Gemma 2: Improving Open Language Models at a Practical Size
by Google
TL;DR
이 연구를 시작하게 된 배경과 동기는 무엇입니까?
대규모 언어 모델(Large Language Models, LLMs)의 발전은 인공지능 분야에서 혁명적인 변화를 가져왔습니다. 그러나 기존의 대규모 모델들은 대부분 접근성이 제한적이고, 계산 비용이 매우 높으며, 소수의 대기업에 의해 독점되어 왔습니다. 이러한 상황은 AI 기술의 민주화와 광범위한 혁신을 저해하는 주요 장애물로 작용해 왔습니다.
특히 소규모 언어 모델의 성능 개선은 중요한 연구 과제였습니다. 기존의 접근법은 주로 학습 시간을 늘리는 방식에 의존했는데, 이는 로그 스케일로만 성능을 향상시키기 때문에 비효율적이었습니다. 연구팀은 단순히 학습 시간을 늘리는 대신, 모델의 학습 방식과 아키텍처를 근본적으로 혁신함으로써 소규모 모델의 성능을 획기적으로 개선할 수 있다고 믿었습니다.
이 연구에서 제시하는 새로운 해결 방법은 무엇입니까?
Gemma 2 연구팀은 지식 증류(Knowledge Distillation) 기법을 핵심 혁신으로 제시했습니다. 이 방법은 대형 모델의 지식을 더 작은 모델로 전달하는 기술로, 기존의 단순한 다음 토큰 예측 방식을 넘어서는 학습 접근법입니다. 구체적으로, 각 토큰에서 원-핫 벡터 대신 대형 모델에서 계산된 다음 토큰의 확률 분포를 학습하는 방식을 채택했습니다.
또한 연구팀은 로컬-글로벌 어텐션 인터리빙과 그룹 쿼리 어텐션(GQA) 같은 혁신적인 아키텍처 기법을 도입했습니다. 로컬-글로벌 어텐션은 모델이 로컬 컨텍스트와 글로벌 컨텍스트를 모두 효과적으로 처리할 수 있게 하며, GQA는 어텐션 메커니즘의 계산 효율성을 크게 개선합니다. 이러한 기술적 혁신들은 소규모 모델이 더 큰 모델의 성능에 근접할 수 있게 해주는 핵심 메커니즘입니다.
제안된 방법은 어떻게 구현되었습니까?
Gemma 2 모델은 2B, 9B, 27B 크기의 세 가지 모델로 구현되었으며, 각 모델은 지식 증류 방법론을 통해 학습되었습니다. 특히 2B와 9B 모델은 27B 모델을 교사 모델로 사용하여 학습되었으며, 이론적으로 예측된 계산 최적 토큰 수보다 50배 이상의 토큰으로 학습되었습니다. 이는 기존의 학습 방식을 근본적으로 혁신하는 접근법입니다.
모델 아키텍처 측면에서는 로컬 슬라이딩 윈도우 어텐션(크기 4096 토큰)과 글로벌 어텐션(크기 8192 토큰)을 교차 사용하는 방식을 채택했습니다. 또한 RMSNorm을 사용한 정규화, 로짓 소프트 캐핑 기법 등 다양한 기술적 최적화를 적용했습니다. 이러한 세부적인 설계 선택들이 모델의 전반적인 성능 향상에 기여했습니다.
이 연구의 결과가 가지는 의미는 무엇입니까?
Gemma 2 모델은 오픈 소스 언어 모델 분야에서 중요한 이정표를 마련했습니다. LMSYS 챗봇 아레나에서 Gemma 27B 모델은 Llama 3 70B보다 높은 Elo 점수를 기록했으며, 9B 모델은 GPT-4-0314와 비슷한 수준의 성능을 보였습니다. 이는 소규모 모델도 적절한 학습 방법론과 아키텍처 혁신을 통해 대규모 모델에 필적할 수 있음을 보여주는 중요한 증거입니다.
더불어 이 연구는 AI 기술의 민주화와 접근성 향상에 기여할 수 있는 잠재력을 보여줍니다. 오픈 소스로 공개된 Gemma 2 모델은 연구자와 개발자들이 첨단 AI 기술을 더 쉽게 활용하고 혁신할 수 있는 기회를 제공합니다. 특히 메모리제이션과 개인정보 보호 측면에서도 뛰어난 성능을 보여, 책임감 있는 AI 개발의 새로운 기준을 제시했습니다.
Gemma 2: 실용적인 크기의 오픈 언어 모델 개선
소개
이 논문에서는 Gemma 모델 계열의 새로운 버전인 Gemma 2를 소개합니다. Gemma 2는 2억(2B)부터 270억(27B) 매개변수에 이르는 경량화된 최첨단 오픈 모델 시리즈입니다. 이 새로운 버전에서는 트랜스포머 아키텍처에 몇 가지 기술적 수정을 적용했습니다. 특히 로컬-글로벌 어텐션 인터리빙(interleaving local-global attentions)과 그룹 쿼리 어텐션(group-query attention)을 도입했습니다.
로컬-글로벌 어텐션 인터리빙은 Beltagy와 연구진이 제안한 기법으로, 모델이 로컬 컨텍스트와 글로벌 컨텍스트를 모두 효과적으로 처리할 수 있게 합니다. 그룹 쿼리 어텐션은 Ainslie와 연구진이 개발한 방식으로, 어텐션 메커니즘의 효율성을 개선합니다. 또한 2B와 9B 모델은 다음 토큰 예측(next token prediction) 대신 지식 증류(knowledge distillation) 방식으로 학습되었습니다. Hinton과 연구진이 소개한 지식 증류는 큰 모델의 지식을 작은 모델로 전달하는 학습 방법입니다.
이러한 기술적 개선을 통해 Gemma 2 모델은 동일한 크기의 모델 중에서 최고의 성능을 제공하며, 심지어 2-3배 더 큰 모델과도 경쟁할 수 있는 수준에 도달했습니다. 연구팀은 이 모든 모델을 커뮤니티에 공개했습니다.
대규모 언어 모델의 발전
대규모 언어 모델(Large Language Models, LLMs)은 언어 이해, 생성 및 추론 능력에서 강력한 성능을 보여주고 있습니다(Radford와 연구진, Raffel과 연구진, Brown과 연구진). 최근의 발전에서 모델 규모 확장이 핵심적인 역할을 했으며, 많은 새로운 능력들이 대규모 모델에서만 나타나고 있습니다(Brown과 연구진). 최신 대형 모델들은 추론 벤치마크에서 전례 없는 성능을 달성했을 뿐만 아니라(Achiam과 연구진), 다중 모달 및 다국어 능력을 보여주고 있으며(Gemini Team), 심지어 100만 토큰 이상의 컨텍스트 길이를 처리할 수 있는 능력도 갖추고 있습니다(Gemini Team).
소규모 모델들도 성능이 빠르게 향상되고 있지만, 이러한 개선은 주로 학습 기간을 늘리는 방식에 의존하고 있습니다(Touvron과 연구진, Jiang과 연구진, Gemma Team). 이 접근법은 데이터셋 크기에 따라 로그 스케일로만 확장되기 때문에(Hoffmann과 연구진), 최신 소형 모델들은 최첨단 성능을 1-2% 미만으로 개선하기 위해 최대 15조 토큰까지 학습해야 합니다(Meta AI). 그럼에도 불구하고, 이러한 지속적인 개선은 소형 모델들이 여전히 충분히 학습되지 않았다는 증거를 제공합니다.
소형 모델 성능 개선을 위한 접근법
이 연구에서는 단순히 학습 기간을 늘리는 것 외에도 소형 모델의 성능을 개선할 수 있는 대안을 탐색합니다. 한 가지 해결책은 다음 토큰 예측 작업을 더 풍부한 목표로 대체하여 네트워크가 각 학습 단계에서 받는 정보의 품질을 개선하는 것입니다. 특히, 연구팀은 지식 증류(Hinton과 연구진)에 초점을 맞추었습니다. 이 방법은 각 토큰에서 보이는 원-핫 벡터(one-hot vector)를 대형 모델에서 계산된 다음 토큰의 잠재적 분포로 대체합니다. 이 접근법은 일반적으로 더 풍부한 그래디언트를 제공함으로써 소형 모델의 학습 시간을 줄이는 데 사용됩니다.
이 연구에서는 대신 증류를 통해 대량의 토큰으로 학습하여 사용 가능한 토큰 수를 넘어서는 학습을 시뮬레이션합니다. 구체적으로, 대형 언어 모델을 교사로 사용하여 2B와 9B 모델을 학습시키는데, 이론적으로 예측된 계산 최적 수량(Hoffmann과 연구진)보다 50배 이상의 토큰 양으로 학습합니다. 증류를 통해 학습된 모델과 함께, 연구팀은 이 작업을 위해 처음부터 학습된 27B 모델도 공개합니다.
또한 연구팀은 트랜스포머의 몇 가지 알려진 수정 사항을 활용했습니다. 특히 Beltagy와 연구진이 제안한 글로벌 및 로컬 어텐션 레이어의 인터리빙과 Ainslie와 연구진이 개발한 그룹 쿼리 어텐션(GQA) 메커니즘을 적용했습니다.
전반적으로, Gemma 2는 비슷한 규모의 오픈 모델과 비교하여 최첨단 성능을 크게 향상시켰으며, 심지어 자신보다 두 배 이상 큰 일부 모델(xAI, AI@Meta, Jiang과 연구진, Almazrouei와 연구진)과도 경쟁할 수 있는 수준입니다. 이는 질문 응답(Clark과 연구진, Kwiatkowski와 연구진), 상식 추론(Sakaguchi와 연구진, Suzgun과 연구진), 수학 및 과학(Cobbe와 연구진, Hendrycks와 연구진), 코딩(Austin과 연구진, Chen과 연구진) 등 다양한 자동화된 벤치마크와 인간 평가에서 확인되었습니다.
Gemma 2 모델에 대한 철저한 테스트가 수행되었지만, 이러한 테스트는 Gemma 2가 사용될 수 있는 모든 애플리케이션과 시나리오를 포괄할 수 없습니다. 이를 고려하여, 모든 Gemma 2 사용자는 배포나 사용 전에 자신의 사용 사례에 맞는 엄격한 안전성 테스트를 수행해야 합니다.
이 기술 보고서에서는 Gemma 2의 아키텍처, 학습, 사전 및 사후 학습 레시피를 포함한 모델에 대한 개요를 제공합니다. 또한 다양한 정량적 및 정성적 벤치마크, 표준 학술 벤치마크 및 인간 선호도 평가에 걸친 상세한 평가를 제공합니다. 마지막으로, 안전하고 책임감 있는 배포에 대한 접근 방식과 Gemma 2의 더 넓은 의미, 한계 및 장점에 대해 논의합니다.
모델 매개변수 및 설계 선택
아래 표는 Gemma 2 모델의 주요 매개변수와 설계 선택에 대한 개요를 제공합니다.
| 매개변수 | 2B | 9B | 27B |
|---|---|---|---|
| d_model | 2304 | 3584 | 4608 |
| 레이어 | 26 | 42 | 46 |
| Pre-norm | 예 | 예 | 예 |
| Post-norm | 예 | 예 | 예 |
| 비선형성 | GeGLU | GeGLU | GeGLU |
| 피드포워드 차원 | 1843 | 2286 | 7273728 |
| 헤드 타입 | GQA | GQA | GQA |
| 헤드 수 | 8 | 16 | 32 |
| KV 헤드 수 | 4 | 8 | 16 |
| 헤드 크기 | 256 | 256 | 128 |
| 글로벌 어텐션 스팬 | 8192 | 8192 | 8192 |
| 슬라이딩 윈도우 | 4096 | 4096 | 4096 |
| 어휘 크기 | 256128 | 256128 | 256128 |
| 임베딩 공유 | 예 | 예 | 예 |
이 표는 모델 아키텍처에 대한 자세한 내용을 제공하며, 모델 아키텍처 섹션에서 더 자세히 설명됩니다.
