DeepSeek-Coder: When the Large Language Model Meets Programming - The Rise of Code Intelligence
by DeepSeek AI
TL;DR
이 연구를 시작하게 된 배경과 동기는 무엇입니까?
현재 코드 인텔리전스 분야에서는 대부분의 고성능 모델들이 비공개 소스로 제공되어 연구 개발의 확장성과 접근성에 상당한 제약이 있었습니다. 특히 GPT-4나 Gemini와 같은 비공개 모델들이 뛰어난 성능을 보여주고 있지만, 이러한 모델들의 기술적 세부사항이나 학습 방법론에 대한 접근이 제한되어 있었습니다. 이러한 한계를 극복하고 코드 인텔리전스 분야의 발전을 가속화하기 위해 DeepSeek-Coder 연구가 시작되었습니다.
이 연구에서 제시하는 새로운 해결 방법은 무엇입니까?
DeepSeek-Coder는 세 가지 핵심적인 기술적 혁신을 도입했습니다. 첫째, 87개의 프로그래밍 언어를 포괄하는 2조 개의 토큰으로 구성된 대규모 데이터셋을 구축했습니다. 둘째, 저장소 수준의 데이터 구성을 통해 파일 간의 상호 관계를 이해하는 능력을 향상시켰습니다. 셋째, Fill-In-Middle (FIM) 접근 방식을 도입하여 코드 완성 능력을 강화했습니다. 특히 16K 토큰의 확장된 컨텍스트 윈도우를 도입하여 더 긴 코드 시퀀스를 효과적으로 처리할 수 있게 했습니다.
제안된 방법은 어떻게 구현되었습니까?
DeepSeek-Coder는 1.3B부터 33B 파라미터에 이르는 다양한 규모의 모델을 제공합니다. 학습 데이터는 소스 코드 87%, 영어 코드 관련 자연어 코퍼스 10%, 중국어 자연어 코퍼스 3%로 구성되었습니다. 데이터 구축 과정에서는 크롤링, 규칙 기반 필터링, 의존성 분석, 저장소 수준의 중복 제거, 품질 검사 단계를 거쳤습니다. 특히 의존성 분석을 통해 파일 간의 호출 관계를 고려한 학습 데이터를 구성했으며, Fill-In-Middle 학습 전략을 통해 코드의 전체적인 구조와 흐름을 이해하도록 했습니다.
이 연구의 결과가 가지는 의미는 무엇입니까?
DeepSeek-Coder는 다양한 벤치마크에서 기존의 오픈소스 코드 모델들을 능가하는 성능을 보여주었으며, 특히 DeepSeek-Coder-Instruct 33B 모델은 GPT-3.5 Turbo의 성능을 뛰어넘는 결과를 달성했습니다. 더욱 주목할 만한 점은 7B 규모의 모델이 33B 규모의 다른 모델들과 비교해도 경쟁력 있는 성능을 보여주었다는 것입니다. 이는 모델 크기보다 효율적인 학습 방법과 데이터 구성이 더 중요할 수 있다는 점을 시사합니다. 또한 이 연구는 코드 인텔리전스 분야에서 오픈소스 모델의 가능성을 입증하고, 향후 연구 방향을 제시했다는 점에서 큰 의미를 가집니다.
DeepSeek-Coder: 코드 인텔리전스의 부상과 대규모 언어 모델의 만남
저자 정보 및 연구 개요
DeepSeek-AI와 북경대학교 연구진이 공동으로 개발한 DeepSeek-Coder는 코드 생성과 이해를 위한 혁신적인 대규모 언어 모델입니다. Chen과 연구진이 제시한 Codex 모델의 성공을 기반으로, DeepSeek-Coder는 프로그래밍 분야에서 한층 발전된 인공지능 기술을 구현하고자 합니다.
이 연구는 DeepSeek-AI의 핵심 연구진들이 주도했으며, 특히 북경대학교의 소프트웨어 공학 연구실과의 협력을 통해 진행되었습니다. Rozière와 연구진이 개발한 Code Llama와 유사하게, DeepSeek-Coder는 대규모 언어 모델의 강력한 자연어 처리 능력을 프로그래밍 도메인에 효과적으로 적용하는 것을 목표로 합니다.
본 연구는 GitHub를 통해 공개되어 있어 학계와 산업계에서 자유롭게 활용할 수 있으며, 이는 Wang과 연구진이 CodeT5를 통해 보여준 오픈소스 접근방식을 따르고 있습니다. 이러한 공개적인 연구 방식은 코드 인텔리전스 분야의 발전을 가속화하고, 더 넓은 커뮤니티의 참여를 촉진하는데 기여할 것으로 기대됩니다.
DeepSeek-Coder: 코드 인텔리전스의 혁신과 오픈소스 모델의 도약
연구의 배경과 핵심 기여
대규모 언어 모델의 급속한 발전은 소프트웨어 개발 분야에서 코드 인텔리전스의 혁신을 이끌어왔습니다. 그러나 현재까지 대부분의 고성능 모델들이 비공개 소스로 제공되어 왔기 때문에, 연구 개발의 확장성과 접근성에 상당한 제약이 있었습니다. 이러한 한계를 극복하고자 DeepSeek-Coder 시리즈가 개발되었습니다.
