프롬프트에서 하네스까지 — AI 에이전틱 패턴 4년의 기록
Contents
엔지니어링의 엄밀함은 사라지지 않는다 — 이동할 뿐이다. AI 에이전틱 패턴 4년의 기록
"가장 핫한 새 프로그래밍 언어는 영어입니다." — Andrej Karpathy, 2023. 3년 뒤, 그 말은 절반만 맞았습니다.
TL;DR
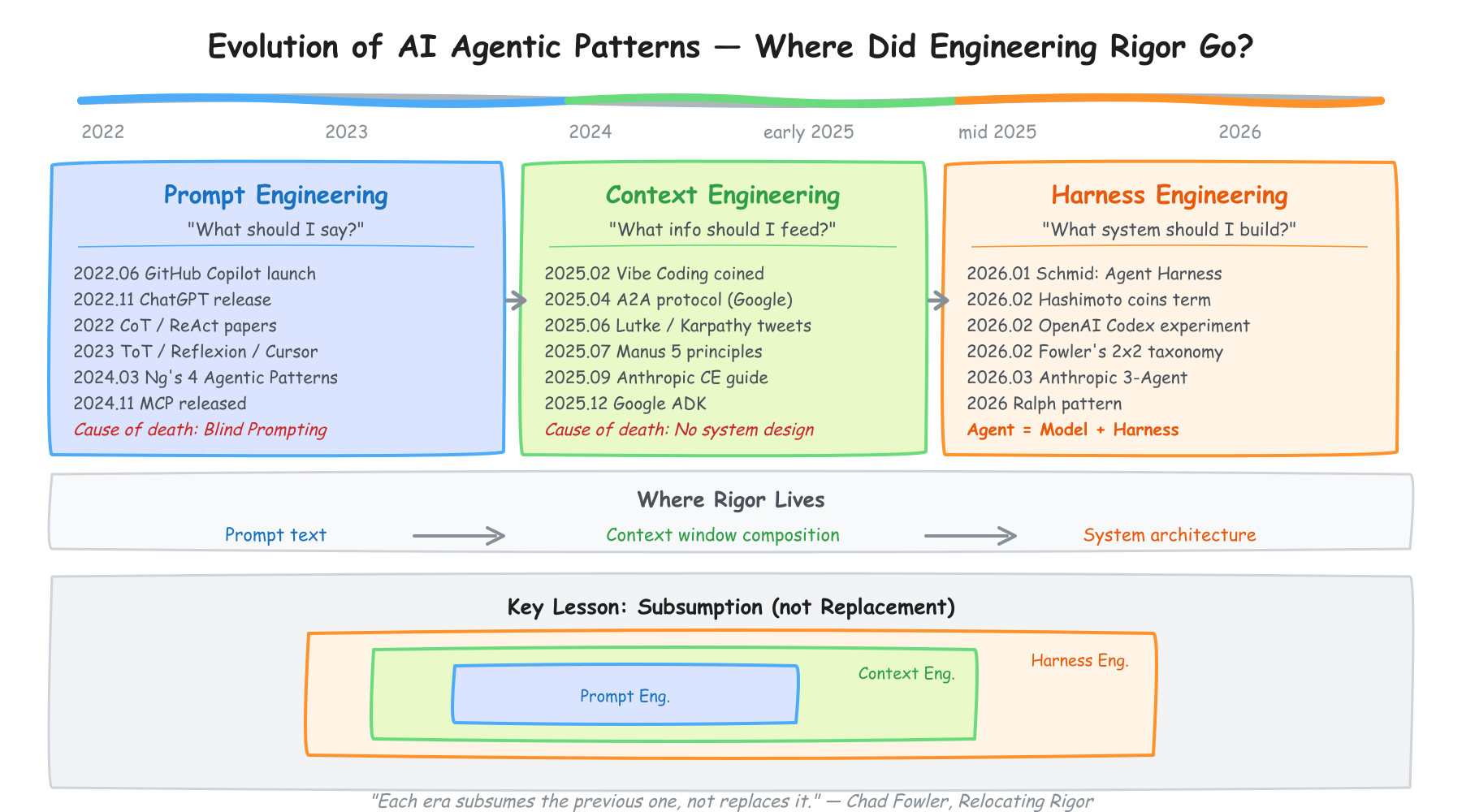
- 2022-2026, AI 개발 패러다임이 세 번 바뀌었습니다. Prompt Engineering → Context Engineering → Harness Engineering
- 각 전환의 진짜 동인은 "이전 패러다임이 약속한 것을 지키지 못했기 때문"입니다
- 엔지니어링의 엄밀함은 사라지지 않았습니다. 프롬프트에서 컨텍스트로, 컨텍스트에서 하네스로 이동했을 뿐입니다 (Chad Fowler의 "Relocating Rigor")
- 2026년의 핵심 메트릭은 프롬프트 품질이 아니라 KV-cache hit rate(모델이 이전 계산을 재활용하는 비율)와 하네스 복잡도입니다
- 이 글은 서베이가 아니라 부검 보고서에 가깝습니다 — 각 시대가 왜 실패했는지를 추적합니다
1. 왜 지금 이 연대기인가
2025년 6월 셋째 주, X(구 트위터)의 AI 타임라인이 갑자기 한 단어를 중심으로 회전하기 시작했습니다. "Context engineering." 6월 19일 Shopify CEO Tobi Lütke가 불을 붙였고, 일주일도 안 돼 Karpathy, Andrew Ng, 수백 명의 엔지니어가 합류했습니다. 며칠 사이에 "prompt engineering"이라는 단어가 타임라인에서 사라지기 시작했습니다. 마치 업계 전체가 어젯밤에 열린 파티에서 깨어나 "우리가 그동안 뭘 하고 있었던 거지?"라고 묻는 것 같았습니다.
이건 처음이 아니었습니다. 불과 4년 사이에 세 번째.
Epsilla의 메타포가 이 4년을 정확히 포착합니다. 2022년, 우리는 완벽한 이메일 작성법을 연구했습니다. 2025년, 받은편지함 관리를 배웠습니다. 2026년, 이메일 시스템 자체를 설계하고 있습니다.
- Prompt Engineering (2022-2024): "어떤 말을 해야 하나?" — 모델에게 보내는 지시문의 품질이 성패를 결정한다고 믿었습니다.
- Context Engineering (2025): "어떤 정보를 넣어야 하나?" — 프롬프트보다 컨텍스트 윈도우에 무엇을 채울지가 더 중요하다는 걸 깨달았습니다.
- Harness Engineering (2026): "어떤 시스템을 만들어야 하나?" — 컨텍스트를 소비하는 전체 시스템의 설계가 진짜 문제라는 걸 인정했습니다.
이 글의 논지는 하나입니다. 엔지니어링의 엄밀함은 사라지지 않았습니다. 이동했을 뿐입니다. Chad Fowler — Ruby 커뮤니티의 원로이자 Honeycomb CTO — 가 "Relocating Rigor"에서 짚었듯이, 소프트웨어 역사에서 이건 처음이 아닙니다. XP 운동이 "설계 문서 대신 테스트 코드"를 주장했을 때, 동적 언어가 "컴파일러의 타입 검사 없이" 배포하겠다고 했을 때, 기존 진영은 매번 같은 말을 했습니다 — "그건 엄밀함을 포기하는 것이다." 매번 틀렸습니다. 엄밀함은 포기된 게 아니라 더 높은 추상화 수준으로 이동한 것이었습니다. 설계 문서에서 자동화된 테스트로, 컴파일러 검사에서 런타임 테스트 스위트로. 이번에도 마찬가지입니다. "AI에게 코드를 맡기면 엔지니어링의 엄밀함이 사라진다"는 비판이 나오고 있지만, 엄밀함은 코드 작성에서 컨텍스트 설계로, 다시 시스템 아키텍처로 자리를 옮기고 있을 뿐입니다.
각 이동은 이전 시대의 실패가 촉발했습니다. 그 실패의 궤적을 추적해 보겠습니다.
2. 프롬프트 엔지니어링의 시대 (2022-2024)
2.1 서막: GitHub Copilot이 문을 열다
프롬프트 엔지니어링 시대의 서막을 올린 건 ChatGPT가 아닙니다. 그보다 5개월 먼저 등장한 도구가 있었습니다.
2022년 6월, GitHub Copilot이 정식으로 출시됩니다. 월 10달러. 역사상 최초의 상업용 AI 코딩 어시스턴트입니다. OpenAI Codex(GPT-3 기반)를 엔진으로, 에디터에서 코드를 작성하면 다음 줄을 제안하는 "고스트 텍스트(ghost text)" 자동완성이 핵심이었습니다.
처음에 반응은 엇갈렸습니다. "복붙 도우미", "스택오버플로우 자동화"라는 비아냥이 나왔습니다. 하지만 실제로 써 본 개발자들의 반응은 달랐습니다. GitHub 자체 조사에 따르면 개발자의 88%가 생산성 향상을 체감했고, 반복적인 코드 작성 시간이 절반으로 줄었습니다. 2024년 초 기준 2,000만 명 이상의 사용자, 470만 유료 구독자, Fortune 100 기업의 90%가 도입. 시장 점유율 약 42%.
흥미로운 건, 이후 3년간 Copilot이 거친 진화 과정이 이 글이 앞으로 다룰 세 시대를 축소판으로 보여준다는 점입니다.
| 시기 | Copilot 버전 | 핵심 변화 | 대응하는 시대 |
|---|---|---|---|
| 2022.06 | 초기 자동완성 | 현재 파일의 코드 기반으로 다음 줄 제안 | 프롬프트 시대. 코드 자체가 프롬프트 역할 |
| 2023.11 | Copilot Chat (GPT-4) | 대화형 코드 질의, 설명, 리팩토링 | 프롬프트에서 컨텍스트로 전환 시작 |
| 2025.02 | Agent Mode | 멀티파일 편집, 터미널 실행, 린트-수정 자동 루프 | 하네스 시대. 에이전트가 도구를 루프 안에서 사용 |
| 2025.05 | Coding Agent | Issue 할당 → 클라우드 환경 → 코드 → 테스트 → PR 생성 | 하네스 시대 심화. 완전 자율 워크플로우 |
2022년의 초기 Copilot은 순수한 프롬프트 엔지니어링 산물이었습니다. 모델에게 "현재 파일의 코드"라는 암묵적 프롬프트를 건네고, 다음 토큰을 예측하게 하는 것. 컨텍스트는 현재 파일 하나. 하네스는 존재하지 않았습니다. 그것만으로도 충분히 유용했습니다 — 2022년에는요.
2.2 ChatGPT와 "영어가 곧 프로그래밍 언어다"
5개월 뒤인 2022년 11월 30일, ChatGPT가 공개됩니다. 5일 만에 100만 사용자. 두 달 만에 1억. 그 주에 무슨 일이 벌어졌는지 기억하십니까? 개발자들의 X 타임라인이 하룻밤 사이에 바뀌었습니다. "이걸로 뭘 만들 수 있지?"가 아니라 "이것에게 어떻게 말해야 하지?"가 질문이었습니다. 모든 것이 말하기의 문제로 보였습니다.
Andrej Karpathy — 전 Tesla AI 디렉터, OpenAI 창립 멤버 — 는 이 순간을 "Software 3.0"이라 명명했습니다. Software 1.0이 사람이 작성한 코드, 2.0이 신경망의 가중치라면, 3.0은 자연어 지시문 자체가 프로그램이라는 패러다임입니다. 프로그래밍을 배우는 데 10년이 걸리던 일을, 영어 한 문장으로 해결할 수 있다니. 매혹적인 약속이었습니다. Copilot이 "코드 작성을 도와주는 도구"였다면, ChatGPT는 "코드를 이해하고 대화할 수 있는 존재"였습니다. 이 둘이 합쳐지면서 프롬프트 엔지니어링이라는 분야가 폭발합니다.
2.3 학문적 토대: 추론을 프롬프트로 유도하다
Copilot과 ChatGPT가 실전에서 가능성을 증명하는 한편, 학계에서는 같은 시기에 다른 질문에 매달리고 있었습니다 — 어떻게 말해야 모델이 더 잘 추론하는가? 그리고 놀라운 답들이 쏟아졌습니다.