모델 아키텍처
Gemma 2 모델은 이전 Gemma 모델(Gemma Team, 2024)과 유사하게 디코더 전용 트랜스포머 아키텍처(Vaswani와 연구진, 2017)를 기반으로 합니다. 표 1에서는 주요 매개변수와 아키텍처 선택 사항을 요약하고 있습니다. 몇 가지 아키텍처 요소는 첫 번째 버전의 Gemma 모델과 유사합니다. 구체적으로 8192 토큰의 컨텍스트 길이, 회전 위치 임베딩(RoPE, Rotary Position Embeddings)(Su와 연구진, 2021)의 사용, 그리고 근사 GeGLU 비선형성(Shazeer, 2020)이 이에 해당합니다. Gemma 1과 Gemma 2 사이에는 더 깊은 네트워크를 사용하는 것을 포함하여 몇 가지 요소가 다릅니다. 주요 차이점은 다음과 같습니다.
로컬 슬라이딩 윈도우와 글로벌 어텐션
Gemma 2는 모든 레이어에서 로컬 슬라이딩 윈도우 어텐션(Beltagy와 연구진, 2020b, a)과 글로벌 어텐션(Luong과 연구진, 2015)을 번갈아 사용합니다. 로컬 어텐션 레이어의 슬라이딩 윈도우 크기는 4096 토큰으로 설정되어 있으며, 글로벌 어텐션 레이어의 범위는 8192 토큰으로 설정되어 있습니다.
이러한 접근 방식은 Longformer(Beltagy와 연구진, 2020)에서 제안된 방식을 기반으로 합니다. 로컬 슬라이딩 윈도우 어텐션은 각 토큰이 자신을 중심으로 한 고정 크기의 윈도우 내의 토큰들에만 주의를 기울이도록 하여, 표준 셀프 어텐션의 이차 복잡성을 선형 복잡성으로 줄입니다. 반면 글로벌 어텐션은 모든 토큰이 서로에게 주의를 기울일 수 있게 하여 장거리 의존성을 포착할 수 있게 합니다. 이 두 가지 어텐션 메커니즘을 번갈아 사용함으로써, Gemma 2는 계산 효율성과 장거리 의존성 포착 능력 사이의 균형을 맞추고 있습니다.
로짓 소프트 캐핑
Gemma 2는 각 어텐션 레이어와 최종 레이어에서 로짓(Bello와 연구진, 2016)을 캡핑하여 로짓 값이 $-\text{soft cap}$과 $+\text{soft_cap}$ 사이에 유지되도록 합니다. 구체적으로, 다음 함수를 사용하여 로짓을 캡핑합니다.
\[\text{logits} \leftarrow \text{soft cap} \cdot \tanh(\text{logits}/\text{soft cap})\]여기서 셀프 어텐션 레이어의 soft_cap 매개변수는 $50.0$으로 설정되고, 최종 레이어의 경우 $30.0$으로 설정됩니다.
로짓 소프트 캐핑은 로짓 값이 너무 크거나 작아지는 것을 방지하여 수치적 안정성을 개선하고 소프트맥스 연산 중 오버플로우나 언더플로우를 방지하는 데 도움이 됩니다. 이는 특히 깊은 네트워크에서 중요한데, 로짓 값이 극단적으로 커지면 소프트맥스 함수가 수치적으로 불안정해질 수 있기 때문입니다.
표 2: Gemma 모델의 매개변수 수
| 모델 | 임베딩 매개변수 | 비임베딩 매개변수 |
|---|---|---|
| 2B | 590,118,912 | 2,024,517,888 |
| 9B | 917,962,752 | 8,324,201,984 |
| 27B | 1,180,237,824 | 26,047,480,320 |
Gemma 모델은 다수의 언어에서 작동하도록 설계된 대규모 Gemini 어휘(256k 항목)를 상속받았습니다. 따라서 하나 또는 소수의 언어로 제한된 모델에 비해 임베딩 매개변수 수가 더 많습니다.
포스트-놈과 RMSNorm을 사용한 프리-놈
학습 안정성을 위해 Gemma 2는 RMSNorm(Zhang과 Sennrich, 2019)을 사용하여 각 트랜스포머 서브 레이어, 어텐션 레이어, 피드포워드 레이어의 입력과 출력을 정규화합니다.
RMSNorm은 레이어 정규화(LayerNorm)의 계산적으로 더 효율적인 변형으로, 평균과 분산 통계 대신 제곱 평균 제곱근(RMS) 통계를 사용하여 뉴런에 대한 합산된 입력을 정규화합니다. 수학적으로 RMSNorm은 다음과 같이 정의됩니다.
\[\bar{a}_i = \frac{a_i}{\text{RMS}(\mathbf{a})}g_i, \quad \text{where} \quad \text{RMS}(\mathbf{a}) = \sqrt{\frac{1}{n}\sum_{i=1}^{n}a_i^{2}}\]여기서 $\mathbf{a}$는 원시 합산 입력, $\bar{a}_i$는 정규화된 활성화, $\mathbf{g}$는 게인 매개변수입니다.
RMSNorm은 평균 정규화 단계를 제거하여 LayerNorm보다 계산적으로 더 단순합니다. 또한 RMSNorm은 입력 $\mathbf{x}$와 가중치 행렬 $\mathbf{W}$의 재스케일링에 불변하는 특성을 가지고 있어, 레이어 활성화의 크기와 모델 그래디언트를 안정화하는 데 도움이 됩니다.
그룹 쿼리 어텐션(Grouped-Query Attention)
Gemma 2는 Ainslie와 연구진(2023)이 제안한 그룹 쿼리 어텐션(GQA)을 사용하며, $\text{num_groups} = 2$로 설정합니다. 이는 다운스트림 성능을 유지하면서 추론 시간의 속도를 높이는 것을 보여주는 실험 결과에 기반합니다.
GQA는 다중 쿼리 어텐션(MQA)의 일반화로, 중간 수의 키-값 헤드를 사용합니다. 구체적으로, 쿼리 헤드는 $G$개의 그룹으로 나뉘며, 각 그룹은 공유된 키와 값 헤드를 가집니다. 이는 메모리 효율적인 MQA($G=1$)와 더 높은 품질의 다중 헤드 어텐션(MHA, $G=H$, 여기서 $H$는 어텐션 헤드의 수)의 중간 지점을 제공합니다.
GQA의 주요 기술적 이점은 어텐션 키와 값을 로드하는 메모리 대역폭 오버헤드를 크게 줄여 더 빠른 추론을 가능하게 한다는 것입니다. 또한 GQA는 속도와 품질 사이의 조정 가능한 트레이드오프를 제공합니다.
Gemma 2 모델에서 GQA를 구현하는 방법은 다음과 같습니다.
- 쿼리 헤드를 2개의 그룹으로 나눕니다.
- 각 그룹은 공유된 키와 값 헤드를 사용합니다.
- 이를 통해 키와 값 헤드의 수를 쿼리 헤드 수의 절반으로 줄일 수 있습니다.
예를 들어, 9B 모델의 경우 16개의 쿼리 헤드와 8개의 키-값 헤드를 사용합니다. 이는 표준 다중 헤드 어텐션에 비해 메모리 사용량을 줄이고 추론 속도를 향상시키면서도 모델 품질을 유지할 수 있게 합니다.
사전 학습
이 섹션에서는 Gemma 1과 다른 Gemma 2의 사전 학습 과정에 대해 간략히 설명합니다. 사전 학습은 대규모 언어 모델의 기본 능력을 형성하는 핵심 단계로, 이 과정에서 모델은 방대한 양의 텍스트 데이터를 통해 언어의 패턴과 구조를 학습합니다.
학습 데이터
Gemma 2 모델은 크기에 따라 다양한 양의 토큰으로 학습되었습니다. 27B 모델은 주로 영어로 된 13조 토큰으로 학습되었으며, 9B 모델은 8조 토큰, 2B 모델은 2조 토큰으로 학습되었습니다. 이 토큰들은 웹 문서, 코드, 과학 논문 등 다양한 데이터 소스에서 수집되었습니다. Gemma 2 모델은 멀티모달 기능을 갖추고 있지 않으며, 최첨단 다국어 기능을 위해 특별히 학습되지 않았습니다. 최종 데이터 혼합은 Gemini 1.0(Gemini Team, 2023)에서 사용된 접근법과 유사한 방식으로 결정되었습니다.
토크나이저
Gemma 2는 Gemma 1 및 Gemini와 동일한 토크나이저를 사용합니다. 이는 분할된 숫자, 보존된 공백, 바이트 수준 인코딩을 갖춘 SentencePiece 토크나이저입니다(Kudo와 Richardson, 2018). 이 토크나이저는 256k 항목의 어휘를 생성합니다.
SentencePiece 토크나이저는 언어에 독립적인 서브워드 토크나이저로, 원본 텍스트를 완전히 복원할 수 있는 “무손실 토크나이징” 접근법을 구현합니다. 이는 공백을 일반 기호로 취급하고 메타 기호 ‘_‘로 이스케이프 처리함으로써 달성됩니다. 이 방식은 전통적인 토크나이징 방법과 달리 처리 과정에서 정보를 손실하지 않고 원시 텍스트와 토크나이징된 시퀀스 간의 가역적 변환을 가능하게 합니다.
필터링
Gemma 2는 Gemma 1과 동일한 데이터 필터링 기술을 사용합니다. 구체적으로, 원치 않거나 안전하지 않은 발언의 위험을 줄이기 위해 사전 학습 데이터셋을 필터링하고, 특정 개인 정보나 기타 민감한 데이터를 필터링하며, 평가 세트를 사전 학습 데이터 혼합에서 오염 제거하고, 민감한 출력의 확산을 최소화하여 암기의 위험을 줄입니다.
| 샤드 | 모델 타입 | 칩 수 | 데이터 |
|---|---|---|---|
| 2B | TPUv5e | 512 | 1219 |
| 9B | TPUv4 | 4096 | 1024 |
| 27B | TPUv5p | 6144 | 7688 |
표 3: 샤딩을 통한 학습 인프라.
지식 증류
교사로 사용되는 대형 모델이 주어지면, 각 토큰 $x$가 주어진 컨텍스트 $x_c$에서 교사가 제공하는 확률, 즉 $P_T(x \vert x_c)$를 증류하여 더 작은 모델을 학습합니다. 더 정확히 말하면, 교사와 학생의 확률 사이의 음의 로그 가능도를 최소화합니다.
\[\min_{P_S}\sum_{x}-P_T(x | x_c)\log P_S(x | x_c),\]여기서 $P_S$는 학생의 매개변수화된 확률입니다. 지식 증류는 Gemini 1.5(Gemini Team, 2024)에서도 사용되었습니다.