DeepSeek-Coder는 1.3B부터 33B 파라미터에 이르는 다양한 규모의 오픈소스 코드 모델을 제공합니다. 이 모델들은 2조 개의 토큰으로 구성된 방대한 데이터셋에서 처음부터 학습되었으며, 프로젝트 수준의 고품질 코드 코퍼스를 기반으로 합니다. 특히 16K 윈도우 크기를 활용한 fill-in-the-blank 태스크를 통해 코드 생성과 채우기 능력을 향상시켰습니다.

위 그래프는 LeetCode 주간 코딩 대회에서 DeepSeek-Coder를 포함한 다양한 AI/ML 모델들의 성능을 보여줍니다. Python, Java, JavaScript, C# 등 여러 프로그래밍 언어에서의 성능을 비교한 결과, DeepSeek-Coder가 GPT-4-Turbo와 GPT-3.5-Turbo를 포함한 다른 모델들을 능가하는 우수한 성능을 보여주었습니다.
광범위한 평가 결과에 따르면, DeepSeek-Coder는 다양한 벤치마크에서 기존의 오픈소스 코드 모델들을 능가하는 성능을 보여주었을 뿐만 아니라, Codex와 GPT-3.5와 같은 비공개 모델들의 성능도 뛰어넘었습니다. 더욱이 DeepSeek-Coder 모델들은 연구 목적뿐만 아니라 상업적 사용에도 제약이 없는 허용적인 라이선스 하에 제공됩니다.
코드 인텔리전스의 현재와 도전 과제
소프트웨어 개발 분야에서 대규모 언어 모델의 발전은 코드 자동 생성, 버그 감지, 코드 최적화 등 다양한 측면에서 혁신을 가져왔습니다. Touvron과 연구진이 제시한 바와 같이, 이러한 모델들은 개발자의 생산성을 향상시키고 인적 오류를 줄이는데 큰 잠재력을 보여주고 있습니다.
그러나 현재 코드 인텔리전스 분야에서 가장 큰 도전 과제는 오픈소스 모델과 비공개 모델 간의 성능 격차입니다. Rozière와 연구진이 개발한 Code Llama와 같은 오픈소스 모델들이 꾸준히 발전해왔지만, OpenAI나 Gemini Team이 개발한 비공개 모델들의 성능에는 미치지 못했습니다.
DeepSeek-Coder의 혁신적 접근
DeepSeek-Coder는 이러한 성능 격차를 해소하기 위해 세 가지 핵심적인 기술적 혁신을 도입했습니다. 첫째, 87개의 프로그래밍 언어를 포괄하는 2조 개의 토큰으로 구성된 대규모 데이터셋을 활용했습니다. 둘째, 저장소 수준의 데이터 구성을 통해 파일 간의 상호 관계를 이해하는 능력을 향상시켰습니다. 셋째, Li와 연구진이 제안한 Fill-In-Middle (FIM) 접근 방식을 도입하여 코드 완성 능력을 강화했습니다.
DeepSeek-Coder의 주요 기술적 기여
DeepSeek-Coder 시리즈는 코드 인텔리전스 분야에서 네 가지 핵심적인 기술적 혁신을 제시합니다. 첫째, 모델의 기본 구조를 다양한 규모로 확장하여 1.3B부터 33B 파라미터까지 제공함으로써, 연구자들이 자원 제약에 따라 적절한 모델을 선택할 수 있게 했습니다. 각 규모별로 기본 버전과 지시어 학습 버전을 함께 제공하여, 다양한 응용 시나리오에 대응할 수 있도록 했습니다.
둘째, 저장소 수준의 데이터 구성 방식을 도입했습니다. 이는 단순히 개별 코드 파일을 학습하는 것을 넘어서, 전체 프로젝트 컨텍스트 내에서 파일 간의 상호 의존성과 관계를 이해하도록 설계되었습니다. 이러한 접근 방식은 크로스-파일 코드 생성 능력을 크게 향상시켰습니다.
셋째, Fill-In-Middle (FIM) 학습 전략을 코드 모델의 사전 학습 단계에 통합했습니다. 이 방식은 코드의 중간 부분을 예측하는 태스크를 통해 모델의 문맥 이해 능력을 향상시킵니다. FIM 학습은 단순한 다음 토큰 예측을 넘어서, 코드의 전체적인 구조와 흐름을 이해하는 데 중요한 역할을 합니다.
넷째, 16K 토큰의 확장된 컨텍스트 윈도우를 도입했습니다. 이는 더 긴 코드 시퀀스를 처리할 수 있게 함으로써, 복잡한 프로그래밍 과제와 대규모 코드베이스 작업에서 더 나은 성능을 발휘할 수 있게 합니다. 특히 프로젝트 수준의 코드 이해와 생성에서 이 확장된 컨텍스트 길이는 큰 장점으로 작용합니다.
성능 평가와 실험 결과
DeepSeek-Coder의 성능 평가는 다양한 공개 코드 관련 벤치마크를 통해 이루어졌습니다. DeepSeek-Coder-Base 33B 모델은 모든 벤치마크에서 기존 오픈소스 모델들을 능가하는 성능을 보여주었습니다. 특히 주목할 만한 점은 DeepSeek-Coder-Instruct 33B가 OpenAI GPT-3.5 Turbo보다 대부분의 평가 지표에서 우수한 성능을 보여주었다는 것입니다.
