Apple Intelligence Foundation Language Models
by Apple
TL;DR
이 연구를 시작하게 된 배경과 동기는 무엇입니까?
애플은 2024년 세계개발자회의(WWDC)에서 iOS 18, iPadOS 18, macOS Sequoia에 깊이 통합된 개인 인공지능 시스템인 ‘애플 인텔리전스’를 소개했습니다. 이 시스템은 사용자의 일상적인 작업에 최적화되고 현재 활동에 맞게 실시간으로 적응할 수 있는 다양한 생성형 모델로 구성되어 있습니다. 애플은 사용자 개인정보 보호를 최우선으로 하면서도 텍스트 작성 및 개선, 알림 요약, 이미지 생성, 앱 간 상호작용 단순화와 같은 기능을 제공하기 위한 기술적 기반이 필요했습니다. 이 연구는 사용자의 개인정보를 보호하면서도 고성능 AI 기능을 제공하는 어려운 과제를 해결하기 위해 시작되었습니다. 특히 온디바이스 처리와 프라이빗 클라우드 컴퓨트(Private Cloud Compute)라는 혁신적인 인프라를 통해 사용자 데이터의 개인정보를 보호하면서 강력한 AI 기능을 제공하는 방법을 찾고자 했습니다. 또한 모델이 “지능형 도구로 사용자에게 권한 부여”, “사용자 대표”, “신중한 설계”, “개인정보 보호”라는 책임감 있는 AI 원칙에 따라 작동하도록 설계되었습니다.
이 연구에서 제시하는 새로운 해결 방법은 무엇입니까?
애플은 두 가지 핵심 파운데이션 언어 모델을 개발했습니다. 첫 번째는 약 30억 개의 매개변수를 가진 온디바이스 언어 모델인 AFM-온디바이스(Apple Foundation Model)이며, 두 번째는 더 큰 규모의 서버 기반 언어 모델인 AFM-서버입니다. 가장 중요한 혁신은 기본 모델에 연결될 수 있는 작은 특수 신경망 모듈인 LoRA 어댑터 아키텍처의 도입입니다. 이를 통해 기본 모델을 그대로 유지하면서 특정 작업에 맞게 모델을 미세 조정할 수 있으며, 필요에 따라 어댑터를 동적으로 교체할 수 있습니다. 또한 애플은 사후 학습을 위한 두 가지 새로운 알고리즘을 제시했습니다. 첫 번째는 교사 위원회를 통한 거부 샘플링 미세 조정 알고리즘(iTeC)으로, 다양한 모델로 구성된 위원회에서 최상의 응답을 선택하여 모델 훈련에 활용합니다. 두 번째는 미러 디센트 정책 최적화와 리브-원-아웃(leave-one-out) 이점 추정기를 사용한 인간 피드백을 통한 강화 학습(MDLOO) 알고리즘입니다. 또한 모델 품질을 유지하면서 메모리 사용량과 추론 비용을 줄이기 위한 정확도 복구 어댑터를 갖춘 혼합 정밀도 양자화 기법을 개발했습니다.
제안된 방법은 어떻게 구현되었습니까?
AFM 모델은 공유 입출력 임베딩 행렬, 사전 정규화와 RMSNorm, 쿼리/키 정규화, 그룹화된 쿼리 어텐션(GQA), SwiGLU 활성화 함수, RoPE 위치 임베딩 등을 포함한 트랜스포머 아키텍처를 기반으로 구현되었습니다. 사전 학습은 핵심(core), 지속적(continued), 컨텍스트 확장(long-context)이라는 세 단계로 진행되었으며, 각 단계에서 다양한 데이터 혼합물과 훈련 목표를 사용했습니다. 데이터 소스에는 웹 페이지, 라이선스 데이터셋, 코드, 수학, 공개 데이터셋이 포함되었으며, 모든 데이터에서 사용자 개인 데이터와 같은 민감한 정보는 제외되었습니다. 사후 학습 단계에서는 지도 학습 미세 조정(SFT)과 인간 피드백을 통한 강화 학습(RLHF)이 수행되었습니다. 인간 주석 데이터와 합성 데이터를 모두 포함하는 하이브리드 데이터 전략을 사용했으며, 특히 수학, 도구 사용, 코딩과 같은 특수 도메인에 대한 합성 데이터 생성 방법을 개발했습니다. 모델은 온디바이스 추론을 위한 양자화와 함께 정확도 복구를 위한 LoRA 어댑터를 적용했으며, 이를 통해 가중치당 평균 4비트 미만으로 처리하면서도 모델 품질을 유지했습니다. 요약 기능의 사례 연구에서는 특정 제품 사양에 맞게 어댑터를 미세 조정하는 과정을 상세히 설명했습니다.
이 연구의 결과가 가지는 의미는 무엇입니까?
AFM 모델은 인간 평가에서 오픈 소스 모델(Phi-3, Gemma-1.1, Llama-3, Mistral, DBRX-Instruct)과 상업용 모델(GPT-3.5, GPT-4) 모두와 비교했을 때 경쟁력 있는 성능을 보였습니다. 특히 AFM-온디바이스는 모델 크기가 25% 더 작음에도 Phi-3-mini보다 우수한 성능을 달성했으며, 매개변수 수가 두 배 이상 많은 Gemma-7B와 Mistral-7B보다도 더 나은 성능을 보였습니다. AFM-서버는 GPT-3.5와 비교하여 50% 이상의 승률을 기록했습니다. 이 연구의 가장 중요한 의미는 모델 크기만으로는 성능을 결정할 수 없으며, 효율적인 아키텍처 설계와 훈련 방법이 중요하다는 것을 입증했다는 점입니다. 특히 LoRA 어댑터를 통한 기능별 미세 조정 방식은 제한된 리소스를 가진 디바이스에서도 고성능 AI 기능을 제공할 수 있는 효과적인 방법을 제시합니다. 또한 사용자 개인정보 보호와 강력한 AI 기능 사이의 균형을 맞추는 접근 방식은 향후 AI 기술 개발에 중요한 방향성을 제시합니다. 애플의 책임감 있는 AI 원칙에 따른 설계는 유용성과 안전성을 동시에 고려한 모델 개발의 모범 사례를 보여주며, 이는 실제 사용자 경험에 직접적인 영향을 미치는 AI 시스템 구축에 있어 중요한 이정표가 됩니다.
애플 인텔리전스 파운데이션 언어 모델
소개
애플은 2024년 세계개발자회의(WWDC)에서 애플 인텔리전스(Apple Intelligence)를 소개했습니다. 애플 인텔리전스는 iOS 18, iPadOS 18, 그리고 macOS Sequoia에 깊이 통합된 개인 인공지능 시스템입니다. 이 시스템은 사용자의 일상적인 작업에 최적화되고, 현재 활동에 맞게 실시간으로 적응할 수 있는 다양한 고성능 생성형 모델로 구성되어 있습니다. 애플 인텔리전스에 내장된 파운데이션 모델들은 텍스트 작성 및 개선, 알림 우선순위 지정 및 요약, 가족 및 친구와의 대화를 위한 재미있는 이미지 생성, 그리고 앱 간 상호작용을 단순화하는 인앱 작업 수행과 같은 사용자 경험을 위해 미세 조정되었습니다.
본 보고서에서는 애플 인텔리전스의 핵심을 이루는 두 가지 모델에 대해 자세히 설명합니다. 첫 번째는 약 30억 개의 매개변수를 가진 온디바이스 언어 모델인 AFM-온디바이스(AFM은 Apple Foundation Model의 약자)이며, 두 번째는 더 큰 규모의 서버 기반 언어 모델인 AFM-서버입니다. 이 두 파운데이션 모델은 효율적이고 정확하며 책임감 있게 특수 작업을 수행하도록 구축되고 조정되었습니다(그림 1 참조).

그림 1: 애플 파운데이션 모델의 모델링 개요. 이 그림은 애플 파운데이션 모델의 모델링 프로세스에 대한 고수준 개요를 제공합니다. 데이터 전처리, 사전 학습, 사후 학습, 최적화와 같은 주요 기술 구성 요소를 보여주며, 이 모든 과정은 책임감 있는 AI 원칙에 의해 안내됩니다. 시각화는 모델링 워크플로우의 반복적인 특성과 이 프로세스의 최종 결과물인 애플 파운데이션 모델의 중심적 역할을 강조합니다.
이 두 모델은 애플이 사용자와 개발자를 지원하기 위해 만든 더 큰 생성형 모델 제품군의 일부입니다. 여기에는 Xcode에 인텔리전스를 구축하기 위한 코딩 모델(AFM 언어 모델 기반)과 사용자가 메시지 앱 등에서 시각적으로 자신을 표현하는 데 도움이 되는 디퓨전 모델도 포함됩니다.
애플 인텔리전스는 모든 단계에서 애플의 핵심 가치를 반영하여 설계되었으며, 업계를 선도하는 개인정보 보호를 기반으로 구축되었습니다. 또한 애플은 AI 도구와 그 기반이 되는 모델을 개발하는 방식을 안내하는 책임감 있는 AI 원칙을 수립했습니다.
-
지능형 도구로 사용자에게 권한 부여: AI를 책임감 있게 사용하여 특정 사용자 요구를 해결하는 도구를 만들 수 있는 영역을 식별합니다. 사용자가 목표를 달성하기 위해 이러한 도구를 사용하는 방식을 존중합니다.
-
사용자 대표: 전 세계 사용자를 진정성 있게 대표하는 것을 목표로 깊이 개인화된 제품을 구축합니다. AI 도구와 모델 전반에 걸쳐 고정관념과 시스템적 편향을 영속시키지 않도록 지속적으로 노력합니다.
-
신중한 설계: 설계, 모델 훈련, 기능 개발, 품질 평가 등 모든 단계에서 AI 도구가 오용되거나 잠재적 해를 끼칠 수 있는 방식을 식별하기 위한 예방 조치를 취합니다. 사용자 피드백을 통해 AI 도구를 지속적이고 적극적으로 개선할 것입니다.
-
개인정보 보호: 강력한 온디바이스 처리와 프라이빗 클라우드 컴퓨트(Private Cloud Compute)와 같은 획기적인 인프라를 통해 사용자의 개인정보를 보호합니다. 파운데이션 모델을 훈련할 때 사용자의 개인 데이터나 사용자 상호작용을 사용하지 않습니다.
이러한 원칙은 애플 인텔리전스를 가능하게 하고 기능과 도구를 전문화된 모델과 연결하는 아키텍처의 모든 단계에 반영되어 있습니다. 이 보고서의 나머지 부분에서는 고성능이면서도 빠르고 전력 효율적인 모델을 개발하는 방법, 이러한 모델을 훈련하는 접근 방식, 특정 사용자 요구에 맞게 어댑터를 미세 조정하는 방법, 그리고 유용성과 의도하지 않은 해악 모두에 대해 모델 성능을 평가하는 방법과 같은 결정에 대한 세부 정보를 제공합니다.
프라이빗 클라우드 컴퓨트[Apple, 2024b]는 애플 인텔리전스의 핵심 인프라 중 하나로, 서버 기반 대규모 언어 모델을 위한 개인정보 보호 기능을 제공합니다. 이 혁신적인 인프라는 사용자 데이터의 개인정보를 보호하면서도 클라우드에서 AI 모델 추론을 가능하게 합니다. 프라이빗 클라우드 컴퓨트는 디바이스와 클라우드 간의 하이브리드 컴퓨팅 모델을 지원하여 온디바이스 제약을 넘어서는 더 크고 강력한 모델을 가능하게 하면서도 개인정보 보호 보장을 유지합니다. 이는 애플의 “개인정보 보호” 책임감 있는 AI 원칙을 실현하는 핵심 기술적 기반입니다.
아키텍처
AFM 기본 모델은 트랜스포머 아키텍처(Vaswani와 연구진)를 기반으로 한 밀집형 디코더 전용 모델로, 다음과 같은 설계 선택을 통해 구축되었습니다.
-
공유 입출력 임베딩 행렬: Press와 Wolf가 제안한 방식을 적용하여 파라미터의 메모리 사용량을 줄였습니다. 이 기법은 입력 임베딩과 출력 임베딩을 동일한 행렬로 공유함으로써 모델 크기를 효율적으로 감소시킵니다.
-
사전 정규화(Pre-Normalization)와 RMSNorm: Nguyen과 Salazar가 제안한 사전 정규화 방식과 Zhang과 Sennrich가 개발한 RMSNorm을 적용하여 학습 안정성을 향상시켰습니다. 사전 정규화는 각 서브레이어에 입력을 전달하기 전에 정규화를 적용하는 방식으로, 기존 트랜스포머의 후처리 정규화보다 더 안정적인 학습을 가능하게 합니다.
-
쿼리/키 정규화: Wortsman과 연구진이 제안한 쿼리/키 정규화를 적용하여 학습 안정성을 더욱 개선했습니다. 이 기법은 어텐션 로짓의 성장 불안정성 문제를 해결하는 데 도움이 됩니다.
-
그룹화된 쿼리 어텐션(GQA): Ainslie와 연구진이 제안한 그룹화된 쿼리 어텐션을 8개의 키-값 헤드로 구현하여 KV-캐시 메모리 사용량을 줄였습니다. GQA는 여러 쿼리 헤드가 하나의 키-값 헤드를 공유하도록 하여 메모리 효율성과 모델 품질 사이의 균형을 맞추는 기법입니다.
-
SwiGLU 활성화 함수: Shazeer가 제안한 SwiGLU 활성화 함수를 사용하여 더 높은 효율성을 달성했습니다. SwiGLU는 기존의 ReLU 활성화 함수보다 더 나은 성능을 제공하는 게이트 선형 유닛(GLU) 변형입니다.
-
RoPE 위치 임베딩: Su와 연구진이 제안한 RoPE(Rotary Position Embedding)를 기본 주파수 $500\mathrm{k}$로 설정하여 긴 컨텍스트 지원을 가능하게 했습니다. RoPE는 회전 행렬을 사용하여 상대적 위치 정보를 효과적으로 인코딩하는 방식입니다.
표 1은 AFM-온디바이스 모델의 주요 차원 정보를 제공합니다.
| 모델 차원 | 3072 |
|---|---|
| 헤드 차원 | 128 |
| 쿼리 헤드 수 | 24 |
| 키/값 헤드 수 | 8 |
| 레이어 수 | 26 |
| 비임베딩 파라미터 수 (B) | 2.58 |
| 임베딩 파라미터 수 (B) | 0.15 |
표 1: AFM-온디바이스 차원 정보.
이러한 아키텍처 설계는 AFM 모델이 제한된 리소스를 가진 디바이스에서도 효율적으로 작동할 수 있도록 하면서 높은 성능을 유지하는 데 중점을 두고 있습니다. 특히 그룹화된 쿼리 어텐션과 공유 임베딩 행렬은 메모리 사용량을 크게 줄이는 데 기여하며, RMSNorm과 쿼리/키 정규화는 학습 과정의 안정성을 향상시킵니다. 또한 RoPE 위치 임베딩은 긴 시퀀스 처리 능력을 개선하여 다양한 실제 응용 시나리오에서 모델의 유용성을 높입니다.
사전 학습
AFM 사전 학습 과정은 다양한 애플 인텔리전스 기능을 지원하는 고성능 언어 모델을 개발하는 데 중요한 역할을 합니다. 이 과정에서는 효율성과 데이터 품질에 중점을 두어 효율적이고 지연 시간이 낮은 모델을 통해 고품질의 엔드투엔드 사용자 경험을 제공하는 것을 목표로 합니다.
데이터
AFM 사전 학습 데이터셋은 다양하고 고품질의 데이터 혼합물로 구성되어 있습니다. 여기에는 출판사로부터 라이선스를 취득한 데이터, 엄선된 공개 또는 오픈소스 데이터셋, 그리고 애플의 웹 크롤러인 Applebot[Apple, 2024a]을 통해 수집된 공개 정보가 포함됩니다. 애플은 표준 robots.txt 지시문을 통해 Applebot의 크롤링을 거부하는 웹페이지의 권리를 존중합니다.
사용자 개인정보 보호에 중점을 두고 있기 때문에, 데이터 혼합물에는 애플 사용자의 개인 데이터가 포함되지 않습니다. 또한 공개적으로 이용 가능한 데이터에서 비속어, 안전하지 않은 자료, 개인 식별 정보를 제외하기 위한 광범위한 노력이 이루어졌습니다. 또한 많은 일반적인 평가 벤치마크에 대한 엄격한 오염 제거 작업도 수행되었습니다.
애플은 데이터의 양보다 품질이 다운스트림 모델 성능을 결정하는 핵심 요소임을 발견했습니다. 다음은 데이터 혼합물의 주요 구성 요소에 대한 자세한 내용입니다.
웹 페이지
애플은 웹 크롤러인 Applebot[Apple, 2024a]을 사용하여 공개적으로 이용 가능한 정보를 크롤링하며, 표준 robots.txt 지시문을 통해 Applebot의 크롤링을 거부하는 웹 게시자의 권리를 존중합니다. 또한 비속어가 포함된 페이지를 제외하고 특정 범주의 개인 식별 정보(PII)를 제거하기 위한 필터를 적용합니다. 남은 문서는 품질 필터링과 일반 텍스트 추출을 수행하는 파이프라인에 의해 처리됩니다. 구체적으로:
- 본문 추출은 Safari의 리더 모드와 Boilerpipe(Kohlschütter 등, 2010) 알고리즘의 조합을 사용하여 수행됩니다.
- 휴리스틱과 모델 기반 분류기를 사용한 안전성 및 비속어 필터링이 적용됩니다.
- 지역 민감 n-그램 해싱을 사용한 전역 퍼지 중복 제거가 수행됩니다.
- 휴리스틱과 모델 기반 분류기를 사용한 광범위한 품질 필터링이 적용됩니다(Kong 등, 2024, Li 등, 2024a).
- 811개의 일반적인 사전 학습 벤치마크에 대한 오염 제거가 수행되며, 특정 n-그램의 충돌 횟수가 “일반 사용” 임계값인 1000에 도달하지 않는 한, 벤치마크 데이터셋과의 4-13 그램 충돌이 발생하는 전체 문서를 필터링합니다.
라이선스 데이터셋
애플은 출판사로부터 제한된 양의 고품질 데이터를 식별하고 라이선스를 취득하기 위해 많은 노력을 기울입니다. 이러한 라이선스 데이터셋은 다양하고 고품질의 긴 컨텍스트 데이터의 자연스러운 소스를 제공하므로, 지속적인 사전 학습 및 컨텍스트 확장 단계의 데이터 혼합물에 포함됩니다. 출판사 라이선스 데이터의 섹션은 웹 페이지와 동일한 방식으로 오염을 제거합니다.
코드
코드 데이터는 GitHub에서 라이선스 필터링된 오픈 소스 저장소에서 얻습니다. 여기서 MIT, Apache, BSD, CC0, CC-BY, Unlicensed, ISC, Artistic 라이선스를 사용하는 저장소만 포함됩니다. 코드 데이터의 대부분은 Swift, Python, C, Objective-C, C++, JavaScript, Java, Go를 포함한 14개의 일반적인 프로그래밍 언어를 다룹니다. 이 데이터는 중복 제거되고, PII 및 품질에 대해 추가로 필터링되며, 앞선 절과 동일한 방식으로 오염이 제거됩니다.
