From Prompts to Harnesses — Four Years of AI Agentic Patterns
Contents
Engineering Rigor Doesn't Disappear — It Relocates. Four Years of AI Agentic Patterns
"The hottest new programming language is English." — Andrej Karpathy, 2023. Three years later, he was only half right.
TL;DR
- Between 2022 and 2026, the AI development paradigm shifted three times: Prompt Engineering → Context Engineering → Harness Engineering.
- The real driver behind each shift: the previous paradigm couldn't deliver on its promises.
- Engineering rigor never disappeared. It moved — from prompts to context, from context to harnesses (Chad Fowler's "Relocating Rigor").
- The key metric in 2026 isn't prompt quality — it's KV-cache hit rate and harness complexity.
- This post reads more like an autopsy report than a survey — it traces why each era failed.
1. Why This Chronicle, Why Now
The third week of June 2025, the AI timeline on X suddenly started revolving around a single phrase: "Context engineering." On June 19, Shopify CEO Tobi Lütke lit the match, and within a week Karpathy, Andrew Ng, and hundreds of engineers had joined in. In a matter of days, the phrase "prompt engineering" began vanishing from the timeline. It felt like the entire industry had woken up from a party the night before, asking "what have we been doing this whole time?"
This wasn't the first time. It was the third in just four years.
Epsilla's metaphor captures those four years perfectly. In 2022, we studied how to write the perfect email. In 2025, we learned to manage our inbox. In 2026, we're designing the email system itself.
- Prompt Engineering (2022-2024): "What should I say?" — We believed the quality of instructions sent to the model determined success or failure.
- Context Engineering (2025): "What information should I provide?" — We realized what fills the context window matters more than the prompt itself.
- Harness Engineering (2026): "What system should I build?" — We accepted that the design of the entire system consuming context is the real problem.
This post has one thesis: Engineering rigor never disappeared. It relocated. As Chad Fowler — Ruby community elder and Honeycomb CTO — noted in "Relocating Rigor," this isn't the first time in software history. When the XP movement argued for "test code instead of design documents," when dynamic languages shipped "without the compiler's type checking," the old guard said the same thing every time — "that's abandoning rigor." They were wrong every time. Rigor wasn't abandoned; it moved to a higher level of abstraction. From design documents to automated tests. From compiler checks to runtime test suites. Same thing here. The criticism that "handing code to AI means losing engineering rigor" is making the rounds, but rigor is simply relocating — from writing code to designing context, and from designing context to system architecture.
Each relocation was triggered by the previous era's failure. Let's trace that arc.

2. The Prompt Engineering Era (2022-2024)
2.1 Prologue: GitHub Copilot Opens the Door
The curtain-raiser for the prompt engineering era wasn't ChatGPT. It was a tool that arrived five months earlier.
In June 2022, GitHub Copilot launched publicly. Ten dollars a month. The first commercial AI coding assistant in history. Powered by OpenAI Codex (GPT-3-based), its core feature was "ghost text" autocomplete — suggesting the next line as you typed code in your editor.
Initial reactions were mixed. "Glorified copy-paste," "automated Stack Overflow," the skeptics sneered. But developers who actually used it told a different story. According to GitHub's own research, 88% of developers reported productivity gains, and time spent on repetitive code was cut in half. By early 2024: over 20 million users, 4.7 million paid subscribers, adoption by 90% of Fortune 100 companies. Roughly 42% market share.
What's interesting is that Copilot's three-year evolution is a miniature of the three eras this post covers.
| Period | Copilot Version | Key Change | Corresponding Era |
|---|---|---|---|
| 2022.06 | Initial autocomplete | Suggests next line based on current file | Prompt era. The code itself serves as the prompt |
| 2023.11 | Copilot Chat (GPT-4) | Conversational code Q&A, explanations, refactoring | Transition from prompt to context begins |
| 2025.02 | Agent Mode | Multi-file edits, terminal execution, auto lint-fix loops | Harness era. Agent uses tools inside a loop |
| 2025.05 | Coding Agent | Issue assignment → cloud env → code → test → PR creation | Harness era deepened. Fully autonomous workflow |
The initial 2022 Copilot was a pure prompt engineering artifact. Hand the model an implicit prompt — "the code in the current file" — and let it predict the next token. Context: one file. Harness: nonexistent. That was enough to be useful — in 2022.
2.2 ChatGPT and "English Is the New Programming Language"
Five months later, November 30, 2022: ChatGPT launches. One million users in five days. A hundred million in two months. Remember what happened that week? Developer timelines on X transformed overnight. The question wasn't "what can I build with this?" but "how do I talk to this thing?" Everything looked like a problem of phrasing.
Andrej Karpathy — former Tesla AI Director, OpenAI founding member — called this moment "Software 3.0." If Software 1.0 was human-written code and 2.0 was neural network weights, then 3.0 was a paradigm where natural language instructions are the program. What used to take ten years of learning to program, solved with a single English sentence. A seductive promise. If Copilot was "a tool that helps you write code," ChatGPT was "an entity that understands code and can converse about it." The two combined, and prompt engineering exploded as a field.
2.3 Academic Foundations: Inducing Reasoning Through Prompts
While Copilot and ChatGPT were proving the concept in the field, academia was wrestling with a different question in the same period — how do you phrase things so the model reasons better? And the answers were remarkable.
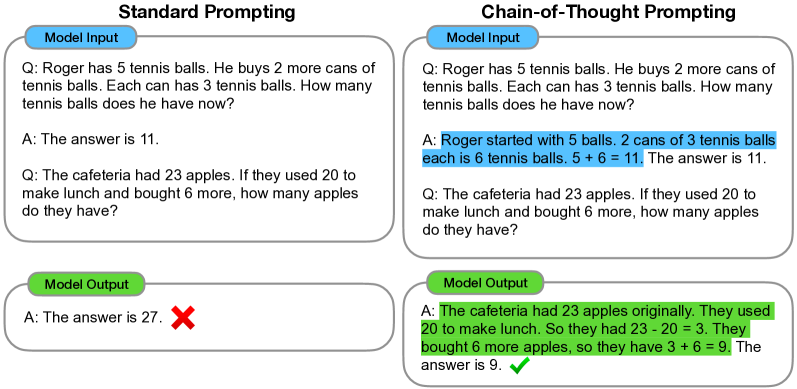
Chain-of-Thought (CoT) Prompting — Wei et al., 2022. Published in January 2022 by the Google Brain team, this paper was prompt engineering's first revolution. The idea is stunningly simple: instead of asking the model to answer directly, tell it "Let's think step by step." Take a math problem:
- Standard prompt: "A cafe has 23 customers. 6 more arrive at lunch, 5 leave in the afternoon. How many customers?" → Model: "25" (wrong)
- CoT prompt: Same problem + "Let's think step by step" → Model: "Start with 23. 6 arrive → 23 + 6 = 29. 5 leave → 29 - 5 = 24" (correct)
On GSM8K (grade-school math), PaLM 540B's accuracy jumped from 17.9% to 58.1%. Just by asking the model to "show its work," arithmetic, commonsense, and symbolic reasoning performance leapt. The power of a single prompt line, proven.
ReAct: Combining Reasoning and Acting — Yao et al., 2022. In October of the same year, a Princeton-Google team took it further. If CoT was "thinking only," ReAct alternates between Thought and Action. The model searches Wikipedia on its own, observes the result, then reasons again — a loop.
Thought: I need to know about X to answer this question.
Action: Search[X]
Observation: X is ...
Thought: Now comparing with Y...
Action: Search[Y]
...
