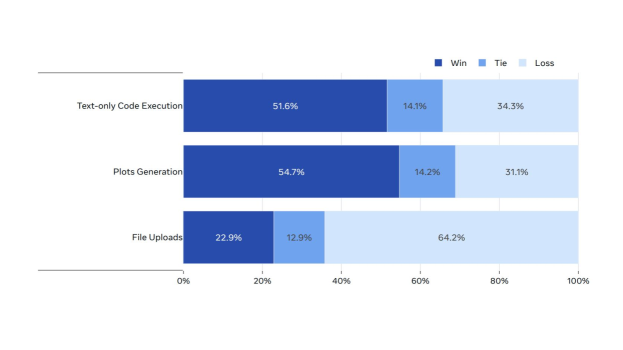
위 그래프는 코드 실행 작업에서 Llama 3 405B와 GPT-4o의 성능을 비교한 인간 평가 결과를 보여줍니다. 텍스트만을 사용하는 코드 실행과 플롯 생성 작업에서 Llama 3 405B는 GPT-4o를 크게 앞섰습니다. 다만 파일 업로드 사용 사례에서는 다소 뒤처지는 모습을 보였습니다.
이러한 평가 결과들은 Llama 3가 도구 활용 능력에서도 최신 모델들과 견줄 만한, 때로는 더 우수한 성능을 보유하고 있음을 입증합니다. 특히 코드 실행과 API 호출과 같은 실용적인 작업에서 강점을 보여주었으며, 이는 실제 응용 환경에서의 활용 가능성을 높여주는 중요한 특징입니다. 인간 평가 결과에서 Llama 3는 매우 흥미로운 성과를 보여주었습니다. 연구진은 약 7,000개의 프롬프트를 포함하는 포괄적인 평가를 수행했는데, 이는 영어, 추론, 코딩, 힌디어, 스페인어, 포르투갈어의 6가지 개별 능력과 영어, 추론, 코딩의 3가지 멀티턴 능력을 평가하도록 설계되었습니다.
평가 방법론은 매우 체계적이었습니다. 주석자들은 두 개의 서로 다른 모델 응답 중 어느 것을 선호하는지 7점 척도로 평가했습니다. 이 척도는 한 모델의 응답이 다른 모델의 응답보다 “훨씬 더 좋음”, “더 좋음”, “약간 더 좋음”, “거의 동등함”과 같은 세밀한 구분을 가능하게 했습니다. 한 모델의 응답이 “더 좋음” 또는 “훨씬 더 좋음”으로 평가된 경우를 해당 모델의 “승리”로 간주했습니다.
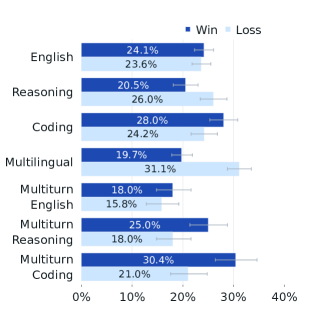
위 그래프는 Llama 3 405B와 GPT-4를 비교한 인간 평가 결과를 보여줍니다. 대부분의 능력에서 두 모델의 승률은 오차 범위 내에 있었으며, 특히 멀티턴 추론과 코딩 작업에서는 Llama 3 405B가 GPT-4를 앞섰습니다. 다만 다국어(힌디어, 스페인어, 포르투갈어) 프롬프트에서는 GPT-4에 비해 다소 낮은 성능을 보였습니다.
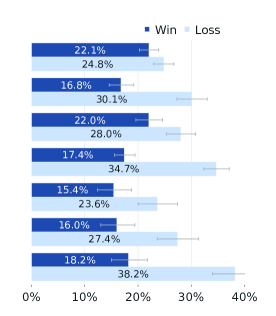
GPT-4o와의 비교에서는 영어 프롬프트에서 대등한 성능을 보여주었습니다. 이는 Llama 3가 최신 GPT-4 모델과도 경쟁할 수 있는 수준에 도달했음을 시사합니다.
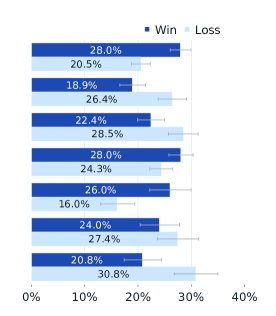
Claude 3.5 Sonnet과의 비교에서는 다국어 프롬프트에서 대등한 성능을, 단일 및 멀티턴 영어 프롬프트에서는 더 우수한 성능을 보였습니다. 그러나 코딩과 추론 능력에서는 다소 뒤처지는 모습을 보였습니다.
질적 분석 결과, 인간 평가에서의 모델 성능은 모델의 톤, 응답 구조, 상세함과 같은 미묘한 요소들에 크게 영향을 받는 것으로 나타났습니다. 이러한 요소들은 후속 학습 과정에서 지속적으로 최적화되고 있는 부분입니다.
전반적으로 인간 평가 결과는 표준 벤치마크 평가 결과와 일관성을 보였습니다. Llama 3 405B는 업계를 선도하는 모델들과 매우 경쟁력 있는 성능을 보여주었으며, 이는 현재 공개적으로 이용 가능한 모델들 중 최고 수준의 성능을 달성했음을 의미합니다.
다만 연구진은 인간 평가의 한계점도 지적했습니다. 모델 응답을 평가하기 위한 객관적 기준을 정의하기가 어렵고, 인간 주석자들의 개인적 편향, 배경, 선호도가 평가 결과에 영향을 미칠 수 있어 일부 결과가 일관되지 않거나 신뢰성이 떨어질 수 있다는 점을 언급했습니다. Llama 3의 안전성 평가는 매우 포괄적이고 체계적으로 이루어졌습니다. 연구진은 안전한 콘텐츠 생성 능력을 평가하면서도 유용한 정보 제공을 최대화하는 것에 중점을 두었습니다. 안전성 작업은 데이터 정제와 필터링 형태로 사전 학습 단계에서부터 시작되었으며, 이후 특정 안전성 정책에 맞춰 모델을 정렬하면서도 유용성을 유지하는 방식으로 안전성 미세조정이 진행되었습니다.
연구진은 다국어, 긴 컨텍스트, 도구 사용, 다양한 멀티모달 기능을 포함한 Llama 3의 모든 능력에 대해 안전성 완화 조치의 효과를 측정했습니다. 또한 사이버보안과 화학/생물학 무기 위험에 대한 업리프트(uplift) 평가도 수행했습니다. 여기서 업리프트는 웹 검색과 같은 기존 기술을 사용하는 것과 비교했을 때 새로운 기술 발전이 도입하는 추가적인 위험을 의미합니다.
레드팀(Red Team) 평가를 통해 반복적으로 다양한 안전성 위험을 식별하고 대응하는 과정도 수행되었으며, 잔여 위험에 대한 평가도 이루어졌습니다. 마지막으로 시스템 수준의 안전성, 즉 모델 자체의 입출력 주변에 분류기를 개발하고 조율하는 작업을 통해 안전성을 더욱 강화하고 개발자들이 다양한 사용 사례에 맞게 안전성을 커스터마이즈하고 생성형 AI를 더 책임감 있게 배포할 수 있도록 했습니다.
벤치마크 구성에 있어서는 ML Commons의 위험 분류 체계를 기반으로 다양한 내부 벤치마크를 개발했습니다. ToxiGen, XS Test와 같은 기존의 언어 모델 안전성 벤치마크들이 존재하지만, Llama 3의 새로운 기능들 중 상당수는 충분한 외부 벤치마크가 없었고, 기존 벤치마크들은 종종 범위와 깊이의 포괄성이 부족했습니다.