더욱 흥미로운 점은 DeepSeek-Coder-Base 7B 모델의 성능입니다. 이 모델은 CodeLlama-33B와 같은 훨씬 더 큰 모델들과 비교해도 경쟁력 있는 성능을 보여주었습니다. 이는 모델 크기만이 성능을 결정하는 것이 아니라, 효율적인 학습 방법과 데이터 구성이 더욱 중요할 수 있다는 점을 시사합니다.
DeepSeek-Coder의 데이터셋 구축
DeepSeek-Coder의 학습 데이터셋은 소스 코드 87%, 영어 코드 관련 자연어 코퍼스 10%, 중국어 자연어 코퍼스 3%로 구성되어 있습니다. 영어 코퍼스는 GitHub의 마크다운 문서와 StackExchange에서 수집된 자료로, 모델이 코드 관련 개념을 이해하고 라이브러리 사용법이나 버그 수정과 같은 작업을 수행하는 능력을 향상시키는 데 활용됩니다. 중국어 코퍼스는 고품질 기술 문서들로 구성되어 중국어 이해 능력을 향상시키는 데 사용됩니다.

데이터셋 구축 과정은 위 그림과 같이 데이터 크롤링, 규칙 기반 필터링, 의존성 분석, 저장소 수준의 중복 제거, 품질 검사 단계로 이루어집니다. 이러한 체계적인 접근을 통해 고품질의 학습 데이터를 확보할 수 있습니다.
GitHub 데이터 수집 및 필터링
GitHub에서 2023년 2월 이전에 생성된 공개 저장소들을 수집하여, 87개의 프로그래밍 언어로 작성된 코드만을 선별했습니다. StarCoder 프로젝트에서 사용된 것과 유사한 필터링 규칙을 적용하여 초기 데이터의 32.8%만을 선별했습니다. 주요 필터링 규칙은 다음과 같습니다.
- 평균 줄 길이가 100자를 초과하거나 최대 줄 길이가 1000자를 초과하는 파일 제외
- 알파벳 문자가 25% 미만인 파일 제외
- XSLT를 제외한 모든 언어에서 첫 100자 내에 “<?xml version=”이 포함된 파일 제외
- HTML 파일의 경우 가시적 텍스트 비율이 20% 이상이고 100자 이상인 파일만 유지
- JSON과 YAML 파일은 50~5000자 사이의 파일만 유지하여 데이터 중심 파일 제거
의존성 분석
기존 코드 언어 모델들이 주로 파일 단위의 소스 코드로 학습되어 프로젝트 수준의 코드를 효과적으로 다루지 못하는 한계를 극복하기 위해, DeepSeek-Coder는 동일 저장소 내 파일들 간의 의존성을 고려합니다. 파일 간의 호출 관계를 분석하여 의존성 그래프를 구성하고, 각 파일이 의존하는 컨텍스트가 해당 파일보다 앞서 입력 시퀀스에 배치되도록 정렬합니다.
이를 위해 Python의 “import”, C#의 “using”, C의 “include”와 같은 키워드를 정규 표현식으로 추출하여 파일 간의 의존성을 파악합니다. 위상 정렬 알고리즘을 사용하여 의존성을 고려한 파일 순서를 결정하며, 이는 실제 코딩 관행과 구조를 더 정확하게 반영하여 모델의 프로젝트 수준 코드 이해 능력을 향상시킵니다.
의존성 분석 알고리즘
의존성 분석을 위한 위상 정렬 알고리즘은 프로젝트 내 파일들의 의존 관계를 효과적으로 처리합니다. 알고리즘은 먼저 그래프 자료구조와 진입차수(in-degree) 사전을 초기화합니다. 각 파일에 대해 그래프에 빈 인접 리스트를 생성하고 진입차수를 0으로 설정합니다.
알고리즘은 모든 파일 쌍에 대해 의존성을 검사하며, 파일 A가 파일 B에 의존할 경우 B에서 A로 향하는 간선을 추가하고 A의 진입차수를 증가시킵니다. 이후 연결되지 않은 서브그래프들을 식별하고, 각 서브그래프에 대해 수정된 위상 정렬을 수행합니다.
일반적인 위상 정렬과 달리, 이 알고리즘은 진입차수가 0인 노드만을 선택하는 대신 최소 진입차수를 가진 노드를 선택합니다. 이는 그래프 내 순환이 존재할 경우에도 적절한 순서를 생성할 수 있게 합니다. 선택된 노드의 이웃들의 진입차수를 감소시키고, 이 과정을 모든 노드가 처리될 때까지 반복합니다.
저장소 수준의 중복 제거
대규모 언어 모델의 학습 데이터셋에서 중복 제거가 성능 향상에 중요한 역할을 한다는 것이 여러 연구를 통해 입증되었습니다. Lee와 연구진은 언어 모델 학습 코퍼스에 많은 근접 중복이 존재하며, 긴 반복 문자열을 제거함으로써 모델의 성능을 향상시킬 수 있다는 것을 보여주었습니다.
