Claude Code 내부 아키텍처 분석
Contents
Claude Code의 속살이 드러났습니다. npm Source Map 유출로 본 에이전틱 AI의 해부학.
Anthropic이 "오픈소스"라고 부르는 것과 실제로 오픈된 것 사이에는 4,600개 파일만큼의 간극이 있었습니다.
TL;DR
- npm source map 실수로 Claude Code의 비공개 코어 엔진(4,600+ 파일) 전체가 노출되었습니다
- 공식 "오픈소스"는 플러그인 껍데기(279개)뿐 — 핵심 엔진은 상용 비공개였습니다
- 내부에는 8겹 보안 레이어, 4단계 메시지 압축, 비용 인식 에러 복구 등 정교한 프로덕션 아키텍처가 있습니다
- 미출시 피처 플래그에서 음성 모드, 멀티 에이전트 Coordinator, 선제적 Kairos 모드 등 로드맵이 드러났습니다
- 에이전틱 AI 시스템의 실전 아키텍처를 들여다볼 수 있는 드문 기회입니다
1. 무슨 일이 있었나
2026년 3월 31일, 보안 연구자 Chaofan Shou가 X에 스크린샷 몇 장을 올렸습니다. Anthropic의 Claude Code 내부 소스코드 전체가 npm 패키지 안에 고스란히 들어 있었다는 내용이었습니다. Source map(.map) 파일은 빌드 과정에서 압축·난독화된 코드를 원본 소스코드로 역추적할 수 있게 해주는 디버깅용 매핑 파일입니다. 프로덕션 배포에서는 제거하는 게 상식인데, 그것이 그대로 남아 있었던 겁니다.
Reddit r/LocalLLaMA가 들끓었고, 커뮤니티는 몇 시간 만에 전체 코드베이스를 해부하기 시작했습니다.
의도적인 해킹이 아닙니다. 정교한 사회공학 공격도 아닙니다. 빌드 파이프라인에서 .map 파일을 프로덕션 패키지에서 제외하는 단계를 누락한, 단순한 빌드 설정 실수입니다. 하지만 그 .map 파일 안에는 내부 프롬프트 구조, 에이전트 오케스트레이션 로직, 툴 호출 패턴 — 사실상 Claude Code의 두뇌 전체가 담겨 있었습니다. Anthropic이 Claude Code를 얼마나 정교하게 설계했는지 — 혹은 얼마나 허술하게 배포했는지 — 가 동시에 드러나는 순간이었습니다. 경쟁사와 보안 연구자 모두에게 의도치 않은 선물이 된 셈입니다.
한 가지 짚고 넘어가야 할 게 있습니다. Anthropic은 Claude Code를 "오픈소스"라고 마케팅해왔습니다. 공식 GitHub 저장소가 있고, 누구나 볼 수 있습니다. 하지만 거기에 있는 건 뭘까요?
플러그인 시스템. Hook 예제. 설정 파일 템플릿. 11개의 예제 플러그인.
요리로 치면, 레스토랑 메뉴판과 테이블 세팅을 공개하고 "우리 주방은 오픈입니다"라고 말한 격입니다. 진짜 레시피, 조리법, 비밀 소스는 전부 뒤에 숨겨져 있었습니다. 이번에 npm source map을 통해 드러난 건 바로 그 주방 전체입니다 — TypeScript/React로 작성된 4,600개 이상의 소스 파일, 55개 이상의 디렉토리. 라이선스는 Apache 2.0이 아니라 Anthropic Commercial Terms of Service입니다. 진정한 오픈소스와는 거리가 있습니다.
이 글에서는 법적, 윤리적 논의는 제쳐두겠습니다. 대신 유출된 코드가 드러내는 기술적 아키텍처를 깊이 파고들어 봅니다. 솔직히 말씀드리면, 꽤 인상적입니다. 실수로 유출한 부분만 빼면요.
2. 전체 아키텍처: 생각보다 훨씬 큽니다
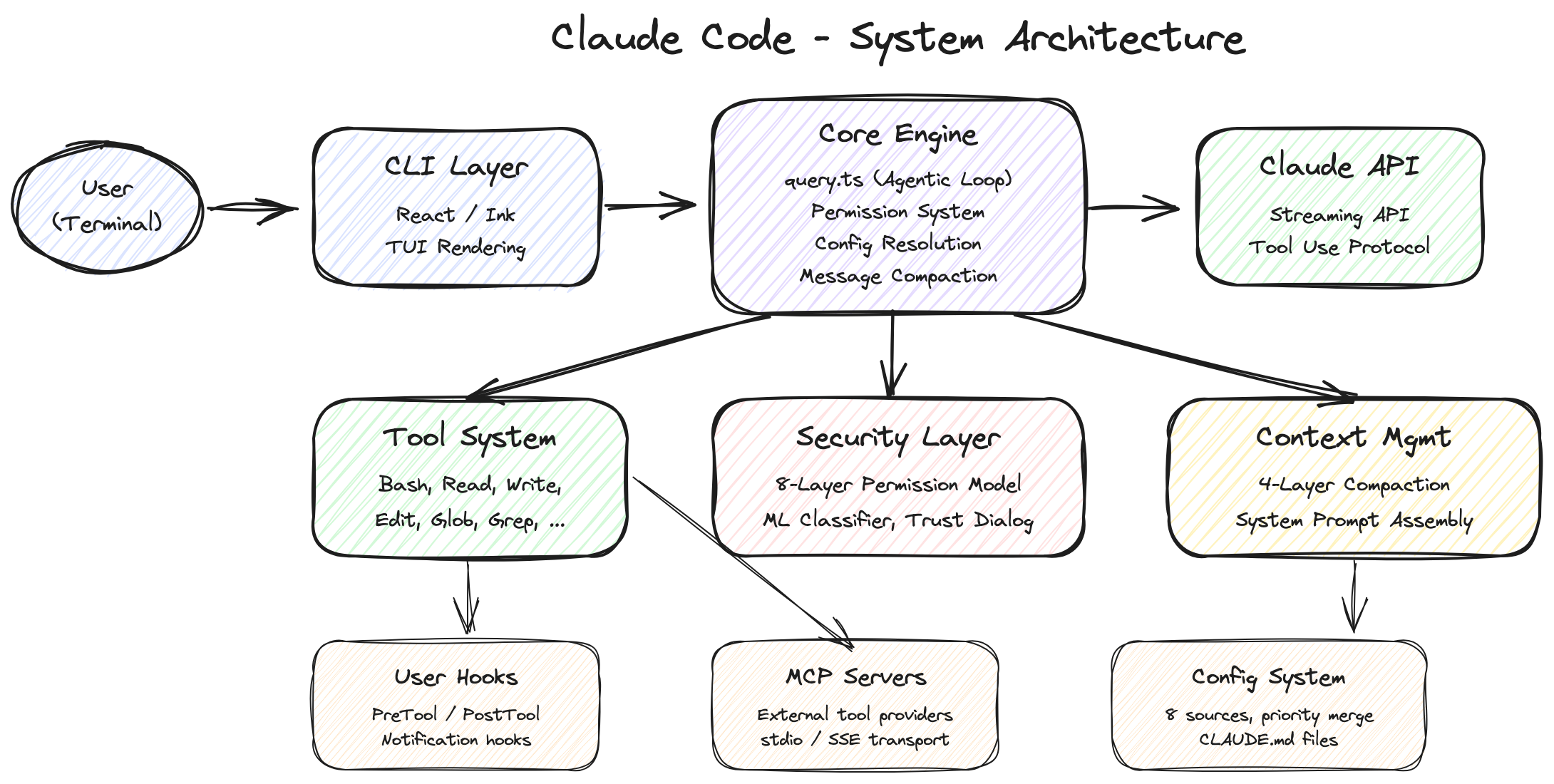
Claude Code를 처음 접하면 "API 래퍼 아닌가?"라고 생각하기 쉽습니다. 터미널에서 Claude에게 말 걸고, Claude가 코드를 고쳐주고, 끝. 심플해 보입니다.
유출된 코드를 열어보면 그 생각이 산산조각 납니다.
기술 스택
| 레이어 | 기술 | 왜 이 선택인가 |
|---|---|---|
| 런타임 | Bun | Node.js 대비 빠른 시작 시간과 네이티브 TypeScript 지원. 번들러의 feature() API로 빌드 시점에 불필요한 코드를 제거할 수 있습니다 (섹션 6.1에서 상세히 다룹니다) |
| 언어 | TypeScript (strict mode) | 4,600+ 파일 규모의 코드베이스에서 타입 안전성은 선택이 아닌 필수입니다 |
| UI | React 18 + Ink | 터미널에서 React 컴포넌트를 렌더링합니다. 권한 다이얼로그, 진행 표시줄, 멀티패널 레이아웃 등 복잡한 UI가 이 선택을 정당화합니다 |
| API 클라이언트 | @anthropic-ai/sdk |
Anthropic 공식 SDK |
| MCP 클라이언트 | @modelcontextprotocol/sdk |
LLM이 외부 도구·데이터 소스와 표준화된 방식으로 통신하기 위한 개방형 프로토콜(Model Context Protocol) |
| 피처 플래그 | GrowthBook | 서버 측 기능 제어 및 A/B 테스트. 보안 킬 스위치부터 미출시 기능 게이트까지 (섹션 6.2, 7) |
| 번들러 | Bun bundler | feature() 함수의 반환값에 따라 사용되지 않는 코드 분기를 빌드에서 완전히 제거하여 내부/외부 빌드를 분리합니다 |
터미널 앱에 React를 쓴다는 게 과하게 느껴질 수 있습니다. 하지만 코드를 보면 권한 다이얼로그(PermissionDialog.tsx), Worker 배지(WorkerBadge), 멀티패널 레이아웃, 실시간 스트리밍 UI 같은 복잡한 인터랙션이 이 선택을 이해하게 만듭니다. 터미널이지만 단순한 텍스트 출력이 아니라, 상당히 풍부한 UI를 제공하고 있습니다.
공식 오픈소스 vs 유출 코드: 숫자로 보는 괴리
공식 저장소 (anthropics/claude-code) |
유출 코드 | |
|---|---|---|
| 파일 수 | ~279개 (스크립트/설정 위주) | 4,600개+ (풀스택 엔진) |
| 핵심 엔진 | 미포함 | 포함 |
| 도구 구현체 | 미포함 | 전체 포함 (Bash, Read, Write, Edit…) |
| 에이전틱 루프 | 미포함 | 포함 (query.ts 1,729줄) |
| 권한 시스템 | 미포함 | 포함 (permissions.ts 52K) |
| API 통신 | 미포함 | 포함 (스트리밍, 캐싱, 폴백) |
| Bridge/원격 | 미포함 | 포함 (33+ 파일) |
| MCP 클라이언트 | 미포함 | 포함 (client.ts 119K) |
| 라이선스 | Anthropic Commercial ToS | 비공개 상용 코드 |
279개 vs 4,600개. "오픈소스"라는 단어의 정의에 대해 다시 한번 생각해 볼 필요가 있겠습니다.
3. 에이전틱 루프: 심장을 열어봅니다
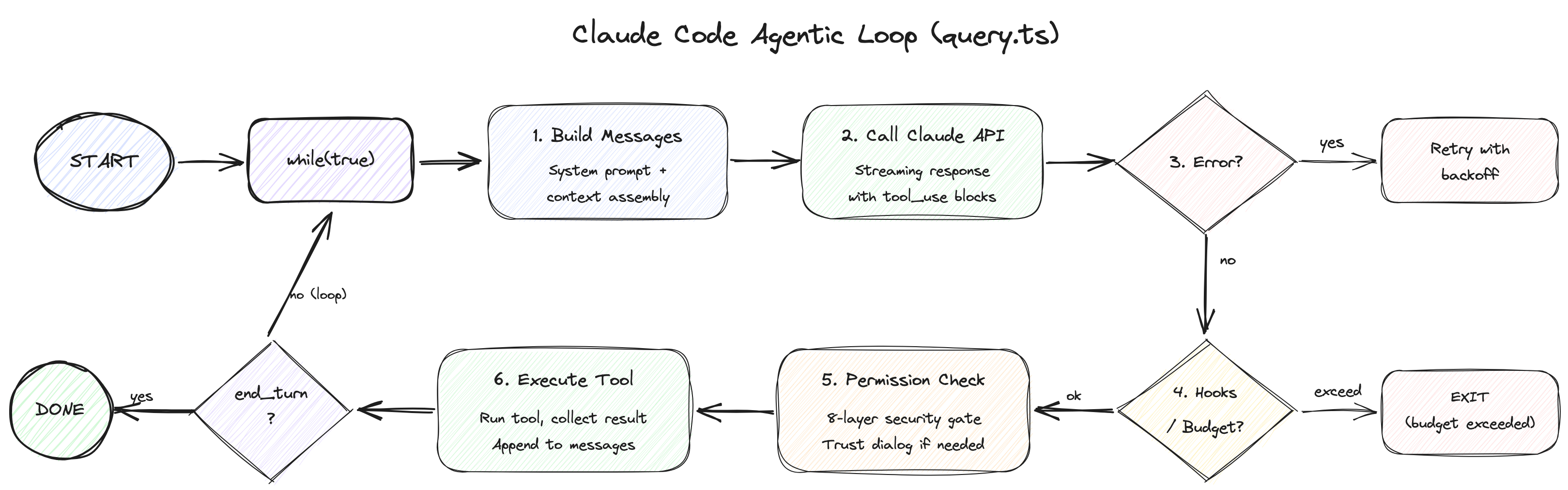
Claude Code의 심장은 query.ts입니다 — 1,729줄의 while(true) 루프입니다. "에이전틱 루프"라고 부르는 이것이 사용자 입력을 받아 도구를 실행하고, 결과를 다시 Claude에게 던지는 전체 사이클을 관장합니다.