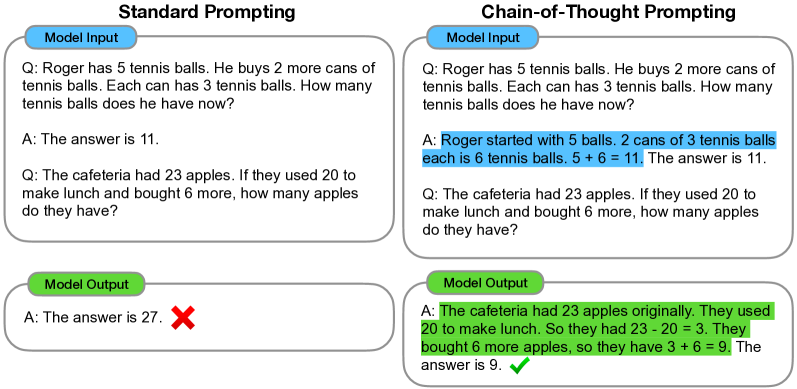
Chain-of-Thought (CoT) 프롬프팅 — Wei et al., 2022. 2022년 1월, Google Brain 팀이 발표한 이 논문이 프롬프트 엔지니어링의 첫 번째 혁명입니다. 아이디어는 놀라울 만큼 단순합니다. 모델에게 바로 답을 내라고 하지 말고, "단계별로 생각하라(Let's think step by step)"고 시키는 것. 수학 문제를 예로 들면:
- 일반 프롬프트: "카페에 손님 23명이 있습니다. 점심에 6명이 더 왔고, 오후에 5명이 갔습니다. 손님은 몇 명입니까?" → 모델: "25" (오답)
- CoT 프롬프트: 같은 문제 + "단계별로 생각해 봅시다" → 모델: "처음 23명. 6명이 옴 → 23 + 6 = 29명. 5명이 감 → 29 - 5 = 24명" (정답)
GSM8K(초등학교 수학) 벤치마크에서 PaLM 540B의 정확도가 17.9%에서 58.1%로 뛰었습니다. 중간 추론 과정을 "보여달라"고 요구했을 뿐인데, 산술·상식·상징적 추론 성능이 비약적으로 향상된 겁니다. 프롬프트 한 줄의 위력이 증명된 순간이었습니다.
ReAct: 추론과 행동의 결합 — Yao et al., 2022. 같은 해 10월, 프린스턴-Google 팀이 한 단계 더 나아갔습니다. CoT가 "생각만 하는" 패턴이었다면, ReAct는 생각(Thought)과 행동(Action)을 번갈아 수행하게 합니다. 모델이 스스로 위키피디아를 검색하고, 결과를 관찰(Observation)하고, 다시 추론하는 루프입니다.
Thought: 이 질문에 답하려면 X에 대해 알아야 합니다.
Action: Search[X]
Observation: X는 ...입니다.
Thought: 이제 Y와 비교하면...
Action: Search[Y]
...
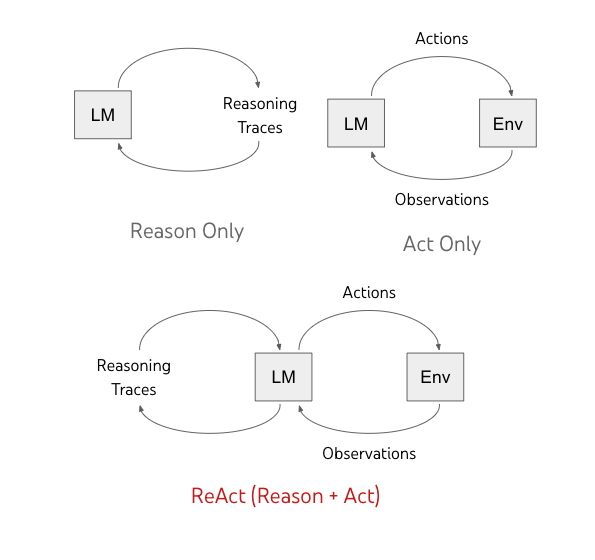
핵심 성과는 두 가지입니다. 첫째, 외부 도구를 사용하므로 환각이 줄어듭니다 — 모델이 "모르는 것"을 검색으로 해결할 수 있습니다. 둘째, 추론 과정이 투명합니다 — 왜 그런 답을 냈는지 추적할 수 있습니다. ALFWorld 벤치마크에서 34% 절대 향상, WebShop에서 10% 향상. 에이전트의 원형이 여기서 태어났습니다. 오늘날의 모든 AI 에이전트 — Claude Code, Cursor Agent, GitHub Copilot Coding Agent — 가 이 Thought-Action-Observation 루프의 변형입니다.
여기까지는 순조로웠습니다. 문제는 이 아이디어들을 더 밀어붙이면서 시작됩니다.
Tree-of-Thought — Yao et al., 2023. 2023년에는 추론의 "깊이"가 아닌 "너비"를 확장하려는 시도가 나왔습니다.

CoT가 일직선으로 추론한다면, Tree-of-Thought는 여러 가지 추론 경로를 동시에 탐색하고, 막다른 길에 도달하면 백트래킹(되돌아가기)합니다. 체스에서 "이 수를 두면… 상대가 이렇게 나오면… 그럼 내가 이렇게…" 하고 여러 수를 미리 읽는 것과 같은 원리입니다. 매혹적이었지만, 비용이 폭발했습니다. 하나의 문제에 대해 수십 번의 API 호출이 필요합니다. 논문의 "Future Work" 섹션에서는 비용을 한 줄짜리 caveat으로 언급하지만, 프로덕션 엔지니어의 AWS 청구서에서는 그게 첫 줄짜리 위기입니다.
Self-Refine과 Reflexion — Madaan et al., 2023, Shinn et al., 2023. 사람이 글을 쓰고 고치듯, 모델에게도 자기 출력을 비판하고 개선하게 하면 어떨까? Self-Refine은 생성→피드백→수정 루프를, Reflexion은 언어적 강화학습(verbal reinforcement learning — 실패 경험을 자연어로 기록하여 다음 시도에 활용하는 것)을 제안했습니다. 흥미로운 접근이었지만, 근본적인 한계가 있었습니다 — 피드백의 품질이 모델 자신의 능력에 종속된다는 것. 실력 없는 학생이 자기 답을 채점하는 것과 같은 문제입니다. (이 문제가 2026년 Anthropic의 3-에이전트 아키텍처에서 다시 등장합니다. 결국 "채점은 다른 사람이 해야 한다"는 결론에 도달하는 데 3년이 걸렸습니다.)
2.4 Andrew Ng의 4대 에이전틱 디자인 패턴
2024년 3월, Andrew Ng — Stanford 교수, Coursera 공동 설립자, 전 Google Brain/Baidu AI 수장 — 가 Sequoia AI Ascent 무대에 올랐습니다. 그가 발표한 4가지 에이전틱 디자인 패턴은 그간의 연구를 실무 프레임워크로 종합한 것이었습니다.
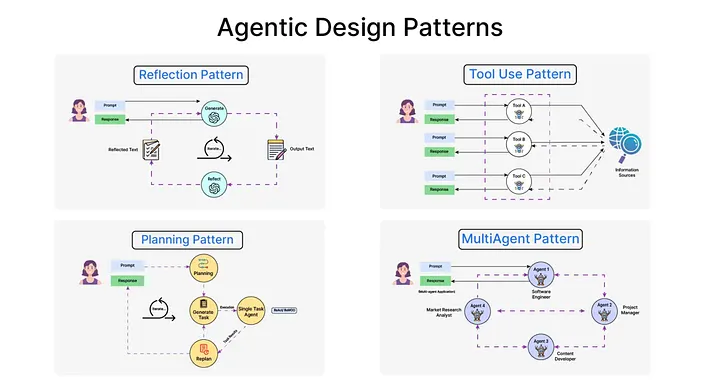
Reflection (반성). 모델이 자기 출력을 비판하고 수정합니다. Self-Refine과 같은 원리이지만, Ng는 이것을 가장 안정적이고 예측 가능한 패턴으로 위치시켰습니다. 코드를 생성한 뒤 "이 코드에 버그가 있는지 검토하라"고 재요청하는 것. 간단하지만 놀라울 만큼 효과적입니다. 핵심은 같은 모델이 다른 페르소나로 검토한다는 것 — "시니어 코드 리뷰어의 관점에서 검토하라"는 역할 부여가 품질을 높입니다.
Tool Use (도구 사용). ReAct의 실전 버전입니다. 모델이 웹 검색, 코드 실행, 데이터베이스 쿼리, 계산기 등 외부 도구를 호출합니다. 중요한 건, 도구를 언제 사용할지를 모델이 스스로 결정한다는 것입니다. "현재 환율이 필요하다 → 환율 API 호출 → 결과를 계산에 사용"의 판단을 모델이 합니다. 이것이 챗봇과 에이전트를 구분하는 결정적 차이입니다.
Planning (계획). 복잡한 과제를 하위 단계로 분해합니다. "웹사이트를 만들어라"라는 요청을 "1) 요구사항 분석 2) 디자인 3) 프론트엔드 구현 4) 백엔드 구현 5) 테스트 6) 배포"로 나누는 것. 강력하지만 가장 불안정한 패턴이기도 합니다. Ng의 표현을 빌리면 "디테일에 악마가 있다(the devil is in the details)" — 계획은 멋지게 세우지만, 실행에서 무너지는 경우가 많았습니다.
Multi-Agent Collaboration (다중 에이전트 협업). 전문화된 에이전트들이 서로 다른 역할을 맡아 협업합니다. 코더 에이전트 + 리뷰어 에이전트 + 테스터 에이전트가 각자의 전문 영역에서 작업하고, 결과를 교환합니다. 2024년 시점에서 가장 초기 단계의 패턴이었고, 가장 많은 가능성을 품고 있었습니다.
Ng의 핵심 발견: "GPT-3.5에 에이전틱 워크플로우를 씌우면 특정 벤치마크에서 GPT-4 제로샷보다 낫다." 모델을 업그레이드하지 않아도, 모델을 감싸는 패턴을 바꾸면 성능이 도약한다? 이건 프롬프트 엔지니어링의 정점이었습니다. 동시에, "모델 바깥의 시스템이 중요하다"는 힌트이기도 했습니다. 하지만 2024년 초에는 아직 아무도 그 함의를 끝까지 밀어붙이지 않았습니다.
이 패턴들은 같은 해 12월, Anthropic의 "Building Effective Agents"에서 더 체계적으로 정리됩니다. Anthropic은 두 가지를 구분했습니다. 워크플로우는 흐름이 미리 정해진 파이프라인이고(예: "코드 생성 → 리뷰 → 테스트"를 순서대로), 에이전트는 LLM이 다음 행동을 스스로 결정하는 자율적 프로세스입니다. 둘 중 하나가 우월한 게 아닙니다. Anthropic의 핵심 메시지는 "가능한 한 단순하게 시작하라"입니다. 워크플로우로 충분하면 에이전트를 쓸 필요 없고, 에이전트가 필요해도 복잡한 프레임워크 대신 기본 패턴의 조합으로 충분하다는 것이었습니다.
2.5 한계: 프롬프트의 벽에 부딪히다
그런데 이 패턴들을 프로덕션에 넣으면 어떻게 될까요?
이런 상황을 상상해 보십시오. 어느 팀이 코딩 에이전트의 프롬프트를 3주에 걸쳐 다듬었습니다. "기존 코딩 컨벤션을 따라라", "테스트를 작성하라", "사용하지 않는 import를 남기지 마라" — 지시문은 점점 길어졌고, 간단한 과제에서는 잘 작동했습니다. 그런데 프로젝트가 커지면서 문제가 터졌습니다. 에이전트가 이미 존재하는 유틸리티 함수를 무시하고 새로 만들기 시작한 겁니다. 프롬프트에 "기존 코드를 재사용하라"고 아무리 써놓아도, 컨텍스트 윈도우에 해당 유틸리티 파일이 포함되지 않으면 에이전트는 그 존재 자체를 모릅니다. 프롬프트는 완벽했지만, 에이전트가 볼 수 있는 정보가 불완전했던 겁니다. 이건 프롬프트의 문제가 아닙니다. 프롬프트가 소비하는 컨텍스트의 문제입니다.
Mitchell Hashimoto — Vagrant와 Terraform의 창시자, HashiCorp 공동 설립자 — 는 이런 상황을 "Blind Prompting"이라 불렀습니다. 엄격한 측정이나 테스트 없이, 시행착오에만 의존하는 프롬프트 작성. 솔직히 말하면, 대부분의 팀이 하고 있던 것이 바로 이것이었습니다. 프롬프트를 수정하고, 출력을 눈으로 확인하고, "이번엔 괜찮은 것 같다"고 결론 내리는 것. 소프트웨어 엔지니어링이라기보다는 연금술에 가까웠습니다.
문제는 구조적이었습니다. 모델은 비결정론적(non-deterministic)입니다 — 같은 입력에 매번 다른 출력이 나올 수 있다는 뜻입니다. "Please"를 추가했더니 성능이 올라갔다는 보고가 있는가 하면, 줄바꿈 하나에 출력이 완전히 달라지기도 합니다. CodeRabbit의 2025년 분석은 이 격차를 수치로 보여줬습니다 — AI가 공동 작성한 코드에서 주요 이슈가 1.7배, 성능 비효율은 8배 더 많이 발생했습니다.