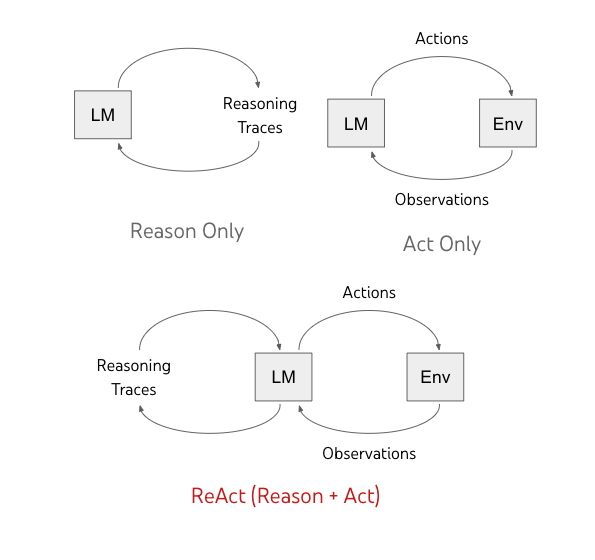
Two key results. First, external tool use reduces hallucination — the model can look up what it doesn't know. Second, the reasoning process is transparent — you can trace why it gave a particular answer. A 34% absolute improvement on ALFWorld, 10% on WebShop. The archetype of the agent was born here. Every AI agent today — Claude Code, Cursor Agent, GitHub Copilot Coding Agent — is a variation on this Thought-Action-Observation loop.
So far, smooth sailing. The trouble started when people pushed these ideas harder.
Tree-of-Thought — Yao et al., 2023. In 2023, the push was to expand reasoning's "breadth," not just its depth.

Where CoT reasons in a straight line, Tree-of-Thought explores multiple reasoning paths simultaneously, backtracking from dead ends. Like reading ahead in chess: "if I play this move… and they respond like this… then I could…" Fascinating, but costs exploded. A single problem required dozens of API calls. The paper's "Future Work" section mentions cost in a one-liner caveat; on a production engineer's AWS bill, it's the first line of a crisis.
Self-Refine and Reflexion — Madaan et al., 2023, Shinn et al., 2023. If humans write and then revise, why not have models critique and improve their own output? Self-Refine proposed a generate→feedback→revise loop; Reflexion introduced verbal reinforcement learning — recording failure experiences in natural language and using them in subsequent attempts. Interesting approaches, but with a fundamental limitation: the quality of feedback is bounded by the model's own ability. Same problem as having a struggling student grade their own exam. (This problem resurfaces in Anthropic's 3-agent architecture in 2026. It took three years to arrive at "someone else should do the grading.")
2.4 Andrew Ng's Four Agentic Design Patterns
In March 2024, Andrew Ng — Stanford professor, Coursera co-founder, former head of Google Brain and Baidu AI — took the stage at Sequoia AI Ascent. His four agentic design patterns synthesized the research into a practical framework.
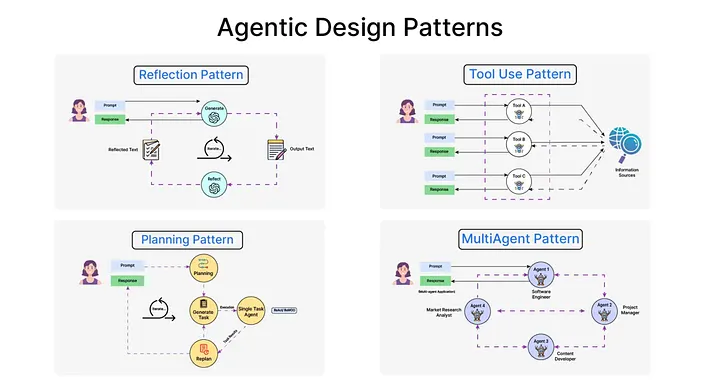
Reflection. The model critiques and revises its own output. Same principle as Self-Refine, but Ng positioned it as the most stable and predictable pattern. Generate code, then re-prompt: "review this code for bugs." Simple, yet surprisingly effective. The key: the same model reviews under a different persona — prompting "review from the perspective of a senior code reviewer" raises quality.
Tool Use. The production version of ReAct. The model calls external tools: web search, code execution, database queries, calculators. The crucial part is that the model decides when to use a tool. "I need the current exchange rate → call the exchange rate API → use the result in my calculation." This autonomous decision-making is what separates agents from chatbots.
Planning. Decomposing complex tasks into subtasks. "Build a website" becomes "1) requirements analysis 2) design 3) frontend 4) backend 5) testing 6) deployment." Powerful but the most brittle pattern. In Ng's words, "the devil is in the details" — the plan looks great, but execution often falls apart.
Multi-Agent Collaboration. Specialized agents take on different roles and collaborate. A coder agent + reviewer agent + tester agent, each working in their domain, exchanging results. The most embryonic pattern as of 2024, and the one with the most potential.
Ng's key finding: "Wrapping GPT-3.5 in an agentic workflow outperforms GPT-4 zero-shot on certain benchmarks." Without upgrading the model, changing the pattern around the model yields a performance leap. This was the apex of prompt engineering. It was also a hint that "the system outside the model matters." But in early 2024, nobody had followed that implication to its conclusion.
These patterns were further systematized in December of that year in Anthropic's "Building Effective Agents." Anthropic drew a distinction: workflows are pipelines with predetermined flows (e.g., "generate code → review → test" in sequence), while agents are autonomous processes where the LLM decides its next action. Neither is inherently superior. Anthropic's core message: "start as simply as possible." If a workflow suffices, don't reach for an agent. Even when you need an agent, combinations of basic patterns beat complex frameworks.
2.5 Hitting the Wall: The Limits of Prompts
So what happens when you put these patterns into production?
Picture this. A team spends three weeks polishing their coding agent's prompt. "Follow existing coding conventions," "write tests," "don't leave unused imports" — the instructions grow longer, and on simple tasks everything works fine. Then the project scales up, and things break. The agent starts ignoring existing utility functions and writing new ones from scratch. No matter how many times you write "reuse existing code" in the prompt, if the utility file isn't in the context window, the agent doesn't know it exists. The prompt was perfect, but the information the agent could see was incomplete. This isn't a prompt problem. It's a context problem.
Mitchell Hashimoto — creator of Vagrant and Terraform, co-founder of HashiCorp — called this "Blind Prompting." Writing prompts through trial and error, without rigorous measurement or testing. Let's be honest: that's exactly what most teams were doing. Tweak the prompt, eyeball the output, conclude "looks okay this time." Closer to alchemy than software engineering.
The problem was structural. Models are non-deterministic — the same input can produce different outputs each time. One report says adding "Please" improved performance; elsewhere, a single newline completely changes the output. CodeRabbit's 2025 analysis quantified the gap — AI co-authored code had 1.7x more major issues and 8x more performance inefficiencies.
The cause of death for the prompt era is clear. Rigor belonged not in the prompt text but in the context the prompt consumes. But before that realization landed, the industry sprinted toward one more dead end.
3. The AI Coding Tool Explosion and the Vibe Coding Hangover (2024-Early 2025)
3.1 Cursor: An Editor That "Understands Context"
If Copilot was autocomplete that only saw the current file, Cursor — which appeared in March 2023 — changed the question entirely. Four MIT students — Michael Truell, Sualeh Asif, Arvid Lunnemark, Aman Sanger — built this VS Code fork that fundamentally changed how AI understands code.
The key difference is context scope.
| Dimension | GitHub Copilot (Initial) | Cursor |
|---|---|---|
| Context Scope | Current file | Entire codebase |
| Indexing | None | RAG + AST-based semantic search |
| Reference System | None | @file, @codebase, @Docs, @PR, @commit |
| Edit Unit | Single line/block | Multi-file simultaneous editing (Composer) |
| Agent Mode | None (added 2025) | Agent Mode (terminal, filesystem access) |
| Model Selection | GPT family | GPT-4o, Claude 3.5 Sonnet, Gemini, etc. |
How Cursor understands a codebase is technically interesting. It recursively scans every file in the project, parses the AST (Abstract Syntax Tree) to identify key symbols — functions, classes, variables. It converts these symbols into vector embeddings for semantic search. File names are obfuscated and code chunks encrypted for security.