3.1 Async Generator: 우아한 설계 선택
가장 먼저 눈에 띄는 건 함수 시그니처입니다.
export async function* query(
params: QueryParams,
): AsyncGenerator<
| StreamEvent
| RequestStartEvent
| Message
| TombstoneMessage
| ToolUseSummaryMessage,
Terminal // 반환값: 종료 이유
>
async function* — async generator입니다. 일반 함수가 값을 하나만 return하는 것과 달리, generator는 yield로 값을 여러 번 내보낼 수 있는 함수입니다. 여기에 async가 붙으면 비동기 작업(API 호출, 파일 읽기 등)을 await하면서 중간 결과를 하나씩 밀어줄 수 있습니다.
이게 왜 영리한 선택인지 설명하겠습니다. 이런 "이벤트를 연속으로 내보내는" 패턴을 구현하는 전통적인 방법은 두 가지입니다. 이벤트 이미터(EventEmitter)는 emitter.on('data', callback)처럼 이벤트 이름에 콜백 함수를 등록하는 방식입니다. Node.js 스트림이 대표적인 예입니다. 콜백 기반은 query(params, onEvent, onDone, onError)처럼 성공·실패·이벤트 각각에 별도의 함수를 넘기는 방식입니다. 두 방식 모두 이벤트 흐름, 종료 처리, 에러 처리가 서로 다른 채널로 흩어지기 때문에, 코드가 복잡해질수록 "이벤트는 받았는데 종료를 놓쳤다"거나 "에러 핸들러 등록을 깜빡했다" 같은 버그가 생기기 쉽습니다.
Async generator는 이 세 가지를 하나의 함수 안에 통합합니다. 소비자 쪽에서는 for await...of 루프로 이벤트를 하나씩 받다가, generator가 끝나면 return 값에서 종료 이유(Terminal)를 가져옵니다. 에러가 나면 generator 안에서 throw한 것이 소비자의 try-catch로 자연스럽게 전파됩니다. 별도의 에러 채널이나 콜백 등록이 필요 없습니다.
결과적으로 "스트리밍 이벤트 → 정상 종료 → 에러 전파"라는 세 가지 흐름을 하나의 함수 시그니처로 깔끔하게 표현합니다. 복잡한 상태 머신을 다뤄야 하는 에이전틱 루프에 특히 잘 맞는 패턴입니다.
3.2 불변 파라미터 + 가변 상태: Continue Site 패턴
루프는 두 종류의 데이터를 분리합니다.
불변 파라미터 — 루프 전체에서 변하지 않는 것들:
type QueryParams = {
messages: Message[]
systemPrompt: SystemPrompt
canUseTool: CanUseToolFn // 권한 검사 콜백
toolUseContext: ToolUseContext // 도구 실행 컨텍스트
taskBudget?: { total: number } // API task_budget (beta)
maxTurns?: number // 최대 턴 제한
fallbackModel?: string // 폴백 모델
querySource: QuerySource // 쿼리 출처 (REPL, agent 등)
// ...
}
가변 상태 — 매 이터레이션마다 갱신되는 것들:
type State = {
messages: Message[]
toolUseContext: ToolUseContext
autoCompactTracking: AutoCompactTrackingState | undefined
maxOutputTokensRecoveryCount: number
hasAttemptedReactiveCompact: boolean
maxOutputTokensOverride: number | undefined
pendingToolUseSummary: Promise<ToolUseSummaryMessage | null> | undefined
stopHookActive: boolean | undefined
turnCount: number
transition: Continue | undefined // 이전 이터레이션의 계속 사유
}
여기서 주목할 패턴은 "Continue Site"입니다. 루프 안에서 상태를 갱신하고 다음 이터레이션으로 넘어가는 코드 지점(site)을 가리키는 용어인데, 소스 코드 주석에서 직접 이렇게 설명하고 있습니다.
// Continue site는 9개의 개별 대입문 대신 `state = { ... }` 한 번으로 상태를 갱신합니다.
9개의 개별 필드를 하나씩 수정하는 대신, 전체 상태 객체를 한 번에 재할당합니다.
state = {
...state,
messages: newMessages,
turnCount: nextTurnCount,
transition: { reason: 'next_turn' }
}
이 패턴의 장점은 두 가지입니다. 첫째, 상태 전이가 원자적(atomic)입니다. "원자적"이란 "전부 성공하거나 전부 실패하거나" 둘 중 하나라는 뜻입니다. 만약 9개 필드를 한 줄씩 따로 수정한다면, 3번째 줄에서 에러가 나면 앞의 2개만 바뀌고 나머지 7개는 그대로인 반쪽짜리 상태가 됩니다. 객체를 통째로 재할당하면 이런 중간 상태가 원천적으로 불가능합니다. 둘째, transition 필드를 통해 왜 다음 턴으로 넘어갔는지를 기록합니다. 'next_turn'인지, 에러 복구 때문인지, 폴백 모델로 전환했는지가 명시되므로, 테스트에서 복구 경로가 제대로 작동했는지를 메시지 내용을 들여다보지 않고도 검증할 수 있습니다.
React의 setState — 상태를 직접 수정하지 않고 새 객체로 교체하는 — 철학이 백엔드 루프에까지 스며든 것으로, Anthropic 엔지니어들의 React 사랑이 엿보이는 부분입니다.
이 패턴이 중요한 이유는, 에이전틱 루프에서 상태 관리 버그가 곧 사용자 비용으로 이어지기 때문입니다. 상태가 꼬이면 불필요한 API 호출이 발생하고, 그건 곧 토큰 비용입니다. Cursor나 Windsurf 같은 경쟁 제품들도 비슷한 에이전틱 루프를 구현하고 있을 텐데, 이 수준의 상태 관리 엄밀성을 갖추고 있는지는 알 수 없습니다. 코드가 공개되지 않았으니까요.
3.3 턴당 6단계 파이프라인: 상세 워크스루
각 턴은 다음 6단계를 거칩니다. 소스 코드의 실제 라인 번호와 함께 살펴보겠습니다.
1단계: Pre-Request Compaction (lines 365-548)
API를 호출하기 전에 대화 히스토리를 정리합니다. 5개의 압축 메커니즘이 저렴한 것부터 순서대로 적용됩니다. 각 메커니즘의 상세한 작동 원리는 섹션 4에서 깊이 다루지만, 간략히 소개하면:
- Tool Result Budget — 도구 실행 결과의 크기를 제한합니다. 파일 읽기나 검색 결과가 수천 줄일 수 있는데, 이를 예산 내로 잘라냅니다.
- Snip Compact — 오래된 메시지를 통째로 잘라냅니다. 가장 저렴하지만 가장 과격합니다.
- Microcompact — 개별 도구 결과를 선택적으로 클리어합니다. 프롬프트 캐시를 고려해서 클리어 대상을 고릅니다.
- Context Collapse — 메시지 블록 단위로 단계적으로 축소합니다. 원본은 건드리지 않고 축소된 뷰를 생성합니다.
- Auto-Compact — 위 4개로도 부족할 때 전체 대화를 LLM으로 요약합니다. 가장 비싸지만 가장 효과적입니다.
코드로 보면 이렇습니다.
// 1. Tool Result Budget 적용 (lines 369-394)
messagesForQuery = await applyToolResultBudget(
messagesForQuery,
toolUseContext.contentReplacementState,
// 에이전트/REPL 소스만 교체 기록을 저장 (resume을 위해)
persistReplacements ? records => void recordContentReplacement(...) : undefined,
)
// 2. Snip Compact — 가장 저렴 (lines 401-410)
if (feature('HISTORY_SNIP')) {
const snipResult = snipModule!.snipCompactIfNeeded(messagesForQuery)
messagesForQuery = snipResult.messages
snipTokensFreed = snipResult.tokensFreed
}
// 3. Microcompact — 캐시 인식 도구 결과 클리어 (lines 413-426)
const microcompactResult = await deps.microcompact(messagesForQuery, toolUseContext, querySource)
messagesForQuery = microcompactResult.messages
// 4. Context Collapse — 단계적 축소 (lines 440-447)
if (feature('CONTEXT_COLLAPSE') && contextCollapse) {
const collapseResult = await contextCollapse.applyCollapsesIfNeeded(...)
messagesForQuery = collapseResult.messages
}
// 5. Auto-Compact — 임계값 초과 시 전체 요약 (lines 453-543)
const { compactionResult, consecutiveFailures } = await deps.autocompact(...)
이 순서가 중요합니다. Context Collapse가 Auto-Compact 앞에 오는 이유는 소스 코드 주석에서 직접 설명합니다.
// Auto-Compact보다 먼저 실행됩니다. Collapse만으로 Auto-Compact
// 임계값 아래로 줄어들면, Auto-Compact는 실행되지 않고(no-op)
// 단일 요약 대신 세밀한 컨텍스트를 유지할 수 있습니다.
Collapse로 충분히 줄어들면 Auto-Compact(비싼 API 호출)가 발동하지 않습니다. 세밀한 컨텍스트를 최대한 보존하면서 비용을 아끼는 전략입니다.
한 가지 미묘한 문제가 있습니다. 압축으로 오래된 메시지를 날리면, 서버는 그 메시지들에서 소비된 토큰을 더 이상 알 수 없습니다. 그래서 클라이언트가 "지금까지 총 X 토큰을 썼고, 남은 예산은 Y입니다"를 직접 계산해서 서버에 알려줘야 합니다. 서버와 클라이언트가 서로 다른 시점의 히스토리를 보고 있기 때문에 생기는 동기화 문제로, 에이전틱 시스템에서 흔히 겪는 까다로운 부분입니다.
2단계: API Call & Streaming (lines 659-863)
for await (const message of deps.callModel(
fullSystemPrompt,
prependUserContext(messagesForQuery, userContext),
toolUseContext,
{ taskBudget, taskBudgetRemaining, maxOutputTokensOverride, skipCacheWrite },
)) {
// 스트리밍 이벤트 처리
}
여기서의 핵심은 StreamingToolExecutor입니다. 보통이라면 "Claude 응답 완료 → 도구 실행 → 결과 반환"이 순차적으로 일어납니다. 하지만 Claude Code는 Claude가 응답을 생성하는 동안 도구를 병렬로 실행합니다. Claude가 "파일을 읽어볼게요"라고 타이핑하는 중에 이미 파일이 읽히고 있다는 뜻입니다. 사용자가 체감하는 대기 시간이 줄어드는 건 이런 트릭 덕분입니다.
물론 모든 도구를 무작정 동시에 실행할 수는 없습니다. 파일을 읽는 도구 두 개는 동시에 돌려도 문제가 없지만, 파일을 쓰는 도구와 읽는 도구가 동시에 돌면 결과를 예측할 수 없습니다. 소스를 보면 이 문제를 꽤 정교하게 해결하고 있습니다.