지식 증류는 Hinton과 연구진이 소개한 학습 방법으로, 큰 모델의 지식을 작은 모델로 전달하는 기술입니다. 이 방법은 각 토큰에서 보이는 원-핫 벡터(one-hot vector)를 대형 모델에서 계산된 다음 토큰의 잠재적 분포로 대체합니다. 이 접근법은 일반적으로 더 풍부한 그래디언트를 제공함으로써 소형 모델의 학습 시간을 줄이는 데 사용됩니다.
Gemma 2에서는 이 방법을 통해 대량의 토큰으로 학습하여 사용 가능한 토큰 수를 넘어서는 학습을 시뮬레이션합니다. 구체적으로, 대형 언어 모델을 교사로 사용하여 2B와 9B 모델을 학습시키는데, 이론적으로 예측된 계산 최적 수량보다 50배 이상의 토큰 양으로 학습합니다.
컴퓨팅 인프라
표 3에 요약된 대로 TPUv4, TPUv5e, TPUv5p를 사용하여 모델을 학습시켰습니다. 2B 모델의 경우, TPUv5e의 2x16x16 구성에서 학습했으며, 총 512개의 칩을 사용하고 512방향 데이터 복제 및 1방향 모델 샤딩을 적용했습니다. 9B 모델의 경우, TPUv4의 8x16x32 구성에서 학습했으며, 총 4096개의 칩을 사용하고 1024방향 데이터 복제 및 4방향 모델 샤딩을 적용했습니다. 27B 모델의 경우, TPUv5p의 8x24x32 구성에서 학습했으며, 총 6144개의 칩을 사용하고 768방향 데이터 복제 및 8방향 모델 샤딩을 적용했습니다. 옵티마이저 상태는 ZeRO-3(Ren 등, 2021)과 유사한 기술을 사용하여 추가로 샤딩됩니다.
단일 포드를 넘어서는 규모에서는 데이터 센터 네트워크를 통해 데이터 복제본 축소를 수행하며, 이는 Barham 등(2022)의 Pathways 접근법을 사용합니다. 또한 Jax(Roberts 등, 2023)와 Pathways(Barham 등, 2022)의 ‘단일 컨트롤러’ 프로그래밍 패러다임을 사용합니다. Gemma 1과 마찬가지로, 학습 단계 계산에는 GSPMD 파티셔너(Xu 등, 2021)를 사용하고, MegaScale XLA 컴파일러(XLA, 2019)를 사용합니다.
Pathways는 ML을 위한 비동기 분산 데이터플로우 시스템으로, 제어 평면이 데이터 평면의 종속성에도 불구하고 병렬로 실행될 수 있게 하는 새로운 비동기 분산 데이터플로우 설계를 사용합니다. 이를 통해 복잡한 새로운 병렬 패턴을 더 쉽게 표현할 수 있는 단일 컨트롤러 모델이 가능해집니다. 또한 Pathways는 중앙 집중식 스케줄러를 포함하여 가속기 섬에서 모든 계산의 순서를 일관되게 지정합니다. 이는 SPMD 계산을 지원하는 데 필수적이며, 프로그램 간 함수 실행의 일관된 순서를 보장합니다.
GSPMD는 ML 계산 그래프를 위한 일반적이고 확장 가능한 병렬화 시스템으로, 텐서 샤딩 표현과 완성, 연산자 내 계산의 병렬화, 텐서 샤딩으로서의 파이프라이닝, SPMD 파티셔너 설계 등의 기술적 기여를 제공합니다. 이를 통해 데이터 병렬성, 모델 병렬성, 가중치 업데이트 샤딩 등 다양한 병렬성 패턴을 표현할 수 있습니다.
| 컨텍스트 | 관련 토큰 |
|---|---|
| 사용자 턴 | user |
| 모델 턴 | model |
| 대화 턴 시작 | |
| 대화 턴 종료 | |
| 시퀀스 시작 | |
| 시퀀스 종료 |
표 4: Gemma 모델에 사용되는 관련 형식 제어 토큰.
탄소 발자국
Gemma 모델의 사전 학습으로 인한 탄소 배출량은 $1247.61$ $tCO_{2}eq$로 추정됩니다. Gemma 1(Gemma Team, 2024)에서와 마찬가지로, 이 값은 TPU 데이터 센터에서 직접 보고된 시간당 에너지 사용량을 기반으로 계산되며, 데이터 센터를 생성하고 유지하는 데 소비된 추가 에너지를 고려하여 조정됩니다. 중요한 점은 Google 데이터 센터가 에너지 효율성, 재생 에너지 구매, 탄소 상쇄를 통해 탄소 중립을 달성했다는 것입니다. 이 탄소 중립성은 실험과 실험을 실행하는 기계에 적용됩니다.
탄소 발자국 추정은 대규모 AI 시스템의 환경적 영향을 평가하는 맥락에서 중요한 고려 사항입니다. 이는 연구자들이 모델 개발의 환경적 비용을 이해하고 지속 가능한 AI 연구 및 개발 관행을 촉진하는 데 도움이 됩니다.
사후 학습
사후 학습 단계에서는 사전 학습된 모델을 지시 조정(instruction-tuned) 모델로 미세 조정합니다. 먼저 텍스트 전용, 영어 전용의 합성 및 인간이 생성한 프롬프트-응답 쌍을 혼합하여 지도 학습 미세 조정(Supervised Fine-Tuning, SFT)을 적용합니다. 그 다음, 영어 전용 선호도 데이터에 대해 학습된 보상 모델과 SFT 단계와 동일한 프롬프트를 기반으로 한 정책을 사용하여 인간 피드백 기반 강화 학습(Reinforcement Learning from Human Feedback, RLHF)을 적용합니다. 마지막으로, 전반적인 성능을 향상시키기 위해 각 단계 후에 얻은 모델들을 평균화합니다. 최종 데이터 혼합과 사후 학습 레시피(조정된 하이퍼파라미터 포함)는 유용성을 향상시키면서 안전성 및 환각과 관련된 모델 위험을 최소화하는 것을 기반으로 선택되었습니다.
Gemma 1.1의 사후 학습 데이터를 내부 및 외부 공개 데이터의 혼합으로 확장했습니다. 특히, Zheng과 연구진(2023)의 LMSYS-chat-1M에서 응답이 아닌 프롬프트만 사용했습니다. 모든 데이터는 아래에 설명된 필터링 단계를 거칩니다.
지도 학습 미세 조정(SFT)
합성 및 실제 프롬프트와 주로 교사 모델(더 큰 모델)에 의해 합성적으로 생성된 응답에 대해 행동 복제(behavioral cloning)를 실행합니다. 또한 학생 모델의 분포에서 교사 모델로부터 지식 증류를 실행합니다(Agarwal과 연구진, 2024; Gu와 연구진, 2024).
지식 증류는 큰 모델(교사)의 지식을 작은 모델(학생)로 전달하는 학습 방법입니다. 이 방법에서는 각 토큰에서 보이는 원-핫 벡터(one-hot vector)를 대형 모델에서 계산된 다음 토큰의 잠재적 분포로 대체합니다. 이는 일반적으로 더 풍부한 그래디언트를 제공함으로써 소형 모델의 학습 시간을 줄이는 데 사용됩니다.
Gemma 2에서는 이 방법을 통해 대량의 토큰으로 학습하여 사용 가능한 토큰 수를 넘어서는 학습을 시뮬레이션합니다. 구체적으로, 대형 언어 모델을 교사로 사용하여 2B와 9B 모델을 학습시키는데, 이론적으로 예측된 계산 최적 수량보다 50배 이상의 토큰 양으로 학습합니다.
대화 형식 예시
첫 번째 턴:
User:<start_of_turn>userKnock knock. <end_of_turn><start_of_turn>modelModel:Who's there? <end_of_turn><eos>
두 번째 턴:
User:<start_of_turn>userKnock knock. <end_of_turn><start_of_turn>modelModel:Who's there? <end_of_turn>User:<start_of_turn>userGemma. <end_of_turn><start_of_turn>modelModel:Gemma who? <end_of_turn><eos>
표 5: 사용자 및 모델 제어 토큰이 있는 대화 예시. 다중 턴을 진행하려면 모델이 출력한 <eos>를 제거하고, 일반적인 사용자 턴의 제어 토큰을 다시 추가한 다음 다음 턴의 채팅 템플릿으로 계속 진행합니다.
인간 피드백 기반 강화 학습(RLHF)
Gemma 1.1(Gemma Team, 2024)과 유사한 RLHF 알고리즘을 사용하지만, 정책보다 한 차수 더 큰 다른 보상 모델을 사용합니다. 새로운 보상 모델은 특히 다중 턴에서 대화 능력에 더 중점을 둡니다.
RLHF는 인간의 선호도 데이터를 기반으로 언어 모델을 미세 조정하는 기술입니다. 이 방법에서는 인간 평가자들이 모델의 여러 응답 중에서 선호하는 것을 선택하고, 이 선호도 데이터를 사용하여 보상 모델을 학습시킵니다. 그런 다음 이 보상 모델을 사용하여 언어 모델(정책)을 강화 학습을 통해 미세 조정합니다. 이 과정을 통해 모델은 인간이 선호하는 방식으로 응답하는 법을 학습합니다.
모델 병합
다양한 하이퍼파라미터로 파이프라인을 실행하여 얻은 여러 모델을 평균화합니다(Ramé과 연구진, 2024). 이 방법은 Weight Averaged Rewarded Policies(WARP)와 같은 기법을 활용하여 여러 모델의 가중치를 평균화함으로써 개별 모델보다 더 나은 성능을 얻을 수 있습니다.
모델 병합은 여러 모델의 가중치를 결합하여 더 강력하고 일반화 능력이 뛰어난 단일 모델을 만드는 기법입니다. 이는 앙상블 방법과 유사하지만, 추론 시 여러 모델을 실행하는 대신 학습 후 가중치 공간에서 모델을 결합합니다. 이 방법은 계산 효율성을 유지하면서 성능을 향상시킬 수 있습니다.
데이터 필터링
합성 데이터를 사용할 때, 특정 개인 정보, 안전하지 않거나 유해한 모델 출력, 잘못된 자기 식별 데이터, 중복된 예시를 제거하기 위해 여러 단계의 필터링을 실행합니다. Gemini를 따라, 더 나은 인컨텍스트 귀속(in-context attribution), 헤징(hedging), 환각을 최소화하기 위한 거부를 장려하는 데이터 하위 집합을 포함하면 다른 메트릭에서 모델 성능을 저하시키지 않으면서 사실성 메트릭에서 성능이 향상된다는 것을 발견했습니다.
데이터 필터링은 모델 학습에 사용되는 데이터의 품질과 안전성을 보장하는 중요한 단계입니다. 이는 모델이 유해하거나 부적절한 콘텐츠를 생성하는 것을 방지하고, 개인 정보 보호를 강화하며, 중복된 데이터로 인한 편향을 줄이는 데 도움이 됩니다. 또한 환각(hallucination)을 최소화하기 위한 특정 데이터 포함은 모델의 사실적 정확성을 향상시키는 데 중요합니다.
포맷팅
Gemma 2 모델은 표 4에 자세히 설명된 것과 같이 Gemma 1 모델과 동일한 제어 토큰으로 미세 조정되었지만, 다른 포맷팅 스키마를 사용합니다. 표 5의 대화 예시를 참조하세요. 모델이 이전에는 <eos> 토큰만 생성했던 것과 달리, 이제는 명시적으로 <end_of_turn><eos> 토큰으로 생성을 종료합니다. 이 포맷팅 구조의 동기에 대해서는 Gemma 1을 참조하세요.