Early Cursor centered on chat-based code editing, but when Composer mode arrived in late 2024, the game changed. A three-panel layout (CMD+SHIFT+I) — progress, files, chat — where you type "add a user auth system" in natural language and it creates and modifies multiple files simultaneously. Beyond single-file edits: project-level changes. Cursor 2.0 in 2025 added mixture-of-experts models and reinforcement learning, with up to 8 agents running simultaneously in Git worktree isolation. Most tasks complete at ~250 tokens/second within 30 seconds.
Growth was the fastest in SaaS history. By 2025: $1.2B ARR, $29.3B valuation. Shopify, Vercel, Linear, and other major tech companies adopted it.
3.2 The Cambrian Explosion of AI Coding Tools
Cursor's success triggered a Cambrian explosion of AI coding tools.
Devin (Cognition Labs, 2024.03). Arrived with the title "first AI software engineer." Claimed to build and deploy apps end-to-end. The promo video showed it completing Upwork freelancer tasks, but YouTuber Carl Brown analyzed it and revealed key claims were overstated. Independent testing by Answer.AI researchers: 3 out of 20 tasks succeeded. Yet Cognition acquired Windsurf for $250M in July 2025 and reached a \$10.2B valuation by September. The gap between hype and substance was a defining feature of this era.
Windsurf (formerly Codeium). Started as an AI autocomplete extension, rebranded as a full AI IDE in late 2024. Its agentic assistant "Cascade" was the differentiator. Hit $82M ARR, but after the CEO was recruited to Google via a $2.4B licensing deal, it was acquired by Cognition.
Others: Void Editor (open-source Cursor alternative, privacy-focused), Augment Code ($250M funding, enterprise-focused), Sourcegraph Cody (code-search-based), Aider (terminal-based open-source pair programmer), Cline (VS Code extension, autonomous coding).
Between 2024 and 2025, AI agent framework GitHub repos (1,000+ stars) grew from 14 to 89 — a 535% increase. GitHub's 2024 survey found 92% of developers were using AI coding tools.
3.3 Vibe Coding: Prompt Engineering Taken to Its Logical Extreme
Amid this explosive growth, in February 2025 Karpathy posted on X:
"I just accepted all Cursor changes suggested to me… I barely even look at the diffs. The code has grown past my ability to fully read it."
He called it "vibe coding." Don't read the code. Copy-paste error messages. If it works, it works. The ultimate form of prompt engineering — or maybe its logical conclusion. If English produces code, why bother understanding the code?
Karpathy himself framed it as something for "weekend projects only." But the industry ignored that nuance. 25% of Y Combinator's Winter 2025 batch reported that 95% of their codebase was AI-generated. Collins Dictionary named it 2025's Word of the Year. The phenomenon was massive.
Then came the hangover. Faster than expected.
In September 2025, Fast Company ran "The Vibe Coding Hangover." The situation: an MVP built quickly with AI three months ago gets funded. Customers start arriving. Bug reports pile up. You open the code to fix things — and nobody understands it. The person who "wrote" it never read it either. CodeRabbit data showed the scale — 1.7x more major issues in AI-generated code, 45% security vulnerability rate (Veracode, 2025). What dazzled in demos was crumbling in production.
Simon Willison — Django web framework co-creator and prolific AI tools blogger — nailed it:
"If an LLM wrote all of the code, but you reviewed and tested it, that's not vibe coding."
The point was never who wrote the code. It was where the rigor lives.
Chad Fowler's "Relocating Rigor," introduced in Section 1, explains exactly this. Rigor doesn't disappear; it relocates. Fowler distills three principles from this pattern:
- Encode invariants as machine-enforced rules. Writing "this function only takes positive numbers" as a comment isn't rigor. Making the type system or an assertion verify it is.
- Failures should be immediate and loud. Silent errors come back as bigger problems later. Fail fast, fail loudly.
- The engineer's role changes. From typing code to specifying intent and verifying results.
Vibe coding violated all three. Invariants were implicit, evaluation was "if it runs it ships," and engineers gave up on verification. The logical extreme of prompt engineering, and a total loss of where rigor belongs. So where should rigor have moved?
4. The Context Engineering Era (Mid-2025 Onward)
4.1 Origin: One Week in June 2025
Back to June 2025. On June 19, Shopify CEO Tobi Lütke wrote on X:
"I much prefer the term 'context engineering' over 'prompt engineering'. It describes the core skill much better. The art of providing all the context for the task to be plausibly solvable by an LLM."
One tweet changed the industry's vocabulary.
A week later, Karpathy responded:
"Context engineering is the delicate art and science of filling the context window with just the right information for the next step."
Then he added: this is just one small piece of a "thick layer" of new software. "Thick layer." Remember that phrase. It returns eight months later under the name harness engineering.
This wasn't a simple terminological swap. The core question itself shifted. From "what should I say" to "what information should I provide."
4.2 LLM-as-OS: Karpathy's Operating System Metaphor
The framework that most clearly illuminates this shift is Karpathy's LLM-as-OS metaphor. Think of the LLM as the kernel of modern computing.
| Traditional OS Component | Role | LLM OS Equivalent | Note |
|---|---|---|---|
| Kernel | System resource management | LLM inference engine | Central to problem-solving |
| RAM | Working memory | Context window | Managed in token units |
| File System | Persistent storage | RAG / Vector DB | Retrieve and inject only what's needed |
| System Calls | Hardware control | Tool Call / API | Interaction with the outside world |
| Process Management | Multitasking | Multi-agent orchestration | Agent collaboration and isolation |
This metaphor matters because it clarifies the prompt's place: a prompt is just a single command typed into the OS. What actually determines performance is what you load into RAM (the context window). No matter how precisely you craft an ls command, it's useless if the file you need is on an unmounted disk.