프롬프트 시대의 사인(死因)은 명확합니다. 엄밀함이 있어야 할 곳은 프롬프트 텍스트가 아니라, 프롬프트가 소비하는 컨텍스트 전체였습니다. 하지만 그 깨달음이 오기 전에, 업계는 한 번 더 막다른 골목을 향해 질주합니다.
3. AI 코딩 도구의 폭발과 바이브 코딩의 숙취 (2024-2025 초)
3.1 Cursor: "컨텍스트를 이해하는" 에디터의 등장
Copilot이 "현재 파일"만 보는 자동완성이었다면, 2023년 3월에 등장한 Cursor는 질문 자체를 바꿨습니다. MIT 출신 네 명의 학생 — Michael Truell, Sualeh Asif, Arvid Lunnemark, Aman Sanger — 이 만든 이 VS Code 포크(fork — 기존 프로젝트의 코드를 복사하여 독립적으로 발전시킨 것)는, AI가 코드를 이해하는 방식을 근본적으로 바꿨습니다.
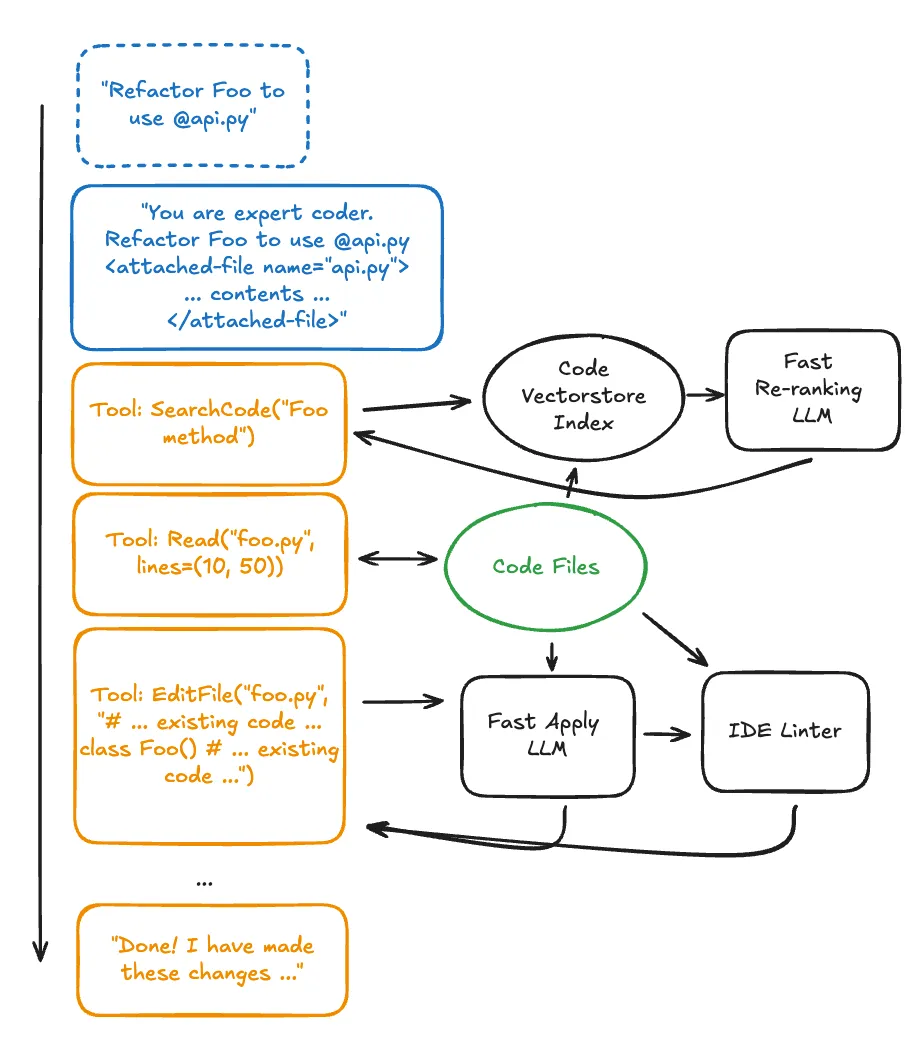
핵심 차이는 컨텍스트 범위입니다.
| 차원 | GitHub Copilot (초기) | Cursor |
|---|---|---|
| 컨텍스트 범위 | 현재 파일 | 전체 코드베이스 |
| 인덱싱 | 없음 | RAG + AST 기반 시맨틱 검색 |
| 참조 시스템 | 없음 | @file, @codebase, @Docs, @PR, @commit |
| 편집 단위 | 단일 줄/블록 | 멀티파일 동시 편집 (Composer) |
| 에이전트 모드 | 없음 (2025년 추가) | Agent Mode (터미널, 파일 시스템 접근) |
| 모델 선택 | GPT 계열 | GPT-4o, Claude 3.5 Sonnet, Gemini 등 선택 가능 |
Cursor가 코드베이스를 이해하는 방식은 기술적으로 흥미롭습니다. 프로젝트의 모든 파일을 재귀적으로 스캔하고, AST(Abstract Syntax Tree — 코드의 구조를 트리 형태로 표현한 것)를 파싱하여 함수, 클래스, 변수 등 핵심 심볼을 식별합니다. 이 심볼들을 벡터 임베딩(고차원 수학적 표현)으로 변환하여 시맨틱 검색(의미 기반 검색)이 가능하게 합니다. 파일 이름은 난독화하고 코드 청크는 암호화하여 보안도 유지합니다.
초기 Cursor는 채팅 기반 코드 편집이 중심이었지만, 2024년 하반기에 Composer 모드가 추가되면서 게임이 바뀌었습니다. CMD+SHIFT+I로 열리는 세 패널(진행 상황/파일/채팅) 레이아웃에서, 자연어로 "사용자 인증 시스템을 추가해줘"라고 하면 여러 파일을 동시에 생성하고 수정합니다. 단일 파일 편집을 넘어 프로젝트 단위의 변경이 가능해진 것입니다. 2025년에 출시된 Cursor 2.0에서는 여기에 혼합 전문가 모델(mixture-of-experts — 하나의 모델 안에 전문화된 하위 네트워크(expert)가 여러 개 있고, 입력에 따라 관련된 것만 선택적으로 활성화하는 구조)과 강화학습이 더해졌고, 최대 8개의 에이전트를 Git worktree 격리 환경에서 동시에 실행할 수 있게 됩니다. 대부분의 작업이 초당 ~250 토큰, 30초 이내에 완료됩니다.
성장 속도는 역사상 SaaS 기업 중 최고였습니다. 2025년 기준 12억 달러 ARR, 293억 달러 기업가치. Shopify, Vercel, Linear 등 주요 기술 기업이 도입했습니다.
3.2 AI 코딩 도구의 캄브리아 대폭발
Cursor의 성공은 AI 코딩 도구의 캄브리아 대폭발(생물학에서 짧은 기간에 다양한 종이 폭발적으로 출현한 사건)을 촉발했습니다.
Devin (Cognition Labs, 2024.03). "최초의 AI 소프트웨어 엔지니어"라는 타이틀로 등장했습니다. 앱을 처음부터 끝까지 만들고 배포까지 한다는 주장이었습니다. 홍보 영상에서 Upwork 프리랜서 작업을 수행하는 모습을 보여줬는데, YouTuber Carl Brown이 이를 분석하여 주요 부분이 과장되었음을 밝혔습니다. Answer.AI 연구진의 독립 테스트에서는 20개 과제 중 3개만 성공했습니다. 그럼에도 Cognition은 2025년 7월 Windsurf를 2.5억 달러에 인수하고, 9월에는 102억 달러 기업가치를 달성했습니다. 과대광고와 실질 가치 사이의 괴리가 이 시대의 특징입니다.
Windsurf (구 Codeium). AI 자동완성 확장 프로그램으로 시작, 2024년 말 풀 AI IDE로 리브랜딩했습니다. "Cascade"라는 에이전틱 어시스턴트가 특징. 8,200만 달러 ARR을 달성했지만, CEO가 Google에 24억 달러 라이선싱 딜로 스카우트된 후 Cognition에 인수됩니다.
그 외: Void Editor(오픈소스 Cursor 대안, 프라이버시 중심), Augment Code(2.5억 달러 펀딩, 엔터프라이즈 특화), Sourcegraph Cody(코드 검색 기반), Aider(터미널 기반 오픈소스 페어 프로그래머), Cline(VS Code 확장, 자율 코딩).
2024년에서 2025년 사이, AI 에이전트 프레임워크 GitHub 저장소(1,000+ 스타)가 14개에서 89개로 — 535% 증가했습니다. GitHub의 2024 설문에 따르면 개발자의 92%가 AI 코딩 도구를 사용하고 있었습니다.
3.3 바이브 코딩: 프롬프트 엔지니어링의 논리적 극한
이 도구들의 폭발적 성장 속에서, 2025년 2월 Karpathy가 X에 글을 올렸습니다.
"Cursor가 제안한 모든 변경사항을 그냥 전부 수락했습니다… diff도 거의 안 봅니다. 코드가 제가 완전히 읽을 수 있는 수준을 넘어서 자라났습니다."
"Vibe coding"이라는 이름이 붙었습니다. 코드를 읽지 않고, 에러 메시지를 복붙하고, 되면 되는 거고. 프롬프트 엔지니어링의 궁극적 형태, 혹은 논리적 귀결이라고 해야 할까요. 영어로 말하면 코드가 나오니까, 코드를 이해할 필요가 뭐 있겠습니까?
Karpathy 자신은 이걸 "주말 프로젝트에서나" 할 만한 것으로 제시했습니다. 하지만 업계의 반응은 그 뉘앙스를 무시했습니다. Y Combinator Winter 2025 배치의 25%가 코드베이스의 95%를 AI로 생성했다고 보고했습니다. Collins 사전이 2025 올해의 단어로 선정할 만큼 현상은 거대했습니다.
그리고 숙취가 왔습니다. 예상보다 빨리.
2025년 9월, Fast Company가 "The Vibe Coding Hangover"를 보도했습니다. 상황은 이랬습니다. 3개월 전에 AI로 빠르게 만든 MVP가 투자를 받았습니다. 이제 고객이 들어오기 시작합니다. 버그 리포트가 쌓입니다. 수정하려고 코드를 열어보는데 — 아무도 이 코드를 이해하지 못합니다. 작성한 사람도 읽지 않았으니까요. CodeRabbit 데이터가 규모를 보여줬습니다 — AI 생성 코드의 주요 이슈 1.7배, 보안 취약점 비율 45%(Veracode, 2025). 데모에서 빛나던 것들이 프로덕션에서 무너지기 시작한 겁니다.
Simon Willison — Django 웹 프레임워크 공동 창시자이자 AI 도구 전문 블로거 — 이 정곡을 찔렀습니다.
"LLM이 모든 코드를 작성했더라도, 당신이 리뷰하고 테스트했다면 그건 vibe coding이 아닙니다."
핵심은 코드를 누가 썼는가가 아니라, 엄밀함이 어디에 있는가였습니다.
섹션 1에서 소개한 Chad Fowler의 "Relocating Rigor"가 정확히 이 상황을 설명합니다. 엄밀함은 사라지지 않고 이동한다. Fowler는 이 패턴에서 세 가지 원칙을 뽑아냅니다.
- "반드시 지켜져야 하는 규칙"은 코드로 강제하라. "이 함수는 양수만 받는다"를 주석으로 적어놓는 건 엄밀함이 아니다. 타입 시스템이나 assertion으로 기계가 검증하게 만들어야 한다.
- 실패는 즉각적이고 시끄러워야 한다. 조용히 넘어가는 에러는 나중에 더 큰 문제로 돌아온다. 잘못되면 바로, 크게 터뜨려라.
- 엔지니어의 역할이 바뀐다. 코드를 타이핑하는 것에서, 의도를 명세하고 결과를 검증하는 것으로.
Vibe coding은 이 세 가지를 모두 무시한 결과였습니다. 규칙은 코드가 아니라 머릿속에만 있었고, 실패는 조용히 넘어갔고, 엔지니어는 검증을 포기했습니다. 프롬프트 엔지니어링의 논리적 극한이자, 엄밀함의 위치를 완전히 잃어버린 상태. 그렇다면 엄밀함은 어디로 이동해야 했을까요?
4. 컨텍스트 엔지니어링의 시대 (2025 중반~)
4.1 기원: 2025년 6월의 일주일
다시 2025년 6월로 돌아갑시다. 6월 19일, Shopify CEO Tobi Lütke가 X에 씁니다.
"'프롬프트 엔지니어링'보다 '컨텍스트 엔지니어링'이라는 용어가 훨씬 마음에 듭니다. 핵심 역량을 더 잘 설명하거든요. LLM이 과제를 그럴듯하게 풀 수 있도록 모든 컨텍스트를 제공하는 기술."