DeepSeek-Coder는 기존 연구들과 달리 파일 수준이 아닌 저장소 수준에서 중복 제거를 수행합니다. 파일 수준의 중복 제거는 저장소 내 특정 파일들을 필터링하여 저장소의 구조를 훼손할 수 있기 때문입니다. 대신 저장소 수준에서 연결된 코드를 하나의 샘플로 취급하고 동일한 근접 중복 제거 알고리즘을 적용하여 저장소 구조의 무결성을 유지합니다.
품질 검사와 오염 방지
DeepSeek-Coder는 앞서 설명한 기본적인 필터링 규칙 외에도 컴파일러와 품질 모델, 그리고 휴리스틱 규칙을 조합하여 추가적인 데이터 필터링을 수행합니다. 이를 통해 구문 오류가 있는 코드, 가독성이 떨어지는 코드, 모듈화가 부족한 코드 등을 제거합니다.
최종적으로 구축된 소스 코드 데이터셋은 총 798GB 규모로, 6억 3백만 개의 파일을 포함하고 있습니다. Java가 18.63%로 가장 큰 비중을 차지하며, Python이 15.12%, C++이 11.39%를 차지합니다. TypeScript(7.60%), PHP(7.38%), JavaScript(6.75%) 등도 상당한 비중을 보입니다.
테스트 셋의 정보가 학습 데이터에 포함되는 것을 방지하기 위해 n-gram 기반의 필터링을 구현했습니다. 특히 HumanEval, MBPP, GSM8K, MATH 등의 벤치마크에서 나온 문제와 해답이 포함된 파일들을 제거하는 데 중점을 두었습니다. 필터링 기준은 다음과 같습니다.
테스트 데이터와 동일한 10-gram 문자열을 포함하는 코드는 학습 데이터에서 제외됩니다. 테스트 데이터의 문자열이 10-gram보다 짧지만 3-gram 이상인 경우에는 정확한 매칭 방식으로 필터링을 수행합니다. 이러한 엄격한 필터링을 통해 테스트 데이터의 오염을 방지하고 모델 평가의 신뢰성을 확보합니다.
이러한 체계적인 데이터 구축 과정을 통해 DeepSeek-Coder는 고품질의 학습 데이터셋을 확보할 수 있었으며, 이는 모델의 성능과 신뢰성 향상에 핵심적인 역할을 합니다. 특히 저장소 수준의 중복 제거와 의존성 분석을 통해 실제 소프트웨어 개발 환경을 더욱 정확하게 반영하는 데이터셋을 구축했다는 점이 주목할 만합니다.
학습 정책과 모델 구조
학습 목표와 전략
DeepSeek-Coder의 학습은 두 가지 핵심적인 목표를 중심으로 이루어집니다. 첫 번째는 다음 토큰 예측(Next Token Prediction)으로, 고정 길이의 입력을 구성하여 주어진 컨텍스트를 기반으로 다음에 올 토큰을 예측하는 것입니다.
두 번째는 중간 채우기(Fill-in-the-Middle, FIM) 방식입니다. 코드 사전 학습 과정에서는 주어진 컨텍스트와 이후 텍스트를 기반으로 중간에 들어갈 내용을 생성해야 하는 경우가 많습니다. Bavarian과 연구진이 제안한 FIM 방식은 텍스트를 세 부분으로 무작위로 나누고, 이 부분들의 순서를 섞은 후 특수 문자로 연결하는 방식을 사용합니다.

FIM 방식에는 PSM(Prefix-Suffix-Middle)과 SPM(Suffix-Prefix-Middle)이라는 두 가지 모드가 있습니다. PSM 모드에서는 텍스트가 \(\text{Prefix}, \text{Suffix}, \text{Middle}\) 순서로 구성되며, SPM 모드에서는 \(\text{Suffix}, \text{Prefix}, \text{Middle}\) 순서로 구성됩니다.
DeepSeek-Coder-Base 1.3B 모델을 사용한 실험에서는 HumanEval-FIM 벤치마크를 통해 FIM 기법의 효과를 평가했습니다. 이 벤치마크는 Python 코드에서 한 줄을 무작위로 가려두고 모델이 이를 예측하는 단일 라인 FIM 태스크입니다. 실험 결과, 100% FIM 비율에서 HumanEval-FIM 성능이 가장 높았지만, 코드 완성 능력은 가장 낮았습니다. 이는 FIM과 코드 완성 능력 사이에 트레이드오프가 존재함을 보여줍니다.
최종적으로 50% PSM 비율이 MSP(Masked Span Prediction) 전략보다 우수한 성능을 보여 이를 학습 정책으로 채택했습니다. 구현에는 세 개의 특수 토큰을 도입했으며, 각 코드 파일을 \(f_{pre}\), \(f_{middle}\), \(f_{suf}\) 세 부분으로 나누어 다음과 같은 형태로 학습 예제를 구성합니다.
\[\texttt{<|fim_start|>}f_{pre}\texttt{<|fim_hole|>}f_{suf}\texttt{<|fim_end|>}f_{middle}\texttt{<|eos_token|>}\]DeepSeek-Coder의 실험 결과 분석
DeepSeek-Coder의 성능을 평가하기 위해 네 가지 주요 과제에서 광범위한 실험을 진행했습니다. 코드 생성, FIM 코드 완성, 크로스 파일 코드 완성, 그리고 프로그램 기반 수학적 추론 능력을 평가했으며, 이를 최신 대규모 언어 모델들과 비교했습니다.