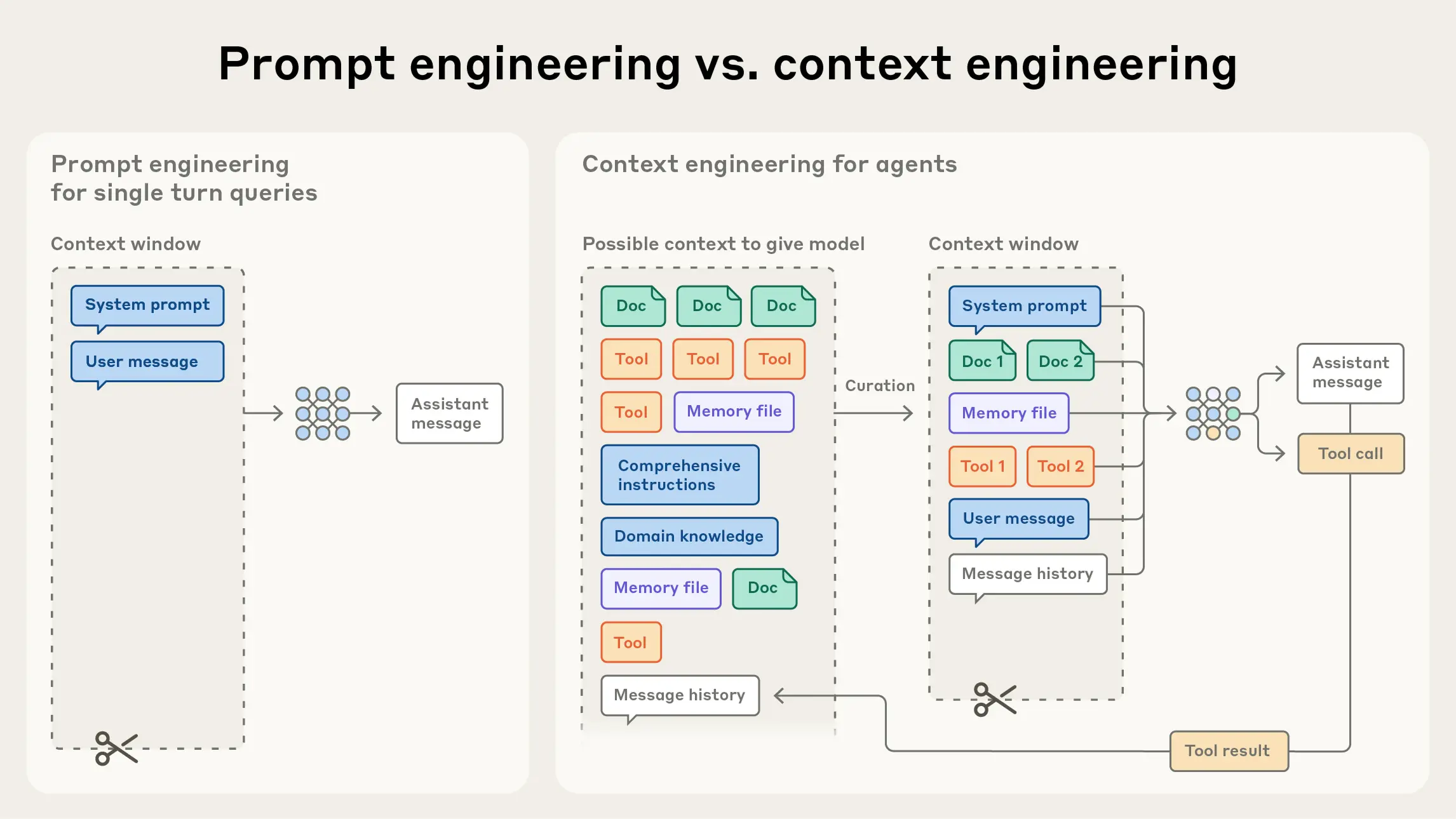
Anthropic formalized this in September 2025 with "Effective Context Engineering for AI Agents," calling it "the natural evolution of prompt engineering." The technique of optimizing the blend of five elements entering the context window: system prompt, user input, conversation history, tool results, and retrieved knowledge. The moment rigor moved from prompts to context.
4.3 Core Principles: Where Rigor Landed
Context engineering isn't "stuff more information in." If it were, it would be called "context stuffing." And early on, plenty of teams made exactly that mistake. Dump 10 documents from the RAG pipeline into the context wholesale. When tokens run out, expand the window. When it still doesn't work, blame the model.
Google ADK's design philosophy makes the problem with this approach clear: context is a "compiled view over a richer stateful system," not a raw data dump. Load your entire database into RAM and the OS slows to a crawl.
Anthropic's Four Strategies: Write / Select / Compress / Isolate
Anthropic's guide classifies context curation into four strategies. Say you're building a customer support agent. Here's how each strategy works:
- Write: Craft the system prompt in a clear, structured format: "You are a customer support agent. Refund policy is 30 days. For technical issues, create a ticket." The key isn't "what to say" but "how to structure it."
- Select: When a customer says "cancel my order," pull only the cancellation/refund docs into the context — not the entire FAQ. To prevent the "Lost-in-the-Middle" problem — where accuracy on information buried in the middle of long contexts drops sharply, just like forgetting the middle chapters of a long book — optimize for signal-to-noise ratio over volume.
- Compress: After a 20-turn conversation, summarize the first 15 turns into "Customer requested refund for Product X, receipt verified, asking about shipping costs." Anthropic reports well-designed compression maintains 80%+ information retention while significantly reducing token usage.
- Isolate: When a customer reports a technical issue, delegate to a diagnostic sub-agent separately. This keeps log analysis data from flooding the main conversation context.
Google ADK's Context Stack Architecture
Google ADK implemented these principles as a concrete architecture. Three core design principles:
- Separate storage from presentation. Think of it like a database: distinguish between the raw data (tables) and what you show on screen (views). The agent's complete conversation history, user information, and past tool results are stored as-is in the Session. But the tokens actually sent to the model API each turn are a "Working Context" — assembled by selecting only what's needed from the source. The original stays untouched; every read generates a fresh, optimized view.
- Explicit transformation pipeline. This "view building" can't be ad hoc. Named stages execute in a defined order: "inject system prompt → select relevant history → summarize tool results → check token budget." Not arbitrary string concatenation, but a reproducible pipeline for assembling context.
- Default scoping. When an agent delegates to a sub-agent, it doesn't pass the entire conversation. A sub-agent tasked with "modify this file" gets only that file and its relevant context. The context-window version of least privilege.
Building on these principles, Google ADK divides the context window into two regions:
- Stable Prefix: System prompt, agent identity, tool definitions, long-term summaries — things that change rarely, placed at the front.
- Variable Suffix: Latest user input, new tool outputs — things that change often, placed at the back.
Why does the order matter? Because of the KV-cache.
KV-cache: The Production Metric That Matters
Listen to the Manus team. They rewrote their agent framework four times. Four. The first version focused on prompt optimization; the second revamped agent architecture; the third redesigned the tool system. Only on the fourth attempt did they realize the real bottleneck was none of those — it was context management.
The metric they called "the single most important metric" for production agents was KV-cache hit rate.
Here's how KV-cache works. When you send a prompt to an LLM API, the model computes attention Keys and Values for each token. This computation is expensive. But if the prefix of the current request matches the previous request, that portion can reuse cached results — no recomputation needed. On Claude Sonnet, a cache hit reduces cost by 10x. The difference between an agent re-computing the system prompt across 30 turns versus leveraging the cache is enormous.

The crucial point: if even one token in the context prefix changes, the entire downstream cache is invalidated. That's why Google ADK says to put the "stable prefix" up front. In production, the stability of your prompt matters far more than its "quality." Ironic — we spent two years polishing prompts, and what actually matters in production is not touching them.
The Manus team went further, articulating five production principles:
- KV-cache optimization and prefix stability come first. Exactly as described above. Keep system prompts and tool definitions as fixed as possible.
- Don't swap tool lists mid-run. If an agent dynamically adds or removes tools during execution, tool definitions in the prefix break the cache. Instead, toggle tools between active/inactive states.
- Controlled diversity. If the agent repeats the same action for the same input, it can loop. Vary response format or phrasing slightly (e.g., shuffle JSON key order, rephrase with synonyms) to nudge the model toward new attempts — without compromising prefix stability.
- Production-first approach. Improving via context engineering iterates far faster than fine-tuning models from scratch. Ship improvements in hours, not weeks.
- The harness survives model swaps. Design the context management system to be model-agnostic. Swap Claude for GPT, GPT for Gemini — the harness should keep working.
HumanLayer's 12-Factor Agents organizes production agent principles in the same spirit, inspired by Heroku's 12-Factor Apps. The three most relevant to context engineering:
- Acknowledge that the context window has limits. "Past 40% full, you're in the dumb zone" — an empirical rule that instruction-following ability drops sharply once the context is over 40% utilized. The exact opposite of the intuition that more information is better.
- Use structured output over natural language. Inter-agent communication and tool results should use structured formats like JSON, not free-form text, to reduce parsing errors.
- Design human-in-the-loop from the start. Not "we'll add approval later" — architect intervention points into the system from day one.