// StreamingToolExecutor.ts
private canExecuteTool(isConcurrencySafe: boolean): boolean {
const executingTools = this.tools.filter(t => t.status === 'executing')
return (
executingTools.length === 0 ||
(isConcurrencySafe && executingTools.every(t => t.isConcurrencySafe))
)
}
모든 도구에는 isConcurrencySafe(동시 실행 안전) 플래그가 있습니다. FileReadTool, GlobTool, GrepTool 같은 읽기 전용 도구는 true — 서로 영향을 주지 않으니 동시에 실행해도 됩니다. FileWriteTool이나 BashTool처럼 파일 시스템이나 환경을 변경하는 도구는 false — 반드시 혼자 실행되어야 합니다. 위 코드의 조건을 풀어 쓰면 "지금 실행 중인 도구가 없거나, 실행 중인 도구와 새 도구 모두 동시 실행 안전할 때만 허용"입니다.
그리고 한 도구가 에러를 내면 함께 실행 중이던 형제 도구들도 sibling_error로 취소됩니다.
type AbortReason =
| 'sibling_error' // 형제 도구 에러 → 나도 취소
| 'user_interrupted' // 사용자가 Ctrl+C / ESC
| 'streaming_fallback' // 모델 폴백으로 폐기
모델 폴백도 여기서 처리됩니다. API 호출이 실패하거나 주 모델이 응답하지 못하면, 미리 지정해 둔 대체 모델(fallback model)로 자동 전환합니다.
if (innerError instanceof FallbackTriggeredError && fallbackModel) {
currentModel = fallbackModel
attemptWithFallback = true
// 고아(orphan) 메시지에 tombstone 생성
yield* yieldMissingToolResultBlocks(assistantMessages, 'Model fallback triggered')
// StreamingToolExecutor 초기화 후 재시도
}
여기서 등장하는 tombstone(묘비) 메시지를 설명하겠습니다. 모델이 전환되면 이전 모델이 요청했던 도구 호출들은 더 이상 유효하지 않습니다. 하지만 대화 히스토리에는 "도구를 호출했다"는 기록이 남아 있고, 그에 대한 결과가 없으면 히스토리가 꼬입니다. Tombstone은 이 빈자리를 채우는 마커입니다 — 데이터베이스에서 "이 항목은 삭제되었음"을 표시하는 것과 같은 개념으로, "이 도구 호출은 모델 폴백으로 인해 폐기되었습니다"라는 기록을 남겨서 히스토리의 앞뒤가 맞도록 합니다.
3단계: 에러 복구 캐스케이드 (lines 1062-1256)
이 부분이 아키텍처적으로 가장 인상적인 곳입니다. API 호출은 실패할 수 있습니다 — 프롬프트가 너무 길거나(413 에러), 응답이 출력 토큰 한도를 초과하거나. 단순한 시스템이라면 에러를 사용자에게 던지고 끝내겠지만, Claude Code는 저비용에서 고비용 순서로 복구를 시도합니다.
Prompt-too-long (413 에러) 복구 — 3단계 캐스케이드:
1단계: Context Collapse 드레인 (비용: 0)
└ Context Collapse는 평소에 "이 블록은 축소할 수 있다"는 후보를 미리 골라둡니다(프리뷰).
413 에러가 발생하면, 대기 중이던 축소 후보들을 즉시 확정(커밋)해서 컨텍스트를 줄입니다.
이미 준비된 것을 적용만 하면 되므로 추가 API 호출이 필요 없습니다.
2단계: Reactive Compact (비용: API 1회 호출)
└ 전체 대화를 요약합니다. 이미지를 스트리핑하고, 요약 후 재시도합니다.
└ "strip retry" — 요약 자체도 너무 크면 미디어를 제거한 뒤 한 번 더 시도합니다.
3단계: 에러 표출
└ 모든 시도가 실패하면 사용자에게 에러를 보여줍니다.
Max-output-tokens 복구 — 역시 3단계:
1단계: 토큰 캡 에스컬레이션 (비용: 0)
└ 8K → 64K (ESCALATED_MAX_TOKENS)로 투명하게 올립니다.
└ 메타 메시지 없이 자동으로 처리됩니다. 사용자는 모릅니다.
2단계: Resume 메시지 주입 (비용: API 재호출, 최대 3회)
└ "이전 응답이 잘렸습니다. 잘린 부분부터 이어서 작성해주세요"
└ 라는 메시지를 주입하고 모델을 다시 호출합니다.
└ maxOutputTokensRecoveryCount를 추적해서 최대 3회까지만 시도합니다.
3단계: 복구 소진
└ 3회 시도 후에도 해결 안 되면 현재까지의 결과로 완료 처리합니다.
이 캐스케이드의 설계 원칙은 명확합니다. 첫 번째 시도는 항상 무료(free)입니다. 전체 대화를 요약하는 비싼 작업은 최후의 수단입니다. 이건 단순한 "재시도"가 아니라, 비용-효과를 정밀하게 고려한 복구 전략입니다.
4단계: Stop Hooks & Token Budget (lines 1267-1355)
Stop hook은 사용자 정의 검증 로직을 실행합니다. "테스트를 통과하지 않으면 멈추지 마"라는 hook을 걸면, Claude가 작업을 끝내려 할 때 hook이 실행되고, 실패하면 hook의 에러 메시지가 대화에 주입되어 Claude가 다시 시도합니다.
토큰 버짓은 더 흥미롭습니다. 단순히 "예산을 다 쓰면 멈춰라"가 아니라, 진전이 없으면 예산이 남아 있어도 멈추는 로직이 들어 있습니다.
function checkTokenBudget(tracker, budget, globalTurnTokens) {
const pct = (turnTokens / budget) * 100
const isDiminishing = (
continuationCount >= 3 && // 3회 이상 연속으로 계속했고
deltaSinceLastCheck < 500 && // 직전 체크 이후 생성된 토큰이 500 미만이고
lastDeltaTokens < 500 // 그 전에도 500 미만이면 → "삽질 중"
)
if (!isDiminishing && turnTokens < budget * 0.9) { // 삽질 아니고 예산 90% 미만이면
return { action: 'continue', nudgeMessage: ... } // 계속
}
return { action: 'stop', completionEvent: { diminishingReturns, ... } } // 중단
}
이것이 감소 수익(diminishing returns) 감지입니다. 3회 연속으로 계속했는데 매번 500 토큰도 생성하지 못하면, "이건 더 해봤자 의미 없다"고 판단하고 멈춥니다. 예산의 90%를 소진하기 전까지는 계속하되, 진전 없는 삽질은 허용하지 않습니다.
이 로직이 왜 중요한지 생각해보면: 에이전틱 루프에서 가장 위험한 건 무한 루프입니다. Claude가 "한 번만 더 고쳐볼게요"를 반복하면서 토큰만 소비하고 진전이 없는 상황. 이 감소 수익 감지는 그런 상황을 자동으로 차단합니다.
5단계: Tool 실행 (lines 1363-1520)
2단계에서 시작된 스트리밍 모드와 배치 모드가 공존합니다. 2단계에서 StreamingToolExecutor가 이미 병렬 안전 도구들을 실행해 두었으므로, 여기서는 그 결과를 수거하고 나머지 도구를 순차 실행합니다.
// 스트리밍: 2단계에서 이미 실행한 병렬 안전 도구의 결과를 수거
if (streamingToolExecutor) {
toolResults = await streamingToolExecutor.getRemainingResults()
}
// 배치: 스트리밍으로 처리되지 않은 나머지 도구를 순차 실행
toolResults = await runTools(toolUseBlocks, toolUseContext, canUseTool)
도구가 실행되는 동안 터미널에는 스피너가 실시간으로 업데이트됩니다. progressAvailableResolve라는 Promise resolver가 "새 진행 상황이 생겼다"는 신호를 UI 소비자에게 보내고, UI가 이를 받아 스피너 텍스트를 갱신하는 구조입니다.
6단계: Post-Tool & 다음 턴 전이 (lines 1547-1727)
도구 실행이 끝나면 다음 턴을 준비하기 위한 여러 "부가 작업"을 처리합니다. 여기서 눈에 띄는 건 prefetch(미리 가져오기) 패턴입니다. 1단계(압축)에서 "스킬 목록 조회"와 "메모리 로드" 같은 느린 작업을 미리 시작해 놓고, 여기 6단계에서 그 결과를 수확(consume)합니다. 2~5단계가 진행되는 동안 네트워크 요청이 백그라운드에서 이미 완료되어 있으므로 대기 시간이 사라집니다.
// 1. 스킬 디스커버리 소비 — 1단계에서 prefetch한 결과를 여기서 수확
if (pendingSkillPrefetch?.settledAt !== null) {
const skillAttachments = await pendingSkillPrefetch.promise
}
// 2. 메모리 어태치먼트 소비 — 역시 1단계에서 prefetch한 결과를 수확
if (pendingMemoryPrefetch?.settledAt !== null) {
const memoryAttachments = await pendingMemoryPrefetch.promise
}
// 3. 큐된 명령어 드레인 — 도구 실행 중 쌓인 슬래시 명령어, 태스크 알림 등을 처리
const queuedCommands = getCommandsByMaxPriority(...)
// 4. MCP 서버 도구 새로고침 — 외부 도구 목록이 바뀌었을 수 있으므로 갱신
if (toolUseContext.options.refreshTools) {
toolUseContext.options.tools = toolUseContext.options.refreshTools()
}
부가 작업을 마치면 다음 턴으로 상태를 전이합니다.
// Continue Site: 다음 턴으로
state = {
messages: [...messagesForQuery, ...assistantMessages, ...toolResults],
toolUseContext: toolUseContextWithQueryTracking,
autoCompactTracking: tracking,
turnCount: nextTurnCount,
transition: { reason: 'next_turn' },
}
// while(true) 루프 상단으로 돌아감
3.4 종료 이유: 루프가 끝나는 9가지 방법
| Exit Reason | 의미 | 발생 지점 |
|---|---|---|
completed |
정상 완료 (도구 호출 없이 응답 종료) | line 1264, 1357 |
blocking_limit |
하드 토큰 한도 도달 | line 646 |
aborted_streaming |
스트리밍 중 사용자 중단 (Ctrl+C) | line 1051 |
aborted_tools |
도구 실행 중 사용자 중단 | line 1515 |
prompt_too_long |
복구 시도 후에도 프롬프트 초과 | line 1175, 1182 |
image_error |
이미지 검증 실패 (크기 초과 등) | line 977, 1175 |
model_error |
예상치 못한 모델 에러 | line 996 |
hook_stopped |
Stop hook이 진행을 차단 | line 1520 |
max_turns |
최대 턴 수 초과 (maxTurns 파라미터) |
line 1711 |
3.5 QueryEngine.ts: 세션과 턴의 상위 관리자
지금까지 살펴본 query.ts는 "한 번의 사용자 입력 → Claude 응답 → 도구 실행 → 다시 Claude" 사이클을 담당합니다. 그렇다면 여러 번의 사용자 입력에 걸친 세션 전체는 누가 관리할까요? QueryEngine.ts(1,295줄)입니다.
class QueryEngine {
mutableMessages: Message[] // 전체 대화 히스토리
permissionDenials: PermissionDenial[] // 도구 권한 거부 기록
totalUsage: Usage // 누적 토큰 사용량
readFileState: FileStateCache // 파일 상태 캐시 (중복 읽기 방지)
discoveredSkillNames: Set<string> // 발견된 스킬 (턴마다 초기화)
loadedNestedMemoryPaths: Set<string> // 로드된 메모리 경로 (중복 방지)
}
submitMessage() 메서드가 사용자 입력을 받아 query()를 호출하고, 결과를 세션에 축적합니다. 아래처럼 매 턴의 토큰 사용량을 누적해서 전체 세션의 비용을 추적합니다.
this.totalUsage = accumulateUsage(this.totalUsage, currentMessageUsage)
트랜스크립트(대화 기록) 저장에는 비대칭적 전략이 적용됩니다.
// 사용자 메시지: 블로킹 저장 (--resume 복원에 필수)
await recordTranscript(userMessage)
// 어시스턴트 메시지: fire-and-forget (실행만 하고 완료를 기다리지 않는 비동기 패턴)
recordTranscript(assistantMessage) // await 없음
모든 메시지를 같은 우선순위로 저장하지 않습니다. 사용자 메시지는 --resume으로 세션을 이어받을 때 반드시 있어야 하므로, 디스크에 기록이 완료될 때까지 다음 단계로 넘어가지 않습니다(await). 반면 어시스턴트 응답은 없어도 세션 복원 자체는 가능하므로, 저장 요청만 보내고 완료를 기다리지 않은 채 바로 다음 작업을 진행합니다(await 없음). 저장이 실패하더라도 루프가 멈추지 않습니다. 이렇게 하면 디스크 I/O 대기 시간을 절반 가까이 줄이면서도, 정작 잃으면 안 되는 데이터는 확실히 보호하는 균형을 잡을 수 있습니다.