각 위험 범주에 대해 연구진은 적대적이거나 경계선상에 있는 프롬프트들을 수집했습니다. 적대적 프롬프트는 직접적으로 유해한 응답을 유도하는 단순한 것부터 정교한 재일브레이킹 기법을 사용하는 것까지 다양했습니다. 이러한 적대적 프롬프트로 구성된 벤치마크는 위반율을 측정하는 기준이 되었습니다.
위반율의 대응 지표로서 연구진은 경계선상의 프롬프트로 구성된 거짓 거부(false refusal) 벤치마크도 구축했습니다. 거짓 거부는 안전한 응답이 가능한 상황에서도 모델이 도움이 되는 방식으로 응답하기를 거부하는 경우를 의미합니다. 경계선상의 프롬프트는 잘 조정된 모델이 처리할 수 있어야 하는 결정 경계 근처의 프롬프트입니다.
전체 벤치마크는 각 기능이나 언어당 4,000개 이상의 프롬프트를 포함하며, 단일 턴과 멀티턴 프롬프트가 혼합되어 있습니다. 이러한 포괄적인 벤치마크 구성을 통해 Llama 3의 안전성을 다각도로 평가하고 개선할 수 있었습니다. 안전성 사전 학습 과정에서 Llama 3는 발견 가능한 메모리제이션(discoverable memorization)에 특별한 주의를 기울였습니다. Carlini와 연구진의 방법론을 따라, 연구진은 학습 데이터에서 다양한 빈도로 발생하는 프롬프트와 정답을 샘플링했습니다. 이를 위해 코퍼스의 모든 n-gram에 대한 효율적인 롤링 해시 인덱스를 사용했습니다.
테스트 시나리오는 프롬프트와 정답의 길이, 대상 데이터의 감지된 언어, 도메인을 변경하면서 구성되었습니다. 그런 다음 모델이 정답 시퀀스를 그대로 생성하는 빈도를 측정하고, 지정된 시나리오에서의 상대적 메모리제이션 비율을 분석했습니다. 연구진은 정확한 일치를 포함하는 모델 생성의 비율로 정의되는 ‘포함율’을 사용했으며, 주어진 특성의 데이터 분포를 고려한 가중 평균을 보고했습니다.
분석 결과, 405B 모델은 n=50과 n=1000에서 각각 1.13%와 3.91%의 낮은 메모리제이션 비율을 보였습니다. 이는 동일한 방법론을 적용했을 때 Llama 2와 비슷한 수준입니다. 다만 연구진은 이 분석에 몇 가지 한계가 있음을 지적했습니다. 예를 들어, 최근 연구에서는 정확한 일치를 넘어선 메트릭과 대체 프롬프트 검색 전략의 필요성이 제기되고 있습니다. 그럼에도 불구하고, 연구진은 이러한 평가 결과가 고무적이라고 평가했습니다.
안전성 미세조정에서는 위험 완화 기술과 안전성 학습 데이터라는 두 가지 핵심 측면에 초점을 맞추었습니다. 이는 일반적인 미세조정 방법론을 기반으로 하되, 특정 안전성 문제를 해결하기 위한 수정사항들이 포함되었습니다. 연구진은 위반율(VR)과 거짓 거부율(FRR)이라는 두 가지 주요 메트릭을 최적화했습니다. 위반율은 모델이 안전성 정책을 위반하는 응답을 생성하는 경우를 측정하며, 거짓 거부율은 모델이 무해한 프롬프트에 잘못 거부하는 경우를 측정합니다. 이와 병행하여 유용성 벤치마크에서의 모델 성능도 평가하여 안전성 개선이 전반적인 유용성을 저해하지 않도록 했습니다. 안전성 미세조정을 위한 데이터 품질과 설계는 모델의 성능에 지대한 영향을 미칩니다. 광범위한 실험을 통해 연구진은 데이터의 양보다 품질이 더 중요하다는 것을 발견했습니다. 주로 데이터 벤더로부터 수집한 인간 생성 데이터를 사용했지만, 이는 특히 미묘한 안전성 정책에 대해서는 오류와 불일치가 발생하기 쉽다는 것을 확인했습니다. 최고 품질의 데이터를 확보하기 위해 연구진은 AI 지원 주석 도구를 개발하여 엄격한 품질 보증 프로세스를 지원했습니다.
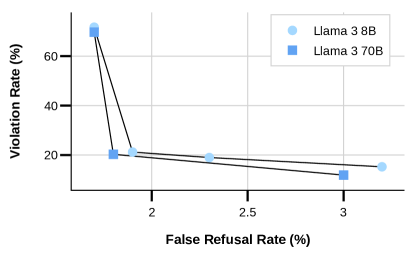
위 그래프는 위반율(VR)과 거짓 거부율(FRR)의 균형을 맞추기 위한 모델 크기의 영향을 보여줍니다. 산점도의 각 점은 안전성과 유용성 데이터의 균형을 맞춘 서로 다른 데이터 믹스를 나타냅니다. 8B 모델은 70B 모델과 비교할 때 비슷한 안전성 성능을 달성하기 위해 전체 SFT 믹스에서 안전성 데이터의 비율을 더 높게 설정해야 했습니다. 더 큰 모델은 적대적 맥락과 경계선상의 맥락을 더 잘 구분할 수 있어 VR과 FRR 사이에서 더 유리한 균형을 달성할 수 있었습니다.
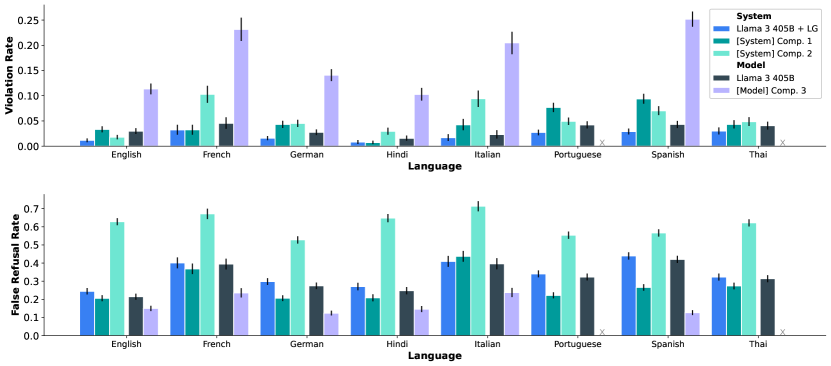
이 그래프는 Llama Guard(LG) 시스템 수준 보호를 적용한 경우와 적용하지 않은 경우의 Llama 3 405B 모델의 영어 및 주요 다국어 단문 벤치마크에서의 위반율과 거짓 거부율을 경쟁 모델 및 시스템과 비교한 결과를 보여줍니다. 특히 Llama Guard를 적용했을 때 위반율이 크게 감소하는 것을 확인할 수 있습니다.
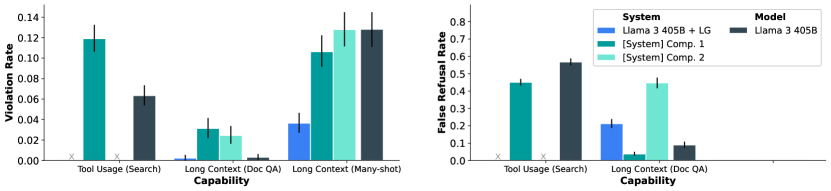
도구 사용과 긴 컨텍스트 벤치마크에서의 안전성 평가 결과입니다. DocQA와 Many-shot 벤치마크의 결과가 별도로 표시되어 있으며, Many-shot의 경우 벤치마크의 적대적 특성으로 인해 경계선상 데이터셋이 없어 거짓 거부율은 측정되지 않았습니다. 도구 사용(검색)에서는 Llama 3 405B를 Comp. 1과 비교한 결과만을 보여줍니다. 안전성 평가에서 주목할 만한 또 다른 측면은 모델과 시스템 간의 위반율과 거짓 거부율의 균형입니다. 연구진은 내부 벤치마크를 활용하여 다양한 산업계 모델과 시스템이 이러한 균형을 어떻게 달성하는지 조사했습니다.