비교 대상으로는 CodeGeeX2, StarCoder, CodeLlama, code-cushman-001, GPT-3.5, GPT-4와 같은 주요 모델들이 포함되었습니다. CodeGeeX2는 ChatGLM2 아키텍처를 기반으로 개발된 다국어 코드 생성 모델의 2세대 버전이며, StarCoder는 86개 프로그래밍 언어를 지원하는 150억 파라미터 규모의 공개 모델입니다. CodeLlama는 LLaMA2를 기반으로 5천억 토큰의 코드 데이터로 추가 학습된 모델 시리즈이며, code-cushman-001은 GitHub Copilot의 초기 모델로 사용된 OpenAI의 120억 파라미터 모델입니다.
코드 생성 성능 평가
HumanEval과 MBPP 벤치마크에서의 평가 결과, DeepSeek-Coder-Base는 HumanEval에서 평균 50.3%, MBPP에서 66.0%의 정확도를 달성했습니다. 특히 주목할 만한 점은 67억 파라미터의 DeepSeek-Coder-Base가 340억 파라미터의 CodeLlama-Base보다 우수한 성능을 보여주었다는 것입니다.
DeepSeek-Coder-Base 33B 모델은 Python에서 56.1%, C++에서 58.4%, Java에서 51.9%의 정확도를 달성했습니다. 지시어 미세조정을 거친 DeepSeek-Coder-Instruct 모델은 GPT-3.5-Turbo의 성능을 뛰어넘어 GPT-4와의 성능 격차를 크게 줄였습니다.
DS-1000 벤치마크에서는 실제 데이터 과학 워크플로우에서의 코드 생성 능력을 평가했습니다. 이 벤치마크는 Matplotlib, NumPy, Pandas, SciPy, Scikit-Learn, PyTorch, TensorFlow와 같은 7개의 주요 라이브러리에 걸쳐 1,000개의 실용적인 문제를 포함하고 있습니다.
DS-1000 평가에서 DeepSeek-Coder는 모든 라이브러리에서 높은 정확도를 보여주었으며, 특히 Matplotlib에서 56.1%, NumPy에서 49.6%, PyTorch에서 36.8%의 정확도를 달성했습니다. 이는 모델이 단순한 코드 생성을 넘어 실제 데이터 과학 워크플로우에서도 라이브러리를 정확하게 활용할 수 있음을 보여줍니다.
LeetCode 대회 벤치마크 평가
실제 프로그래밍 문제 해결 능력을 더욱 엄격하게 평가하기 위해 LeetCode 대회 문제들을 기반으로 새로운 벤치마크를 구축했습니다. 2023년 7월부터 2024년 1월까지 진행된 LeetCode 대회의 최신 문제 180개를 수집하여 각 문제당 100개의 테스트 케이스를 포함시켰습니다. 이는 사전 학습 데이터의 오염을 방지하기 위해 최신 문제들만을 선별한 것입니다.
LeetCode 대회 벤치마크 평가에서 DeepSeek-Coder-Instruct 모델들은 기존 오픈소스 코딩 모델들을 크게 앞서는 성능을 보여주었습니다. 67억 파라미터의 DeepSeek-Coder-Instruct는 19.4%, 330억 파라미터 모델은 27.8%의 Pass@1 점수를 달성했습니다. 특히 330억 파라미터 모델은 GPT-3.5-Turbo를 능가하는 유일한 오픈소스 모델이 되었습니다.
체인 오브 소트(Chain-of-Thought, CoT) 프롬프팅을 적용했을 때 DeepSeek-Coder-Instruct 모델들의 성능이 더욱 향상되었습니다. “먼저 단계별 개요를 작성한 다음 코드를 작성해야 합니다”라는 지시문을 추가함으로써, 특히 복잡한 문제에서 더 나은 성능을 보여주었습니다. 이는 코드 작성 전에 상세한 설명을 구성하는 과정이 로직과 의존성을 더 효과적으로 이해하고 처리하는 데 도움이 된다는 것을 시사합니다.
FIM 코드 완성 평가
DeepSeek-Coder 모델들은 사전 학습 단계에서 0.5의 FIM(Fill-In-the-Middle) 비율로 학습되었습니다. 이 특별한 학습 전략은 모델이 주어진 코드 스니펫의 앞뒤 문맥을 기반으로 빈 칸을 채우는 능력을 향상시켰습니다. 이는 코드 완성 도구에서 특히 유용한 기능입니다.
단일 라인 채우기 벤치마크에서 DeepSeek-Coder는 13억 파라미터라는 작은 모델 크기에도 불구하고 StarCoder와 CodeLlama와 같은 더 큰 모델들보다 우수한 성능을 보여주었습니다. 이러한 성능 우위는 DeepSeek-Coder가 사용한 고품질 사전 학습 데이터의 효과를 입증합니다. 또한 모델 크기가 증가할수록 성능도 함께 향상되는 경향을 보였으며, 이는 코드 완성 태스크에서 모델 용량의 중요성을 보여줍니다.
크로스 파일 코드 완성 평가
크로스 파일 코드 완성 태스크에서는 기존 오픈소스 모델들의 성능을 평가했습니다. 이 태스크는 단순한 코드 생성과 달리 여러 파일에 걸친 의존성을 가진 저장소에 대한 접근과 이해가 필요합니다. CrossCodeEval을 사용하여 7B 규모의 오픈소스 코드 모델들의 크로스 파일 완성 능력을 평가했습니다. 이 데이터셋은 Python, Java, TypeScript, C# 등 네 가지 주요 프로그래밍 언어로 작성된 실제 오픈소스 저장소들을 기반으로 구성되었습니다.