4. 메시지 압축: 컨텍스트 윈도우와의 정교한 전쟁
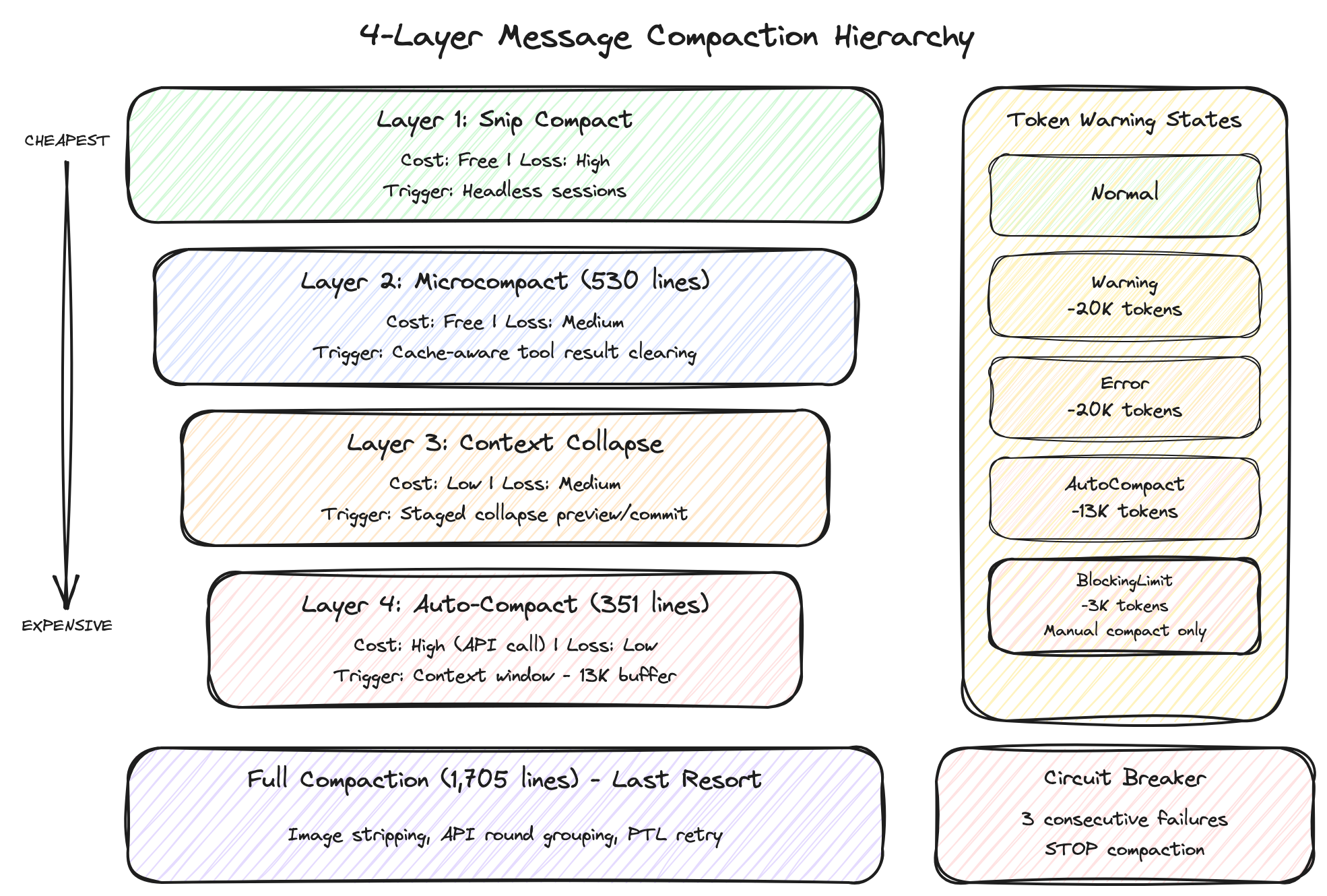
에이전틱 AI 도구의 최대 적은 컨텍스트 윈도우 한계입니다. LLM에 보낼 수 있는 텍스트의 총량에는 상한이 있고, 대화가 길어지면 이전 내용이 잘려나가거나 API가 413(Prompt Too Long) 에러를 반환합니다. Claude Code의 압축 시스템은 이 문제를 4개 계층으로 해결하며, 각 계층은 비용과 정보 손실 정도가 다릅니다. 핵심 원칙은 "항상 가장 저렴한 것부터"입니다.
4.1 Snip Compact — 가장 저렴하고 가장 과격합니다
비용: 무료 (API 호출 없음) 정보 손실: 높음
"Snip(잘라내기)"이라는 이름 그대로, 오래된 메시지를 통째로 잘라내고 최근 컨텍스트만 남깁니다. 요약이나 분석 없이 그냥 버리는 것이라 정보 손실이 크지만, API 호출이 전혀 없으므로 비용은 0입니다. HISTORY_SNIP 피처 플래그 뒤에 있으며, 주로 헤드리스(headless, UI 없이 백그라운드에서 실행되는) 세션에서 사용됩니다. 사용자가 직접 보지 않는 자동화된 세션이라 과격한 잘라내기가 허용되는 셈입니다.
const snipResult = snipModule!.snipCompactIfNeeded(messagesForQuery)
messagesForQuery = snipResult.messages
snipTokensFreed = snipResult.tokensFreed
여기서 snipTokensFreed — Snip이 제거한 토큰 수 — 가 이후 Auto-Compact 단계로 전달됩니다. 왜일까요? Auto-Compact는 "현재 토큰 수가 임계값을 넘었는가"를 기준으로 발동 여부를 결정합니다. 그런데 토큰 수 추정(tokenCountWithEstimation)은 현재 남아 있는 메시지만 세기 때문에, Snip이 이미 줄여놓은 양을 모릅니다. 이 정보를 전달하지 않으면 "Snip이 충분히 줄였는데도 Auto-Compact가 불필요하게 발동"하는 상황이 생깁니다. 소스 주석이 이를 직접 설명합니다.
// snipTokensFreed를 Auto-Compact로 전달하여 임계값 판단에 반영합니다.
// tokenCountWithEstimation만으로는 Snip이 제거한 양을 알 수 없기 때문입니다.
4.2 Microcompact (530줄) — 캐시를 존중하는 선택적 클리어
비용: 무료 (API 호출 없음) 정보 손실: 중간
"Micro"라는 이름은 전체 대화를 한꺼번에 압축하는 게 아니라, 특정 도구의 결과만 골라서 개별적으로 클리어한다는 뜻입니다. 예를 들어 10턴 전에 file_read로 읽은 파일 내용(수백 줄)은 이미 Claude가 소화한 정보이므로, 원본 대신 "[Old tool result content cleared]"라는 짧은 플레이스홀더로 교체해도 이후 대화에 큰 영향이 없습니다.
// 클리어 대상: file_read, shell, grep, glob, web_search, web_fetch, file_edit, file_write
// 결과를 "[Old tool result content cleared]"로 교체
// 이미지/문서: 2,000 토큰으로 추정
// 텍스트: 대략적 토큰 카운트로 추정
그런데 아무 도구 결과나 무작정 클리어하면 안 됩니다. 여기서 이 계층의 진짜 핵심이 등장합니다 — 캐시 편집 블록 피닝(cache edit block pinning)입니다.
이걸 이해하려면 먼저 프롬프트 캐싱을 알아야 합니다. Anthropic API에 프롬프트를 보낼 때, 프롬프트의 앞부분(프리픽스)이 이전 요청과 동일하면 서버가 그 부분의 계산을 건너뜁니다. 매 턴마다 시스템 프롬프트 + 이전 대화 전체를 다시 보내야 하는 에이전틱 루프에서, 이 캐싱은 비용과 지연 시간을 크게 줄여줍니다.
문제는 Microcompact가 대화 중간에 있는 도구 결과를 클리어하면, 그 지점부터 프롬프트의 내용이 바뀌어서 그 이후의 모든 캐시가 무효화된다는 것입니다. 대화 앞쪽의 오래된 grep 결과 하나를 클리어했는데, 그 뒤에 있는 수만 토큰의 캐시가 전부 날아가면 오히려 역효과입니다.
캐시 편집 블록 피닝은 이 문제를 해결합니다. "피닝(pinning)"이란 캐시된 프리픽스 영역 안에 있는 도구 결과를 클리어하지 않고 고정(pin)해 두는 것입니다. 구체적으로는:
- 어떤 도구 결과가 현재 캐시된 프리픽스 범위 안에 있는지 추적합니다
- 캐시 범위 안의 결과는 클리어 대상에서 제외합니다 (피닝)
- 캐시 범위 밖의 결과만 안전하게 클리어합니다
- 피닝된 결과는
pendingCacheEdits에 "나중에 클리어할 후보"로 기록해 둡니다 - 다음 턴에서 캐시 범위가 바뀌면, 더 이상 캐시 안에 있지 않은 후보들을 그때 클리어합니다
const pendingCacheEdits = feature('CACHED_MICROCOMPACT')
? microcompactResult.compactionInfo?.pendingCacheEdits
: undefined
결국 "지금 당장 클리어하면 캐시가 깨지니까, 안전한 시점까지 미뤄두겠다"는 전략입니다. 프롬프트 캐싱에서 캐시 미스 한 번은 수만 토큰의 재계산을 의미하므로, 섣부른 클리어로 캐시를 깨는 것보다 조금 더 큰 프롬프트를 보내는 게 오히려 저렴할 수 있습니다. 캐시 히트율을 유지하면서 컨텍스트를 줄이는 건 서로 상충하는 목표인데, 이 피닝 메커니즘이 그 균형을 잡습니다.
4.3 Context Collapse — 단계적 축소
비용: 낮음 정보 손실: 중간
이 계층은 Git의 커밋 모델에서 영감을 받은 듯한 "단계적 축소(staged collapse)" 개념을 사용합니다. 전체 대화를 한 번에 압축하는 대신 두 단계로 나뉩니다.
프리뷰(preview) 단계: 대화를 스캔하면서 "이 메시지 블록은 축소할 수 있겠다"는 후보를 골라냅니다. 예를 들어, 10턴 전에 5개 파일을 연속으로 읽은 블록이 있으면, 이걸 "5개 파일을 읽어서 X를 확인함"이라는 한 줄 요약으로 축소할 수 있다고 표시합니다. 이 시점에서는 아무것도 바뀌지 않습니다.
커밋(commit) 단계: 프리뷰에서 고른 후보들을 실제로 축소합니다. 하지만 여기서 핵심적인 설계 결정이 있습니다 — 원본 메시지를 수정하지 않습니다. 대신 축소 결과(요약)를 별도의 collapse 저장소에 보관하고, API에 프롬프트를 보낼 때 projectView() 함수가 원본 위에 축소된 뷰를 "덮어씌워서" 보여줍니다.
소스 주석이 이 설계를 직접 설명합니다.
// 아무것도 yield하지 않습니다 — 축소된 뷰는 REPL 전체 히스토리에 대한
// 읽기 시점 프로젝션입니다. 요약 메시지는 REPL 배열이 아닌 별도의 collapse
// 저장소에 보관됩니다. 이 덕분에 축소 결과가 턴을 넘어서도 유지됩니다.
// projectView()가 매 진입 시 커밋 로그를 재생(replay)합니다.
이것을 읽기 시점 프로젝션(read-time projection)이라고 부릅니다. 데이터베이스의 "뷰(view)"와 같은 개념입니다 — 원본 테이블은 그대로 있고, 조회할 때마다 가공된 결과를 보여주는 가상 테이블이 따로 있는 것처럼, 여기서도 원본 메시지 배열은 건드리지 않고 API에 보내는 시점에 축소된 버전을 계산합니다. Git이 원본 파일을 건드리지 않으면서 다른 브랜치의 스냅샷을 보여주는 것과도 유사합니다.