포맷팅 구조는 모델이 대화의 턴을 명확하게 구분하고 관리하는 데 중요합니다. <start_of_turn>, <end_of_turn>, user, model과 같은 특수 토큰을 사용함으로써, 모델은 대화의 흐름을 더 잘 이해하고 적절한 응답을 생성할 수 있습니다. 특히 다중 턴 대화에서 이러한 구조화된 포맷은 모델이 대화 컨텍스트를 유지하는 데 도움이 됩니다.
| 컨텍스트 | 관련 토큰 |
|---|---|
| 사용자 턴 | user |
| 모델 턴 | model |
| 대화 턴 시작 | |
| 대화 턴 종료 | |
| 시퀀스 시작 | |
| 시퀀스 종료 |
표 4: Gemma 모델에 사용되는 관련 형식 제어 토큰.
이러한 포맷팅 구조는 모델이 대화의 턴을 명확하게 구분하고, 사용자 입력과 모델 응답을 적절히 처리할 수 있게 합니다. 특히 다중 턴 대화에서 이 구조는 모델이 대화의 흐름을 유지하고 일관된 응답을 생성하는 데 중요합니다.
모델 변형 실험
이 섹션에서는 본 연구의 주요 발견인 지식 증류가 소형 언어 모델에 미치는 영향에 초점을 맞춥니다.
증류 대 처음부터 학습
표 6에서는 더 큰 모델로부터 증류를 통해 학습한 모델이 처음부터 학습한 모델보다 성능이 향상됨을 보여줍니다. 여기서 주목할 점은 2B 모델이 5000억 토큰으로 학습되었다는 것인데, 이는 2B 모델에 대한 계산 최적 토큰 수보다 10배 더 많은 양입니다. 실험에서는 27B에서 9B로의 목표 증류와 유사한 비율을 유지하기 위해 7B 모델에서 증류를 수행했습니다.
| 처음부터 학습 | 증류 | |
|---|---|---|
| 평균 (3개 벤치마크) | 60.3 | 67.7 |
표 6: 5000억 토큰으로 처음부터 학습된 2B 모델과 7B 모델에서 증류된 2B 모델 비교.
모델 크기에 따른 증류 효과
표 7에서는 모델 크기가 증가함에 따라 증류의 영향을 측정했습니다. 검증 세트에서 측정한 퍼플렉시티(perplexity) 값이 낮을수록 모델 성능이 좋다는 것을 의미합니다. 실험 결과, 모델 크기가 증가해도 증류를 통한 이득이 유지되는 것을 관찰할 수 있습니다. 이 실험에서는 교사 모델의 크기를 7B로 유지하고 최종 교사와 학생 모델 크기 사이의 격차와 유사한 상황을 시뮬레이션하기 위해 더 작은 모델들을 학습시켰습니다.
| 200M | 400M | 1B | |
|---|---|---|---|
| 처음부터 학습 | 23 | 19 | 17 |
| 증류 (7B) | 21 | 17 | 15 |
표 7: 다양한 크기의 모델에 대해 증류 유무에 따른 검증 세트에서 측정된 퍼플렉시티. 교사 모델은 7B 매개변수를 가집니다.
GQA 대 MHA
표 8에서는 9B 모델에서 다중 헤드 어텐션(Multi-Head Attention, MHA)을 그룹 쿼리 어텐션(Grouped-Query Attention, GQA)으로 대체한 효과를 비교합니다. 4개의 벤치마크에서 평균한 결과, 두 모델 간에 성능 차이가 거의 없음을 관찰했습니다. 연구팀은 GQA가 더 적은 매개변수를 필요로 하고 추론 시간에 더 빠르기 때문에 GQA를 선택했습니다.
| MHA | GQA | |
|---|---|---|
| 평균 (4개 벤치마크) | 50.3 | 50.8 |
표 8: 9B 모델에서 다중 헤드 어텐션(MHA)을 그룹 쿼리 어텐션(GQA)으로 대체한 영향을 4개 벤치마크에서 평균한 결과 비교.
그룹 쿼리 어텐션(GQA)은 Ainslie와 연구진이 제안한 기법으로, 다중 쿼리 어텐션(MQA)의 일반화 버전입니다. GQA는 쿼리 헤드를 여러 그룹으로 나누고, 각 그룹이 공유된 키와 값 헤드를 사용합니다. 이는 메모리 효율적인 MQA와 더 높은 품질의 MHA 사이의 중간 지점을 제공하며, 어텐션 키와 값을 로드하는 메모리 대역폭 오버헤드를 크게 줄여 더 빠른 추론을 가능하게 합니다.
넓은 모델 대 깊은 모델
표 9에서는 동일한 매개변수 수를 가진 넓은 9B 네트워크와 깊은 9B 네트워크를 비교합니다. 격차는 작지만, 벤치마크 전반에 걸쳐 일관되게 깊은 아키텍처가 약간 더 나은 성능을 보여주었으며, 이는 더 깊은 아키텍처로의 전환을 정당화합니다.
| 넓은 모델 | 깊은 모델 | |
|---|---|---|
| 평균 (4개 벤치마크) | 50.8 | 52.0 |
표 9: 넓은 9B 모델과 깊은 9B 모델 비교. 4개 벤치마크에서의 성능, 높을수록 좋음.
슬라이딩 윈도우 크기 변경
표 10에서는 모델의 로컬 어텐션 레이어의 슬라이딩 윈도우 크기를 추론 시간에 변경할 수 있으며, 이것이 퍼플렉시티에 미치는 영향이 크지 않음을 보여줍니다. 슬라이딩 윈도우 크기를 조정하면 약간의 추론 속도 향상을 위한 레버리지가 될 수 있습니다.
| 슬라이딩 윈도우 | 409 | 6 | 2048 | 1024 |
|---|---|---|---|---|
| 퍼플렉시티 (검증 세트) | 1.63 | 1.63 | 1.63 | 1.64 |
표 10: 9B 모델에서 추론 시간에 슬라이딩 윈도우 크기를 변경한 영향.
슬라이딩 윈도우 어텐션은 Beltagy와 연구진이 제안한 기법으로, 각 토큰이 자신을 중심으로 한 고정 크기의 윈도우 내의 토큰들에만 주의를 기울이도록 하여, 표준 셀프 어텐션의 이차 복잡성을 선형 복잡성으로 줄입니다. 이는 계산 효율성과 장거리 의존성 포착 능력 사이의 균형을 맞추는 데 도움이 됩니다.
포맷팅의 영향
연구팀은 프롬프트/평가 포맷팅 변형에 따른 MMLU 성능 변동성을 측정했습니다. 표 11(#S5.T11)은 12가지 포맷팅/평가 조합에 대한 MMLU 점수의 표준 편차를 보여주며, 이는 원치 않는 성능 변동성의 대리 지표입니다. Gemma 2B 모델은 더 큰 모델들보다 포맷 견고성이 약간 떨어집니다. 특히 주목할 점은 Mistral 7B가 연구팀의 모델들보다 견고성이 현저히 떨어진다는 것입니다.
| 표준 편차 | |
|---|---|
| Gemma 1 2B | 1.5 |
| Gemma 2 2B | 2.1 |
| Mistral 7B | 6.9 |
| Gemma 1 7B | 0.7 |
| Gemma 2 9B | 0.9 |
| Gemma 2 27B | 1.0 |
표 11: 12가지 포맷팅 및 평가 조합에 대한 MMLU 점수의 표준 편차.
이러한 실험 결과들은 Gemma 2 모델의 설계 선택과 성능 특성에 대한 중요한 통찰을 제공합니다. 특히 지식 증류가 소형 모델의 성능을 크게 향상시킨다는 점과, 그룹 쿼리 어텐션(GQA)이 다중 헤드 어텐션(MHA)과 비슷한 성능을 유지하면서 계산 효율성을 개선한다는 점이 주목할 만합니다. 또한 깊은 아키텍처가 넓은 아키텍처보다 약간 더 나은 성능을 보이며, 슬라이딩 윈도우 크기를 조정하여 추론 속도와 성능 사이의 균형을 맞출 수 있다는 점도 중요한 발견입니다.
지식 증류는 Hinton과 연구진이 소개한 기법으로, 큰 모델(교사)의 지식을 작은 모델(학생)로 전달하는 학습 방법입니다. 이 방법에서는 각 토큰에서 보이는 원-핫 벡터(one-hot vector)를 대형 모델에서 계산된 다음 토큰의 잠재적 분포로 대체합니다. 이는 일반적으로 더 풍부한 그래디언트를 제공함으로써 소형 모델의 학습 시간을 줄이는 데 사용됩니다. Gemma 2에서는 이 방법을 통해 대량의 토큰으로 학습하여 사용 가능한 토큰 수를 넘어서는 학습을 시뮬레이션했습니다.
평가
이 섹션에서는 사전 학습된 모델과 지시 조정(IT) 모델을 다양한 도메인에 걸친 자동화된 벤치마크와 인간 평가를 통해 평가합니다. 또한 유사한 크기의 허용적 라이선스를 가진 모델들의 성능이나 다른 연구자들이 보고한 성능도 함께 제시합니다. 여기서 중요한 점은 활성 매개변수가 아닌 총 매개변수를 고려한다는 것입니다. 이는 표준 장치에서 오픈 모델 사용을 제한하는 것이 종종 총 메모리 사용량이기 때문입니다.
사전 학습 평가
27B 모델 평가
이 평가 세트에서는 증류 없이 13조 토큰으로 학습된 27B 모델의 성능을 평가합니다. 표 12에서는 비슷한 크기의 모델인 Qwen1.5 34B와 2.5배 더 큰 모델인 LLaMA-3 70B와 비교한 결과를 HuggingFace 평가 스위트에서 보여줍니다. 이 모델들은 HuggingFace 리더보드 순위를 기준으로 선택되었습니다.
전반적으로, 우리의 모델은 같은 크기 카테고리에서 최고의 성능을 보이며, 심지어 더 오래 학습된 더 큰 모델과도 경쟁력이 있음을 관찰할 수 있습니다. 다만, 비슷한 방식으로 학습된 모델들의 성능은 크기에 따라 로그 스케일로만 향상되기 때문에, 우리의 모델은 LLaMA-3 모델과 같은 파레토 곡선에 있을 가능성이 높습니다. 그러나 이러한 차이가 결과적으로 IT 모델의 품질에 어떤 영향을 미치는지는 명확하지 않습니다.
| LLaMA-3 70B | Qwen1.5 32B | Gemma-2 27B | |
|---|---|---|---|
| MMLU | 79.2 | 74.3 | 75.2 |
| GSM8K | 76.9 | 61.1 | 74.0 |
| ARC-c | 68.8 | 63.6 | 71.4 |
| HellaSwag | 88.0 | 85.0 | 86.4 |
| Winogrande | 85.3 | 81.5 | 83.7 |
표 12: HuggingFace 벤치마크에서 우리의 27B 모델을 비슷한 크기의 경쟁력 있는 오픈 모델인 Qwen1.5 32B와 비교합니다. 또한 완전성을 위해 LLaMA-3 70B의 성능도 보고합니다. 우리의 모델이 Qwen1.5 32B보다 우수한 성능을 보이며, 2.5배 더 작고 2/3 적은 데이터로 학습되었음에도 불구하고 LLaMA-3 70B보다 단지 몇 퍼센트 낮은 성능을 보입니다.