트윗 하나가 업계의 어휘를 바꿨습니다.
일주일 뒤, Karpathy가 화답합니다.
"컨텍스트 엔지니어링은 다음 단계에 딱 필요한 정보로 컨텍스트 윈도우를 채우는 섬세한 기술이자 과학입니다."
그리고 한마디를 덧붙입니다 — 이건 새로운 소프트웨어의 "두꺼운 레이어(thick layer)" 중 작은 한 조각일 뿐이라고. "두꺼운 레이어." 이 표현을 기억해 두십시오. 8개월 뒤 하네스 엔지니어링이라는 이름으로 돌아옵니다.
단순한 용어 교체가 아니었습니다. 핵심 질문 자체가 바뀐 겁니다. "어떤 말을 해야 하나"에서 "어떤 정보를 넣어야 하나"로.
4.2 LLM-as-OS: Karpathy의 운영체제 비유
이 전환을 가장 선명하게 이해하게 해주는 프레임워크가 Karpathy의 LLM-as-OS 비유입니다. LLM을 현대 컴퓨팅의 커널로 보는 것입니다.
| 기존 OS 구성요소 | 역할 | LLM OS 대응 | 비고 |
|---|---|---|---|
| 커널 | 시스템 리소스 관리 | LLM 추론 엔진 | 문제 해결의 중추 |
| RAM | 작업 기억 장치 | 컨텍스트 윈도우 | 토큰 단위로 관리 |
| 파일 시스템 | 영구 저장소 | RAG / 벡터 DB | 필요한 정보만 검색·주입 |
| 시스템 호출 | 하드웨어 제어 | Tool Call / API | 외부 세계와의 상호작용 |
| 프로세스 관리 | 멀티태스킹 | 멀티 에이전트 오케스트레이션 | 에이전트 간 협업·격리 |
이 비유가 중요한 이유는, 프롬프트의 위치를 명확히 해주기 때문입니다. 프롬프트는 OS에 입력하는 명령어 한 줄일 뿐입니다. 진짜 성능을 결정하는 건 RAM(컨텍스트 윈도우)에 무엇을 올려놓는가입니다. ls 명령어를 아무리 정교하게 작성해도, 필요한 파일이 마운트되지 않은 디스크에 있으면 소용없죠.
Anthropic은 2025년 9월, "Effective Context Engineering for AI Agents"에서 이것을 "프롬프트 엔지니어링의 자연스러운 진화"로 공식화했습니다. 컨텍스트 윈도우에 들어가는 다섯 가지 요소 — 시스템 프롬프트, 사용자 입력, 대화 히스토리, 도구 결과, 검색된 지식 — 의 배합을 최적화하는 기술이라는 것입니다. 엄밀함이 프롬프트에서 컨텍스트로 이동한 순간이었습니다.
4.3 핵심 원칙: 엄밀함이 도착한 곳
컨텍스트 엔지니어링은 "정보를 많이 넣어라"가 아닙니다. 그랬으면 "context stuffing"이라 불렸을 겁니다. 초기에 많은 팀이 정확히 이 실수를 했습니다. RAG 파이프라인에서 검색된 문서 10개를 통째로 컨텍스트에 밀어넣습니다. 토큰이 부족해지면 윈도우 크기를 늘립니다. 그래도 안 되면 모델을 탓합니다.
Google ADK의 설계 철학이 이 접근의 문제를 명확히 합니다 — 컨텍스트는 "풍부한 상태 시스템 위의 컴파일된 뷰(compiled view over a richer stateful system)"이지, 원시 데이터 덤프가 아닙니다. 데이터베이스를 통째로 RAM에 올리면 OS가 느려지는 것과 같은 이치입니다.
Anthropic의 4대 전략: Write / Select / Compress / Isolate
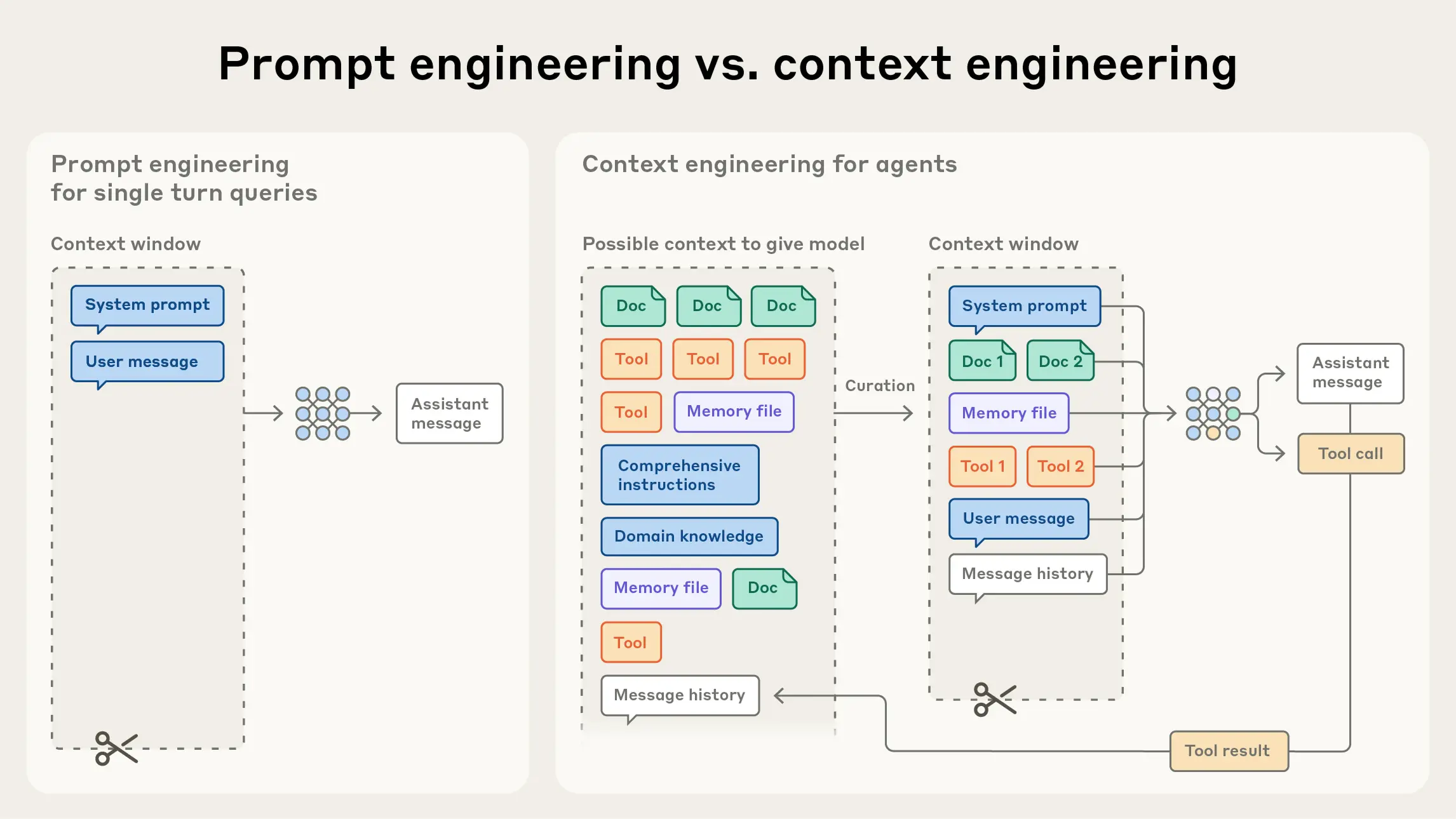
Anthropic의 가이드는 컨텍스트 큐레이션을 네 가지 전략으로 분류했습니다. 고객 지원 에이전트를 만든다고 해봅시다. 이 네 전략이 어떻게 작동하는지 따라가 봅시다.
- Write (작성): 시스템 프롬프트를 "고객 지원 에이전트입니다. 환불 정책은 30일입니다. 기술 문제는 티켓을 생성하세요"처럼 명확하고 구조화된 형태로 작성합니다. "무엇을 말할 것인가"가 아니라 "어떻게 구조화할 것인가"가 핵심입니다.
- Select (선택): 고객이 "주문 취소"라고 하면, 전체 FAQ가 아니라 취소/환불 관련 문서만 골라 컨텍스트에 넣습니다. "Lost-in-the-Middle" 현상 — 긴 책의 중간 부분을 기억 못 하는 것처럼, 컨텍스트가 길어지면 중간에 있는 정보의 정확도가 급격히 떨어지는 문제 — 을 방지하기 위해, 양보다 신호 대 잡음비(Signal-to-Noise Ratio)를 최적화해야 합니다.
- Compress (압축): 고객과 20턴 대화를 나눴다면, 초반 15턴을 "고객이 제품 X의 환불을 요청, 영수증 확인 완료, 배송비 문의 중"으로 요약합니다. Anthropic에 따르면 잘 설계된 압축은 정보 보존율 80% 이상을 유지하면서 토큰 사용량을 크게 줄일 수 있습니다.
- Isolate (격리): 고객이 기술 문제를 보고하면, 진단 서브에이전트에게 별도로 위임합니다. 메인 대화 컨텍스트에 로그 분석 데이터가 넘치지 않도록 격리하는 겁니다.
Google ADK의 컨텍스트 스택 아키텍처
Google ADK는 이 원칙을 구체적인 아키텍처로 구현했습니다. 세 가지 핵심 설계 원칙:
- 저장과 표현의 분리. 데이터베이스에 비유하면, 원본 데이터(테이블)와 화면에 보여주는 뷰(view)를 구분하는 것입니다. 에이전트의 전체 대화 히스토리, 사용자 정보, 과거 도구 결과 등은 세션(Session)에 원본 그대로 보관합니다. 하지만 매 턴마다 모델 API에 실제로 보내는 토큰은 이 원본에서 필요한 부분만 골라 조립한 "작업 컨텍스트(Working Context)"입니다. 원본은 건드리지 않고, 읽을 때마다 그 시점에 최적화된 뷰를 새로 만드는 것이죠.
- 명시적 변환 파이프라인. 이 "뷰 만들기"가 즉흥적이면 안 됩니다. "시스템 프롬프트 삽입 → 관련 히스토리 선별 → 도구 결과 요약 → 토큰 예산 확인"처럼 이름이 붙은 단계들이 정해진 순서로 실행됩니다. 문자열을 임의로 이어붙이는 게 아니라, 재현 가능한 파이프라인으로 컨텍스트를 조립하는 것입니다.
- 기본 스코핑. 에이전트가 서브에이전트에게 작업을 위임할 때, 전체 대화를 통째로 넘기지 않습니다. "이 파일을 수정해줘"라는 서브에이전트에게는 해당 파일과 관련 컨텍스트만 전달합니다. 최소 권한 원칙(least privilege)의 컨텍스트 버전입니다.
이 원칙들을 바탕으로, Google ADK는 컨텍스트 윈도우를 구체적으로 두 영역으로 나눕니다.
- 안정 접두어 (Stable Prefix): 시스템 프롬프트, 에이전트 정체성, 도구 정의, 장기 요약 — 자주 변하지 않는 것을 앞쪽에 배치
- 동적 접미어 (Variable Suffix): 최신 사용자 입력, 새로운 도구 출력 — 자주 변하는 것을 뒤쪽에 배치
왜 이 순서가 중요한가? KV-cache 때문입니다.
KV-cache: 프로덕션의 핵심 메트릭
Manus 팀의 이야기를 들어보십시오. 이 팀은 에이전트 프레임워크를 네 번 갈아엎었습니다. 네 번. 첫 번째 버전은 프롬프트 최적화에 집중했고, 두 번째는 에이전트 아키텍처를 바꿨고, 세 번째는 도구 체계를 재설계했습니다. 네 번째에서야 깨달았습니다 — 진짜 병목은 프롬프트도, 아키텍처도, 도구도 아니라 컨텍스트 관리였다는 것을.
이 팀이 프로덕션 에이전트의 "가장 중요한 단일 메트릭"이라고 부른 건 KV-cache hit rate였습니다.
KV-cache(Key-Value Cache)의 작동 원리를 설명하겠습니다. LLM API에 프롬프트를 보내면, 모델은 각 토큰의 어텐션 키(Key)와 값(Value)을 계산합니다. 이 계산은 비용이 큽니다. 그런데 이전 요청의 프롬프트 접두어가 현재 요청과 동일하면, 그 부분은 재계산할 필요 없이 캐시된 결과를 사용할 수 있습니다. Claude Sonnet 기준 캐시 히트 시 비용이 10분의 1로 줄어듭니다. 에이전트가 30번의 턴을 거치면서 매번 시스템 프롬프트를 재계산하는 것과, 캐시를 활용하는 것의 차이는 어마어마합니다.