왜 이렇게 복잡하게 할까요? 두 가지 이유가 있습니다. 첫째, REPL 히스토리의 원본을 보존하면 축소를 되돌리거나 다른 뷰를 생성할 수 있습니다. 둘째, 캐시 영향을 최소화합니다. 축소가 적용되는 시점에 API로 보내는 토큰 시퀀스가 바뀌므로 캐시가 한 번 리셋되지만, projectView()가 매 턴마다 동일한 커밋 로그를 리플레이하기 때문에 그 이후의 턴에서는 새 접두어가 안정적으로 유지됩니다. Auto-Compact(전체 요약)처럼 매번 다른 결과가 나오는 게 아니라, 한 번 확정된 축소는 이후 계속 같은 토큰 시퀀스를 생성합니다. 코드에서 notifyCompaction()을 호출하여 캐시 감지 시스템의 베이스라인을 리셋하는 것도 이 때문입니다.
4.4 Auto-Compact (351줄) — 최후의 수단
비용: 높음 (Claude API 추가 호출) 정보 손실: 낮음 (AI가 요약하므로 핵심은 보존)
앞선 3개 계층(Snip, Microcompact, Context Collapse)은 모두 기존 메시지를 잘라내거나 클리어하거나 뷰를 축소하는 방식이었습니다. Auto-Compact는 근본적으로 다릅니다 — 전체 대화 히스토리를 Claude에게 보내서 "지금까지의 대화를 요약해줘"라고 요청합니다. AI가 맥락을 이해한 뒤 핵심만 추려내므로 정보 손실이 가장 적지만, API 호출이 추가로 발생하므로 비용도 가장 높습니다.
발동 시점을 결정하는 임계값 로직은 명확합니다.
function getAutoCompactThreshold(model: string): number {
const effectiveContextWindow = getEffectiveContextWindowSize(model)
return effectiveContextWindow - 13_000 // 13K 토큰 버퍼
}
컨텍스트 윈도우에서 13K 토큰의 여유 공간을 남겨둡니다. 이 버퍼는 시스템 프롬프트, 도구 정의, 그리고 다음 턴의 모델 응답이 들어갈 자리입니다. 나머지 공간이 대화 히스토리로 가득 차면 자동 압축이 발동합니다.
여기에 서킷 브레이커(circuit breaker) 패턴이 적용됩니다. 전기 시스템에서 과부하가 걸리면 차단기가 회로를 끊어 장비를 보호하듯, 소프트웨어에서도 연속 실패를 감지하면 더 이상 시도하지 않고 차단합니다.
MAX_CONSECUTIVE_AUTOCOMPACT_FAILURES = 3
왜 필요할까요? 대화가 극도로 길어지면 요약 요청 자체도 컨텍스트 한도를 넘어서 실패할 수 있습니다. 서킷 브레이커 없이는 "압축 실패 → 재시도 → 또 실패 → 재시도…"의 무한 루프에 빠집니다. 3회 연속 실패 시 서킷 브레이커가 작동해서 깔끔하게 포기하고, 다른 복구 경로(섹션 3.3의 에러 복구 캐스케이드)에 제어를 넘깁니다.
4.5 Full Compaction (1,705줄) — Auto-Compact의 엔진룸
Auto-Compact가 "요약해줘"라고 요청하기 전에, 요약 대상 자체를 정리하는 전처리 단계입니다. 요약에 보낼 프롬프트도 컨텍스트 한도가 있으므로, 불필요한 부분을 미리 줄여서 요약 성공률을 높입니다.
- 이미지 스트리핑: 이미지와 문서를
[image]/[document]플레이스홀더로 교체합니다. 이미지 한 장이 수천 토큰을 차지할 수 있는데, 요약 모델에게는 "여기 이미지가 있었다"는 사실만 알려주면 충분합니다. - API 라운드 그룹핑: Claude API에서
tool_use(도구 호출 요청)와tool_result(실행 결과)는 반드시 쌍으로 존재해야 합니다. 한쪽만 삭제하면 API가 거부하므로, 이 쌍을 하나의 그룹으로 묶어서 "버릴 때는 그룹 단위로" 처리합니다. - Thinking 블록 제거: (Anthropic 내부 빌드 전용) Claude의 추론 과정(chain-of-thought) 블록을 압축 전에 제거합니다. 요약에 포함할 필요 없는 중간 사고 과정이기 때문입니다.
- PTL(Prompt-Too-Long) 재시도: 위 전처리를 거쳤는데도 요약 요청 자체가 컨텍스트 한도를 넘으면, 가장 오래된 API 라운드 그룹부터 제거합니다. 한도 내로 들어올 때까지 반복하되, 해소되지 않으면 전체 그룹의 20%를 한꺼번에 드롭하는 것으로 폴백합니다.
truncateHeadForPTLRetry(messages, ptlResponse) {
// prompt-too-long 초과분이 해소될 때까지 가장 오래된 API 라운드 그룹부터 제거
// 해소되지 않으면 전체 그룹의 20%를 제거하는 것으로 폴백
}
4.6 토큰 경고 상태 시스템
위 압축 메커니즘들이 백그라운드에서 동작하는 동안, 사용자에게도 "지금 컨텍스트가 얼마나 찼는지"를 시각적으로 알려줍니다. 4단계 경고 상태 머신입니다.
[정상]
↓ 컨텍스트 윈도우까지 20K 토큰 남음
[Warning] ← 노란색 경고. "대화가 길어지고 있습니다"
↓ 컨텍스트 윈도우까지 20K 토큰 남음
[Error] ← 주황색 경고. "곧 압축이 발동합니다"
↓ 컨텍스트 윈도우까지 13K 토큰 남음
[AutoCompact] ← 자동 압축 발동. 사용자에게 알림
↓ 컨텍스트 윈도우까지 3K 토큰 남음
[BlockingLimit] ← 빨간색. 자동 압축으로도 부족, 수동 압축(/compact)만 가능
인사이트: 왜 4단계인가
4단계 압축이 단순히 "점점 더 세게 압축"하는 직선적 구조가 아닙니다. 각 단계는 서로 다른 축에서 서로 다른 것을 희생합니다.
| 계층 | 비용 | 정보 손실 | 캐시 영향 | 핵심 트레이드오프 |
|---|---|---|---|---|
| Snip | 무료 | 높음 | 없음 | 과거를 통째로 버리지만 현재 캐시는 보존 |
| Microcompact | 무료 | 중간 | 피닝으로 최소화 | 개별 결과를 클리어하되 캐시 범위는 존중 |
| Context Collapse | 낮음 | 중간 | 최소화 (축소 시점에 한 번 리셋, 이후 안정) | 원본은 보존하되, 축소된 뷰가 API에 전달되므로 적용 시점에 캐시 리셋 발생. 이후 새 접두어로 캐시 재누적 |
| Auto-Compact | 높음 | 낮음 | 전체 리셋 | AI가 요약하므로 정보는 보존하지만 API 비용 발생 |
이건 "비용 최소화"와 "정보 보존 최대화"라는 두 축 위에서 최적의 균형점을 찾는 문제입니다. 경제학에서 말하는 파레토 프론티어 — 하나를 개선하면 반드시 다른 하나가 나빠지는 트레이드오프의 경계선 — 위에 4개 계층이 각각 다른 점으로 놓여 있습니다. 어떤 단일 전략도 모든 면에서 최적일 수 없기 때문에, 상황에 따라 가장 적합한 전략을 순서대로 적용하는 것입니다.
5. 도구 시스템: 체계적으로 확장 가능한 스위스 아미 나이프
Claude Code가 실제로 할 수 있는 것은 도구 시스템이 결정합니다. 파일을 읽고, 코드를 편집하고, 터미널 명령을 실행하는 것 — 이 모든 "능력"은 개별 도구(tool)로 구현되어 있고, tools.ts를 보면 그 전체 그림이 보입니다.
5.1 도구 인터페이스
모든 도구는 같은 인터페이스를 따릅니다. 핵심은 ToolUseContext — 도구가 실행될 때 받는 "세계(world)" 객체입니다. 어떤 도구든 실행에 필요한 모든 것을 이 하나의 객체에서 꺼내 씁니다.
// ToolUseContext — 도구 실행에 필요한 모든 것이 여기 담깁니다
type ToolUseContext = {
options: { tools: Tools; mainLoopModel: string; mcpClients: MCPServerConnection[]; maxBudgetUsd?: number; ... }
abortController: AbortController
readFileState: FileStateCache // 중복 파일 읽기 방지
getAppState(): AppState // 애플리케이션 상태 접근
setAppState(f: (prev: AppState) => AppState): void
// ... 40+ 필드 (에이전트 ID, 권한 추적, 콘텐츠 교체 상태 등)
}
40개가 넘는 필드가 있는 이유는, 도구가 단순히 "파일 읽기"만 하는 게 아니기 때문입니다. 현재 사용 중인 모델이 뭔지(mainLoopModel), 비용 한도를 넘었는지(maxBudgetUsd), 사용자가 취소를 눌렀는지(abortController), 같은 파일을 또 읽으려 하는 건 아닌지(readFileState) 등 실행 맥락 전체가 필요합니다.
주목할 점은 권한 관련 컨텍스트입니다.
type ToolPermissionContext = DeepImmutable<{
mode: PermissionMode // 현재 권한 모드 (ask/auto/bypass)
additionalWorkingDirectories: ... // 접근 허용된 추가 디렉토리
alwaysAllowRules: ToolPermissionRulesBySource // "항상 허용" 규칙 목록
alwaysDenyRules: ToolPermissionRulesBySource // "항상 거부" 규칙 목록
alwaysAskRules: ToolPermissionRulesBySource // "항상 물어보기" 규칙 목록
isBypassPermissionsModeAvailable: boolean // 권한 우회 모드 사용 가능 여부
isAutoModeAvailable?: boolean
strippedDangerousRules?: ToolPermissionRulesBySource // 위험 규칙 제거 기록
shouldAvoidPermissionPrompts?: boolean // 백그라운드 에이전트용 (UI 없음)
awaitAutomatedChecksBeforeDialog?: boolean // 코디네이터 워커용
prePlanMode?: PermissionMode // 플랜 모드 진입 전 모드 저장
}>
바깥을 감싸는 DeepImmutable이 중요합니다. TypeScript의 Readonly는 객체의 최상위 속성만 읽기 전용으로 만듭니다. 예를 들어 rules 자체를 다른 객체로 교체하는 건 막아주지만, rules.alwaysAllowRules 배열에 항목을 추가하는 건 막지 못합니다. 겉문은 잠갔지만 안쪽 방문은 열려 있는 셈입니다. DeepImmutable은 이 문제를 해결합니다. 최상위뿐 아니라 중첩된 모든 속성, 배열, 배열 안의 객체까지 재귀적으로 읽기 전용으로 잠급니다. 권한 규칙은 시스템의 보안 경계이므로, 코드 어디에서든 실수로 변경되는 것을 타입 시스템 차원에서 원천 차단하는 것입니다.
5.2 도구 등록의 3계층 구조
getAllBaseTools() 함수를 보면, Claude Code의 도구는 세 계층으로 나뉩니다.
항상 활성화: BashTool, FileReadTool, FileEditTool, WebSearchTool, AgentTool 등 20여 개의 기본 도구. 이것들이 Claude Code의 핵심 능력을 구성합니다.
조건부 활성화: 환경이나 설정에 따라 켜지는 도구들입니다. 재미있는 예로, GlobTool과 GrepTool은 Anthropic 내부 빌드에서는 비활성화됩니다. 이유는 내부 빌드의 Bun 바이너리에 bfs(파일 검색)와 ugrep(텍스트 검색)이라는 고성능 네이티브 도구가 직접 임베딩되어 있어서, JavaScript로 구현된 Glob/Grep보다 빠르기 때문입니다. 외부 빌드에는 이 임베딩이 없으므로 JavaScript 도구가 활성화됩니다. PowerShellTool은 Windows에서만, LSPTool은 환경변수로 명시적으로 켜야 합니다.
피처 플래그 기반 (미출시): feature() 함수로 게이트된 도구들입니다. WebBrowserTool, WorkflowTool, SleepTool, PushNotificationTool 등 15개 이상이 여기에 속합니다. 이것들은 섹션 7에서 자세히 다룹니다.
흥미로운 건 USER_TYPE === 'ant'로 분기되는 Anthropic 내부 전용 도구입니다.
const REPLTool = process.env.USER_TYPE === 'ant'
? require('./tools/REPLTool/REPLTool.js').REPLTool
: null
REPLTool, ConfigTool, TungstenTool, SuggestBackgroundPRTool — 이 도구들은 외부 사용자에게는 존재하지 않습니다. Anthropic 엔지니어들이 내부적으로 사용하는 도구 세트가 따로 있다는 뜻입니다. 특히 TungstenTool은 이름만으로는 용도를 알 수 없는데, 텅스텐(고밀도 금속)이라는 이름에서 "무거운 작업"을 처리하는 도구로 추정됩니다.