수학
애플은 웹에서 얻은 두 가지 범주의 고품질 데이터를 통합합니다. 첫 번째 범주는 수학 콘텐츠가 풍부한 20개 웹 도메인에서 30억 토큰으로 구성된 수학 Q&A 데이터셋입니다. HTML 페이지에서 관련 태그를 식별하여 질문과 답변을 추출합니다. 두 번째 범주는 수학 포럼, 블로그, 튜토리얼, 세미나와 같은 웹 페이지에서 140억 토큰을 모은 것입니다. 이러한 웹 페이지를 필터링하기 위해 수학적 템플릿을 식별하기 위한 40개 문자열 모음이 있는 수학 태그 필터, 수학 콘텐츠를 식별하기 위한 350개 유니코드 및 LaTeX 기호 모음이 있는 수학 기호 필터, 특별히 수학을 위해 설계된 언어 모델 분류기로 구동되는 품질 필터[Kong 등, 2024], 그리고 사람이 수동으로 레이블링한 도메인의 모든 웹 페이지를 처리하는 도메인 필터를 포함하는 특수 파이프라인을 사용했습니다. 이러한 필터를 적용한 후 중복 제거, 오염 제거, PII 제거를 수행하여 최종 데이터셋을 생성했습니다.
공개 데이터셋
애플은 언어 모델 훈련에 사용을 허용하는 라이선스가 있는 여러 고품질 공개 데이터셋을 평가하고 선택했습니다. 그런 다음 사전 학습 혼합물에 포함하기 전에 개인 식별 정보를 제거하기 위해 데이터셋을 필터링했습니다.
토크나이저
AFM은 SentencePiece의 구현을 따르는 바이트 페어 인코딩(BPE) 토크나이저를 사용합니다. 모든 숫자는 개별 자릿수로 분할되며, 알 수 없는 UTF-8 문자를 바이트 토큰으로 분해하기 위해 바이트 폴백을 사용합니다. 유니코드 정규화는 활성화하지 않습니다. 총 어휘 크기는 AFM-서버의 경우 10만 개, AFM-온디바이스의 경우 4만 9천 개 토큰입니다.
레시피
AFM 사전 학습은 세 가지 뚜렷한 단계로 나뉩니다.
- 코어: 대부분의 컴퓨팅 예산을 소비합니다.
- 지속적: 낮은 품질의 대량 웹 크롤 데이터의 가중치를 낮추고, 대신 더 높은 코드 및 수학 가중치와 함께 위에서 설명된 라이선스 데이터를 포함합니다.
- 컨텍스트 확장: 지속적인 사전 학습의 또 다른 단계와 유사하지만, 더 긴 시퀀스 길이에서 수행되며 합성 긴 컨텍스트 데이터가 혼합물에 포함됩니다.
세 가지 사전 학습 단계 이후의 모델 품질에 대한 자세한 내용(내부 벤치마크 구현에서 파생된 AFM에 대한 추가 메트릭과 함께)은 부록 C에 있으며, 부록 D는 AFM-서버의 긴 컨텍스트 기능을 검토합니다.
세 단계 모두 정규화를 위해 분리된 가중치 감소[Loshchilov와 Hutter, 2019]를 사용하며, [Wortsman 등, 2023]에서 $\mu$ Param (simple)로 설명된 것과 유사한 $\mu$ Param[Yang 등, 2022]의 단순화된 버전도 사용합니다. 지금까지 이러한 규모에서 더 정교한 매개변수 노름 제어가 필요하다는 것을 발견하지 못했습니다.
모든 단계는 float32에서 모델과 옵티마이저 상태를 분할하여 유지하고, 효율성을 위해 순방향 및 역방향 패스에서 bfloat16으로 캐스팅합니다.
코어 사전 학습
AFM-서버 코어 훈련은 처음부터 수행되는 반면, AFM-온디바이스는 더 큰 모델에서 증류 및 가지치기됩니다.
AFM-서버: AFM-서버는 8192개의 TPUv4 칩에서 4096의 시퀀스 길이와 4096 시퀀스의 배치 크기를 사용하여 6.3T 토큰에 대해 처음부터 훈련됩니다. 배치 크기는 모델 크기와 컴퓨팅 예산에 맞는 스케일링 법칙을 사용하여 결정되었지만, 다운스트림 결과는 상당히 넓은 범위의 배치 크기에 상대적으로 둔감하며, 예측된 배치 크기의 $0.5\times$에서 $2\times$ 사이의 어떤 값도 유사한 결과를 산출했을 것으로 예상됩니다(실제로 예측된 최적값은 $\sim$ 3072였지만, 4096은 칩 활용도를 더 높일 수 있었습니다).
모델 차원이 768인 프록시 모델을 사용하여 학습률 스윕을 수행한 결과, 최적의 학습률 범위가 0.01-0.02임을 발견했으므로 보수적으로 0.01을 선택했습니다. $\mu$ Param (simple)의 사용으로 인해 선형 레이어는 $\sim$ 0.1로 스케일된 효과적인 학습률을 갖게 됩니다. 조정된 분리된 가중치 감소는 $3.16\mathrm{e}{-4}$를 사용하며, 이는 테스트된 모든 모델 크기와 컴퓨팅 예산에서 잘 작동하는 것으로 나타났습니다. 학습률 스케줄은 5000 스텝 동안의 선형 웜업을 포함하고, 이후 훈련의 나머지 기간 동안 코사인 감소를 통해 피크의 0.005까지 감소합니다. 부록 A는 AFM 코어 사전 학습 레시피를 더 일반적인 구성과 비교합니다.
AFM-온디바이스: 온디바이스 모델의 경우, 지식 증류[Hinton 등, 2015]와 구조적 가지치기가 모델 성능과 훈련 효율성을 향상시키는 효과적인 방법임을 발견했습니다. 이 두 방법은 서로 보완적이며 다른 방식으로 작동합니다.
구체적으로, AFM-온디바이스를 훈련하기 전에, [Wang 등, 2020; Xia 등, 2023]에 설명된 방법과 유사한 방법을 통해 학습된 가지치기 마스크를 사용하여 처음부터 훈련된 6.4B 모델에서 초기화합니다. 주요 차이점은 다음과 같습니다.
- 피드포워드 레이어의 은닉 차원만 가지치기합니다.
- HardConcrete 마스킹[Louizos 등, 2018] 대신 Soft-Top-K 마스킹[Lei 등, 2023]을 사용합니다.
- 마스크를 학습하기 위해 코어 단계와 동일한 사전 학습 데이터 혼합물을 사용하며, 188B 토큰에 대해 훈련합니다.
그런 다음 AFM-온디바이스의 코어 사전 학습 중에, 실제 레이블을 교사 모델의 상위 1 예측과 볼록 조합으로 대체하여 증류 손실을 사용합니다(교사의 레이블에 0.9 가중치 할당). 이 과정은 전체 6.3T 토큰에 대해 훈련됩니다. 가지치기된 모델에서 초기화하면 데이터 효율성과 최종 벤치마크 결과가 0-2% 향상되는 것을 관찰했으며, 증류를 추가하면 MMLU와 GSM8K가 각각 약 5%와 3% 향상됩니다. 더 자세한 절제 결과는 부록 B에서 찾을 수 있습니다. 배치 크기를 제외한 모든 훈련 하이퍼파라미터는 AFM-서버와 동일하게 유지됩니다.
지속적인 사전 학습
두 모델 모두 8192의 시퀀스 길이에서 지속적인 사전 학습을 수행하며, 수학과 코드의 가중치를 높이고 대량 웹 크롤의 가중치를 낮춘 혼합물에서 추가로 1T 토큰을 학습합니다. 또한 앞선 절에 설명된 라이선스 데이터도 포함합니다. 피크 학습률 $3\mathrm{e}{-4}$와 분리된 가중치 감소 $1\mathrm{e}{-5}$, 1000 웜업 스텝과 피크의 0.001까지의 최종 학습률 감소를 사용하며, 이는 코어 사전 학습과 다릅니다. 다른 설정(배치 크기 등)은 그대로 유지됩니다. AFM-온디바이스의 경우 코어 사전 학습과 달리 여기서는 증류 손실이 도움이 되지 않는다는 것을 발견했으므로, 레시피는 AFM-서버에 사용된 것과 동일합니다.
컨텍스트 확장
마지막으로, $32768$ 토큰의 시퀀스 길이에서 추가로 100B 토큰의 지속적인 사전 학습을 수행하며, 지속적인 사전 학습 단계의 데이터 혼합물을 사용하고 합성 긴 컨텍스트 Q&A 데이터를 추가합니다. 또한 RoPE 기본 주파수를 500k에서 $6315089$로 증가시켜 [Liu 등, 2024]에 설명된 스케일링 법칙을 따릅니다. 이는 짧은 컨텍스트에서 긴 컨텍스트로의 일반화를 개선할 것으로 예상되며, 이는 사전 학습 데이터의 대부분이 32k 토큰보다 훨씬 짧은 문서로 구성되어 있기 때문에 바람직합니다. 레시피는 지속적인 사전 학습에 사용된 것과 유사합니다. AFM-서버의 긴 컨텍스트 성능은 부록 D에서 검토됩니다.
옵티마이저
AFM 사전 학습을 위해 모멘텀이 있는 RMSProp[Hinton, 2012] 변형을 선택했습니다. 특히, 제곱 기울기의 편향 보정된 지수 이동 평균의 제곱근으로 원시 기울기를 나누어 즉각적인 업데이트를 생성하고, 이를 매개변수 블록당 최대 노름 $1.0$으로 클리핑한 다음, 편향 보정 없이 지수 이동 평균으로 이 추정치를 스텝에 걸쳐 추가로 평활화하여 순 업데이트를 생성합니다. 달리 명시되지 않는 한, 제곱 기울기($\beta_{2}$)와 업데이트($\beta_{1}$) 모두에 대한 평활화 상수는 $0.95$로 설정됩니다. 수치적 안정성을 위해 즉각적인 제곱 기울기에 작은 상수 $\epsilon=1\mathrm{e}{-30}$이 평활화 전에 추가됩니다.
평활화된 업데이트는 학습률로 스케일되고, 가중치 감소가 추가된 다음, 예약된 감소가 적용되어 최종 가중치 델타를 형성합니다. 안정성을 위한 추가 보호 장치로, 옵티마이저 전에 전역 기울기 노름을 $1.0$으로 클리핑합니다. 더 일반적인 구성과의 레시피 비교는 부록 A를 참조하십시오.
훈련 인프라
AFM 모델은 v4 및 v5p Cloud TPU 클러스터에서 AXLearn 프레임워크[Apple, 2023]를 사용하여 사전 학습됩니다. AXLearn은 공용 클라우드용으로 설계된 JAX[Bradbury 등, 2018] 기반 딥 러닝 라이브러리입니다. 훈련은 텐서, 완전 분할 데이터 병렬, 시퀀스 병렬성의 조합을 사용하여 수행되며, 이를 통해 훈련이 높은 활용도로 많은 수의 모델 매개변수와 시퀀스 길이로 확장될 수 있습니다. 이 시스템을 통해 AFM-온디바이스, AFM-서버 및 더 큰 모델을 포함한 AFM 모델을 효율적이고 확장 가능하게 훈련할 수 있습니다.
AFM-서버는 $8 \times 1024$ 칩 슬라이스로 구성된 8192개의 TPUv4 칩에서 훈련되었으며, 여기서 슬라이스는 데이터 센터 네트워크(DCN)[Chowdhery 등, 2022]에 의해 연결됩니다. 데이터 병렬성만 슬라이스 경계를 넘어가고, 다른 유형의 상태 분할은 슬라이스 내에서만 이루어집니다. 이는 슬라이스 내 상호 연결 대역폭이 DCN보다 몇 배 더 높기 때문입니다. 이 훈련 실행에 대한 지속적인 모델-플롭-활용도(MFU)는 약 52%였습니다. AFM-온디바이스는 2048개의 TPUv5p 칩으로 구성된 한 슬라이스에서 훈련되었습니다.
사후 학습
애플 인텔리전스 기능은 기본 모델 위에 어댑터를 통해 구동됩니다. 경험적으로 일반 목적 사후 학습을 개선하면 모든 기능의 성능이 향상된다는 것을 발견했습니다. 이는 모델이 지시 따르기, 추론, 글쓰기에 대한 더 강력한 능력을 갖게 되기 때문입니다. 애플은 사전 학습된 AFM 모델에 일반 목적 지시 따르기와 대화 능력을 부여하기 위한 사후 학습 방법에 대한 광범위한 연구를 수행했습니다. 이러한 모델 능력이 사용자 개인정보 보호에 대한 약속과 책임감 있는 AI 원칙을 포함한 애플의 핵심 가치와 원칙에 부합하도록 하는 것이 목표입니다.
사후 학습 노력에는 데이터 수집 및 생성, 지시 튜닝, 그리고 정렬(alignment) 혁신의 일련의 과정이 포함됩니다. 사후 학습 과정은 지도 학습 미세 조정(SFT)과 인간 피드백을 통한 강화 학습(RLHF)이라는 두 단계로 구성됩니다. 애플은 두 가지 새로운 사후 학습 알고리즘을 제시합니다.
- 교사 위원회를 통한 거부 샘플링 미세 조정 알고리즘(iTeC)
- 미러 디센트 정책 최적화와 리브-원-아웃(leave-one-out) 이점 추정기를 사용한 인간 피드백을 통한 강화 학습(MDLOO) 알고리즘
이 두 알고리즘은 강화 학습 반복에 사용되어 모델 품질을 크게 향상시킵니다.
데이터
애플은 사후 학습 파이프라인에서 인간 주석과 합성 데이터를 모두 포함하는 하이브리드 데이터 전략을 사용합니다. 데이터 수집 및 실험 과정 전반에 걸쳐 데이터 품질이 모델 성공의 핵심이라는 것을 발견했으며, 따라서 광범위한 데이터 큐레이션 및 필터링 절차를 수행했습니다.
인간 주석
시연 데이터
AFM의 지시 미세 조정을 위해 다양한 출처에서 고품질 인간 주석 시연 데이터셋을 수집합니다. 이 대화 스타일 데이터는 시스템 수준 및 작업 수준 지시(프롬프트)와 해당 응답으로 구성됩니다. Zhou 등의 연구와 유사하게, 실험에서 데이터의 양보다 품질이 더 중요하다는 것을 관찰했습니다. 결과적으로 애플 인텔리전스 기능을 다루는 다양한 작업 분포를 목표로 하는 것 외에도, 유용성, 무해성, 표현, 응답 정확성과 같은 주요 데이터 품질 기준에 중점을 둡니다. 사용자 개인정보를 보호하기 위해 데이터에 개인 식별 정보가 없는지 확인하는 단계를 취하고, 사용자가 애플에 저장한 개인 데이터는 포함하지 않습니다.
인간 선호도 피드백
AFM의 능력을 반복적으로 개선하기 위해 강화 학습을 위한 인간 피드백을 추가로 수집합니다. 특히, 인간 주석자에게 동일한 프롬프트에 대한 두 가지 모델 응답을 비교하고 순위를 매기도록 지시하여 나란히 비교 선호도 레이블을 수집합니다. 또한 이 과정을 안내하기 위해 단일 측면 질문도 사용합니다. 이러한 질문은 평가자가 지시 따르기, 안전성, 사실성, 표현 등 다양한 측면에서 모델 응답 품질을 평가하도록 안내하며, 모델 훈련을 위해 이러한 레이블도 유지합니다. 이 과정에서 애플의 가치와 기준을 강조합니다. 시연 데이터와 마찬가지로 피드백 데이터에서도 데이터 품질이 중요하다는 것을 발견했으며, 따라서 통합된 플라이휠에서 데이터와 모델 품질을 공동으로 반복하여 개선합니다.
합성 데이터
인간 주석 외에도 합성 데이터 생성을 통해 데이터 품질과 다양성을 향상시키는 방법을 탐구합니다. 강력한 보상 모델의 안내를 받을 때 AFM이 고품질 응답을 생성할 수 있으며, 일부 특정 도메인에서는 이러한 응답이 인간 주석과 동등하거나 심지어 더 우수한 것으로 나타났습니다. 따라서 다양성을 높이기 위해 프롬프트 세트를 확장하고, 생성된 응답이 AFM 자체에 도움이 될 수 있다는 것을 발견했습니다. 다음은 AFM 사후 학습을 위해 합성 데이터를 생성하는 세 가지 도메인에 대해 논의합니다. 수학, 도구 사용, 코딩.
수학
수학 분야에서는 광범위한 주제와 난이도 수준으로 인해 인간 시연을 수집하는 것이 매우 자원 집약적입니다. 이는 인간 작성자의 전문 지식이 필요하기 때문입니다. 또한 모델이 지속적으로 개선됨에 따라 인간이 작성한 콘텐츠에만 의존하는 것은 비현실적이 됩니다. 결과적으로 이러한 과제를 효과적으로 해결하기 위해 합성 데이터의 잠재력을 탐색하는 것이 필수적입니다.
수학을 위한 합성 데이터 생성에는 두 가지 주요 단계가 포함됩니다. 합성 수학 문제 생성과 해당 솔루션 생성입니다. 수학 문제 합성을 위해 시드 프롬프트 세트를 훨씬 더 큰 다양한 프롬프트 세트로 변환하는 여러 “진화” 전략을 사용합니다.
-
문제 재구성 및 역전: Yu 등의 접근 방식을 따라 AFM에 시드 수학 질문을 재구성하도록 프롬프트하고, 최종 답변이 제공될 때 원시 문제 진술에서 특정 숫자를 도출하기 위한 역방향 질문을 큐레이션합니다.
-
문제 진화: Xu 등의 지시 진화 기법에서 영감을 받아, 시드 문제 세트 $\mathcal{D}_{\text{seed}}$가 주어지면 AFM에 두 가지 서로 다른 수학 문제 세트를 생성하도록 프롬프트합니다.
- $F(\mathcal{D}_{\text{seed}})\xrightarrow[\text{}]{\scriptstyle\text{depth}}\mathcal{D}_{\text{depth}}$
- $F(\mathcal{D}_{\text{seed}})\xrightarrow[\text{}]{\scriptstyle\text{breadth}}\mathcal{D}_{\text{breadth}}$
심층 진화는 복잡성을 추가하여 지시를 향상시키는 반면, 광범위한 진화는 주제 범위를 개선합니다. $\mathcal{D}_{\text{breadth}}$와 $\mathcal{D}_{\text{depth}}$ 모두에 대해 먼저 임베딩 모델로 중복 제거를 수행한 다음, 수학 문제의 일관성과 해결 가능성을 보장하기 위해 LLM에 프롬프트합니다. 또한 $\mathcal{D}_{\text{depth}}$에는 난이도 수준이 할당되며, 지정된 임계값 이상의 점수를 받은 수학 문제만 선택합니다.