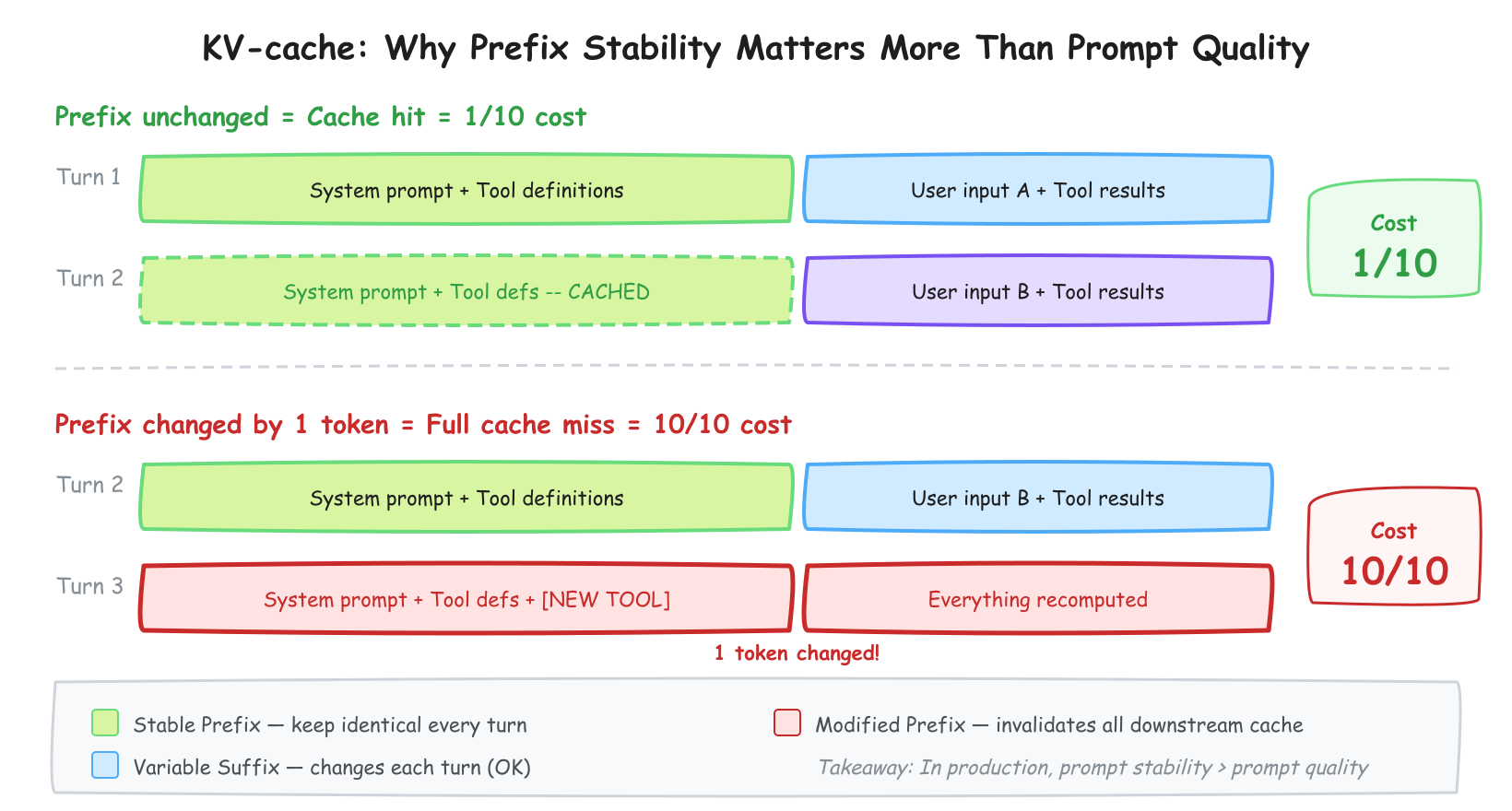
핵심은 이겁니다. 컨텍스트 접두어의 토큰 하나만 바뀌어도 이후 전체 캐시가 무효화됩니다. 그래서 Google ADK가 "안정 접두어"를 앞에 놓으라고 한 겁니다. 프롬프트의 "품질"보다 프롬프트의 "안정성"이 프로덕션에서는 훨씬 중요합니다. 아이러니합니다 — 2년 동안 프롬프트를 다듬었는데, 정작 프로덕션에서 중요한 건 프롬프트를 건드리지 않는 것이었습니다.
Manus 팀은 여기서 더 나아가 다섯 가지 실전 원칙을 제시했습니다.
- KV-cache 최적화와 접두어 안정성이 최우선. 위에서 설명한 그대로입니다. 시스템 프롬프트와 도구 정의는 가능한 한 고정합니다.
- 도구 목록을 중간에 바꾸지 말 것. 에이전트가 실행 중에 도구를 동적으로 추가하거나 제거하면, 도구 정의가 접두어에 포함되어 있으므로 캐시가 깨집니다. 대신 사용 가능한 도구를 상태에 따라 활성/비활성으로 전환하는 방식을 씁니다.
- 통제된 다양성. 에이전트가 같은 입력에 같은 행동만 반복하면 루프에 빠질 수 있습니다. 응답 포맷이나 표현을 약간씩 변주하여(예: JSON 키 순서를 바꾸거나, 같은 의미를 다른 문장으로 표현) 모델이 새로운 시도를 하도록 유도합니다. 다만 접두어 안정성을 해치지 않는 범위 내에서요.
- 프로덕션 우선 접근. 모델을 처음부터 다시 훈련(fine-tuning)하는 것보다, 컨텍스트 엔지니어링으로 개선하는 쪽이 반복 속도가 훨씬 빠릅니다. 개선 사항을 몇 시간 안에 배포할 수 있습니다.
- 모델이 바뀌어도 하네스는 유지. 컨텍스트 관리 시스템을 특정 모델에 종속되지 않게 설계합니다. Claude에서 GPT로, GPT에서 Gemini로 모델을 교체해도 하네스는 그대로 작동해야 합니다.
HumanLayer의 12-Factor Agents도 같은 맥락에서 프로덕션 에이전트의 원칙을 정리했습니다. Heroku의 12-Factor Apps(클라우드 네이티브 앱 설계 원칙)에서 영감을 받은 것입니다. 컨텍스트 엔지니어링과 직결되는 핵심 세 가지만 꼽으면 이렇습니다.
- 컨텍스트 윈도우에 한계가 있다는 걸 인정하라. "40% 이상 차면 dumb zone" — 컨텍스트의 40%를 넘어서면 모델의 지시 따르기(instruction following) 능력이 급격히 떨어진다는 경험칙입니다. 정보를 많이 넣을수록 좋다는 직관과 정반대입니다.
- 자연어보다 구조화된 출력을 써라. 에이전트 간 통신이나 도구 결과는 자유 형식 텍스트가 아니라 JSON 같은 구조화된 형식을 사용해야 파싱 오류가 줄어듭니다.
- Human-in-the-loop를 설계 시점에 넣어라. "나중에 사람 승인 기능을 추가하겠다"가 아니라, 처음부터 사람이 개입할 수 있는 지점을 아키텍처에 포함시켜야 합니다.
4.4 에이전틱 인프라
MCP: 도구 연결의 표준이 되다
컨텍스트 엔지니어링의 가장 근본적인 인프라부터 시작합시다. MCP(Model Context Protocol)입니다. Anthropic이 2024년 11월에 발표한 이 개방형 프로토콜은, LLM이 외부 도구·데이터 소스와 통신하는 방식을 표준화합니다.
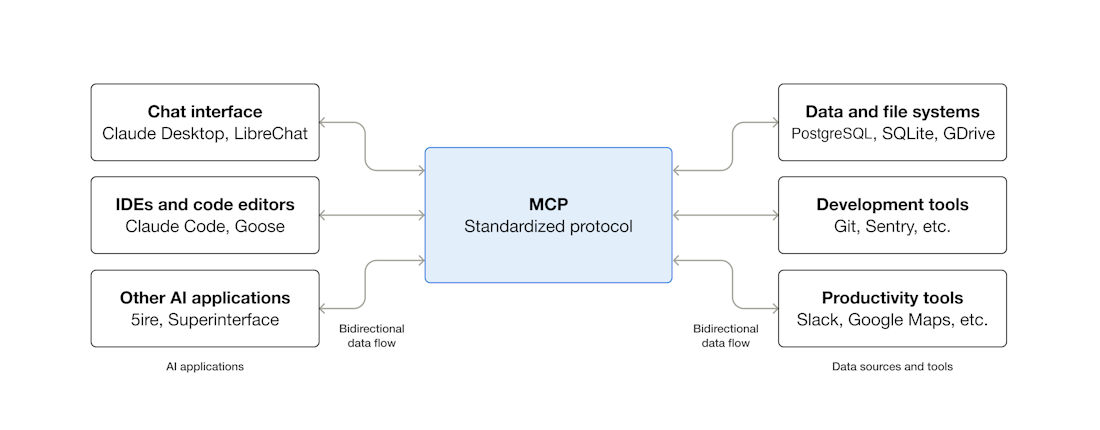
MCP 이전에는 각 도구마다 연결 방식이 달랐습니다. Slack API, GitHub API, 데이터베이스, 파일 시스템 — 에이전트가 접근해야 하는 도구마다 별도의 통합 코드를 작성해야 했습니다. USB 이전에 프린터, 키보드, 마우스가 각각 다른 포트를 쓰던 것과 비슷합니다. MCP는 이 USB 역할을 합니다. 도구 쪽에서 MCP 서버를 한 번 만들어두면, MCP를 지원하는 모든 AI 클라이언트(Claude, ChatGPT, Cursor, VS Code 등)가 동일한 방식으로 연결할 수 있습니다.
채택 속도가 놀라웠습니다. 2025년 3월 OpenAI가 Agents SDK와 ChatGPT에 MCP를 도입했고, 4월에는 Google DeepMind가 Gemini 지원을 발표했습니다. 12월에는 Anthropic이 MCP를 Linux Foundation 산하의 Agentic AI Foundation에 기부하며, Anthropic·OpenAI·Google·Microsoft가 공동 거버넌스에 참여하게 됩니다. 1년 만에 월간 SDK 다운로드 9,700만 건 이상, 10,000개 이상의 커뮤니티 서버가 운영되는 산업 표준이 된 것입니다.
MCP가 컨텍스트 엔지니어링에서 중요한 이유는, 도구 결과가 컨텍스트 윈도우의 핵심 구성 요소이기 때문입니다. 도구 연결이 표준화되면 도구 결과의 형식도 예측 가능해지고, 컨텍스트 구성이 안정화됩니다. 참고로 Google은 2025년 4월 A2A(Agent-to-Agent Protocol)를 발표하여 에이전트 간 통신도 표준화하려 하고 있습니다. MCP가 "에이전트 ↔ 도구"의 세로축이라면, A2A는 "에이전트 ↔ 에이전트"의 가로축입니다.
에이전트의 분해와 협업: 스킬, 서브에이전트, 스웜
에이전트가 복잡해지면서, "하나의 거대한 에이전트"보다 작고 전문화된 단위를 조합하는 패턴이 등장했습니다.
스킬(Skills)은 에이전트가 수행할 수 있는 재사용 가능한 능력 단위입니다. 도구(tool)가 "검색 API 호출"이라는 단일 기능이라면, 스킬은 "관련 문서를 검색하고, 요약하고, 사용자에게 제시한다"는 일련의 작업 흐름을 캡슐화합니다. 도구가 함수라면, 스킬은 함수 여러 개를 조합한 모듈입니다. 여기서 중요한 특성이 지연 로딩(lazy loading)입니다. 에이전트가 수십 개의 스킬을 가질 수 있지만, 모든 스킬의 상세 정의를 컨텍스트에 미리 올려놓으면 토큰 낭비가 심합니다. 대신 스킬 목록(이름과 한 줄 설명)만 안정 접두어에 넣어두고, 에이전트가 특정 스킬이 필요하다고 판단하면 그때 상세 정의를 동적 접미어 쪽에 로딩합니다. 접두어(스킬 목록)는 고정되어 있으므로 KV-cache가 깨지지 않고, 상세 정의는 도구 결과처럼 뒤쪽에서 유연하게 추가됩니다. Google ADK의 Stable Prefix / Variable Suffix 패턴이 여기서도 작동하는 것입니다.
서브에이전트(Sub-agent)는 메인 에이전트가 특정 작업을 위임하는 하위 에이전트입니다. 앞서 다룬 "Isolate(격리)" 전략의 구현체이기도 합니다. 코딩 에이전트가 디버깅 요청을 받으면, 디버깅 전문 서브에이전트에게 해당 파일과 에러 로그만 넘깁니다. 메인 에이전트의 컨텍스트 윈도우는 깨끗하게 유지됩니다.