평가 과정에서는 최대 시퀀스 길이를 2048 토큰으로 설정하고, 최대 출력 길이는 50 토큰, 크로스 파일 컨텍스트는 512 토큰으로 제한했습니다. 크로스 파일 컨텍스트를 위해 Ding과 연구진이 제공한 공식 BM25 검색 결과를 활용했습니다. 정확한 매칭과 편집 유사도를 평가 지표로 사용했습니다.
DeepSeek-Coder는 여러 프로그래밍 언어에 걸쳐 크로스 파일 완성 태스크에서 일관되게 우수한 성능을 보여주었습니다. 특히 저장소 수준의 사전 학습 없이 파일 수준의 코드 코퍼스만으로 학습했을 때, Java, TypeScript, C# 언어에서 성능 저하가 관찰되었습니다. 이는 저장소 수준의 사전 학습이 효과적으로 크로스 파일 컨텍스트를 포착하는 데 중요한 역할을 한다는 것을 보여줍니다.
프로그램 기반 수학 추론 평가
프로그램 기반 수학 추론은 모델이 프로그래밍을 통해 수학 문제를 이해하고 해결하는 능력을 평가합니다. 이 평가를 위해 Gao와 연구진이 제안한 프로그램 보조 수학 추론(PAL) 방법을 7개의 서로 다른 벤치마크에 적용했습니다. 이 벤치마크들은 GSM8K, MATH, GSM-Hard, SVAMP, TabMWP, ASDiv, MAWPS를 포함하며, 각각 고유한 도전 과제와 맥락을 제공합니다.
평가 결과에서 볼 수 있듯이, DeepSeek-Coder 모델들은 모든 벤치마크에서 주목할 만한 성능을 보여주었습니다. 특히 330억 파라미터 모델은 GSM8K에서 60.7%, MATH에서 29.1%, GSM-Hard에서 54.1%의 정확도를 달성했습니다. 이러한 결과는 DeepSeek-Coder가 복잡한 수학적 계산과 문제 해결이 필요한 애플리케이션에서도 효과적으로 활용될 수 있음을 입증합니다.
DeepSeek-Coder-v1.5: 일반 언어 모델에서 코드 모델로의 진화
DeepSeek-Coder 모델의 자연어 이해와 수학적 추론 능력을 더욱 향상시키기 위해, 연구진은 DeepSeek-LLM-7B Base 모델을 기반으로 2조 개의 토큰을 사용하여 추가 사전 학습을 진행했습니다. 이를 통해 DeepSeek-Coder-v1.5 7B가 탄생했습니다.
사전 학습 데이터 구성
DeepSeek-Coder-v1.5의 사전 학습 데이터는 다음과 같이 구성되었습니다.
| 데이터 소스 | 비율 |
|---|---|
| 소스 코드 | 70% |
| 마크다운과 StackExchange | 10% |
| 코드 관련 자연어 | 7% |
| 수학 관련 자연어 | 7% |
| 중국어-영어 이중 언어 | 6% |
이전 버전과 달리 DeepSeek-Coder-v1.5는 사전 학습 단계에서 4K 컨텍스트 길이로 다음 토큰 예측 목표만을 사용했습니다. 이는 모델이 더 긴 시퀀스를 효과적으로 처리할 수 있도록 하면서도, 학습 과정을 단순화하고 최적화했습니다.
성능 평가 및 분석
연구진은 DeepSeek-Coder-v1.5 7B와 DeepSeek-Coder 6.7B의 공정한 비교를 위해 동일한 평가 파이프라인을 사용하여 다양한 벤치마크에서 성능을 평가했습니다. 평가는 다음 세 가지 주요 영역에서 이루어졌습니다.
-
프로그래밍: Chen과 연구진의 HumanEval 데이터셋을 사용한 다국어 평가와 Austin과 연구진의 MBPP 데이터셋을 활용한 파이썬 평가를 수행했습니다.
-
수학적 추론: Cobbe와 연구진의 GSM8K 벤치마크와 Hendrycks와 연구진의 MATH 벤치마크를 통해 수학 문제 해결 능력을 프로그램 생성 방식으로 평가했습니다.
-
자연어 처리: MMLU, BBH, HellaSwag, Winogrande, ARC-Challenge 등 다양한 자연어 이해 벤치마크를 통해 모델의 언어 이해 능력을 평가했습니다.
평가 결과, DeepSeek-Coder-Base-v1.5는 코딩 성능에서 약간의 감소를 보였지만, 대부분의 과제에서 이전 모델을 크게 앞서는 성능을 보여주었습니다. 특히 수학적 추론과 자연어 처리 분야에서 모든 벤치마크에서 현저한 성능 향상을 달성했습니다.
예를 들어, GSM8K에서는 43.2%에서 62.4%로, MATH에서는 19.2%에서 24.7%로 성능이 향상되었으며, MMLU에서는 36.6%에서 49.1%로, BBH에서는 44.3%에서 55.2%로 큰 폭의 개선을 보였습니다. 이는 추가 사전 학습을 통해 모델의 수학적 추론 능력과 자연어 처리 능력이 크게 향상되었음을 입증합니다.