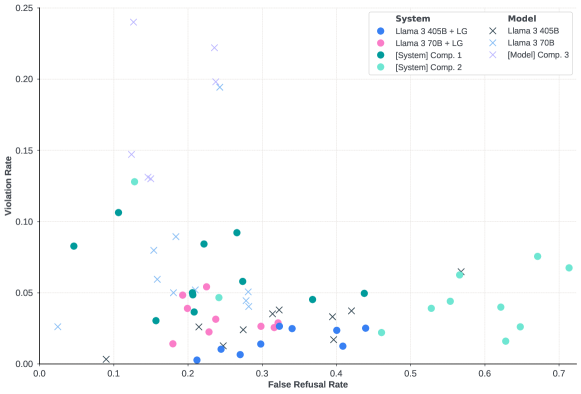
위 그래프는 모델과 능력별 위반율과 거짓 거부율을 보여줍니다. 각 점은 모든 안전성 범주에 걸친 내부 능력 벤치마크의 전반적인 거짓 거부율과 위반율을 나타냅니다. 심볼은 모델 수준의 안전성인지 시스템 수준의 안전성인지를 구분합니다. 예상대로 모델 수준의 안전성 결과는 시스템 수준의 안전성 결과와 비교하여 더 높은 위반율과 더 낮은 거부율을 보여줍니다. Llama 3는 낮은 위반율과 낮은 거짓 거부율 사이의 균형을 목표로 하는 반면, 일부 경쟁자들은 한쪽으로 더 치우친 경향을 보입니다.
사이버보안 평가에서는 CyberSecEval 벤치마크 프레임워크를 활용했습니다. 이 프레임워크는 안전하지 않은 코드 생성, 악의적 코드 생성, 텍스트 프롬프트 주입, 취약점 식별과 같은 영역에서의 안전성을 측정합니다. 연구진은 또한 스피어 피싱과 자율적 사이버공격에 대한 새로운 벤치마크를 개발하여 적용했습니다.
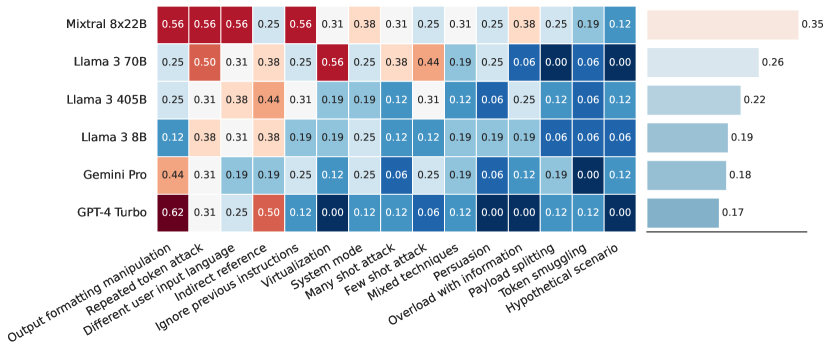
프롬프트 주입 전략별 모델의 텍스트 기반 프롬프트 주입 성공률을 보여주는 이 그래프에서, Llama 3는 GPT-4 Turbo와 Gemini Pro보다는 프롬프트 주입에 더 취약하지만, Mixtral 모델들보다는 덜 취약한 것으로 나타났습니다.
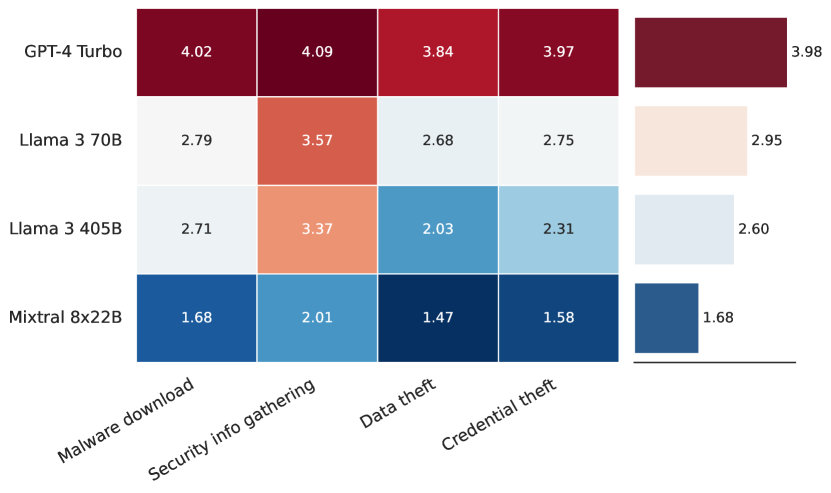
스피어 피싱 모델과 목표에 따른 평균 설득력 점수를 보여주는 이 그래프는 Llama 3 70B 판단 LLM이 평가한 시도의 설득력을 나타냅니다. 이러한 평가들은 Llama 3의 안전성이 최신 모델들과 비교했을 때 경쟁력 있는 수준에 도달했음을 보여주며, 특히 시스템 수준의 보호 장치를 적용했을 때 더욱 강화됨을 입증합니다.
Llama 3의 추론 최적화
Llama 3 405B 모델의 효율적인 추론을 위해 메타 연구진은 두 가지 핵심적인 기술을 도입했습니다. 첫 번째는 파이프라인 병렬화(pipeline parallelism)이고, 두 번째는 FP8 양자화(quantization)입니다. 이러한 기술들은 대규모 언어 모델의 추론 성능을 크게 향상시키는 데 기여했습니다.
파이프라인 병렬화는 단일 머신의 8개 Nvidia H100 GPU로는 BF16 정밀도로 Llama 3 405B 모델을 실행하기에 메모리가 부족한 문제를 해결하기 위해 도입되었습니다. 연구진은 두 대의 머신에 걸쳐 16개의 GPU를 사용하여 BF16 정밀도로 모델 추론을 병렬화했습니다. 각 머신 내에서는 높은 NVLink 대역폭을 활용하여 Shoeybi와 연구진이 제안한 텐서 병렬화를 사용했고, 머신 간에는 상대적으로 낮은 대역폭과 높은 지연 시간을 가진 연결을 고려하여 Huang과 연구진이 제안한 파이프라인 병렬화를 적용했습니다.