4.4 Agentic Infrastructure
MCP: The Emerging Standard for Tool Integration
Let's start with the most foundational piece of context engineering infrastructure: MCP (Model Context Protocol). This open protocol, announced by Anthropic in November 2024, standardizes how LLMs communicate with external tools and data sources.
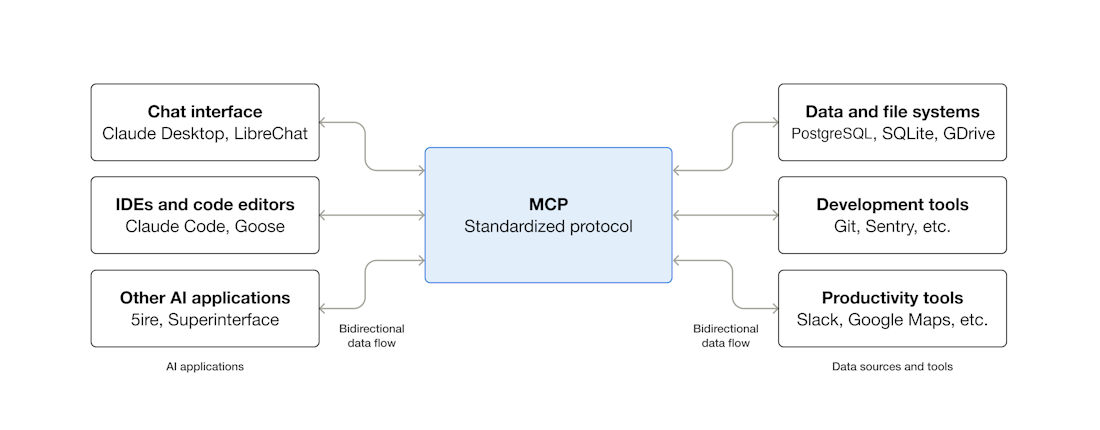
Before MCP, every tool had its own integration method. Slack API, GitHub API, databases, file systems — each tool the agent needed to access required custom integration code. Like the pre-USB era, when printers, keyboards, and mice each used different ports. MCP is the USB. Build an MCP server on the tool side once, and every AI client that supports MCP (Claude, ChatGPT, Cursor, VS Code, etc.) connects the same way.
Adoption was swift. In March 2025, OpenAI integrated MCP into its Agents SDK and ChatGPT. In April, Google DeepMind announced Gemini support. By December, Anthropic donated MCP to the Linux Foundation's Agentic AI Foundation, with Anthropic, OpenAI, Google, and Microsoft joining the governance. Within a year: 97M+ monthly SDK downloads, over 10,000 community servers — an industry standard.
MCP matters for context engineering because tool results are a core component of the context window. Standardized tool connections mean predictable result formats, which means more stable context composition. For reference, Google announced A2A (Agent-to-Agent Protocol) in April 2025 to standardize inter-agent communication as well. If MCP is the vertical axis of "agent ↔ tool," A2A is the horizontal axis of "agent ↔ agent."
Decomposition and Collaboration: Skills, Sub-agents, Swarms
As agents grew more complex, the pattern of composing small, specialized units emerged over "one giant agent."
Skills are reusable capability units an agent can perform. Where a tool is a single function like "call search API," a skill encapsulates a workflow: "search relevant documents, summarize them, present to the user." If tools are functions, skills are modules composed of multiple functions. A key property here is lazy loading. An agent might have dozens of skills, but pre-loading every skill's full definition into the context wastes tokens. Instead, put just the skill catalog (names and one-line descriptions) in the stable prefix. When the agent determines it needs a specific skill, load its full definition into the variable suffix on demand. The prefix (skill catalog) stays fixed, so the KV-cache remains intact; detailed definitions are added flexibly at the end, like tool results. Google ADK's Stable Prefix / Variable Suffix pattern at work again.
Sub-agents are subordinate agents to which a main agent delegates specific tasks. They're also the implementation of the "Isolate" strategy covered earlier. When a coding agent gets a debugging request, it hands the relevant file and error log to a debugging sub-agent. The main agent's context window stays clean.
Swarms are an orchestration pattern proposed in OpenAI's experimental framework released in October 2024. The core idea: routines and handoffs. No central orchestrator — agents autonomously hand work to each other. In customer support: a general agent starts the conversation, hands off to a refund specialist when a refund comes up, hands off again to a tech support agent for technical issues. This pattern later evolved into the OpenAI Agents SDK for production use.
Context Hub: Curing the Agent's Amnesia
Ask a coding agent to "implement payments with the Stripe API." It'll use the Stripe API it learned during training. Problem: that API might be six months out of date. Endpoints changed, new required parameters added. The code compiles but throws 404s at runtime. Karpathy compared this to anterograde amnesia — LLMs can't accumulate new information after training and operate each conversation solely on what they knew at training time.
Andrew Ng's Context Hub tackles this head-on. Before generating code, the agent runs a CLI command like chub get stripe --lang python to fetch the latest API documentation in real-time and inject it into context. Three core design principles:
- Curated documentation. No raw web search results. Each API has human-verified docs to eliminate noise. Started with 68 API docs and the community keeps growing.
- Stack-specific. The
--lang pyor--lang jsflag fetches docs matching the agent's language. Reduces token waste. - Annotation persistence. Notes the agent attaches to docs survive across sessions. "This endpoint has tight rate limits — use batch processing" carries over to the next session.
Think of it as the practical evolution of RAG. Where RAG "retrieves related docs and injects them," Context Hub "systematically manages and injects verified, up-to-date docs."
Memory: Beyond the Session
The context window is "working memory." But for agents to retain knowledge across sessions, a separate memory system is needed. The "Agent Drift" mentioned earlier is exactly this problem — LLMs operate on short-term memory alone each conversation.
The solution is external memory: file-based memory (CLAUDE.md, project notes), vector DBs (semantic similarity search), structured memory (JSON state passed between sessions). Both Claude and ChatGPT have introduced cross-conversation memory features. Anthropic's approach uses "context compaction" — progressively summarizing older conversations and injecting them into new context. In practice, this becomes a multi-stage compression pipeline — from the cheapest method (dropping old messages entirely) to selectively compressing individual tool results, to full summarization — managing the cost/information-loss tradeoff in stages.
4.5 Still Not Enough — The Context Wall
Context engineering was real progress. No question. But teams running agents in production soon hit a wall.
First, the single-turn limitation. Most context engineering techniques focus on "what to put in this API call." But agents aren't single-turn. They make dozens of chained decisions, execute tools, interpret results. If at turn 15 you need a tool result from turn 3 that's already been compressed away? If you composed the context perfectly but the loop consuming it is poorly designed? That's not a context problem — it's a system problem.
Second, no error recovery. A tool call fails. The model hallucinates. Costs spike. No matter how well you compose context, handling runtime exceptions requires separate mechanisms. Production agents need cost-aware error recovery (try the free option first, then cheap, then expensive), diminishing-returns detection (stop the loop if it keeps repeating the same mistake), and circuit breakers (automatically halt when consecutive failures are detected). These are beyond the scope of context engineering.
Third, security. If an agent processes external input while also accessing sensitive data and modifying state, a single prompt injection can exfiltrate company data. Simon Willison called this the "Lethal Trifecta," covered in detail in Section 5.4. Context engineering addresses "what to put in" but not "what to prevent."
The cause of death for the context era: even perfect context fails when the system consuming it is poorly designed. Context was a necessary condition, not a sufficient one. Time for rigor to move again.
5. The Harness Engineering Era (2026 Onward)
5.1 Origin: The Simultaneous Discovery of February 2026
In February 2026, Mitchell Hashimoto published "My AI Adoption Journey," documenting his path from AI skepticism to real results. The conclusion he reached:
Every time the agent makes a mistake, change the system so that mistake structurally cannot recur.