확장된 수학 질문 세트를 사용하여 AFM에 질문당 체인 오브 소트(chain-of-thought)를 포함한 $N$개의 응답을 합성하도록 프롬프트합니다. 초기 시드 데이터에 정답이 있는 경우, 이를 “결과 보상 신호”로 사용하여 합성된 답변을 필터링할 수 있습니다. 추론 단계가 적은 문제의 경우, 올바른 최종 답변이 종종 올바른 중간 단계와 연관된다는 것을 관찰했습니다. 직접적인 답변 확인이 실패하거나 정답을 사용할 수 없는 경우, LLM 판사를 쿼리하여 응답의 정확성을 평가합니다. 필터링된 답변을 훈련 데이터에 공급하면 모델의 수학 능력이 크게 향상된다는 것을 발견했습니다.
도구 사용
함수 호출, 코드 인터프리터, 브라우징과 같은 도구 사용 기능을 합성 데이터와 인간 데이터의 혼합을 통해 개발합니다. 모델 기능은 먼저 단일 도구 사용 사례에 초점을 맞춘 합성 데이터로 부트스트랩됩니다. 그런 다음 다중 도구 및 다단계 시나리오를 포함하는 모델 기능을 개선하기 위해 인간 주석을 수집합니다. 또한 도구 선택의 난이도를 높이기 위해 오라클 도구를 다른 유사한 도구와 혼합하여 인간이 큐레이션한 함수 호출 데이터를 보강합니다. 또한 인간이 큐레이션한 함수 호출 데이터에서 병렬 함수 호출을 합성하여 새로운 기능을 활성화하고, 인간이 큐레이션한 함수 호출 및 일반 SFT 데이터를 기반으로 도구 의도 감지 데이터를 합성하여 도구 호출 과잉 트리거 문제를 완화합니다.
코딩
합성 코딩 데이터셋의 생성에는 거부 샘플링을 사용한 자체 지시 방법이 포함됩니다. 이 접근 방식을 통해 모델은 자율적으로 데이터를 학습하고 생성할 수 있습니다. 71개의 다양한 프로그래밍 주제를 시드로 시작하여 모델에 코딩 인터뷰와 같은 질문의 초기 풀을 생성하도록 프롬프트합니다. 각 질문에 대해 모델은 일련의 단위 테스트와 여러 가능한 솔루션을 생성합니다. 그런 다음 실행 기반 거부 샘플링 방법을 사용하여 최상의 솔루션을 선택합니다. 이는 각 잠재적 솔루션을 모든 단위 테스트와 함께 컴파일하고 실행하는 것을 포함합니다. 가장 많은 성공적인 실행을 가진 솔루션이 선택됩니다. 이는 (질문, 테스트 케이스, 솔루션) 트리플의 컬렉션을 생성합니다. 마지막으로 통과한 단위 테스트 수를 사용하여 트리플을 필터링함으로써 데이터셋의 품질을 검증하여 SFT에 사용되는 12K의 고품질 트리플을 얻습니다.
지도 학습 미세 조정(SFT)
다중 작업 지시 튜닝을 확장하면 다양한 작업에서 모델 성능이 크게 향상된다는 것이 Chung 등에 의해 입증되었습니다. 마찬가지로, 애플은 후속 정렬을 위한 강력한 기본 모델을 달성하기 위해 지도 학습 미세 조정 데이터를 확장하려고 시도합니다. SFT 동안 주어진 프롬프트에 대한 시연 데이터에 대해 모델을 수집하고 훈련합니다. 프롬프트는 가장 최근의 사용자 지시뿐만 아니라 이전의 모든 사용자-모델-시스템 상호작용으로 구성될 수 있습니다. 다양한 자연어 사용 사례를 다루는 고품질 혼합물을 형성하기 위해 인간 데이터와 합성 데이터를 모두 신중하게 선택하고 결합합니다.
데이터 선택
모델 훈련을 위해 데이터를 온보딩하기 전에 일련의 품질 가드를 설정합니다. 여기에는 사내 인간 레이블러의 평가, 자동 모델 기반 필터링 기술, 텍스트 임베딩을 통한 중복 제거가 포함됩니다. 또한 앞선 절에서 설명한 다양한 합성 데이터 생성 방법과 앞선 절에서 설명한 거부 샘플링을 통해 혼합물 크기를 확장합니다.
혼합 비율 조정
혼합 가중치를 조정하기 위해 이를 최적화 문제로 취급합니다. 구체적으로, 가중치 세트 $(w_{1},w_{2},…,w_{n})$가 주어지면, 여기서 $w_{i}$는 혼합물에서 특정 구성 요소의 비율을 나타내며, $w_{i}\rightarrow w_{i}\pm\Delta w_{i}$로 모델을 훈련하고 일련의 벤치마크에서 품질 변화를 평가합니다. 이러한 실험을 광범위하게 실행하면 최상의 혼합물을 효과적으로 식별하고 영향이 가장 적은 데이터 구성 요소를 제거할 수 있다는 것을 발견했습니다.
훈련 하이퍼파라미터
모델은 AFM-서버의 경우 $5\mathrm{e}{-6}$, AFM-디바이스 모델의 경우 $2\mathrm{e}{-5}$의 일정한 학습률과 $0.1$의 드롭아웃 비율로 훈련됩니다. 평가 메트릭이 다른 체크포인트에 걸쳐 변동하기 때문에, 자동 평가 벤치마크를 기반으로 체크포인트 선택을 실행하고 RL에 대한 헤드룸을 테스트하기 위해 보상 모델로 best-of-N 선택을 수행합니다.
인간 피드백을 통한 강화 학습(RLHF)
수집된 인간 선호도 데이터를 사용하여 강화 학습을 추가로 적용하여 모델 성능과 품질을 개선합니다. 이는 강력한 보상 모델을 훈련하고 이를 아래에서 논의할 iTeC와 MDLOO라는 두 가지 알고리즘에 적용하는 것을 포함합니다. RLHF 파이프라인에 대한 자세한 내용은 부록 E에 설명되어 있습니다.
보상 모델링
앞선 절의 방법으로 수집된 인간 선호도 데이터를 사용하여 보상 모델을 훈련합니다. 각 인간 선호도 데이터 항목에는 하나의 프롬프트와 두 개의 응답이 포함되며, 다음과 같은 인간 레이블이 포함됩니다.
- 두 응답 중 선호되는 응답과 선호도 수준, 즉 선호되는 응답이 거부된 응답보다 현저히 더 좋은지, 더 좋은지, 약간 더 좋은지, 또는 무시할 만큼 더 좋은지 여부
- 각 응답의 단일 측면 평가, 지시 따르기 속성, 간결성, 진실성, 각 응답의 무해성을 측정
보상 모델 훈련은 RLHF에서 보상 모델링의 표준 관행을 따르며 두 가지 주요 혁신이 있습니다.
- 인간 선호도 수준을 고려하는 소프트 레이블 손실 함수를 설계합니다.
- 보상 모델링에서 정규화 항으로 단일 측면 평가를 통합합니다.
RLHF에서 보상 모델링을 위해 일반적으로 사용되는 Bradley-Terry-Luce(BTL) 모델(Bradley와 Terry)을 사용합니다. 이 모델에서 인간 주석자가 한 응답을 다른 응답보다 선호할 확률은 보상의 차이에 대한 시그모이드 함수로 모델링됩니다. 소프트 레이블 손실 함수는 선호도 수준이 높을 때, 예를 들어 한 응답이 다른 응답보다 현저히 더 좋을 때 이 확률이 높도록 장려하고, 그 반대의 경우도 마찬가지입니다. 이는 Llama 2(Touvron 등)에서의 마진 기반 손실 함수와 다르며, 이 또한 선호도 수준을 활용합니다. 경험적으로 애플의 방법이 마진 기반 손실 함수보다 더 잘 작동한다는 것을 발견했습니다. 또한 단일 측면 평가를 정규화 항으로 사용하면 보상 모델의 정확도를 효과적으로 개선할 수 있다는 것을 발견했습니다. 보상 모델링 기법에 대한 자세한 내용은 E.1절에서 찾을 수 있습니다.
반복적 교사 위원회(iTeC)
여러 라운드의 RLHF로 모델의 능력을 완전히 활용하기 위해, 거부 샘플링(RS), 직접 선호도 최적화(DPO)(Rafailov 등)와 IPO(Azar 등)와 같은 변형, 온라인 강화 학습(RL)을 포함한 다양한 선호도 최적화 알고리즘을 효과적으로 결합하는 새로운 반복적 RLHF 프레임워크를 제안합니다. 이를 통해 모든 크기의 AFM 모델에 RLHF의 이점을 제공하고 동시에 정렬을 개선할 수 있습니다.
반복적 위원회
AFM RLHF를 개발하면서 배운 가장 중요한 교훈 중 하나는 다양한 최고 성능 모델 세트를 사용하여 온라인 인간 선호도 데이터 수집을 새로 고치는 것입니다. 구체적으로, 각 배치의 인간 선호도 데이터 수집을 위해 SFT, RS, DPO/IPO, RL에서 훈련된 최신 유망 모델과 이전 반복에서의 최고 모델을 포함하는 “모델 위원회”를 설정합니다. 최신 모델 위원회에서 샘플링된 응답에 대한 쌍별 인간 선호도를 수집합니다. 각 배치의 인간 선호도 데이터를 획득한 후, 보상 모델을 새로 고치고, 선호도 최적화 알고리즘 컬렉션을 사용하여 새로운 모델 세트를 추가로 훈련합니다. 그런 다음 새로운 모델 위원회로 다음 라운드의 반복적 RLHF 데이터 수집을 계속합니다.
위원회 증류
또한 최신 보상 모델을 재순위 지정자로 사용하여 모델 위원회에서 거부 샘플링(증류)을 실행합니다. 글로벌 수준에서 재순위를 지정하는 대신, 즉 위원회에서 단일 최고 성능 모델을 선택하고 이를 교사 모델로 사용하는 대신, 프롬프트 수준에서 모델 응답의 순위를 다시 매깁니다. 구체적으로, 각 프롬프트에 대해 위원회의 각 모델에서 여러 응답을 샘플링하고, 최신 보상 모델을 사용하여 각 프롬프트에 대한 최상의 응답을 선택합니다. 이를 통해 다양한 선호도 최적화 알고리즘으로 훈련된 모델의 장점을 결합할 수 있습니다. 예를 들어, 온라인 RLHF, DPO, IPO와 같이 부정적인 예제를 활용하는 알고리즘이 수학과 같은 추론 기술을 개선하는 데 더 나은 반면, 거부 샘플링 미세 조정은 지시 따르기와 글쓰기 기술을 더 효과적으로 학습한다는 것을 발견했습니다.
증류 확장
모든 크기의 AFM 모델에 RLHF 개선 사항을 적용하기 위해 모델 위원회에서 증류를 확장합니다. 데이터와 모델 품질을 신중하게 반복하는 것이 데이터 양보다 훨씬 더 중요한 더 큰 모델과 달리, 작은 모델은 증류를 위한 프롬프트 수를 확장할 때 엄청난 개선을 달성할 수 있다는 것을 발견했습니다. 최종 AFM-온디바이스 모델은 모델 위원회에서 생성된 100만 개 이상의 고품질 응답으로 훈련되었습니다.
온라인 RLHF 알고리즘: MDLOO
이 섹션에서는 모델 훈련 중에 응답을 디코딩하고 보상을 최대화하기 위해 RL 알고리즘을 적용하는 온라인 강화 학습 알고리즘 MDLOO를 소개합니다. 일반적으로 채택된 RLHF 목표를 사용하여 KL-페널티 보상 함수(Ouyang 등)를 최대화합니다.
\[\max_{\theta}\mathbb{E}_{x\sim\mathcal{D},y\sim\pi_{\theta}(\cdot|x)}\left[r_{\phi}(x,y)-\beta D_{\text{KL}}\left(\pi_{\theta}(\cdot|x)\|\pi_{\text{ref}}(\cdot|x)\right)\right],\]여기서 $\mathcal{D}$는 프롬프트 분포, $D_{\text{KL}}(\cdot|\cdot)$은 두 분포 간의 Kullback-Leibler 발산을 나타내며, $\beta$는 행동 정책 $\pi_{\theta}$와 참조 정책 $\pi_{\text{ref}}$ 사이의 발산을 제어하는 계수입니다. 참조 정책은 일반적으로 SFT로 훈련된 모델입니다. RL 훈련에서는 다음과 같은 보상 함수를 사용합니다.
\[R(x,y)=r_{\phi}(x,y)-\beta\log\frac{\pi_{\theta}(y|x)}{\pi_{\text{ref}}(y|x)},\]이 기대값은 위의 식과 동등합니다. 전체 응답의 생성을 하나의 행동으로 간주하는 밴딧 설정을 고려하며, 토큰별 보상이나 이점을 얻기 위해 가치 네트워크(비평가)를 사용하지 않습니다. PPO(Schulman 등)와 같이 일반적으로 사용되는 RLHF 알고리즘과 유사하게 신뢰 영역 기반 정책 반복 알고리즘을 사용합니다. 온라인 RL 알고리즘에서 두 가지 주요 설계 선택을 했습니다.
- 최근 연구(Ahmadian 등)과 유사하게 프롬프트-응답 쌍의 이점을 추정하기 위해 Leave-One-Out(LOO) 추정기를 사용합니다.
- 더 일반적으로 사용되는 클리핑 기반 PPO 방법과 달리 정책을 최적화하기 위해 Mirror Descent Policy Optimization(MDPO)(Tomar 등)을 사용합니다.
따라서 온라인 RL 알고리즘을 Mirror Descent with Leave-One-Out estimation(MDLOO)이라고 명명합니다.
더 구체적으로, 알고리즘의 디코딩 단계에서 각 프롬프트에 대해 여러 응답을 디코딩하고, 각 응답의 이점을 (프롬프트, 응답) 쌍의 보상과 동일한 프롬프트에 의해 생성된 다른 응답의 평균 보상의 차이로 할당합니다. 직관적으로, 이 추정기는 응답이 일반적인 응답보다 얼마나 더 나은지 측정하는 것을 목표로 합니다. 경험적으로 이 이점 추정기가 RL 알고리즘을 안정화하고 강력한 결과를 달성하는 데 중요하다는 것을 발견했습니다.
또한 각 반복에서 정책 변경을 제어하기 위해 KL-정규화 기반 신뢰 영역 방법, 즉 MDPO를 사용합니다. 이 알고리즘이 애플의 설정에서 PPO보다 더 효과적이라는 것을 발견했습니다. 온라인 RLHF 알고리즘에 대한 자세한 내용은 E.2절에서 찾을 수 있습니다.
애플 인텔리전스 기능 구동하기
애플 인텔리전스는 지원되는 아이폰, 아이패드, 맥 모델에 통합된 개인 인텔리전스 시스템입니다. 이 시스템을 위해 설계된 애플의 파운데이션 모델은 빠르고 효율적으로 작동하도록 구축되었습니다. 기본 모델이 광범위한 기능에서 인상적인 수준의 성능을 달성했지만, 실제로 중요한 품질 측정 기준은 운영 체제 전반에 걸친 특정 작업에서의 성능입니다. 애플은 작업별 미세 조정을 통해 작은 모델의 성능도 최고 수준으로 끌어올릴 수 있다는 것을 발견했으며, 런타임에 교체 가능한 어댑터를 기반으로 하는 아키텍처를 개발하여 단일 파운데이션 모델이 수십 가지의 특정 작업에 특화될 수 있도록 했습니다.
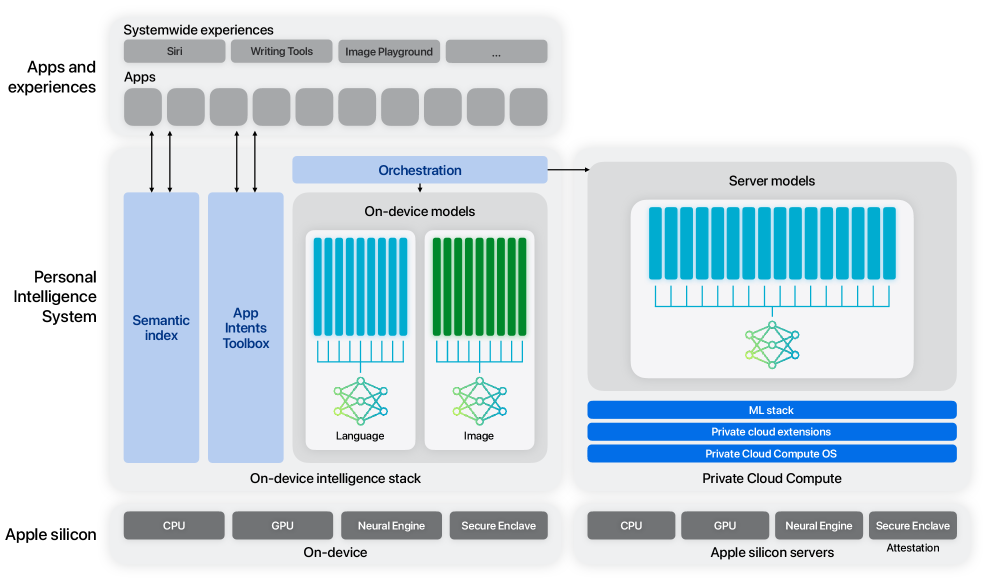
그림 2: 언어 온디바이스 및 서버 모델과 이미지 모델을 위한 어댑터가 있는 애플 인텔리전스 아키텍처. 이 보고서에서는 텍스트 모델만 설명합니다.
이 그림은 언어 및 이미지 처리를 위한 온디바이스 모델과 서버 측 모델을 포함하는 애플의 개인 인텔리전스 시스템 아키텍처를 보여줍니다. 주요 구성 요소는 다양한 애플 실리콘 컴포넌트를 활용하는 온디바이스 인텔리전스 스택과 온디바이스 및 서버 측 모델을 통합하는 오케스트레이션 레이어입니다. 이 그림은 언어 모델과 이미지 모델 간의 분리를 강조하며, 이 보고서는 텍스트 기반 온디바이스 모델과 이들의 더 넓은 시스템과의 통합에 초점을 맞추고 있습니다.
어댑터 아키텍처
애플의 파운데이션 모델은 사용자의 일상 활동에 맞게 미세 조정되었으며, 현재 작업에 맞게 동적으로 특화될 수 있습니다. 이를 위해 Hu와 연구진이 제안한 LoRA 어댑터를 사용합니다. LoRA 어댑터는 기본 모델의 다양한 레이어에 연결될 수 있는 작은 신경망 모듈로, 특정 작업에 맞게 모델을 미세 조정합니다. 각 작업에 대해 AFM의 셀프 어텐션 레이어의 모든 선형 투영 행렬과 포인트와이즈 피드포워드 네트워크의 완전 연결 레이어를 조정합니다.
어댑터만 미세 조정함으로써 사전 훈련된 기본 모델의 원래 매개변수는 변경되지 않고 유지되어, 모델의 일반적인 지식을 보존하면서 특정 작업을 지원하도록 어댑터를 조정할 수 있습니다. 어댑터 매개변수는 16비트로 표현되며, 약 30억 개의 매개변수를 가진 온디바이스 모델의 경우 랭크 16 어댑터의 매개변수는 일반적으로 수십 메가바이트가 필요합니다.