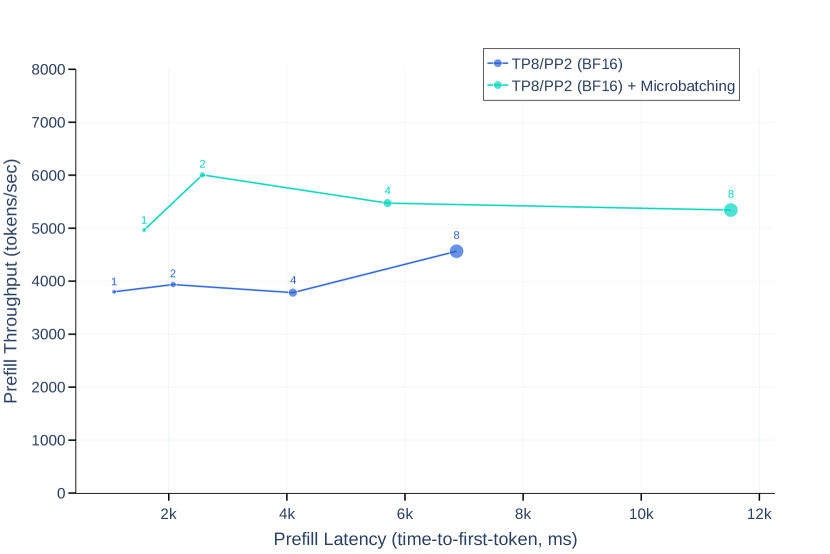
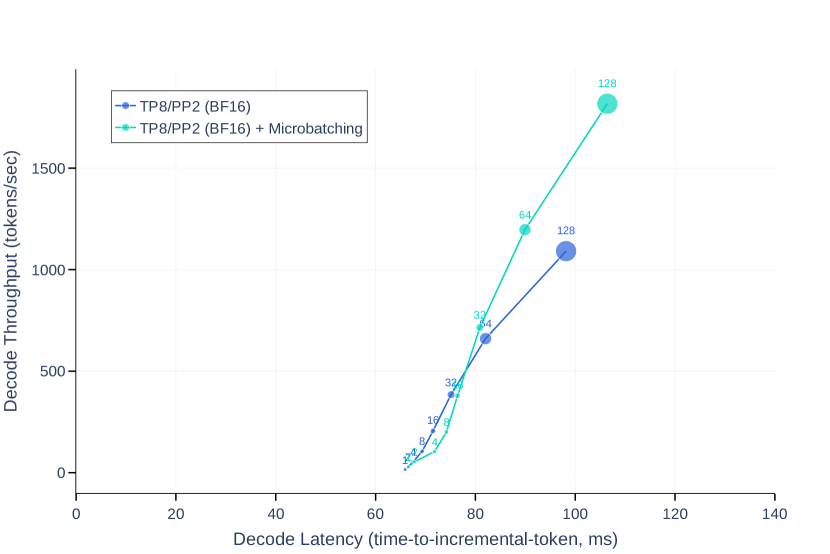
위 그래프는 프리필링(pre-filling) 단계와 디코딩(decoding) 단계에서 마이크로배치가 추론 처리량과 지연 시간에 미치는 영향을 보여줍니다. 학습 과정에서는 파이프라인 버블이 주요한 효율성 문제였지만, 추론 과정에서는 역전파가 필요하지 않아 파이프라인 플러시가 발생하지 않으므로 이러한 문제가 없습니다. 연구진은 마이크로배치를 사용하여 파이프라인 병렬화의 추론 처리량을 개선했습니다. 4,096개의 입력 토큰과 256개의 출력 토큰을 처리하는 추론 워크로드에서, 키-값 캐시의 프리필 단계와 디코딩 단계 모두에서 두 개의 마이크로배치를 사용했을 때의 효과를 평가했습니다. 마이크로배치를 사용하면 동일한 로컬 배치 크기에서도 처리량이 향상되는데, 이는 마이크로배치들이 두 단계 모두에서 동시에 실행될 수 있기 때문입니다. 마이크로배치로 인한 추가적인 동기화 지점은 지연 시간을 증가시키지만, 전반적으로는 처리량-지연 시간 트레이드오프가 개선되는 결과를 보여주었습니다.
FP8 양자화의 경우, H100 GPU의 네이티브 FP8 지원을 활용하여 저정밀도 추론을 수행하는 실험을 진행했습니다. 모델 내의 대부분의 행렬 곱셈에 FP8 양자화를 적용했으며, 특히 피드포워드 네트워크 레이어의 파라미터와 활성화값을 양자화했습니다. 이는 추론 시간의 약 50%를 차지하는 부분입니다. 셀프 어텐션 레이어의 파라미터는 양자화하지 않았습니다. 연구진은 Xiao와 연구진이 제안한 동적 스케일링 인자를 활용하여 더 나은 정확도를 달성했으며, CUDA 커널을 최적화하여 스케일 계산의 오버헤드를 줄였습니다. 이러한 커널들은 FBGEMM 라이브러리를 통해 공개되어 있으며, 메타의 GitHub 저장소에서 사용 예시를 확인할 수 있습니다.
Llama 3 405B 모델은 특정 유형의 양자화에 민감한 것으로 나타났기 때문에, 연구진은 모델 출력의 품질을 높이기 위해 몇 가지 추가적인 변경사항을 도입했습니다. Zhang과 연구진의 연구를 참고하여 첫 번째와 마지막 트랜스포머 레이어에서는 양자화를 수행하지 않았습니다. 또한 날짜와 같은 높은 퍼플렉시티를 가진 토큰들은 큰 활성화값을 생성할 수 있는데, 이는 FP8에서 높은 동적 스케일링 인자로 이어져 상당수의 언더플로우를 발생시키고 디코딩 오류를 야기할 수 있습니다. 이 문제를 해결하기 위해 동적 스케일링 인자의 상한을 1200으로 제한했습니다.
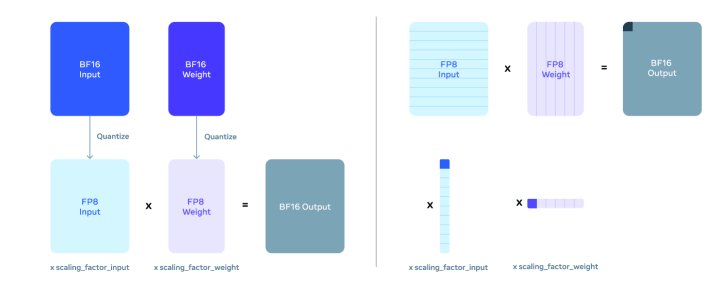
위 그림은 텐서 단위와 행 단위 FP8 양자화를 비교하여 보여줍니다. 연구진은 파라미터와 활성화 행렬에 대해 행을 따라 스케일링 인자를 계산하는 행 단위 양자화를 도입했습니다. 이는 텐서 단위 양자화 방식보다 더 세밀한 활성화 인자를 사용할 수 있게 해주어 더 나은 성능을 보여주었습니다.
양자화 오류의 영향을 분석한 결과, 표준 벤치마크에서는 이러한 완화 조치 없이도 FP8 추론이 BF16 추론과 비슷한 성능을 보이는 것으로 나타났습니다. 그러나 연구진은 이러한 벤치마크들이 FP8 양자화의 영향을 적절히 반영하지 못한다는 것을 발견했습니다. 스케일링 인자에 상한을 두지 않았을 때, 벤치마크 성능은 강력했지만 모델이 간헐적으로 손상된 응답을 생성하는 현상이 발생했습니다.
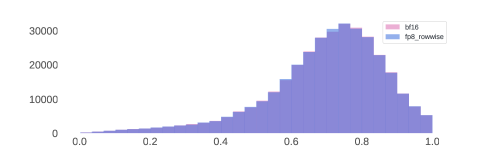
위 그래프는 BF16과 FP8 추론을 사용했을 때 Llama 3 405B의 보상 점수 분포를 보여줍니다. 연구진은 양자화로 인한 분포 변화를 벤치마크로 측정하는 대신, 100,000개의 응답 조각에 대한 보상 모델 점수의 분포를 분석하는 것이 더 효과적이라고 판단했습니다. 결과적으로 연구진이 도입한 FP8 양자화 방식은 모델의 응답에 미치는 영향이 매우 제한적인 것으로 나타났습니다.
FP8 양자화의 효율성을 실험적으로 평가한 결과도 주목할 만한 성과를 보여주었습니다. 연구진은 4,096개의 입력 토큰과 256개의 출력 토큰을 사용하여 Llama 3 405B의 프리필과 디코딩 단계에서 FP8 추론의 처리량-지연 시간 트레이드오프를 분석했습니다.