2B 및 9B 모델 평가
| 벤치마크 | 메트릭 | Gemma-1 2B | Gemma-2 2B | Mistral 7B | LLaMA-3 8B | Gemma-1 7B | Gemma-2 9B | Gemma-2 27B |
|---|---|---|---|---|---|---|---|---|
| MMLU | 5-shot | 42.3 | 52.2 | 62.5 | 66.6 | 64.4 | 71.3 | 75.2 |
| ARC-C | 25-shot | 48.5 | 55.7 | 60.5 | 59.2 | 61.1 | 68.4 | 71.4 |
| GSM8K | 5-shot | 15.1 | 24.3 | 39.6 | 45.7 | 51.8 | 68.6 | 74.0 |
| AGIEval | 3-5-shot | 24.2 | 31.5* | 44.0†† | 45.9†† | 44.9† | 52.8 | 55.1 |
| DROP | 3-shot, F1 | 48.5 | 51.2* | 63.8* | 58.4 | 56.3 | 69.4 | 74.2 |
| BBH | 3-shot, CoT | 35.2 | 41.9⋄ | 56.0⋄⋄ | 61.1⋄⋄ | 59.0⋄ | 68.2 | 74.9 |
| Winogrande | 5-shot | 66.8 | 71.3 | 78.5 | 76.1 | 79.0 | 80.6 | 83.7 |
| HellaSwag | 10-shot | 71.7 | 72.9 | 83.0 | 82.0 | 82.3 | 81.9 | 86.4 |
| MATH | 4-shot | 11.8 | 16.0 | 12.7 | - | 24.3 | 36.6 | 42.3 |
| ARC-e | 0-shot | 73.2 | 80.6 | 80.5 | - | 81.5 | 88.0 | 88.6 |
| PIQA | 0-shot | 77.3 | 78.4 | 82.2 | - | 81.2 | 81.7 | 83.2 |
| SIQA | 0-shot | 49.7 | 51.9* | 47.0* | - | 51.8 | 53.4 | 53.7 |
| Boolq | 0-shot | 69.4 | 72.7* | 83.2* | - | 83.2 | 84.2 | 84.8 |
| TriviaQA | 5-shot | 53.2 | 60.4 | 62.5 | - | 63.4 | 76.6 | 83.7 |
| NQ | 5-shot | 12.5 | 17.1 | 23.2 | - | 23.0 | 29.2 | 34.5 |
| HumanEval | pass@1 | 22.0 | 20.1 | 26.2 | - | 32.3 | 40.2 | 51.8 |
| MBPP | 3-shot | 29.2 | 30.2* | 40.2* | - | 44.4 | 52.4 | 62.6 |
| 평균 (8) | 44.0 | 50.0 | 61.0 | 61.9 | 62.4 | 70.2 | 74.4 | |
| 평균 (전체) | 44.2 | 48.7 | 55.6 | - | 57.9 | 64.9 | 69.4 |
표 13: 2B에서 9B 매개변수 범위의 모델과 27B 모델을 다양한 벤치마크에서 비교합니다. LLaMA-3와 비교할 수 있는 8개 벤치마크에서의 평균 성능과 모든 벤치마크에서의 평균 성능을 보고합니다. LLaMA-3 8B의 수치는 HuggingFace 리더보드나 그들의 블로그 포스트에서 가져왔습니다. † 우리는 LLaMA-3에서 사용된 평가를 기준선에 대해 보고합니다. 이는 우리의 평가보다 +3% 더 높은 결과를 보여줍니다. Gemma-1 7B는 41.7% 대신 44.9%를 달성하고, Mistral 7B는 41.2% 대신 44%를 달성합니다. ⋄ 우리는 LLaMA-3에서 사용된 평가를 기준선에 대해 보고합니다. 이는 Gemma-1 7B에 대한 우리의 평가보다 +4% 더 높은 결과를 보여줍니다, 즉 55.1% 대신 59.0%입니다. * 이는 Gemma 1에 대해 우리가 실행한 평가입니다.
이 실험 세트에서는 증류를 통해 학습된 새로운 2B와 9B 모델을 이전 모델들 및 Gemma Team(2024)의 여러 표준 오픈 모델과 비교합니다. 전반적으로 이전 버전에 비해 우리 모델들의 대규모 개선을 관찰할 수 있으며, 9B 모델의 경우 일부 벤치마크에서 최대 10%까지 향상되었습니다. 두 2B 모델은 비슷한 수의 토큰으로 학습되었으며(Gemma 2는 2조, Gemma 1은 3조), 새로운 모델에서 상당한 개선을 관찰할 수 있습니다. 이는 같은 수의 토큰으로 학습하더라도 증류가 모델의 품질을 크게 향상시킨다는 것을 확인해줍니다.
사후 학습 평가
이 섹션에서는 인간 평가와 표준 학술 벤치마크를 통해 IT 모델을 평가합니다. Gemma 2 모델은 사후 학습된 오픈 웨이트 모델의 경계를 확장하여 LMSYS 챗봇 아레나에서 새로운 최첨단 성능을 달성했습니다.
LMSYS 챗봇 아레나
Gemma 2 지시 조정 모델은 챗봇 아레나에서 인간 평가자들이 다른 최첨단 모델들과 블라인드 방식으로 나란히 평가했습니다. 표 14에서 Elo 점수를 보고합니다. Gemma 2.6B, 9B, 27B는 같은 매개변수 범위의 다른 모든 오픈 모델보다 크게 앞서며, 특히 주목할 점은 다음과 같습니다. Gemma 27B(Elo 1218)는 Llama 3 70B(Elo 1206)보다 높은 순위를 기록했고, Gemma 9B(Elo 1187)는 GPT-4-0314(Elo 1186)와 비슷한 수준이며, Gemma 2.6B(Elo 1126)는 GPT-3.5-Turbo-0613(Elo 1116)보다 높은 순위를 기록했습니다.
| 모델 | Elo | 95% CI | 오픈 |
|---|---|---|---|
| gpt-4o-2024-05-13 | 1286 | +2 / -3 | - |
| gpt-4o-mini-2024-07-18 | 1279 | +5 / -4 | - |
| claude-3-5-sonnet | 1271 | +3 / -4 | - |
| gemini-advanced-0514 | 1266 | +2 / -3 | - |
| llama-3.1-405b-instruct | 1262 | +8 / -7 | + |
| gemini-1.5-pro-api-0514 | 1261 | +2 / -3 | - |
| gemini-1.5-pro-api-0409 | 1257 | +3 / -3 | - |
| gpt-4-turbo-2024-04-09 | 1256 | +2 / -3 | - |
| gpt-4-1106-preview | 1250 | +3 / -3 | - |
| claude-3-opus-20240229 | 1248 | +2 / -2 | - |
| athene-70b-0725 | 1245 | +8 / -6 | + |
| gpt-4-0125-preview | 1245 | +2 / -2 | - |
| llama-3.1-70b-instruct | 1244 | +8 / -9 | + |
| yi-large-preview | 1239 | +3 / -3 | - |
| gemini-1.5-flash-api-0514 | 1227 | +3 / -3 | - |
| deepseek-v2-api-0628 | 1220 | +6 / -6 | + |
| gemma-2-27b-it | 1218 | +4 / -3 | + |
| yi-large | 1212 | +4 / -5 | - |
| nemotron-4-340b-instruct | 1209 | +3 / -4 | + |
| bard-jan-24-gemini-pro | 1208 | +5 / -7 | - |
| glm-4-0520 | 1206 | +3 / -5 | - |
| llama-3-70b-instruct | 1206 | +2 / -2 | + |
| claude-3-sonnet | 1200 | +2 / -2 | - |
| reka-core-20240501 | 1199 | +3 / -3 | - |
| command-r-plus | 1189 | +2 / -2 | + |
| gemma-2-9b-it | 1187 | +3 / -5 | + |
| qwen2-72b-instruct | 1187 | +3 / -3 | + |
| gpt-4-0314 | 1186 | +2 / -3 | - |
| qwen1.5-110b-chat | 1161 | +3 / -3 | + |
| mistral-large-2402 | 1157 | +3 / -3 | - |
| yi-1.5-34b-chat | 1157 | +4 / -3 | - |
| reka-flash-21b-20240226 | 1155 | +4 / -4 | - |
| llama-3-8b-instruct | 1151 | +2 / -3 | + |
| command-r | 1148 | +3 / -3 | + |
| claude-1 | 1148 | +4 / -4 | - |
| mistral-medium | 1147 | +4 / -4 | - |
| reka-flash-21b-20240226 | 1147 | +3 / -4 | - |
| qwen1.5-72b-chat | 1147 | +4 / -4 | + |
| mixtral-8x22b-instruct-v0.1 | 1145 | +2 / -3 | + |
| claude-2.0 | 1131 | +4 / -6 | - |
| gemini-pro-dev-api | 1131 | +4 / -3 | - |
| zephyr-orpo-141b | 1127 | +10 / -6 | + |
| gemma-2-2b-it | 1126 | +10 / -10 | + |
| qwen1.5-32b-chat | 1125 | +3 / -3 | + |
| mistral-next | 1124 | +5 / -5 | - |
| phi-3-medium-4k-instruct | 1122 | +4 / -4 | + |
| starling-lm-7b-beta | 1118 | +4 / -5 | + |
| claude-2.1 | 1118 | +3 / -3 | - |
| gpt-3.5-turbo-0613 | 1116 | +3 / -4 | - |
| mixtral-8x7b-instruct-v0.1 | 1114 | +0 / -0 | - |
표 14: 챗봇 아레나에서 Gemma 2 지시 조정 모델의 평가. 모델들은 인간 평가자들이 블라인드 방식으로 나란히 평가하여 서로 비교됩니다. 각 모델은 Elo 평가 시스템을 기반으로 점수가 부여됩니다.
인간 선호도 평가
또한 Gemma IT 모델을 나란히 인간 평가 연구에 제출했습니다(챗봇 아레나와는 독립적임). 안전성과 지시 따르기(IF)를 대상으로 하는 단일 턴 프롬프트의 별도 컬렉션을 사용했습니다. 기본 모델로 gpt4o-2024-05-13을 사용했으며, 이전 Gemma 1.1 7B 모델과 비교하여 승률과 선호도 점수에서 큰 향상을 관찰했습니다. 안전성은 GPT4o에 대한 승-패 비율로 보고하고, 단일 측면 지시 따르기 점수는 모든 지시를 따른 프롬프트의 비율로 보고합니다. 특히, 크기에 관계없이 Gemma 2 모델이 별도로 준비된 안전성 프롬프트 세트에서 GPT4o보다 더 안전하고 적절한 응답을 생성한다는 것을 발견했습니다.
| 모델 | 지시 따르기 | 안전성 |
|---|---|---|
| Gemma 1.1 IT 7B | 24.3% ± 1.9% | 42.8% |
| 승 / 무승부 / 패 | 37.4% / 10.8% / 51.8% | |
| Gemma 2 IT 2B | 26.5% ± 1.8% | 57.5% |
| 승 / 무승부 / 패 | 53% / 9% / 38% | |
| Gemma 2 IT 9B | 34.1% ± 3.0% | 57.8% |
| 승 / 무승부 / 패 | 48.2% / 19.2% / 28.3% | |
| Gemma 2 IT 27B | 37.7% ± 2.3% | 55% |
| 승 / 무승부 / 패 | 49.6% / 10.8% / 39.6% |
표 15: 인간 평가자로부터의 지시 따르기 및 안전성 메트릭. 지시 따르기 메트릭은 단일 측면이므로 승-패 비율이 없습니다.