어댑터 모델은 동적으로 로드되고 메모리에 임시로 캐시되며 교체될 수 있어, 파운데이션 모델이 현재 작업에 맞게 실시간으로 특화될 수 있으면서도 메모리를 효율적으로 관리하고 운영 체제의 응답성을 보장할 수 있습니다. 어댑터 훈련을 용이하게 하기 위해 애플은 기본 모델이나 훈련 데이터가 업데이트되거나 새로운 기능이 필요할 때 어댑터를 빠르게 추가, 재훈련, 테스트 및 배포할 수 있는 효율적인 인프라를 구축했습니다. 어댑터 매개변수는 앞선 절에서 소개된 정확도 복구 어댑터를 사용하여 초기화된다는 점도 주목할 만합니다.
최적화
AFM 모델은 사용자의 일상 활동 전반에 걸쳐 지원하도록 설계되었으며, 추론 지연 시간과 전력 효율성은 전반적인 사용자 경험에 중요합니다. 애플은 AFM이 온디바이스 및 프라이빗 클라우드 컴퓨트에 효율적으로 배포될 수 있도록 다양한 최적화 기법을 적용합니다. 이러한 기법은 전체 모델 품질을 유지하면서 메모리, 지연 시간 및 전력 사용량을 크게 줄입니다.
AFM을 엣지 디바이스의 제한된 메모리 예산에 맞추고 추론 비용을 줄이기 위해서는 모델 품질을 유지하면서 가중치당 효과적인 비트 수를 줄이는 모델 양자화 기법을 적용하는 것이 중요합니다. 이전 연구에서는 4비트 양자화 모델이 원래 32/16비트 부동 소수점 버전에 비해 품질 손실이 미미하다는 것을 발견했습니다(일반적으로 사전 훈련 메트릭으로 측정됨). AFM은 다양한 제품 기능을 지원할 것으로 예상되므로, 양자화된 모델이 이러한 사용 사례에 중요한 특정 도메인의 기능을 유지하는 것이 필수적입니다.
모델 용량과 추론 성능 사이의 최적의 균형을 달성하기 위해 애플은 최첨단 양자화 방법과 정확도 복구 어댑터를 활용하는 프레임워크를 개발했습니다. 이를 통해 가중치당 평균 4비트 미만의 거의 무손실 양자화를 달성하고 유연한 양자화 스킴 선택을 제공할 수 있습니다.
방법론
모델은 사후 훈련 단계 이후에 압축되고 양자화되며, 평균적으로 가중치당 4비트 미만으로 처리됩니다(양자화 스킴에 대한 자세한 내용은 나중에 논의됨). 양자화된 모델은 종종 중간 수준의 품질 손실을 보입니다. 따라서 양자화된 모델을 직접 애플리케이션 팀에 전달하여 기능 개발을 진행하는 대신, 품질 복구를 위한 매개변수 효율적인 LoRA 어댑터 세트를 연결합니다. 이러한 LoRA 어댑터 훈련 레시피가 사전 훈련 및 사후 훈련 프로세스와 일관되도록 합니다. 그런 다음 제품 팀은 양자화된 기본 모델을 고정한 상태에서 정확도 복구 어댑터에서 어댑터 가중치를 초기화하여 자체 기능별 LoRA 어댑터를 미세 조정합니다.
정확도 복구 어댑터 훈련은 샘플 효율적이며 기본 모델 훈련의 미니 버전으로 간주될 수 있습니다. 어댑터의 사전 훈련 단계에서는 양자화된 모델의 용량을 완전히 복구하기 위해 약 100억 개의 토큰(기본 모델 훈련의 약 0.15%)만 필요합니다. 애플리케이션 어댑터는 이러한 정확도 복구 어댑터에서 미세 조정되므로 추가적인 메모리 사용이나 추론 비용이 발생하지 않습니다.
어댑터 크기와 관련하여, 랭크 16 어댑터가 모델 용량과 추론 성능 사이의 최적의 균형을 제공한다는 것을 발견했습니다. 그러나 다양한 사용 사례에 유연성을 제공하기 위해 애플리케이션 팀이 선택할 수 있는 다양한 랭크 ${8, 16, 32}$의 정확도 복구 어댑터 세트를 제공합니다. 부록 F에서는 비양자화, 양자화 및 복구된 모델 간의 자세한 평가 결과를 제공하며, 복구된 모델이 비양자화 버전에 훨씬 더 가깝게 수행된다는 것을 보여줍니다.
양자화 스킴
정확도 복구 어댑터가 가져오는 또 다른 이점은 더 유연한 양자화 스킴 선택을 가능하게 한다는 것입니다. 이전에 LLM을 양자화할 때, 일반적으로 가중치를 작은 블록으로 그룹화하고, 각 블록을 해당 최대 절대값으로 정규화하여 이상치를 필터링한 다음, 블록 단위로 양자화 알고리즘을 적용했습니다. 더 큰 블록 크기는 가중치당 더 낮은 효과적인 비트와 더 높은 처리량을 제공하지만, 양자화 손실이 증가합니다. 이러한 균형을 맞추기 위해 일반적으로 블록 크기를 64나 32와 같은 작은 값으로 설정합니다.
애플의 실험에서는 정확도 복구 어댑터가 이러한 균형에서 파레토 프론티어를 크게 개선할 수 있다는 것을 발견했습니다. 더 공격적인 양자화 스킴에서 더 많은 오류가 복구됩니다. 결과적으로 모델 용량을 잃을 걱정 없이 AFM에 고효율 양자화 스킴을 사용할 수 있게 되었습니다.
구체적으로, 애플 뉴럴 엔진(ANE)에서 실행되는 AFM-온디바이스 모델은 팔레타이제이션을 사용합니다. 투영 가중치의 경우, 모든 16개의 열/행이 동일한 양자화 상수(즉, 룩업 테이블)를 공유하고 K-평균을 사용하여 16개의 고유 값(4비트)으로 양자화됩니다. 양자화 블록 크기는 최대 10만까지 가능합니다. 또한 AFM의 임베딩 레이어는 입력과 출력 사이에 공유되므로 ANE에서 투영 레이어와 다르게 구현됩니다. 따라서 더 나은 효율성을 위해 채널별 양자화와 8비트 정수를 사용하여 임베딩을 양자화합니다.
혼합 정밀도 양자화
잔차 연결은 AFM의 모든 트랜스포머 블록과 모든 레이어에 존재합니다. 따라서 모든 레이어가 동일한 중요성을 갖는 것은 아닙니다. 이러한 직관에 따라 메모리 사용량을 더욱 줄이기 위해 일부 레이어를 2비트 양자화(기본값은 4비트)로 전환합니다. 평균적으로 AFM-온디바이스는 상당한 품질 손실 없이 가중치당 약 3.5비트(bpw)로 압축될 수 있습니다. 애플은 이미 메모리 요구 사항을 충족하기 때문에 생산에서는 3.7 bpw를 사용하기로 결정했습니다.
대화형 모델 분석
애플은 각 작업에 대한 비트 레이트 선택을 더 잘 안내하기 위해 Hohman과 연구진이 개발한 Talaria라는 대화형 모델 지연 시간 및 전력 분석 도구를 사용합니다.
추가 논의
양자화된 모델과 LoRA 어댑터의 사용은 개념적으로 Dettmers와 연구진이 제안한 QLoRA와 유사해 보입니다. QLoRA는 미세 조정 중에 계산 리소스를 절약하기 위해 설계된 반면, 애플의 초점은 다양한 LoRA 어댑터 간에 전환하여 다양한 특정 사용 사례에서 높은 성능을 효율적으로 지원하는 능력에 있습니다. 기능별 미세 조정 전에 먼저 동일한 사전 훈련 및 사후 훈련 데이터에 대해 정확도 복구 어댑터를 훈련하는데, 이는 모델 품질을 보존하는 데 중요합니다.
정확도 복구 프레임워크는 Frantar와 연구진이 제안한 GPTQ 및 Lin과 연구진이 제안한 AWQ와 같은 다양한 양자화 기법과 결합될 수 있습니다. 이는 양자화 방법 자체에 직접적으로 의존하지 않기 때문입니다. 앞선 절에서 설명한 기능 어댑터는 이러한 정확도 복구 어댑터에서 초기화됩니다.
사례 연구: 요약
애플은 AFM-온디바이스 모델을 사용하여 요약 기능을 구현합니다. 디자인 팀과 협력하여 이메일, 메시지 및 알림에 대한 요약 사양을 만들었습니다. AFM-온디바이스는 일반적인 요약에 능숙하지만, 사양을 엄격하게 준수하는 요약을 유도하기는 어렵다는 것을 발견했습니다. 따라서 요약을 위해 양자화된 AFM-온디바이스 위에 LoRA 어댑터를 미세 조정합니다. 이 어댑터는 앞선 절에서 설명한 대로 정확도 복구 어댑터에서 초기화됩니다.
이메일, 메시지 및 알림을 다루는 입력 페이로드로 구성된 데이터 혼합물을 사용합니다. 이러한 페이로드에는 공개 데이터셋, 벤더 데이터 및 내부적으로 생성 및 제출된 예제가 포함됩니다. 모든 데이터는 생산에 사용하도록 승인되었습니다. 벤더 데이터와 내부적으로 생성된 데이터는 사용자 정보를 제거하기 위해 익명화되었습니다. 이러한 페이로드가 주어지면, 제품 요구 사항에 따라 AFM-서버를 사용하여 합성 요약을 생성합니다. 이러한 페이로드와 요약은 훈련에 사용됩니다.
합성 요약
AFM-서버를 사용하여 합성 요약을 생성합니다. 규칙 기반 필터와 모델 기반 필터를 연속적으로 적용합니다. 규칙 기반 필터는 길이 제약, 형식 제약, 관점, 어조 등과 같은 휴리스틱을 기반으로 합니다. 모델 기반 필터는 함의와 같은 더 어려운 문제를 선별하는 데 사용됩니다. 이 합성 데이터 파이프라인을 통해 대량의 훈련 데이터를 효율적으로 생성하고 미세 조정을 위한 고품질 예제를 유지하기 위해 한 차수만큼 필터링할 수 있습니다.
프롬프트 주입
AFM-온디바이스는 입력 콘텐츠에 있는 지시사항을 따르거나 질문에 답하는 경향이 있어 요약하는 대신 이러한 내용을 처리하는 경우가 있다는 것을 발견했습니다. 이 문제를 완화하기 위해 휴리스틱을 사용하여 이러한 콘텐츠가 포함된 많은 예제를 식별하고, 유사한 행동을 보이지 않는 AFM-서버를 사용하여 요약을 생성한 다음, 이 합성 데이터셋을 미세 조정 데이터 혼합물에 추가합니다.
평가
AFM 모델은 사전 학습, 사후 학습, 그리고 가장 중요하게는 기능별 벤치마크에서 평가됩니다.
사전 학습 평가
이 섹션에서는 일반적인 퓨 샷 사전 학습 평가 지표를 제시합니다. 이러한 벤치마크는 사전 학습 진행 상황을 추적하는 데 유용하지만, 사후 학습된 모델과 기능 어댑터에 대한 인간 평가가 최종 사용자 경험과 더 밀접하게 연관되어 있음을 발견했습니다.
AFM 사전 학습 모델은 공개 소스 평가 도구와 벤치마크를 사용하여 평가됩니다. 표 2는 HELM MMLU v1.5.0에서 AFM-온디바이스와 AFM-서버의 결과를 보여줍니다. 이 벤치마크는 57개 과목에 걸쳐 5-샷 객관식 문제 해결 능력을 테스트합니다. 또한 표 3과 표 4는 각각 허깅페이스 OpenLLM 리더보드 V1과 HELM-Lite v1.5.0 벤치마크 스위트에서 AFM-서버의 결과를 보여줍니다. 이러한 벤치마크는 AFM 사전 학습 모델이 강력한 언어 및 추론 능력을 보유하고 있으며, 사후 학습 및 기능 미세 조정을 위한 견고한 기반을 제공한다는 것을 보여줍니다.
| AFM-온디바이스 | AFM-서버 | |
|---|---|---|
| MMLU (5 샷) | 61.4 | 75.4 |
표 2: HELM MMLU-5s v1.5.0 평가 결과.
| AFM-서버 | |
|---|---|
| MMLU (5-샷) | 75.3 |
| GSM8K (5-샷) | 72.4 |
| ARC-c (25-샷) | 69.7 |
| HellaSwag (10-샷) | 86.9 |
| Winogrande (5-샷) | 79.2 |
표 3: OpenLLM 리더보드 V1 평가 결과 일부.
| AFM-서버 | |
|---|---|
| Narrative QA | 77.5 |
| Natural Questions (open) | 73.8 |
| Natural Questions (closed) | 43.1 |
| Openbook QA | 89.6 |
| MMLU | 67.2 |
| MATH-CoT | 55.4 |
| GSM8K | 72.3 |
| LegalBench | 67.9 |
| MedQA | 64.4 |
| WMT 2014 | 18.6 |
표 4: HELM-Lite v1.5.0 사전 학습 평가 결과. 참고: 많은 벤치마크(예: MMLU)는 일반적으로 사용되는 설정과 크게 다릅니다.
사후 학습 평가
사후 학습 모델을 종합적인 벤치마크로 평가하고 다양한 오픈 소스 모델뿐만 아니라 GPT-3.5 및 GPT-4와도 비교합니다. 이 섹션에서 보고된 모든 결과는 어댑터 없이 bfloat16 정밀도로 AFM-온디바이스 및 AFM-서버 기본 모델을 사용하여 얻은 것입니다.
이 섹션에서는 먼저 AFM의 일반적인 능력을 측정하는 인간 평가 결과를 제시한 다음, 몇 가지 특정 능력과 도메인에 대한 결과를 제시합니다.
인간 평가
인간 평가는 실제 사용 사례와 사용자 피드백을 시뮬레이션하므로 종종 언어 모델 평가의 황금 표준으로 사용됩니다. 따라서 모델을 개발하는 동안과 최종 형태를 평가하기 위해 광범위한 인간 평가를 수행합니다.
다양한 측면을 테스트하기 위해 평가 프롬프트 세트를 수집하며, 여기에는 일반적인 능력과 안전성이 모두 포함됩니다. 각 프롬프트에 대해 두 개의 모델 응답이 인간 평가자에게 익명으로 제시되어 나란히 비교됩니다. 평가의 성격에 따라, 일관된 평가 기준과 평가 품질을 보장하기 위해 단일 응답 평가 및 나란히 선호도 평가의 예시가 포함된 상세한 가이드라인이 인간 평가자에게 제공됩니다. 각 모델 응답 쌍은 여러 평가자에 의해 평가되며, 그들의 평가는 최종 결과를 위해 집계됩니다.
전반적으로, 인간 평가가 사용자 경험과 더 잘 일치하고 LLM을 평가자로 사용하는 일부 학술 벤치마크보다 더 나은 평가 신호를 제공한다는 것을 발견했습니다.
일반적인 모델 능력을 평가하기 위해 1,393개의 포괄적인 프롬프트 세트를 수집했습니다. 이 프롬프트들은 다양한 난이도 수준에 걸쳐 있으며 분석적 추론, 브레인스토밍, 챗봇, 분류, 폐쇄형 질문 응답, 코딩, 추출, 수학적 추론, 개방형 질문 응답, 재작성, 안전성, 요약, 글쓰기와 같은 주요 카테고리를 다룹니다. 과적합을 방지하기 위해 훈련 데이터를 준비할 때 평가 프롬프트에 대한 오염 제거를 수행했습니다.
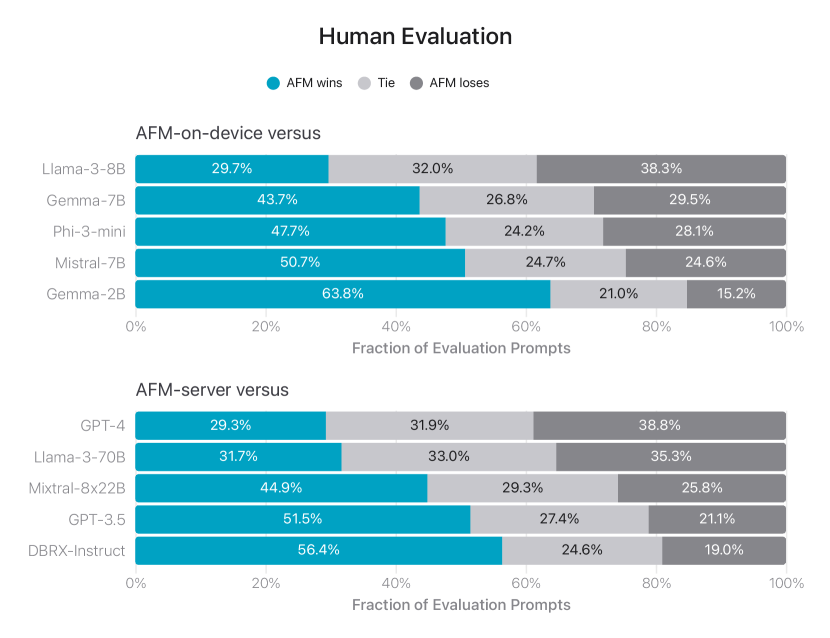
그림 3: AFM-온디바이스와 AFM-서버의 비교 모델 대비 나란히 평가. 인간 평가자들이 경쟁 모델보다 AFM 모델을 더 자주 선호하는 것으로 나타났습니다.
그림 3에서는 AFM을 오픈 소스 모델(Phi-3, Gemma-1.1, Llama-3, Mistral, DBRX-Instruct)과 상업용 모델(GPT-3.5, GPT-4) 모두와 비교합니다. AFM 모델은 인간 평가자들에 의해 경쟁 모델보다 선호됩니다. 특히, AFM-온디바이스는 모델 크기가 25% 더 작음에도 불구하고 Phi-3-mini와 비교했을 때 47.7%의 승률을 얻었으며, 심지어 매개변수 수가 두 배 이상 많은 오픈 소스 강력한 기준선인 Gemma-7B와 Mistral-7B보다 더 우수한 성능을 보였습니다. 폐쇄형 소스 모델과 비교했을 때, AFM-서버는 GPT-3.5에 대해 50% 이상의 승률과 27.4%의 동률을 기록하며 경쟁력 있는 성능을 달성했습니다.
지시 따르기
지시 따르기(IF)는 언어 모델에서 우리가 원하는 핵심 능력입니다. 실제 프롬프트는 종종 복잡한 지시사항을 포함하기 때문입니다. RLHF 데이터 수집과 인간 평가 모두에서 지시 따르기의 중요성을 강조합니다. 이 하위 섹션에서는 자동화된 벤치마크를 사용하여 모델의 IF 기술을 평가합니다.
그림 4에서는 AFM-온디바이스와 AFM-서버를 공개 IFEval 벤치마크에서 평가합니다. 이 벤치마크는 언어 모델이 프롬프트의 지시사항을 정확하게 따르는 응답을 생성하는 능력을 측정합니다. 이 벤치마크의 지시사항은 일반적으로 응답 길이, 형식, 내용 등에 대한 요구 사항을 포함합니다. AFM-온디바이스와 AFM-서버 모두 지시 수준과 프롬프트 수준 정확도에서 우수한 성능을 달성하는 것으로 나타났습니다.