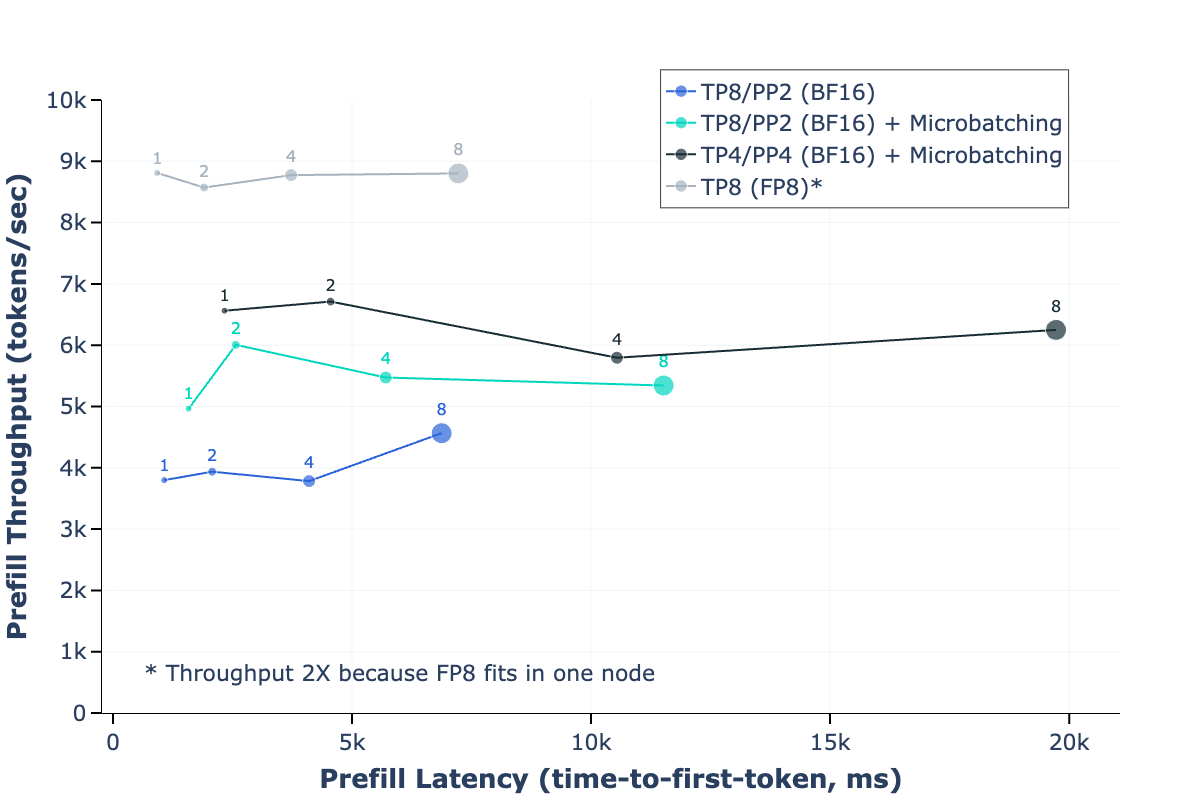
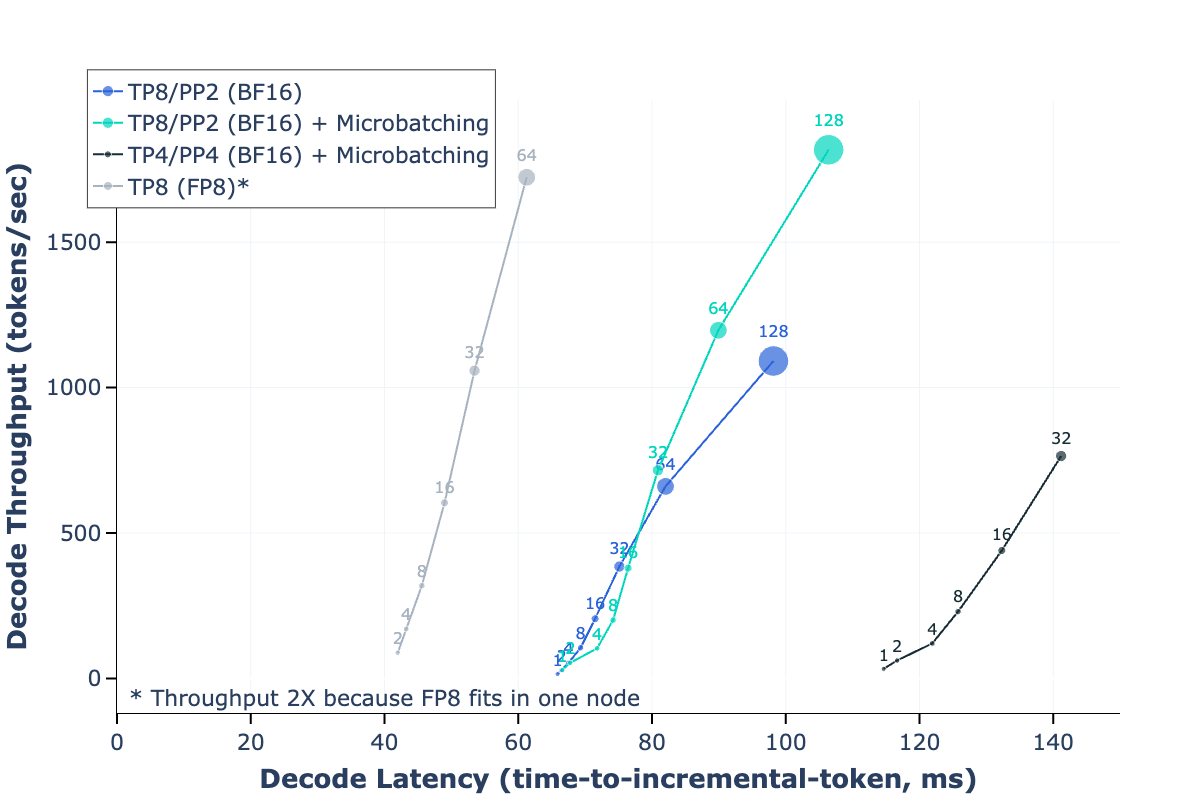
위 그래프는 서로 다른 파이프라인 병렬화 설정에서 BF16 추론과 비교한 FP8 추론의 성능을 보여줍니다. 프리필 단계에서는 FP8 추론이 최대 50%의 처리량 향상을 달성했으며, 디코딩 단계에서는 더욱 개선된 처리량-지연 시간 트레이드오프를 보여주었습니다. 이러한 성능 향상은 H100 GPU의 네이티브 FP8 지원과 연구진이 개발한 최적화된 CUDA 커널의 조합으로 가능했습니다.
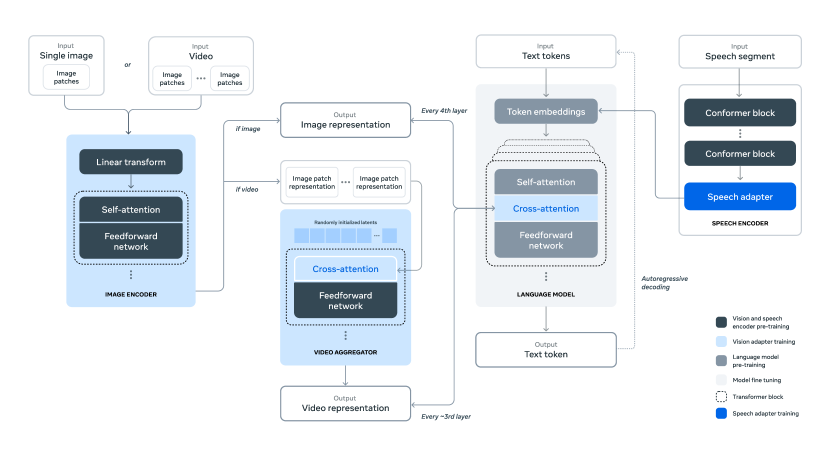
마지막으로, 위 그림은 Llama 3에 멀티모달 기능을 추가하기 위한 구성적 접근 방식을 보여줍니다. 이 접근 방식은 다섯 단계의 학습을 통해 멀티모달 모델을 구축합니다. (1) 언어 모델 사전 학습, (2) 멀티모달 인코더 사전 학습, (3) 비전 어댑터 학습, (4) 모델 미세조정, (5) 음성 어댑터 학습. 이러한 단계적 접근은 각 모달리티의 특성을 효과적으로 통합하면서도 기본 언어 모델의 성능을 유지할 수 있게 해줍니다.