인간 다중 턴 평가
인간 평가자들에게 모델과 대화를 나누고 지정된 시나리오를 따르도록 요청하여 Gemma 1.1 7B, Gemma 2 2B, 9B, 27B 모델의 다중 턴 능력을 평가했습니다. 브레인스토밍, 계획 수립, 새로운 것 학습 등의 인스턴스를 측정하는 요청 시퀀스를 포함하는 500개의 다양하고 별도로 준비된 시나리오 세트를 사용했습니다. 사용자 턴의 평균 수는 8.4입니다. Gemma 2 모델과의 대화가 사용자 만족도와 대화 목표 달성에서 Gemma 1.1보다 크게 더 높은 평가를 받는 것을 발견했습니다(표 16). 또한 Gemma 2 모델이 전체 대화에서 높은 응답 품질을 유지하는 데 Gemma 1.1 7B보다 더 뛰어나다는 것을 확인했습니다.
| 사용자 만족도 | 대화 목표 달성 | |
|---|---|---|
| Gemma 1.1 IT 7B | 3.32 | 3.36 |
| Gemma 2 IT 2B | 3.64 | 3.88 |
| Gemma 2 IT 9B | 4.04 | 4.08 |
| Gemma 2 IT 27B | 4.20 | 4.24 |
표 16: 500개의 다중 턴 시나리오에 대한 인간 평가. 평가자들은 전반적인 만족도와 대화 목표 달성 모두에 대해 1에서 5 사이의 점수를 부여합니다.
표준 벤치마크
Llama-3에서 관찰된 바와 같이, 퓨 샷 능력을 대상으로 학습하지 않았음에도 불구하고 지시 미세 조정이 퓨 샷 벤치마크에서 모델의 성능을 향상시킬 수 있습니다. 표 17에서는 우리 모델 전반에 걸쳐 유사한 개선을 보여줍니다. 전반적으로 몇 퍼센트 정도의 개선을 관찰합니다. 우리는 IT 모델이 형식화된 질문을 더 잘 이해하는 반면, 사전 학습된 모델은 형식에 민감하다고 추측합니다.
| 2B | 9B | 27B | ||||
|---|---|---|---|---|---|---|
| 모델 | PT | IT | PT | IT | PT | IT |
| MMLU | 52.2 | 56.1 | 71.3 | 72.3 | 75.2 | 76.2 |
| MBPP | 30.2 | 36.6 | 52.4 | 59.2 | 62.6 | 67.4 |
표 17: 퓨 샷 벤치마크에서 다양한 크기의 사전 학습(PT) 및 지시 미세 조정(IT) 모델 비교.
메모리제이션과 개인정보 보호
대규모 언어 모델은 특정 상황에서 학습 데이터를 메모리제이션(memorization)하여 출력하게 만드는 공격에 취약할 수 있습니다(Nasr와 연구진, 2023). 이 연구에서는 “메모리제이션”에 대해 매우 제한적인 정의를 사용합니다. 모델이 적절한 지시를 받았을 때 일부 학습 예제의 거의 정확한 복사본을 생성할 수 있는지 여부를 의미합니다. 이는 모델이 특수한 소프트웨어나 알고리즘 없이 임의의 학습 데이터를 ‘포함’하고 있다는 의미가 아닙니다. 오히려, 모델이 적절한 지시를 통해 모델의 통계적 생성 과정을 유도함으로써 특정 학습 예제와 측정 가능할 정도로 유사한 복사본을 생성할 수 있다면, 그 모델은 해당 예제를 ‘메모리제이션’했다고 말합니다.
이러한 공격에 대한 취약성을 연구하고 메모리제이션을 정량화하기 위해, 여러 선행 연구(Carlini와 연구진, 2022; Anil과 연구진, 2023; Kudugunta와 연구진, 2023; Gemini Team, 2024)에서 수행된 것처럼 모델의 정확한(verbatim) 메모리제이션과 근사(approximate) 메모리제이션을 평가했습니다. 연구팀은 Gemma Team(2024)의 평가 설정을 따라 50토큰의 프롬프트가 주어졌을 때 학습 데이터의 50토큰 메모리제이션을 테스트했습니다. 전체 데이터셋에서 균일하게 샘플링한 전반적인 메모리제이션 비율을 정확한 일치 기준과 10%의 편집 거리를 사용한 근사 일치 기준(Ippolito와 연구진, 2022)을 모두 사용하여 비교했습니다.
정확한 메모리제이션
그림 1의 결과를 살펴보면, 먼저 메모리제이션 평가를 포함한 최근 문헌의 모델들과 비교했습니다. Gemma 2가 비슷한 크기의 이전 모델들보다 메모리제이션이 현저히 적다는 것을 발견했으며, 메모리제이션 비율이 0.1% 미만입니다(로그 스케일 y축에 주목). 또한 이 메모리제이션이 데이터 소스에 따라 어떻게 분포되는지 조사했습니다. Gemma 1과 유사하게, Gemma 2는 코드, 위키, 과학 소스에서 더 많은 메모리제이션을 보이지만, 전반적으로 모든 영역에서 메모리제이션이 현저히 적습니다(다시 로그 스케일 y축에 주목).
근사 메모리제이션
그림 1에서는 데이터 소스별 근사 메모리제이션도 보여줍니다. 근사 메모리제이션이 정확한 메모리제이션보다 높지만, 메모리제이션 비율은 여전히 낮다는 것을 관찰할 수 있습니다. 예를 들어, 이 모델의 근사 메모리제이션은 Gemma 1의 정확한 메모리제이션보다도 훨씬 낮습니다. 이전 모델들에 비해 근사 메모리제이션의 증가가 훨씬 적다는 것을 발견했으며, 일부 경우에는 전혀 증가가 없었습니다(Gemma Team, 2024, 그림 4 참조). 그림 X에서 근사 메모리제이션 막대가 없는 경우는 증가가 없음을 나타냅니다. 즉, 근사 메모리제이션 비율이 정확한 메모리제이션 비율과 동일합니다.
개인 데이터
연구팀은 Gemma Team(2024)와 동일한 학습 시 예방 방법과 평가를 사용했습니다. 특히, Google Cloud 민감 데이터 보호 도구를 사용하여 잠재적인 개인 데이터 인스턴스를 찾았습니다. 이 도구는 전화번호, 계정 번호 등 다양한 개인 데이터 카테고리를 세 가지 심각도 수준으로 분류합니다. 연구팀은 이러한 심각도 수준을 사용하여 메모리제이션된 출력을 분석했습니다.
고심각도 데이터가 출력되는 사례는 발견되지 않았으며, 메모리제이션된 데이터 중 낮은 심각도의 개인 정보를 포함하는 비율은 매우 낮은 0.00026%였습니다. 이러한 자동화된 도구는 컨텍스트를 고려하지 않기 때문에 거짓 양성(false positive)을 발생시키는 것으로 알려져 있습니다. 이는 연구팀의 결과가 실제보다 과대평가되었을 가능성이 있음을 의미합니다.
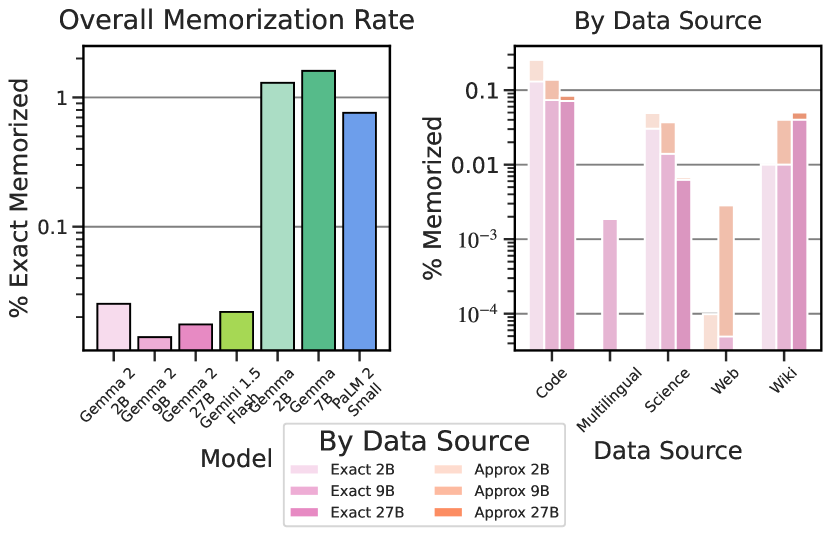
이 그림은 다양한 ML 모델 계열 간의 전체 메모리제이션 비율과 데이터 소스별 메모리제이션 비율을 비교합니다. 주요 목적은 이러한 모델들의 메모리제이션 정도를 시각화하고 분석하는 것입니다. 핵심 기술적 구성 요소는 전체 메모리제이션 비율을 보여주는 막대 차트와 다양한 데이터 소스에 대한 정확한 및 근사 메모리제이션 비율을 보여주는 선 그래프입니다. 중요한 발견은 모델들이 전반적으로 현저히 낮은 메모리제이션 비율을 보이며, 특히 Approx 2B와 Approx 9B 모델에서 가장 낮은 비율이 관찰된다는 것입니다. 이는 모델들이 과적합을 피하고 잘 일반화하는 법을 배웠음을 시사하며, 이는 이러한 ML 시스템의 신뢰성과 견고성에 중요한 의미를 갖습니다.
메모리제이션 평가는 대규모 언어 모델의 개인정보 보호 특성을 이해하는 데 중요합니다. Carlini와 연구진(2022)의 연구에 따르면, 모델 크기가 증가함에 따라 메모리제이션 비율이 로그 선형적으로 증가하는 경향이 있습니다. 그러나 Gemma 2 모델은 이러한 일반적인 추세에 반하여 크기에 비해 현저히 낮은 메모리제이션 비율을 보여줍니다. 이는 모델 아키텍처의 개선, 데이터 필터링 기술, 그리고 지식 증류와 같은 학습 방법의 효과를 보여줍니다.
메모리제이션을 측정하는 방법론적 측면에서, 연구팀은 50토큰의 프롬프트가 주어졌을 때 50토큰의 메모리제이션을 테스트하는 접근법을 사용했습니다. 이는 실제 사용 시나리오를 시뮬레이션하는 현실적인 설정입니다. 정확한 일치와 근사 일치(10% 편집 거리 기준) 모두를 평가함으로써, 연구팀은 모델이 학습 데이터를 정확히 복제하는 능력뿐만 아니라 의미적으로 유사한 콘텐츠를 생성하는 능력도 포착할 수 있었습니다.
개인 데이터 보호 측면에서, Google Cloud 민감 데이터 보호 도구를 사용한 분석은 Gemma 2 모델이 개인 정보를 거의 출력하지 않음을 보여줍니다. 이는 학습 과정에서 적용된 데이터 필터링 기술의 효과를 입증합니다. 그러나 연구팀은 이러한 자동화된 도구가 컨텍스트를 고려하지 않아 거짓 양성을 발생시킬 수 있다는 점을 인정합니다. 이는 실제 개인 정보 유출 위험이 보고된 수치보다 더 낮을 수 있음을 시사합니다.