또한 일반적인 지시 따르기 능력을 측정하기 위해 AlpacaEval 2.0 LC 벤치마크에서도 AFM 모델을 벤치마킹했으며, 결과는 모델이 매우 경쟁력 있다는 것을 시사합니다.
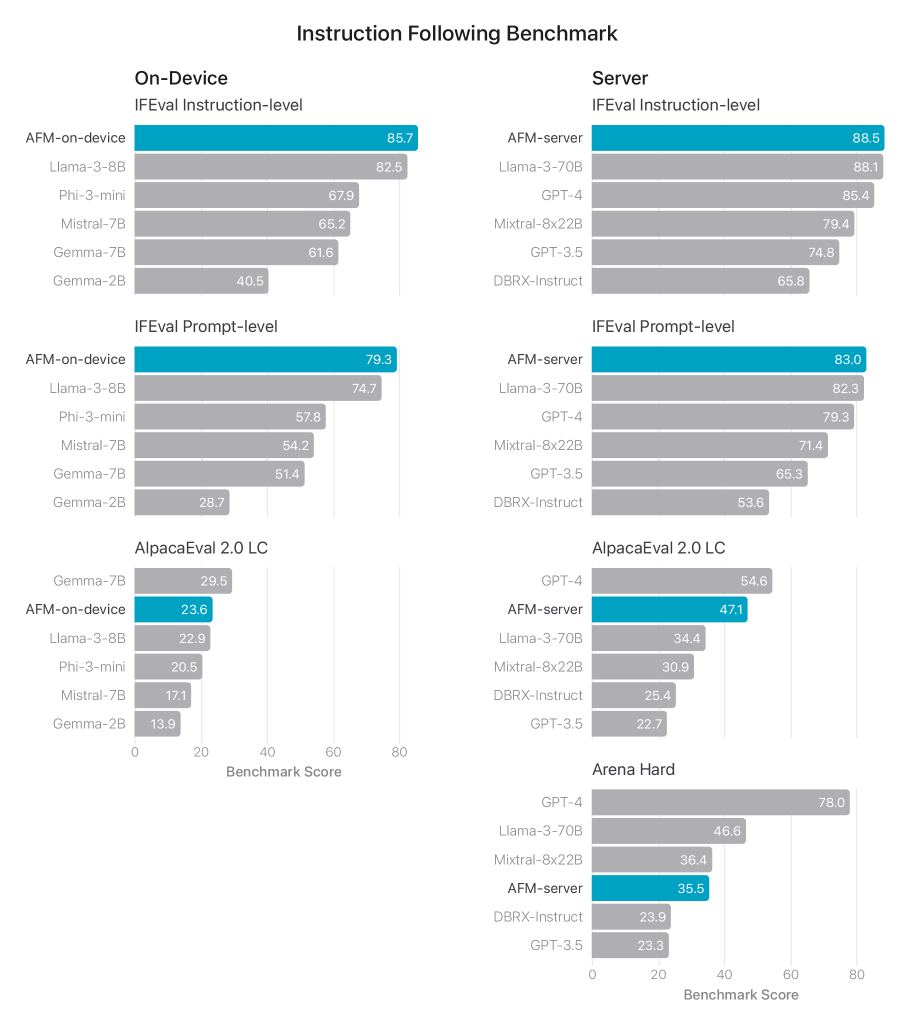
그림 4: AFM 모델과 관련 비교 모델의 지시 따르기 능력(IFEval로 측정, 높을수록 좋음). Mistral 7B, Llama3 8B, Llama3 70B, DBRX-Instruct, Mixtral 8x22B의 AlpacaEval 2.0 LC 결과는 AlpacaEval 리더보드에서 가져왔습니다. 비교 모델의 Arena Hard 결과는 Arena-Hard-Auto 리더보드에서 가져왔습니다. 다른 모든 결과는 자체 평가에서 얻은 것입니다.
도구 사용
도구 사용 애플리케이션에서는 사용자 요청과 설명이 포함된 잠재적 도구 목록이 주어지면, 모델은 호출할 도구의 이름과 매개변수 값을 지정하는 구조화된 출력을 제공하여 도구 호출을 발행할 수 있습니다. 도구 설명은 OpenAPI 사양을 따를 것으로 예상됩니다.
함수 호출의 네이티브 지원을 통해 Berkeley Function Calling Leaderboard 벤치마크에서 AST 메트릭을 사용하여 평가합니다. 그림 5에서 볼 수 있듯이, AFM-서버는 Gemini-1.5-Pro-Preview-0514와 GPT-4를 능가하며 전체적으로 최고의 정확도를 달성했습니다.
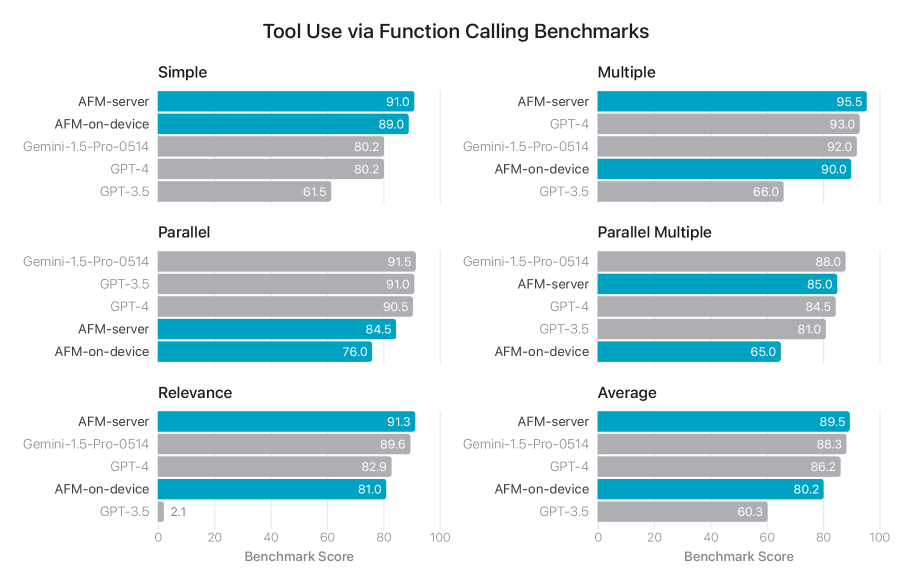
그림 5: 함수 호출 API에 대한 Berkeley Function Calling Leaderboard 벤치마크 평가 결과와 관련 비교 샘플. 숫자는 Gorilla 리더보드에서 수집되었습니다.
글쓰기
글쓰기는 대규모 언어 모델이 갖추어야 할 가장 중요한 능력 중 하나로, 어조 변경, 재작성, 요약과 같은 다양한 다운스트림 사용 사례를 가능하게 합니다. 그러나 글쓰기 품질을 평가하는 것은 간단한 작업이 아니며, 위의 공개 벤치마크에서 잘 다루어지지 않습니다.
다양한 글쓰기 지시사항으로 구성된 내부 요약 및 작문 벤치마크에서 AFM의 글쓰기 능력을 평가합니다. LLM-as-a-judge 방법론을 따라, 각 요약 및 작문 작업에 대한 평가 지시사항을 설계하고 GPT-4 Turbo에게 모델 응답에 대해 1부터 10까지의 점수를 할당하도록 프롬프트합니다. 평가자로 GPT-4를 사용하는 선택으로 인해 GPT-4 Turbo의 점수가 과대평가될 수 있다는 점에 유의합니다. LLM을 평가자로 사용하는 것과 관련된 길이 편향과 같은 특정 제한 사항과 편향이 있다는 점도 언급합니다.
AFM을 가장 뛰어난 모델 몇 개와 함께 더 작은 규모의 오픈 소스 모델과 비교합니다. 그림 6에서 볼 수 있듯이, AFM-온디바이스는 Gemma-7B와 Mistral-7B와 비교했을 때 비슷하거나 더 우수한 성능을 달성할 수 있습니다. AFM-서버는 DBRX-Instruct와 GPT3.5를 크게 능가하며 GPT4와 비슷한 수준입니다.

그림 6: AFM-온디바이스와 AFM-서버 및 관련 비교 샘플의 내부 요약 및 작문 벤치마크에서의 글쓰기 능력(높을수록 좋음). 모델이 관련 모델보다 더 좋거나 비슷한 성능을 보이는 것으로 나타났습니다.
수학
그림 7에서는 GSM8K와 MATH를 포함한 수학 벤치마크에서 사후 학습 AFM의 성능을 비교합니다. GSM8K에는 8-샷 체인 오브 소트(CoT) 프롬프트를 사용하고 MATH에는 4-샷 CoT 프롬프트를 사용합니다. 모든 평가는 내부 자동화된 평가 파이프라인을 사용하여 수행됩니다. AFM-온디바이스가 크기가 절반 이하임에도 불구하고 Mistral-7B와 Gemma-7B를 크게 능가하는 것을 볼 수 있습니다.
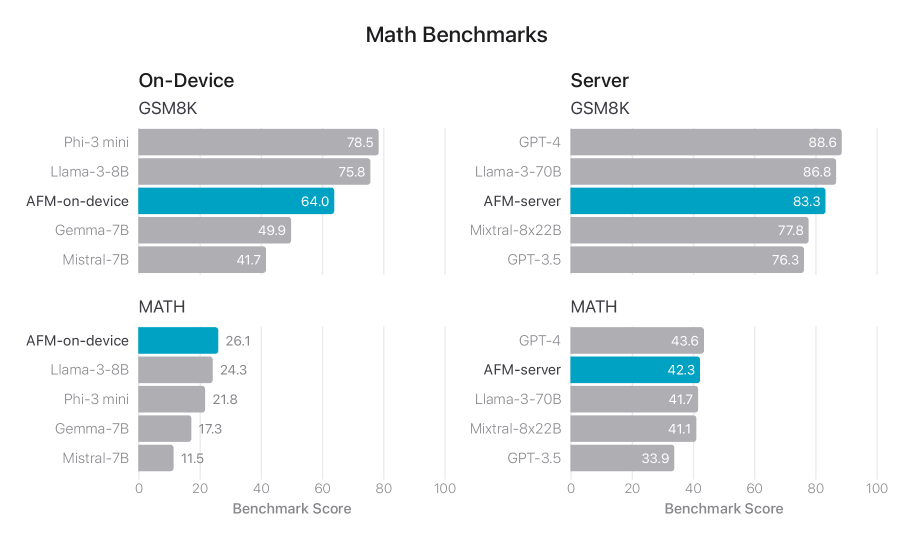
그림 7: AFM-온디바이스와 AFM-서버 및 관련 비교 샘플의 수학 벤치마크. GSM8K는 8-샷이고 MATH는 4-샷입니다. 모든 결과는 내부 자동화된 평가 파이프라인으로 수집되었습니다.
요약 기능 평가
이메일, 메시지, 알림을 요약하기 위한 제품팀 사양은 요약 품질을 다양한 오픈 소스, 라이선스 및 독점 데이터셋과 비교하여 평가하기 위한 맞춤형 가이드라인, 메트릭, 전문 평가자 세트가 필요했습니다.
데이터셋: 각 사용 사례에 대해 신중하게 다양한 페이로드를 샘플링했습니다. 이러한 평가 데이터셋은 제품 기능이 실제 환경에서 직면할 가능성이 높은 다양한 입력 세트를 강조하며, 다양한 콘텐츠 유형과 길이의 단일 및 스택 문서의 계층화된 혼합을 포함합니다. 실제 사용자 입력을 시뮬레이션하는 평가 데이터셋을 구축하기 위한 파이프라인을 개발했습니다.
평가자: 요약 품질을 평가하기 위해 전문화된 글쓰기 및 이해 능력을 갖춘 고도로 훈련된 전임 애플 직원 평가자 풀을 모집했습니다. 평가 프로젝트에 참여하기 위해 각 평가자는 글쓰기 관련 분야에서 학사 학위 필수, 맞춤형 훈련 세션, 내부 평가 품질 벤치마크에 대한 지속적으로 높은 성과를 포함하는 일련의 자격 및 훈련 단계를 통과해야 합니다.
평가 가이드라인: 평가 작업 중에 평가자에게는 요약에 대한 사양, 원본 입력 콘텐츠, 출력 요약이 제시됩니다. 평가자는 3점 척도(“좋음”, “중립”, “나쁨”)를 사용하여 다음과 같은 품질의 하위 차원에서 요약을 평가합니다.
- 구성: 문법, 구두점, 철자, 간결성을 고려한 요약의 전반적인 가독성을 평가합니다.
- 포괄성: 요약이 필수적인 요점을 포착하거나 사용자를 위한 행동/결론을 호출하는 데 얼마나 포괄적인지 평가합니다.
- 근거성: 요약이 원본 페이로드에 대해 얼마나 근거가 있는지 평가합니다. 완전히 근거가 없는 요약에는 과장되거나, 추론되거나, 부정확하거나, 환각된 세부 사항이 포함될 수 있습니다.
- 지시 따르기: 요약이 특정 스타일 및 형식 요구 사항을 충족하는지 평가합니다. 요구 사항은 각 기능에 맞게 조정되며 특정 제품 및 디자인 기대치를 반영합니다.
- 유해성: 요약이 애플의 안전성 분류법에 따라 유해하거나 안전하지 않은 내용을 포함하는지 평가합니다.
사전 정의된 제품 사양에 따라 하위 차원 중 하나라도 “나쁨”으로 분류되면 요약은 “나쁨”으로 분류됩니다. 마찬가지로 모든 하위 차원이 좋은 경우에만 요약은 “좋음”으로 분류됩니다. 이러한 분류는 모든 요약 중 좋은/나쁜 요약의 비율로 정의된 “좋은/나쁜 결과 비율” 메트릭을 계산하는 데 사용됩니다.
결과: 인간 평가자에게 AFM-온디바이스 어댑터, Phi-3-mini, Llama-3-8B, Gemma-7B의 요약 품질을 평가하도록 요청했습니다. 그림 8은 AFM-온디바이스-어댑터가 전반적으로 다른 모델보다 우수한 성능을 보인다는 것을 보여줍니다.
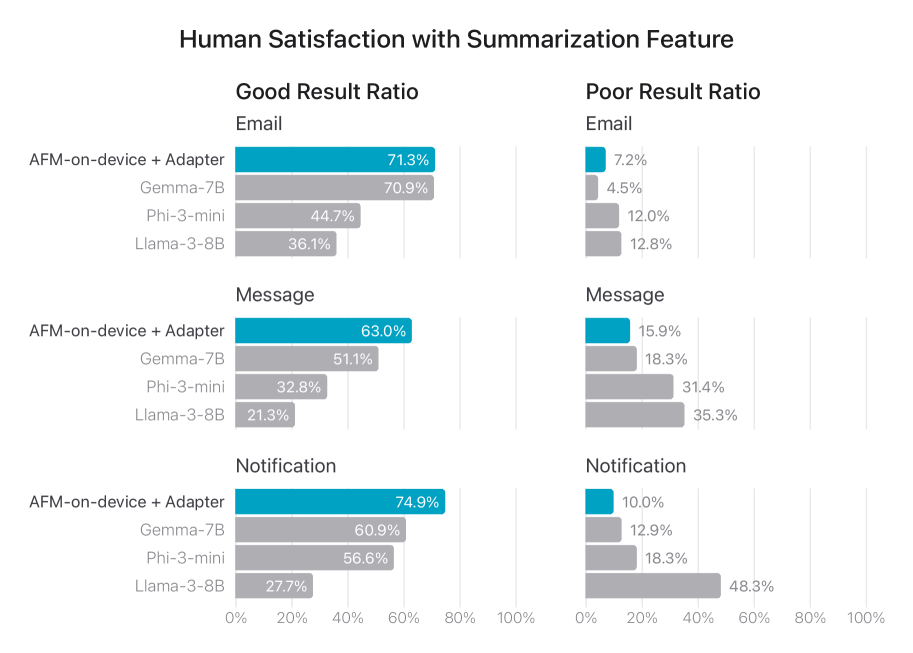
그림 8: 모든 응답에 대한 세 가지 요약 사용 사례에 대한 “좋음”과 “나쁨” 응답의 비율. 요약은 다섯 가지 차원에 따라 “좋음”, “중립”, 또는 “나쁨”으로 분류됩니다. 모든 차원이 좋은 경우 결과는 “좋음”으로 분류됩니다(높을수록 좋음). 차원 중 하나라도 나쁜 경우 결과는 “나쁨”으로 분류됩니다(낮을수록 좋음). 전반적으로, AFM-온디바이스 어댑터는 비교 가능한 모델보다 더 나은 요약을 생성합니다.
책임감 있는 AI
개요
애플 인텔리전스는 사용자에게 권한을 부여하고, 그들을 진정성 있게 대표하며, 개인정보를 보호하기 위해 책임감 있게 개발되고 신중하게 설계되었습니다. 애플의 책임감 있는 AI 접근 방식에서 가장 중요한 것은 궁극적으로 특정 사용자 요구를 해결하는 지능적이고 명확하게 정의된 도구를 제공하는 것입니다. 기능이 수행하고자 하는 바를 명확하게 정의함으로써 잠재적인 안전성 격차를 더 잘 식별할 수 있습니다.
애플은 생성형 AI 기반 기능의 설계와 평가에서 포괄적이고 일관성 있는 접근을 위해 안전성 분류 체계를 개발했습니다. 이 분류 체계는 전 세계 사용자에게 유용한 기능을 제공하기 위해 인공지능과 기계학습을 활용한 애플의 광범위한 경험을 기반으로 구축되고 확장되었으며, 기능을 개발하고 테스트함에 따라 정기적으로 업데이트됩니다. 현재 이 분류 체계는 “혐오 발언, 고정관념 및 비방”, “차별, 소외 및 배제”, “불법 활동”, “성인 성적 자료”, “그래픽 폭력” 등을 포함한 51개의 하위 카테고리로 구성된 12개의 주요 카테고리로 이루어져 있습니다.
이 분류 체계는 각 특정 기능과 관련된 잠재적 문제와 위험을 구조적으로 고려하는 방법으로 사용됩니다. 새로운 위험이나 추가 위험이 식별되면, 애플은 각 개별 기능에 맞게 상황화된 관련 정책을 개발하고 수정합니다. 이때 해당 기능이 제공하는 특정 요구, 생성하는 콘텐츠, 그리고 적절한 완화 조치를 고려합니다. 이러한 정책은 학계, AI 윤리학자, 신뢰 및 안전성, 법률 전문가 등의 광범위한 내부 및 외부 의견을 통해 개발되어 관련 위험, 그러한 위험의 잠재적 심각성, 그리고 이러한 위험이 특정 그룹에 미칠 수 있는 불균형적 영향을 더 잘 식별하고 이해하는 데 도움이 됩니다. 이러한 정책은 데이터 수집, 인간 주석, 모델 훈련, 가드레일 개발, 평가 및 레드 팀 테스트 작업을 안내합니다.