이 3계층 구조가 왜 중요할까요? 에이전틱 AI 도구에서 "어떤 능력을 줄 것인가"는 핵심 설계 결정입니다. 도구가 너무 많으면 시스템 프롬프트가 비대해지고 (토큰 비용 증가), 너무 적으면 에이전트의 능력이 제한됩니다. Claude Code는 이 문제를 빌드 타임 제거 + 조건부 활성화 + 피처 플래그의 3계층으로 해결합니다. Cursor나 Devin도 비슷한 도구 확장 문제를 겪을 텐데, 이런 계층적 접근은 참고할 만합니다.
5.3 도구 풀 조립: 캐시 안정성까지 고려한 설계
assembleToolPool() 함수에서 빌트인 도구와 MCP 도구를 합치는 로직이 있는데, 여기서 섹션 4.2에서 다룬 프롬프트 캐싱의 캐시 안정성을 위한 흥미로운 처리가 보입니다.
export function assembleToolPool(permissionContext, mcpTools): Tools {
const builtInTools = getTools(permissionContext)
const allowedMcpTools = filterToolsByDenyRules(mcpTools, permissionContext)
// 프롬프트 캐시 안정성을 위해 각 파티션을 정렬하되, 빌트인 도구를 연속된
// 접두사(prefix)로 유지합니다. 서버의 claude_code_system_cache_policy가
// 마지막 빌트인 도구 뒤에 글로벌 캐시 브레이크포인트를 배치하기 때문에,
// 단순 정렬로 MCP 도구가 빌트인 사이에 끼어들면 이후 모든 캐시 키가
// 무효화됩니다.
const byName = (a: Tool, b: Tool) => a.name.localeCompare(b.name)
return uniqBy(
[...builtInTools].sort(byName).concat(allowedMcpTools.sort(byName)),
'name',
)
}
빌트인 도구와 MCP 도구를 각각 따로 정렬한 뒤 이어 붙입니다. 왜 전체를 한 번에 정렬하지 않을까요?
섹션 4에서 프롬프트 캐싱이 "프리픽스(앞부분) 일치"로 작동한다고 설명했습니다. 도구 정의도 프롬프트의 일부이므로, 도구 목록의 순서가 바뀌면 캐시가 깨집니다. Anthropic 서버는 빌트인 도구 목록의 마지막 항목 뒤에 캐시 브레이크포인트(여기까지는 캐시해도 안전하다는 경계 표시)를 놓습니다. 만약 전체를 한 번에 알파벳 정렬하면, 사용자가 MCP 도구를 하나 추가했을 때 그 도구 이름이 빌트인 도구 사이에 끼어들면서 빌트인 도구의 순서가 바뀌고, 캐시 브레이크포인트 이전의 모든 캐시가 무효화됩니다. "빌트인만 먼저 정렬 → MCP만 따로 정렬 → 이어 붙이기"로 하면, MCP 도구를 아무리 추가/제거해도 빌트인 영역은 변하지 않아 캐시가 보존됩니다.
이런 수준의 캐시 최적화는 실제 프로덕션에서의 비용 경험 없이는 나오기 어렵습니다.
5.4 동적 도구 검색 (Tool Search)
tool-search-2025-10-16 베타 기능입니다. 문제는 이렇습니다 — Claude Code의 도구가 빌트인 20여 개 + MCP 도구 수십 개가 되면, 도구 정의만으로 시스템 프롬프트에서 수천 토큰을 차지합니다. 매 턴마다 이 비용을 지불하는 건 낭비입니다.
해결책은 필요할 때만 도구를 로드하는 것입니다. 모든 도구를 처음부터 Claude에게 보여주는 대신, ToolSearchTool이라는 "도구를 찾는 도구"만 제공합니다. Claude가 "파일을 검색하고 싶다"고 생각하면, 먼저 ToolSearchTool로 관련 도구를 검색하고, 그 도구의 정의가 그때 로드됩니다.
// tools.ts:247-249
// 도구 검색이 활성화될 수 있으면 ToolSearchTool을 포함 (낙관적 검사)
// 실제 도구 지연(defer) 결정은 claude.ts에서 API 요청 시점에 수행
...(isToolSearchEnabledOptimistic() ? [ToolSearchTool] : []),
여기서 "낙관적 검사(optimistic check)"라는 표현이 눈에 띕니다. 도구 등록 시점에서는 "아마 필요할 것이다"라고 낙관적으로 ToolSearchTool을 포함해 두고, 실제로 어떤 도구를 지연 로드할지는 API 요청 시점에 결정합니다. 등록 시점의 검사가 약간 부정확해도 괜찮습니다 — 최악의 경우 ToolSearchTool이 쓰이지 않을 뿐, 시스템이 깨지지는 않으니까요. 이건 웹 프론트엔드의 게으른 로딩(lazy loading)을 LLM 도구 시스템에 적용한 것입니다.
6. 다층 보안: 양파를 까보면
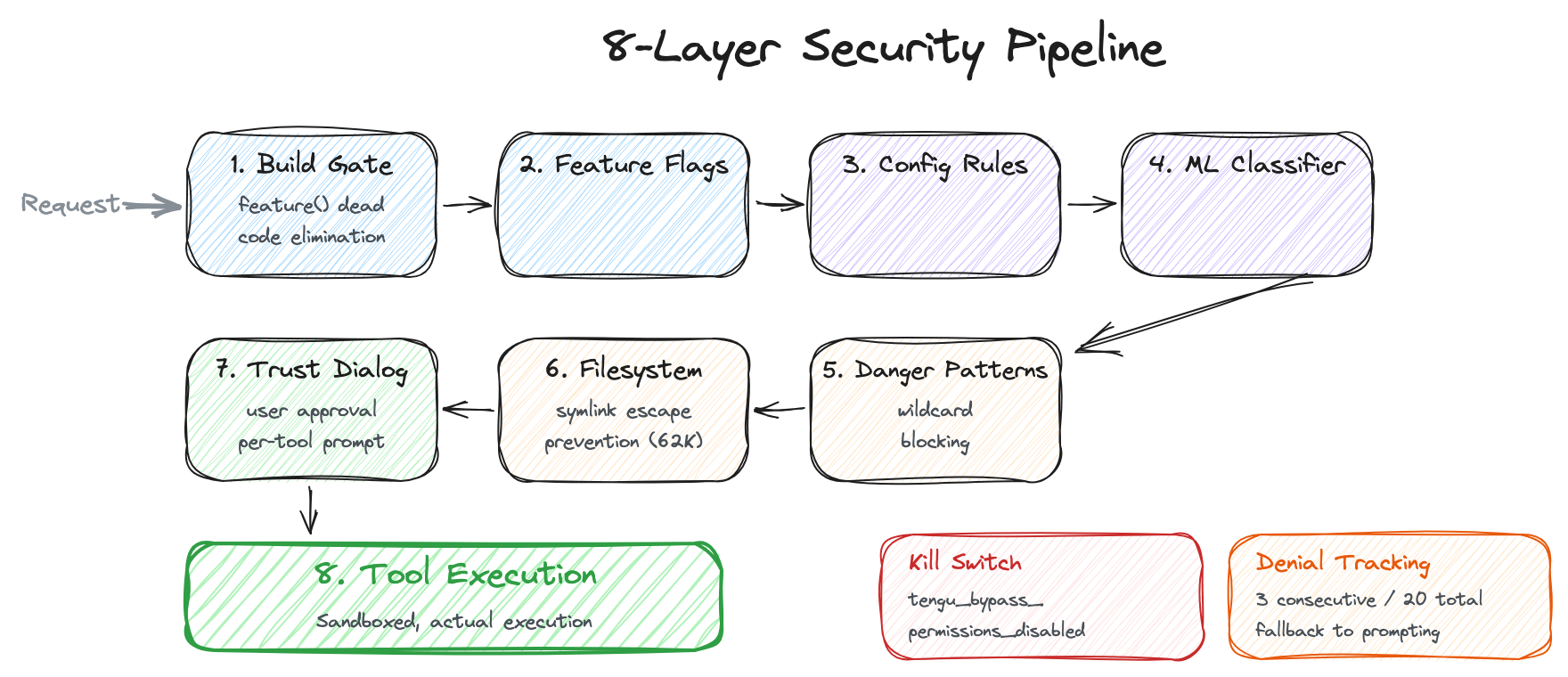
"AI 에이전트가 내 파일 시스템에 접근하고, 터미널 명령을 실행한다" — 보안 연구자를 떨리게 하기에 충분한 문장입니다. 잘못 작성된 프롬프트 하나로 rm -rf /가 실행될 수 있고, 악의적인 프롬프트 인젝션으로 민감한 파일이 유출될 수 있습니다. Claude Code가 이 문제를 어떻게 다루는지 보면, 양파 같은 다층 방어가 드러납니다. 8개 레이어입니다.
6.1 레이어 1: 빌드 타임 게이트 — 코드가 존재하지 않는 보안
// tools.ts:117-119
const WebBrowserTool = feature('WEB_BROWSER_TOOL')
? require('./tools/WebBrowserTool/WebBrowserTool.js').WebBrowserTool
: null
feature() 함수는 빌드 타임에 평가됩니다. 일반적인 if (config.enabled) 분기문은 런타임에 검사되므로, false 분기의 코드도 바이너리에 포함됩니다. 누군가 환경변수를 조작하면 활성화할 수 있다는 뜻입니다. 반면 feature()는 Bun 번들러가 빌드 시점에 false인 분기의 require()를 완전히 제거합니다. 외부 빌드에는 Anthropic 내부 전용 도구의 코드가 물리적으로 존재하지 않습니다. 런타임에 환경변수를 바꿔서 활성화하는 건 불가능합니다 — 바이너리에 코드 자체가 없으니까요.
같은 코드베이스에서 "내부용"과 "외부용" 빌드를 분기하면서도, 런타임 조작의 보안 위험을 원천적으로 제거하는 기발한 접근입니다. 물론, 이번에 유출된 건 바로 그 빌드 타임에 제거되었어야 할 코드가 source map에 남아있었기 때문입니다. 바이너리에는 없지만 source map에는 있었던 것 — 아이러니한 상황입니다.
USER_TYPE 환경변수도 같은 패턴으로 사용됩니다.
// tools.ts:16-19
const REPLTool =
process.env.USER_TYPE === 'ant'
? require('./tools/REPLTool/REPLTool.js').REPLTool
: null
6.2 레이어 2: 피처 플래그 — 서버 측 킬 스위치
빌드 후에도 서버 측에서 기능을 제어할 수 있습니다. GrowthBook 기반의 tengu_ 접두사 플래그들이 그 역할을 합니다. (tengu는 Anthropic 내부의 Claude Code 프로젝트 코드네임으로 추정됩니다.)
| 플래그 | 역할 |
|---|---|
tengu_amber_quartz_disabled |
음성 모드 킬 스위치 |
tengu_bypass_permissions_disabled |
권한 우회 모드 킬 스위치 |
tengu_auto_mode_config.enabled |
자동 모드 서킷 브레이커 |
tengu_ccr_bridge |
원격 제어 자격 확인 |
tengu_sessions_elevated_auth_enforcement |
신뢰 디바이스 토큰 요구 |
보안 사고가 발생하면 서버에서 즉시 킬 스위치를 당길 수 있습니다. 클라이언트 업데이트 없이 기능을 비활성화할 수 있다는 건 인시던트 대응 관점에서 매우 중요합니다.
Anthropic 내부에서는 환경변수로 이를 오버라이드할 수도 있습니다.