DeepSeek-Coder: 코드 인텔리전스의 혁신과 미래 전망
본 연구에서는 코딩을 위한 특화된 대규모 언어 모델 시리즈인 DeepSeek-Coder를 소개했습니다. 1.3B, 6.7B, 33B 파라미터의 세 가지 규모로 개발된 이 모델들은 프로젝트 수준의 세심하게 선별된 코드 코퍼스를 기반으로 학습되었으며, “fill-in-the-blank” 사전 학습 목표를 활용하여 코드 채우기 능력을 향상시켰습니다.
DeepSeek-Coder의 주요 혁신 중 하나는 컨텍스트 윈도우를 16,384 토큰으로 확장한 것입니다. 이는 광범위한 코드 생성 작업에서 모델의 효과성을 크게 향상시켰습니다. 평가 결과에 따르면, DeepSeek-Coder-Base 33B는 다양한 표준 테스트에서 기존의 오픈소스 코드 모델들을 능가하는 성능을 보여주었습니다. 특히 주목할 만한 점은 DeepSeek-Coder-Base 6.7B 모델이 34B 파라미터의 CodeLlama와 대등한 성능을 달성했다는 것입니다. 이는 사전 학습 코퍼스의 높은 품질을 입증하는 결과입니다.
DeepSeek-Coder-Base 모델의 제로샷 지시어 수행 능력을 향상시키기 위해 고품질 지시어 데이터로 미세조정을 진행했습니다. 그 결과 DeepSeek-Coder-Instruct 33B 모델은 다양한 코딩 관련 작업에서 OpenAI의 GPT-3.5 Turbo를 능가하는 성능을 보여주었습니다.
자연어 이해 능력을 더욱 향상시키기 위해 DeepSeek-LLM 7B 체크포인트를 기반으로 추가 사전 학습을 진행했습니다. 이 과정에서 자연어, 코드, 수학 데이터를 포함하는 20억 토큰 규모의 다양한 데이터셋을 처리했으며, 그 결과로 DeepSeek-Coder-v1.5가 탄생했습니다. 이 새로운 모델은 이전 버전의 뛰어난 코딩 성능을 유지하면서도 자연어 이해 능력이 크게 향상되었습니다.
이러한 연구 결과는 효과적인 코드 중심 대규모 언어 모델이 강력한 일반 언어 모델을 기반으로 구축되어야 한다는 저자들의 견해를 뒷받침합니다. 그 이유는 코딩 작업을 효과적으로 해석하고 실행하기 위해서는 다양한 형태의 자연어로 표현되는 인간의 지시사항을 깊이 있게 이해해야 하기 때문입니다.
향후 연구진은 더 큰 규모의 일반 언어 모델을 기반으로 더욱 강력한 코드 중심 대규모 언어 모델을 개발하고 공개할 계획입니다. 이는 코드 인텔리전스 분야의 지속적인 발전을 위한 중요한 기여가 될 것으로 기대됩니다.
DeepSeek-Coder의 실제 활용 사례 분석
DeepSeek-Coder-Instruct 모델의 실제 활용 사례를 통해 모델의 실용적인 성능과 적용 가능성을 살펴보겠습니다. 두 가지 대표적인 사례를 통해 모델의 다양한 기능과 성능을 검증했습니다.
데이터베이스 구축 및 분석 사례

첫 번째 사례는 Python을 사용한 학생 데이터베이스 구축과 데이터 분석 과정을 보여줍니다. 이 사례에서는 SQLite 데이터베이스를 생성하고 학생 정보를 관리하는 전체 과정이 구현되었습니다. 특히 주목할 만한 점은 모델이 데이터베이스 생성, 데이터 삽입, 그리고 데이터 분석까지 이어지는 복잡한 작업을 버그 없이 수행했다는 것입니다.
모델은 다단계 대화를 통해 사용자의 요구사항을 정확히 이해하고, 각 단계에서 필요한 코드를 생성했습니다. 첫 단계에서는 데이터베이스 스키마 설계와 초기 데이터 삽입을, 두 번째 단계에서는 학생들의 연령 분포 분석을 수행했습니다. 각 단계에서 생성된 코드는 실행 가능한 형태로 제공되었으며, 상세한 설명이 함께 제시되었습니다.
알고리즘 문제 해결 사례

두 번째 사례는 모델의 알고리즘 문제 해결 능력을 보여줍니다. 특히 2023년 11월에 출제된 LeetCode 대회 문제를 활용했는데, 이는 모델의 학습 데이터에 포함되지 않은 시점의 문제입니다. 이를 통해 모델이 학습 데이터의 분포를 넘어서는 문제도 효과적으로 해결할 수 있음을 입증했습니다.
해당 문제는 토너먼트 형식의 대회에서 우승자를 결정하는 알고리즘을 구현하는 것이었습니다. 모델은 방향성 그래프를 활용한 위상 정렬 알고리즘을 제시했으며, 이는 최적화된 해결책으로 평가받았습니다. 특히 모델이 제시한 해결책은 코드의 정확성뿐만 아니라, 알고리즘의 효율성 측면에서도 우수한 성능을 보여주었습니다.