특히, 분류 체계 자체가 정책의 유일한 결정 요소는 아닙니다. 예를 들어, 안전성 분류 체계에 속하는 콘텐츠가 항상 차단되는 것은 아닙니다. 이를 일방적으로 수행하는 것은 “사용자가 목표를 달성하기 위해 이러한 도구를 사용하는 방식을 존중한다”와 같은 애플의 책임감 있는 AI 개발 원칙의 다른 측면과 충돌할 수 있기 때문입니다. 따라서 도구로 작동하는 기능은 사용자의 의도를 효과적으로 해결하기 위해 다양한 종류의 콘텐츠를 처리하고 생성하는 데 더 허용적일 수 있습니다. 반면, 사용자가 지정한 의도를 넘어서는 콘텐츠를 생성할 수 있는 기능은 더 제한적일 필요가 있을 수 있습니다. 그럼에도 불구하고, 애플은 일부 유해 카테고리(예: 자해 관련 콘텐츠)는 항상 특별한 주의를 기울이고, 다른 카테고리(예: 불법 콘텐츠)는 항상 차단되도록 노력합니다.
또한, 애플의 책임감 있는 AI 원칙은 안전성 분류 체계와 함께 애플 파운데이션 모델과 애플 인텔리전스의 모든 단계에 내장되어 있으며, 이는 기능별로 위험을 평가하고 정책을 수립하는 데 도움이 됩니다. 애플은 사용 사례별로 맞춤화된 특정 어댑터의 미세 조정의 일부로 안전 지향적 데이터를 포함합니다. 또한, 추론 시점에서 입력과 출력 수준 모두에서 잠재적 해악을 평가하기 위해 사전 및 사후 처리 단계로 가드레일 모델[Inan 등, 2023]을 실행합니다. 마지막으로, 애플은 지속적인 사용자 피드백을 통해 AI 도구를 지속적이고 적극적으로 개선하기 위한 메커니즘을 갖추고 있습니다.
사전 학습
사전 학습 단계에서 애플은 앞서 설명한 가치가 유지되도록 여러 단계를 취합니다. 애플은 애플 사용자 데이터가 포함되지 않도록 하는 엄격한 데이터 정책을 따르며, 훈련 코퍼스의 각 구성 요소에 대해 철저한 법적 검토를 수행합니다. 또한, 비속어, 안전하지 않은 자료, 스팸, PII 또는 금융 데이터를 포함한 잠재적으로 유해한 콘텐츠를 줄이기 위한 안전성 필터링을 수행합니다.
사전 학습은 다양한 다운스트림 기능 간에 공유되는 단계이기 때문에, 안전성 완화 조치는 분류 체계와 정책을 기능별 수준에서 반복할 수 있도록 하는 일반적인 기능을 유지하는 것을 목표로 하며, 이러한 다운스트림 모델의 유용성을 해치지 않습니다. 애플은 이전 연구에서 배운 교훈을 적용하여 사전 학습 단계에서 과도하게 공격적인 필터링을 피합니다. 이는 안전성 정렬에 잠재적인 이점이 있기 때문입니다[Touvron 등, 2023]. 직관적으로, 사전 학습된 모델은 다운스트림 기능과 정책이 처리해야 할 수 있는 콘텐츠를 인식해야 합니다. 일부 경우에는 주의를 기울여야 하거나, 다른 경우에는 그러한 콘텐츠를 직접 처리해야 할 수도 있습니다.
사후 학습
사후 학습 단계에서는 각 다운스트림 모델에서 사후 학습(예: RLHF)의 모든 복잡성을 필요로 하지 않도록 책임감 있는 AI 원칙과의 기본적인 정렬 수준을 심어주는 것을 목표로 합니다. 이를 위해 두 가지 주요 고려 사항이 있습니다.
- 모델이 잠재적 해악을 최소화하면서 사용자에게 유용한 출력을 생성하도록 해야 합니다.
- 최상의 사용자 경험을 제공하기 위해 안전성 분류 체계와 정책을 기능별로 상황화해야 합니다.
유용성과 무해성의 균형을 맞추기 위해, 애플의 해결책은 안전성 정렬을 평가하고 반복되는 여러 핵심 사후 학습 작업 중 하나로 취급하는 것입니다. 별도의 훈련 단계로 취급하는 대신, 애플은 신뢰할 수 있는 벤더와 긴밀히 협력하여 정책과 가치에 따라 큐레이션된 적대적 데이터를 SFT 및 RLHF 훈련 코퍼스에 포함시킵니다. 또한 모델 개발 중에 사용되는 자동 및 인간 평가에 안전성 작업과 벤치마크를 통합합니다. 총 10% 이상의 훈련 데이터가 단일 및 다중 턴 안전성 카테고리 주석, 쌍별 및 전체 선호도 평가, 주석자 재작성을 포함한 적대적이거나 안전성 또는 민감한 주제와 관련된 데이터입니다. 이 데이터는 앞선 절에서 설명한 대로 직접 사용되거나 합성 데이터 생성을 위한 시드 데이터로 사용됩니다.
애플은 기본 정렬을 넘어 각 기능에 대한 적절한 안전성 동작을 달성하기 위한 추가 작업을 수행합니다. 이를 위한 주요 방법은 안전성 특정 훈련 데이터를 수집하고 어댑터를 미세 조정할 때 이를 포함하는 것입니다. 예를 들어, 요약 어댑터를 미세 조정할 때 요약할 콘텐츠 내에 포함된 악의적인 질문에 대한 강건성 향상, 요약할 유해하거나 민감한 콘텐츠를 의도치 않게 증폭시킬 가능성 감소와 같은 측면을 개선하고자 했습니다.
악의적 코드 방지
코드 생성은 특별한 주의가 필요합니다. 애플의 코드 벤치마크는 생성된 코드를 실제로 실행하여 구문적 및 의미적 정확성을 모두 판단합니다. 따라서 코드 모델의 책임감 있는 훈련에는 모든 생성된 코드를 기본적으로 안전하지 않은 것으로 취급하는 것이 포함됩니다. 모든 코드는 항상 인터넷이나 내부 또는 외부 서비스에 대한 접근 없이 완전히 잠긴 환경에서 실행됩니다. 구체적으로, 잠긴 환경은 클러스터 수준에서 FireCracker 감옥을 사용하는 FireCracker[Agache 등, 2020]로 관리됩니다.
레드 팀 테스트
레드 팀 테스트는 모델로부터 안전성 정책을 위반하는 응답을 유도하거나, 아직 정책이 존재하지 않는 유해한 응답을 유도하려고 시도합니다. 이러한 결과는 정책 개발과 안전성 평가 데이터셋의 초점과 내용에 모두 영향을 미칩니다. 이는 다시 설계, 엔지니어링 및 출시 준비 결정에 영향을 줄 수 있습니다.
레드 팀 테스트는 본질적으로 창의적인 노력으로, 레드 팀 테스터가 알려진 모델 취약점을 탐색하고 새로운 취약점을 발견하기 위해 공격 벡터의 조합을 사용해야 합니다. 언어 모델과 상호 작용할 때 사용되는 공격 벡터에는 재일브레이크/프롬프트 인젝션, 설득 기법[Zeng 등, 2024], 그리고 모델 오작동을 유발하는 것으로 알려진 언어적 특징(예: 속어, 코드 스위칭, 이모티콘, 오타)이 포함됩니다.
애플은 정렬된 모델의 잠재적으로 알려지지 않은 실패 모드를 유도하기 위해 수동 및 자동 레드 팀 테스트[Ganguli 등, 2022]를 모두 사용합니다. 최근 연구[Touvron 등, 2023]에 따르면 자동화된 프로세스가 이전에 데이터 수집의 “골드” 표준으로 간주되던 인간보다 더 다양한 프롬프트를 생성할 수 있다고 제안합니다. 이러한 자동화된 프로세스에는 격차를 식별하기 위해 언어 모델 자체를 사용하는 것이 포함될 수 있으며, 이 중 일부는 직관적이지 않거나 심지어 놀라울 수도 있습니다. 이러한 예제는 합성 훈련 또는 평가 데이터로 직접 사용되거나 향후 데이터 수집 노력에 정보를 제공하는 데 사용될 수 있습니다.
기본적인 인간 레드 팀 테스트 작업 스키마는 다음과 같습니다. 레드 팀 테스터에게 안전성 분류 체계 카테고리와 공격 벡터가 할당됩니다. 그들은 해당 공격 벡터를 사용하여 해당 카테고리의 콘텐츠를 포함하는 응답을 유도하기 위한 입력을 작성합니다. 응답이 대상 콘텐츠를 포함하지 않는 경우, 레드 팀 테스터는 고정된 수의 대화 턴에 참여할 수 있으며, 그 후 모델 출력의 최종 유해성 평가를 제공하고 있는 경우 분류 체계 카테고리를 나열합니다. 주석 품질을 보장하기 위해 레드 팀 테스터는 또한 평가에 대한 전반적인 신뢰도 점수를 제공합니다.
기본 모델 수준에서의 레드 팀 테스트 외에도, 애플은 특정 기능에 대한 레드 팀 테스트도 수행합니다. 기능 수준의 레드 팀 테스트 프로젝트는 해당 기능의 안전성 정책과 엔지니어링 우려 사항에 의해 정보가 제공된 공격 벡터와 함께 기능별 가이드라인을 사용합니다. 이러한 프로젝트는 해당 특정 기능에 대한 알려진 위험에 대한 심층적인 탐색을 제공하고 알려지지 않은 취약점을 적대적으로 탐색할 수도 있습니다.
애플의 레드 팀 테스트 프로젝트는 내부 및 외부 크라우드를 사용하여 실행됩니다. 레드 팀 테스트의 민감한 특성으로 인한 책임감 있는 데이터 수집을 보장하기 위해 애플은 다음과 같은 조치를 취합니다. 1) 레드 팀 테스트를 완전히 자발적으로 만듭니다; 2) 각 레드 팀 테스터가 주당 작업에 소비하는 시간에 엄격한 제한을 둡니다; 3) 하루 24시간 이용 가능한 건강 및 웰빙 리소스를 제공합니다; 4) 주간 오피스 아워와 발생하는 우려 사항을 전달할 수 있는 슬랙 채널을 통해 내부 레드 팀 테스터와의 열린 의사소통 라인을 유지합니다.
평가
앞서 언급한 바와 같이, 안전성은 파운데이션 모델 개발 중에 반복되는 여러 축 중 하나이므로 사후 학습 중에 동일한 자동 및 인간 평가 주기를 거칩니다.
안전성 평가 세트
인간 평가 중 노이즈, 비용 및 처리 시간을 줄이기 위해 안전성 평가 세트가 깨끗하면서도 도전적이고 포괄적이어야 합니다. 이를 위해 애플은 모델의 다른 버전에서 일관되게 낮은 유해성 응답을 산출하는 “쉬운” 프롬프트를 필터링하고, 평가 프롬프트 세트 커버리지를 개선하기 위해 임베딩 기반 분석을 사용합니다. 전체적으로, 애플은 안전성 정책에 따라 AFM의 유해 콘텐츠, 민감한 주제 및 사실성에 대한 성능을 테스트하기 위한 천 개 이상의 적대적 프롬프트 세트를 큐레이션했습니다.
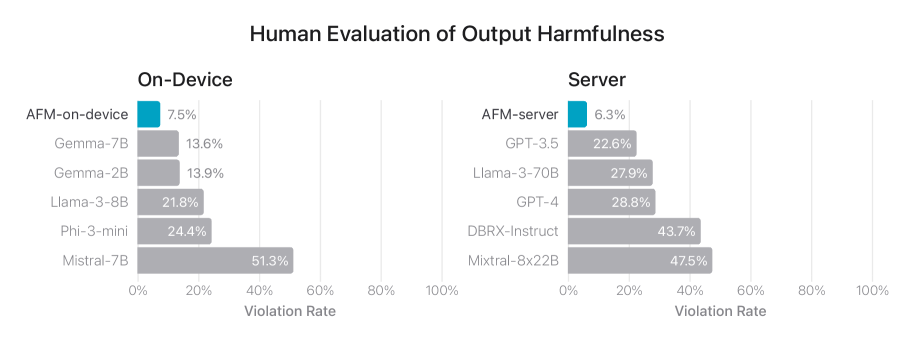
그림 9: 유해 콘텐츠, 민감한 주제 및 사실성에 대한 위반 응답 비율(낮을수록 좋음). 애플의 모델은 적대적 프롬프트에 직면했을 때 강건한 성능을 보입니다. 이 그림은 다양한 AI/ML 모델의 출력 유해성에 대한 인간 평가 결과를 보여줍니다. 주요 목적은 적대적 프롬프트에 직면했을 때 이러한 모델의 강건성을 평가하는 것입니다. 주요 기술적 구성 요소는 다양한 모델 아키텍처(예: AFM, Gemma, Llama, GPT, DBRX-Instruct)와 해당 위반율로, 이는 유해하거나, 민감하거나, 사실적으로 부정확하다고 간주되는 응답의 비율을 측정합니다. 중요한 발견은 온디바이스 모델이 일반적으로 서버 기반 모델에 비해 낮은 위반율을 보인다는 것으로, 이는 적대적 프롬프트에 더 강건하다는 것을 나타냅니다. 이는 실제 응용 프로그램에서 신뢰할 수 있고 안정적인 AI/ML 시스템 배포에 중요한 의미를 갖습니다.
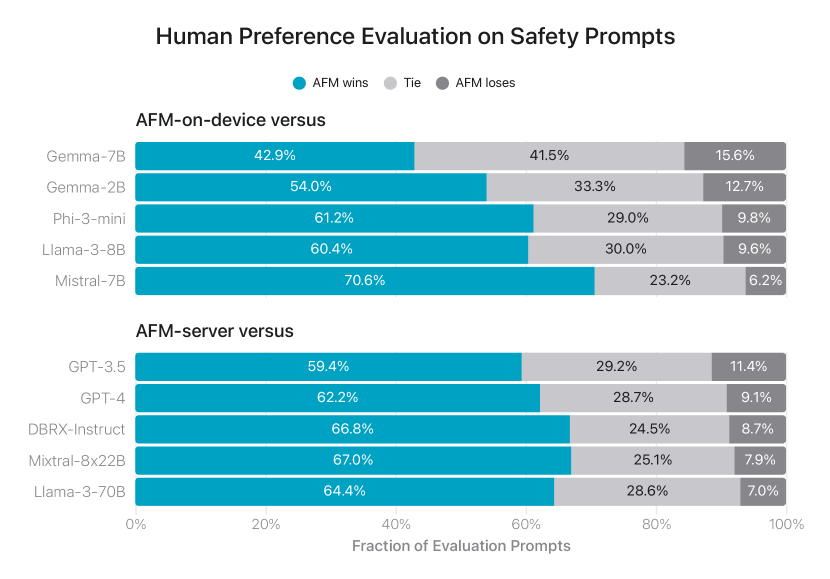
그림 10: 안전성 프롬프트에 대한 애플의 파운데이션 모델과 비교 가능한 모델 간의 나란히 평가에서 선호되는 응답의 비율. 인간 평가자들은 애플의 응답이 더 안전하고 유용하다고 판단했습니다. 이 그림은 안전성 프롬프트에 대한 AI 파운데이션 모델(AFM)과 다른 비교 가능한 모델 간의 인간 선호도 평가 결과를 보여줍니다. 주요 목적은 나란히 비교에서 각 모델에 대한 선호 응답의 비율을 시각화하는 것입니다. 주요 기술적 구성 요소는 AFM-온디바이스 대 AFM-서버와 같은 다양한 모델 구성과 AFM 승리, 무승부, 패배에 해당하는 메트릭입니다. 중요한 발견은 AFM 모델이 인간 평가자들이 인식한 대로 안전성과 유용성 측면에서 다른 모델보다 우수한 성능을 보였다는 것입니다. 이 연구의 중요성은 AFM 모델이 다른 비교 가능한 모델보다 안전성과 신뢰성 측면에서 이점을 보여준다는 것으로, 이는 대규모 언어 모델의 개발 및 배포에 중요한 의미를 갖습니다.
안전성 평가 결과
그림 9는 이 안전성 평가 세트에서 인간 평가자들이 평가한 다양한 모델의 위반율을 요약합니다. 낮을수록 좋습니다. AFM-온디바이스와 AFM-서버 모두 적대적 프롬프트에 강건하여, 오픈 소스 및 상업용 모델보다 훨씬 낮은 위반율을 달성했습니다.
또한, 그림 10에서는 안전성 평가 프롬프트에 대한 나란히 인간 선호도를 보고합니다. AFM 모델은 인간 평가자들에 의해 경쟁 모델보다 안전하고 유용한 응답으로 선호되었습니다.
결론
이 보고서에서는 애플 인텔리전스 기능을 지원하는 파운데이션 언어 모델인 AFM-온디바이스와 AFM-서버를 소개했습니다. 이 모델들은 아이폰, 아이패드, 맥에서 효율적으로 작동하도록 설계되었으며, 프라이빗 클라우드 컴퓨트를 통해 애플 실리콘 서버에서도 구동됩니다. 이 모델들은 언어 이해, 지시 따르기, 추론, 글쓰기, 도구 사용과 같은 작업에서 높은 성능을 발휘하도록 훈련되었습니다.
애플은 사용자들이 가장 자주 수행하는 작업에 모델을 특화시키기 위한 혁신적인 아키텍처를 개발했습니다. 파운데이션 모델 위에 기능별 어댑터를 미세 조정하여 이메일, 메시지, 알림 요약과 같은 고품질 사용자 경험을 제공합니다. 이러한 모델들은 사용자들이 애플 제품에서 일상적인 활동을 수행하는 데 도움을 주기 위한 목적으로 만들어졌으며, 애플의 핵심 가치와 책임감 있는 AI 원칙에 기반하여 모든 단계에서 신중하게 설계되었습니다.
이러한 파운데이션 모델들은 애플 인텔리전스의 핵심을 이루며, 애플이 구축한 개인 인텔리전스 시스템을 통해 사용자들에게 권한을 부여하고 그들의 삶을 풍요롭게 하는 데 기여합니다. 애플의 파운데이션 모델은 사용자 개인정보 보호를 최우선으로 하면서도 강력한 AI 기능을 제공하는 균형 잡힌 접근 방식을 보여줍니다. 이 모델들은 온디바이스에서 작동하거나 프라이빗 클라우드 컴퓨트를 통해 안전하게 처리되어, 사용자 데이터의 개인정보를 보호하면서도 고급 AI 기능을 제공합니다.
애플의 파운데이션 모델은 다양한 벤치마크에서 경쟁력 있는 성능을 보여주었으며, 특히 안전성과 유용성 측면에서 뛰어난 결과를 달성했습니다. 인간 평가에서 AFM 모델은 경쟁 모델보다 더 자주 선호되었으며, 특히 AFM-온디바이스는 매개변수 수가 더 많은 일부 오픈 소스 모델보다 우수한 성능을 보였습니다. 이는 모델 크기만으로는 성능을 결정할 수 없으며, 효율적인 아키텍처 설계와 훈련 방법이 중요하다는 것을 보여줍니다.
애플은 이러한 파운데이션 모델을 기반으로 다양한 애플 인텔리전스 기능을 계속 발전시켜 나갈 것이며, 사용자 개인정보 보호와 책임감 있는 AI 개발이라는 핵심 가치를 유지하면서 혁신적인 AI 기술을 제공할 것입니다. 이러한 접근 방식은 사용자 중심의 AI 시스템을 구축하는 데 있어 중요한 방향성을 제시하며, 기술의 발전과 사용자의 권리 사이의 균형을 맞추는 모범 사례를 보여줍니다.