// CLAUDE_INTERNAL_FC_OVERRIDES (Anthropic 내부 전용)
// '{"my_feature": true, "my_config": {"key": "val"}}' 형식으로 오버라이드
6.3 레이어 3: 설정 기반 규칙 — 8개 소스의 우선순위
각 도구에 대해 "허용/거부/물어보기" 규칙을 설정할 수 있는데, 이 규칙은 8개의 서로 다른 소스에서 올 수 있습니다.
type PermissionRule = {
source: PermissionRuleSource // 8개 소스 중 하나
ruleBehavior: 'allow' | 'deny' | 'ask'
ruleValue: {
toolName: string // "Bash", "FileEdit" 등
ruleContent?: string // 패턴, 예: "python:*"
}
}
같은 도구에 대해 여러 소스에서 상충하는 규칙이 올 수 있으므로, 우선순위가 필요합니다. 번호가 낮을수록 우선순위가 높아 나중에 적용되어 이전 규칙을 덮어씁니다.
userSettings—~/.claude/settings.json(사용자 전역 설정, 최우선)projectSettings—.claude/settings.json(프로젝트별 설정, 팀과 공유됨)localSettings—.claude/local.json(로컬 전용, git에 올리지 않음)flagSettings— GrowthBook 피처 플래그 (서버 측 제어)policySettings— 조직 수준 정책 (엔터프라이즈 관리자가 설정)cliArg— 명령줄 인수 (--allowedTools등)command— 런타임 규칙 업데이트 (대화 중/allow등)session— 인메모리 세션 전용 규칙 (재시작하면 사라짐, 최하위)
사용자 설정이 최우선이라는 건, 조직 정책(policySettings)이나 서버 피처 플래그(flagSettings)보다 사용자가 더 강하게 제어할 수 있다는 뜻입니다. 다만 뒤에서 볼 레이어 5(위험 패턴 감지)와 레이어 8(킬 스위치)은 이 규칙 시스템을 오버라이드할 수 있습니다.
6.4 레이어 4: Transcript Classifier — AI가 AI를 감시합니다
yoloClassifier.ts — 52K짜리 파일입니다. (파일 이름이 "YOLO(You Only Live Once)"인데 52K라니, Anthropic 엔지니어의 유머 감각이 엿보입니다.)
이 레이어는 자동 모드(auto)에서 작동합니다. 자동 모드란 사용자에게 매번 "이 도구를 실행해도 될까요?"라고 묻는 대신, Claude가 스스로 판단해서 실행하는 모드입니다. 편리하지만 위험합니다 — 잘못된 판단으로 파일이 삭제되거나 위험한 명령이 실행될 수 있으니까요. 이 위험을 줄이기 위해 Claude API를 한 번 더 호출해서 도구 사용의 안전성을 별도로 판정합니다.
1. 도구 사용 요청 발생
2. 화이트리스트 체크
└ FileRead, Grep, Glob, Tasks 등 읽기 전용 → 분류기 건너뛰고 자동 허용
(파일을 읽기만 하는 건 위험하지 않으므로 API 호출 낭비를 피함)
3. Classifier API 호출 → "허용" 또는 "거부"
4. 거부 추적:
└ 연속 3회 거부 → 프롬프팅 모드로 폴백
└ 총 20회 거부 → 프롬프팅 모드로 폴백
거부 추적의 폴백 메커니즘이 중요합니다. 분류기가 지나치게 보수적으로 작동하면, 안전한 작업까지 계속 거부해서 사용자가 아무것도 할 수 없게 됩니다. 연속 3회 또는 누적 20회 이상 거부하면 "차라리 사용자에게 직접 물어보자"는 프롬프팅 모드로 자동 전환합니다.
팁:
CLAUDE_CODE_DUMP_AUTO_MODE=1환경변수를 설정하면 분류기의 요청/응답이/tmp/claude-code/auto-mode/에 JSON으로 덤프됩니다. 자동 모드가 왜 특정 작업을 거부하는지 디버깅할 때 유용합니다.
분류기 API 호출 자체가 실패하면(네트워크 에러, 타임아웃 등) 어떻게 될까요? 프롬프팅으로 폴백합니다 — 자동 거부가 아닙니다. 이것이 fail-open 전략입니다. 보안 시스템이 장애를 만나면 두 가지 선택지가 있습니다. 모든 것을 차단하는 fail-closed, 또는 통과시키는 fail-open. 보안에서 fail-open은 보통 위험한 선택이지만, 여기서의 "통과"는 "무조건 실행"이 아니라 "사용자에게 판단을 넘김"이므로 합리적입니다.
6.5 레이어 5: 위험 패턴 감지
레이어 3의 설정 규칙과 레이어 4의 분류기를 통과하더라도, 특정 패턴은 하드코딩으로 차단합니다.
DANGEROUS_BASH_PATTERNS = [
// 인터프리터: 임의 코드를 실행할 수 있는 프로그래밍 언어 런타임
'python', 'node', 'ruby', 'perl', 'bash', 'sh', 'zsh', 'ksh',
// 코드 실행: 문자열을 코드로 해석하는 명령
'exec', 'eval', 'source',
// 네트워크: 외부로 데이터를 유출하거나 악성 코드를 다운로드할 수 있는 도구
'curl', 'wget', 'nc', 'ncat', 'socat',
// 바이너리/암호화: 데이터 변환이나 암호화로 악성 행위를 은닉할 수 있는 도구
'dd', 'xxd', 'openssl',
// 원격 접근: 다른 시스템으로 침투할 수 있는 도구
'ssh', 'scp', 'sftp',
// 권한 상승: 관리자 권한을 획득하거나 격리를 탈출할 수 있는 명령
'sudo', 'su', 'chroot', 'unshare', 'docker', 'podman',
// 파일시스템 권한: 파일 보호를 우회할 수 있는 명령
'chmod', 'chown', 'chgrp', 'umask', 'mount', 'umount'
]
자동 모드에서 python:*이나 인터프리터 와일드카드를 허용 규칙으로 설정하려 하면 차단됩니다.
isDangerousBashPermission(rule) {
// 도구 수준 allow without content (모든 bash 허용) → 위험
// "python:*", "python*", "python -*" → 위험
// 인터프리터 프리픽스 + 와일드카드 → 위험
}
왜 인터프리터가 특별히 위험할까요? BashTool이 python을 실행할 수 있으면, 그 안에서 파이썬 코드를 통해 어떤 시스템 명령이든 실행할 수 있습니다. python -c "import os; os.system('rm -rf /')" 같은 식으로 Bash 레벨의 모든 보안 검사를 우회할 수 있기 때문에, 인터프리터 실행 자체를 원천 봉쇄하는 것입니다.
6.6 레이어 6: 파일시스템 권한 검증 (62K)
가장 큰 권한 파일(62K)은 파일 경로 검증만 담당합니다. Claude가 "이 파일을 수정하겠습니다"라고 할 때, 그 경로가 정말 접근해도 되는 곳인지를 검증합니다.
- 절대 경로 정규화:
./src/../config.json같은 상대 경로를/home/user/project/config.json으로 풀어서 "실제로 어디인지"를 확인합니다 - 심볼릭 링크 탈출 방지: 프로젝트 폴더 안에
link → /etc/passwd를 가리키는 symlink를 만들어두면, Claude가link를 통해 시스템 파일에 접근할 수 있습니다. 이 검증이 symlink의 실제 대상 경로까지 확인해서 이런 탈출을 차단합니다 - Glob 패턴 안전 확장:
/**/*같은 패턴이 의도치 않게 프로젝트 밖의 경로까지 포함하지 않도록 확장 범위를 제한합니다 - CWD 전용 모드 vs 전체 접근 모드:
acceptEdits모드에서는 현재 작업 디렉토리만 수정 가능 - 스크래치패드 지원: Coordinator 워커(섹션 7.3)가 공유 디렉토리에 접근할 수 있도록 허용 (
tengu_scratch) - Windows/POSIX 경로 처리:
C:\Users\...와/home/...를 모두 처리하는 크로스 플랫폼 지원
6.7 레이어 7: Trust Dialog
새 프로젝트에서 Claude Code를 처음 실행하면 보안 대화상자가 나타납니다. 프로젝트의 .claude/ 디렉토리에 설정이 있는 경우, 그 설정이 무엇을 허용하는지 사용자에게 보여주고 명시적 동의를 받습니다.
- 프로젝트 스코프의 MCP 서버 설정 (외부 도구 연결)
- 커스텀 Hook 설정 (사용자 정의 셸 명령 실행)
- Bash 권한 설정 (어떤 명령이 자동 허용되는지)
- API 키 헬퍼 (인증 정보 접근)
- AWS/GCP 명령 접근 (클라우드 리소스 제어)
- OTEL 헤더 (텔레메트리 데이터 전송)
이 레이어가 필요한 이유는, 악의적인 프로젝트 설정으로 인한 공격을 막기 위해서입니다. 누군가 .claude/settings.json에 "allowedTools": ["Bash:rm -rf /"]를 넣어두고 GitHub에 올려놓으면, 그 저장소를 클론한 사용자가 Claude Code를 실행하는 순간 위험한 명령이 자동 허용될 수 있습니다. Trust Dialog가 이를 사전에 차단합니다.
6.8 레이어 8: Bypass Permissions Kill Switch
Bypass 모드는 모든 권한 검사를 건너뛰는 "궁극의 편의" 모드입니다. 개발 중에 "매번 물어보지 마"라고 쓸 수 있지만, 악용되면 모든 보안 레이어가 무력화됩니다. 이 킬 스위치는 GrowthBook 서버에서 tengu_bypass_permissions_disabled를 활성화하면 작동합니다.
// bypassPermissionsKillswitch.ts
// 사용자가 bypass 모드에 진입하는 것 자체를 차단
// 이미 bypass 모드인 사용자는 이전 모드로 강제 복귀
// 진단 메시지 표시
보안 사고 발생 시 Anthropic이 서버에서 이 플래그를 켜면, 전 세계의 모든 Claude Code 클라이언트에서 bypass 모드가 즉시 비활성화됩니다. 클라이언트 업데이트가 필요 없으므로 대응 시간이 거의 0입니다.
인사이트: 보안 모델의 설계 철학
8개 레이어를 관통하는 일관된 원칙이 있습니다.
- Deny by default — 명시적 allow 규칙이 없으면 거부합니다. 새 도구가 추가되면 기본적으로 차단 상태입니다
- Fail to prompting, not to deny — 시스템이 판단할 수 없으면 자동 거부가 아니라 사용자에게 묻습니다. UX를 해치지 않으면서 안전망을 유지합니다
- Defense in depth — 레이어 1(빌드 타임)이 뚫려도 레이어 4(분류기)가, 분류기가 뚫려도 레이어 5(패턴 감지)가 잡습니다. 단일 실패점이 없습니다
- Server-side kill switch — 보안 사고 발생 시 클라이언트 업데이트 없이 서버에서 즉시 기능을 비활성화할 수 있습니다
- Build-time elimination — 코드가 바이너리에 존재하지 않으면, 그 코드의 취약점도 존재하지 않습니다. 가장 근본적인 보안입니다
7. 미출시 기능: 로드맵이 유출됐습니다
피처 플래그 뒤에 숨어 있던 미출시 기능들이 드러났습니다. 경쟁사에게 가장 "의도치 않은 선물"이 된 영역입니다.
7.1 Voice Mode — 음성으로 코딩하기
// voice/voiceModeEnabled.ts
export function isVoiceModeEnabled(): boolean {
return hasVoiceAuth() && isVoiceGrowthBookEnabled()
}
export function hasVoiceAuth(): boolean {
// OAuth 전용 (Claude.ai 계정 필요)
// API 키/Bedrock/Vertex로는 사용 불가
// voice_stream 엔드포인트 사용
}
export function isVoiceGrowthBookEnabled(): boolean {
return feature('VOICE_MODE')
? !getFeatureValue_CACHED_MAY_BE_STALE('tengu_amber_quartz_disabled', false)
: false
}
몇 가지를 알 수 있습니다.
- 전용
voice_streamAPI 엔드포인트가 존재합니다. 일반 Messages API와 별도입니다. - OAuth 인증 전용입니다. API 키나 서드파티 클라우드(Bedrock/Vertex) 사용자는 접근할 수 없습니다.
- GrowthBook 킬 스위치(
tengu_amber_quartz_disabled)가 걸려 있어서 서버에서 즉시 끌 수 있습니다. - 캐싱 전략이
_CACHED_MAY_BE_STALE로, 실시간이 아닌 캐시된 플래그 값을 사용합니다. 음성 모드 활성화 여부를 매번 서버에 물어보지 않는다는 뜻입니다.
7.2 Web Browser Tool — 진짜 브라우저 자동화
const WebBrowserTool = feature('WEB_BROWSER_TOOL')
? require('./tools/WebBrowserTool/WebBrowserTool.js').WebBrowserTool
: null
현재 WebFetchTool은 정적 HTML만 가져옵니다 — JavaScript로 렌더링되는 SPA(Single Page Application) 페이지는 내용을 볼 수 없습니다. WebBrowserTool은 Bun의 WebView API를 활용한 실제 브라우저 자동화로 추정됩니다. JavaScript 렌더링이 필요한 페이지와도 상호작용할 수 있다는 뜻입니다. Anthropic의 Computer Use(데스크톱 화면을 보고 마우스/키보드를 조작하는 기능)를 터미널 안에서 웹 브라우저에 특화시킨 버전이라고 볼 수 있습니다.