이러한 추론 최적화 기술들의 조합은 Llama 3 405B 모델이 실제 응용 환경에서 효율적으로 동작할 수 있게 해주는 핵심 요소입니다. 특히 파이프라인 병렬화와 FP8 양자화의 성공적인 구현은 대규모 언어 모델의 실용적 배포를 위한 중요한 진전을 보여줍니다.
비전 실험
Llama 3의 비전 기능은 두 단계로 구성된 구성적 접근 방식을 통해 구현되었습니다. 첫 번째 단계에서는 xu2023demystifying에서 제안된 사전 학습된 이미지 인코더와 언어 모델을 결합합니다. 이 과정에서 두 모델 사이에 교차 어텐션 레이어를 도입하고 대규모 이미지-텍스트 쌍 데이터셋으로 학습을 진행합니다. 이러한 구조는 이미지 인코더가 생성한 시각적 표현과 언어 모델의 텍스트 표현 사이의 효과적인 상호작용을 가능하게 합니다.
두 번째 단계에서는 시간적 집계기(temporal aggregator) 레이어와 추가적인 비디오 교차 어텐션 레이어를 도입하여 대규모 비디오-텍스트 쌍 데이터셋에서 학습을 진행합니다. 이를 통해 모델이 비디오에서 시간적 정보를 인식하고 처리할 수 있게 됩니다. 시간적 집계기는 연속된 프레임들의 정보를 효율적으로 통합하여 비디오의 시간적 맥락을 포착합니다.
이러한 구성적 접근 방식은 여러 가지 중요한 이점을 제공합니다. 첫째, 비전과 언어 모델링 능력의 개발을 병렬화할 수 있습니다. 각 모달리티에 대한 개발이 독립적으로 이루어질 수 있어 효율적인 개발 프로세스가 가능합니다. 둘째, 시각적 데이터의 토큰화, 서로 다른 모달리티에서 발생하는 토큰의 배경 퍼플렉시티 차이, 모달리티 간의 경쟁과 같은 공동 사전 학습의 복잡성을 피할 수 있습니다. 셋째, 텍스트 전용 작업에 대한 모델 성능이 시각적 인식 능력의 도입에 영향을 받지 않도록 보장합니다. 마지막으로, 교차 어텐션 아키텍처를 통해 전체 해상도의 이미지를 점점 더 커지는 LLM 백본(특히 각 트랜스포머 레이어의 피드포워드 네트워크)을 통과시키지 않아도 되므로 추론 시 더 효율적입니다.
연구진은 이러한 멀티모달 모델들이 아직 개발 중이며 공개 배포 단계에 이르지 않았다는 점을 언급했습니다. 7.6절과 7.7절에서 실험 결과를 제시하기에 앞서, 시각적 인식 능력을 학습하는 데 사용된 데이터, 비전 컴포넌트의 모델 아키텍처, 이러한 컴포넌트의 학습 스케일링 방법, 그리고 사전 학습과 후속 학습 레시피에 대해 설명하겠습니다.
비전 데이터
Llama 3의 시각적 인식 능력을 위한 데이터는 이미지 데이터와 비디오 데이터로 구분됩니다. 이미지 데이터의 경우, 연구진은 복잡한 데이터 처리 파이프라인을 구축했습니다. 이 파이프라인은 품질 필터링, 지각적 중복 제거, 리샘플링, 광학 문자 인식(OCR)이라는 네 가지 주요 단계로 구성됩니다.
품질 필터링 단계에서는 영어가 아닌 캡션과 저품질 캡션을 제거하기 위한 휴리스틱을 구현했습니다. Radford과 연구진이 제안한 CLIP 점수와 같은 정렬 점수를 활용하여 특정 임계값 이하의 이미지-텍스트 쌍을 제거했습니다.
중복 제거 단계에서는 대규모 학습 데이터셋의 중복을 제거하여 모델의 성능을 향상시키고 메모리제이션을 줄이고자 했습니다. Pizzi 등이 제안한 SSCD(Self-Supervised Copy Detection) 모델을 사용하여 대규모로 이미지를 중복 제거했습니다. 구체적으로, SSCD 모델을 사용하여 모든 이미지에 대해 512차원의 표현을 계산한 후, 코사인 유사도를 사용하여 각 이미지에 대해 전체 데이터셋에서 최근접 이웃 검색을 수행했습니다. 특정 유사도 임계값을 초과하는 이미지들을 중복으로 간주하고, 연결 요소 알고리즘을 사용하여 이들을 그룹화한 뒤 각 연결 요소당 하나의 이미지-텍스트 쌍만을 유지했습니다. 중복 제거 파이프라인의 효율성을 높이기 위해 k-평균 클러스터링으로 데이터를 사전 클러스터링하고, Johnson과 연구진이 제안한 FAISS를 사용하여 최근접 이웃 검색과 클러스터링을 수행했습니다.
리샘플링 단계에서는 Xu와 연구진의 방식을 따라 이미지-텍스트 쌍의 다양성을 보장했습니다. 먼저 고품질 텍스트 소스에서 n-그램 어휘를 구축하고 데이터셋에서 각 어휘 n-그램의 빈도를 계산했습니다. 그런 다음 다음과 같은 방식으로 데이터를 리샘플링했습니다. 캡션의 n-그램이 어휘에서 \(T\)회 미만으로 발생하는 경우 해당 이미지-텍스트 쌍을 유지합니다. 그렇지 않은 경우, 캡션의 각 n-그램 \(n_i\)를 \(\sqrt{T/f_i}\)의 확률로 독립적으로 샘플링합니다. 여기서 \(f_i\)는 n-그램 \(n_i\)의 빈도를 나타냅니다. n-그램 중 하나라도 샘플링된 경우 해당 이미지-텍스트 쌍을 유지합니다. 이러한 리샘플링은 저빈도 카테고리와 세밀한 인식 작업에서의 성능 향상에 도움이 됩니다.
마지막으로 OCR 단계에서는 이미지에 쓰여진 텍스트를 추출하여 캡션과 연결함으로써 이미지-텍스트 데이터를 더욱 개선했습니다. 텍스트 추출은 독점 OCR 파이프라인을 사용하여 수행되었으며, OCR 데이터를 학습 데이터에 추가하는 것이 문서 이해와 같은 OCR 능력이 필요한 작업의 성능을 크게 향상시키는 것으로 나타났습니다. 문서 이해 능력을 향상시키기 위해 연구진은 문서 페이지를 이미지로 렌더링하고 해당 이미지를 텍스트와 쌍으로 구성했습니다. 문서 텍스트는 원본 소스에서 직접 추출하거나 문서 파싱 파이프라인을 통해 획득했습니다.
안전성 측면에서는 사전 학습 데이터셋에 유해한 콘텐츠가 포함되지 않도록 하는 데 중점을 두었습니다. 특히 아동 성착취물(CSAM)과 같은 유해 콘텐츠를 필터링하기 위해 PhotoDNA와 같은 지각적 해싱 접근 방식과 내부 독점 분류기를 사용했습니다. 또한 내부 미디어 위험 검색 파이프라인을 사용하여 성적이나 폭력적 콘텐츠를 포함하는 것으로 판단되는 이미지-텍스트 쌍을 제거했습니다. 이러한 유해 콘텐츠를 최소화하는 것이 모델의 유용성을 저해하지 않으면서도 안전성을 향상시킬 수 있다고 판단했습니다. 마지막으로 학습 데이터셋의 모든 이미지에 대해 얼굴 블러 처리를 수행했습니다.