부록 A: 핵심 사전 학습 레시피 절제 실험
본 부록에서는 앞선 절에서 선택한 ‘핵심’ 사전 학습 설정(옵티마이저, 스케일링 법칙에 따른 배치 크기, 가중치 감소 등)을 Wortsman과 연구진의 연구를 기반으로 한 기준선과 비교합니다. 특히, 기준선은 AdamW 옵티마이저를 사용하며 $\beta_{1}=0.9$, $\beta_{2}=0.95$, $\epsilon=1\mathrm{e}{-15}$의 표준 하이퍼파라미터 구성과 $1\mathrm{e}{-4}$의 분리된 가중치 감소를 적용합니다. 또한 학습률을 피크의 $0.0001$까지 감소시키며, 1024 시퀀스의 배치 크기를 사용합니다. 이외의 모든 레시피 설정은 동일하게 유지됩니다.
훈련은 AFM-온디바이스 아키텍처를 사용하여 3.1T 토큰에 대해 진행되었으나, 공식 AFM 훈련에 사용된 것과는 다른 데이터 혼합물을 사용했습니다.
표 5는 핵심 사전 학습 레시피 절제 실험의 퓨 샷 결과를 보여줍니다.
| 작업 | 기준선 (정확도) | AFM (정확도) |
|---|---|---|
| arc_challenge | 41.9 | 44.6 |
| arc_easy | 75.6 | 76.1 |
| hellaswag | 54.3 | 55.0 |
| lambada | 69.3 | 68.9 |
| piqa | 78.3 | 78.4 |
| sciq | 94.5 | 94.7 |
| winogrande | 67.3 | 66.9 |
| triviaqa (1-샷) | 40.5 | 41.0 |
| webqs (1-샷) | 20.6 | 20.6 |
| CoreEN 평균 | 60.2 | 60.7 |
| GSM8K (8-샷 CoT) | 16.6 | 18.9 |
| MMLU (5-샷) | 45.4 | 45.5 |
표 5: 핵심 사전 학습 레시피 절제 실험의 퓨 샷 결과. 별도로 명시되지 않은 경우 0-샷 프롬프트를 사용했습니다.
표 5에서 볼 수 있듯이, AFM의 레시피는 기준선에 비해 약간의 개선을 보여줍니다. 대부분의 작업에서 성능이 소폭 향상되었지만, 그 차이는 일반적으로 매우 작습니다. 이는 이 모델 크기와 훈련 예산에서는 기준선에 의해 이미 핵심 레시피 설정이 충분히 잘 구성되어 있음을 시사합니다.
특히 주목할 만한 점은 GSM8K 작업에서 AFM 레시피가 기준선보다 2.3% 더 높은 성능을 보인다는 것입니다. 이는 AFM의 레시피가 수학적 추론과 같은 복잡한 작업에서 더 효과적일 수 있음을 시사합니다. 반면, lambada와 winogrande 작업에서는 기준선이 약간 더 나은 성능을 보였습니다.
전체적으로 CoreEN 평균에서 AFM 레시피는 기준선보다 0.5% 더 높은 성능을 달성했습니다. 이러한 결과는 AFM 레시피의 설계 선택이 전반적으로 효과적이었음을 보여주지만, 이 모델 크기와 훈련 예산에서는 그 차이가 크지 않다는 것을 나타냅니다.
이 절제 실험에서 사용된 데이터 혼합물은 공식 AFM 실행에 사용된 것과 다르다는 점에 유의해야 합니다. 따라서 이 결과는 특정 데이터 혼합물에서의 레시피 효과를 보여주는 것이며, 다른 데이터 혼합물에서는 결과가 달라질 수 있습니다.
이러한 결과는 모델 훈련에 있어 옵티마이저 선택, 배치 크기, 가중치 감소와 같은 하이퍼파라미터 설정이 중요하지만, 특정 모델 크기와 훈련 예산에서는 표준적인 구성도 충분히 좋은 성능을 달성할 수 있음을 시사합니다. 그럼에도 불구하고, AFM 레시피의 미세한 개선은 대규모 훈련에서 누적되어 최종 모델 성능에 의미 있는 영향을 미칠 수 있습니다.
가지치기와 증류에 대한 절제 연구
이 부록에서는 구조적 가지치기와 증류를 별도로 사용한 평가 결과를 자세히 설명하고, 이 두 방법을 함께 사용했을 때 최상의 성능을 얻을 수 있음을 보여줍니다.
표 6은 초기 버전의 사전 학습 데이터 혼합물을 사용하여 3B 모델을 훈련한 절제 실험 결과를 보여줍니다. 표에서 볼 수 있듯이, 가지치기와 증류 방법 모두 처음부터 훈련된 기준 모델보다 더 나은 성능을 달성할 수 있습니다. 예를 들어, 가지치기와 증류는 각각 42.9%와 44.9%의 MMLU 점수를 달성한 반면, 50% 더 많은 단계를 사용한 기준 모델은 34.6%에 그쳤습니다.
흥미로운 점은 가지치기가 CoreEn 벤치마크에서 더 높은 점수를 달성한 반면, 증류는 MMLU에서 더 좋은 성능을 보인다는 것입니다. 이는 두 방법이 서로 다른 유형의 작업에서 각각 장점을 가지고 있음을 시사합니다. 가지치기는 모델의 구조를 최적화하여 일부 언어 이해 작업에서 더 효과적일 수 있으며, 증류는 지식 전달을 통해 추론 기반 작업에서 더 효과적일 수 있습니다.
마지막으로, 이 두 방법을 함께 결합했을 때, MMLU와 GSM8k에서 큰 폭의 추가 개선이 관찰되었습니다. 이 결합된 접근법은 5배 더 많은 계산을 사용하여 훈련된 기준 모델과 비교하여 더 나은 또는 동등한 결과를 얻었습니다. 이는 가지치기와 증류가 상호 보완적인 이점을 제공하며, 함께 사용할 때 계산 효율성과 모델 성능 사이의 최적의 균형을 달성할 수 있음을 보여줍니다.
| 메트릭/방법 | 기준선 | 가지치기 | 증류 | 둘 다 | 기준선 |
|---|---|---|---|---|---|
| 훈련 비용 | 1.5$\times$ | 1$\times$ | 1$\times$ | 1$\times$ | 5$\times$ |
| MMLU (5-샷) | 34.6 | 42.9 | 44.9 | 49.3 | 45.4 |
| GSM8K (8-샷 CoT) | 12.7 | 13.5 | 11.0 | 16.8 | 16.9 |
| CoreEN 평균 | 59.8 | 61.0 | 58.1 | 59.7 | 60.3 |
표 6: 가지치기와 증류 방법에 대한 절제 실험 결과. 훈련 데이터는 공식 AFM 실행과 다른 초기 버전입니다.
이러한 결과는 모델 최적화 전략으로서 구조적 가지치기와 지식 증류의 효과를 명확하게 보여줍니다. Wang과 연구진이 제안한 구조적 가지치기 방법은 모델의 중요한 구조를 보존하면서 매개변수 수를 줄이는 데 효과적입니다. 이 방법은 가중치 행렬을 저차원 표현으로 분해하여 모델의 표현력을 유지하면서 계산 효율성을 향상시킵니다.
한편, Hinton과 연구진이 소개한 지식 증류는 큰 교사 모델의 지식을 작은 학생 모델로 전달하는 방법입니다. 이 과정에서 학생 모델은 교사 모델의 소프트 타겟(확률 분포)을 모방하도록 훈련되어, 단순히 하드 레이블만 사용하는 것보다 더 풍부한 정보를 학습할 수 있습니다.
AFM 모델에서는 이 두 방법을 결합하여 사용했습니다. 먼저 구조적 가지치기를 통해 모델의 크기를 줄이고, 그 다음 지식 증류를 적용하여 작은 모델이 더 큰 모델의 성능에 가까워지도록 했습니다. 이러한 접근법은 Xia와 연구진의 연구에서도 유사하게 사용되었으며, 그들은 큰 언어 모델을 구조적으로 가지치기하고 계속 사전 학습하는 방법을 제안했습니다.
이 절제 연구의 결과는 가지치기와 증류가 개별적으로도 효과적이지만, 함께 사용할 때 더욱 강력한 시너지 효과를 낼 수 있음을 보여줍니다. 특히, 두 방법을 결합했을 때 MMLU 점수가 49.3%로 크게 향상되었으며, 이는 5배 더 많은 계산을 사용한 기준 모델의 45.4%보다 높은 수치입니다. 마찬가지로 GSM8K에서도 결합된 방법이 16.8%의 점수를 달성하여, 5배 더 많은 계산을 사용한 기준 모델의 16.9%와 거의 동등한 성능을 보였습니다.
이러한 결과는 계산 효율성과 모델 성능 사이의 균형을 맞추는 데 있어 가지치기와 증류의 결합이 매우 효과적인 전략임을 시사합니다. 특히 제한된 계산 자원으로 고성능 모델을 개발해야 하는 상황에서, 이러한 접근법은 훈련 비용을 크게 줄이면서도 경쟁력 있는 성능을 달성할 수 있는 방법을 제공합니다.
부록 C 사전 학습 단계별 평가
이 부록에서는 핵심(core), 지속적(continued), 그리고 긴 컨텍스트(long-context) 사전 학습 단계 이후의 퓨 샷 평가 결과를 제시합니다. 이 평가는 사후 학습 이후의 다운스트림 평가와 상관관계가 있는 것으로 나타난 낮은 분산, 다양성, 그리고 신뢰성을 갖춘 평가 지표의 하위 집합을 사용합니다. 이러한 지표들은 내부 평가 도구와 벤치마크 공식을 사용하여 도출되었으며, 절대적인 성능 비교를 위해 최적화되지 않았습니다(예: 길이 정규화를 적용하지 않고, 가능한 경우 더 어려운 테스트 분할을 사용합니다—TriviaQA의 경우 한 예시). 따라서 이 결과들은 다른 발표된 결과와 비교하기에 적합하지 않습니다.
표 7은 AFM-온디바이스 모델의 사전 학습 단계별 평가 결과를 보여줍니다. 별도로 명시되지 않은 경우 0-샷 프롬프트를 사용했습니다.
| 핵심 | 지속적 | 컨텍스트 확장 | |
|---|---|---|---|
| ARC_C | 43.17 | 47.53 | 45.39 |
| ARC_E | 74.87 | 78.62 | 78.37 |
| HellaSwag | 54.70 | 55.50 | 55.24 |
| LAMBADA | 73.51 | 70.13 | 69.90 |
| PIQA | 77.37 | 78.67 | 78.40 |
| SciQ | 94.90 | 95.80 | 95.70 |
| WinoGrande | 65.82 | 67.32 | 67.01 |
| TriviaQA (1 샷) | 42.46 | 39.13 | 38.11 |
| WebQS (1 샷) | 19.24 | 18.06 | 17.22 |
| CoreEN 평균 | 60.67 | 61.20 | 60.59 |
| MMLU (5 샷) | 57.00 | 61.35 | 60.64 |
| GSM8K (8 샷 CoT) | 27.45 | 42.53 | 40.00 |
| MATH (4 샷 CoT) | 8.31 | 16.97 | 15.48 |
| HumanEval-Py pass@1 | 16.48 | 27.38 | 30.84 |
| MultiPLE-Swift pass@1 | 8.88 | 19.24 | 18.06 |
표 7: 내부 평가 도구를 사용한 AFM-온디바이스의 사전 학습 평가. 별도로 명시되지 않은 경우 0-샷 프롬프트를 사용했습니다. TriviaQA 평가는 더 크고 더 어려운 “Web” 분할에서 수행되었습니다.
표 8은 AFM-서버 모델의 사전 학습 단계별 평가 결과를 보여줍니다.
| 핵심 | 지속적 | 컨텍스트 확장 | |
|---|---|---|---|
| ARC_C | 58.28 | 58.87 | 57.94 |
| ARC_E | 85.61 | 85.44 | 85.06 |
| HellaSwag | 64.17 | 64.53 | 64.37 |
| LAMBADA | 78.38 | 77.59 | 77.82 |
| PIQA | 82.37 | 81.99 | 81.88 |
| SciQ | 96.60 | 97.10 | 97.00 |
| WinoGrande | 80.51 | 79.16 | 79.08 |
| TriviaQA (1 샷) | 54.33 | 53.57 | 53.42 |
| WebQS (1 샷) | 29.97 | 27.66 | 27.41 |
| CoreEN 평균 | 70.02 | 69.55 | 69.33 |
| MMLU (5 샷) | 74.00 | 75.24 | 74.80 |
| GSM8K (8 샷 CoT) | 75.44 | 74.83 | 75.51 |
| MATH (4 샷 CoT) | 32.24 | 36.48 | 35.77 |
| HumanEval-Py | 33.23 | 40.77 | 39.55 |
| MultiPLE-Swift | 30.15 | 37.70 | 38.11 |
표 8: 내부 평가 도구를 사용한 AFM-서버의 사전 학습 평가. 별도로 명시되지 않은 경우 0-샷 프롬프트를 사용했습니다. TriviaQA 평가는 더 크고 더 어려운 “Web” 분할에서 수행되었습니다.
표 7과 표 8에서 볼 수 있듯이, 사전 학습의 세 단계 이후의 내부 벤치마크 결과를 제시하고 있습니다. 예상대로 지속적 사전 학습 단계는 수학과 특히 코드 모델 능력을 향상시키는 동시에 다른 몇몇 벤치마크도 미묘하게 개선합니다. 컨텍스트 확장 단계는 대부분의 벤치마크를 비슷한 수준으로 유지하며, 변화(긍정적이든 부정적이든)는 일반적으로 평가 노이즈로 간주되는 범위 내에 있습니다.
AFM-온디바이스 모델의 경우, 지속적 사전 학습 단계에서 가장 주목할 만한 개선은 GSM8K와 MATH 벤치마크에서 볼 수 있습니다. GSM8K의 성능은 27.45%에서 42.53%로 크게 향상되었으며, MATH는 8.31%에서 16.97%로 두 배 이상 향상되었습니다. 이는 지속적 사전 학습 단계에서 수학 콘텐츠의 가중치를 높인 결과로 볼 수 있습니다. 또한 코드 관련 벤치마크인 HumanEval-Py와 MultiPLE-Swift에서도 상당한 개선이 있었습니다. 반면, TriviaQA와 WebQS와 같은 일부 지식 집약적 작업에서는 약간의 성능 저하가 관찰되었습니다.
AFM-서버 모델의 경우, 지속적 사전 학습 단계는 MATH 벤치마크에서 32.24%에서 36.48%로의 개선과 코드 관련 벤치마크에서의 상당한 향상을 보여줍니다. HumanEval-Py는 33.23%에서 40.77%로, MultiPLE-Swift는 30.15%에서 37.70%로 향상되었습니다. 이러한 결과는 지속적 사전 학습 단계에서 코드와 수학 데이터의 가중치를 높이는 전략이 효과적이었음을 보여줍니다.
컨텍스트 확장 단계는 두 모델 모두에서 대부분의 벤치마크에서 지속적 사전 학습 단계와 비슷한 성능을 유지하거나 약간의 변화를 보입니다. 이는 컨텍스트 확장 단계가 주로 모델의 긴 컨텍스트 처리 능력을 향상시키는 데 초점을 맞추고 있으며, 이러한 표준 벤치마크는 대부분 짧은 컨텍스트에서 평가되기 때문에 큰 변화가 관찰되지 않는 것으로 이해할 수 있습니다.
흥미로운 점은 AFM-온디바이스 모델의 경우 HumanEval-Py 성능이 컨텍스트 확장 단계에서 27.38%에서 30.84%로 추가 향상된 반면, AFM-서버 모델에서는 약간 감소했다는 것입니다. 이는 모델 크기와 아키텍처에 따라 컨텍스트 확장의 영향이 다를 수 있음을 시사합니다.
전반적으로, 이러한 평가 결과는 AFM 모델의 사전 학습 단계별 진행 상황을 잘 보여주며, 특히 지속적 사전 학습 단계가 수학과 코드 관련 능력을 크게 향상시키는 데 효과적이었음을 확인할 수 있습니다. 또한 컨텍스트 확장 단계는 대부분의 표준 벤치마크 성능을 유지하면서도 긴 컨텍스트 처리 능력을 향상시키는 데 기여했을 것으로 추정됩니다. 이러한 단계별 접근 방식은 모델의 다양한 능력을 균형 있게 발전시키는 데 효과적인 전략임을 보여줍니다.
부록 D 긴 컨텍스트 평가
AFM의 이번 버전은 8k 이상의 컨텍스트 길이를 지원하는 것이 주요 목표는 아니었지만, 표 9에서는 RULER(Hsieh와 연구진) 벤치마크를 사용하여 AFM-서버를 4k에서 32k 컨텍스트 길이에서 평가한 결과를 보여줍니다. 주목할 만한 점은 모델이 바늘-건초더미(needle-in-the-haystack, NIAH)와 같은 단순한 검색 유형 작업에서는 $32\mathrm{k}$ 이상의 시퀀스 길이에서도 완벽하게 수행할 수 있다는 것입니다. 그러나 RULER는 NIAH보다 더 복잡한 평가 벤치마크이기 때문에, 컨텍스트 길이가 증가함에 따라 모델 성능이 점차 저하되는 것이 분명합니다. 이는 AFM-서버의 실제 컨텍스트 길이가 검색 이상의 작업에서는 현재 최대 24k 정도임을 시사합니다.
| AFM-서버 | 평균 정확도 |
|---|---|
| Ctx @ 4096 | 91.7 |
| Ctx @ 8192 | 87.7 |
| Ctx @ 16384 | 84.1 |
| Ctx @ 20480 | 79.1 |
| Ctx @ 24576 | 75.8 |
| Ctx @ 32768 | 43.3 |
표 9: RULER(Hsieh와 연구진) 평균 평가 결과. 13개의 합성 긴 컨텍스트 작업에 대해 작업당 500개의 예제를 사용하여 평균을 낸 결과입니다.
RULER 벤치마크는 단순한 바늘-건초더미 테스트를 넘어 언어 모델의 긴 컨텍스트 이해 능력을 종합적으로 평가하기 위해 설계되었습니다. 이 벤치마크는 다중 홉 추적, 정보 집계, 질문 응답과 같은 다양한 작업 카테고리를 포함하여 모델이 긴 컨텍스트에서 엔티티를 추적하고, 관련 정보를 집계하며, 질문에 답할 수 있는 능력을 테스트합니다. 이러한 작업들은 단순한 정보 검색을 넘어 더 복잡한 이해와 추론 능력을 요구합니다.
표 9의 결과를 보면, AFM-서버는 4096 토큰 컨텍스트에서 91.7%의 높은 정확도를 보이지만, 컨텍스트 길이가 증가함에 따라 성능이 점진적으로 감소합니다. 8192 토큰에서는 87.7%, 16384 토큰에서는 84.1%, 20480 토큰에서는 79.1%, 24576 토큰에서는 75.8%로 성능이 떨어집니다. 특히 32768 토큰에 도달하면 성능이 43.3%로 급격히 하락하는 것을 볼 수 있습니다.