이러한 사례들은 DeepSeek-Coder-Instruct가 단순한 코드 생성을 넘어, 실제 개발 환경에서 마주하는 복잡한 문제들을 효과적으로 해결할 수 있음을 보여줍니다. 특히 데이터베이스 관리, 데이터 분석, 알고리즘 최적화와 같은 다양한 영역에서 실용적인 솔루션을 제공할 수 있다는 점이 주목할 만합니다.
DeepSeek-Coder의 학습 과정 벤치마크 분석
DeepSeek-Coder-Base 모델의 학습 과정에서 성능 변화를 추적하기 위해 연구진은 체계적인 검증 프레임워크를 구축했습니다. 이 프레임워크는 학습 코퍼스에서 신중하게 선별된 8,000개의 코드 파일로 구성된 검증 데이터셋을 활용합니다. 이 데이터셋은 모델의 성능을 정확하게 평가하기 위해 다양한 프로그래밍 언어와 코딩 패턴을 포함하도록 설계되었습니다.
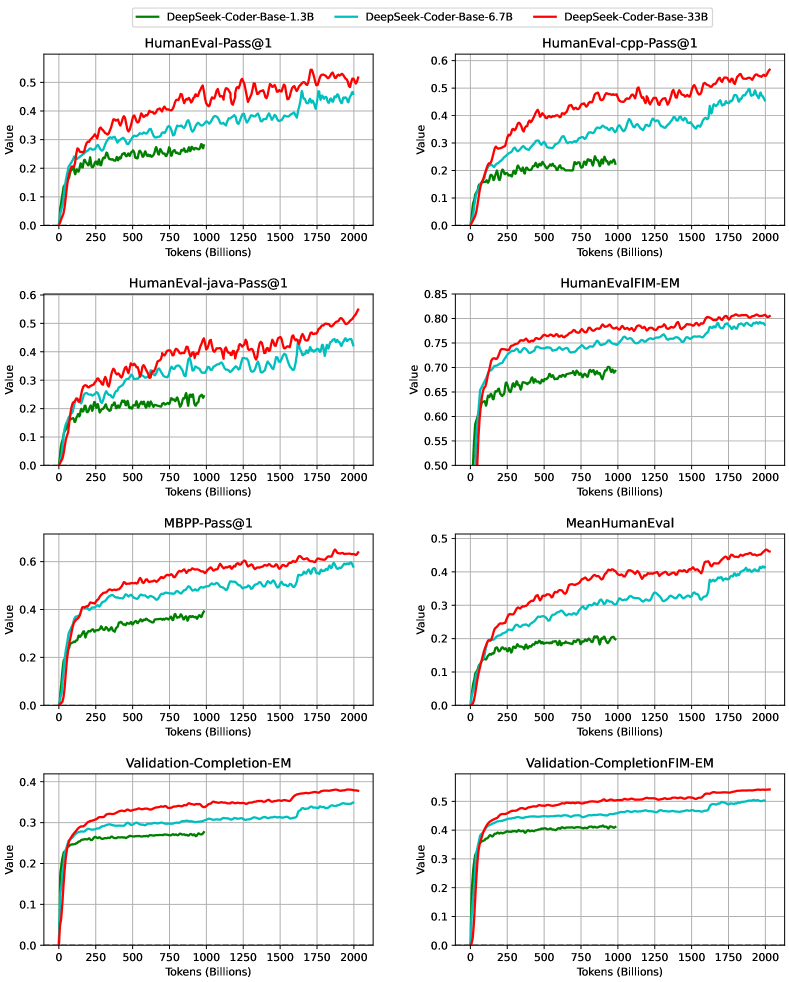
위 그래프는 DeepSeek-Coder-Base 모델의 학습 과정에서 다양한 평가 지표의 변화를 보여줍니다. 주요 평가 지표들은 다음과 같습니다.
- HumanEval 계열 지표:
- HumanEval-Pass@1: Python 코드 생성 능력
- HumanEval-cpp-Pass@1: C++ 코드 생성 능력
- HumanEval-java-Pass@1: Java 코드 생성 능력
- MeanHumanEval: 세 언어에 대한 평균 성능
- 코드 완성 지표:
- Validation-Completion-EM: 정확한 매칭 기반 코드 완성 성능
- Validation-Completion-FIM-EM: Fill-in-Middle 태스크에서의 코드 완성 성능
- MBPP-Pass@1: 다양한 Python 프로그래밍 문제 해결 능력
학습 곡선 분석 결과, 모델 크기가 증가할수록(1.3B에서 33B 파라미터로) 전반적인 성능이 향상되는 것을 확인할 수 있습니다. 특히 주목할 만한 점은 모델이 학습 초기에 빠른 성능 향상을 보이다가 점차 수렴하는 패턴을 보인다는 것입니다. 이는 Bavarian과 연구진이 제시한 Fill-in-Middle 학습 방식의 효과성을 입증하는 결과입니다.
벤치마크 결과는 DeepSeek-Coder 아키텍처의 확장성을 보여주며, 특히 대규모 모델(33B 파라미터)에서도 안정적인 학습이 가능하다는 것을 입증합니다. 이는 StarCoder와 연구진이 제시한 대규모 코드 모델의 확장성 연구 결과와도 일치합니다.
References
Subscribe via RSS