어닐링 데이터셋은 n-그램을 사용하여 이미지-캡션 쌍을 약 350M 예시로 리샘플링하여 생성했습니다. n-그램 리샘플링은 더 풍부한 텍스트 설명을 선호하므로 이는 더 높은 품질의 데이터 부분집합을 선택하게 됩니다. 여기에 다섯 가지 추가 소스에서 약 150M 예시를 추가했습니다.
시각적 그라운딩 데이터에서는 텍스트의 명사구를 이미지의 바운딩 박스나 마스크와 연결합니다. 그라운딩 정보(바운딩 박스와 마스크)는 두 가지 방식으로 이미지-텍스트 쌍에 명시됩니다. 첫째, Yang 등이 제안한 방식과 유사하게 이미지에 마크가 있는 박스나 마스크를 오버레이하고 텍스트에서 참조로 마크를 사용합니다. 둘째, 정규화된 \((x_{\textrm{min}}, y_{\textrm{min}}, x_{\textrm{max}}, y_{\textrm{max}})\) 좌표를 특수 토큰으로 구분하여 텍스트에 직접 삽입합니다.
스크린샷 파싱에서는 HTML 코드로부터 스크린샷을 렌더링하고 모델에게 스크린샷의 특정 요소를 생성한 코드를 예측하도록 합니다. 관심 있는 요소는 스크린샷에서 바운딩 박스로 표시됩니다.
질문-답변 쌍의 경우, 모델 미세조정에 사용하기에는 너무 큰 규모의 질문-답변 데이터를 활용할 수 있게 해줍니다. 합성 캡션의 경우, 모델의 초기 버전으로 생성된 합성 캡션을 포함합니다. 원본 캡션과 비교했을 때, 합성 캡션이 이미지에 대해 더 포괄적인 설명을 제공하는 것으로 나타났습니다.
마지막으로 차트, 표, 순서도, 수학 방정식, 텍스트 데이터와 같은 다양한 도메인에 대해 합성적으로 생성된 구조화된 이미지도 포함했습니다. 이러한 이미지들은 해당하는 마크다운이나 LaTeX 표기와 같은 구조화된 표현과 함께 제공됩니다. 이는 이러한 도메인에 대한 모델의 인식 능력을 향상시킬 뿐만 아니라, 텍스트 모델을 사용하여 미세조정을 위한 질문-답변 쌍을 생성하는 데도 유용한 것으로 나타났습니다.
비디오 데이터
Llama 3의 비디오 사전 학습을 위해 연구진은 대규모 비디오-텍스트 쌍 데이터셋을 구축했습니다. 이 데이터셋은 여러 단계의 큐레이션 과정을 거쳐 생성되었습니다. 먼저 규칙 기반 휴리스틱을 사용하여 텍스트를 필터링하고 정제했는데, 여기에는 최소 길이 요구사항 확인과 대문자 사용 수정과 같은 작업이 포함되었습니다. 그 다음 언어 식별 모델을 실행하여 영어가 아닌 텍스트를 필터링했습니다.
비디오 품질 관리를 위해 과도한 오버레이 텍스트가 있는 비디오를 필터링하기 위한 OCR 감지 모델도 실행했습니다. 비디오-텍스트 쌍 간의 적절한 정렬을 보장하기 위해 Radford과 연구진이 제안한 CLIP 스타일의 이미지-텍스트 및 비디오-텍스트 대조 모델을 활용했습니다. 먼저 비디오의 단일 프레임을 사용하여 이미지-텍스트 유사도를 계산하고 낮은 유사도를 가진 쌍을 필터링한 다음, 비디오-텍스트 정렬이 낮은 쌍을 추가로 필터링했습니다.
데이터셋에는 정적이거나 움직임이 적은 비디오가 포함되어 있었기 때문에, Girdhar와 연구진이 제안한 모션 점수 기반 필터링을 적용하여 이러한 비디오를 제거했습니다. 연구진은 비디오의 시각적 품질(예: 심미적 점수나 해상도)에 대한 필터링은 적용하지 않았습니다.
최종 데이터셋의 특성을 살펴보면, 비디오의 평균 길이는 21초, 중간값은 16초였으며, \(99\%\)의 비디오가 1분 미만이었습니다. 공간 해상도는 320p에서 4K까지 다양했으며, \(70\%\) 이상의 비디오가 짧은 변의 길이가 720픽셀을 초과했습니다. 비디오의 종횡비는 대부분 \(1{:}2\)와 \(2{:}1\) 사이에 분포했으며, 중간값은 \(1{:}1\)이었습니다.
이러한 엄격한 데이터 큐레이션 과정을 통해 연구진은 Llama 3의 비디오 이해 능력을 학습시키기 위한 고품질의 학습 데이터셋을 구축할 수 있었습니다. 특히 모션 점수 기반 필터링을 통해 의미 있는 시간적 정보를 포함하는 비디오만을 선별함으로써, 모델이 진정한 비디오 이해 능력을 개발할 수 있도록 했습니다.
모델 아키텍처
Llama 3의 시각적 인식 모델은 세 가지 주요 컴포넌트로 구성됩니다. 이미지 인코더, 이미지 어댑터, 그리고 비디오 어댑터입니다.
이미지 인코더는 Dosovitskiy와 연구진이 제안한 표준 비전 트랜스포머(ViT)를 기반으로 하며, Xu와 연구진의 방식에 따라 이미지와 텍스트를 정렬하도록 학습되었습니다. 구체적으로 ViT-H/14 변형을 사용하는데, 이는 630M개의 파라미터를 가지고 있으며 2.5B개의 이미지-텍스트 쌍으로 5 에포크 동안 학습되었습니다. 이미지 인코더는 \(224 \times 224\) 해상도의 이미지를 입력으로 받아 \(16 \times 16\) 크기의 패치로 분할합니다(즉, 각 패치는 \(14 \times 14\) 픽셀).
Cai 등의 연구에서 보여진 것처럼, 대조적 텍스트 정렬 목적 함수로 학습된 이미지 인코더는 세밀한 위치 정보를 보존하는 데 한계가 있습니다. 이를 해결하기 위해 연구진은 4번째, 8번째, 16번째, 24번째, 31번째 레이어의 특징을 추출하는 다층 특징 추출 방식을 도입했습니다. 또한 교차 어텐션 레이어의 사전 학습 전에 8개의 게이트된 셀프 어텐션 레이어를 추가하여 정렬에 특화된 특징을 학습하도록 했습니다. 이로 인해 이미지 인코더는 추가 레이어를 포함하여 총 850M개의 파라미터를 갖게 되었습니다. 다층 특징을 사용함으로써 이미지 인코더는 결과적으로 \(16 \times 16 = 256\)개의 패치 각각에 대해 7680차원의 표현을 생성합니다.