스웜(Swarm)은 OpenAI가 2024년 10월 공개한 실험적 프레임워크에서 제안된 오케스트레이션 패턴입니다. 핵심은 루틴(routine)과 핸드오프(handoff). 중앙 오케스트레이터 없이, 에이전트들이 자율적으로 서로에게 작업을 넘깁니다. 고객 지원을 예로 들면, 일반 상담 에이전트가 대화를 시작하고, 환불 문의가 들어오면 환불 전문 에이전트에게 핸드오프, 기술 문제가 나오면 기술 지원 에이전트에게 다시 핸드오프. 이 패턴은 이후 OpenAI Agents SDK로 발전하여 프로덕션에서 사용 가능한 형태가 되었습니다.
Context Hub: 에이전트의 기억상실증을 치료하다
코딩 에이전트에게 "Stripe API로 결제를 구현해줘"라고 시키면 어떻게 될까요? 에이전트는 훈련 시점에 학습한 Stripe API를 사용합니다. 문제는 그 API가 6개월 전 버전일 수 있다는 것입니다. 엔드포인트가 바뀌었거나, 새로운 필수 파라미터가 추가되었거나. 결과물은 컴파일되지만 실행하면 404를 뱉습니다. Karpathy는 이걸 "전향성 기억상실증(anterograde amnesia)"이라 비유했습니다. LLM은 훈련 이후의 새 정보를 축적하지 못하고, 매 대화마다 "훈련 시점에 알고 있던 것"만으로 작동합니다.
Andrew Ng의 Context Hub는 이 문제를 정면으로 해결합니다. 에이전트가 코드를 생성하기 전에, chub get stripe --lang python 같은 CLI 명령으로 최신 API 문서를 실시간 검색하여 컨텍스트에 주입하는 도구입니다. 핵심 설계 원칙이 세 가지 있습니다.
- 큐레이션된 문서. 웹 검색 결과를 그대로 넣지 않습니다. 각 API별로 사람이 검증한 문서를 제공하여 노이즈를 제거합니다. 68개 API 문서로 시작해 커뮤니티가 계속 확장하고 있습니다.
- 스택 특화.
--lang py또는--lang js플래그로 에이전트가 사용하는 언어에 맞는 문서만 가져옵니다. 토큰 낭비를 줄입니다. - 어노테이션 지속성. 에이전트가 문서에 붙인 메모(annotation)가 세션 간에 유지됩니다. "이 엔드포인트는 rate limit이 빡빡하니 배치로 처리하라"는 교훈이 다음 세션에도 남습니다.
RAG(검색 증강 생성)의 실무적 진화 형태라고 할 수 있습니다. RAG가 "관련 문서를 검색해서 넣는다"라면, Context Hub는 "검증된 최신 문서를 체계적으로 관리하고 주입한다"입니다.
메모리: 세션을 넘어서
컨텍스트 윈도우는 "작업 기억(working memory)"입니다. 하지만 에이전트가 세션 간에 기억을 유지하려면 별도의 메모리 시스템이 필요합니다. 앞서 언급한 "Agent Drift"가 바로 이 문제입니다. LLM은 매 대화마다 단기 기억만으로 작동하니까요.
해결책은 외부 메모리입니다. 파일 기반 메모리(CLAUDE.md, 프로젝트 노트), 벡터 DB(시맨틱 유사도 기반 검색), 구조화된 메모리(세션 간 전달되는 JSON 상태). Claude와 ChatGPT 모두 대화 간 기억 기능을 도입했습니다. Anthropic의 접근은 "컨텍스트 컴팩션(compaction)" — 오래된 대화를 단계적으로 요약하여 새 컨텍스트에 주입하는 전략 — 이었습니다. 실전에서는 다단계 압축 파이프라인으로 구현됩니다 — 가장 저렴한 방법(오래된 메시지를 통째로 제거)부터, 개별 도구 결과를 선택적으로 압축하는 방법, 전체를 요약하는 방법까지 비용과 정보 손실의 트레이드오프를 단계적으로 관리합니다.
4.5 그래도 부족했다 — 컨텍스트의 벽
컨텍스트 엔지니어링은 진짜 진보였습니다. 의심의 여지가 없습니다. 하지만 프로덕션에서 에이전트를 운영해 본 팀들은 곧 벽에 부딪혔습니다.
첫째, 단일 턴의 한계입니다. 컨텍스트 엔지니어링의 대부분의 기법은 "이번 API 호출에 무엇을 넣을 것인가"에 초점을 맞춥니다. 하지만 에이전트는 단일 턴이 아닙니다. 수십 번의 연쇄적인 결정을 내리고, 도구를 실행하고, 결과를 해석합니다. 15번째 턴에서 3번째 턴의 도구 결과가 필요한데 이미 압축되어 사라졌다면? 컨텍스트를 완벽하게 구성했지만, 그 컨텍스트를 소비하는 루프 자체가 잘못 설계되어 있다면? 이건 컨텍스트의 문제가 아니라 시스템의 문제입니다.
둘째, 에러 복구의 부재입니다. 도구 호출이 실패하면? 모델이 환각을 보이면? 비용이 폭주하면? 컨텍스트를 아무리 잘 구성해도, 실행 중 발생하는 예외를 처리하는 메커니즘은 별도로 필요합니다. 프로덕션 에이전트는 비용 인식 에러 복구(무료 옵션 먼저 시도, 그 다음 저비용, 마지막에 고비용), 수확 체감 감지(같은 실수를 반복하면 루프 중단), 서킷 브레이커(전기의 차단기처럼, 연속 실패가 감지되면 자동으로 차단하는 패턴) 같은 메커니즘이 필요합니다. 이것들은 컨텍스트 엔지니어링의 범위를 넘어서는 것들이었습니다.
셋째, 보안입니다. 에이전트가 외부 입력을 처리하면서 동시에 민감한 데이터에 접근하고 상태를 변경할 수 있다면, 프롬프트 인젝션(사용자가 악의적 지시를 입력에 숨기는 공격) 한 방에 회사 데이터가 유출될 수 있습니다. Simon Willison은 이것을 "Lethal Trifecta"라 불렀는데, 섹션 5.4에서 상세히 다룹니다. 컨텍스트 엔지니어링은 "무엇을 넣을 것인가"를 다루지만, "무엇을 하지 못하게 할 것인가"는 다루지 않습니다.
컨텍스트 시대의 사인(死因)은 이겁니다. 완벽한 컨텍스트를 구성해도, 그것을 소비하는 시스템의 설계가 허술하면 여전히 실패합니다. 컨텍스트는 필요 조건이었지 충분 조건이 아니었습니다. 엄밀함이 또 이동해야 할 때가 온 것입니다.
5. 하네스 엔지니어링의 시대 (2026~)
5.1 기원: 2026년 2월의 동시 발견
2026년 2월, Mitchell Hashimoto가 "My AI Adoption Journey"를 발표했습니다. AI 회의론에서 출발해 실질적인 성과를 내기까지의 여정을 기록한 글이었습니다. 그 여정에서 그가 도달한 결론:
에이전트가 실수할 때마다, 그 실수가 구조적으로 다시 발생할 수 없도록 시스템을 변경한다.
프롬프트를 고치는 게 아닙니다. 에이전트를 둘러싼 시스템 — 규칙, 도구, 제약, 피드백 루프 — 을 바꾸는 겁니다. "harness engineering"이라는 용어가 태어난 순간이었습니다.
놀라운 건 그 다음에 벌어진 일입니다. 2주 만에 OpenAI, Martin Fowler/Birgitta Böckeler(ThoughtWorks의 수석 기술 컨설턴트), Ethan Mollick(Wharton 경영대학원 교수)이 서로 독립적으로 같은 결론을 발표했습니다. 사전 조율이 아니었습니다. 모두가 같은 벽에 부딪히고 있었기 때문에 가능한 동시 발견이었습니다. 과학사에서 이런 걸 "multiple discovery"라고 부릅니다. 아이디어의 시간이 온 거죠.
Fowler/Böckeler가 핵심 공식을 제시했습니다.
에이전트 = 모델 + 하네스
하네스란 "에이전트에서 모델을 뺀 나머지 전부"입니다. Philipp Schmid — Hugging Face 기술 리드 — 는 이것을 OS 비유로 확장했습니다. 모델은 CPU(연산 능력), 하네스는 운영체제(컨텍스트 큐레이션, 도구 관리, 권한 제어, 에러 복구)입니다. Mollick — Wharton 경영대학원 교수이자 AI 실용주의 옹호자 — 은 말(horse) 비유를 썼습니다. "하네스는 말의 힘을 수레나 쟁기에 연결하는 장치." 말이 아무리 강력해도, 고삐와 안장과 굴레가 없으면 밭을 갈 수 없습니다.
Simon Willison의 에이전트 정의도 이 맥락에서 읽어야 합니다. "에이전트란 목표를 달성하기 위해 루프 안에서 도구를 실행하는 LLM입니다." 핵심은 "루프"입니다. 그리고 루프를 제어하는 것이 하네스입니다.
5.2 하네스의 해부학: 네 사분면
"하네스"라고 하면 거창하게 들리지만, 결국 에이전트의 실수를 잡아내고 바로잡는 장치들의 집합입니다. Fowler/Böckeler가 2×2 분류 체계로 깔끔하게 정리했습니다.
| 피드포워드 (사전 유도) | 피드백 (사후 교정) | |
|---|---|---|
| 결정론적 | 가이드(Guides): AGENTS.md, .cursorrules, 코딩 컨벤션 |
연산적(Computational): 컴파일러, 타입 체커, 린터 |
| 비결정론적 | 시스템 프롬프트/지시문: 역할 정의, 행동 제약, few-shot 예시 | 추론적(Inferential): LLM-as-a-judge, 의미론적 코드 리뷰 |
각 사분면이 어떤 실패를 막는지 구체적으로 봅시다.
좌상단 — 가이드 (결정론적 피드포워드). 에이전트가 애초에 잘못된 방향으로 가지 않게 유도합니다. AGENTS.md 파일에 "React보다 Vanilla JS를 써라"라고 쓰면, 에이전트는 코드를 생성할 때 이 지침을 참조합니다. Cursor의 .cursorrules 파일이 바로 이 사분면입니다 — 프로젝트별로 "이 프로젝트에서는 Tailwind CSS를 사용한다", "타입은 항상 명시적으로 선언한다" 같은 규칙을 정의합니다. 비용은 거의 0. 하지만 강제성은 없습니다. 에이전트가 무시할 수도 있습니다.
우상단 — 연산적 (결정론적 피드백). 가이드를 무시해도 기계적으로 잡아냅니다. 컴파일러 에러, 린터 경고, 타입 체커, 정적 분석. 에이전트가 잘못된 코드를 쓰면, 컴파일 에러를 받아서 자동으로 수정합니다. OpenAI Codex 팀이 특히 강조한 계층입니다 — 인간 리뷰어 대신 커스텀 린터가 아키텍처 규칙을 강제합니다.
좌하단 — 시스템 프롬프트 (비결정론적 피드포워드). 결정론적 규칙으로 포착할 수 없는 뉘앙스를 처리합니다. "사용자에게 공손하게 대하라", "확실하지 않으면 확인을 구하라", "보안에 민감한 작업은 반드시 승인을 받아라" 같은 행동 제약. 규칙이라기보다는 지침입니다.
우하단 — 추론적 (비결정론적 피드백). "코드가 컴파일되지만 의미적으로 틀린" 경우를 잡습니다. 또 다른 LLM이 코드를 리뷰하거나, 생성된 출력의 품질을 평가합니다. Anthropic의 Evaluator 에이전트가 이 사분면에 해당합니다.
프로덕션 하네스는 이 네 사분면을 레이어링하여 조합합니다. 방어의 깊이(defense in depth)입니다. 섹션 4에서 다룬 12-Factor Agents의 말을 빌리면, "프로덕션에서 성공하는 대부분의 'AI 에이전트'는 마법적인 자율 존재가 아니라, LLM 기능이 핵심 지점에 삽입된 잘 설계된 전통적 소프트웨어"입니다.
5.3 실전: 세 개의 사례
이론은 충분합니다. 실전에서 하네스 엔지니어링은 어떻게 작동할까요?
Anthropic의 3-에이전트 아키텍처. Anthropic 팀이 장시간 실행 에이전트를 실험하면서 계속 부딪힌 문제가 있었습니다. 에이전트에게 "웹앱을 만들어라"고 시키면, 30분 뒤 뭔가가 나옵니다. 작동은 합니다. 하지만 버튼이 겹치고, API가 엉뚱한 데이터를 반환하고, 에이전트 자신은 "완료!"라고 보고합니다. 왜? 2026년 3월, "Harness Design for Long-Running Application Development"에서 공개한 핵심 발견은 놀라울 만큼 단순했습니다 — 에이전트는 자기 작업을 정확히 평가할 수 없다. 학생이 자기 시험을 채점하면 안 되는 것과 같은 이유입니다.