7.3 Coordinator Mode — 멀티 에이전트 오케스트레이션 (19K)
가장 야심찬 미출시 기능입니다.
// coordinator/coordinatorMode.ts
export function isCoordinatorMode(): boolean {
if (feature('COORDINATOR_MODE')) {
return isEnvTruthy(process.env.CLAUDE_CODE_COORDINATOR_MODE)
}
return false
}
Coordinator는 직접 코드를 쓰지 않습니다. 여러 워커 에이전트를 생성하고 작업을 분배하는 메타 오케스트레이터입니다.
- 워커는
AgentTool로 스폰됩니다 - 결과는
<task-notification>XML 블록으로 도착합니다 SendMessage로 워커에게 후속 지시를 보냅니다TaskStop으로 워커를 종료합니다
허용되는 도구가 엄격히 제한됩니다.
COORDINATOR_MODE_ALLOWED_TOOLS = new Set([
'AgentTool', // 워커 생성
'TaskStop', // 워커 종료
'SendMessage', // 워커와 통신
'SyntheticOutput', // 워커 결과를 조합해서 사용자에게 보여줄 최종 출력 생성
])
Coordinator는 Bash를 실행할 수 없습니다. 파일도 읽을 수 없습니다. 오직 워커를 관리하는 것만 합니다. 이건 권한 분리(principle of least privilege)의 극단적 적용입니다 — 오케스트레이터가 직접 도구를 실행할 수 있으면, 단일 장애점이 되기 때문입니다.
공유 스크래치패드 (tengu_scratch GrowthBook 게이트):
워커 간 정보 공유를 위한 디렉토리입니다. 일반적인 파일시스템 권한 검사를 우회합니다 — 워커가 CWD 밖의 스크래치패드에 접근할 수 있어야 하니까요.
이건 사실상 AI 에이전트의 마이크로서비스 아키텍처입니다. 마이크로서비스에서 API 게이트웨이가 직접 비즈니스 로직을 실행하지 않고 서비스들에 요청을 분배하듯, Coordinator는 직접 코드를 쓰지 않고 워커들에게 작업을 분배합니다. 각 워커는 격리된 컨텍스트에서 독립적으로 작업하고, 결과만 Coordinator에게 돌려줍니다.
7.4 Kairos — 선제적 어시스턴트
그리스어로 "적절한 때"를 의미하는 Kairos는 Claude가 먼저 행동하는 모드입니다.
| 피처 플래그 | 도구 | 기능 |
|---|---|---|
KAIROS |
SendUserFileTool |
사용자에게 파일을 선제적으로 전송 |
KAIROS || KAIROS_PUSH_NOTIFICATION |
PushNotificationTool |
모바일/데스크톱 푸시 알림 |
KAIROS_GITHUB_WEBHOOKS |
SubscribePRTool |
GitHub PR 웹훅 구독 |
PROACTIVE || KAIROS |
SleepTool |
백그라운드 대기 (타이머) |
KAIROS_CHANNELS |
(미상) | 멀티 채널 통합 |
KAIROS_BRIEF |
(미상) | 체크포인트/상태 업데이트 |
시나리오를 그려보면 이렇습니다. GitHub PR에 새 리뷰 코멘트가 달리면 SubscribePRTool이 감지하고, CI 결과를 확인한 뒤, PushNotificationTool로 "PR #123에 리뷰가 달렸고, CI가 실패했습니다. 이 부분을 수정하면 될 것 같습니다"라는 알림을 보냅니다. SleepTool로 주기적으로 깨어나서 상태를 점검합니다.
사용자가 세션을 열지 않아도 Claude가 일하는 구조입니다. 이건 코딩 어시스턴트를 넘어 자율 소프트웨어 엔지니어링 에이전트로의 전환을 의미합니다.
7.5 Agent Triggers & Monitoring
const cronTools = feature('AGENT_TRIGGERS')
? [CronCreateTool, CronDeleteTool, CronListTool]
: []
const RemoteTriggerTool = feature('AGENT_TRIGGERS_REMOTE')
? require('./tools/RemoteTriggerTool/RemoteTriggerTool.js').RemoteTriggerTool
: null
const MonitorTool = feature('MONITOR_TOOL')
? require('./tools/MonitorTool/MonitorTool.js').MonitorTool
: null
"팀메이트(teammate)"는 Anthropic이 장기 실행 에이전트 인스턴스를 부르는 내부 용어로 추정됩니다. 팀메이트가 생성한 크론 작업은 해당 에이전트의 agentId로 태그되어, 그 에이전트의 메시지 큐로 라우팅됩니다. 즉, 장기 실행 에이전트가 자기만의 스케줄을 관리할 수 있습니다 — "매일 오전 9시에 CI 상태를 점검하라" 같은 자율적 반복 작업이 가능해지는 것입니다.
7.6 UDS Inbox — 멀티 디바이스 메시징
const ListPeersTool = feature('UDS_INBOX')
? require('./tools/ListPeersTool/ListPeersTool.js').ListPeersTool
: null
"UDS"는 Unified Device Stack(통합 디바이스 스택)으로 추정됩니다. 에이전트가 "피어" — 같은 사용자 계정에 연결된 다른 디바이스나 Claude Code 인스턴스 — 를 조회하고, bridge://(Bridge 시스템 경유)나 other://(직접 통신) 스키마로 메시지를 라우팅할 수 있습니다.
노트북의 Claude Code가 "데스크톱의 Claude Code한테 이 테스트 돌려달라고 해줘"라고 요청하는 세계입니다. 아직 먼 이야기일 수 있지만, 통신 파이프는 이미 깔려 있습니다.
7.7 Workflow Scripts
const WorkflowTool = feature('WORKFLOW_SCRIPTS')
? (() => {
require('./tools/WorkflowTool/bundled/index.js').initBundledWorkflows()
return require('./tools/WorkflowTool/WorkflowTool.js').WorkflowTool
})()
: null
번들된 워크플로우(pre-built 자동화 스크립트)가 있고, 초기화 시스템이 있습니다. 서브 에이전트 내부에서는 재귀 실행이 차단됩니다 (ALL_AGENT_DISALLOWED_TOOLS에 포함). 워크플로우가 또 다른 워크플로우를 호출하고, 그것이 또 다른 워크플로우를 호출하는 무한 재귀를 방지하기 위한 안전장치입니다.
7.8 Bridge — 원격 제어 시스템 (33+ 파일)
Bridge 시스템은 33개 이상의 파일로 구성된 대형 서브시스템입니다. Claude.ai 웹에서 로컬 머신의 Claude Code를 제어하는 "Remote Control" 기능의 백엔드입니다.
연결 흐름
1. 사용자 → OAuth로 claude.ai 로그인
2. CCR(Claude Cloud Runtime) API → 구독 + GrowthBook 게이트 확인 (tengu_ccr_bridge)
3. 로컬 Claude Code → environment_id + environment_secret 획득
4. 인증된 터널 설정 (WebSocket)
5. 브라우저 → Bridge API → 로컬 도구 실행 → 결과 반환
보안 티어
| 티어 | 인증 요구사항 | 용도 |
|---|---|---|
| Standard | OAuth 토큰 | 일반 원격 세션 |
| Elevated | OAuth + Trusted Device Token (JWT) | 민감한 작업이 포함된 세션 |
Elevated 티어에서는 X-Trusted-Device-Token 헤더로 디바이스 신뢰성을 추가 검증합니다.
// bridge/trustedDevice.ts
// 물리적 디바이스에 바인딩된 JWT
// "이 요청이 실제로 등록된 장치에서 온 것"을 보장
세션 격리
각 원격 세션은 Git worktree로 격리됩니다. 브라우저에서 두 개의 탭으로 같은 프로젝트에 접속해도, 각각 독립된 작업 디렉토리에서 돌아갑니다. 세션 간 merge conflict를 원천 봉쇄하는 접근입니다.
세션 라이프사이클은 sessionRunner.ts가 관리하며, JWT 서명된 WorkSecret으로 세션 핸드오프 보안을 유지합니다.
인사이트: 원격 제어의 설계 교훈
Bridge 시스템에서 주목할 점은 세션 격리 전략입니다. Git worktree를 세션 격리 단위로 사용한 것은 기존 인프라(Git)를 활용해 파일시스템 수준의 격리를 달성하는 실용적 선택입니다. 컨테이너나 VM 수준의 격리보다 오버헤드가 낮으면서도, 각 세션이 독립된 작업 디렉토리를 갖습니다.
2티어 인증 구조(Standard/Elevated)도 배울 점이 있습니다. 모든 원격 작업에 최고 수준의 인증을 요구하면 사용자 경험이 나빠지고, 최저 수준만 요구하면 보안이 약해집니다. 작업의 민감도에 따라 인증 수준을 달리하는 이 접근은, 보안과 편의성 사이의 균형을 잡는 현실적 방법입니다.
인사이트: 미출시 기능이 말해주는 방향
이 기능들을 종합하면 Anthropic의 전략이 보입니다.
- CLI → 플랫폼: 단일 터미널 도구에서 멀티 디바이스, 멀티 에이전트 플랫폼으로
- 반응적 → 선제적: 사용자 명령 대기에서 자율적 모니터링/알림으로
- 텍스트 → 멀티모달: 타이핑에서 음성, 브라우저 자동화로
- 단일 → 오케스트레이션: 하나의 에이전트에서 Coordinator가 관리하는 에이전트 스웜으로
8. 마무리: 유출이 말해주는 것
npm source map이라는 어처구니없는 경로로 세상에 나온 Claude Code의 내부는, 단순한 API 래퍼가 아니라 4,600개 파일에 걸친 풀스택 에이전트 플랫폼이었습니다. "LLM API를 호출하고 도구를 실행하면 끝"이라는 건 데모 수준의 이해였습니다. 프로덕션에서는 4단계 압축 계층, 캐시 편집 블록 피닝, 비용 인식 에러 복구, 8겹 보안, 스트리밍 병렬 도구 실행 같은 것들이 필요합니다. OpenAI Codex, Cursor, Devin 같은 경쟁 제품도 내부적으로는 비슷한 수준의 복잡성을 가지고 있을 겁니다. 다만 그 코드가 공개된 적이 없을 뿐입니다.
이 아키텍처를 관통하는 하나의 원칙이 있다면, 비용 인식(cost-awareness)입니다. 에러 복구는 무료 옵션부터, 압축은 API 호출 없는 방법부터, 도구 검색은 필요할 때만. API 호출 한 번이 곧 비용인 시스템에서, "가장 저렴한 방법부터"는 우아함이 아니라 생존 전략입니다.
미출시 기능들은 Anthropic의 방향을 보여줍니다. 음성 모드, 웹 브라우저 자동화, 멀티 에이전트 Coordinator, 선제적 Kairos 모드. "코딩 어시스턴트"에서 "자율 소프트웨어 엔지니어링 플랫폼"으로의 전환이 이미 코드 레벨에서 진행 중입니다.
그리고 "오픈소스"에 대한 질문이 남습니다. 공식 저장소에는 플러그인 인터페이스(279개 파일)만 있고, 핵심 엔진(4,600+ 파일)은 상용 라이선스 뒤에 있습니다. 이건 Anthropic만의 문제가 아닙니다. 많은 AI 제품이 "오픈"이라는 라벨 아래 확장 인터페이스만 공개하고 핵심은 비공개로 유지합니다.
아이러니가 있습니다. 빌드 타임 데드코드 제거라는 세련된 보안 메커니즘을 구현해놓고, 같은 빌드 파이프라인에서 source map을 지우는 걸 누락했습니다. 8겹의 양파 껍질로 사용자의 파일 시스템을 보호하면서, 자기 소스코드는 npm에 올려버린 것입니다.
어쩌면 이게 소프트웨어 엔지니어링의 본질인지도 모릅니다. 가장 정교한 시스템도 가장 단순한 실수에 무너집니다. Anthropic의 엔지니어들이 구축한 것은 분명 인상적인 에이전틱 아키텍처입니다. 다만 다음번에는 .npmignore에 *.map을 추가하는 걸 잊지 않기를 바랍니다.
이 글은 유출된 소스코드의 기술적 분석이며, 소스코드의 재배포나 사용을 권장하지 않습니다. 모든 코드의 저작권은 Anthropic PBC에 있습니다.
Subscribe via RSS