Not fixing the prompt. Changing the system around the agent — rules, tools, constraints, feedback loops. The moment the term "harness engineering" was born.
What happened next was remarkable. Within two weeks, OpenAI, Martin Fowler/Birgitta Böckeler (ThoughtWorks principal tech consultant), and Ethan Mollick (Wharton professor) independently published the same conclusion. No coordination. Everyone had been hitting the same wall. In the history of science, this is called "multiple discovery." The idea's time had come.
Fowler/Böckeler provided the key formula:
Agent = Model + Harness
The harness is "everything in the agent minus the model." Philipp Schmid — Hugging Face tech lead — extended the OS metaphor: the model is the CPU (compute power); the harness is the operating system (context curation, tool management, permission control, error recovery). Mollick used a horse metaphor: "The harness connects the horse's power to the cart or the plow." No matter how powerful the horse, without reins, saddle, and bridle, you can't plow a field.
Simon Willison's agent definition reads in this same context: "An agent is an LLM that runs tools in a loop to achieve a goal." The key word is "loop." And the harness is what controls the loop.
5.2 Anatomy of the Harness: Four Quadrants
"Harness" sounds grand, but it's ultimately a collection of mechanisms that catch and correct agent mistakes. Fowler/Böckeler organized it cleanly in a 2x2 framework.
| Feedforward (Pre-guidance) | Feedback (Post-correction) | |
|---|---|---|
| Deterministic | Guides: AGENTS.md, .cursorrules, coding conventions |
Computational: Compilers, type checkers, linters |
| Non-deterministic | System prompts/instructions: Role definitions, behavioral constraints, few-shot examples | Inferential: LLM-as-judge, semantic code review |
Let's look at what failures each quadrant catches.
Top-left — Guides (Deterministic Feedforward). Steer the agent away from bad directions before it starts. Put "use Vanilla JS, not React" in an AGENTS.md file, and the agent references it during code generation. Cursor's .cursorrules file is squarely in this quadrant — define project-specific rules like "this project uses Tailwind CSS" or "always declare types explicitly." Near-zero cost. But no enforcement — the agent can ignore it.
Top-right — Computational (Deterministic Feedback). Catches mistakes mechanically, even if guides are ignored. Compiler errors, linter warnings, type checkers, static analysis. When the agent writes bad code, it gets the compile error and auto-corrects. The quadrant the OpenAI Codex team emphasized most — custom linters enforce architectural rules in place of human reviewers.
Bottom-left — System Prompts (Non-deterministic Feedforward). Handles nuance that deterministic rules can't capture. "Be polite to users," "ask for confirmation when uncertain," "always get approval for security-sensitive operations." More guidelines than rules.
Bottom-right — Inferential (Non-deterministic Feedback). Catches "code that compiles but is semantically wrong." Another LLM reviews the code or evaluates output quality. Anthropic's Evaluator agent lives in this quadrant.
Production harnesses layer all four quadrants. Defense in depth. As Section 4's 12-Factor Agents put it: "Most 'AI agents' that succeed in production aren't magical autonomous beings — they're well-designed traditional software with LLM capabilities inserted at key points."
5.3 In Practice: Three Case Studies
Enough theory. How does harness engineering work in the real world?
Anthropic's 3-Agent Architecture. As the Anthropic team experimented with long-running agents, one problem kept resurfacing. Tell an agent "build a web app," and 30 minutes later something appears. It runs. But buttons overlap, APIs return wrong data, and the agent reports "Done!" Why? In March 2026, "Harness Design for Long-Running Application Development" revealed a finding that was stunningly simple: agents cannot accurately evaluate their own work. Same reason students shouldn't grade their own exams.
So, inspired by GANs (Generative Adversarial Networks — where a generator and discriminator compete to improve quality), they split the agent into three. Separate the maker from the judge.
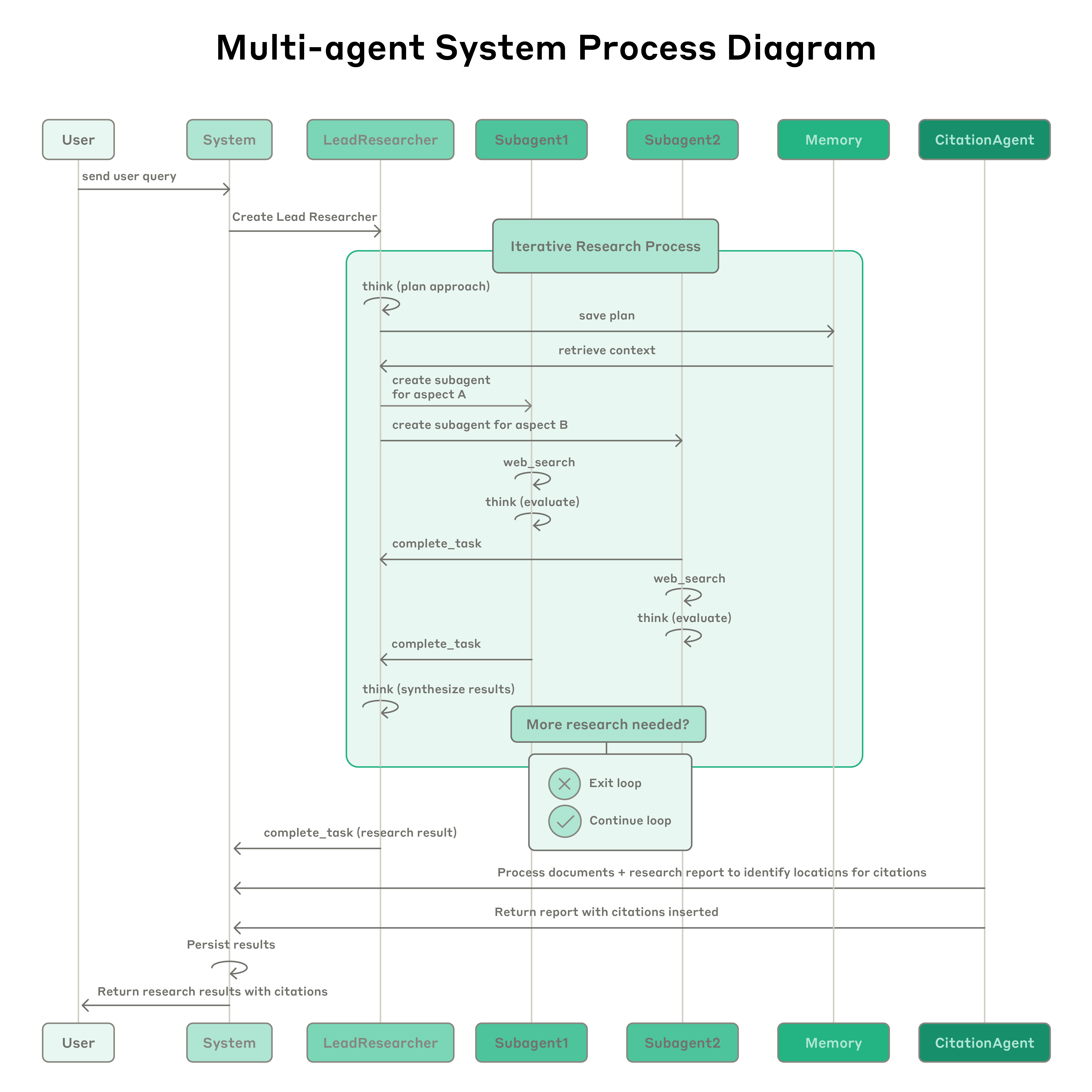
- Planner: Expands a simple prompt into a detailed product spec. Focuses on ambitious scope and high-level design, not technical details. A key finding: overly specific technical instructions cause cascading errors.