그래서 GAN(Generative Adversarial Network — 생성자와 판별자가 서로 경쟁하며 품질을 높이는 신경망 구조)에서 영감을 받아 에이전트를 세 개로 분리했습니다. 만드는 놈과 평가하는 놈을 나눈 겁니다.
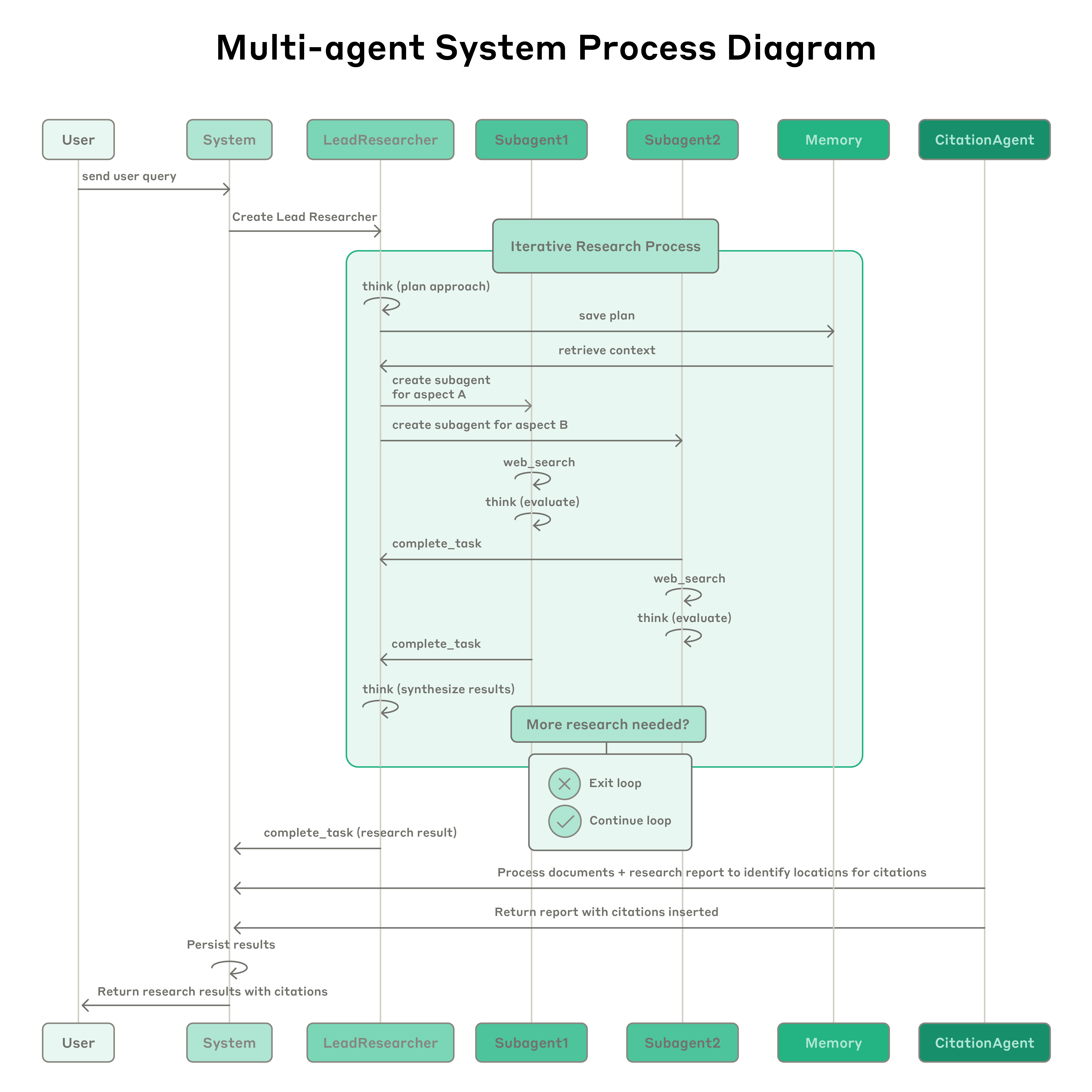
- Planner: 간단한 프롬프트를 상세한 제품 스펙으로 확장합니다. 기술적 세부사항이 아니라 야심찬 범위와 상위 설계에 집중합니다. 너무 구체적인 기술 지시를 내리면 오히려 캐스케이딩 에러(하나의 잘못된 결정이 연쇄적으로 문제를 일으키는 것)가 발생한다는 발견이 핵심이었습니다.
- Generator: 한 번에 하나의 기능씩 구현합니다. React, Vite, FastAPI, SQLite 스택으로, 각 스프린트를 자체 평가한 뒤 QA에 넘깁니다. 스프린트 단위로 작업하여 컨텍스트를 주기적으로 리셋합니다.
- Evaluator: Playwright(브라우저 자동화 프레임워크)로 E2E 테스트를 실행합니다. UI 기능, API 엔드포인트, 데이터베이스 상태를 제품 깊이, 기능성, 비주얼 디자인, 코드 품질 기준으로 채점합니다. 기준 미달이면 Generator에게 구체적 피드백과 함께 다시 돌려보냅니다.
비용은? 단독 실행(20분, 9달러) 대비 풀 하네스는 6시간에 200달러입니다. 22배. 하지만 결과물의 완성도는 비교가 안 됩니다. 이건 단순한 비용 증가가 아니라 비용의 위치 이동입니다. 사람이 사후에 수정하는 비용에서, 시스템이 사전에 검증하는 비용으로.
OpenAI Codex 실험. 이 사례는 좀 더 자세히 살펴볼 가치가 있습니다. OpenAI가 "Harness Engineering"에서 공개한 실험의 규모부터 봅시다. 5개월. 처음 3명에서 7명으로 늘어난 엔지니어 팀. 수동으로 작성한 코드 0줄. 생성된 코드 약 100만 줄. PR 약 1,500개. 수동 대비 약 10배 속도.
잠깐. 수동 코드 0줄? 7명의 엔지니어가 5개월 동안 코드를 한 줄도 안 썼다고?
맞습니다. 그리고 이게 핵심입니다. 방 안의 인간들은 코드를 작성하지 않았습니다. 코드가 안정적으로 생성될 수 있는 환경을 설계하고 있었습니다. 그들이 한 일은 세 가지였습니다.
- 저장소 지식의 시스템화. 팀이 처음 발견한 건, 에이전트가 같은 실수를 반복한다는 것이었습니다. 왜? Slack에서 합의한 아키텍처 결정, 시니어 개발자 머릿속에만 있는 설계 원칙 — 이런 것들이 에이전트에게는 보이지 않았기 때문입니다. 그래서 모든 원칙과 설계 결정을 저장소 안의 마크다운과 코드로 문서화했습니다. "에이전트에게 보이지 않는 지식은 존재하지 않는 것과 같다."
- 기계적 강제성. 문서화만으로는 부족했습니다. "이 패턴을 쓰세요"라고 적어놓아도 에이전트는 무시합니다. 그래서 커스텀 린터와 구조적 테스트로 아키텍처 규칙을 강제했습니다. 에이전트가 린터를 통과하려고 스스로 코드를 수정하게 하는 겁니다. 인간 리뷰어를 기계적 강제로 대체한 것이죠.
- 점진적 공개. 초기에 팀은 방대한 문서를 한 번에 주입하려 했습니다. 결과는? 에이전트가 길을 잃었습니다. 수천 페이지를 쏟아부으면 정작 필요한 정보가 노이즈에 묻힙니다. 해결책은 에이전트에게 지도(map)를 주고 필요한 정보를 직접 찾아가게 하는 방식이었습니다. "Codex에게 1,000페이지짜리 매뉴얼이 아니라 지도를 줘라."

이 세 가지를 한 문장으로 요약하면 이겁니다. 실수가 나면 에이전트를 탓하지 않고, 하네스를 개선한다. Hashimoto의 철학과 정확히 같은 결론입니다.
Ralph 패턴: 밤새 돌아가는 에이전트. 세 번째 사례는 기업이 아니라 커뮤니티에서 나왔습니다. Anthropic과 OpenAI가 "어떻게 하네스를 설계하는가"를 보여줬다면, Ralph는 "하네스 위에서 에이전트를 어떻게 자율 실행하는가"를 보여준 커뮤니티 사례입니다. Geoffrey Huntley가 제안한 이 패턴의 핵심은 단순합니다. PRD(Product Requirements Document — 제품 요구사항 문서)를 정의하고, AI 코딩 도구(Claude Code, Amp 등)를 루프 안에서 반복 실행하여 PRD의 모든 항목이 완료될 때까지 돌리는 것입니다.
영리한 점은 컨텍스트 관리 방식입니다. 매 이터레이션마다 에이전트를 클린 컨텍스트로 새로 시작합니다. 컨텍스트 윈도우가 오염되거나 비대해지는 문제를 원천 차단하는 거죠. 대신 상태는 git 히스토리, progress.txt, prd.json으로 유지합니다. 에이전트의 기억은 컨텍스트 윈도우가 아니라 파일 시스템에 있는 겁니다.
검증이 프로그래밍적으로 가능할수록(컴파일, 테스트, 린트) Ralph는 더 자율적으로 작동합니다. Fowler의 2×2 분류에서 "연산적 피드백(컴파일러, 린터)" 사분면이 핵심인 셈입니다. 2개월 만에 GitHub 스타 12,000개를 넘기며, "개발자가 자는 동안 에이전트가 코드를 짠다"는 하네스 엔지니어링의 비전을 가장 직접적으로 구현한 사례가 되었습니다.
5.4 보안: Lethal Trifecta와 2인 규칙
하네스 엔지니어링에서 보안은 선택이 아닌 필수입니다. Willison의 "Lethal Trifecta"가 핵심 프레임워크입니다.
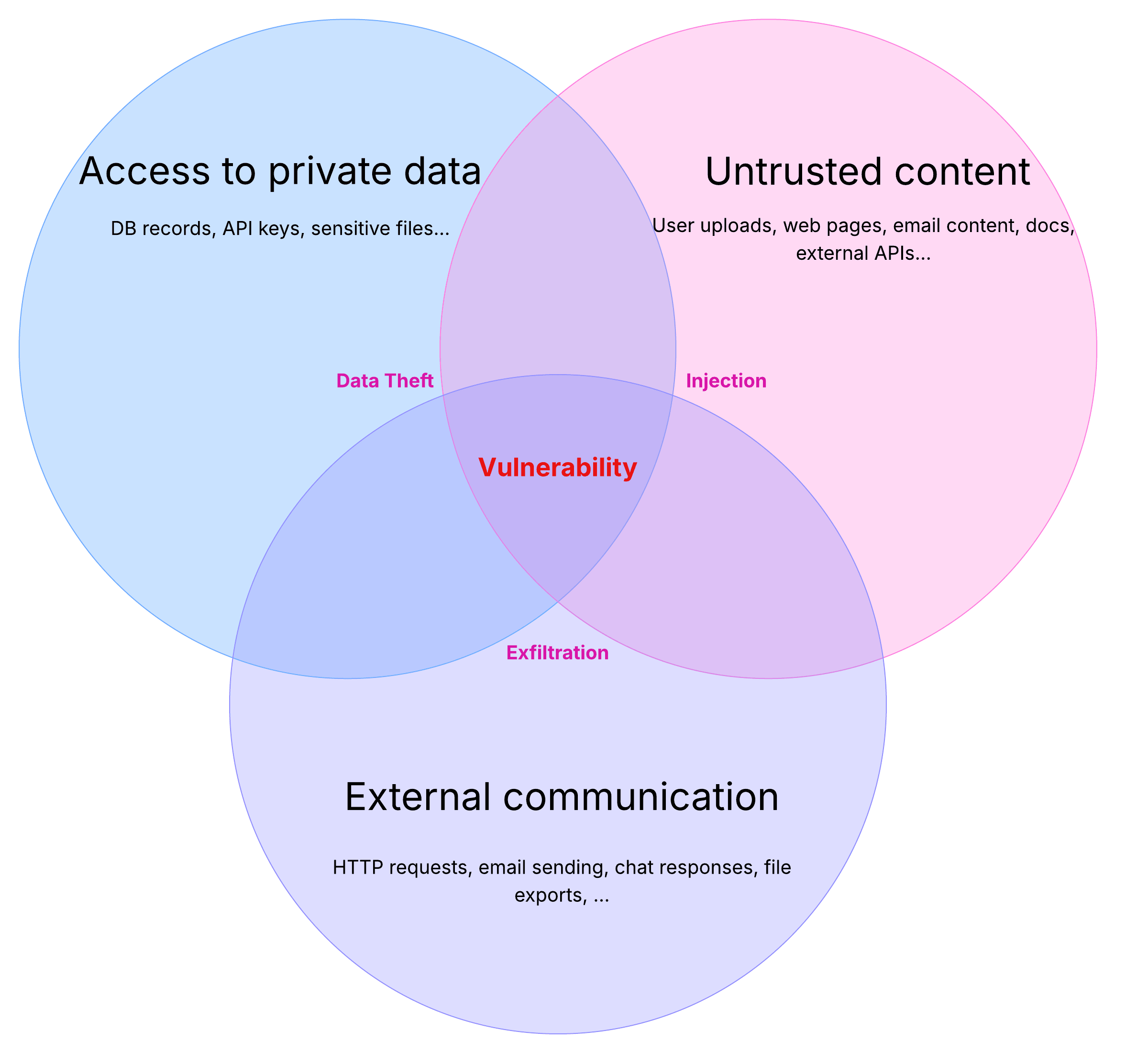
에이전트가 다음 세 가지를 동시에 가질 때 보안 사고는 필연입니다.