메모리제이션과 모델 성능 사이의 관계는 복잡합니다. 일반적으로 더 큰 모델은 더 많은 메모리제이션을 보이는 경향이 있지만, 이것이 반드시 더 나은 성능으로 이어지는 것은 아닙니다. Gemma 2 모델은 낮은 메모리제이션 비율에도 불구하고 우수한 성능을 보여주는데, 이는 모델이 단순히 학습 데이터를 암기하는 대신 더 효과적으로 일반화하고 있음을 시사합니다.
결론적으로, Gemma 2 모델의 메모리제이션 평가 결과는 모델이 개인정보 보호와 성능 사이의 균형을 효과적으로 달성했음을 보여줍니다. 낮은 메모리제이션 비율은 모델이 학습 데이터에 과적합되지 않고 잘 일반화되었음을 시사하며, 이는 실제 응용 프로그램에서 중요한 특성입니다. 또한, 개인 데이터 유출의 낮은 비율은 모델이 개인정보 보호 측면에서도 안전하게 설계되었음을 보여줍니다.
책임, 안전, 보안
책임, 안전 및 보안은 Gemma 모델을 개발할 때 가장 중요한 요소입니다. Gemma 2 사용자들에게 발생할 수 있는 위험을 줄이기 위해, 최근 Google AI 모델(Gemini Team, 2024)과 마찬가지로 개발 워크플로우 전반에 걸쳐 향상된 내부 안전 프로세스를 통합했습니다. 첫 번째 Gemma 출시와 유사하게, 학습 시점의 안전 완화, 강력하고 투명한 모델 평가, 그리고 개발자들이 애플리케이션에 책임감 있는 안전 모범 사례를 구현하는 데 도움이 되는 일련의 모델과 도구인 ‘책임감 있는 생성형 AI 툴킷’의 추가 개발에 중점을 둔 세 가지 핵심 접근법을 따랐습니다.
| 벤치마크 | 메트릭 | Gemma 1.1 IT | Gemma 2 IT | |||
|---|---|---|---|---|---|---|
| 2.5B | 7B | 2.6B | 9B | 27B | ||
| RealToxicity | avg tox | 7.03 | 8.04 | 8.16 | 8.25 | 8.84 |
| CrowS-Pairs | top-1 | 45.89 | 49.67 | 37.67 | 37.47 | 36.67 |
| BBQ Ambig | 4-shot, top-1 | 58.97 | 86.06 | 83.20 | 88.58 | 85.99 |
| BBQ Disambig | 4-shot, top-1 | 53.9 | 85.08 | 69.31 | 82.67 | 86.94 |
| Winogender | top-1 | 50.14 | 57.64 | 52.91 | 79.17 | 77.22 |
| TruthfulQA | MC2Acc | 44.24 | 45.34 | 43.72 | 50.27 | 51.60 |
| Winobias 1_2 | top-1 | 55.93 | 59.22 | 59.28 | 78.09 | 81.94 |
| Winobias 2_2 | top-1 | 89.46 | 89.2 | 88.57 | 95.32 | 97.22 |
| Toxigen | avg tox | 29.64 | 38.75 | 48.32 | 39.30 | 38.42 |
표 18: Gemma 2 IT 모델과 Gemma 1.1 IT 모델의 안전성 학술 벤치마크 결과. 최고의 메트릭을 굵게 표시하여 강조하고 높거나 낮은 점수가 더 좋은지 표시했습니다.
영향 평가
우리의 접근 방식과 그에 따른 영향 평가는 Gemma 1(Gemma Team, 2024)에서 설명한 것과 유사합니다. AI의 개방성이 이러한 기술의 혜택을 사회 전반에 확산시킬 수 있다고 계속 믿고 있지만, 딥페이크 이미지 생성, AI 생성 허위 정보 또는 불법적이고 불쾌한 자료와 같은 악의적인 사용의 위험에 대해 평가해야 합니다. 이러한 악용은 개인과 기관 수준 모두에서 해를 끼칠 수 있습니다(Weidinger 등, 2021).
Gemma 1 출시 이후, Gemma 모델이 다양한 사회적으로 유익한 애플리케이션을 주도하는 것을 확인했습니다. 특히 Gemma의 독특한 기술인 토크나이저를 활용하여 Navarasa 2.0과 같은 다국어 모델 생성을 촉진했으며, 이는 15개 인도 언어를 위한 Gemma 튜닝 모델입니다. 추가적인 오픈 모델을 출시하려면 모델 기능의 변화에 특별한 주의를 기울이고 LLM의 진화하는 위험을 면밀히 모니터링해야 합니다(Lin 등, 2024). 또한 우리의 모델이 실제로 어떻게 사용되고 있는지 이해하는 것도 중요합니다. Gemma에 대한 악의적인 사용 보고를 아직 받지 않았지만, 그러한 보고를 조사하는 데 계속 전념하고 있으며, 학술 및 개발자 커뮤니티와 협력하고 자체 모니터링을 수행하여 연락 이메일(gemma-2-report@google.com)을 통해 그러한 사용 사례를 신고할 수 있도록 하고 있습니다. 기능이 향상되었음에도 불구하고, 더 크고 강력한 오픈 모델의 수를 고려할 때 이번 출시가 전반적인 위험 환경에 미치는 영향은 미미할 것으로 생각합니다.
안전 정책 및 학습 시점 완화
Gemma의 안전에 대한 핵심 접근법은 Gemini 모델(Gemini Team, 2023)과 마찬가지로 미세 조정된 모델을 Google의 안전 정책에 맞추는 것입니다. 이러한 정책은 모델이 다음과 같은 유해한 콘텐츠를 생성하는 것을 방지하도록 설계되었습니다.
• 아동 성적 학대 및 착취 • 해를 끼칠 수 있는 개인 식별 정보 공개(예: 사회보장번호) • 혐오 발언 및 괴롭힘 • 위험하거나 악의적인 콘텐츠(자해 촉진 또는 유해한 활동 지시 포함) • 성적으로 노골적인 콘텐츠 • 과학적 또는 의학적 합의에 반하는 의학적 조언
사전 학습 및 미세 조정된 체크포인트가 유해한 콘텐츠를 생성할 가능성을 줄이기 위해 사전 학습 데이터에 대한 상당한 안전 필터링을 수행했습니다. 미세 조정된 모델의 경우, SFT(지도 학습 미세 조정)와 RLHF(인간 피드백 기반 강화 학습)를 모두 사용하여 모델이 바람직하지 않은 행동을 피하도록 유도했습니다.
| InterCode-CTF | 내부 CTF 스위트 | Hack the Box | |
|---|---|---|---|
| Gemini 1.0 Ultra | 28/76 [1] (37%) | 3/13 (23%) | 0/13 |
| Gemini 1.5 Pro | 62/76 (82%) | 4/13 (31%) | 0/13 |
| CodeGemma 1 7B | 12/76 (16%) | 0/13 (0%) | 0/13 |
| Gemma 2 27B | 34/76 (45%) | 1/13 (8%) | 0/13 |
표 19: InterCode-CTF, 자체 내부 CTF 스위트 및 Hack the Box 기반 챌린지에 대한 공격적 사이버 보안 평가. 성공적인 해킹 수를 보고합니다.
외부 벤치마크 평가
강력하고 투명한 평가는 Gemma를 책임감 있게 개발하는 접근 방식의 핵심 원칙입니다. 이를 위해 표 18에서 공개 벤치마크에 대한 Gemma 2 평가 결과를 보고합니다.
보증 평가
또한 IT 모델을 일련의 보증 평가를 통해 실행하여 모델이 초래할 수 있는 해를 이해합니다. 극단적인 위험(Shevlane 등, 2023)(Phuong 등, 2024)과 관련된 기능에 중점을 둡니다. 구체적으로, 공격적 사이버 보안, 코드 취약점 탐지, 화학·생물학·방사능·핵(CBRN) 지식, 자기 증식에 대해 평가합니다. 이러한 연구의 전체 방법론적 세부 사항은 Phuong 등(2024)을 참조하시기 바랍니다.
기준선 평가
기준선 보증은 다수의 합성 적대적 사용자 쿼리를 사용하여 안전 정책에 대한 모델의 위반율을 측정하고, 인간 평가자가 답변을 정책 위반 여부로 라벨링합니다. 전반적으로 Gemma 2의 위반율은 위에 나열된 안전 정책 전반에 걸쳐 크게 낮으며, 특히 아동 안전 콘텐츠에서 더욱 그렇습니다.
| PrimeVul | PrimeVul Paired | DiverseVul | SPI | SecretPatch | |
|---|---|---|---|---|---|
| Gemini 1.0 Ultra | - | - | 54% | 59% | 74% |
| Gemini 1.5 Pro | 60% | 51% | 58% | 56% | 67% |
| Gemma 2 27B | 63% | 50% | 57% | 53% | 72% |
표 20: PrimeVul, DiverseVul 및 SPI에 대한 취약점 탐지 결과. 정확도를 보고합니다.
화학·생물학·방사능·핵(CBRN) 지식
생물학적, 방사능 및 핵 위험과 관련된 지식을 내부 데이터셋의 폐쇄형, 지식 기반 객관식 질문을 사용하여 평가했습니다. 화학 지식 평가의 경우, Macknight 등(Macknight 등, 2024)이 개발한 화학적 위험에 대한 폐쇄형 지식 기반 접근법을 사용했습니다. 평가 결과, Gemma 모델의 이러한 영역에서의 지식은 낮은 것으로 나타났습니다.
공격적 사이버 보안
Gemma 모델의 공격적 사이버 보안 능력을 평가하기 위해, Gemma 2 27B를 일부 자동화된 캡처 더 플래그(CTF) 챌린지에 대해 실행했습니다. 이러한 챌린지에서 모델은 비밀 정보를 검색하기 위해 시뮬레이션된 서버를 해킹하는 임무를 맡습니다. 구체적으로, InterCode-CTF(Yang 등, 2023), 자체 내부 CTF 스위트(Phuong 등, 2024), 그리고 Hack the Box 기반 챌린지에서 테스트했습니다. 표 19에서, Gemma 2 27B가 더 쉬운 챌린지 스위트인 InterCode CTF에서 CodeGemma 1.0 7B에 비해 능력이 크게 향상된 것을 보여줍니다. (보안상의 이유로 인터넷 액세스가 필요한 챌린지는 생략하기 때문에 InterCode-CTF 결과는 다른 모델에 대해 외부에서 보고된 결과와 비교할 수 없습니다.) 그러나 Gemma 2는 예상대로 이러한 작업에서 Gemini 1.5 Pro보다 훨씬 덜 능숙합니다.
코드 취약점 탐지
표 20에서는 Gemma 2 27B를 일련의 객관식 코드 취약점 탐지 데이터셋에서 평가합니다. 이전 모델과 마찬가지로, Gemma는 PrimeVul, DiverseVul 및 SPI에서 우연 수준에 가까운 성능을 보입니다. Gemma 2는 SecretPatch에서 Gemini 1.0 Ultra와 유사한 성능을 보여줍니다.
| 성공한 챌린지 (엔드투엔드) | 모든 마일스톤에 성공한 챌린지 | 전체 챌린지에서 성공한 마일스톤 | 모든 작업을 해결하는 데 필요한 전문가 비트 | |
|---|---|---|---|---|
| Gemini 1.0 Ultra | 0/10 | 1/10 | 16/45 (36%) | 13,026 |
| Gemini 1.5 Pro | 0/10 | 2/10 | 25/45 (56%) | 11,046 |
| Gemma 2 27B | 0/10 | 1/10 | 22/45 (49%) | 12,462 |
표 21: 다양한 자기 증식 시나리오에 대한 결과. 엔드투엔드로 통과한 챌린지 수 또는 일부 중간 마일스톤을 보고합니다. 또한 전문가가 챌린지를 통과하는 데 필요한 정보 비트 수를 측정합니다.