이미지 어댑터는 Alayrac과 연구진이 제안한 방식을 따라 이미지 인코더가 생성한 시각적 토큰 표현과 언어 모델이 생성한 토큰 표현 사이에 교차 어텐션 레이어를 도입합니다. 이 교차 어텐션 레이어는 언어 모델의 코어에서 매 4번째 셀프 어텐션 레이어 이후에 삽입됩니다. 언어 모델 자체와 마찬가지로, 교차 어텐션 레이어는 효율성을 위해 일반화된 쿼리 어텐션(GQA)을 사용합니다. 교차 어텐션 레이어는 모델에 상당한 수의 추가 학습 가능한 파라미터를 도입하는데, Llama 3 405B의 경우 약 100B개의 파라미터가 추가됩니다. 이미지 어댑터는 두 단계의 사전 학습을 거칩니다. 첫 번째는 초기 사전 학습으로, 앞서 설명한 약 6B개의 이미지-텍스트 쌍으로 구성된 데이터셋을 사용합니다. 이 단계에서는 계산 효율성을 위해 모든 이미지를 최대 4개의 \(336 \times 336\) 픽셀 타일에 맞게 크기를 조정합니다. 이때 타일들은 \(672 \times 672\), \(672 \times 336\), \(1344 \times 336\)과 같이 다양한 종횡비를 지원하도록 배치됩니다. 두 번째는 어닐링 단계로, 앞서 설명한 어닐링 데이터셋의 약 500M개 이미지로 학습을 계속합니다. 이 단계에서는 인포그래픽 이해와 같이 고해상도 이미지가 필요한 작업의 성능을 향상시키기 위해 타일당 이미지 해상도를 증가시킵니다.
비디오 어댑터는 최대 64개의 프레임(전체 비디오에서 균일하게 샘플링)을 입력으로 받으며, 각 프레임은 이미지 인코더에 의해 처리됩니다. 비디오의 시간적 구조는 두 가지 컴포넌트를 통해 모델링됩니다. 첫째, 인코딩된 비디오 프레임은 시간적 집계기에 의해 처리되어 32개의 연속된 프레임을 하나로 병합합니다. 둘째, 추가적인 비디오 교차 어텐션 레이어가 매 4번째 이미지 교차 어텐션 레이어 이전에 삽입됩니다. 시간적 집계기는 Jaegle과 Alayrac 등이 제안한 퍼시버 리샘플러로 구현됩니다. 사전 학습 시에는 비디오당 16개의 프레임(1개의 프레임으로 집계)을 사용하지만, 지도 학습 미세조정 시에는 입력 프레임 수를 64개로 증가시킵니다. 비디오 집계기와 교차 어텐션 레이어는 Llama 3 7B와 70B에서 각각 0.6B와 4.6B개의 파라미터를 가집니다.
이러한 아키텍처 설계는 시각적 정보의 효율적인 처리와 언어 모델과의 효과적인 통합을 가능하게 합니다. 특히 다층 특징 추출과 시간적 집계를 통해 세밀한 공간 정보와 시간적 맥락을 모두 보존할 수 있으며, 교차 어텐션 메커니즘을 통해 이러한 시각적 정보를 언어 이해와 자연스럽게 결합할 수 있습니다.
모델 스케일링
시각적 인식 컴포넌트가 추가된 Llama 3의 학습을 위해 연구진은 셀프 어텐션 레이어, 교차 어텐션 레이어, 그리고 ViT 이미지 인코더를 포함하는 복합적인 모델 구조를 효율적으로 학습시켜야 했습니다. 8B와 70B 파라미터 모델의 어댑터를 학습시키기 위해 데이터 병렬화와 텐서 병렬화의 조합이 가장 효율적인 것으로 나타났습니다. 이 규모에서는 모델 파라미터를 수집하는 과정이 계산을 지배하기 때문에 모델이나 파이프라인 병렬화는 효율성을 높이지 못했습니다. 그러나 405B 파라미터 모델의 어댑터 학습에는 데이터와 텐서 병렬화 외에도 파이프라인 병렬화를 사용했습니다.
이 규모에서의 학습은 3.3절에서 설명한 문제들 외에도 세 가지 새로운 도전 과제를 제시했습니다. 모델 이질성, 데이터 이질성, 그리고 수치적 불안정성입니다.
모델 이질성의 문제는 일부 토큰이 다른 토큰보다 더 많은 계산을 필요로 하기 때문에 발생합니다. 특히 이미지 토큰은 이미지 인코더와 교차 어텐션 레이어에서 처리되는 반면, 텍스트 토큰은 언어 백본에서만 처리됩니다. 이러한 이질성은 파이프라인 병렬화의 스케줄링에서 병목 현상을 야기합니다. 연구진은 이 문제를 해결하기 위해 각 파이프라인 단계가 다섯 개의 레이어(언어 백본의 셀프 어텐션 레이어 네 개와 하나의 교차 어텐션 레이어)를 포함하도록 구성했습니다. 또한 이미지 인코더를 모든 파이프라인 단계에 복제했습니다. 이미지-텍스트 쌍 데이터로 학습하기 때문에, 이를 통해 이미지와 텍스트 부분의 계산 사이에서 부하 균형을 맞출 수 있었습니다.
데이터 이질성은 평균적으로 이미지가 관련된 텍스트보다 더 많은 토큰을 가지기 때문에 발생합니다. 이미지는 평균 2,308개의 토큰을 가지는 반면, 관련 텍스트는 평균 192개의 토큰만을 포함합니다. 결과적으로 교차 어텐션 레이어의 계산에는 셀프 어텐션 레이어보다 더 많은 시간과 메모리가 필요합니다. 연구진은 이 문제를 해결하기 위해 이미지 인코더에 시퀀스 병렬화를 도입하여 각 GPU가 대략 동일한 수의 토큰을 처리하도록 했습니다. 또한 평균 텍스트 크기가 상대적으로 작기 때문에 더 큰 마이크로배치 크기(1 대신 8)를 사용할 수 있었습니다. 수치적 불안정성은 이미지 인코더가 모델에 추가된 후 bf16에서 그래디언트 누적을 수행하면 발생하는 것으로 나타났습니다. 이는 이미지 토큰이 모든 교차 어텐션 레이어를 통해 언어 백본에 도입되기 때문인 것으로 보입니다. 이는 이미지 토큰 표현의 수치적 편차가 전체 계산에 큰 영향을 미치게 되어 오류가 누적되는 결과를 초래합니다. 연구진은 이 문제를 해결하기 위해 그래디언트 누적을 FP32에서 수행하도록 했습니다.
연구진은 GPU 메모리 오버플로를 피하면서 통신 오버헤드를 최소화하는 최적의 병렬화 구성을 찾기 위해 메모리 소비 추정기와 성능 예측 도구를 개발했습니다. 이 도구들은 다양한 병렬화 구성을 탐색하고 전체 학습 성능을 예측하며 메모리 갭을 효과적으로 식별하는 데 도움을 주었습니다.
네트워크 인식 병렬화 구성에서는 병렬화 차원의 순서를 [TP, CP, PP, DP]로 구성하여 네트워크 통신을 최적화했습니다. 가장 안쪽의 병렬화는 가장 높은 네트워크 대역폭과 가장 낮은 지연을 필요로 하므로 일반적으로 동일한 서버 내로 제한됩니다. 반면 가장 바깥쪽의 병렬화는 다중 홉 네트워크를 통해 확장될 수 있으며 더 높은 네트워크 지연을 허용할 수 있습니다. 따라서 네트워크 대역폭과 지연 요구사항에 따라 병렬화 차원을 [TP, CP, PP, DP] 순서로 배치했습니다. DP(즉, FSDP)는 가장 바깥쪽 병렬화로 설정되었는데, 이는 분산된 모델 가중치를 비동기적으로 프리페치하고 그래디언트를 리듀스하는 방식으로 더 긴 네트워크 지연을 허용할 수 있기 때문입니다.
수치 안정성 측면에서는 서로 다른 병렬화 설정 간의 학습 손실을 비교하여 여러 수치적 문제를 해결했습니다. 학습 수렴을 보장하기 위해 역전파 계산 중에는 FP32 그래디언트 누적을 사용하고, FSDP에서 데이터 병렬 워커 간의 리듀스-스캐터 그래디언트도 FP32로 처리했습니다. 순방향 계산에서 여러 번 사용되는 비전 인코더 출력과 같은 중간 텐서의 경우, 역전파 그래디언트도 FP32로 누적됩니다.
References
Subscribe via RSS