- Generator: Implements one feature at a time. React, Vite, FastAPI, SQLite stack. Self-evaluates each sprint, then hands off to QA. Working in sprints means periodically resetting context.
- Evaluator: Runs E2E tests via Playwright (a browser automation framework). Grades UI functionality, API endpoints, and database state against criteria for product depth, functionality, visual design, and code quality. Below threshold? Back to the Generator with specific feedback.
Cost? A solo run takes 20 minutes and $9. The full harness: 6 hours and $200. A 22x increase. But the quality of the output is incomparable. This isn't just a cost increase — it's a relocation of cost. From humans fixing things after the fact to the system verifying beforehand.
The OpenAI Codex Experiment. This one deserves a closer look. Let's start with the scale that OpenAI revealed in "Harness Engineering." Five months. An engineering team that grew from 3 to 7. Lines of manually written code: zero. Generated code: approximately 1 million lines. Around 1,500 PRs. Roughly 10x faster than manual.
Wait. Zero manual code? Seven engineers wrote not a single line of code for five months?
Correct. And that's the point. The humans in the room weren't writing code. They were designing the environment in which code could be reliably generated. What they did boils down to three things:
- Systematize repository knowledge. The team's first discovery: the agent kept making the same mistakes. Why? Architecture decisions agreed upon in Slack, design principles that lived only in a senior dev's head — invisible to the agent. So they documented every principle and decision as markdown and code within the repo. "Knowledge invisible to the agent doesn't exist."
- Mechanical enforcement. Documentation alone wasn't enough. "Please use this pattern" written in a doc gets ignored. So they built custom linters and structural tests that enforce architectural rules. The agent fixes its own code to pass the linter. Human reviewers replaced by mechanical enforcement.
- Progressive disclosure. Initially, the team tried injecting massive documentation all at once. Result: the agent got lost. Dump thousands of pages and the information you actually need drowns in noise. The solution was to give the agent a map and let it find what it needs. "Give Codex a map, not a 1,000-page manual."

These three distill to one sentence: When the agent makes a mistake, don't blame the agent — improve the harness. The exact same conclusion as Hashimoto.
The Ralph Pattern: Agents That Run Overnight. The third case study comes not from a company but from the community. Where Anthropic and OpenAI showed "how to design a harness," Ralph shows "how to run an agent autonomously on top of a harness." Proposed by Geoffrey Huntley, the core is simple: define a PRD (Product Requirements Document), then run an AI coding tool (Claude Code, Amp, etc.) in a loop until every PRD item is complete.
The clever part is context management. Every iteration, the agent restarts with a clean context. This eliminates context window pollution and bloat at the source. State is maintained via git history, progress.txt, and prd.json. The agent's memory lives not in the context window but in the file system.
The more programmatically verifiable the checks (compile, test, lint), the more autonomously Ralph operates. In Fowler's 2x2, the "Computational Feedback (compilers, linters)" quadrant is the linchpin. Within two months it crossed 12,000 GitHub stars, becoming the most direct embodiment of harness engineering's vision: "the agent codes while you sleep."
5.4 Security: The Lethal Trifecta and the Rule of Two
In harness engineering, security isn't optional — it's structural. Willison's "Lethal Trifecta" is the core framework.
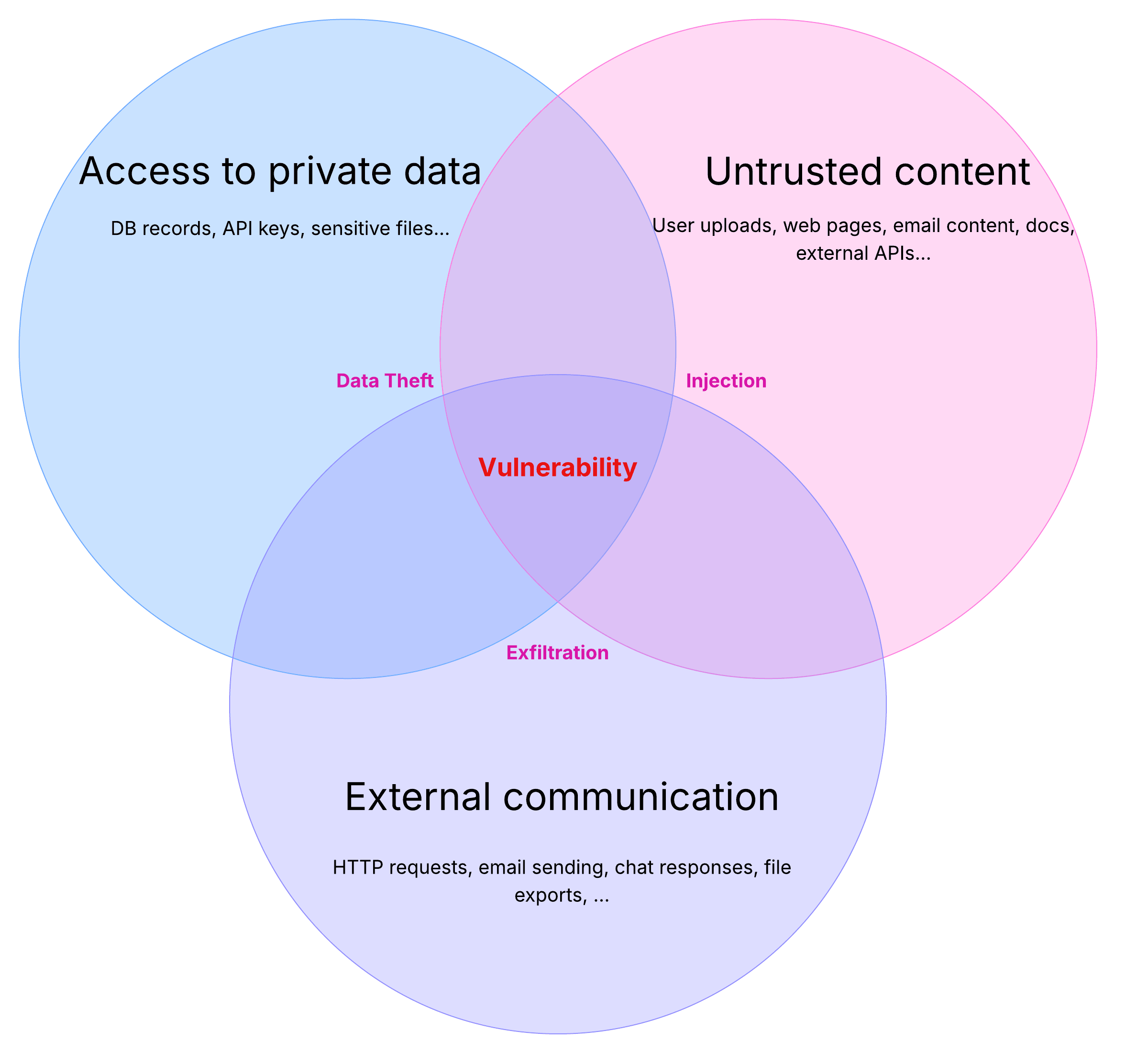
When an agent simultaneously has all three of the following, a security incident isn't a matter of if but when:
- Processes untrusted input (external web, email, user input)
- Accesses sensitive systems/data (PII, internal APIs, databases)
- Can modify state (send emails, delete files, make API calls)
Meta AI's "Rule of Two" turns this into an actionable rule, borrowed from Chromium browser's security policy. Let the agent have at most two of these three simultaneously. If all three are needed, require human-in-the-loop approval.
Concrete examples:
- Read external data (1) + process sensitive info (2) → state modification (3) blocked. Requires human approval.