- 신뢰할 수 없는 입력 처리 (외부 웹, 이메일, 사용자 입력)
- 민감한 시스템/데이터 접근 (개인정보, 내부 API, 데이터베이스)
- 상태 변경 능력 (이메일 발송, 파일 삭제, API 호출)
Meta AI의 "Rule of Two"는 이것을 실천 가능한 규칙으로 바꿨습니다. Chromium 브라우저의 보안 정책에서 빌려온 개념입니다. 에이전트가 이 세 가지 중 최대 두 가지만 동시에 가질 수 있게 하라. 세 가지 모두 필요하면 반드시 human-in-the-loop(사람의 승인)를 거쳐야 합니다.
구체적 예시:
- 외부 데이터 읽기(1) + 민감 정보 처리(2) → 상태 변경(3) 불가. 반드시 사람의 승인 필요.
- 외부 데이터 읽기(1) + 상태 변경(3) → 민감 정보 접근(2) 차단. 샌드박스에서만 실행.
- 민감 정보 처리(2) + 상태 변경(3) → 외부 입력(1) 차단. 내부 데이터만 처리.
이 가드레일은 기능 제약이 아니라 신뢰성 확보의 필수 요소입니다. 하네스가 없는 에이전트는 데모에서는 빛나지만 프로덕션에서는 시한폭탄입니다.
6. 세 시대의 부검 보고서
6.1 종합 비교
| 차원 | Prompt Engineering | Context Engineering | Harness Engineering |
|---|---|---|---|
| 시대 | 2022-2024 | 2025 | 2026~ |
| 핵심 질문 | "어떤 말을 해야 하나?" | "어떤 정보를 넣어야 하나?" | "어떤 시스템을 만들어야 하나?" |
| 은유 | 이메일 작성 | 받은편지함 관리 | 이메일 시스템 설계 |
| OS 비유 | 명령어 한 줄 | RAM 관리 | 운영체제 전체 |
| 핵심 메트릭 | 응답 품질 (주관적) | KV-cache hit rate | 태스크 완료율, 비용/태스크 |
| 실패 모드 | Blind prompting, 비결정론 | 컨텍스트 오염, Lost-in-the-Middle | 오케스트레이션 버그, 보안 사고 |
| 엄밀함의 위치 | 프롬프트 텍스트 | 컨텍스트 윈도우 구성 | 전체 시스템 아키텍처 |
| 대표 도구 | ChatGPT, 초기 Copilot | Cursor Composer, RAG 파이프라인 | Claude Code, Copilot Coding Agent |
| 필요 역량 | 언어 감각 + 도메인 지식 | 정보 아키텍처 | 시스템 설계 + 보안 |
6.2 교훈: 엄밀함의 이동 경로
이 표를 세로로 읽으면 기술사가 보이고, 가로로 읽으면 각 시대의 한계가 보입니다. 하지만 가장 중요한 패턴은 대각선에 있습니다 — 각 시대는 이전 시대를 대체하지 않고 포함(subsume)합니다.
하네스 엔지니어링 안에 컨텍스트 엔지니어링이 있고, 그 안에 프롬프트 엔지니어링이 있습니다. 좋은 하네스는 여전히 좋은 컨텍스트를 요구하고, 좋은 컨텍스트는 여전히 좋은 프롬프트를 요구합니다. "프롬프트 엔지니어링이 죽었다"는 트윗을 가끔 봅니다. 틀렸습니다. 프롬프트 엔지니어링은 하네스 엔지니어링의 서브모듈이 되었을 뿐입니다. 죽은 게 아니라 승진한 겁니다 — 더 큰 시스템의 일부로.
Fowler/Böckeler가 강조한 한 가지 더. 하네스는 뜯어낼 수 있어야(rippable) 합니다. 모델이 발전하면 하네스의 "smart" 로직 중 일부는 불필요해집니다. Claude 5.0이 나오면 Claude 4.5를 위해 만든 에러 복구 로직의 절반이 쓸모없어질 수 있습니다. 하네스 설계의 기술은 "무엇을 만들 것인가"만큼이나 "무엇을 쉽게 제거할 수 있게 만들 것인가"에 달려 있습니다. 과도한 엔지니어링은 다음 모델 업데이트의 발목을 잡습니다.
6.3 전망: 엄밀함의 다음 정류장
이 패턴이 계속된다면 — 그리고 지난 4년이 어떤 증거라면 — 엄밀함은 또 이동할 것입니다. 이미 몇 가지 방향이 보입니다.
Guardian Agent. 상상해 보십시오 — 에이전트가 코드를 배포하려 하는데, 다른 에이전트가 실시간으로 "잠깐, 이 변경은 규제 준수 범위 밖"이라고 막아서는 것. Anthropic의 Evaluator가 그 원시적 형태입니다. 독립적인 인프라 레이어로 분화하는 건 시간 문제. 엄밀함이 "실행"에서 "감시"로 이동하는 겁니다.
평가 엔지니어링. "behavior beats benchmarks"라는 표현이 등장했습니다. MMLU 점수가 아니라, 에이전트가 실제 업무를 완료하는 비율. 실패했을 때 얼마나 우아하게 복구하는가. 특히 어려운 건 검증 불가능한(non-verifiable) 보상입니다. 코드가 컴파일되는지는 기계가 판단할 수 있지만, "이 글이 잘 읽히는가", "이 디자인이 아름다운가"는 어떻게 점수를 매길까요? LLM-as-a-judge(LLM이 다른 LLM의 출력을 평가하는 것)가 하나의 답으로 떠오르고 있지만, 평가자 자체의 편향 문제는 여전히 열려 있습니다. "어떻게 평가할 것인가" 자체가 엔지니어링 분야가 되고 있습니다. 솔직히 말하면, 이 글을 작성하면서 사용한 것도 정확히 이 패턴입니다 — 평가 에이전트가 8개 기준에 따라 점수를 매기고, 80점 미달이면 피드백 기반으로 재작성하는 루프를 돌렸습니다. (2026년에 이 길이의 글을 쓰면서 AI를 안 썼을 거라고 생각한 분은 없겠죠?)
지식 엔진. 현재의 컨텍스트 엔지니어링은 "이번 턴에 무엇을 넣을 것인가"를 다룹니다. 하지만 실제 소프트웨어 프로젝트에는 코드 자체보다 더 중요한 정보가 있습니다. "왜 이 아키텍처를 선택했는가", "6개월 전에 이 방식을 시도했다가 왜 철회했는가", "이 모듈의 원래 설계 의도는 무엇이었는가" — 코드에는 남아 있지 않지만 프로젝트의 맥락을 이해하는 데 결정적인 지식들입니다.
지식 엔진은 이것을 해결하려 합니다. 벡터 검색(현재 코드와 유사한 코드 찾기)을 넘어, 코드 그래프(함수 간 호출 관계, 의존성 구조), 커밋 히스토리(코드가 왜, 어떻게 변해왔는가), 메모리 시스템(과거 세션에서 학습한 교훈)을 결합하는 방향입니다. Andrew Ng의 Context Hub가 "최신 API 문서"라는 한 가지 축을 해결했다면, 지식 엔진은 프로젝트의 전체 역사와 설계 의도를 에이전트가 이해하게 만드는 것입니다. "이 함수를 수정하라"가 아니라 "이 함수가 왜 이렇게 생겼는지 이해한 상태에서 수정하라"의 차이. 다른 차원의 게임입니다.
Willison은 이미 "Agentic Engineering Patterns"이라는 이름으로 이 패턴들을 체계화하고 있습니다. 흩어진 관행들이 엔지니어링 분야로 결정화(crystallize)되는 과정입니다. 2023년에 "prompt engineering"이 당연한 단어가 되었듯, 2027년쯤이면 "harness engineering"도 그렇게 되어 있겠죠. 그때쯤 누군가가 또 새로운 이름을 들고 나타날 겁니다. 그게 이 업계입니다.
2023년에 Karpathy는 "가장 핫한 새 프로그래밍 언어는 영어"라고 했습니다. 3년 뒤, 가장 핫한 새 엔지니어링은 영어가 아닌 다른 것을 다루고 있습니다 — 컨텍스트 윈도우의 구조, 에이전트 루프의 상태 머신, 보안 가드레일의 레이어링. 영어는 여전히 중요합니다. 하지만 그건 이제 시스템의 일부일 뿐이지, 시스템 자체가 아닙니다.
Chad Fowler의 말이 이 글의 결론을 대신합니다. 엄밀함은 사라지지 않고, 피드백과 현실에 더 가까운 곳으로 이동합니다. 코드를 쓰는 사람에서 컨텍스트를 큐레이션하는 사람으로, 다시 에이전트가 작동하는 환경을 설계하는 사람으로. 역할이 바뀐 게 아니라 추상화 수준이 올라간 겁니다.
질문은 엄밀함이 이동하는가가 아닙니다. 이건 확인되었습니다. 질문은 우리가 이번에는 그 이동을 얼마나 빨리 알아차릴 수 있는가입니다.
참고문헌
- Mitchell Hashimoto, "My AI Adoption Journey", 2026.02
- Andrej Karpathy, "Software in the Age of AI" (YC 키노트), 2025.06
- Andrej Karpathy, "Context Engineering" (X 포스트), 2025.06.25
- Andrew Ng, "4 Agentic Design Patterns" (Sequoia AI Ascent + The Batch), 2024.03
- Simon Willison, "Agentic Engineering Patterns", 2026.02
- Simon Willison, "The Lethal Trifecta for AI Agents", 2025.06
- Martin Fowler (Birgitta Böckeler), "Harness Engineering", 2026.02
- Philipp Schmid, "The Importance of Agent Harness in 2026", 2026.01
- Ethan Mollick, "Models, Apps, and Harnesses", 2026.02
- Tobi Lütke, "Context Engineering" (X 포스트), 2025.06.19
- Chad Fowler, "Relocating Rigor", 2026.01
- Anthropic, "Building Effective Agents", 2024.12
- Anthropic, "Effective Context Engineering for AI Agents", 2025.09
- Anthropic, "Harness Design for Long-Running Application Development", 2026.03
- OpenAI, "Harness Engineering: Leveraging Codex in an Agent-First World", 2026.02
- Google, "Architecting Efficient Context-Aware Multi-Agent Framework", 2025.12
- Manus, "Context Engineering for AI Agents: Lessons from Building Manus", 2025
- HumanLayer, "12-Factor Agents", 2025
- Meta AI, "Agents Rule of Two", 2025
- Andrew Ng, "Context Hub", 2026.03
- Wei et al., "Chain-of-Thought Prompting Elicits Reasoning in LLMs", 2022
- Yao et al., "ReAct: Synergizing Reasoning and Acting in LLMs", 2022
- Yao et al., "Tree of Thoughts", 2023
- Madaan et al., "Self-Refine: Iterative Refinement with Self-Feedback", 2023
- Shinn et al., "Reflexion: Language Agents with Verbal Reinforcement Learning", 2023
- Epsilla, "The Third Evolution: From Prompt to Context to Harness Engineering", 2026
- CodeRabbit, "State of AI vs Human Code Generation Report", 2025
- Fast Company, "The Vibe Coding Hangover", 2025.09
- Collins Dictionary, "Word of the Year 2025: Vibe Coding", 2025
- Veracode, "State of Software Security 2025", 2025
- GitHub, "Octoverse 2024", 2024
- Cursor, "Series D Announcement", 2025.11
- Fortune, "Cursor at a Crossroads", 2026.03
- sshh, "How Cursor AI IDE Works", 2025
- Anthropic, "Model Context Protocol", 2024.11
- Google, "Announcing the Agent2Agent Protocol (A2A)", 2025.04
- OpenAI, "Swarm: Multi-Agent Orchestration Framework", 2024.10
- Geoffrey Huntley, "Ralph: Autonomous AI Agent Loop", 2026
Subscribe via RSS