이러한 성능 저하 패턴은 현재 AFM-서버의 실질적인 컨텍스트 처리 능력이 약 24k 토큰까지는 상당히 안정적이지만, 그 이상에서는 복잡한 작업을 효과적으로 처리하기 어렵다는 것을 시사합니다. 이는 모델이 단순한 정보 검색(NIAH)에서는 32k 이상의 컨텍스트에서도 잘 작동할 수 있지만, 더 복잡한 추론과 이해가 필요한 작업에서는 컨텍스트 길이가 증가함에 따라 어려움을 겪는다는 것을 의미합니다.
RULER 벤치마크는 다양한 시퀀스 길이와 작업 복잡성을 사용자가 설정할 수 있게 하여 모델 성능의 세밀한 분석을 가능하게 합니다. 또한 합성적 특성으로 인해 모델의 매개변수적 지식에 대한 의존도를 줄이고, 모델이 긴 컨텍스트 입력을 효과적으로 활용하는 능력을 독립적으로 평가할 수 있습니다.
이러한 평가 결과는 AFM-서버가 중간 길이의 컨텍스트(24k 토큰까지)에서는 상당히 강력한 성능을 보이지만, 더 긴 컨텍스트에서의 성능 향상을 위해서는 추가적인 개선이 필요하다는 것을 보여줍니다. 이는 현재 많은 대규모 언어 모델들이 직면하고 있는 공통적인 도전 과제로, 모델이 주장하는 컨텍스트 크기와 실제 효과적인 컨텍스트 크기 사이에 차이가 있을 수 있음을 시사합니다.
AFM의 이번 버전이 8k 이상의 컨텍스트 길이 지원에 초점을 맞추지 않았다는 점을 고려할 때, 이러한 결과는 향후 버전에서 긴 컨텍스트 처리 능력을 개선하기 위한 중요한 기준점을 제공합니다. 특히 32k 토큰 이상의 컨텍스트에서 복잡한 작업을 효과적으로 처리하기 위한 모델 아키텍처 및 훈련 방법의 개선이 필요할 것으로 보입니다.
부록 E: RLHF를 위한 기술적 세부사항
E.1 보상 모델링
RLHF(인간 피드백을 통한 강화 학습)에서 보상 모델 훈련에 사용되는 인간 선호도 데이터는 다음과 같은 형식을 갖습니다.
- $x$: 프롬프트(입력 질문이나 지시사항)
- $y_c$: 선택된(선호된) 응답
- $y_r$: 거부된 응답
- $\ell$: 인간 선호도의 수준
- $z^{\text{if}}_c$와 $z^{\text{if}}_r$: 두 응답의 지시 따르기 속성
- $z^{\text{verb}}_c$와 $z^{\text{verb}}_r$: 두 응답의 간결성
- $z^{\text{truth}}_c$와 $z^{\text{truth}}_r$: 두 응답의 진실성
- $z^{\text{harm}}_c$와 $z^{\text{harm}}_r$: 두 응답의 무해성
보상 모델링에서 선호도 수준 $\ell$은 4가지 가능한 값을 가지며, 이는 선택된 응답이 거부된 응답보다 무시할 만큼 더 좋은지, 약간 더 좋은지, 더 좋은지, 또는 현저히 더 좋은지를 나타냅니다. 단일 측면 평가의 경우, 각 레이블(예: $z^{\text{if}}_c$)은 3가지 가능한 값을 가집니다. 지시 따르기, 진실성, 무해성의 경우 3가지 값은 응답에 주요 문제가 있는 경우, 경미한 문제가 있는 경우, 또는 문제가 없는 경우에 해당합니다. 간결성의 경우 3가지 값은 응답이 너무 장황한 경우, 너무 짧은 경우, 또는 적절한 경우에 해당합니다.
보상 모델은 다중 헤드 아키텍처를 사용합니다. 구체적으로, 디코더 전용 트랜스포머를 사용하여 마지막 레이어의 패딩이 아닌 마지막 토큰의 임베딩을 얻습니다. 이 임베딩에 하나의 선형 헤드와 네 개의 MLP 헤드를 연결합니다. 모델 매개변수를 $\phi$로 표시하고 입력 프롬프트-응답 쌍을 $(x, y)$로 표시합니다. 선형 헤드는 선호도 보상 $r_{\phi}(x, y) \in \mathbb{R}$을 출력합니다. 네 개의 MLP 헤드는 응답의 지시 따르기, 간결성, 진실성, 무해성 속성을 나타내는 분류 헤드입니다. 이 네 개의 분류 헤드의 출력 로짓을 각각 $u_{\phi}^{\text{if}}$, $u_{\phi}^{\text{verb}}$, $u_{\phi}^{\text{truth}}$, $u_{\phi}^{\text{harm}}$으로 표시합니다.
소프트 레이블 손실
선호도 보상 $r_{\phi}(x, y)$는 Bradley-Terry-Luce(BTL) 모델을 기반으로 훈련됩니다. BTL 모델에서 $y_c$가 $y_r$보다 선호될 확률은 $\sigma(r_{\phi}(x, y_c) - r_{\phi}(x, y_r))$로 모델링됩니다. 여기서 $\sigma$는 시그모이드 함수입니다. 직관적으로, 이 확률은 선호된 응답 $y_c$가 거부된 응답 $y_r$보다 현저히 더 좋다고 주석이 달린 경우 더 커야 하고, $y_c$가 $y_r$보다 무시할 만큼만 더 좋은 경우 더 작아야 합니다. 이 정보를 선호도 수준 $\ell$을 사용하여 통합합니다. 구체적으로, 각 선호도 수준 $\ell$에 대해 목표 선호도 확률 $p_{\ell}$을 설계합니다. 그런 다음 다음과 같은 소프트 레이블 손실을 사용합니다.
\[L_{\text{ranking}}(\phi) = -p_{\ell}\log(\sigma(r_{\phi}(x,y_c)-r_{\phi}(x,y_r))) - (1-p_{\ell})\log(\sigma(r_{\phi}(x,y_r)-r_{\phi}(x,y_c)))\]목표 수준 $p_{\ell}$은 알고리즘의 하이퍼파라미터이며 선호도 수준이 높을수록 더 큰 값을 가져야 합니다. 실험에서는 현저히 더 좋음, 더 좋음, 약간 더 좋음, 무시할 만큼 더 좋음에 대해 각각 $p_{\ell} = 0.95, 0.85, 0.75, 0.65$를 선택했습니다.
정규화로서의 단일 측면 평가
또한 보상 모델에서 정규화 항으로 단일 측면 평가를 활용합니다. 이러한 평가를 정규화 항으로 사용하면 인간 선호도를 더 잘 포착하는 임베딩을 학습할 수 있습니다. 정규화 손실은 다음과 같습니다.
\[L_{\text{regu}}(\phi) = \sum_{\text{grade}\in{\text{if,verb,truth,harm}}}\Big{(}\mathsf{cross\_entropy}(u_{\phi}^{\text{grade}}(x,y_{c}),z^{\text{grade}}_{c}) + \mathsf{cross\_entropy}(u_{\phi}^{\text{grade}}(x,y_{r}),z^{\text{grade}}_{r})\Big{)}.\]전체적으로, 사용하는 보상 모델 훈련 손실은 다음과 같습니다.
\[L_{\text{ranking}}(\phi) + \lambda L_{\text{regu}}(\phi).\]E.2 온라인 RL 알고리즘
이 섹션에서는 MDLOO(Mirror Descent Leave-One-Out)라는 온라인 RLHF 알고리즘에 대해 더 자세히 설명합니다.
이점(Advantage)의 Leave-One-Out(LOO) 추정기
알고리즘의 각 반복에서는 데이터 수집 단계와 정책 업데이트 단계가 있습니다. $\theta_k$를 $k$번째 반복의 시작 시점의 모델 매개변수라고 합시다. 프롬프트 세트에서 $n$개의 프롬프트 배치를 샘플링하고, 각 프롬프트에 대해 정책 $\pi_{\theta_k}$에 따라 $K$개의 응답을 샘플링하여 각 반복에서 총 $nK$개의 데이터 포인트를 수집합니다. $x$를 프롬프트, $y_i$를 응답 중 하나라고 합시다. 밴딧 설정을 고려하므로, 정의에 따라 $(x, y_i)$의 이점은 다음과 같습니다.
\[A_k(x, y_i) = R(x, y_i) - \mathbb{E}_{y \sim \pi_{\theta_k}(\cdot|x)}[R(x, y)].\]$A_k(x, y_i)$를 추정하기 위해 leave-one-out(LOO) 방법을 사용합니다. 즉, 다른 $K-1$개의 응답으로 프롬프트 $x$가 주어졌을 때의 평균 보상을 추정합니다.
\[\widehat{A}_k(x, y_i) = R(x, y_i) - \frac{1}{K-1}\sum_{j \neq i}R(x, y_j).\]최근 연구에서 보여주듯이, 이 이점 추정은 RLHF에 유익합니다. 경험적으로, LOO 추정기를 사용하면 보상을 직접 이점 추정으로 사용하거나 실행 평균 기준선을 사용하는 것보다 더 안정적인 훈련과 더 나은 결과를 얻을 수 있다는 것을 발견했습니다.
미러 디센트 정책 최적화(MDPO)
정책 최적화 접근 방식은 널리 사용되는 신뢰 영역 정책 최적화 알고리즘 클래스에 속합니다. 이러한 알고리즘의 기본 아이디어는 각 정책 반복에서 정책이 한 반복에서 너무 많이 변경되지 않도록 정규화 방법을 적용하는 것입니다. 정규화는 KL 정규화를 추가하거나 PPO에서와 같이 확률 비율에 대한 클리핑을 사용하여 달성할 수 있습니다. 이 연구에서는 미러 디센트 정책 최적화(MDPO)에서와 같이 KL 정규화를 사용합니다. 특히, $k$번째 반복에서, 데이터(각 프롬프트에 대해 $\pi_{\theta_k}$에 따라 샘플링된 $K$개의 응답과 함께 프롬프트)를 사용하여 다음과 같은 정규화된 이점 최대화 문제를 최적화하는 것을 목표로 합니다.
\[\max_{\theta}\Psi(\theta) := \mathbb{E}_{x\sim\mathcal{D}}\left[\mathbb{E}_{y\sim\pi_{\theta_k}(\cdot|x)}[A_k(x,y)] - \gamma D_{\text{KL}}(\pi_{\theta}(\cdot|x) || \pi_{\theta_k}(\cdot|x))\right].\]여기서 KL 정규화 항은 식 (1)의 항과 다릅니다. 식 (1)의 KL 정규화는 정책 모델과 참조 모델 사이의 것인 반면, 식 (8)의 KL 정규화 항은 정책 모델과 $k$번째 반복의 시작 시점의 정책 사이의 것입니다. 그러면 $\Psi(\theta)$의 그래디언트를 다음과 같이 얻을 수 있습니다.
\[\nabla\Psi(\theta) = \mathbb{E}_{x\sim\mathcal{D},y\sim\pi_{\theta_k}(\cdot|x)}\left[\frac{\pi_{\theta}(y|x)}{\pi_{\theta_k}(y|x)}A_k(x,y) \nabla\log\pi_{\theta}(y|x)\right] - \gamma\mathbb{E}_{x\sim\mathcal{D}}\left[ \nabla D_{\text{KL}}\pi_{\theta}(\cdot|x) || \pi_{\theta_k}(\cdot|x)\right].\]MDLOO 알고리즘은 식 (9)의 기대값을 $\pi_{\theta_k}$로 수집된 $nK$ 샘플로 대체하고, 이점 $A_k(x, y)$를 식 (7)의 LOO 추정기 $\widehat{A}_k(x, y)$로 대체하여 도출할 수 있습니다. 경험적으로, MDLOO가 이 설정에서 널리 사용되는 PPO 알고리즘보다 더 잘 작동한다는 것을 발견했습니다.
부록 F: 정확도 복구 어댑터 절제 연구
이 섹션에서는 비양자화, 양자화, 그리고 정확도가 복구된 모델에 대한 평가 결과를 살펴보겠습니다. 표 10에서 볼 수 있듯이, 양자화된 모델은 사전 학습 및 사후 학습 메트릭 모두에서 상당한 품질 저하를 보입니다. 그러나 랭크 16의 정확도 복구 LoRA 어댑터를 사용함으로써 Alpaca 승률은 7-18% 향상되고, GSM8K 정확도는 5-10% 향상됩니다. 복구된 모델은 모델 크기를 크게 줄이면서도 원래의 비양자화 모델에 훨씬 더 가까운 성능을 보여줍니다.
흥미로운 점은 양자화 스킴이 더 공격적으로 변할수록(3.7에서 3.5 bpw로), 어댑터가 더 많은 품질을 복구한다는 것입니다. 이는 정확도 복구 어댑터가 더 높은 압축률에서도 모델 성능을 유지하는 데 특히 효과적임을 시사합니다.
| BPW | 모델 | IFEval | Alpaca Eval 2.0 LC | GSM8K (8-샷 CoT) |
|---|---|---|---|---|
| 16 | AFM-온디바이스 | 100.0% | 100.0% | 100.0% |
| 3.5 | 양자화 | 98.4% | 76.7% | 82.2% |
| 정확도 복구 (랭크 16) | 98.8% | 94.7% | 92.1% | |
| 3.7 | 양자화 | 97.9% | 87.3% | 91.3% |
| 정확도 복구 (랭크 16) | 100.6% | 94.8% | 96.0% |
표 10: 양자화 및 정확도 복구 모델에 대한 평가 결과. 수치는 비양자화 버전 대비 정규화되었습니다.
이 결과는 LoRA 어댑터가 양자화로 인한 정확도 손실을 효과적으로 복구할 수 있음을 명확하게 보여줍니다. 특히 3.5 bpw 양자화의 경우, Alpaca Eval 2.0 LC에서 76.7%에서 94.7%로, GSM8K에서 82.2%에서 92.1%로 성능이 크게 향상되었습니다. 3.7 bpw 양자화의 경우에도 유사한 개선이 관찰되었으며, Alpaca Eval에서 87.3%에서 94.8%로, GSM8K에서 91.3%에서 96.0%로 향상되었습니다.
이러한 정확도 복구 어댑터의 효과는 Hu와 연구진이 제안한 LoRA(Low-Rank Adaptation) 방법론의 강점을 보여줍니다. LoRA는 사전 훈련된 모델의 가중치를 직접 수정하지 않고 저차원 분해 행렬을 주입하여 모델을 효율적으로 적응시키는 방법입니다. 이 접근법은 원래 다운스트림 작업에 모델을 미세 조정하기 위해 개발되었지만, 여기서는 양자화로 인한 정확도 손실을 복구하는 데 효과적으로 활용되고 있습니다.
양자화 스킴이 더 공격적일수록(3.7 bpw에서 3.5 bpw로) 어댑터가 더 많은 품질을 복구한다는 관찰은 특히 주목할 만합니다. 3.5 bpw 양자화에서 Alpaca Eval 성능은 76.7%에서 94.7%로 18% 향상되었지만, 3.7 bpw에서는 87.3%에서 94.8%로 7.5% 향상되었습니다. 이는 더 공격적인 양자화가 더 많은 정보 손실을 초래하지만, LoRA 어댑터가 이러한 손실을 효과적으로 보상할 수 있음을 시사합니다.
이 결과는 Dettmers와 연구진이 제안한 QLoRA와 개념적으로 유사하지만, 중요한 차이점이 있습니다. QLoRA는 미세 조정 중에 계산 리소스를 절약하기 위해 설계된 반면, 이 연구에서의 초점은 다양한 LoRA 어댑터 간에 전환하여 다양한 특정 사용 사례에서 높은 성능을 효율적으로 지원하는 능력에 있습니다.
또한 이 정확도 복구 프레임워크는 Frantar와 연구진이 제안한 GPTQ 및 Lin과 연구진이 제안한 AWQ와 같은 다양한 양자화 기법과 결합될 수 있습니다. 이는 양자화 방법 자체에 직접적으로 의존하지 않기 때문입니다.
정확도 복구 어댑터의 또 다른 이점은 더 유연한 양자화 스킴 선택을 가능하게 한다는 것입니다. 일반적으로 LLM을 양자화할 때, 가중치를 작은 블록으로 그룹화하고 각 블록을 해당 최대 절대값으로 정규화하여 이상치를 필터링한 다음, 블록 단위로 양자화 알고리즘을 적용합니다. 더 큰 블록 크기는 가중치당 더 낮은 효과적인 비트와 더 높은 처리량을 제공하지만, 양자화 손실이 증가합니다. 이러한 균형을 맞추기 위해 일반적으로 블록 크기를 64나 32와 같은 작은 값으로 설정합니다.
그러나 정확도 복구 어댑터를 사용하면 이러한 균형에서 파레토 프론티어를 크게 개선할 수 있습니다. 더 공격적인 양자화 스킴에서 더 많은 오류가 복구되기 때문에, 모델 용량을 잃을 걱정 없이 고효율 양자화 스킴을 사용할 수 있게 됩니다. 이는 표 10의 결과에서 명확하게 드러나며, 특히 3.5 bpw와 같은 더 공격적인 양자화 설정에서도 정확도 복구 어댑터가 성능을 효과적으로 복원할 수 있음을 보여줍니다.
이러한 정확도 복구 어댑터는 AFM 모델의 기능별 어댑터를 초기화하는 데도 사용됩니다. 제품팀은 양자화된 기본 모델을 고정한 상태에서 정확도 복구 어댑터에서 어댑터 가중치를 초기화하여 자체 기능별 LoRA 어댑터를 미세 조정합니다. 이는 양자화로 인한 정확도 손실을 복구하면서도 특정 작업에 모델을 최적화할 수 있게 해줍니다.
정확도 복구 어댑터 훈련은 샘플 효율적이며, 기본 모델 훈련의 미니 버전으로 간주될 수 있습니다. 어댑터의 사전 훈련 단계에서는 양자화된 모델의 용량을 완전히 복구하기 위해 약 100억 개의 토큰(기본 모델 훈련의 약 0.15%)만 필요합니다. 이는 전체 모델을 재훈련하는 것보다 훨씬 효율적인 접근 방식입니다.
랭크 16 어댑터가 모델 용량과 추론 성능 사이의 최적의 균형을 제공한다는 것이 발견되었지만, 다양한 사용 사례에 유연성을 제공하기 위해 애플리케이션 팀이 선택할 수 있는 다양한 랭크 ${8, 16, 32}$의 정확도 복구 어댑터 세트가 제공됩니다. 이를 통해 각 애플리케이션의 특정 요구 사항에 맞게 최적의 어댑터를 선택할 수 있습니다.
결론적으로, 정확도 복구 어댑터는 양자화된 모델의 성능을 원래의 비양자화 모델에 가깝게 복원하면서도 모델 크기를 크게 줄일 수 있는 효과적인 방법입니다. 이는 제한된 리소스를 가진 디바이스에서 고성능 언어 모델을 배포하는 데 중요한 기술적 발전을 나타냅니다.
References
Subscribe via RSS