- Read external data (1) + modify state (3) → sensitive data access (2) blocked. Sandbox only.
- Process sensitive info (2) + modify state (3) → external input (1) blocked. Internal data only.
These guardrails aren't feature constraints — they're prerequisites for trustworthiness. An agent without a harness dazzles in demos but is a ticking time bomb in production.
6. Autopsy Report Across Three Eras
6.1 Comparative Overview
| Dimension | Prompt Engineering | Context Engineering | Harness Engineering |
|---|---|---|---|
| Era | 2022-2024 | 2025 | 2026 onward |
| Core Question | "What should I say?" | "What info should I provide?" | "What system should I build?" |
| Metaphor | Writing an email | Managing an inbox | Designing the email system |
| OS Analogy | A single command | RAM management | The entire operating system |
| Key Metric | Response quality (subjective) | KV-cache hit rate | Task completion rate, cost/task |
| Failure Mode | Blind prompting, non-determinism | Context pollution, Lost-in-the-Middle | Orchestration bugs, security incidents |
| Where Rigor Lives | Prompt text | Context window composition | Entire system architecture |
| Representative Tools | ChatGPT, early Copilot | Cursor Composer, RAG pipelines | Claude Code, Copilot Coding Agent |
| Required Skills | Language sense + domain knowledge | Information architecture | System design + security |
6.2 Lessons: The Migration Path of Rigor
Read this table vertically and you see a technology history. Read it horizontally and you see each era's limitations. But the most important pattern runs along the diagonal — each era doesn't replace its predecessor; it subsumes it.
Harness engineering contains context engineering, which contains prompt engineering. A good harness still requires good context, and good context still requires good prompts. You occasionally see tweets declaring "prompt engineering is dead." Wrong. Prompt engineering became a submodule of harness engineering. It didn't die — it got promoted, absorbed into a larger system.
One more point emphasized by Fowler/Böckeler: the harness should be rippable. As models improve, some of the harness's "smart" logic becomes unnecessary. When Claude 5.0 ships, half the error-recovery logic built for Claude 4.5 may become dead weight. The art of harness design lies as much in "what to build" as in "what to make easy to remove." Over-engineering today shackles you to tomorrow's model update.
6.3 Outlook: Rigor's Next Stop
If this pattern continues — and the last four years are any evidence — rigor will move again. Several directions are already visible.
Guardian Agents. Imagine an agent about to deploy code, and another agent intervening in real-time: "Hold on — this change falls outside regulatory compliance." Anthropic's Evaluator is its primitive form. It's only a matter of time before this crystallizes into an independent infrastructure layer. Rigor migrating from "execution" to "supervision."
Evaluation Engineering. The phrase "behavior beats benchmarks" has emerged. Not MMLU scores, but the rate at which agents complete real-world tasks. How gracefully they recover from failure. Especially difficult: non-verifiable rewards. A machine can judge whether code compiles, but "does this prose read well?" or "is this design beautiful?" — how do you score that? LLM-as-judge (one LLM evaluating another's output) is one emerging answer, but evaluator bias remains an open problem. "How to evaluate" is becoming an engineering discipline in its own right. Full disclosure: this is exactly the pattern used to write this post — an evaluation agent scored against 8 criteria, triggering a rewrite loop whenever a section fell below 80. (You didn't think a post this long in 2026 was written without AI, did you?)
Knowledge Engines. Current context engineering deals with "what to put in this turn." But real software projects contain information more important than the code itself. "Why did we choose this architecture?" "We tried this approach six months ago — why did we roll it back?" "What was the original design intent of this module?" Knowledge that doesn't survive in code but is critical to understanding the project.
Knowledge engines aim to solve this. Beyond vector search (finding code similar to the current code), they combine code graphs (function call relationships, dependency structures), commit history (why and how code evolved), and memory systems (lessons learned from past sessions). If Andrew Ng's Context Hub solved one axis — "latest API docs" — knowledge engines aim to make the agent understand the project's entire history and design intent. Not "modify this function" but "understand why this function looks the way it does, then modify it." A different game entirely.
Willison is already systematizing these patterns under the name "Agentic Engineering Patterns." Scattered practices crystallizing into an engineering discipline. Just as "prompt engineering" became a household term in 2023, "harness engineering" will be by 2027 or so. And by then, someone will show up with yet another new name. That's this industry.
In 2023, Karpathy said "the hottest new programming language is English." Three years later, the hottest new engineering deals with something other than English — context window structure, agent loop state machines, security guardrail layering. English still matters. But it's now a component of the system, not the system itself.
Chad Fowler's words serve as this post's conclusion. Rigor doesn't disappear; it migrates toward feedback and closer to reality. From the person writing code, to the person curating context, to the person designing the environment in which agents operate. The role hasn't changed — the abstraction level has risen.
The question isn't whether rigor relocates. That's confirmed. The question is how quickly we notice the next time it moves.
References
- Mitchell Hashimoto, "My AI Adoption Journey", 2026.02
- Andrej Karpathy, "Software in the Age of AI" (YC Keynote), 2025.06
- Andrej Karpathy, "Context Engineering" (X post), 2025.06.25
- Andrew Ng, "4 Agentic Design Patterns" (Sequoia AI Ascent + The Batch), 2024.03
- Simon Willison, "Agentic Engineering Patterns", 2026.02
- Simon Willison, "The Lethal Trifecta for AI Agents", 2025.06
- Martin Fowler (Birgitta Böckeler), "Harness Engineering", 2026.02
- Philipp Schmid, "The Importance of Agent Harness in 2026", 2026.01
- Ethan Mollick, "Models, Apps, and Harnesses", 2026.02
- Tobi Lütke, "Context Engineering" (X post), 2025.06.19
- Chad Fowler, "Relocating Rigor", 2026.01
- Anthropic, "Building Effective Agents", 2024.12
- Anthropic, "Effective Context Engineering for AI Agents", 2025.09
- Anthropic, "Harness Design for Long-Running Application Development", 2026.03
- OpenAI, "Harness Engineering: Leveraging Codex in an Agent-First World", 2026.02
- Google, "Architecting Efficient Context-Aware Multi-Agent Framework", 2025.12
- Manus, "Context Engineering for AI Agents: Lessons from Building Manus", 2025
- HumanLayer, "12-Factor Agents", 2025
- Meta AI, "Agents Rule of Two", 2025
- Andrew Ng, "Context Hub", 2026.03
- Wei et al., "Chain-of-Thought Prompting Elicits Reasoning in LLMs", 2022
- Yao et al., "ReAct: Synergizing Reasoning and Acting in LLMs", 2022
- Yao et al., "Tree of Thoughts", 2023
- Madaan et al., "Self-Refine: Iterative Refinement with Self-Feedback", 2023
- Shinn et al., "Reflexion: Language Agents with Verbal Reinforcement Learning", 2023
- Epsilla, "The Third Evolution: From Prompt to Context to Harness Engineering", 2026
- CodeRabbit, "State of AI vs Human Code Generation Report", 2025
- Fast Company, "The Vibe Coding Hangover", 2025.09
- Collins Dictionary, "Word of the Year 2025: Vibe Coding", 2025
- Veracode, "State of Software Security 2025", 2025
- GitHub, "Octoverse 2024", 2024
- Cursor, "Series D Announcement", 2025.11
- Fortune, "Cursor at a Crossroads", 2026.03
- sshh, "How Cursor AI IDE Works", 2025
- Anthropic, "Model Context Protocol", 2024.11
- Google, "Announcing the Agent2Agent Protocol (A2A)", 2025.04
- OpenAI, "Swarm: Multi-Agent Orchestration Framework", 2024.10
- Geoffrey Huntley, "Ralph: Autonomous AI Agent Loop", 2026
Subscribe via RSS