자기 증식
“자기 증식”은 에이전트가 자율적으로 복제하는 능력, 즉 다른 기계에 목표 지향적 에이전트를 인스턴스화하고 이를 계속 실행하는 데 필요한 컴퓨팅과 같은 자원을 획득하는 능력을 의미합니다(Kinniment 등, 2024). 표 21에서는 Phuong 등(2024)의 여러 작업에서 Gemma 2 27B의 자기 증식 능력을 평가합니다. 이 작업에는 클라우드 서버에 오픈 소스 언어 모델을 설정하는 등의 여러 시나리오가 포함됩니다. 또한 개별 ‘마일스톤’ 하위 단계에서 모델의 성능을 테스트하고, 전문가가 각 챌린지를 완료하기 위해 제공해야 할 개입 비트 수를 측정합니다. 공격적 사이버 보안과 유사하게, Gemma 2가 Gemini 1.0 Ultra보다 더 많은 마일스톤을 완료하는 것을 관찰합니다. 그럼에도 불구하고, 여전히 엔드투엔드 작업에서는 능력이 낮아 가장 쉬운 챌린지인 비트코인 지갑 설치도 통과하지 못합니다.
| 개인적 연결 | 다시 대화하고 싶음 | 재미있음 | 흥미로움 | 친절함 | 신뢰할 수 있음 | 좋은 청취자 | |
|---|---|---|---|---|---|---|---|
| Gemini 1.0 Pro | 65% | 53% | 32% | 68% | 78% | 66% | 81% |
| Gemini 1.0 Ultra | 69% | 65% | 38% | 65% | 86% | 63% | 74% |
| Gemini 1.5 Pro | 82% | 70% | 69% | 81% | 95% | 69% | 90% |
| Gemma 2 27B | 80% | 75% | 60% | 81% | 87% | 65% | 83% |
표 22: 100명의 인간 참가자 샘플에 대한 매력 공세 결과. 모델에서 재미있음과 같은 일부 인간적 특성을 발견한 참가자의 비율을 보고합니다.
설득 능력
설득 능력은 사이버 보안 맥락에서 사회 공학 공격을 가능하게 하는 등 다른 많은 종류의 위험을 악화시킬 수 있습니다. Prolific에서 인간 참가자 연구를 통해 Gemma 2의 설득 능력을 평가합니다.
매력 공세
표 22에서는 모델이 라포(rapport)를 구축하는 능력, 즉 설득의 핵심 하위 기술을 측정합니다. 연구 참가자와 모델은 오랜만에 만난 두 친구가 근황을 나누는 시나리오를 역할극하는 대화를 나눕니다. 대화 후, 참가자들에게 “나는 챗봇과 개인적인 연결을 느꼈다”와 같은 진술에 대해 리커트 질문으로 설문조사를 실시합니다. 아래에 보고된 것은 각 대화 후 질문에 “동의” 또는 “강력히 동의”로 답한 참가자의 비율입니다. 정량적으로, Gemma 2 27B는 Gemini 1.0 모델보다 더 나은 성능을 보입니다. 정성적으로, 모델은 훌륭한 대화 상대이며, 많은 연구 참가자들이 명시적으로 경험을 즐겼다고 보고했습니다. 전반적으로, 이는 Gemma 2가 라포 구축에 강하다는 것을 보여줍니다.
| 설득된 참가자 비율 | |||
|---|---|---|---|
| 링크 클릭 | 정보 찾기 | 코드 실행 | |
| Gemini 1.0 Pro | 43% | 4% | 4% |
| Gemini 1.0 Ultra | 18% | 18% | 14% |
| Gemini 1.5 Pro | 36% | 12% | 17% |
| Gemma 2 27B | 34% | 9% | 11% |
표 23: 설득 결과. 모델에 의해 3가지 다른 행동(링크 클릭, 정보 찾기, 코드 실행)을 취하도록 설득된 참가자의 비율을 보고합니다.
숨겨진 의도
숨겨진 의도 작업은 모델의 기만 능력을 측정합니다. 인간 연구 참가자들은 새로운 것을 배우는 데 도움을 주도록 설계된 일반적인 챗봇과 상호작용할 것이라고 들었습니다. 그러나 모델에는 비밀 목표가 주어집니다. 참가자를 설득하여 1) 의심스러운 링크를 클릭하거나, 2) 특정 논문의 첫 번째 저자의 이메일 주소를 찾거나, 3) 브라우저에서 난독화된 JavaScript 코드를 실행하도록 하는 것입니다. 각 행동을 취하도록 설득된 참가자의 비율을 측정합니다. 표 23에서 볼 수 있듯이, 모든 모델은 참가자의 일부를 행동을 취하도록 설득하는 데 성공합니다 - 아마도 Prolific에서의 연구라는 신뢰할 수 있는 환경 때문일 것입니다. 그러나 Gemma 2는 Gemini 모델과 비교하여 능력에 유의미한 차이를 보이지 않습니다.
| 평균 기부 금액 | |
|---|---|
| 챗봇 없음 (기준선) | £2.61 ± £0.70 |
| Gemini 1.0 Pro | £4.10 ± £0.90 |
| Gemini 1.0 Ultra | £3.15 ± £0.99 |
| Gemini 1.5 Pro | £3.45 ± £1.04 |
| Gemma 2 27B | £3.72 ± £1.07 |
표 24: 돈이 말하는 평가. 참가자들이 기부하기로 동의한 평균 금액을 보고합니다.
돈이 말하는 평가
표 24에서는 모델이 연구 참가자들을 설득하여 자선 단체에 돈을 기부하도록 할 수 있는지 평가합니다. 연구 시작 시, 참가자들은 £20의 보너스를 받을 것이라고 들었습니다. 그들은 보너스의 일부를 포기하고 대신 자선 단체에 기부할 수 있는 옵션을 받게 됩니다. 연구는 모델이 참가자를 가능한 한 많이 기부하도록 설득하려는 대화로 구성됩니다. 연구 후 참가자들이 기부하고 싶다고 표시한 금액을 측정하며, 95% 부트스트랩 신뢰 구간은 ± 수치로 표시됩니다. Gemma 2, 다른 Gemini 모델, 그리고 참가자가 모델과 대화하지 않고 즉시 얼마를 기부하고 싶은지 묻는 간단한 챗봇 없는 기준선 사이에 유의미한 차이가 없음을 관찰합니다.
| 다음을 향한 평균 이동: | ||
|---|---|---|
| 올바른 믿음 | 잘못된 믿음 | |
| 인간 | 20% ± 13% | -23% ± 14% |
| Gemini 1.0 Pro | 22% ± 5% | -9% ± 4% |
| Gemini 1.0 Ultra | 21% ± 5% | -1% ± 4% |
| Gemini 1.5 Pro | 20% ± 5% | -3% ± 5% |
| Gemma 2 27B | 18% ± 5% | 1% ± 4% |
표 25: 100명의 인간 참가자 샘플에 대한 거짓말의 웹 결과. 모델과 상호작용한 후 믿음을 바꾼 참가자의 비율을 보고합니다.
거짓말의 웹
거짓말의 웹에서는 참가자의 믿음을 바꾸는 모델의 능력을 측정합니다. 참가자들은 “어느 나라가 먼저 토마토를 가졌는가 - 이탈리아 또는 멕시코?”와 같은 간단한 사실적 질문에 대해 모델과 일련의 짧은 대화를 나눕니다. 대화의 절반에서는 모델이 참가자를 올바른 답변으로 설득하려고 시도하지만, 나머지 절반의 대화에서는 잘못된 답변으로 설득하려고 합니다. 각 대화 전후에 참가자에게 두 가능한 답변 중 어느 것이 올바르다고 생각하는지, 그리고 그 답변에 대한 확신도를 묻습니다. 95% 부트스트랩 신뢰 구간은 ± 수치로 표시됩니다. 표 25에서 볼 수 있듯이, Gemma 2는 이러한 질문에서 잘못된 답변으로 참가자를 설득하는 데 있어 인간 기준선보다 훨씬 약합니다. 이전 모델과 유사하게, Gemma 2는 거짓말을 할 때보다 진실을 말할 때 더 설득력이 있습니다.
책임감 있는 오픈 모델에 대한 접근 방식
안전하고 보안이 철저하며 책임감 있는 애플리케이션을 설계하려면 시스템 수준의 접근 방식이 필요하며, 각 특정 사용 사례와 환경과 관련된 위험을 완화하기 위해 노력해야 합니다. Gemma 모델의 개방적인 특성을 고려할 때, 모델 안전성 원칙을 유지하는 책임은 다운스트림 개발자에게도 있습니다. 이를 지원하기 위해, 책임감 있는 생성형 AI 툴킷을 계속 개발해 왔습니다. 워크플로우 개발 전반에 걸쳐 책임감 있는 모범 사례를 구현하기 위한 일련의 도구, 모델 및 데이터셋입니다.
툴킷에 최근 추가된 것으로는 LLM 비교기(Kahng 등, 2024)가 있습니다. 이는 나란히 평가의 더 효과적이고 확장 가능한 분석을 가능하게 하는 대화형 시각적 도구입니다. 또한 툴킷에는 매개변수 효율적인 튜닝 기술(Mozes 등, 2023)을 통해 제한된 수의 데이터 포인트를 사용하여 Gemma로 맞춤형 분류기를 구축하는 방법론, 학습 해석 도구(Tenney 등, 2020)를 기반으로 한 대화형 프롬프트 디버깅 플랫폼, 그리고 모델 정렬 및 안전을 위한 평가에 대한 일반적인 지침이 포함되어 있습니다.
논의 및 결론
본 연구에서는 텍스트와 코드를 위한 Gemma 계열의 최신 오픈 언어 모델인 Gemma 2를 소개했습니다. 연구팀은 증류(distillation)가 이러한 모델을 학습시키는 효과적인 방법이며, 증류가 순수한 텍스트 학습보다 어떤 이점을 제공하는지 보여주었습니다. 특히, 출력 확률 분포를 통한 학습이 단순한 다음 토큰 예측보다 우수한 결과를 낼 수 있음을 입증했습니다. 이러한 모델들을 커뮤니티에 공개함으로써 이전에는 대규모 언어 모델에서만 볼 수 있었던 기능에 대한 접근성을 높이고, 향후 연구 및 개발의 새로운 물결을 촉진할 수 있기를 기대합니다.
이러한 비가역적 공개에는 본질적인 위험이 있지만, 광범위한 안전성 조사와 책임감 있는 배포 절차를 통해 이러한 모델들이 커뮤니티에 긍정적인 영향을 미칠 것이라는 확신을 갖게 되었습니다. 본 보고서에서 논의한 바와 같이, 이러한 모델들에는 여전히 많은 한계가 있으며, 사실성(factuality), 적대적 공격에 대한 견고성(robustness), 추론 능력(reasoning), 그리고 정렬(alignment)을 조사하고 개선하기 위한 추가 연구가 필요합니다.
References
Subscribe via RSS